TL;DR#
Audio-Visual Speech Recognition (AVSR) improves speech recognition, especially in noisy conditions, by utilizing both audio and video. Large Language Models (LLMs) have improved this task, but integrating speech representations into LLMs increases computational costs. Current solutions compress speech data before feeding it to LLMs, which degrades performance with higher compression. This creates a trade-off between efficiency and accuracy.
This paper introduces Llama-MTSK for AVSR, a Matryoshka-based Multimodal LLM that flexibly adapts token allocation based on computational constraints while preserving performance. It encodes audio-visual data at multiple granularities, eliminating the need for separate models for different compression levels. Three LoRA-based Matryoshka strategies are introduced for efficient fine-tuning. Evaluations show Llama-MTSK achieves state-of-the-art results matching or surpassing models trained independently at fixed compression levels.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it introduces a novel approach to AVSR that balances accuracy and computational efficiency, making it applicable to resource-constrained scenarios. It leverages MRL, and provides a flexible way to tune the model based on the tasks/datasets, leading to new research directions in multimodal LLMs. This approach paves the way for deploying more sophisticated AVSR systems in real-world applications.
Visual Insights#

🔼 This figure illustrates the training and inference stages of the Llama-MTSK model. During training (left panel), audio and visual data are processed by pre-trained encoders. The resulting tokens are then compressed to multiple scales (different levels of granularity) and projected into a shared embedding space. These multi-scale audio-visual tokens are fed into a Llama-based large language model (LLM), which is fine-tuned using one of three proposed LoRA (Low-Rank Adaptation) strategies based on the Matryoshka Representation Learning principle. The right panel shows the inference stage. Llama-MTSK allows dynamic adjustment of the audio-visual compression rate at inference time based on computational resource constraints. Only the projector and LoRA modules corresponding to the chosen compression rate are activated, maintaining high efficiency. The color-coding in the figure indicates whether the parameters were trained or kept frozen.
read the caption
Figure 1: Training and inference stages for Llama-MTSK. (Left) During training, we produce audio-visual tokens via pre-trained encoders, followed by specific-scale compression and projection modules. Then, we feed the concatenated audio-visual tokens at multiple scales to the pre-trained Llama-based LLM, which is adapted through one of the three proposed LoRA approaches following the Matryoshka Representation Learning principle. (Right) At inference, Llama-MTSK allows us to change on-the-fly the audio-visual compression rates for each input data conditioned on our specific requirements using the same model architecture and weights, enabling high flexibility. Furthermore, only one projector and one LoRA module are activated at inference (in this figure, those associated with the audio and video compression rates equal to 3333), guaranteeing model’s scalability in training and no extra cost in inference. and represent whether the parameters are trained or kept frozen, respectively.
| Method | Compression Rates (A,V) | |||
| (4,2) | (4,5) | (16,2) | (16,5) | |
| LRS3 Dataset | ||||
| Llama-AVSR† | 2.4 | 2.8 | 3.3 | 4.1 |
| \hdashline
Llama
| 2.6 | 2.7 | 3.7 | 4.1 |
| Llama
| 2.3 | 2.2 | 3.3 | 3.6 |
| Llama
| 2.4 | 2.4 | 3.2 | 3.5 |
| LRS2 Dataset | ||||
| Llama-AVSR | 4.1 | 4.5 | 5.3 | 8.1 |
| \hdashline
Llama
| 4.8 | 5.9 | 6.4 | 8.9 |
| Llama
| 3.4 | 4.7 | 4.8 | 6.4 |
| Llama
| 3.6 | 4.8 | 6.1 | 9.0 |
🔼 Table 1 presents a comparison of the performance of four different audio-visual speech recognition (AVSR) models on two benchmark datasets, LRS2 and LRS3. The models compared are Llama-AVSR (a state-of-the-art model that trains separate models for different audio-visual compression rates) and three variations of a novel Matryoshka-based multimodal LLM called Llama-MTSK (MS, SS, and MSS). The table shows Word Error Rates (WER) for each model across various combinations of audio and video compression rates. This allows for an evaluation of the tradeoff between computational efficiency (higher compression rates) and recognition accuracy. The key point of comparison is to show that the single Llama-MTSK model can achieve similar or better performance than the four separate Llama-AVSR models, demonstrating its efficiency and flexibility.
read the caption
Table 1: Comparison between Llama-AVSR and our proposed Llama MS, SS, and MSS approaches on LRS2 and LRS3 benchmarks. †Llama-AVSR trains 4444 independent models tailored to each configuration of audio-video compression rates.
In-depth insights#
MTSK for AVSR#
MTSK for AVSR (Audio-Visual Speech Recognition) represents a paradigm shift by incorporating Matryoshka Representation Learning to enhance adaptability in AVSR systems. This approach allows a single model to function effectively across various computational constraints and accuracy needs, eliminating the need for training multiple models for different compression levels. By encoding audio-visual representations at multiple granularities, Llama-MTSK maximizes the efficiency-performance trade-off, making it a versatile solution for deployment in diverse environments.
Elastic Inference#
The concept of Elastic Inference revolves around dynamically adjusting the computational resources allocated to a machine learning model at inference time. This adaptability is crucial in real-world deployments where workloads fluctuate, and fixed resource allocations lead to inefficiency. Elastic Inference aims to optimize the trade-off between performance and cost, scaling resources up during periods of high demand to maintain low latency and scaling down during periods of low demand to minimize expenses. Techniques for achieving elastic inference include dynamically adjusting model size (e.g., through pruning or quantization), batch size, or the number of active model replicas. The goal is to enable models to efficiently serve diverse and changing request patterns without compromising service level agreements (SLAs) or incurring unnecessary costs. This requires careful monitoring of system metrics and predictive scaling mechanisms to anticipate workload changes.
LoRA Fine-Tuning#
LoRA (Low-Rank Adaptation) is a parameter-efficient fine-tuning technique that freezes the pre-trained LLM weights and introduces trainable rank-decomposition matrices to adapt the model to downstream tasks. This significantly reduces the number of trainable parameters, making it computationally cheaper and faster compared to full fine-tuning. LoRA’s modularity allows it to be easily integrated and removed without altering the original LLM. In the context of this paper, LoRA is utilized to adapt the LLM to the multimodal audio-visual speech recognition task, enabling efficient learning of the relationship between audio-visual features and text. The authors propose three LoRA-based strategies to efficiently fine-tune the LLM, each employing distinct methods using global and scale-specific LoRA modules. Extensive evaluations show that LoRA enables achieving state-of-the-art results while significantly reducing computational costs.
Avg Pool vs Stack#
Average Pooling vs. Stacking are two distinct methods for compressing audio and visual tokens before feeding them into a Large Language Model (LLM) for tasks like Audio-Visual Speech Recognition (AVSR). Average pooling reduces the sequence length by averaging consecutive tokens, essentially downsampling the representation. While computationally efficient, it can lead to information loss, especially with high compression ratios, potentially degrading performance. Stacking, on the other hand, concatenates consecutive tokens along the feature dimension. This maintains the original sequence length but increases the dimensionality of each token, enabling the LLM to potentially access finer-grained information. However, stacking can significantly increase the computational cost due to the larger feature dimension, requiring careful management to balance performance and efficiency. The choice between these techniques depends on the specific task, the desired trade-off between computational cost and accuracy, and the architecture of the LLM.
MTSK Limitations#
Memory Requirements: Processing multiple sequences at various granularities during training increases the LLM’s memory footprint, demanding careful selection of compression rates to balance feasibility and performance. LoRA vs Other Methods: The study primarily focuses on LoRA for parameter-efficient fine-tuning, but other methods like adapter-tuning and advanced LoRA techniques could be explored to extend the method’s capabilities, offering avenues for further research.
More visual insights#
More on figures

🔼 This figure illustrates three different approaches for adapting a Large Language Model (LLM) using Low-Rank Adaptation (LoRA) within a Matryoshka framework. The Matryoshka concept involves processing audio-visual data at multiple scales (granularities) simultaneously. The three methods are: 1. Multi-Scale (MS) LoRA: A single global LoRA module is used to fine-tune the LLM’s parameters across all scales. This shares learned knowledge efficiently. 2. Specific-Scale (SS) LoRA: Separate LoRA modules are trained for each scale, allowing for specialized learning at each level of detail. This may improve accuracy but at higher computational cost. 3. Multi-Specific-Scale (MSS) LoRA: This approach combines MS and SS by utilizing both a global and scale-specific LoRA modules. This offers a potential balance between efficiency and performance. The figure visually depicts the architecture of each approach and how it would be incorporated into the system for processing audio-visual data.
read the caption
Figure 2: Our three proposed LoRA Matryoshka (LoRA ) approaches. Multi-Scale (MS) LoRA uses a shared global LoRA module for all the audio-visual token scales (in this specific example there are three scales) to fine-tune the pre-trained matrices of the LLM. The Specific-Scale (SS) variant defines a LoRA module tailored to each scale, learning and specializing to a specific scale. The third approach, Multi-Specific-Scale (MSS), combines MS and SS to support both global and specific-scale LoRAs. The global LoRA is responsible to capture relationships that can be shared among different-scale tokens, while specific-scale LoRAs learn tokens based on the specific scale.

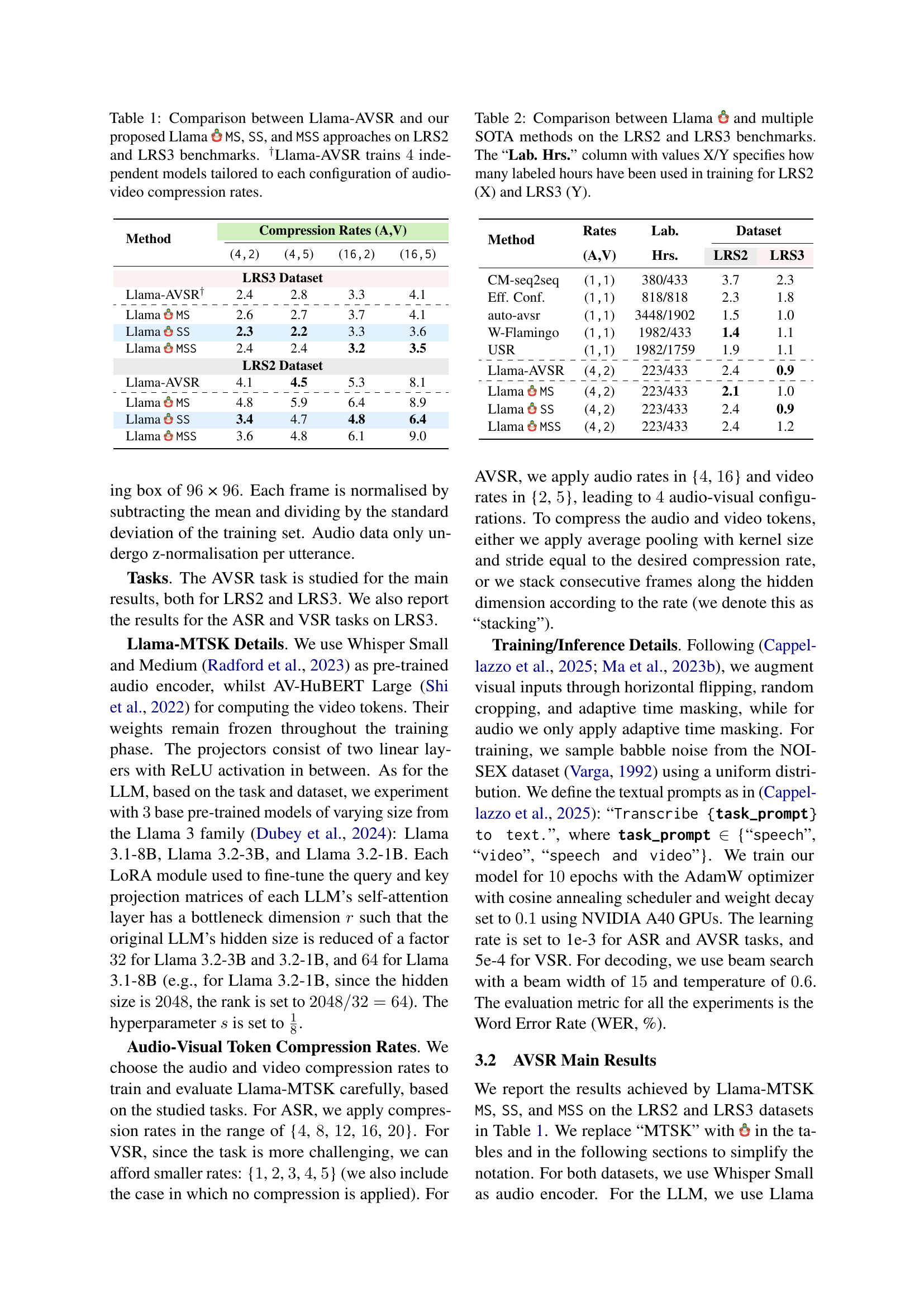
🔼 This figure displays the Word Error Rate (WER) results for the Automatic Speech Recognition (ASR) task, comparing two different compression methods: average pooling and stacking. The results are shown across a range of compression rates. The left panel shows WER for average pooling and the right panel for stacking. Both methods utilize Whisper Small as the audio encoder and Llama 3.2-1B as the Large Language Model (LLM). This visualization helps to assess the impact of different compression methods and rates on the overall performance of the ASR system.
read the caption
Figure 3: WER results for the average pooling (left) and stacking (right) compression methods for the ASR task. We use Whisper Small as audio encoder and Llama 3.2-1B as LLM.

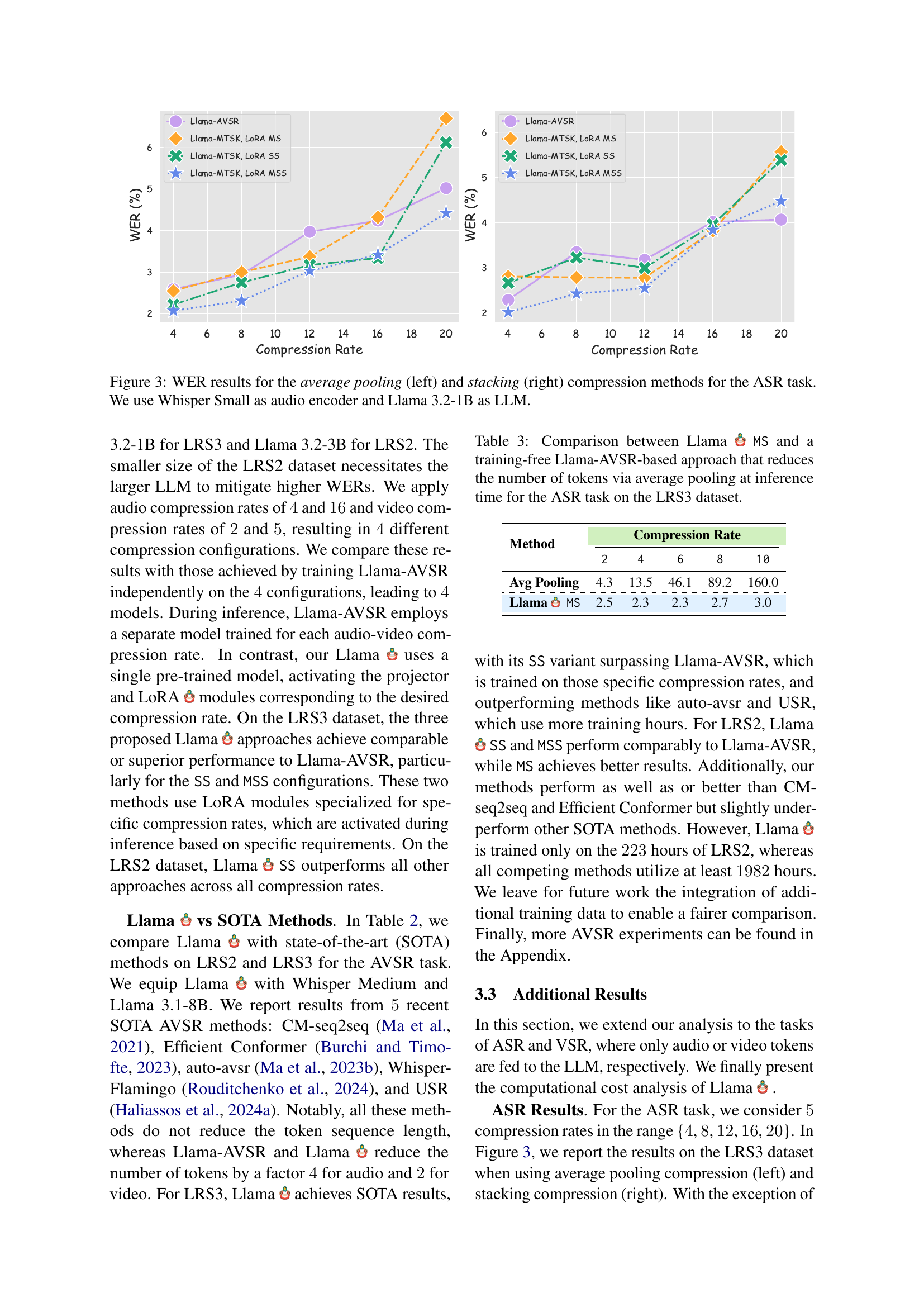
🔼 Figure 4 presents the Word Error Rate (WER) results for the Visual Speech Recognition (VSR) task using two different compression methods: average pooling (left panel) and stacking (right panel). The results are shown for various compression rates. The experiment used AVHuBERT Large as the video encoder and Llama 3.2-3B as the Large Language Model (LLM). This figure showcases the impact of different compression strategies and rates on VSR performance, highlighting the trade-off between computational efficiency and accuracy.
read the caption
Figure 4: WER results for the average pooling (left) and stacking (right) compression methods for the VSR task. We use AVHuBERT Large as video encoder and Llama 3.2-3B as LLM.

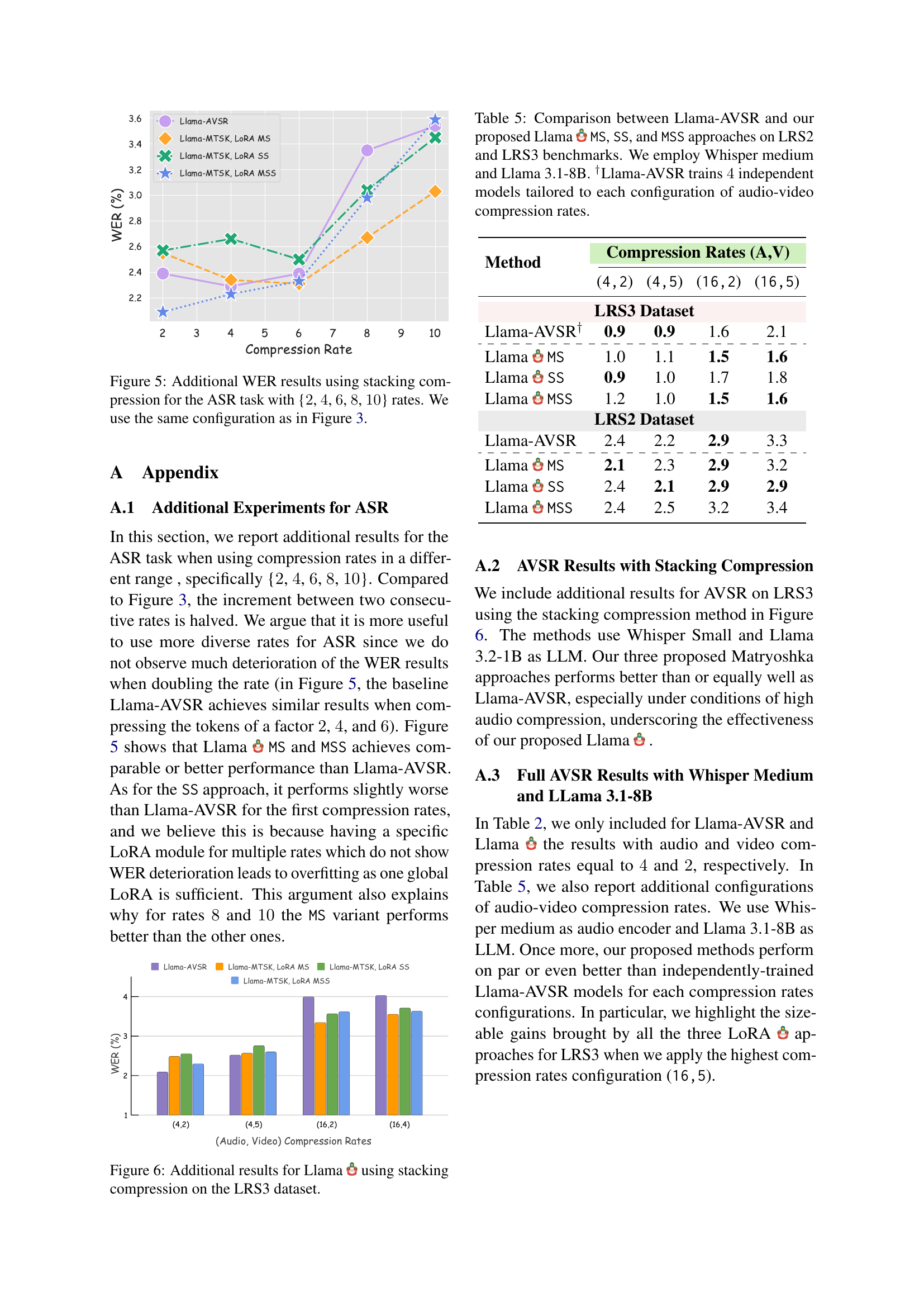
🔼 Figure 5 presents additional Word Error Rate (WER) results for the Automatic Speech Recognition (ASR) task. Unlike Figure 3, which used average pooling for compression, this figure shows results obtained using a stacking compression method. The experiment explores a range of compression rates: {2, 4, 6, 8, 10}. The goal is to demonstrate how different compression techniques and rates affect the performance of Llama-MTSK (the proposed model) in comparison to the Llama-AVSR baseline model. The figure helps to assess the model’s robustness and efficiency across varying levels of compression.
read the caption
Figure 5: Additional WER results using stacking compression for the ASR task with {2222, 4444, 6666, 8888, 10101010} rates. We use the same configuration as in Figure 3.

🔼 Figure 6 presents supplementary results for the Audio-Visual Speech Recognition (AVSR) task using the LRS3 dataset. It specifically focuses on the performance of the Llama-based models (Llama MS, Llama SS, and Llama MSS) when employing a stacking compression method. The figure compares these models against the Llama-AVSR baseline, which trains separate models for each audio-visual compression rate combination. This allows for a direct comparison of the performance and efficiency between the Matryoshka-based approach (capable of handling various compression ratios within a single model) and the conventional method (requiring separate models for each configuration). The x-axis represents different audio-visual compression rate combinations, and the y-axis shows the Word Error Rate (WER), a common metric to assess the accuracy of speech recognition systems.
read the caption
Figure 6: Additional results for Llama using stacking compression on the LRS3 dataset.
More on tables
| Method | Rates | Lab. | Dataset | |
| (A,V) | Hrs. | LRS2 | LRS3 | |
| CM-seq2seq | (1,1) | 380/433 | 3.7 | 2.3 |
| Eff. Conf. | (1,1) | 818/818 | 2.3 | 1.8 |
| auto-avsr | (1,1) | 3448/1902 | 1.5 | 1.0 |
| W-Flamingo | (1,1) | 1982/433 | 1.4 | 1.1 |
| USR | (1,1) | 1982/1759 | 1.9 | 1.1 |
| \hdashline Llama-AVSR | (4,2) | 223/433 | 2.4 | 0.9 |
| \hdashline
Llama
| (4,2) | 223/433 | 2.1 | 1.0 |
| Llama
| (4,2) | 223/433 | 2.4 | 0.9 |
| Llama
| (4,2) | 223/433 | 2.4 | 1.2 |
🔼 Table 2 presents a comparison of the performance of the Llama model against several state-of-the-art (SOTA) methods. The comparison is done using two large-scale audio-visual speech recognition (AVSR) datasets: LRS2 and LRS3. The table shows the word error rate (WER) achieved by each model on each dataset. A key aspect of the comparison is the amount of labeled data used to train each model, which is indicated in the ‘Lab. Hrs.’ column. The values X/Y in this column represent the number of labeled hours used for training on the LRS2 and LRS3 datasets, respectively. This allows for a nuanced comparison, considering the potential impact of training data size on model performance.
read the caption
Table 2: Comparison between Llama and multiple SOTA methods on the LRS2 and LRS3 benchmarks. The “Lab. Hrs.” column with values X/Y specifies how many labeled hours have been used in training for LRS2 (X) and LRS3 (Y).
| Method | Compression Rate | ||||
| 2 | 4 | 6 | 8 | 10 | |
| Avg Pooling | 4.3 | 13.5 | 46.1 | 89.2 | 160.0 |
| \hdashline
Llama
| 2.5 | 2.3 | 2.3 | 2.7 | 3.0 |
🔼 This table compares the performance of Llama MS, a Matryoshka-based Multimodal LLM for AVSR, against a baseline approach. The baseline uses a standard Llama-AVSR model but reduces the number of input tokens by applying average pooling during inference. This comparison is performed for the ASR (Automatic Speech Recognition) task specifically on the LRS3 dataset, across various compression rates. The table helps illustrate the performance gains of Llama MS in terms of Word Error Rate (WER) when compared to a simple token reduction strategy on the same pretrained LLM.
read the caption
Table 3: Comparison between Llama MS and a training-free Llama-AVSR-based approach that reduces the number of tokens via average pooling at inference time for the ASR task on the LRS3 dataset.
| (A,V) Rates | # Tokens | TFLOPs |
| (1,1) | 757 | 11.40 |
| \hdashline (4,2) | 257 | 3.87 |
| (4,5) | 182 | 2.74 |
| (16,2) | 163 | 2.46 |
| (16,5) | 88 | 1.33 |
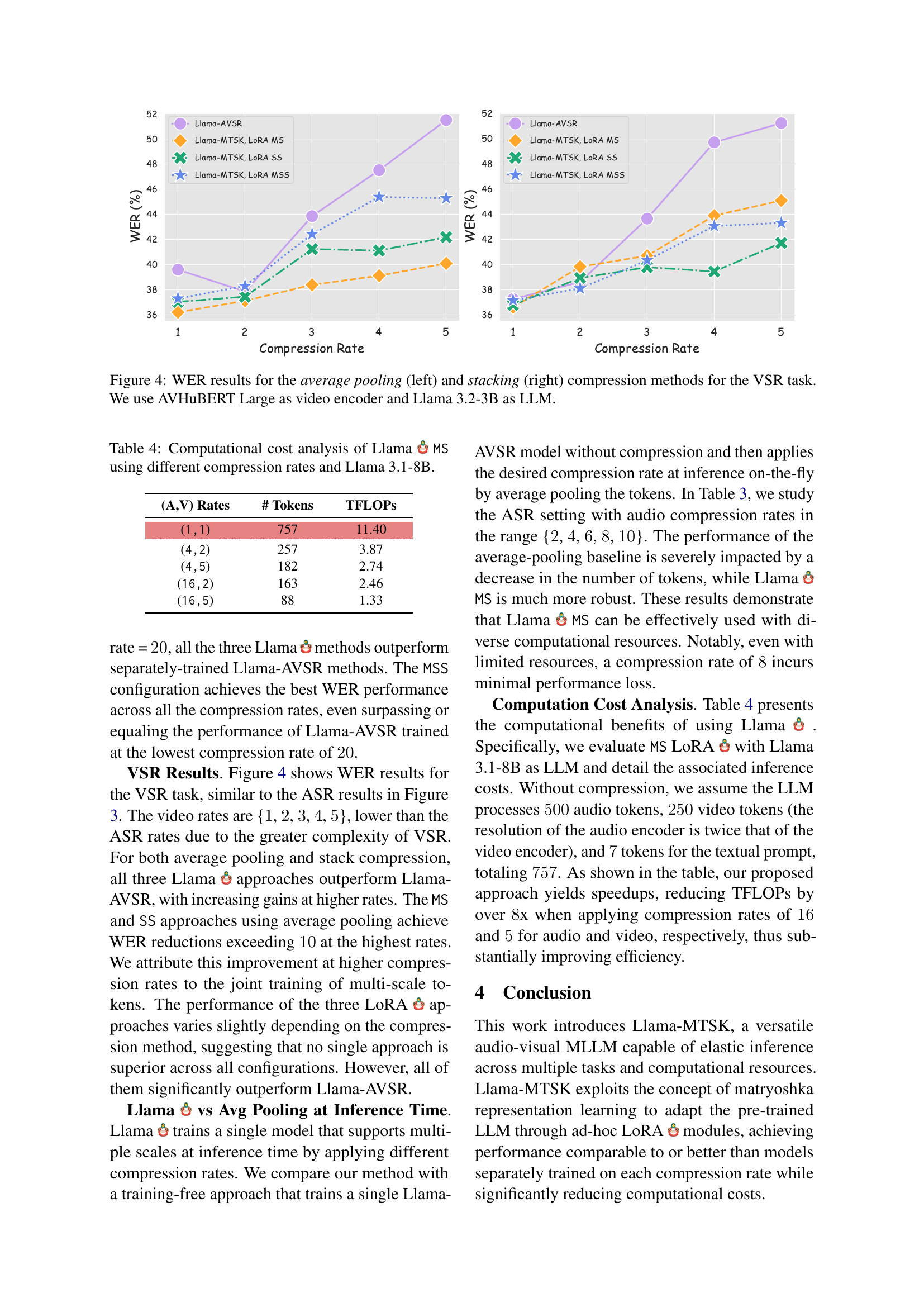
🔼 This table presents a computational cost analysis of the Llama MS model, focusing on different audio-visual compression rates while using the Llama 3.1-8B language model. It details the number of tokens processed and the total floating-point operations (TFLOPS) required for inference at various compression levels. This analysis demonstrates the computational efficiency gains achieved by employing different compression rates in Llama MS.
read the caption
Table 4: Computational cost analysis of Llama MS using different compression rates and Llama 3.1-8B.
| Method | Compression Rates (A,V) | |||
| (4,2) | (4,5) | (16,2) | (16,5) | |
| LRS3 Dataset | ||||
| Llama-AVSR† | 0.9 | 0.9 | 1.6 | 2.1 |
| \hdashline
Llama
| 1.0 | 1.1 | 1.5 | 1.6 |
| Llama
| 0.9 | 1.0 | 1.7 | 1.8 |
| Llama
| 1.2 | 1.0 | 1.5 | 1.6 |
| LRS2 Dataset | ||||
| Llama-AVSR | 2.4 | 2.2 | 2.9 | 3.3 |
| \hdashline
Llama
| 2.1 | 2.3 | 2.9 | 3.2 |
| Llama
| 2.4 | 2.1 | 2.9 | 2.9 |
| Llama
| 2.4 | 2.5 | 3.2 | 3.4 |
🔼 Table 5 presents a comparison of the performance of four different models on the LRS2 and LRS3 speech recognition benchmarks. The models compared are: Llama-AVSR (a baseline model that trains four separate models, each optimized for a specific combination of audio and video compression rates), and three variations of the Llama-MTSK model (Llama MS, Llama SS, and Llama MSS). Llama-MTSK is a novel approach that uses a single model capable of adapting to various compression rates. The table shows Word Error Rates (WER) for each model and each compression rate combination, allowing for a direct comparison of the performance and efficiency of the different approaches.
read the caption
Table 5: Comparison between Llama-AVSR and our proposed Llama MS, SS, and MSS approaches on LRS2 and LRS3 benchmarks. We employ Whisper medium and Llama 3.1-8B. †Llama-AVSR trains 4444 independent models tailored to each configuration of audio-video compression rates.
Full paper#