Multi-modal Large Language Models (MLLMs) often make errors when solving science problems. Evaluating their reasoning is key. However, human evaluation is hard, so MLLMs as judges are popular but unreliable. Current benchmarks are limited in scope/analysis, using synthetic data. This highlights the need for a better evaluation method.
This paper introduces ProJudgeBench, a comprehensive benchmark for MLLM process judges. It includes 2,400 test cases with 50,118 step-level labels across four sciences, annotated by experts for correctness and error type. The paper also introduces ProJudge-173k, a dataset and Dynamic Dual-Phase fine-tuning to enhance open-source models’ evaluation abilities. Evaluation reveals significant performance gaps.
This paper introduces a new benchmark, ProJudgeBench, for evaluating MLLM’s process judges in scientific problem-solving, and introduces a method for instruction-tuning with the new dataset. This will assist researchers in future advancements to improve MLLM for scientific use.
🔼 This table compares ProJudgeBench with other related benchmarks for evaluating the capabilities of large language models (LLMs) as process judges. It highlights key differences in terms of whether the benchmark is multi-modal, multi-disciplinary, incorporates problems with varying difficulty, provides step-level annotation, offers fine-grained error analysis, and reports the average number of steps in the evaluation process. The goal is to show how ProJudgeBench offers a more comprehensive and nuanced evaluation compared to existing benchmarks.
read the captionTable 1: Comparison between related benchmarks with our ProJudgeBench.
Process judges in the context of MLLMs are crucial for evaluating the reasoning behind scientific problem-solving, going beyond just checking final answers. Human evaluation is costly, thus prompting the creation of automated judges using MLLMs. However, the reliability of these model-based judges is uncertain due to inherent errors and biases in MLLMs. A need for comprehensive benchmarks to specifically assess the capabilities of these process judges is paramount. Such benchmarks need to overcome narrow scope, insufficient error analysis, and synthetic or non-generalizable data found in existing ones. The end goal being is to refine process evaluation, enabling more accurate insights into MLLM weaknesses and enhancing overall scientific reasoning capabilities.
ProJudgeBench appears to be a novel benchmark crafted for evaluating the error detection, classification, and diagnostic capabilities of MLLM-based process judges. Its key strengths lie in its multi-modal, multi-discipline nature, spanning mathematics, physics, chemistry, and biology. It employs fine-grained error analysis, categorizing errors into seven distinct types based on observed model mistakes. The dataset comprises solutions from diverse MLLMs, ensuring realistic error patterns, a key differentiator from synthetic data used in other benchmarks. This approach promises to improve the reliability of multi-modal evaluation in the future.
The paper’s methodology for error analysis is comprehensive, classifying mistakes into seven distinct categories, ranging from fundamental numerical errors to complex reasoning deficits. This detailed categorization allows for granular insights into model weaknesses. Crucially, the error analysis is conducted by human experts, ensuring reliability and nuance beyond automated assessments. This emphasis on human-annotated data is a strength, enabling the identification of subtle errors often missed by automated systems. The analysis aims to go beyond mere error detection, focusing on understanding root causes and providing explanations. This approach promotes better targeted model improvements. However, the reliance on human annotation introduces potential biases and scalability limitations. Future work could explore hybrid approaches that combine human expertise with automated techniques for more efficient and objective error analysis.
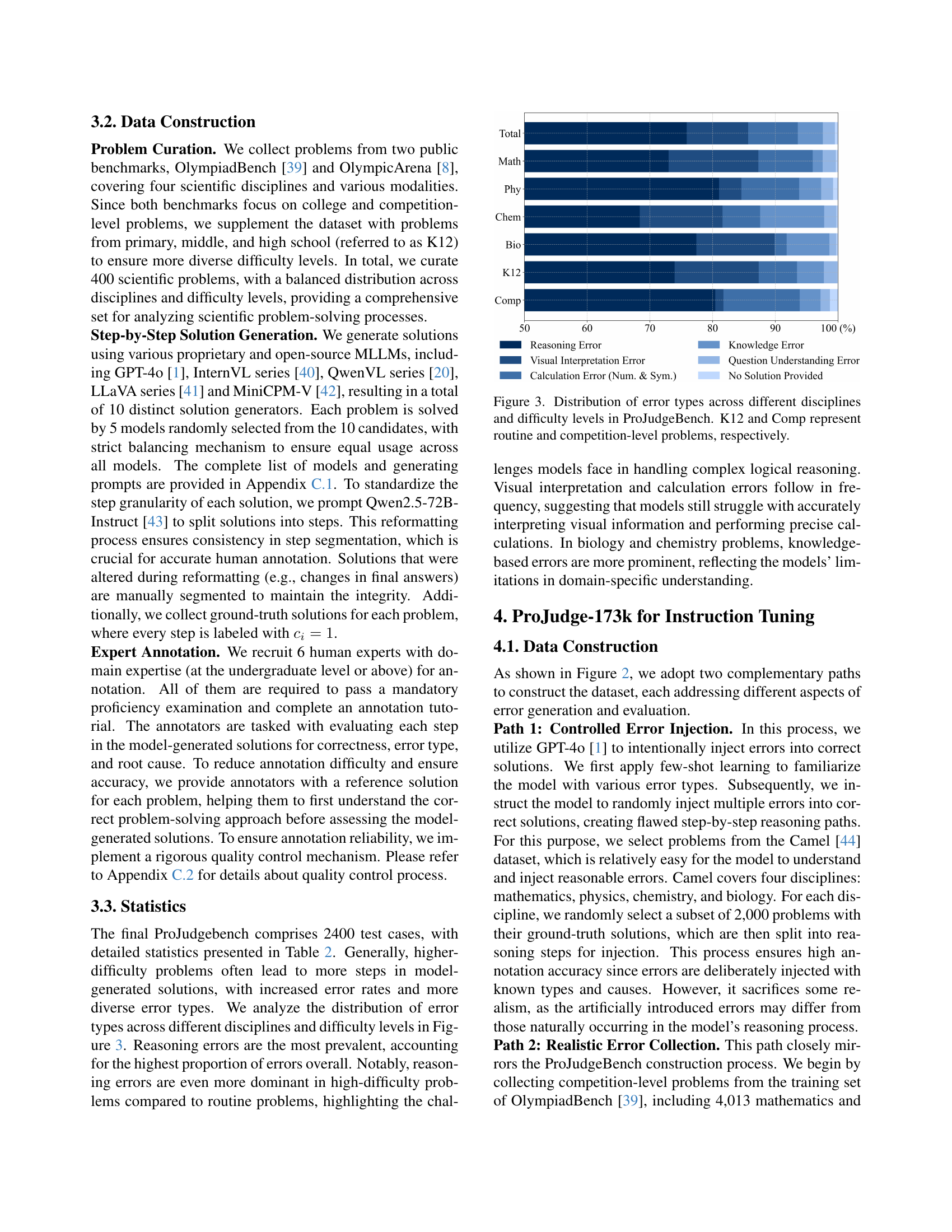
The data creation process involves meticulous efforts in curating problems from OlympiadBench and OlympicArena, supplemented with K12-level questions to ensure difficulty diversity. Solutions are generated by a diverse range of MLLMs, and experts annotate each step for correctness, error type, and explanation. This detailed annotation facilitates a systematic evaluation of process judges and emphasizes the effort to capture real-world reasoning behaviors. Rigorous quality control mechanisms, including inter-annotator agreement checks and resolution of discrepancies, further bolster annotation reliability. This thoroughness ensures the benchmark’s integrity, ultimately enabling reliable assessment of MLLM-based process judges, leading to actionable insights that foster future improvements.
Fine-tuning is crucial for adapting pre-trained models to specific tasks by updating their parameters using task-specific data. This process enhances performance and efficiency, especially when dealing with limited data. Effective fine-tuning strategies often involve techniques like transfer learning, where knowledge gained from pre-training is leveraged. The choice of architecture, data set, and regularization methods are all important considerations for a successful tuning. Analyzing the learning rate and optimization algorithms are key to avoid overfitting or underfitting the model. Ablation studies can also help find and remove the unnecessary parts of the model and achieve a better final performance.
🔼 This table presents a statistical summary of the ProJudgeBench benchmark and the ProJudge-173k dataset. For ProJudgeBench, it shows the number of samples, the distribution across four scientific disciplines (Math, Physics, Chemistry, Biology), the breakdown of problem types (K12, Olympiad, and competition levels), the average and maximum number of steps in the solutions, the average and maximum number of error types, and the average, maximum, and percentage of erroneous steps in the solutions. For ProJudge-173k, similar statistics are provided, including the distribution of problems across Camel, K12, and Olympiad datasets. This gives a comprehensive overview of the size, complexity, and error characteristics of both the benchmark and the instruction tuning dataset.
read the captionTable 2: Statistics of ProJudgeBench and ProJudge-173k.
Multi-modal
Benchmark
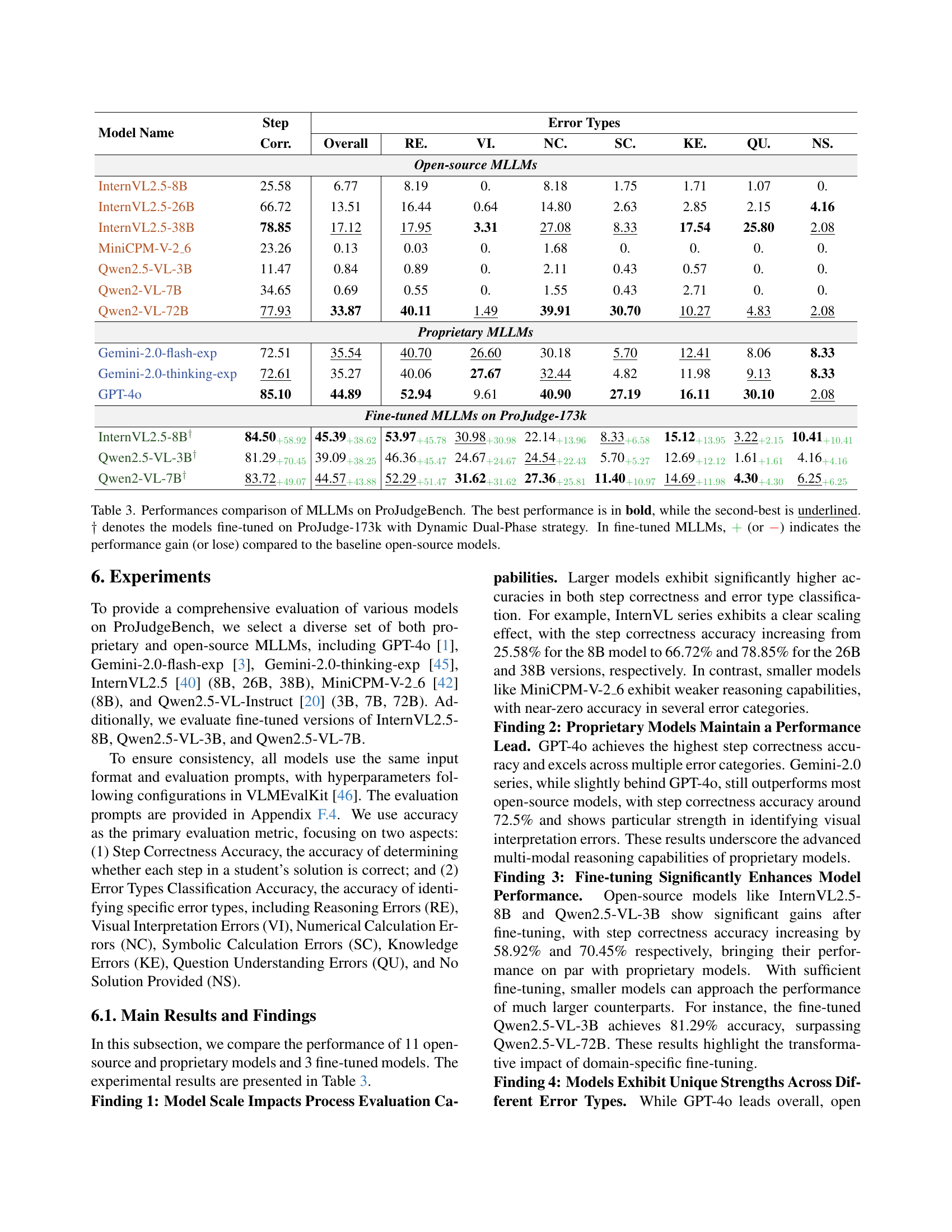
🔼 This table compares the performance of various large language models (LLMs) on the ProJudgeBench benchmark. It shows the overall accuracy and accuracy broken down by error type for each model. Both open-source and proprietary LLMs are included. It also presents results for models fine-tuned using a new Dynamic Dual-Phase strategy on the ProJudge-173k dataset. Performance gains or losses compared to the original, open-source model are indicated using ‘+’ or ‘-’ respectively. The best performing model for each metric is shown in bold, while the second best is underlined.
read the captionTable 3: Performances comparison of MLLMs on ProJudgeBench. The best performance is in bold, while the second-best is underlined. ††{\dagger}† denotes the models fine-tuned on ProJudge-173k with Dynamic Dual-Phase strategy. In fine-tuned MLLMs, +{{\color[rgb]{0.22265625,0.7109375,0.2890625}\definecolor[named]{% pgfstrokecolor}{rgb}{0.22265625,0.7109375,0.2890625}+}}+ (or −{\color[rgb]{1,0,0}\definecolor[named]{pgfstrokecolor}{rgb}{1,0,0}-}-) indicates the performance gain (or lose) compared to the baseline open-source models.
Multi-Discipline
Benchmark
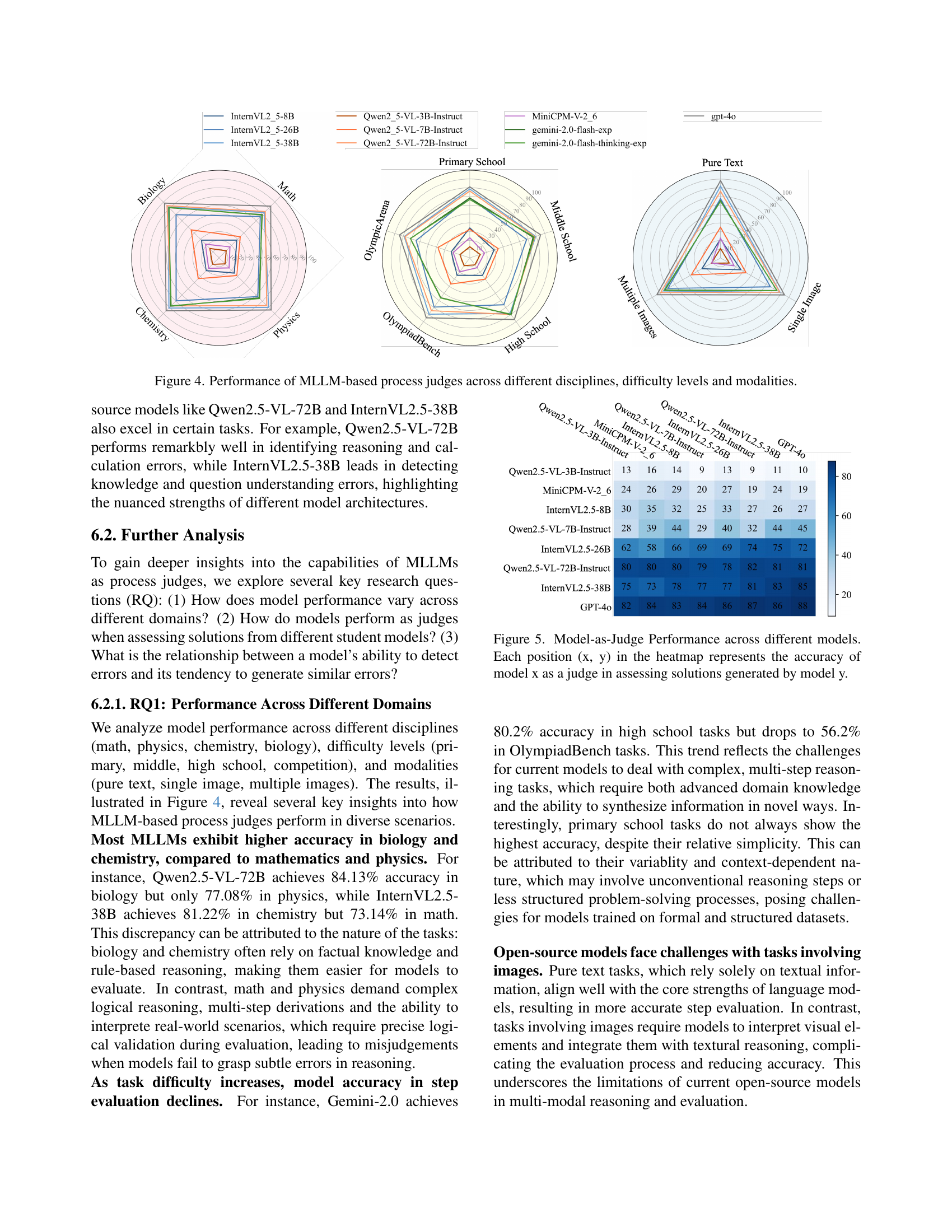
🔼 This table presents an ablation study comparing the effectiveness of two fine-tuning strategies: standard fine-tuning and the Dynamic Dual-Phase (DDP) approach. The DDP method encourages the model to reason explicitly through the problem-solving steps before evaluating solutions. The table shows the performance metrics, specifically the overall step correctness accuracy, on the complete ProJudgeBench dataset and a subset called OlympicArena. This allows for an assessment of both in-domain performance and the generalization capabilities of the models trained with each method.
read the captionTable 4: Ablation study on Dynamic Dual-Phase fine-tuning strategy. We compare the standard fine-tuning (+ FT) with DDP-enhanced training (+ DDP). Overall and OlympicArena represent the results on the full set of ProJudgeBench and its OlympicArena subset respectively.
Multi-Difficulty
Problems
🔼 This table defines seven categories of errors commonly made by large language models (LLMs) during problem-solving. Each error type is described to provide a clear understanding of the different kinds of mistakes LLMs make, which helps in evaluating their performance and identifying areas for improvement. The definitions are detailed enough to facilitate consistent and accurate annotation of errors during the evaluation process.
read the captionTable 5: Definitions of seven error types.
Step-level
Annotation
🔼 This table lists the ten large language models (LLMs) used to generate the solutions within the ProJudgeBench dataset. These LLMs represent a diverse range of architectures, sizes, and training data, reflecting the spectrum of current MLLM capabilities and potential biases. The diversity of models ensures the benchmark evaluates the process judging capabilities on a broad range of reasoning patterns and error types commonly exhibited by different MLLMs.
read the captionTable 6: List of MLLMs used in ProJudgeBench to generate solutions.
Fine-grained
Error Analysis
🔼 Table 7 presents a statistical overview of the ProJudgeBench dataset, broken down by problem type (normal vs. competition-level) and scientific discipline. It provides the number of samples, average and maximum number of steps in the solutions, the average and maximum number of error types present, and the average percentage of erroneous steps within each category. This detailed breakdown allows for an understanding of the dataset’s composition and complexity, showing how metrics change based on problem difficulty and subject matter.
read the captionTable 7: Statistics of ProJudgeBench. K12 and Comp represent normal and competition-level problems, respectively.
Avg.
Steps
🔼 This table lists the ten large language models (LLMs) used to generate the solutions within the ProJudge-173k dataset. These LLMs represent a diverse range of models, both open-source and proprietary, with varying sizes and architectures. They were used to create a varied set of solutions, which reflect different reasoning patterns and error types, enhancing the realism and comprehensiveness of the dataset.
read the captionTable 8: List of MLLMs used in ProJudge-173k to generate solutions.
Statistic
Number
ProJudgeBench
2,400
- # Math / Phy. / Chem. / Bio.
600
- # K12 / OlymBench / OlymArena
1,350 / 250 / 625
- Avg. / Max. Steps
20.8 / 470
- Avg. / Max. Error Types
1.5 / 5
- Avg. / Max. / % Error Steps
6.6 / 226 / 21.6
ProJudge-173k
173,354
- # Math / Phy. / Chem. / Bio.
58k / 40k / 37k / 35k
- # Camel / K12 / OlymdBench
26k / 93k / 53k
- # Avg. / Max. Steps
18.2 / 926
- Avg. / Max. Error Types
1.4 / 5
- Avg. / Max. / % Error Steps
5.9 / 402 / 24.7
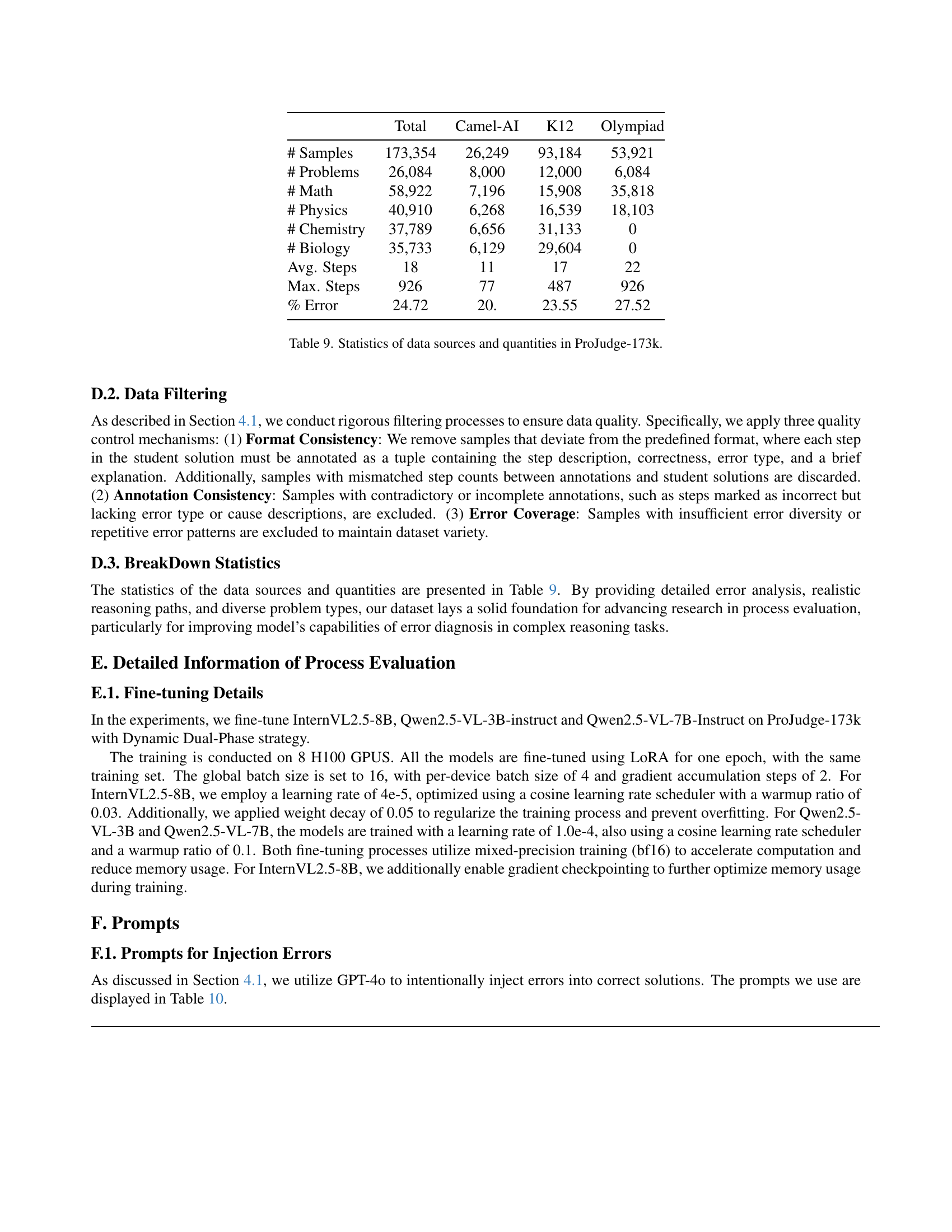
🔼 Table 9 presents a detailed breakdown of the ProJudge-173k dataset, categorized by data source (Camel, K12, and Olympiad) and scientific discipline (Math, Physics, Chemistry, Biology). For each category, it provides the number of samples, problems, average number of steps per solution, maximum number of steps, and average percentage of erroneous steps. This table offers a comprehensive overview of the dataset’s size, complexity, and error distribution across different problem types and difficulty levels, highlighting the dataset’s suitability for training and evaluating robust process judges.
read the captionTable 9: Statistics of data sources and quantities in ProJudge-173k.
🔼 This table displays the prompt used to instruct GPT-4 to introduce errors into correct solutions. The prompt guides GPT-4 to act as an educator who understands both problem-solving and common student mistakes, instructing it to introduce realistic and reasonable errors into a given solution that mimic typical student or AI errors. The prompt specifies seven types of errors to consider and requires a specific format for the response. The response should include step-by-step evaluations marking correct (1) or incorrect (0) steps, with error type and description specified for incorrect steps. The prompt also includes placeholders for the problem, its knowledge points, and the correct solution.
read the captionTable 10: Prompt for injecting errors.
Model
Overall
OlympicArena
InternVL2.5-8B (Base)
25.58
22.33
+ FT
83.37
81.71
+ FT + DDP (Full)
84.50
85.07
QwenVL2.5-3B (Base)
11.47
11.92
+ FT
80.57
80.38
+ FT + DDP (Full)
81.29
81.01
QwenVL2.5-7B (Base)
34.65
38.25
+ FT
81.91
77.88
+ FT + DDP (Full)
83.72
82.67
🔼 This table displays the prompt used to instruct large language models (LLMs) to generate solutions for scientific problems in the ProJudge dataset. The prompt instructs the model to act as a student solving the problem step-by-step, using LaTeX formatting for mathematical expressions, and to include context information if provided. The model is asked to clearly delineate the steps involved in solving the problem.
read the captionTable 11: Prompt for generating solutions.
Error Types
Definitions
Numerical Calculation Error
Errors in basic arithmetic operations such as addition, subtraction, division, or square roots.
Symbolic Calculation Error
Errors in manipulating algebraic expressions, such as incorrect expansion, factoring, simplification, or solving equations with variables.
Visual Interpretation Error
Errors in interpreting graphical data, such as misidentifying coordinates, shapes, spatial relationships, or data within figures.
Reasoning Error
Errors in the logical thinking process that lead to incorrect conclusions, such as flawed arguments, invalid inferences, or gaps in the logical flow of the solution.
Knowledge Error
Errors caused by insufficient understanding or incorrect application of necessary knowledge (e.g., concepts, formulas, theorems, methods), or using outdated or incorrect information.
Question Understanding Error
Errors due to misunderstanding or misinterpreting the problems’ conditions or requirements, such as misreading questions or misapplying given conditions.
No solution provided
The model refuses to answer, fails to follow instructions to make a solution, or encounters anomalies in generation process such as repetitive responses or incomplete outputs.
🔼 This table displays the prompt used to instruct large language models (LLMs) to generate solutions for scientific problems. The prompt guides the LLM to solve problems step-by-step using LaTeX format and to consider all relevant information before providing an answer. The response should end with ‘The final answer is ANSWER.’
read the captionTable 12: Prompt for generating solutions.
MLLMs as solution generators in ProJudgeBench
InternVL2.5-8B
InternVL2.5-26B
InternVL2.5-38B
Qwen2.5-VL-Instruct-3B
Qwen2.5-VL-Instruct-7B
Qwen2.5-VL-Instruct-72B
MiniCPM-V-2_6 (8B)
QVQ-72B-Preview
LLaVA-OneVision (7B)
GPT-4o
🔼 This table displays the prompt used for the process evaluation task in the ProJudgeBench experiment. The prompt instructs the model to act as a teacher evaluating a student’s solution to a scientific problem. The evaluator must first solve the problem correctly, then assess each step of the student’s solution, providing a binary correctness score (1 for correct, 0 for incorrect), classifying any errors using seven predefined categories, and giving a brief explanation for each identified error. The final output should be a Python list with specific formatting.
read the captionTable 13: Prompt for process evaluation.