TL;DR#
Spatio-temporal consistency is vital for creating quality generated videos, but existing research often neglects the complex interplay between plot progression and camera techniques. Current methods mainly focus on combining temporal and spatial consistency by adding descriptions of camera movements after prompts, failing to constrain the outcomes. For videos with frequent camera movements, the interaction between different plot elements becomes increasingly complex. Thus, there is a need for more holistic approaches.
This paper introduces a dataset called DropletVideo-10M, featuring 10 million videos with diverse camera motions and object actions, annotated with detailed captions. The authors introduce and study integral spatio-temporal consistency, which considers the synergy between plot progression, camera techniques, and the impact of prior content. It also proposes an open-source model, DropletVideo, trained to maintain spatio-temporal coherence during video generation. The project is available at https://dropletx.github.io.
Key Takeaways#
Why does it matter?#
This paper tackles a crucial gap in video generation by addressing integral spatio-temporal consistency. By offering both a large-scale dataset and an open-source model, this work enables further research and advancements in generating more realistic and coherent videos, moving beyond current limitations. The study of these techniques can open up new directions for future investigation.
Visual Insights#

🔼 Figure 1 illustrates the difference between two types of spatio-temporal consistency in video generation: Composable and Integral. Composable Spatio-Temporal Consistency (a) involves simply combining temporal and spatial consistency, often without fully considering the impact of camera movement on the scene. Examples like MovieGen and VBench++ represent this approach. While this ensures basic consistency, new scenes introduced after a camera movement tend to be static, lacking dynamic interaction. In contrast, Integral Spatio-Temporal Consistency (b) emphasizes the interrelationship between plot progression, camera techniques, and the influence of previous scene elements on subsequent ones. Camera movement is not simply added; it’s integrated into the narrative. The example of a ‘Forrest Gump’ clip demonstrates this: Maintaining Forrest running while incorporating the movement of a car that enters the scene due to a camera pan requires considering how the car’s motion interacts with Forrest’s action and ensuring consistent spatial relationships are preserved. The blue region highlights the temporal consistency of the plot, while the red region shows the spatial consistency maintained despite camera movement.
read the caption
Figure 1: Comparisons between Composable Spatio-temporal Consistency and Integral Spatio-temporal Consistency. (a) Composable Spatio-Temporal Consistency refers to the straightforward combination of temporal and spatial consistency, without limiting the effects of camera movement. Studies such as MovieGen [49] and VBench++ [26] are dedicated to realizing this consistency. Despite the potential emergence of a new scene post camera movement, the introduced scene tends to be stationary, precluding the onset of further motion. (b) Integral Spatio-Temporal Consistency considers the interplay between plot development and camera techniques, along with the enduring influence of antecedent content on subsequent creation. This is because a camera movement may introduce or eliminate objects, thereby overlaying and impacting the preceding storyline. For example in the “Forrest Gump” clip, achieving integral spatio-temporal consistency requires incorporating the motion of the “car” as it recedes following the camera’s “turn right” action while maintaining the scene of Forrest running, ensuring that “Forrest Gump’s right remains at a consistent distance”, preserving the correct spatial relationships. Temporal consistency in plot progression is highlighted in the blue region, while the red region denotes spatial consistency induced by camera movement
| Words | Year | Clips | Avg dur. | Total dur. | Category | |
| HowTo100M [42] | 4.0 words | 2019 | 100M | 3.6s | 135Khr | Temporal |
| WebVid-10M [6] | 12.0 words | 2021 | 10M | 18.0s | 52Khr | Temporal |
| HD-VILA-100M [71] | 17.6 words | 2022 | 100M | 11.7s | 760.3Khr | Temporal |
| InternVid [66] | 32.5 words | 2023 | 7M | 13.4s | 371.5Khr | Temporal |
| HD-VG-130M [65] | ~9.6 words | 2024 | 130M | ~5.1s | ~184Khr | Temporal |
| Panda-70M [11] | 13.2 words | 2024 | 70M | 8.5s | 167Khr | Temporal |
| MiraData [29] | 318.0 words | 2024 | 788K | 72.1s | 16Khr | Temporal |
| Koala-36M [64] | 202.1 words | 2024 | 36M | 13.75s | 172Khr | Temporal |
| CO3Dv2 [54] | - | 2021 | 36k | - | - | Spatial |
| DL3DV-10K [36] | - | 2023 | 10K | - | - | Spatial |
| RealEstate-10K [81] | - | 2023 | 10K | - | - | Spatial |
| MVImageNet [77] | - | 2023 | 229K | - | - | Spatial |
| MV-Video [27] | - | 2024 | 1.8M | 2s | 1Khr | Spatio-Temporal |
| DropletVideo-10M (Ours) | 206.0 words | 2025 | 10M | 7.3s | 20.4Khr | Spatio-Temporal |
🔼 This table compares DropletVideo-10M with other video-language datasets, highlighting DropletVideo-10M’s superior features. It has longer captions (except for MiraData, which is much smaller), higher information density per second of video (7.3 seconds average), and a unique focus on spatio-temporal attributes, making it the most comprehensive dataset for spatio-temporal video generation. Other datasets, like Koala-36M, may have long captions, but they don’t prioritize camera movement details.
read the caption
Table 1: Comparison of DropletVideo-10M and other video-language datasets. DropletVideo-10M dataset possesses unique advantages. First, it contains longer text captions than all but MiraData, yet MiraData is substantially smaller in scale. Second, with an average video length of 7.3 seconds, it exhibits the highest information density per second of video. Third, DropletVideo-10M emphasizes the spatio-temporal attributes of videos and captions, distinguishing it as the most comprehensive spatio-temporal video generation dataset to date. In contrast, datasets like Koala-36M, despite their wealth of textual descriptions, do not prioritize the specifics of spatial transformations due to camera movement.
In-depth insights#
Spatio-Temporal#
Spatio-temporal consistency is a critical aspect of video generation, ensuring both visual coherence within frames and temporal continuity across consecutive frames. It addresses challenges like maintaining consistent object appearances across varying viewpoints and ensuring smooth transitions that adhere to physical laws. Existing research often focuses on either temporal or spatial consistency independently, or simple combinations. However, true spatio-temporal consistency considers the interplay between plot progression, camera techniques, and the lasting impact of earlier content on later generation. This involves ensuring new scenes introduced by camera movements integrate logically without disrupting the preceding narrative. Achieving this requires models to understand and accurately portray the relationships between objects, scenes, and camera actions over time, creating more complex, multi-plot narratives with natural camera movements.
DropletVideo-10M#
The ‘DropletVideo-10M’ section introduces a large-scale video dataset designed to address the critical challenge of spatio-temporal consistency in video generation. Unlike existing datasets that focus primarily on either temporal coherence or spatial detail, ‘DropletVideo-10M’ emphasizes the synergistic interplay between plot progression, camera techniques (dynamic motion), and the lasting impact of prior content on subsequent frames. The dataset comprises 10 million videos with object actions annotated with an average of 206 words, meticulously detailing camera movements and plot developments. This focus is a key differentiator, aiming to enable models to generate more complex, multi-plot narratives with natural camera movements and smooth scene transitions, overcoming limitations of current approaches that often treat camera movement as a separate, unconstrained element, it is the largest open source dataset that preserves integral spatio-temporal consistency. The explicit descriptions also contain their effects.
Camera Dynamics#
While ‘Camera Dynamics’ isn’t explicitly a section heading, the paper delves into camera movement extensively. The research introduces a novel dataset (DropletVideo-10M) containing videos featuring various camera movements and plot developments. This is a key distinction from existing datasets, which often lack sufficient emphasis on camera dynamics. The paper also addresses how to generate videos with camera motion. It introduces a Motion Adaptive Generation (MAG) strategy, allowing the model to dynamically adjust to the desired motion speed in the generated video. The paper explores how different camera movements (truck right, truck left, pedestal down, tilt up, dolly in, pan right, and tilt up) influence the overall video consistency and coherence. This investigation aims to enhance the realism and visual appeal of generated videos, moving beyond static scenes.
Adaptive Motion#
Adaptive motion in video generation signifies a crucial advancement, allowing for dynamically adjusting movement speeds within generated content. This is significant because previous methods often resulted in videos with fixed motion speeds, which limited creative control and realism. By introducing motion intensity as a controllable parameter, the generative model can better cater to diverse customer preferences and requirements for detail. Such a strategy ensures that generated content adheres to both global and local constraints with fine control. This can be achieved through means such as uniformly sampling video frames and detail caption data for these sampled frames, capture global dependencies, or obtain complete semantic information, thereby controlling the intensity of the video created. Motion intensity, as a control parameter is used to describe the input coding with time, and to ensure diversity, independent strategies in text and vision latent spaces are applied.
3D Consistency#
The discussion of 3D consistency highlights the paper’s focus on spatial coherence in video generation. The authors train their model, DropletVideo, on a large spatio-temporal dataset, enabling it to maintain consistency across varying perspectives. Experiments showcase its ability to preserve details and structure when the camera rotates around objects, such as a snowflake. Furthermore, the model demonstrates proficiency in handling arc shots, effectively maintaining 3D consistency even without specific design for such movements. This capacity underscores the model’s robust spatial understanding and ability to generate visually coherent videos from different viewpoints, even when the camera’s position drastically changes, showing robust spatial 3D continuity.
More visual insights#
More on figures

🔼 This figure compares the DropletVideo-10M dataset with existing datasets. Subfigure (a) shows examples from existing datasets like Panda-70M, highlighting their limited camera movement and short captions. Subfigure (b) showcases DropletVideo-10M, emphasizing its rich diversity in camera motion, detailed long-form captions (averaging 206 words), and strong spatio-temporal consistency (shown via red highlighted text in the example caption). The key difference is that DropletVideo-10M explicitly incorporates both camera movement and event progression within its videos and captions, making it more suitable for research on integral spatio-temporal video generation.
read the caption
Figure 2: The DropletVideo-10M dataset features diverse camera movements, long-captioned contextual descriptions, and strong spatio-temporal consistency. (a) Existing datasets, such as Panda-70M [11], place less emphasis on camera movement and contain relatively brief captions. (b) In contrast, DropletVideo-10M consists of spatio-temporal videos that incorporate both camera movement and event progression. Each video is paired with a caption that conveys detailed spatio-temporal information aligned with the video content, with an average caption length of 206 words. The spatio-temporal information is highlighted in red in the figure.

🔼 This figure illustrates the multi-stage pipeline used to create the DropletVideo-10M dataset. The process begins with collecting raw videos from YouTube using a set of keywords, resulting in a large pool of videos. This pool is then processed through several filtering and segmentation steps. First, video clips are segmented into shorter, more manageable pieces focusing on those containing both object motion and camera movement. Next, these segments are further filtered based on aesthetic and image quality scores to ensure high visual fidelity. The final step involves generating spatio-temporal consistent captions for each video clip using a fine-tuned video captioning model. These captions provide detailed descriptions of both object motion and camera movement, which are crucial for training models focused on integral spatio-temporal consistency.
read the caption
Figure 3: The pipeline we proposed to curate the DropletVideo-10M dataset.

🔼 This figure displays two histograms showing the distributions of aesthetic scores and image quality scores for the DropletVideo-10M dataset. The aesthetic scores were generated using the LAION aesthetics model, while image quality scores came from the DOVER-Technical model. The histograms illustrate that the majority of videos in the dataset receive high scores in both categories, indicating a high overall quality.
read the caption
Figure 4: The aesthetics distribution and the image quality distribution of DropletVideo-10M. These distributions demonstrate that our dataset achieves high scores in both aesthetics and image quality, indicating an overall high-quality standard for the dataset.

🔼 Figure 5 presents example captions generated by four different fine-tuned video-to-text models (InternVL2-8B, ShareGPT4Video-8B, ShareCaptioner-video, and MA-LMM). The captions describe the same video, demonstrating the variation in detail and accuracy across different models. InternVL2-8B is highlighted for its superior ability to capture intricate camera movements and narrative elements.
read the caption
Figure 5: Captions generated by the fine-tuned models, including InternVL2-8B[13, 14], ShareGPT4Video-8B[10], ShareCaptioner-video[10], and MA-LMM[22]. InternVL2-8B[13, 14] captures intricate camera work and narrative elements with high efficacy.

🔼 This figure showcases examples of video captions generated by a fine-tuned video captioning model. The captions, shown alongside corresponding video stills, highlight in red the parts describing camera movements. The examples demonstrate that the model generates detailed and accurate captions that precisely reflect not only the camera’s actions (e.g., zooming, panning, rotating) but also the changes in the scene and object details as the camera moves. These rich, spatio-temporally detailed captions provide valuable training data for video generation models, helping them better understand and reproduce complex camera movements and their impact on the visual narrative.
read the caption
Figure 6: Results of the fine-tuned video captioning model. In the prompts, descriptions related to camera motions are highlighted in red. It is evident from the training samples that the camera undergoes multiple motion changes. Moreover, the scene details in the videos are clearly described and accurately followed as the camera moves. These high-density informational text captions significantly enhance the spatio-temporal semantics of the videos. Consequently, our video captions in the DropletVideo-10M dataset provide enriched guidance for training video generation models.

🔼 The DropletVideo framework processes video data using a 3D causal Variational Autoencoder (VAE) with adaptive equalization sampling, controlled by motion intensity (M). The extracted video features (xv) are fed, along with text embeddings (xt), into a Modality-Expert Transformer. This transformer generates video output using a combined encoding of temporal information (T) and motion intensity (M) (xT&M). The figure compares traditional video sampling (fixed-frame rate after random segment selection) with DropletVideo’s adaptive method, which uses motion intensity (M) to guide adaptive frame rate sampling across the whole video for better consistency.
read the caption
Figure 7: Overview of the DropletVideo Framework. The video is processed by the 3D causal Variational Autoencoder (VAE) following adaptive equalization sampling, which is steered by the motion intensity M𝑀Mitalic_M. The video feature xvsubscript𝑥𝑣x_{v}italic_x start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT is then input into the Modality-Expert Transformer, depicted on the right side of the figure, to facilitate video generation in conjunction with the text encoding xtsubscript𝑥𝑡x_{t}italic_x start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT, and the combined encoding xT&Msubscript𝑥𝑇𝑀x_{T\&M}italic_x start_POSTSUBSCRIPT italic_T & italic_M end_POSTSUBSCRIPT of the temporal T𝑇Titalic_T and the motion intensity M𝑀Mitalic_M. The upper left part illustrates the contrast between (a) the traditional sampling approach and (b) DropletVideo’s adaptive equalization sampling. Traditional methods involve random segment interception followed by fixed-frame-rate sampling of the intercepted segments, whereas DropletVideo employs adaptive frame rate sampling across the entire video segments, guided by M𝑀Mitalic_M.

🔼 Figure 8 demonstrates DropletVideo’s ability to generate videos with integral spatio-temporal consistency. This means that new objects or scenes introduced by camera movements are smoothly integrated into the existing scene and behave logically within the context. The top example (a) shows a lake scene with two boats. As the camera pans, a third boat appears, and the original boats continue their interaction. The leaves on the shore continue to sway naturally, showing the seamless integration of the new element. The bottom example (b) shows a forest scene with birds. As the camera pans, a tree (requested in the text prompt) appears, while the birds and the rest of the scene maintain consistency, illustrating that the new element fits seamlessly into the existing narrative. Both examples highlight DropletVideo’s ability to preserve both spatial and temporal consistency across the video generation process.
read the caption
Figure 8: DropletVideo facilitates the generation of videos that maintain integral spatio-temporal consistency. New objects or scenes introduced via camera movement are seamlessly integrated and interact logically with the pre-existing scenes. In video (a), as the camera moves, a new boat appears on the lake, the boat on the right of the original two boats continues to slowly chase the boat on the left, and the leaves on the shore still sway gently in the breeze. In video (b), as the camera moves left, the tree called for in the text prompt successfully appears in the shot, the original flock of birds continues to fly, and the grass and sky show continuity as the camera moves.

🔼 Figure 9 demonstrates DropletVideo’s ability to generate videos with new objects appearing seamlessly due to camera movements, while maintaining consistency with existing scene elements and prompt descriptions. Four example scenarios are shown: (a) A red apple appears as the camera pans right, while a chef continues cooking, showcasing smooth object integration. (b) An apple with water droplets is accurately rendered, demonstrating the model’s ability to handle detailed descriptions and complex textures. (c) Brown spots are added to the apple by modifying the prompt, showing dynamic visual adjustments based on prompt changes. (d) The apple is changed to bananas, illustrating versatility and precision in object transformation. These examples highlight DropletVideo’s advanced control over object generation and its ability to incorporate new elements into a scene without disrupting established consistency.
read the caption
Figure 9: DropletVideo demonstrates advanced controllability in generating scenes where new objects emerges due to camera movement. In video (a), as the camera pans right, the red apple specified in the prompt appears seamlessly, while the chef continues cooking, illustrating smooth integration of new objects. Video (b) showcases the system’s ability to handle detailed descriptions, as the prompt’s depiction of an apple with water droplets is rendered accurately, highlighting complex textures. In video (c), a prompt modification adds brown spots to the apple, which are visibly integrated, showing dynamic visual adjustments. Finally, in video (d), the prompt changes the apple to bananas, and the system adeptly features bananas, demonstrating versatility and precision in object transformation.

🔼 This figure showcases DropletVideo’s ability to maintain 3D consistency in video generation. The top panel shows a snowflake with a camera rotating around it. Despite the camera movement, the snowflake’s details remain consistent from all angles, demonstrating the model’s ability to maintain spatial coherence. The bottom panel shows a similar example with an insect as the main subject; again, the model accurately represents its 3D form despite the camera rotating around it. While DropletVideo performs well, the authors acknowledge limitations in generating a full 360-degree rotation, an area for future improvement.
read the caption
Figure 10: DropletVideo demonstrates excellent 3D consistency. In the top example, the camera moves around a snowflake, showcasing significant camera movement while maintaining the snowflake’s details from multiple perspectives. In the bottom example, the camera circles around an insect, and DropletVideo ensures the insect’s 3D consistency across a wide range of rotation angles. However, DropletVideo still has limitations in generating content for a full 360-degree rotation, which will be addressed in future work. Overall, these examples illustrate DropletVideo’s strong performance in spatial 3D consistency.

🔼 Figure 11 demonstrates DropletVideo’s ability to control video generation speed. By adjusting the motion intensity parameter (M), users can precisely alter the speed of both camera movements and the movement of the primary subject within the video. The figure shows that doubling the M parameter significantly slows down the rotation of a snowflake, showcasing the model’s fine-grained control over the dynamic aspects of video generation.
read the caption
Figure 11: DropletVideo facilitates precision control over video generation speed. Modifying the Input Speed parameter alters the movement speed of both the camera and target. In the third line, the camera motion parameter M𝑀Mitalic_M is doubled, and the snowflake’s rotation speed is substantially decreased compared to the initial setting.

🔼 Figure 12 visually demonstrates DropletVideo’s versatility in generating diverse camera movements. Each sub-figure [(a) through (e)] showcases a distinct camera technique resulting in a unique visual effect. (a) Camera Truck Right shows a smooth rightward pan, (b) Camera Truck Left illustrates a leftward pan, (c) Camera Pedestal Down depicts a downward vertical movement, (d) Camera Tilt Up demonstrates an upward tilting motion, and (e) Camera Dolly In showcases a forward movement towards the subject. Finally, (f) showcases a composite shot combining a pan to the right and an upward tilt, demonstrating complex camera control.
read the caption
Figure 12: DropletVideo showcases its robust capabilities in generating videos with diverse camera movements. Panels (a)-(e) illustrate the outcomes of specific camera motions: Camera Truck Right, Camera Truck Left, Camera Pedestal Down, Camera Tilt Up, and Camera Dolly In. Panel (f) presents a composite camera shot that combines Camera Pan Right and Tilt Up.

🔼 Figure 13 presents a comparison of video generation results for a ‘snow scene’ prompt across several models: DropletVideo, Kling, Vivago, Gen3, Alpha Turbo, Hailuo, I2V-01-Live, Vidu 2.0, Qingying, I2V 2.0, WanX 2.1, and CogVideoX-Fun. The results demonstrate that DropletVideo, Kling, and Vivago successfully generate videos that accurately reflect the prompt’s specifications regarding camera movement and scene elements. All three models achieve comparable video quality.
read the caption
Figure 13: Snow example. The videos generated by DropletVideo, Kling, and Vivago all maintain consistency with the prompt in terms of camera movement and various elements within the video. Their video quality is at the same level.

🔼 Figure 14 compares video generation results for a scene of boats on a lake with a moving camera. DropletVideo, Hailuo, WanX, and Kling v1.6 all correctly depict the boats’ and camera’s movements. However, Hailuo, WanX, and Kling v1.6 incorrectly synchronize the movement of the lake’s leaves with the camera, making the result unrealistic. DropletVideo successfully maintains the natural relative motion between the leaves, boats, and camera, showcasing its ability to preserve integral spatiotemporal consistency.
read the caption
Figure 14: Boat example. Our DropletVideo, along with Hailuo, WanX, and Kling v1.6, correctly understood the movement of the boat and the camera motion. However, these three models failed to ensure that the motion of the leaves remained logically consistent with the camera movement, resulting in the leaves moving synchronously with the camera, which is an unnatural effect. In contrast, our model maintains the relative motion consistency between the camera, boat, and leaves in the generated video. This is a typical demonstration of its integral spatio-temporal consistency capability.

🔼 Figure 15 presents a comparison of video generation results for a sunset scene, focusing on the alignment of camera movement with object positioning and the realistic depiction of lighting changes. DropletVideo and Kling v1.6 both correctly position elements within the scene as the camera moves. However, Kling v1.6 fails to dynamically adjust the lighting reflections on the clouds, creating an unrealistic effect. In contrast, DropletVideo’s output shows natural variation in cloud lighting reflections, accurately reflecting real-world phenomena, thereby demonstrating a higher level of spatio-temporal consistency.
read the caption
Figure 15: Sunset example. Only DropletVideo and Kling v1.6 successfully ensure the correct alignment between camera movement and object positioning. However, in Kling’s generated video, the lighting reflections on the clouds remain unchanged, lacking natural variation. In contrast, in our model’s generated video, as the camera moves, the light reflections on the clouds dynamically adjust, making the scene more consistent with real-world natural phenomena.

🔼 Figure 16 presents a comparison of video generation results from different models, focusing on a scene where a chef is preparing food and a red apple appears as the camera pans. The other models struggle to produce the apple correctly after the camera movement, often failing to generate it entirely or creating an apple of the wrong size or in an inappropriate location. DropletVideo, in contrast, successfully generates the apple with accurate size and placement, seamlessly integrating it into the scene. This highlights DropletVideo’s superior ability to maintain spatial and temporal consistency during dynamic video generation.
read the caption
Figure 16: Kitchen example. We expect the focus of the video to transition from the chef to a red apple as the camera moves. Only DropletVideo successfully achieved this transition, while other models failed to correctly generate “a red apple” after the camera movement. Besides, it also ensures that the apple it generates are of a reasonable size and are positioned appropriately within the scene.

🔼 Figure 17 presents a comparison of video generation models’ ability to produce a video of a person smoothly ascending a staircase while maintaining consistent camera movement and scene details. The prompt instructed the models to generate a video showing the camera’s upward movement along the staircase, focusing on elements such as the red carpeting, intricate railings, and wall decorations. DropletVideo and Gen-3 successfully achieved this, accurately depicting the camera’s smooth trajectory and including the specified scene elements. However, Runway’s output failed to incorporate key details, like wall decorations and lighting, illustrating the superiority of DropletVideo and Gen-3 in maintaining both visual and motion consistency.
read the caption
Figure 17: Staircase example. We required the camera to move smoothly up the stairs, ensuring that its trajectory remains logically consistent with the staircase in the video. Only our DropletVideo and Gen3 successfully maintained the correct camera movement path. However, Runway failed to generate key elements such as wall decorations and lights.

🔼 Figure 18 presents a comparison of video generation results for a lake scene. The prompt describes a complex camera movement: panning right and then tilting upwards, with corresponding changes in the scene’s elements. While other models failed to accurately reproduce this complex camera motion and scene evolution, DropletVideo successfully generated a video that precisely matched the prompt’s specifications. This highlights DropletVideo’s ability to maintain spatiotemporal consistency during both camera movement and content generation, even adding elements to the scene (sky and clouds) not initially visible in the image.
read the caption
Figure 18: Lake example. The camera movement path is complex—it first moves to the right, then tilts upward, while the elements in the video change accordingly. All other models failed to accurately capture this camera movement, except for our DropletVideo. Our model not only strictly followed the prompt in executing the camera motion but also dynamically altered the scene, successfully revealing the sky and white clouds, which were not present in the initial image.
More on tables
| Institute | Year | Model | Tech Solution | Data | Self-Collected Data | |
| I2VGen-XL [48] | Alibaba | 2023 | ||||
| Animate-Anything [34] | Alibaba | 2024 | ||||
| SVD-XT-1.1 [9] | Stability AI | 2024 | ||||
| DynamiCrafter [70] | Tencent | 2024 | ||||
| CogVideoX [73] | Zhipu AI | 2024 | ||||
| HunyuanVideo [31] | Tencent | 2024 | ||||
| OpenSora [80] | HPC-AI Tech | 2024 | ||||
| OpenSoraPlan [33] | PKU | 2024 | ||||
| WanX [60] | Alibaba | 2024 | ||||
| Cosmos [1] | Nvidia | 2025 | ||||
| Step-Video [41] | Stepfun | 2025 | ||||
| Movie Gen [58] | Meta | 2024 | ||||
| Gen-3 [56] | Runway | 2024 | ||||
| Sora [44] | OpenAI | 2024 | ||||
| Pika [47] | Pika | 2024 | ||||
| Vivago [62] | Vivago | 2024 | ||||
| Ray2 [39] | Luma AI | 2025 | ||||
| Kling [32] | Kwai | 2024 | ||||
| Vidu [61] | Vidu | 2024 | ||||
| Hailuo [20] | MiniMax | 2024 | ||||
| Qingying [2] | Zhipu AI | 2024 | ||||
| DropletVideo (Ours) | 2025 |
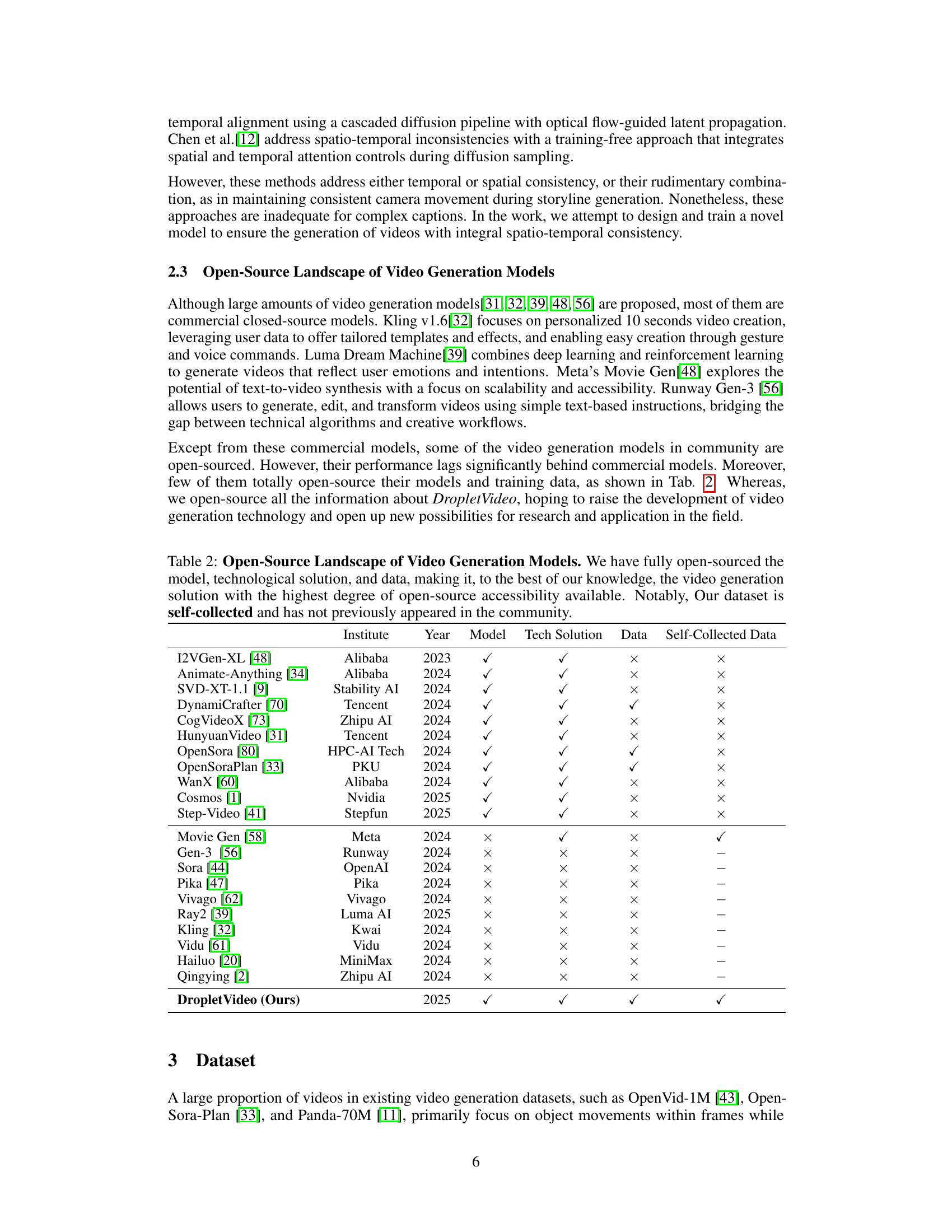
🔼 This table compares various open-source video generation models, highlighting key features like availability of model weights, technological solutions, and datasets. It emphasizes that the DropletVideo project offers a uniquely high degree of open-source accessibility, including self-collected data not previously available in the research community.
read the caption
Table 2: Open-Source Landscape of Video Generation Models. We have fully open-sourced the model, technological solution, and data, making it, to the best of our knowledge, the video generation solution with the highest degree of open-source accessibility available. Notably, Our dataset is self-collected and has not previously appeared in the community.
| Models | I2V-S | I2V-B | CM | SC | BC | TF | MS | DD | AQ | IQ |
| I2VGen-XL[79] | 96.08 | 94.67 | 12.95 | 95.76 | 97.67 | 97.40 | 98.27 | 24.80 | 65.26 | 69.21 |
| Animate-Anything[34] | 98.13 | 96.05 | 10.64 | 98.18 | 97.46 | 98.15 | 98.52 | 2.52 | 66.42 | 71.89 |
| Nvidia-Cosmos[1] | 95.10 | 95.30 | 37.56 | 91.59 | 94.43 | 96.20 | 98.82 | 83.90 | 58.39 | 70.35 |
| DropletVideo (Ours) | 98.51 | 96.74 | 37.93 | 96.54 | 97.02 | 97.68 | 98.94 | 27.97 | 60.94 | 70.35 |
🔼 This table compares the performance of DropletVideo against other state-of-the-art image-to-video models across various metrics. The metrics evaluate different aspects of video generation quality, including the accuracy of subject and background representation (I2V Subject and I2V Background), the smoothness of motion (Motion Smoothness), the effectiveness of camera movements (Camera Motion), the consistency of subjects and backgrounds over time (Subject Consistency and Background Consistency), the stability of the temporal aspect (Temporal Flickering), the dynamic range of the generated videos (Dynamic Degree), and the overall aesthetic and image quality (Aesthetic Quality and Image Quality). DropletVideo shows superior performance in I2V Subject, I2V Background, Motion Smoothness and Camera Motion, while achieving comparable results to the other models in the remaining metrics. This indicates that DropletVideo excels in generating videos with accurate subjects and backgrounds, smooth motion, and effective camera work.
read the caption
Table 3: Comparison of DropletVideo with state-of-the-art image-to-video models. DropletVideo outperforms other models in I2V Subject, I2V Background, Motion Smoothness and Camera Motion. Meanwhile, DropletVideo remain at the current mainstream level for other metrics. In this table, I2V-S stands for I2V Subject, I2V-B stands for I2V Background, CM stands for Camera Motion, SC stands for Subject Consistency, BC stands for Background Consistency, TF stands for Temporal Flickering, MS stands for Motion Smoothness, DD stands for Dynamic Degree, AQ stands for Aesthetic Quality, IQ stands for Imaging Quality.
Full paper#