TL;DR#
Unified models are promising for multimodal tasks but demand computational resources and struggle with interleaved generation. Existing models simultaneously learn understanding and generation, requiring extensive resources. The goal is to develop a resource-efficient approach that achieves both understanding and generation effectively.
This paper introduces ARMOR framework by fine-tuning existing MLLMs. ARMOR extends existing MLLMs using an asymmetric encoder-decoder architecture, a high-quality interleaved dataset, and a training algorithm, and experimental results demonstrate that ARMOR empowers MLLMs with enhanced capabilities using limited resources.
Key Takeaways#
Why does it matter?#
This paper introduces a resource-efficient framework and enhances the way towards achieving both understanding and generation capabilities for MLLMs. The architecture introduces an asymmetric design and a novel training algorithm which could open new research avenues for more efficient multimodal learning.
Visual Insights#

🔼 This figure showcases ARMOR’s multimodal capabilities. It demonstrates ARMOR’s ability to generate different output formats, including images only, text only, and a combination of interleaved text and images, in response to various prompts or questions. The examples provided in the figure illustrate diverse interaction scenarios, highlighting ARMOR’s flexibility and effectiveness in handling various multimodal tasks.
read the caption
Figure 1: ARMOR can output images, text, or interleaved text-image. We show some examples of chat with ARMOR.
| Token Type | Head | Functional Description |
| Special Tokens: | ||
| <imgbos> | text output | Switch model to visual output mode, begin image generation |
| <imgend> | visual output | Terminate image generation, revert to text output mode |
| <imgpad> | visual output | Padding placeholder in image token sequences |
| Image Content Tokens: | ||
| 8192 image tokens | visual output | Content representation tokens |
🔼 This table lists the special tokens and image content tokens used in the ARMOR model. The special tokens control the model’s behavior, such as switching between text and image generation modes, indicating the beginning and end of image generation sequences, and providing padding for image token sequences. The image content tokens represent the visual information processed by the model.
read the caption
Table 1: Special token and image content token specifications.
In-depth insights#
UniM Upgrade#
The concept of a “UniM Upgrade” suggests a method to enhance existing unified models, potentially by leveraging recent advancements in multimodal learning. This could involve incorporating novel attention mechanisms, integrating improved visual representations, or refining the training process to better balance understanding and generation. An upgrade might also target addressing limitations in interleaved text-image generation, a common challenge in UniMs. Furthermore, such an upgrade may strive for resource efficiency, a critical aspect for broader adoption and personalized use. The development of a UniM upgrade is a significant direction, given the rising need for these models.
Asymmetric Synergy#
The concept of “Asymmetric Synergy” suggests an unequal yet mutually beneficial interaction between different components or modalities within a system. In the context of multimodal AI, this might refer to a scenario where one modality contributes more significantly to the overall performance, while the other, though less dominant, plays a crucial supporting role. This synergy could arise from complementary strengths, where one modality compensates for the weaknesses of another. This approach acknowledges that not all modalities are created equal and that optimal system performance can be achieved by carefully balancing their contributions rather than treating them uniformly. Therefore, the success of the multimodal AI depends upon this asymmetric synergy.
WoHG Algorithm#
The WoHG algorithm, a three-stage training process, aims to equip MLLMs with enhanced generation capabilities while preserving their understanding. Each stage has a specific training objective, ensuring progressive improvement. The first stage, “What to Generate”, focuses on enabling the model to autonomously determine the appropriate response format (text or image) based on the input. The second stage, “How to Generate”, is dedicated to improving image generation, activating this capability within the model and ensuring accurate image synthesis based on textual input. Finally, “How to Answer Better”, uses a carefully selected high-quality interleaved dataset to fine-tune the model and ensure a synergistic effect between generated text and images, creating cohesive and contextually relevant responses.
Text-Image Fusion#
Text-Image Fusion represents a critical frontier in multimodal AI, aiming to create synergetic representations that leverage the complementary strengths of textual and visual data. Effective fusion is not merely concatenating features; it involves deep interaction to model complex relationships. Early fusion methods directly combine raw data or low-level features, while late fusion integrates predictions from separate modalities. More advanced approaches, like attention mechanisms, enable adaptive weighting of relevant features across modalities. The key challenge lies in handling the heterogeneity between text and images, addressing issues like differing dimensionality, semantic granularity, and noise levels. Future research should explore context-aware fusion strategies and enhance robustness to modality-specific challenges.
Resource-Efficient#
The concept of resource-efficient computing is increasingly critical, especially for multimodal models demanding substantial computational power. A resource-efficient approach prioritizes minimizing computational costs through innovative techniques like model fine-tuning rather than training from scratch. Further emphasizes on lightweight architectures and optimized data usage. Which ensures accessibility and sustainability in AI development. This efficiency unlocks potential for deployment on limited-resource devices and reduces carbon footprint. The significance of algorithmic optimization alongside hardware considerations is paramount, ensuring maximal utility from available resources, which enables broader participation in AI innovation and promotes eco-friendly practices.
More visual insights#
More on figures

🔼 Figure 2 presents a structural comparison of several Unified Multimodal Models (UniMs). It illustrates the architectural differences in how these models handle multimodal inputs (text and image) and outputs, highlighting distinct approaches such as fully autoregressive architectures, hybrid approaches using autoregressive and diffusion methods, and variations in encoder and decoder designs. Key differences, including the use of asymmetric encoders and decoders, are highlighted to provide insights into the different strategies used for multimodal understanding and generation.
read the caption
Figure 2: Structural comparison of UniMs.

🔼 ARMOR’s architecture is composed of an asymmetric encoder-decoder structure. The encoder leverages the pre-trained components of the MLLM (multimodal large language model), preserving its strong understanding capabilities. The decoder is extended with a new visual output layer (VQGAN decoder) and a forward-switching mechanism, enabling the model to naturally generate text and images and seamlessly interleave them. This enables efficient generation of both images and text, as well as natural text-image interleaving, with minimal added computational overhead. The unified embedding space allows integration of textual and visual information for generating coherent outputs.
read the caption
Figure 3: Architecture of ARMOR.

🔼 This figure illustrates the forward-switching mechanism used in ARMOR. It shows how the model dynamically selects between text and image generation based on the input. Special tokens control which modality’s answer space is used for prediction, enabling natural interleaved text-image generation.
read the caption
Figure 4: Forward switching mechanism.

🔼 This figure shows the first step of the three-stage WoHG training algorithm. In this stage, the model learns to decide what to generate (text, image, or both) based on different types of input questions. The model is trained on various datasets including text-to-text (t2t), text-image-to-text (ti2t), text-to-image (t2i), and text-to-text-image (t2ti). The weights of the loss function are adjusted to α = 1.0 and β = 0.0 to emphasize text prediction, helping the model learn to differentiate between question types.
read the caption
(a) step 1.

🔼 This figure shows the second stage of the three-stage WoHG (What or How to Generate) training algorithm. In this stage, the model focuses on enhancing its image generation capabilities. The parameters related to image generation are unfrozen and trained to improve the accuracy and quality of image generation. The image generation loss weight (β) is set to 1.0, and the text generation loss weight (α) is set to 0.0. The goal is to allow the model to generate high-quality images matching text input, while preserving its multimodal understanding capabilities from the first stage.
read the caption
(b) step 2.

🔼 This figure shows the third stage of the ‘What or How to Generate’ (WoHG) training algorithm. In this stage, the model is fine-tuned using a high-quality dataset of interleaved text and image data. The goal is to improve the model’s ability to generate high-quality, integrated text and image responses that are contextually relevant and coherent. The model learns to better integrate text and visual modalities, leading to more natural and effective multimodal output.
read the caption
(c) step 3.

🔼 This figure demonstrates the three-stage training process of the ‘What or How to Generate’ (WoHG) algorithm. Each stage focuses on a specific objective: Stage 1 trains the model to determine what type of response to generate (text, image, or both); Stage 2 trains the model to improve its image generation capabilities; and Stage 3 trains the model to improve the quality and coherence of its multimodal responses. The figure visually illustrates the changes in the model’s architecture and training data used in each stage.
read the caption
Figure 5: Demonstration of the proposed three-stage WoHG training algorithm.

🔼 This figure displays the evolution of image generation quality throughout the training process, focusing on two different prompts. The leftmost images correspond to epoch 4, and the quality progressively improves towards the rightmost images (epoch 18). Each set of images shows side-by-side examples generated from the same prompt at different training epochs. Prompt 1 focuses on the generation of an aurora, while Prompt 2 involves creating a depiction of a tropical rainforest. The progression demonstrates the model’s learning ability to generate increasingly detailed and accurate images over time.
read the caption
Figure 6: Changes in image generation quality during part of the training process (epochs: 4, 6, 8… 18, from left to right). Prompt 1: “Could you generate an image of the aurora for me?”; Prompt 2: “Please help me draw a picture of the tropical rainforest.”.

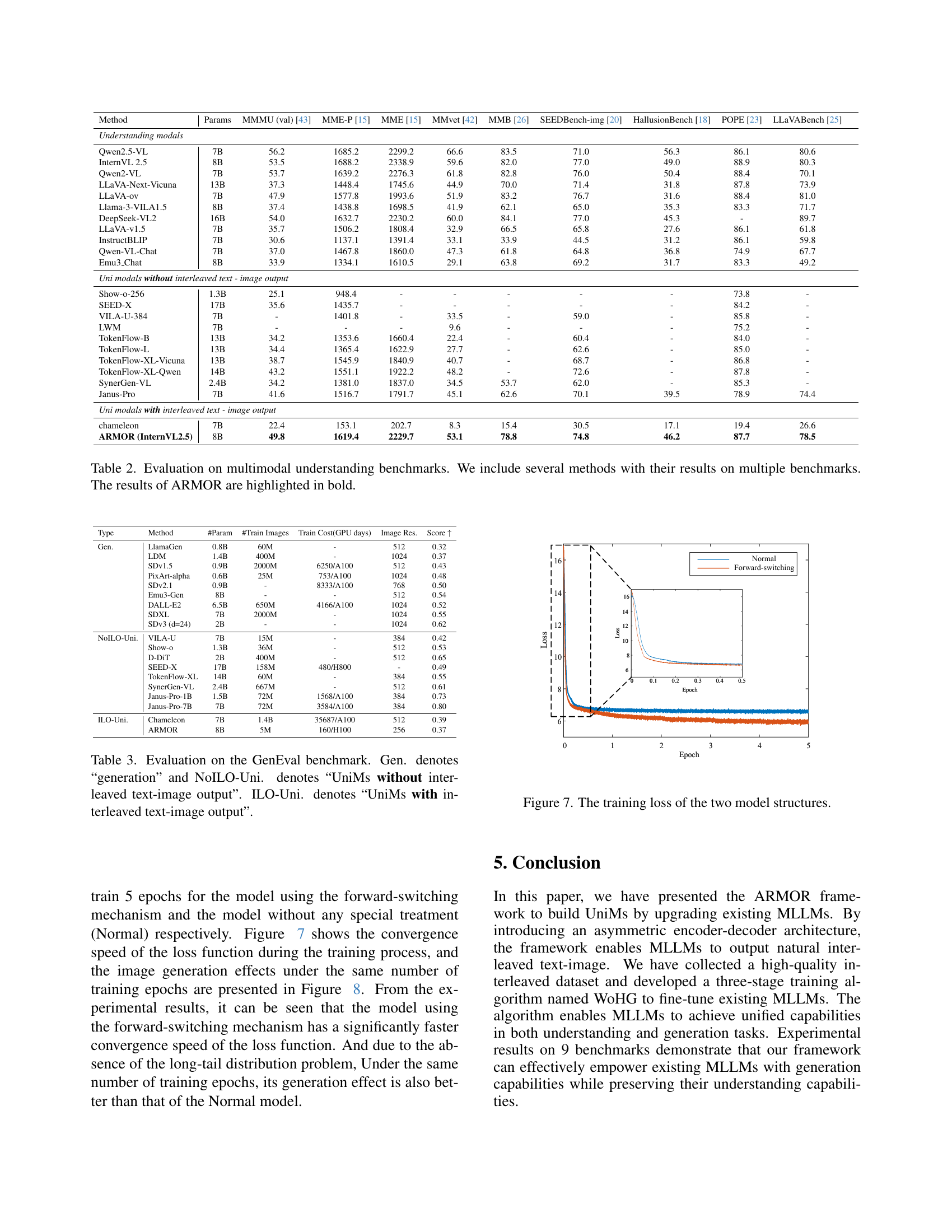
🔼 This figure compares the training loss curves for two different model architectures. The x-axis represents the training epoch, while the y-axis shows the loss value. The plot allows for a visual comparison of the convergence speed and overall training loss between the two models, providing insights into their relative training efficiency and effectiveness.
read the caption
Figure 7: The training loss of the two model structures.

🔼 This figure visualizes the impact of the model architecture on image generation quality. Using the prompt ‘Can you help me draw a picture of a teddy bear doll?’, the model was used to generate images. The first three images (a, b, and c) were generated by a model with a single output layer, while the next three images (d, e, and f) were created by a model with two output layers. The comparison highlights how the increased model complexity (two output layers) leads to improved image generation, resulting in more refined and detailed teddy bear depictions.
read the caption
Figure 8: Generated images with the prompt “Can you help me draw a picture of a teddy bear doll?”. Images (a), (b) and (c) are from a model with one output layer, and images (d), (e) and (f) are from a model with two output layers.

🔼 This figure shows example images generated by a model trained with a visual output layer and adapter. The visual output layer is a component added to enable image generation capabilities, and the adapter is a set of additional transformer layers designed to help integrate the new image generation functionality with the pre-existing language model. The quality of the generated images likely reflects the effectiveness of the training process and the architecture modifications made to the model.
read the caption
Figure 9: The Generated Images Trained with Visual Output Layer and Adapter.
More on tables
| Method | Params | MMMU (val) [43] | MME-P [15] | MME [15] | MMvet [42] | MMB [26] | SEEDBench-img [20] | HallusionBench [18] | POPE [23] | LLaVABench [25] | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Understanding modals | |||||||||||
| Qwen2.5-VL | 7B | 56.2 | 1685.2 | 2299.2 | 66.6 | 83.5 | 71.0 | 56.3 | 86.1 | 80.6 | |
| InternVL 2.5 | 8B | 53.5 | 1688.2 | 2338.9 | 59.6 | 82.0 | 77.0 | 49.0 | 88.9 | 80.3 | |
| Qwen2-VL | 7B | 53.7 | 1639.2 | 2276.3 | 61.8 | 82.8 | 76.0 | 50.4 | 88.4 | 70.1 | |
| LLaVA-Next-Vicuna | 13B | 37.3 | 1448.4 | 1745.6 | 44.9 | 70.0 | 71.4 | 31.8 | 87.8 | 73.9 | |
| LLaVA-ov | 7B | 47.9 | 1577.8 | 1993.6 | 51.9 | 83.2 | 76.7 | 31.6 | 88.4 | 81.0 | |
| Llama-3-VILA1.5 | 8B | 37.4 | 1438.8 | 1698.5 | 41.9 | 62.1 | 65.0 | 35.3 | 83.3 | 71.7 | |
| DeepSeek-VL2 | 16B | 54.0 | 1632.7 | 2230.2 | 60.0 | 84.1 | 77.0 | 45.3 | - | 89.7 | |
| LLaVA-v1.5 | 7B | 35.7 | 1506.2 | 1808.4 | 32.9 | 66.5 | 65.8 | 27.6 | 86.1 | 61.8 | |
| InstructBLIP | 7B | 30.6 | 1137.1 | 1391.4 | 33.1 | 33.9 | 44.5 | 31.2 | 86.1 | 59.8 | |
| Qwen-VL-Chat | 7B | 37.0 | 1467.8 | 1860.0 | 47.3 | 61.8 | 64.8 | 36.8 | 74.9 | 67.7 | |
| Emu3_Chat | 8B | 33.9 | 1334.1 | 1610.5 | 29.1 | 63.8 | 69.2 | 31.7 | 83.3 | 49.2 | |
| Uni modals without interleaved text - image output | |||||||||||
| Show-o-256 | 1.3B | 25.1 | 948.4 | - | - | - | - | - | 73.8 | - | |
| SEED-X | 17B | 35.6 | 1435.7 | - | - | - | - | - | 84.2 | - | |
| VILA-U-384 | 7B | - | 1401.8 | - | 33.5 | - | 59.0 | - | 85.8 | - | |
| LWM | 7B | - | - | - | 9.6 | - | - | - | 75.2 | - | |
| TokenFlow-B | 13B | 34.2 | 1353.6 | 1660.4 | 22.4 | - | 60.4 | - | 84.0 | - | |
| TokenFlow-L | 13B | 34.4 | 1365.4 | 1622.9 | 27.7 | - | 62.6 | - | 85.0 | - | |
| TokenFlow-XL-Vicuna | 13B | 38.7 | 1545.9 | 1840.9 | 40.7 | - | 68.7 | - | 86.8 | - | |
| TokenFlow-XL-Qwen | 14B | 43.2 | 1551.1 | 1922.2 | 48.2 | - | 72.6 | - | 87.8 | - | |
| SynerGen-VL | 2.4B | 34.2 | 1381.0 | 1837.0 | 34.5 | 53.7 | 62.0 | - | 85.3 | - | |
| Janus-Pro | 7B | 41.6 | 1516.7 | 1791.7 | 45.1 | 62.6 | 70.1 | 39.5 | 78.9 | 74.4 | |
| Uni modals with interleaved text - image output | |||||||||||
| chameleon | 7B | 22.4 | 153.1 | 202.7 | 8.3 | 15.4 | 30.5 | 17.1 | 19.4 | 26.6 | |
| ARMOR (InternVL2.5) | 8B | 49.8 | 1619.4 | 2229.7 | 53.1 | 78.8 | 74.8 | 46.2 | 87.7 | 78.5 | |
🔼 This table presents a comparison of various models’ performance on nine multimodal understanding benchmarks. It shows the scores achieved by different models on each benchmark, allowing for a direct comparison of their capabilities in understanding combined text and image data. The models are categorized into those focused primarily on understanding, those focused primarily on generation, and those attempting both (unified models). ARMOR’s results are highlighted for emphasis, showcasing its performance relative to other models.
read the caption
Table 2: Evaluation on multimodal understanding benchmarks. We include several methods with their results on multiple benchmarks. The results of ARMOR are highlighted in bold.
| Type | Method | #Param | #Train Images | Train Cost(GPU days) | Image Res. | Score |
| Gen. | LlamaGen | 0.8B | 60M | - | 512 | 0.32 |
| LDM | 1.4B | 400M | - | 1024 | 0.37 | |
| SDv1.5 | 0.9B | 2000M | 6250/A100 | 512 | 0.43 | |
| PixArt-alpha | 0.6B | 25M | 753/A100 | 1024 | 0.48 | |
| SDv2.1 | 0.9B | - | 8333/A100 | 768 | 0.50 | |
| Emu3-Gen | 8B | - | - | 512 | 0.54 | |
| DALL-E2 | 6.5B | 650M | 4166/A100 | 1024 | 0.52 | |
| SDXL | 7B | 2000M | - | 1024 | 0.55 | |
| SDv3 (d=24) | 2B | - | - | 1024 | 0.62 | |
| NoILO-Uni. | VILA-U | 7B | 15M | - | 384 | 0.42 |
| Show-o | 1.3B | 36M | - | 512 | 0.53 | |
| D-DiT | 2B | 400M | - | 512 | 0.65 | |
| SEED-X | 17B | 158M | 480/H800 | - | 0.49 | |
| TokenFlow-XL | 14B | 60M | - | 384 | 0.55 | |
| SynerGen-VL | 2.4B | 667M | - | 512 | 0.61 | |
| Janus-Pro-1B | 1.5B | 72M | 1568/A100 | 384 | 0.73 | |
| Janus-Pro-7B | 7B | 72M | 3584/A100 | 384 | 0.80 | |
| ILO-Uni. | Chameleon | 7B | 1.4B | 35687/A100 | 512 | 0.39 |
| ARMOR | 8B | 5M | 160/H100 | 256 | 0.37 |
🔼 Table 3 presents a comparison of different models’ performance on the GenEval benchmark, which evaluates visual generation capabilities. The benchmark assesses the quality of generated images. The table specifically categorizes models into those that do not support interleaved text-image output (NoILO-Uni) and those that do (ILO-Uni), showing the impact of this capability on the results. Metrics include the number of parameters (#Param), number of training images, training cost (GPU days), image resolution (Image Res), and the GenEval score, which represents the overall image generation quality.
read the caption
Table 3: Evaluation on the GenEval benchmark. Gen. denotes “generation” and NoILO-Uni. denotes “UniMs without interleaved text-image output”. ILO-Uni. denotes “UniMs with interleaved text-image output”.
| Epoch | Text_L. | Emb. | Visual_L. | Adp. | Und. |
|---|---|---|---|---|---|
| 10 | 0.78 | ||||
| 10 | 0.72 | ||||
| 20 | 0.64 | ||||
| 20 | 0.48 |
🔼 This table presents the results of an experiment evaluating the impact of different model configurations on multimodal understanding ability. Specifically, it shows the effects of including or excluding the text output layer, visual output layer, and added transformer adapter on the model’s performance. The ‘Und.’ column indicates the percentage of the original InternVL2.5 model’s capabilities that were retained after training each configuration, providing a measure of how much the model’s original understanding capabilities were preserved. The experiment uses a single training stage, and different layer combinations are tested in this stage.
read the caption
Table 4: A Single Train Stage Result of Understanding Ability. Text_L denotes the text output layer. Visual_L denotes the visual output layer. Adp. denotes the added transformers adapter. Und. denote the percentage of the original InternVL2.5 capabilities mantained after training.
| Stage | Text_L. | Emb. | Visual_L. | Adp. | Und. |
|---|---|---|---|---|---|
| Stage1 | 0.72 |
🔼 This table presents the results of training the model in the first stage of the WoHG training algorithm. The first stage focuses on enabling the model to decide which modality to generate (text, image, or both) based on the input. It shows the settings for the model’s output layers (text and visual), embedding, adapter modules, and the resulting understanding capability. The understanding capability is measured as a percentage of the original model’s abilities retained after this first stage of training.
read the caption
Table 5: Train The First Stage with A Small Amount of Data.
Full paper#