TL;DR#
Traditional reasoning segmentation methods are limited by supervised fine-tuning, lacking generalization and explicit reasoning. Seg-Zero addresses these limitations with a novel framework that uses cognitive reinforcement to achieve remarkable generalizability and chain-of-thought reasoning. It introduces a decoupled architecture comprising reasoning and segmentation models, interpreting user intentions and generating positional prompts for precise mask generation. This approach overcomes the constraints of existing methods, providing a more adaptable solution.
Seg-Zero employs pure reinforcement learning, specifically GRPO, to fine-tune the reasoning model without explicit reasoning data. A sophisticated reward mechanism integrates format and accuracy rewards, guiding optimization. The model achieves robust zero-shot generalization and exhibits emergent test-time reasoning capabilities. Experiments demonstrate that Seg-Zero surpasses prior models, highlighting its ability to generalize while presenting an explicit reasoning process. This framework advances reasoning segmentation, offering a robust and adaptable approach for complex visual tasks.
Key Takeaways#
Why does it matter?#
This paper introduces a novel approach to reasoning segmentation, enhancing model generalization and reasoning through reinforcement learning. It offers valuable insights for fine-tuning models using RL and opens new avenues for exploring cognitive capabilities in visual understanding tasks, which can inspire future research in AI and computer vision by addressing the limitations of current supervised methods, offering a more robust and adaptable solution for complex segmentation tasks. This approach promises significant advancements in areas requiring detailed visual analysis.
Visual Insights#

🔼 Seg-Zero, a novel reasoning segmentation model, generates a reasoning chain before producing the final segmentation mask. Unlike traditional supervised fine-tuning (SFT) methods, Seg-Zero uses a pure reinforcement learning (RL) approach, learning the reasoning process from scratch. This RL-based method shows significant improvement in both in-domain and out-of-domain segmentation tasks compared to SFT, and the explicit reasoning chain further enhances its performance.
read the caption
Figure 1: Seg-Zero generates a reasoning chain before producing the final segmentation mask. It utilizes a pure reinforcement learning (RL) strategy, learning the reasoning process from zero. In comparison to supervised fine-tuning (SFT), the RL-based model demonstrates superior performance on both in-domain and out-of-domain data, and the integration of reasoning chain further enhances its effectiveness.
| Model | Type | CoT | RefCOCOg | ReasonSeg |
|---|---|---|---|---|
| Baseline | 70.4 | 47.6 | ||
| Seg-Zero | SFT | × | 70.8 | 44.9 |
| Seg-Zero | RL | × | 73.2 | 51.3 |
| Seg-Zero | RL | ✓ | 73.6 | 53.8 |
🔼 This table compares the performance of different training methods on a semantic segmentation task. The methods compared include supervised fine-tuning (SFT) and reinforcement learning (RL), with and without chain-of-thought (CoT) prompting. The results are shown for both in-domain (RefCOCOg) and out-of-domain (ReasonSeg) datasets. The table highlights that the model trained with RL and CoT achieves the best performance across both datasets, demonstrating the effectiveness of this approach for improving generalization capabilities in reasoning segmentation.
read the caption
Table 1: Segmentation task comparison. Model trained with RL + CoT thinking reward achieves best performance on in-domain and OOD data.
In-depth insights#
RL for Reasoning#
Reinforcement Learning (RL) offers a promising avenue for enhancing reasoning capabilities in AI systems. Unlike supervised methods that rely on explicit reasoning data, RL enables models to learn reasoning strategies through trial and error, guided by reward signals. This approach allows for the emergence of novel reasoning chains and adaptation to complex, unseen scenarios. RL-based reasoning can potentially overcome limitations of traditional methods, such as catastrophic forgetting and poor generalization. By carefully designing reward functions that incentivize accurate and coherent reasoning, RL can unlock more robust and flexible AI systems capable of tackling intricate tasks requiring logical inference and problem-solving. Pure RL can enable a model to learn reasoning from zero, by training MLLM to generate reasoning process and producing positional prompts.
Seg-Zero Design#
While the provided document doesn’t have a section explicitly titled “Seg-Zero Design,” the overall architecture and methodology provide ample grounds for insightful analysis. The core idea revolves around a decoupled architecture, separating reasoning and segmentation. This is a departure from end-to-end fine-tuning, allowing for targeted optimization. Reinforcement learning (RL) is used to train the reasoning module without explicit reasoning data which forces emergent reasoning. The design cleverly uses a reward mechanism encompassing format and accuracy. The structured prompts are vital, guiding the LLM towards creating a chain-of-thought before segmentation, thus, improving overall performance. The choice of the segmentation model (SAM2) due to its efficient inference speed is also notable. Ablation studies validate design choices, such as bbox and point prompts, highlighting their complementary roles in precise localization. The success of strict format rewards for OOD generalization underscores the importance of structured outputs. The RL approach to training shows it’s a feasible method and performs better.
Emergent Abilities#
Emergent abilities in AI models, particularly large language models (LLMs), refer to capabilities that arise unexpectedly as the model’s size and complexity increase. These abilities are not explicitly programmed or designed into the model but rather emerge as a result of the model’s learning process and its capacity to generalize from the vast amounts of data it has been trained on. A key characteristic is their unpredictability; they often appear suddenly and are not easily extrapolated from the model’s performance at smaller scales. Another aspect is their context-dependence, in which an ability is shown only in certain task configurations or with the right prompt engineering. Understanding these emergent abilities is crucial for several reasons. Practically, they can lead to the development of AI systems capable of performing tasks previously thought impossible. Theoretically, they offer insights into the nature of intelligence and learning, potentially guiding the design of more effective AI architectures and training methods.
Decoupled Models#
In the realm of machine learning, the concept of decoupled models presents a paradigm shift from traditional monolithic architectures. This approach advocates for breaking down complex tasks into smaller, more manageable sub-problems, each addressed by a dedicated model. The primary advantage lies in enhanced modularity; individual components can be developed, tested, and optimized independently, fostering faster iteration cycles and improved maintainability. Furthermore, decoupled models often exhibit greater flexibility, allowing for dynamic reconfiguration and adaptation to evolving task requirements. Resource allocation can be tailored to each component’s needs, potentially leading to more efficient utilization of computational resources. However, the design of effective decoupling strategies requires careful consideration of task dependencies and communication interfaces between models. The coordination and integration of outputs from multiple models introduce new challenges, demanding sophisticated fusion mechanisms to ensure coherent and consistent overall performance. Moreover, the increased complexity of managing multiple models can add overhead and necessitate robust monitoring and orchestration tools. Despite these challenges, the potential benefits of decoupled models—namely, increased modularity, flexibility, and resource efficiency—make them a compelling architectural choice for a wide range of applications.
Reward Functions#
Reward functions are critical in reinforcement learning, shaping the model’s learning trajectory. A good reward function should align with the task’s objective. The design is often manual, requiring domain expertise and iteration to avoid unintended behaviors. Rewards can be dense (frequent feedback) or sparse (delayed feedback). They may incorporate multiple components (e.g., accuracy, format). A sophisticated reward function can promote desired attributes. For reasoning-based tasks, it could reward CoT or intermediate steps. A strict reward, compared to a soft reward, will greatly improve model performance gain on OOD data. It is more challenging to sample formats that precisely match the strict criteria. However, as the training step increases, the model with strict format reward will tend to output a longer response.
More visual insights#
More on figures

🔼 This figure illustrates the reinforcement learning process used to train the Seg-Zero model. The model generates multiple segmentation mask proposals, each accompanied by a reasoning chain. The reward function then assesses each proposal based on factors such as format correctness and accuracy (Intersection over Union or IoU). The model learns to generate higher-quality segmentation masks by optimizing for these reward signals. The example shows three different proposals and their associated rewards.
read the caption
Figure 2: Illustration of our RL training process. In this case, the model generates three samples by itself, calculates the rewards, and optimizes towards samples that achieve higher rewards.

🔼 Seg-Zero uses a two-stage approach for reasoning-based image segmentation. First, a multi-modal large language model (MLLM) acts as a reasoning model. It receives an image and a user prompt or question, then generates a reasoning chain that helps focus on the relevant object within the image and produces segmentation prompts. These prompts include bounding box coordinates and pixel-level point locations that pinpoint the target object’s precise boundaries. Second, a segmentation model takes these prompts as input and outputs a pixel-wise mask representing the segmented object. The architecture demonstrates how reasoning and segmentation tasks can be decoupled, leveraging the strengths of large language models and specialized segmentation models for effective reasoning segmentation.
read the caption
Figure 3: Seg-Zero includes a reasoning model and a segmentation model. The reasoning model is a MLLM that generates a reasoning chain and provides segmentation prompts. Subsequently the segmentation model produces pixel-wise mask.

🔼 This figure details the user prompt used within the Seg-Zero model. The prompt instructs the model to locate a specific object (’{Question}’) within an image, providing the bounding box coordinates and two points for precise localization. The model is further guided to explain its reasoning process in detail (using
and tags), concluding with the precise object coordinates (usingand tags). The ‘{Question}’ placeholder is replaced with the actual object description, denoted as ‘T’, during both training and inference phases. This structured prompt ensures the model generates detailed reasoning steps and accurately outputs the object location.read the caption
Figure 4: User prompt for Seg-Zero. ‘{Question}’ is replaced with object description 𝐓𝐓\mathbf{T}bold_T in the training and inference.

🔼 The figure compares the performance of models trained using supervised fine-tuning (SFT) and reinforcement learning (RL) on visual question answering (VQA) tasks. It shows that SFT leads to catastrophic forgetting, where the model loses its ability to perform well on general VQA tasks after fine-tuning on a specific task. In contrast, the RL approach maintains general VQA capabilities, indicating its superior robustness and generalization ability. The chart likely displays the accuracy or other relevant metrics on different VQA datasets for both SFT and RL-trained models, illustrating the difference in performance.
read the caption
Figure 5: Visual QA task comparison. SFT suffers catastrophic forgetting, while RL preserves general Visual QA ability.

🔼 Figure 6 showcases qualitative results from the ReasonSeg dataset. It displays several examples of user queries and how the Seg-Zero model utilizes its reasoning chain to interpret complex instructions and accurately segment the target objects within images. The figure demonstrates the model’s ability to reason through nuanced queries, handle multiple objects within a single query, and produce accurate segmentation masks despite ambiguity or complexity in the instructions.
read the caption
Figure 6: Qualitative Results on ReasonSeg [17]. The reason chain helps analyze user instructions and segment the correct objects.

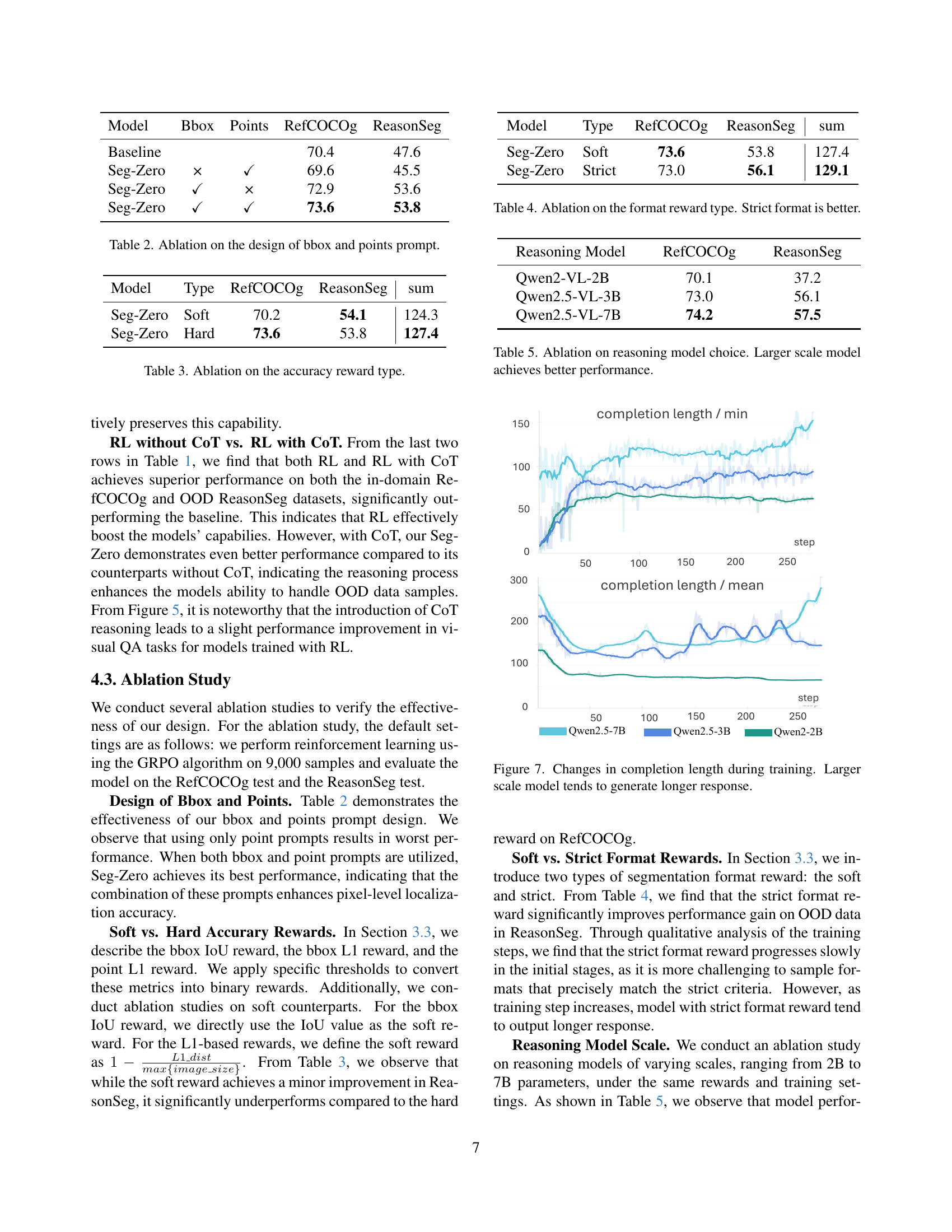
🔼 This figure displays the change in the average and minimum length of model responses during training. It illustrates how the length of generated text varies as the model learns, and particularly how model size affects response length. Larger models (with more parameters) show a trend towards generating longer responses, particularly after the initial training stages. This may reflect increased reasoning capabilities or the increased complexity of the larger model’s internal representations.
read the caption
Figure 7: Changes in completion length during training. Larger scale model tends to generate longer response.

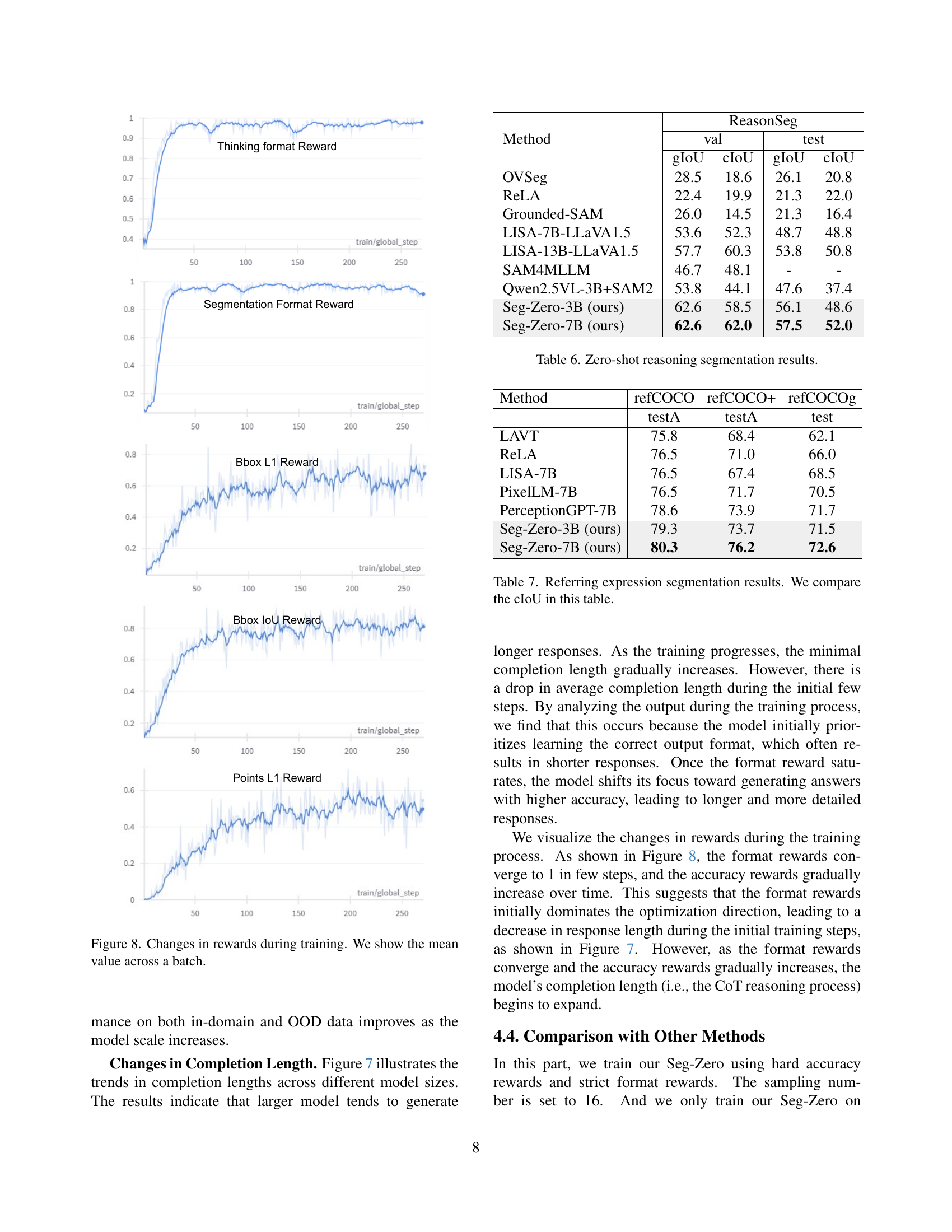
🔼 Figure 8 presents the mean reward values across batches during the training process of the Seg-Zero model. The graph displays the trends of reward values over training iterations, illustrating the convergence of the different rewards used in reinforcement learning. Specifically, it shows the trends for the ‘Thinking Format Reward’, ‘Segmentation Format Reward’, ‘Bbox L1 Reward’, and ‘Points L1 Reward’. The changes in these reward values over time reflect how effectively the model learns to follow the format guidelines and achieve high accuracy in its segmentation tasks.
read the caption
Figure 8: Changes in rewards during training. We show the mean value across a batch.
More on tables
| Model | Bbox | Points | RefCOCOg | ReasonSeg |
|---|---|---|---|---|
| Baseline | 70.4 | 47.6 | ||
| Seg-Zero | × | ✓ | 69.6 | 45.5 |
| Seg-Zero | ✓ | × | 72.9 | 53.6 |
| Seg-Zero | ✓ | ✓ | 73.6 | 53.8 |
🔼 This table presents the results of ablation studies on the design of prompts used in the Seg-Zero model. Specifically, it investigates the impact of using only bounding boxes, only points, or both bounding boxes and points as input prompts for the segmentation task. The performance is evaluated on the RefCOCOg and ReasonSeg datasets, using gIoU as the metric. This helps determine the optimal prompt design for achieving best segmentation accuracy.
read the caption
Table 2: Ablation on the design of bbox and points prompt.
| Model | Type | RefCOCOg | ReasonSeg | sum |
|---|---|---|---|---|
| Seg-Zero | Soft | 70.2 | 54.1 | 124.3 |
| Seg-Zero | Hard | 73.6 | 53.8 | 127.4 |
🔼 This table presents the results of an ablation study on the accuracy reward type used in the Seg-Zero model training. It shows how different accuracy reward designs affect the model’s performance on both in-domain (RefCOCOg) and out-of-domain (ReasonSeg) datasets. The results demonstrate the impact of various accuracy reward types on the final segmentation results.
read the caption
Table 3: Ablation on the accuracy reward type.
| Model | Type | RefCOCOg | ReasonSeg | sum |
|---|---|---|---|---|
| Seg-Zero | Soft | 73.6 | 53.8 | 127.4 |
| Seg-Zero | Strict | 73.0 | 56.1 | 129.1 |
🔼 This table presents the ablation study on the format reward type used in the Seg-Zero model training. It compares the performance of the model when using a ‘soft’ format reward (allowing some flexibility in the output format) versus a ‘strict’ format reward (requiring a precise output format). The results show that the ‘strict’ format reward leads to better overall performance, suggesting that enforcing a structured reasoning process is beneficial for the model’s accuracy.
read the caption
Table 4: Ablation on the format reward type. Strict format is better.
| Reasoning Model | RefCOCOg | ReasonSeg |
|---|---|---|
| Qwen2-VL-2B | 70.1 | 37.2 |
| Qwen2.5-VL-3B | 73.0 | 56.1 |
| Qwen2.5-VL-7B | 74.2 | 57.5 |
🔼 This table presents the results of an ablation study investigating the impact of different reasoning model sizes on the performance of the Seg-Zero model. The study compared three variants of the Qwen model (2B, 3B, and 7B parameters), evaluating their performance on the RefCOCOg and ReasonSeg datasets using the cIoU metric. The results demonstrate that using a larger-scale model consistently improves the overall performance, highlighting the importance of model scale in achieving better reasoning and segmentation capabilities.
read the caption
Table 5: Ablation on reasoning model choice. Larger scale model achieves better performance.
| Method | ReasonSeg | |||
|---|---|---|---|---|
| val | test | |||
| gIoU | cIoU | gIoU | cIoU | |
| OVSeg | 28.5 | 18.6 | 26.1 | 20.8 |
| ReLA | 22.4 | 19.9 | 21.3 | 22.0 |
| Grounded-SAM | 26.0 | 14.5 | 21.3 | 16.4 |
| LISA-7B-LLaVA1.5 | 53.6 | 52.3 | 48.7 | 48.8 |
| LISA-13B-LLaVA1.5 | 57.7 | 60.3 | 53.8 | 50.8 |
| SAM4MLLM | 46.7 | 48.1 | - | - |
| Qwen2.5VL-3B+SAM2 | 53.8 | 44.1 | 47.6 | 37.4 |
| Seg-Zero-3B (ours) | 62.6 | 58.5 | 56.1 | 48.6 |
| Seg-Zero-7B (ours) | 62.6 | 62.0 | 57.5 | 52.0 |
🔼 This table presents a comparison of zero-shot reasoning segmentation results across various methods. The metrics used are gIoU and cIoU (for both validation and test sets). Methods compared include OVSeg, RELA, Grounded-SAM, LISA-7B-LLaVA1.5, LISA-13B-LLaVA1.5, SAM4MLLM, Qwen2.5VL-3B+SAM2 and the two versions of the authors’ model Seg-Zero (using 3B and 7B parameter models). The table shows that Seg-Zero achieves state-of-the-art performance in zero-shot reasoning segmentation.
read the caption
Table 6: Zero-shot reasoning segmentation results.
| Method | refCOCO | refCOCO+ | refCOCOg |
|---|---|---|---|
| testA | testA | test | |
| LAVT | 75.8 | 68.4 | 62.1 |
| ReLA | 76.5 | 71.0 | 66.0 |
| LISA-7B | 76.5 | 67.4 | 68.5 |
| PixelLM-7B | 76.5 | 71.7 | 70.5 |
| PerceptionGPT-7B | 78.6 | 73.9 | 71.7 |
| Seg-Zero-3B (ours) | 79.3 | 73.7 | 71.5 |
| Seg-Zero-7B (ours) | 80.3 | 76.2 | 72.6 |
🔼 This table presents a comparison of the performance of various referring expression segmentation models using the cIoU (complete Intersection over Union) metric. The models compared include LAVT, RELA, LISA-7B, PixelLM-7B, PerceptionGPT-7B, and the Seg-Zero model (in both 3B and 7B variants). The comparison is done across three different datasets: refCOCO, refCOCO+, and refCOCOg, allowing for an evaluation of performance on various data splits and difficulty levels.
read the caption
Table 7: Referring expression segmentation results. We compare the cIoU in this table.
Full paper#