TL;DR#
The paper addresses the rising computational costs of neural machine translation (NMT) due to large language models (LLMs). Traditional encoder-decoder architectures have been overshadowed by single Transformer decoders in NLP. The research explores efficient translation models by integrating LLMs into NMT encoding, retaining the original NMT decoder to create a universal and efficient model. Methods to adapt LLMs for better NMT decoder compatibility are also developed. The paper introduces a new dataset for assessing machine translation generalization across tasks.
The study presents the LaMaTE model, which combines LLMs as NMT encoders with adaptations for improved decoder compatibility. Evaluations on WMT and a new dataset show that the method matches or exceeds translation quality baselines, while achieving 2.4~6.5x inference speedups and a 75% reduction in KV cache memory. The new benchmark, ComMT, is introduced for assessing machine translation generalization across tasks. This approach demonstrates strong generalization across translation-related tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers aiming to enhance machine translation efficiency while retaining quality. By combining LLMs with NMT, it presents a balanced approach that addresses computational costs and scalability, offering new directions for future research. The insights on generalization across tasks are valuable for developing more versatile translation systems.
Visual Insights#

🔼 This figure illustrates three different machine translation model architectures. (a) shows a standard Neural Machine Translation (NMT) model, using a separate encoder to process the source language sequence (x) and a decoder to generate the target language sequence (y). (b) depicts a Large Language Model (LLM) approach, where both x and y, along with an optional prompt (c), are fed into a single decoder network. (c) presents the LaMaTE architecture, which combines LLMs and NMT. LaMaTE uses an LLM as its encoder. The LLM’s output then passes through an adaptor before being input to the NMT decoder, which produces the translated output (y).
read the caption
Figure 1: Architectures of machine translation models. In standard NMT models, an encoder is used to encode the source-language sequence x, and a decoder is used to generate the target-language sequence y from left to right. In LLMs, the decoder-only architecture is adopted. Both x and y, along with the prompt c, are represented as a single sequence, which is processed by a large decoding network. In the LaMaTE model, an LLM serves as the encoder. The output of the LLM is transformed into the input to the NMT decoder through an adaptor. The NMT decoder then generates the target-language sequence as usual.
| Aspect | Models | COMET | BLEU |
| - | LaMaTE (Ours) | ||
| Training Method | W/o S2 | ||
| W/ S2 & Frozen LLM | |||
| Adaptor Design | W/o Layer Fusion | ||
| W/o EncStack | |||
| Decoder Variant | Concat Decoder | ||
| Prefix Decoder | |||
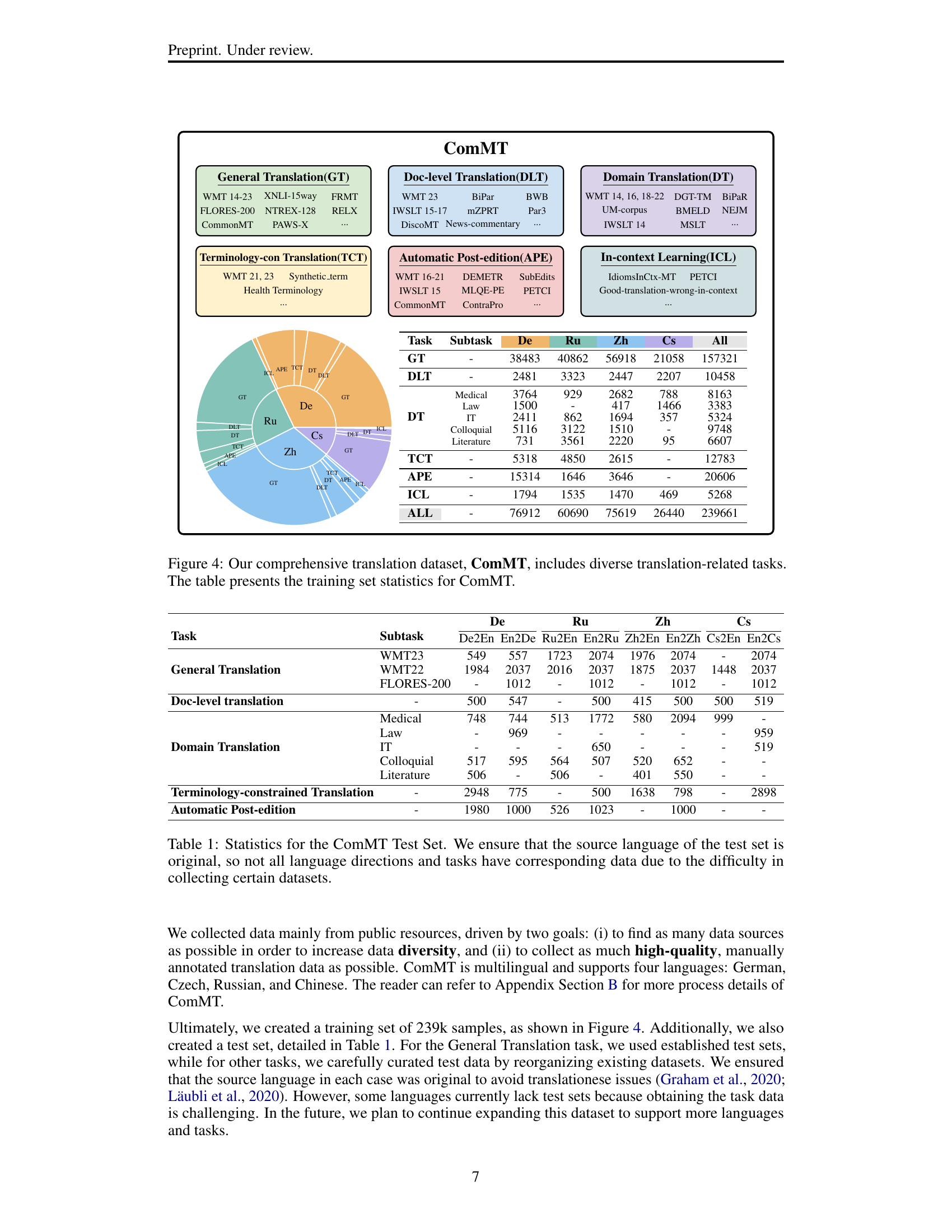
🔼 Table 1 presents statistics for the ComMT (Comprehensive Machine Translation) test set. It shows the number of examples available for each language pair and task within the ComMT benchmark. The table highlights that, due to the challenge of collecting original data across many different languages and tasks, not every combination of language direction and task has a corresponding dataset.
read the caption
Table 1: Statistics for the ComMT Test Set. We ensure that the source language of the test set is original, so not all language directions and tasks have corresponding data due to the difficulty in collecting certain datasets.
In-depth insights#
LLM Encoders#
LLMs as encoders in machine translation present a paradigm shift, leveraging their robust language understanding. LaMaTE, for example, uses an LLM to encode the source language, adapting its output for a traditional NMT decoder. This approach offers efficiency, reducing computational costs compared to end-to-end LLM translation. It combines the strengths of both paradigms: the LLM’s contextual awareness and the NMT decoder’s generation capabilities, leading to potentially improved translation quality and efficiency.
LaMaTE Model#
The LaMaTE model innovatively repurposes large language models (LLMs) as encoders within a traditional NMT framework. It leverages the strengths of LLMs in understanding source language nuances while retaining the efficiency of NMT decoders for target language generation. A crucial component is the adaptor, which bridges the gap between the LLM’s output and the NMT decoder’s input, incorporating fusion, dimensionality reduction, and potentially bidirectional representation learning. The model employs a two-stage training strategy, initially freezing the LLM and training the adaptor and decoder, followed by fine-tuning all components. This helps to strike a balance between efficient training and effectively utilizing the LLM’s knowledge.
ComMT Dataset#
The ‘ComMT Dataset’ is a key contribution; the research constructs a comprehensive benchmark for machine translation, addressing the limitations of existing datasets. The dataset focuses on generalization across diverse tasks, moving beyond single-task contexts. It incorporates various translation-related tasks such as general translation, document-level translation, domain-specific translation, terminology-constrained translation and automatic post-editing. The dataset’s multilingual nature, supporting German, Czech, Russian, and Chinese, enhances its practical relevance. Careful attention is paid to data quality and diversity, using manual annotation and filtering techniques to avoid translationese issues. By providing a high-quality, diverse dataset, the researchers aim to promote the development of more robust and adaptable machine translation systems. This should encourage researchers to prioritize generalization capabilities in MT models.
Decoding Speedup#
Decoding speedup is a crucial area in machine translation, especially when dealing with large language models (LLMs). The efficiency of translating text directly affects the practicality of deploying these models in real-world applications. LLMs, despite their power, can be computationally intensive, making the decoding phase a bottleneck. Optimizing this phase is key to reducing latency and improving user experience. Techniques such as model compression (quantization, pruning) and algorithmic improvements (speculative decoding) are typical approaches. However, the paper explores a different angle, focusing on architectural modifications to enhance speed without sacrificing translation quality. It explores efficient encoding and decoding architectures, such as LaMaTE, achieving 2.4x to 6.5x faster decoding speeds, highlighting the advantages of decoupling encoding and decoding for better performance. This work emphasizes the importance of efficient model design.
Cross Attention#
Cross-attention is a key mechanism that allows the decoder to focus on relevant parts of the input sequence during translation. It guides the decoder by creating connections to source tokens, improving alignment. By using cross-attention, the network selectively attends to certain source words at each decoding step. Retaining cross-attention is particularly beneficial for translation tasks. It enables a more nuanced understanding of the source context.
More visual insights#
More on figures

🔼 This figure shows the architecture of three different decoder models used in machine translation: a standard neural machine translation (NMT) encoder, a standard NMT decoder, and a large language model (LLM) decoder. The NMT encoder processes the input sequence bidirectionally using self-attention and feed-forward neural networks. The NMT decoder generates the target sequence unidirectionally, also using self-attention, but incorporating cross-attention with the encoder’s output for better context. The LLM decoder is a decoder-only model that processes both source and target sequences as a single sequence, leveraging causal self-attention. Layer normalization and residual connections are omitted for clarity.
read the caption
Figure 2: Architecture of the NMT Encoder, NMT Decoder, and LLM Decoder. We omit the layer normalization and residual connections for simplicity.

🔼 The figure illustrates the LaMaTE model architecture, which uses a large language model (LLM) as the encoder and a neural machine translation (NMT) decoder. A key component is the adaptor, which sits between the LLM and the NMT decoder. This adaptor has three parts: a fusion layer that combines the LLM’s hidden states from multiple layers, a multilayer perceptron (MLP) that reduces the dimensionality of the combined representation, and a stack of encoder layers (EncStack) that creates bidirectional representations. The model is trained in two stages: the first stage trains only the adaptor and decoder, and the second stage trains all model parameters, including the LLM.
read the caption
Figure 3: The architecture of LaMaTE, where the Adaptor consists of three components: Fusion combines the representations of layer groups 𝐠ksubscript𝐠𝑘\mathbf{g}_{k}bold_g start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT, MLP reduces the representations’s dimensionality, and EncStack learns bidirectional representations. The training process consists of two stages: the first stage trains the Adaptor and Decoder, and the second stage trains all model parameters.

🔼 Figure 4 presents the ComMT dataset, a comprehensive benchmark for evaluating machine translation models’ capabilities across various tasks. It is not limited to simple sentence-level translation; ComMT includes tasks like document-level translation, which tests coherence and context maintenance in longer texts, and domain-specific translation, assessing performance within specific terminology and styles (medical, legal, IT, colloquial, literature). Additionally, it evaluates performance on constrained translation (where specific terminology must be used) and automatic post-editing (correcting machine-generated translations). The table within Figure 4 details the amount of training data available for each of these tasks across multiple languages (German, Czech, Russian, and Chinese).
read the caption
Figure 4: Our comprehensive translation dataset, ComMT, includes diverse translation-related tasks. The table presents the training set statistics for ComMT.

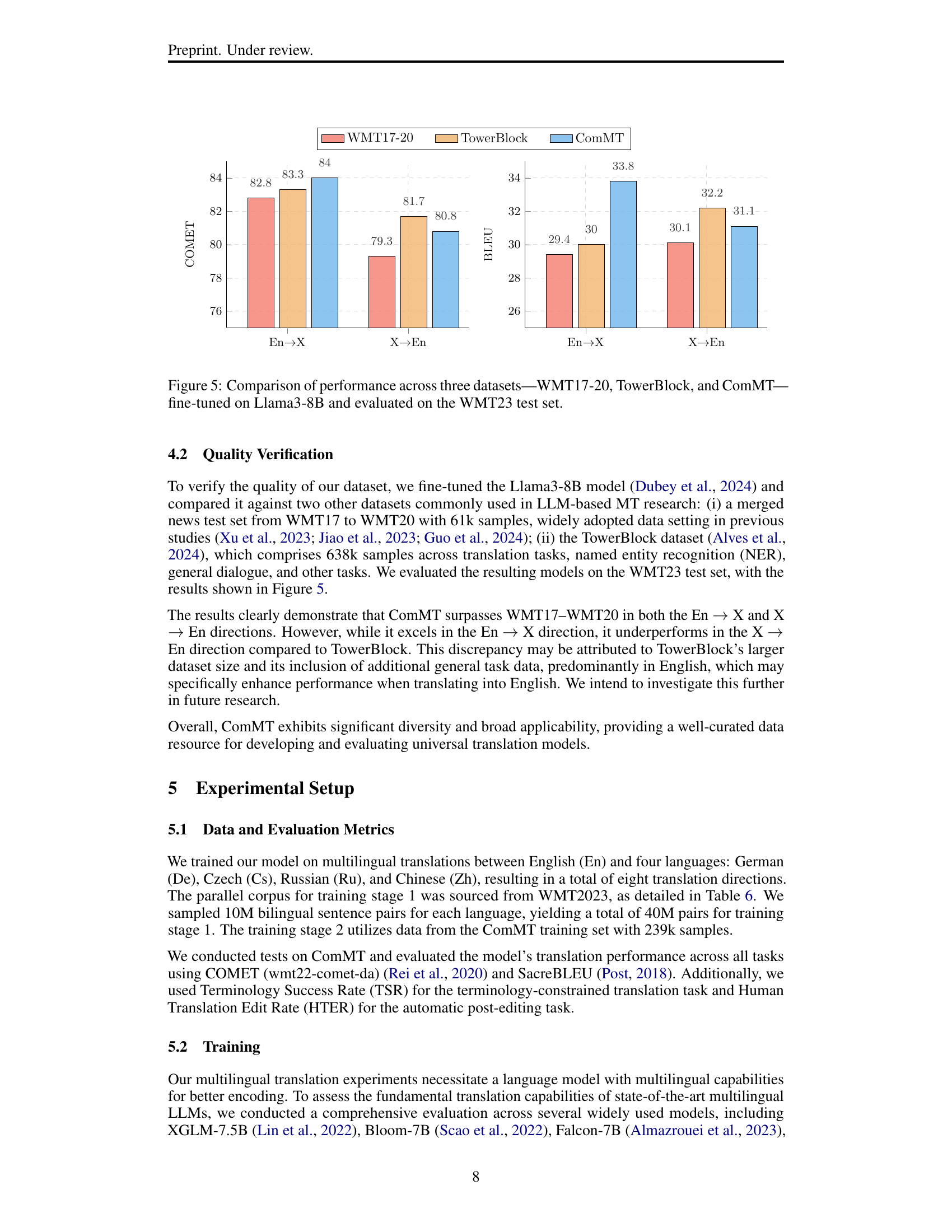
🔼 This figure compares the performance of the Llama3-8B model fine-tuned on three different datasets: WMT17-20, TowerBlock, and ComMT. The model’s performance is then evaluated on the WMT23 test set using BLEU scores. This allows for a comparison of how well the model generalizes across different datasets and task types. The x-axis represents the dataset used for fine-tuning (WMT17-20, TowerBlock, or ComMT), and the y-axis shows the BLEU score achieved on the WMT23 test set. The figure includes separate bars for English-to-other-language translation (En→X) and other-language-to-English translation (X→En), illustrating performance differences in each direction. This visualization helps assess the model’s ability to transfer knowledge from various training data sources and its adaptability for various translation scenarios.
read the caption
Figure 5: Comparison of performance across three datasets—WMT17-20, TowerBlock, and ComMT—fine-tuned on Llama3-8B and evaluated on the WMT23 test set.

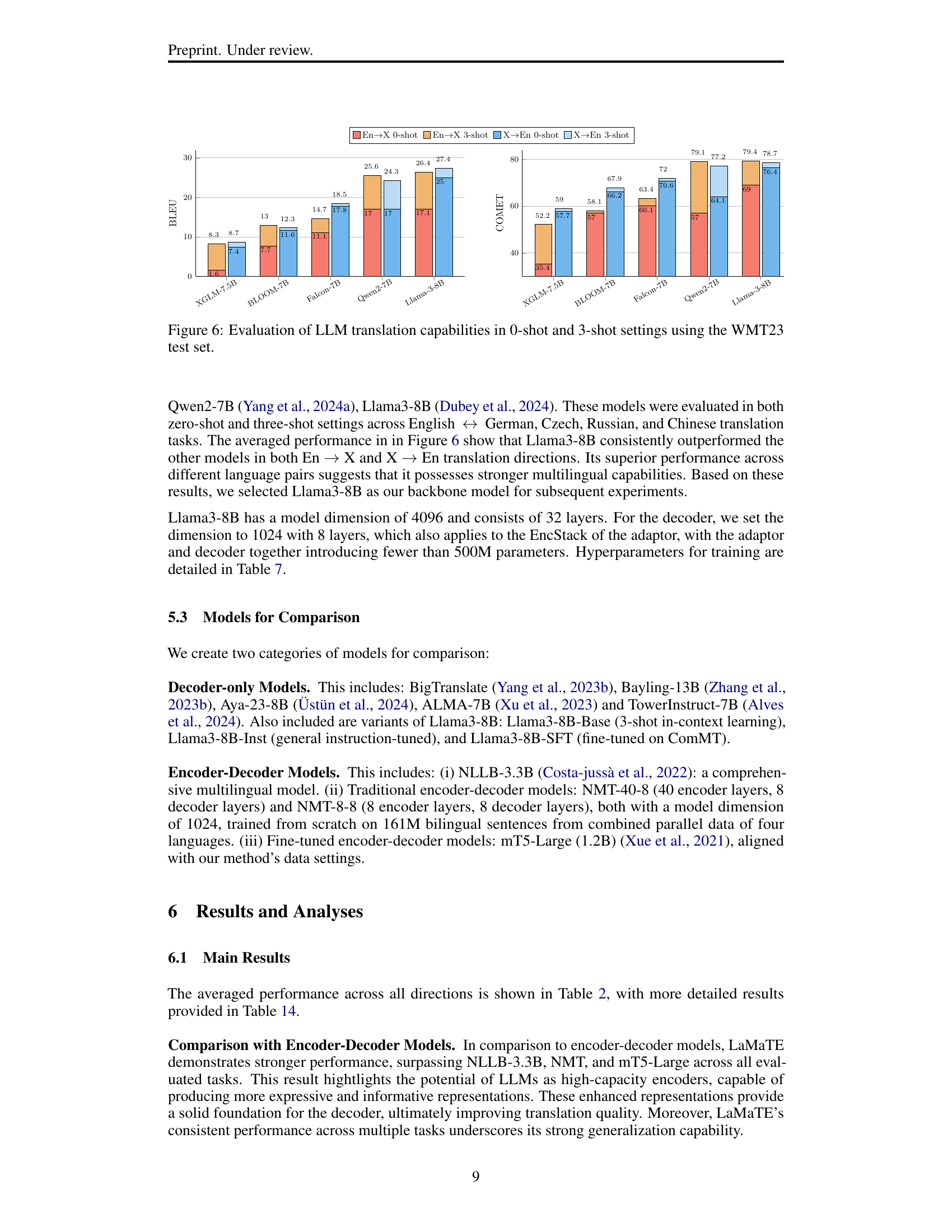
🔼 This figure displays the results of evaluating the translation capabilities of five different large language models (LLMs) in both zero-shot (no prior training on the translation task) and three-shot (three examples provided during inference) settings. The models were tested on eight different translation directions involving English and four other languages (German, Czech, Russian, and Chinese). The y-axis represents the BLEU score, a common metric for evaluating machine translation quality, and shows the performance for each translation direction and model type (zero-shot vs three-shot). The x-axis shows the five different language models: XGLM-7.5B, BLOOM-7B, Falcon-7B, Qwen2-7B, and Llama-3-8B. The figure illustrates how providing a few examples (three-shot) significantly improves the translation quality for most of the LLMs tested, and highlights Llama-3-8B’s consistently superior performance across all settings.
read the caption
Figure 6: Evaluation of LLM translation capabilities in 0-shot and 3-shot settings using the WMT23 test set.

🔼 Figure 7 presents a comparison of four different machine translation models across three metrics that evaluate translation quality. Specifically, it compares the Llama3-8B and TowerInstruct-7B (both decoder-only models) against mT5-large and LaMaTE (both encoder-decoder models). The three metrics used are off-target rate (OTR), which measures how often a model generates translations in an unintended language; unaligned source words (USW), which is the proportion of words in the source language that are not properly translated in the target language; and unaligned target words (UTW), which is the number of words that appear in the target language translation but do not have a proper equivalent in the source language. The figure helps demonstrate how different model architectures can affect the overall quality and alignment of the machine translations.
read the caption
Figure 7: Comparison of decoder-only (Llama3-8B and TowerInstruct-7B) and encoder-decoder (mT5-large and LaMaTE) models on off-target rate (OTR), unaligned source words (USW), and unaligned target words (UTW).

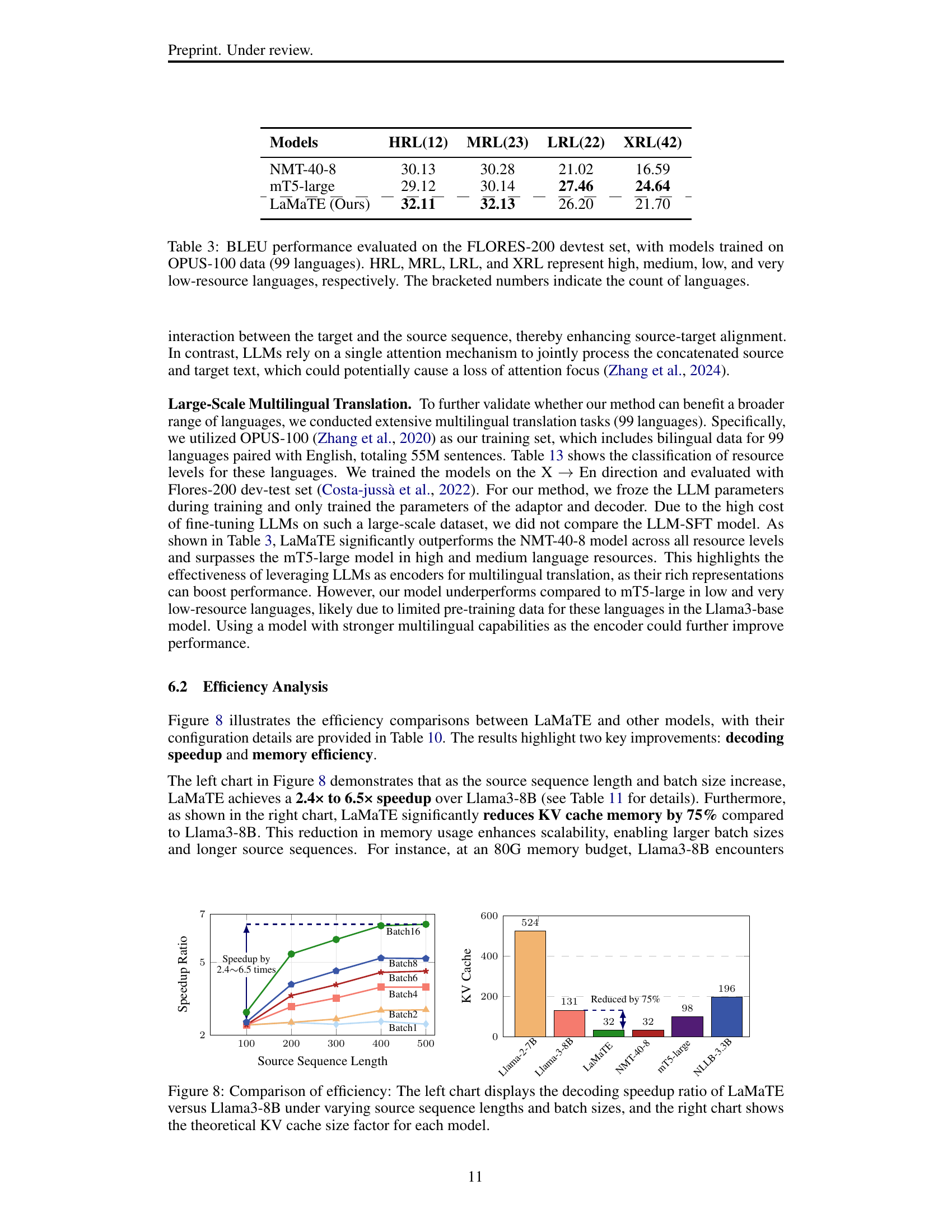
🔼 Figure 8 presents a comparison of the efficiency of LaMaTE against Llama3-8B. The left chart shows the speedup ratio achieved by LaMaTE in decoding, considering varying source sequence lengths and batch sizes. This illustrates how LaMaTE’s decoding speed improves as the complexity of the input increases. The right chart visualizes the theoretical reduction in KV cache memory usage achieved by LaMaTE compared to Llama3-8B. This demonstrates LaMaTE’s improved memory efficiency.
read the caption
Figure 8: Comparison of efficiency: The left chart displays the decoding speedup ratio of LaMaTE versus Llama3-8B under varying source sequence lengths and batch sizes, and the right chart shows the theoretical KV cache size factor for each model.

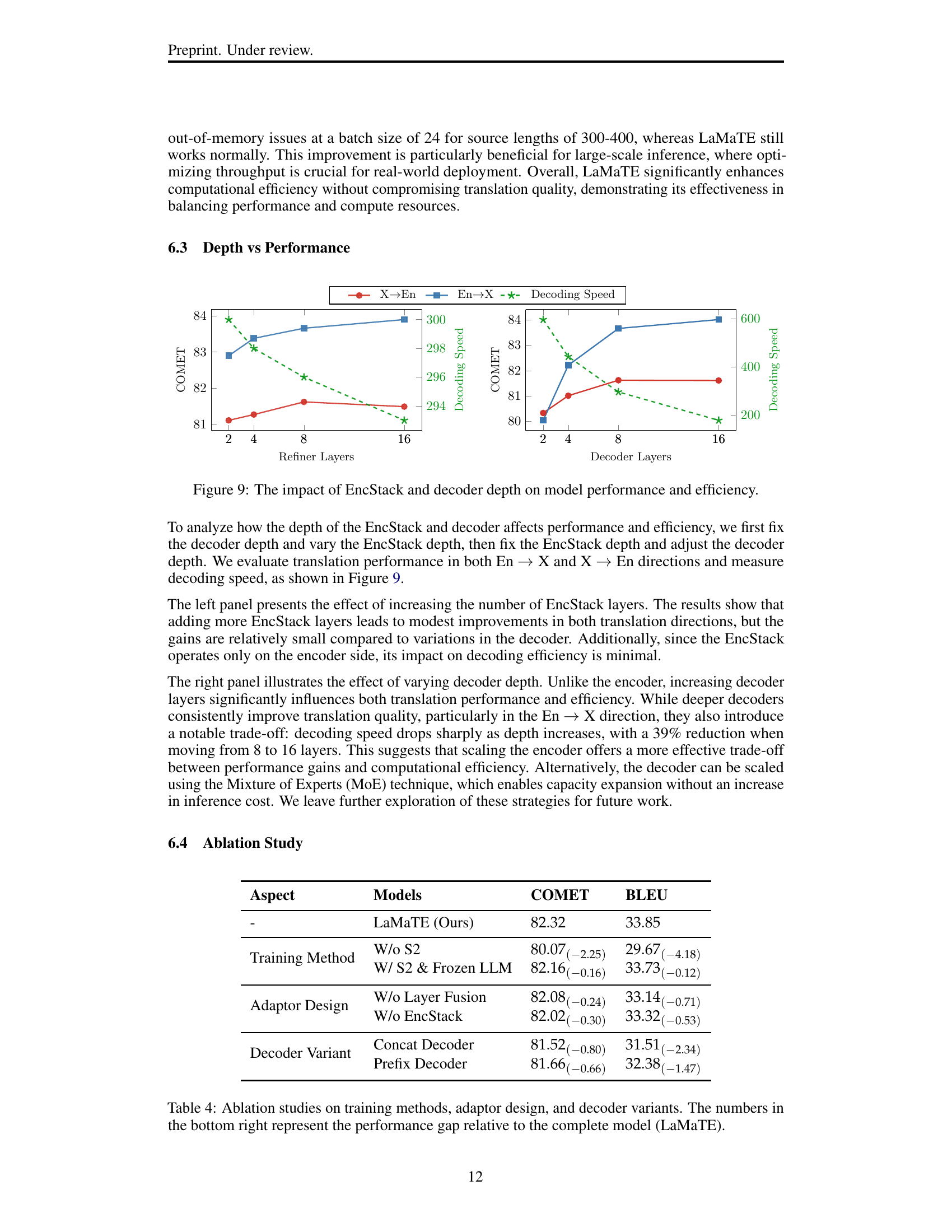
🔼 This figure analyzes how the depth of the EncStack (encoder stack within the adaptor) and the decoder affects both the model’s performance and efficiency. The left panel shows the impact of increasing the number of EncStack layers, while keeping the decoder’s depth fixed. The right panel reverses this, showing the effect of increasing the number of decoder layers, with the EncStack’s depth fixed. The figure plots translation quality (COMET score) and decoding speed against the number of layers for both the EncStack and decoder. This allows for a direct comparison of how changes in depth for each component influence the model’s translation capabilities and inference speed, enabling a discussion on optimal architectural choices regarding depth for balancing performance and efficiency.
read the caption
Figure 9: The impact of EncStack and decoder depth on model performance and efficiency.

🔼 This figure compares two different neural network architectures commonly used in machine translation: the encoder-decoder model and the decoder-only model. The encoder-decoder model consists of two main components: an encoder that processes the input sequence and a decoder that generates the output sequence based on the encoder’s output. The decoder-only model, on the other hand, uses only a decoder to process both the input and output sequences. This figure visually depicts the key structural differences between these two architectures.
read the caption
Figure 10: The Encoder-Decoder and Decoder-only architecture.

🔼 This figure illustrates three decoder architectures used in machine translation. The standard ‘Cross Decoder’ utilizes cross-attention to integrate source information. The ‘Concat Decoder’ omits cross-attention and integrates source information directly into the self-attention mechanism, while the ‘Prefix Decoder’ integrates source information early via fusion methods before self-attention.
read the caption
Figure 11: Three variants of decoders: Cross Decoder is the standard decoder, while Concat Decoder and Prefix Decoder remove the cross-attention sublayer, integrating source information through self-attention and early fusion methods, respectively.
More on tables
| Hyperparameter | Stage1 | Stage2 |
| Learning Rate | 5e-4 | 2e-5 |
| Adam | (0.9, 0.999) | (0.9, 0.999) |
| LR Scheduler | inverse_sqrt | cosine |
| Number of Epochs | 1 | 1 |
| Global Batch Size | 2,560 | 384 |
| Train Steps | 30,000 | 1,200 |
| Warmup Ratio | 0.01 | 0.01 |
| Weight Decay | 0.01 | 0.01 |
| Decoding Method | beam search | |
| Beam Size | 5 | |
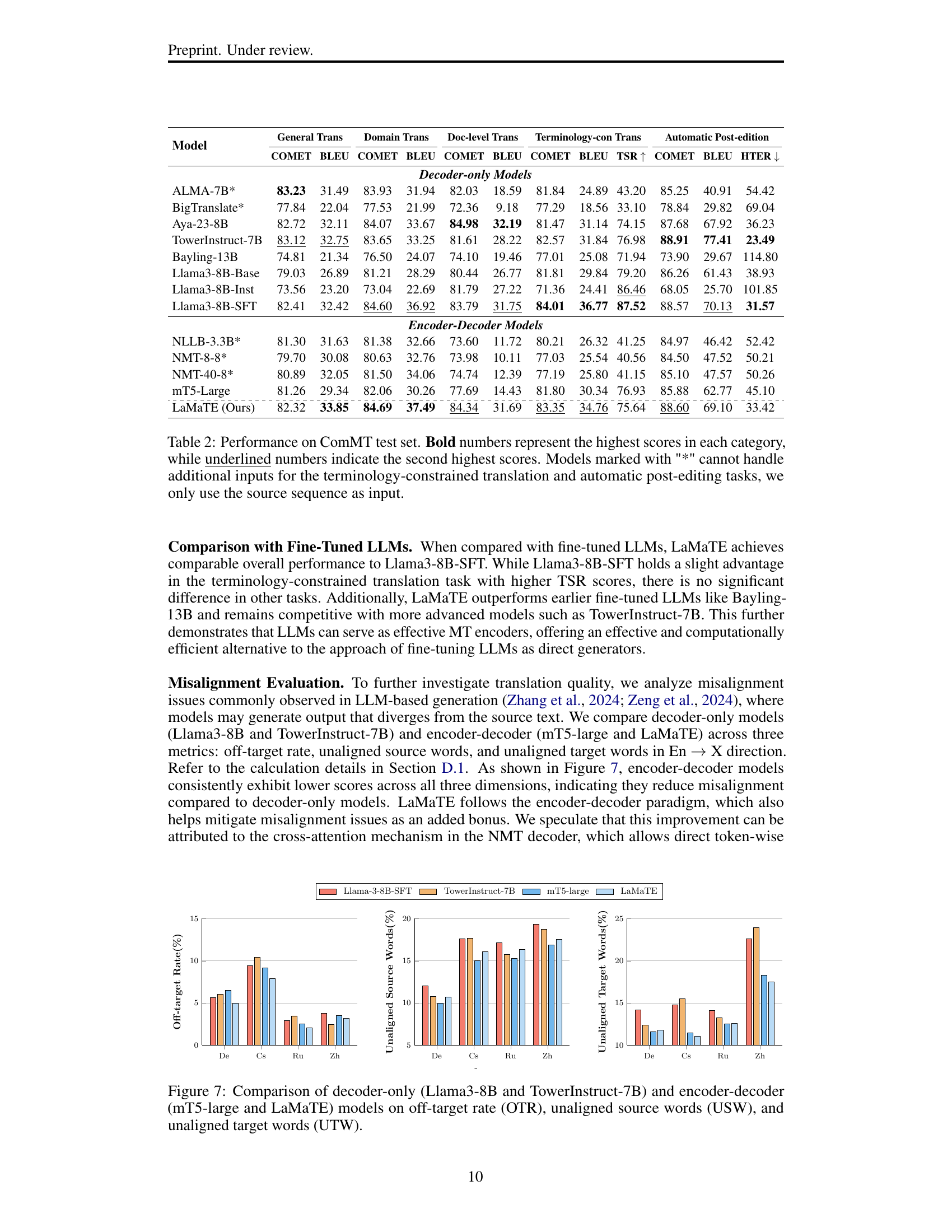
🔼 This table presents the results of the Comprehensive Machine Translation (ComMT) benchmark evaluation. It shows the performance of various machine translation models, including decoder-only and encoder-decoder architectures, across five different translation tasks. The performance is measured using COMET and BLEU scores. Bold numbers highlight the best scores for each task and language pair, while underlined numbers show the second best scores. Note that some models could not utilize additional inputs (such as prompts or terminology constraints) for specific tasks; for those models, only source sequence inputs were used.
read the caption
Table 2: Performance on ComMT test set. Bold numbers represent the highest scores in each category, while underlined numbers indicate the second highest scores. Models marked with '*' cannot handle additional inputs for the terminology-constrained translation and automatic post-editing tasks, we only use the source sequence as input.
| General Translation Model En2De En2Cs En2Ru En2Zh De2En COMET BLEU COMET BLEU COMET BLEU COMET BLEU COMET BLEU NLLB-3.3B 79.62 33.51 88.06 36.79 83.74 29.03 79.66 34.84 81.35 35.42 BigTranslate 70.27 14.59 83.45 23.50 79.46 19.04 80.60 30.99 79.36 26.43 Aya-23-8B 82.27 34.13 87.25 32.02 83.92 26.41 84.03 41.39 84.29 41.24 TowerInstruct-7B 83.10 35.00 78.88 17.41 85.39 29.81 85.93 42.66 85.15 44.33 Bayling-13B 70.03 15.97 68.15 14.34 64.22 12.38 81.88 37.89 81.39 27.85 NMT-8-8 77.18 29.16 85.54 35.94 79.48 25.43 80.29 38.78 81.33 33.33 NMT-40-8 78.42 31.81 86.91 38.04 80.65 26.07 82.05 40.73 82.85 36.99 mT5-Large 78.83 30.74 84.22 30.08 81.62 24.10 83.59 36.89 82.93 37.12 Llama3-8B-Base, 3-shot 73.82 18.61 81.63 24.34 80.17 23.20 81.89 39.51 80.45 32.84 Llama3-8B-Inst, 0-shot 78.81 29.01 77.46 22.29 80.21 22.67 67.46 18.51 74.40 33.20 Llama3-8B-SFT 82.66 37.76 85.80 29.64 83.94 27.03 83.72 40.66 83.76 40.62 LaMaTE-s1 77.73 29.96 85.31 33.22 79.19 24.16 80.88 39.61 82.12 33.39 LaMaTE-s2 80.68 37.59 86.54 35.34 82.45 26.93 84.05 45.98 83.75 41.41 |
| Model Ru2En Zh2En Avg. En X Avg. X En COMET BLEU COMET BLEU COMET BLEU COMET BLEU NLLB-3.3B 80.70 31.59 77.44 22.14 82.77 33.54 79.83 29.72 ALMA-7B 82.46 31.52 79.45 22.77 84.28 31.33 82.18 31.66 BigTranslate 76.84 23.43 75.48 16.29 78.45 22.03 77.23 22.05 Aya-23-8B 81.38 29.92 77.54 21.03 84.37 33.49 81.07 30.73 TowerInstruct-7B 83.18 34.54 80.36 23.99 83.33 31.22 82.90 34.29 Bayling-13B 77.34 21.12 76.89 18.59 71.07 20.15 78.54 22.52 NMT-8-8 78.84 29.13 76.15 21.04 80.62 32.33 78.77 27.83 NMT-40-8 79.83 30.28 76.63 22.56 82.01 34.16 79.77 29.94 mT5-Large 80.42 27.85 77.97 19.73 82.07 30.45 80.44 28.23 Llama3-8B-Base, 3-shot 80.17 30.14 75.38 19.08 79.38 26.42 78.67 27.35 Llama3-8B-Inst, 0-shot 70.55 21.49 68.44 15.12 75.99 23.12 71.13 23.27 Llama3-8B-SFT 81.66 31.88 76.97 20.70 84.03 33.77 80.80 31.07 LaMaTE-s1 79.56 29.18 76.40 20.22 80.78 31.74 79.36 27.60 LaMaTE-s2 80.97 30.29 78.87 22.02 83.43 36.46 81.20 31.24 |
| Domain Translation(COMET) Model Medical Law IT De2En En2De Ru2En En2Ru Zh2En En2Zh Cs2En En2De En2Cs En2Ru En2Cs NLLB-3.3B 87.32 86.65 84.49 88.71 84.29 85.29 88.20 86.89 89.88 86.81 92.09 ALMA-7B 87.06 86.10 84.56 88.02 84.83 85.66 87.57 85.45 88.94 86.60 92.35 BigTranslate 84.79 82.63 81.04 80.14 81.70 84.17 85.61 83.26 88.03 78.57 84.08 Aya-23-8B 87.15 85.88 84.08 88.04 84.82 86.49 87.71 86.31 89.24 87.19 92.97 TowerInstruct-7B 87.51 86.89 85.44 87.77 85.40 87.08 87.15 86.27 82.14 85.27 84.86 Bayling-13B 85.62 80.11 82.47 64.29 83.00 85.03 84.12 75.39 70.65 66.26 75.52 mT5-Large 86.37 85.01 83.24 86.63 82.90 85.86 86.56 84.16 86.85 84.93 91.49 NMT-8-8 87.12 86.69 83.85 86.93 83.61 85.46 87.76 87.98 91.14 83.17 92.73 NMT-40-8 87.50 87.03 84.74 87.79 84.42 86.09 88.21 88.28 91.78 83.03 93.25 Llama3-8B-Base, 3-shot 85.14 83.32 83.11 84.61 82.46 83.96 86.57 79.46 82.13 84.43 88.48 Llama3-8B-Inst, 0-shot 73.47 84.79 74.20 85.72 74.58 75.20 66.78 83.59 81.95 84.20 86.25 Llama3-8B-SFT 86.65 85.86 83.95 88.94 84.85 87.69 88.07 85.53 88.18 88.88 92.84 LaMaTE 87.10 86.39 84.36 88.95 84.36 88.73 87.68 87.70 91.36 89.48 93.86 |
| Model Colloquial Literature Avg. COMET Avg. COMET De2En En2De Ru2En En2Ru Zh2En En2Zh De2En Ru2En Zh2En En2Zh En X X En NLLB-3.3B 87.09 81.32 82.75 78.94 80.69 85.04 63.65 65.98 59.98 65.94 84.32 78.44 ALMA-7B 88.65 82.55 85.86 84.26 83.13 86.86 74.75 72.17 72.27 76.54 85.76 82.09 BigTranslate 82.68 69.91 74.72 66.70 79.57 82.05 67.78 57.47 62.22 72.72 79.30 75.76 Aya-23-8B 89.18 83.50 86.61 84.90 83.18 87.56 74.77 72.45 68.68 77.01 86.28 81.86 TowerInstruct-7B 88.48 81.73 86.66 82.12 82.45 86.79 75.44 73.29 75.38 79.37 84.57 82.72 Bayling-13B 85.94 71.40 81.97 59.95 80.22 82.73 73.92 69.36 71.30 73.87 73.20 79.79 mT5-Large 87.08 78.05 83.92 80.69 80.73 86.85 71.22 69.09 68.30 75.36 84.17 79.94 NMT-8-8 87.79 78.19 83.20 77.54 79.55 84.52 62.26 64.20 51.11 71.86 84.20 77.05 NMT-40-8 88.98 79.76 84.45 79.28 80.53 86.09 63.82 66.56 48.39 75.10 85.23 77.76 Llama3-8B-Base, 3-shot 86.74 75.46 85.39 80.81 78.91 79.51 75.56 72.82 70.58 76.32 81.68 80.73 Llama3-8B-Inst, 0-shot 61.97 73.28 62.26 81.34 57.89 58.92 70.70 69.35 72.04 60.14 77.76 68.32 Llama3-8B-SFT 89.20 85.02 86.75 85.46 81.00 84.73 77.33 75.62 72.26 79.75 86.63 82.57 LaMaTE 88.76 83.01 85.58 82.84 82.75 87.53 75.17 72.15 74.54 78.51 87.12 82.25 |
| Domain Translation(BLEU) Model Medical Law IT De2En En2De Ru2En En2Ru Zh2En En2Zh Cs2En En2De En2Cs En2Ru En2Cs NLLB-3.3B 42.09 33.26 44.36 33.54 31.29 36.81 46.54 48.74 50.43 35.83 33.94 ALMA-7B 41.25 30.20 41.06 28.97 33.32 36.75 42.46 36.61 35.95 33.21 31.69 BigTranslate 32.69 22.00 29.48 18.81 23.56 31.56 37.05 30.83 37.70 20.34 20.5 Aya-23-8B 41.82 30.05 41.01 28.83 32.63 39.09 43.92 42.46 42.64 35.59 34.20 TowerInstruct-7B 43.83 33.71 46.31 32.37 36.13 42.04 43.18 41.83 19.25 33.04 19.03 Bayling-13B 35.04 23.28 32.82 13.71 27.43 36.40 31.26 25.50 18.74 19.31 15.14 mT5-Large 38.44 27.88 36.80 27.38 28.16 34.86 38.61 39.24 39.42 34.08 33.81 NMT-8-8 43.71 34.21 42.18 31.68 33.36 38.55 43.68 49.85 52.75 34.06 38.86 NMT-40-8 44.14 35.43 43.40 32.48 35.28 39.82 46.12 51.68 54.17 33.26 40.33 Llama3-8B-Base, 3-shot 37.89 25.20 37.57 24.07 29.33 30.84 39.71 30.64 26.62 31.98 23.74 Llama3-8B-Inst, 0-shot 27.21 28.33 28.12 26.47 22.31 18.24 22.53 35.31 29.54 32.75 25.40 Llama3-8B-SFT 41.70 30.53 42.70 36.18 36.24 45.76 49.07 41.08 39.90 40.96 36.77 LaMaTE 41.98 32.74 42.04 37.64 32.76 48.97 45.16 47.96 50.83 42.23 45.64 |
| Model Colloquial Literature Avg. BLEU Avg. BLEU De2En En2De Ru2En En2Ru Zh2En En2Zh De2En Ru2En Zh2En En2Zh En X X En NLLB-3.3B 48.09 42.90 32.44 20.69 20.94 33.72 14.51 20.69 5.24 11.76 34.69 30.62 ALMA-7B 49.19 38.16 37.63 26.41 22.20 32.15 22.77 24.04 12.13 13.88 31.27 32.61 BigTranslate 32.92 20.54 19.81 8.45 15.15 24.08 14.91 7.68 3.74 10.05 22.27 21.70 Aya-23-8B 50.86 42.54 40.04 28.84 21.36 35.65 23.65 25.38 10.57 16.48 34.22 33.12 TowerInstruct-7B 53.77 42.61 39.68 26.95 22.65 34.11 24.35 27.79 15.06 18.49 31.22 35.28 Bayling-13B 43.73 28.55 27.45 12.25 20.46 30.57 20.23 18.10 9.61 13.41 21.53 26.61 mT5-Large 49.23 36.53 32.27 24.05 21.39 31.40 19.02 20.99 9.37 13.18 31.08 29.43 NMT-8-8 50.55 41.63 32.31 23.74 21.32 33.79 11.61 16.73 4.74 11.34 35.50 30.02 NMT-40-8 54.16 43.43 34.32 24.53 21.83 33.75 13.06 18.45 4.60 13.52 36.58 31.54 Llama3-8B-Base, 3-shot 46.09 28.92 36.14 23.83 18.16 25.50 24.24 25.13 11.30 14.75 26.01 30.56 Llama3-8B-Inst, 0-shot 22.55 32.94 16.55 25.04 9.10 11.21 21.02 24.38 11.75 7.75 24.82 20.55 Llama3-8B-SFT 55.53 49.83 41.79 31.01 22.28 28.71 30.50 36.33 16.36 21.76 36.59 37.25 LaMaTE 53.41 48.91 36.94 29.80 24.42 38.41 25.60 26.40 16.49 21.82 40.45 34.52 |
| Doc-level Translation Model De2En En2De En2Ru Zh2En En2Zh d-COMET d-BLEU d-COMET d-BLEU d-COMET d-BLEU d-COMET d-BLEU d-COMET d-BLEU NLLB-3.3B 74.01 11.75 73.19 14.56 78.10 7.37 68.34 11.14 70.17 18.58 ALMA-7B 83.73 25.58 81.10 20.14 85.93 14.29 76.53 20.97 80.56 16.26 BigTranslate 74.77 9.04 68.47 9.80 71.34 5.61 68.01 8.48 80.24 22.46 Aya-23-8B 86.10 39.87 85.19 28.92 89.15 25.79 76.61 28.05 82.31 33.04 TowerInstruct-7B 85.86 37.74 83.41 25.61 80.93 18.57 82.53 38.88 81.47 22.22 Bayling-13B 84.71 30.56 72.55 17.50 45.83 4.82 78.62 23.69 79.92 20.90 mT5-Large 79.29 17.04 71.22 10.69 78.99 7.28 74.71 18.11 80.97 22.73 NMT-8-8 74.80 10.94 71.76 9.78 74.49 3.58 69.76 16.00 74.33 11.18 NMT-40-8 76.69 14.04 71.40 11.78 74.33 4.72 69.89 17.26 75.75 13.37 Llama3-8B-Base, 3-shot 34.42 81.76 19.31 75.99 15.26 81.27 29.39 76.52 31.71 83.67 Llama3-8B-Inst, 0-shot 83.01 33.97 82.89 24.09 84.27 19.32 81.91 36.35 70.12 15.48 Llama3-8B-SFT 84.87 35.07 81.62 26.35 85.25 21.78 80.62 40.85 86.25 38.08 LaMaTE 83.52 32.69 82.17 27.45 87.02 22.56 82.68 39.65 83.50 37.56 |
| Model En2Cs Cs2En Avg. En X Avg. X En d-COMET d-BLEU d-COMET d-BLEU d-COMET d-BLEU d-COMET d-BLEU NLLB-3.3B 78.43 10.41 74.34 9.24 74.97 12.73 72.23 10.71 ALMA-7B 84.74 12.38 82.69 17.71 83.08 15.77 80.98 21.42 BigTranslate 68.86 3.98 74.65 6.17 72.23 10.46 72.48 7.90 Aya-23-8B 88.44 24.36 88.33 41.14 86.27 28.03 83.68 36.35 TowerInstruct-7B 66.40 8.22 87.13 36.69 78.05 18.66 85.17 37.77 Bayling-13B 62.70 7.80 85.48 24.23 65.25 12.76 82.94 26.16 mT5-Large 77.80 7.24 80.39 15.45 77.25 11.99 78.13 16.87 NMT-8-8 77.24 7.73 75.92 9.48 74.46 8.07 73.49 12.14 NMT-40-8 78.54 10.54 76.81 12.75 75.01 10.10 74.46 14.68 Llama3-8B-Base, 3-shot 13.67 77.69 36.83 85.34 19.99 79.66 33.55 81.21 Llama3-8B-Inst, 0-shot 83.53 18.99 85.23 34.60 80.20 19.47 83.38 34.97 Llama3-8B-SFT 83.21 19.49 84.98 35.28 84.08 26.43 83.49 37.07 LaMaTE 86.57 22.92 85.36 34.95 84.82 27.62 83.85 35.76 |
| Terminology-constrained Translation Model De2En En2De En2Ru Zh2En COMET BLEU TSR COMET BLEU TSR COMET BLEU TSR COMET BLEU TSR NLLB-3.3B 79.50 21.18 36.03 89.59 48.37 77.52 89.77 30.02 57.83 65.76 8.74 8.91 ALMA-7B 79.49 21.41 36.38 88.49 40.64 69.95 88.98 24.98 55.01 73.29 12.33 24.08 BigTranslate 77.88 18.06 32.25 83.85 29.16 58.41 81.29 17.44 40.16 66.59 7.16 12.55 Aya-23-8B 80.95 31.71 67.25 83.35 39.86 85.78 86.17 27.29 70.55 71.99 13.40 71.18 TowerInstruct-7B 81.35 31.09 66.27 88.85 46.57 87.54 89.39 30.85 73.50 73.28 15.43 78.84 Bayling-13B 81.33 29.76 70.28 81.58 33.65 84.10 66.44 12.46 51.24 70.96 12.03 74.29 mT5-large 81.74 33.70 76.34 87.50 42.76 88.30 87.79 25.71 66.55 71.20 12.44 76.15 NMT-8-8 78.80 21.26 35.62 89.37 47.79 77.14 87.34 27.85 55.24 55.58 6.16 8.53 NMT-40-8 79.35 21.75 36.56 89.45 47.99 76.83 88.64 27.92 55.24 54.37 5.97 8.80 Llama3-8B-Base, 3-shot 81.73 34.34 77.08 85.18 38.04 88.30 86.72 22.60 71.85 73.40 13.87 76.49 Llama3-8B-Inst, 0-shot 64.85 20.68 84.67 85.99 40.56 95.03 84.68 24.76 80.92 57.72 7.96 83.35 Llama3-8B-SFT 82.53 37.28 87.15 89.85 49.62 94.27 89.84 31.70 84.69 74.56 17.06 82.18 LaMaTE 81.83 33.03 71.05 90.17 52.12 90.90 89.53 32.59 72.79 72.71 13.91 75.05 |
| Model En2Zh En2Cs Avg. En X Avg. X En COMET BLEU TSR COMET BLEU TSR COMET BLEU TSR COMET BLEU TSR NLLB-3.3B 85.89 40.52 64.84 85.89 31.77 39.87 87.79 37.67 60.02 72.63 14.96 22.47 ALMA-7B 85.95 38.38 62.56 85.77 27.63 37.15 87.30 32.91 56.17 76.39 16.87 30.23 BigTranslate 83.19 32.19 50.24 80.99 19.24 26.39 82.33 24.51 43.80 72.24 12.61 22.40 Aya-23-8B 87.37 46.84 88.37 88.95 44.92 71.59 86.46 39.73 79.07 76.47 22.56 69.22 TowerInstruct-7B 87.42 48.68 90.45 85.67 35.56 74.10 87.83 40.42 81.40 77.32 23.26 72.56 Bayling-13B 85.46 42.96 92.87 77.95 27.96 58.11 77.86 29.26 71.58 76.15 20.90 72.29 mT5-Large 86.40 40.66 85.81 86.79 41.25 69.73 87.12 37.60 77.60 76.47 23.07 76.25 NMT-8-8 84.48 38.79 60.07 86.25 35.04 43.65 86.86 37.37 59.03 67.19 13.71 22.08 NMT-40-8 85.10 39.34 61.52 86.83 35.70 44.88 87.51 37.74 59.62 66.86 13.86 22.68 Llama3-8B-Base, 3-shot 85.62 40.65 90.59 86.68 40.98 75.64 86.05 35.57 81.60 77.57 24.11 76.79 Llama3-8B-Inst, 0-shot 72.46 32.78 95.36 82.60 39.90 84.29 81.43 34.50 88.90 61.29 14.32 84.01 Llama3-8B-SFT 89.44 56.76 96.06 88.69 47.34 86.45 89.46 46.36 90.37 78.55 27.17 84.67 LaMaTE 89.72 58.44 87.68 88.29 41.01 61.54 89.43 46.04 78.23 77.27 23.47 73.05 |
| Automatic Post-edition Model De2En En2De Ru2En En2Ru COMET BLEU HTER COMET BLEU HTER COMET BLEU HTER COMET BLEU HTER NLLB-3.3B 89.18 52.90 38.94 85.99 51.55 38.70 85.53 48.71 42.47 85.92 40.49 53.89 ALMA-7B 88.12 45.56 44.08 84.24 42.71 46.84 86.74 47.01 42.97 85.93 35.14 58.49 BigTranslate 85.70 42.44 51.04 75.70 24.55 68.72 78.43 30.62 59.87 77.21 21.55 75.29 Aya-23-8B 89.08 75.51 22.83 84.71 63.41 29.53 90.93 75.46 19.22 88.49 54.35 40.16 TowerInstruct-7B 88.98 80.62 17.06 85.64 71.84 20.87 91.64 81.49 14.41 91.13 75.32 19.14 Bayling-13B 84.89 39.59 63.14 74.17 29.85 76.56 78.77 28.56 92.13 51.54 7.89 218.99 mT5-large 88.34 73.97 21.57 85.15 70.13 22.17 89.25 70.37 26.23 81.60 35.31 86.20 NMT-8-8 89.46 52.67 36.74 84.50 50.25 39.38 85.05 51.81 37.90 84.70 43.46 49.92 NMT-40-8 89.60 53.55 36.43 84.88 50.39 39.55 86.10 53.23 36.46 85.12 39.98 52.69 Llama3-8B-Base, 3-shot 88.15 61.72 33.26 84.06 59.78 32.26 86.97 66.00 29.09 88.84 62.54 32.92 Llama3-8B-Inst, 0-shot 61.70 23.09 94.49 78.79 36.02 59.94 55.35 17.51 112.49 79.42 20.86 95.40 Llama3-8B-SFT 90.08 78.05 19.53 86.56 66.46 26.00 90.34 75.15 20.76 91.36 69.48 25.77 LaMaTE 90.50 76.86 21.03 86.07 64.63 25.80 91.04 75.13 19.88 90.89 68.24 26.72 |
| Model En2Zh Avg. En X Avg. X En COMET BLEU HTER COMET BLEU HTER COMET BLEU HTER NLLB-3.3B 75.87 34.04 99.76 82.59 42.03 64.12 87.36 50.81 40.71 ALMA-7B 79.05 28.71 90.65 83.07 35.52 65.33 87.43 46.29 43.52 BigTranslate 73.91 23.21 103.89 75.61 23.10 82.63 82.07 36.53 55.45 Aya-23-8B 82.84 63.29 84.56 85.35 60.35 51.42 90.01 75.49 21.03 TowerInstruct-7B 85.73 74.12 53.72 87.50 73.76 31.24 90.31 81.06 15.74 Bayling-13B 72.20 38.00 160.32 65.97 25.25 151.96 81.83 34.08 77.64 mT5-Large 82.15 54.63 90.52 82.97 53.36 66.30 88.80 72.17 23.90 NMT-8-8 75.99 34.69 99.98 81.73 42.80 63.09 87.26 52.24 37.32 NMT-40-8 77.08 34.85 100.00 82.36 41.74 64.08 87.85 53.39 36.44 Llama3-8B-Base, 3-shot 81.94 54.66 74.88 84.95 58.99 46.68 87.56 63.86 31.17 Llama3-8B-Inst, 0-shot 74.51 36.41 145.27 77.57 31.10 100.20 58.53 20.30 103.49 Llama3-8B-SFT 82.91 55.08 77.20 86.94 63.67 42.99 90.21 76.60 20.14 LaMaTE 82.35 53.76 86.66 86.43 62.21 46.39 90.77 76.00 20.45 |
🔼 Table 3 presents BLEU scores on the FLORES-200 devtest set for various machine translation models. The models were trained using data from OPUS-100, which includes 99 languages. The languages are categorized into four resource levels based on the amount of training data available: high-resource (HRL), medium-resource (MRL), low-resource (LRL), and very low-resource (XRL). The numbers in parentheses after each resource level indicate the number of languages in that category.
read the caption
Table 3: BLEU performance evaluated on the FLORES-200 devtest set, with models trained on OPUS-100 data (99 languages). HRL, MRL, LRL, and XRL represent high, medium, low, and very low-resource languages, respectively. The bracketed numbers indicate the count of languages.
| Data Set | Language | Task |
|---|---|---|
| WMT 14-23-news777https://www.statmt.org/wmt21/translation-task.html. | Cs, De, Ru, Zh | GT |
| WMT 16-21-ape888https://www.statmt.org/wmt21/ape-task.html. | De, Ru, Zh | APE |
| WMT 20,22-chat999https://www.statmt.org/wmt20/chat-task.html. | De | DT(colloquial) |
| WMT 14, 18-22-medical101010https://www.statmt.org/wmt21/biomedical-translation-task.html. | Cs, De, Ru, Zh | DT(medical) |
| WMT 16-it111111https://statmt.org/wmt16/it-translation-task.html. | Cs, De | DT(it) |
| WMT 20-robustness121212https://statmt.org/wmt20/robustness.html. | De | DT(colloquial) |
| WMT 21, 23-terminology131313https://statmt.org/wmt21/terminology-task.html. | Cs, De, Ru, Zh | TCT |
| WMT 23-literary | Zh | DLT |
| IWSLT 14-17141414https://wit3.fbk.eu/2014-01. | Cs, De, Ru, Zh | DLT |
| IWSLT 16151515https://wit3.fbk.eu/2016-02. | De | APE |
| IWSLT23_OPUS_OpenSubtitles 161616https://iwslt.org/2024/subtitling. | De | GT, DT(colloquial) |
| news-commentary-v18 171717https://data.statmt.org/news-commentary/v18.1/training/. | Cs, De, Ru, Zh | DCL |
| GlobalVoices 181818https://opus.nlpl.eu/GlobalVoices/corpus/version/GlobalVoices. | Cs, De, Ru | GT |
| DiscoMT191919https://www.idiap.ch/webarchives/sites/www.idiap.ch/workshop/DiscoMT/. | De | DCL |
| frmt (Riley et al., 2022) | Zh | GT |
| PAWS-X (Yang et al., 2019) | De, Zh | GT |
| XNLI-15way (Conneau et al., 2018) | De, Ru, Zh | GT |
| NTREX128 (Federmann et al., 2022) | Cs, De, Ru, Zh | GT |
| CommonMT (He et al., 2020) | Zh | GT, APE |
| BMELD (Liang et al., 2021) | Zh | DT(colloquial) |
| par3 (Karpinska et al., 2022b) | Cs, De, Ru, Zh | DLT, DT(literature) |
| BWB (Jiang et al., 2023) | Zh | DLT, DT(literature) |
| UM-corpus (Tian et al., 2014) | Zh | GT, DT(law, literature) |
| mZPRT (Xu et al., 2022) | Zh | DLT, DT(colloquial, literature) |
| tico19 (Anastasopoulos et al., 2020) | Ru, Zh | GT |
| FGraDA (Zhu et al., 2021) | Zh | GT |
| NLLB (Costa-jussà et al., 2022) | Ru | GT, DT(colloquial) |
| MULTI30k (Elliott et al., 2016) | Cs, De | GT |
| FLORES-200 (Costa-jussà et al., 2022) | Cs, De, Ru, Zh | GT |
| localization-xml-mt | De, Ru, Zh | DT(it) |
| (Hashimoto et al., 2019) | ||
| DEMETR (Karpinska et al., 2022a) | De, Ru, Zh | APE |
| mlqe-pe (Fomicheva et al., 2020) | De, Ru, Zh | APE |
| XQUAD (Artetxe et al., 2019) | De, Ru, Zh | GT |
| p2p-data (Jin et al., 2023b) | Zh | DLT, DT(literature) |
| NEJM (Liu & Huang, 2021) | Zh | DT(medical) |
| DGT-TM (Steinberger et al., 2013) | Cs, De | DT(law) |
| health_term (Xu & Carpuat, 2021) | De | TCT |
| XCOPA (Ponti et al., 2020) | Zh | GT |
| MINTAKA (Sen et al., 2022) | De | GT |
| MGSM (Shi et al., 2023) | De, Ru, Zh | GT |
| MSLT (Federmann & Lewis, 2017) | Zh | DT(colloquial) |
| Perseus (Zheng et al., 2023) | Zh | GT, DLT, DT(it, medical) |
| BiPaR (Jing et al., 2019) | Zh | DLT, DT(literature) |
| XStoryCloze (Lin et al., 2021) | Ru, Zh | GT, DT(literature) |
| RELX (Köksal & Özgür, 2020) | De | GT |
| PETCI (Tang, 2022) | Zh | GT, ICL |
| QALD-9-Plus (Perevalov et al., 2022) | De, Ru | GT |
| SubEdits (Chollampatt et al., 2020) | De | APE |
| hallucinations-in-nmt | De | APE |
| (Guerreiro et al., 2023) | ||
| good-translation-wrong-in-context | Ru | GT, ICL, DT(colloquial) |
| (Voita et al., 2019) | ||
| CoCoA-MT (Nădejde et al., 2022) | De, Ru | GT, DT(colloquial) |
| unfaithful(Zhang et al., 2024) | De, Zh | GT |
| ContraPro (Müller et al., 2018) | De | GT, APE, DT(colloquial) |
| LiteraryTranslation | Cs, De, Ru, Zh | DLT, DT(literature) |
| (Karpinska & Iyyer, 2023) | ||
| ctxpro (Wicks & Post, 2023) | De, Ru | GT, ICL, DT(colloquial) |
| DeCOCO (Hitschler et al., 2016) | De | GT |
| IdiomsInCtx-MT (Stap et al., 2024) | De, Ru | GT, ICL |
| Books 202020https://opus.nlpl.eu/Books/corpus/version/Books | De, Ru | DLT, DT(literature) |
| EUbookshop 212121https://opus.nlpl.eu/EUbookshop/corpus/version/EUbookshop | Cs, De, Ru | DLT |
| TED2020 (Reimers & Gurevych, 2020) | Cs, De, Ru | DLT |
🔼 This table presents the results of ablation studies conducted on the LaMaTE model. The studies evaluate the impact of different training methods (two-stage training vs. single-stage, with and without frozen LLM parameters), adaptor designs (with and without layer fusion, with and without EncStack), and decoder variants (standard cross-attention decoder vs. concatenation decoder vs. prefix decoder) on the model’s performance. The COMET and BLEU scores are reported for each ablation study, and the numbers in parentheses show the performance differences compared to the complete LaMaTE model, allowing easy comparison and visualization of the impact of each component.
read the caption
Table 4: Ablation studies on training methods, adaptor design, and decoder variants. The numbers in the bottom right represent the performance gap relative to the complete model (LaMaTE).
| General translation Prompt: Translate the following text from English into Chinese. English: I know that advertising is how they make their money, but all that garbage seems counterproductive if it drives people away. Chinese: 我知道广告是为他们创收的一种方式,而如果大量的广告让观众反感离开,似乎会适得其反。 |
| Doc-level translation Prompt: Translate the following text from English into Chinese. English: The outliers tend to be those who die young, so that typical (median) life expectancy is higher than average life expectancy. This means that raising the average HLE can be achieved by raising the HLE of those at the bottom of the health distribution to that of the typical (median) person. This not only makes targeting inequality more attractive, but does not require path-breaking medical innovations to achieve longer lifespans – just the achievement of typical outcomes for more people. With this in mind, it is urgent to close the sizeable rich-poor life-expectancy gap – around 15 years – in the United States. As a metric for economic and social progress, targeting HLE implicitly acknowledges that aging is malleable (if it wasn’t, it wouldn’t be a viable target). It turns out that a range of behaviors and policies, as well as the environment we inhabit, influence how we age and how long we live. It is estimated that our genetics account for only one-quarter of the factors contributing to how we age. Given this malleability, it is crucial that governments focus on HLE for the maximum number of people. Such a focus would also help governments confront one of the biggest challenges of the future: societal aging. Given that every country in the world is expected to experience societal aging, focusing on how well we age becomes paramount. This age malleability requires drawing a distinction between chronological and biological measures of age and focusing on the latter. Chinese: 反常之处便是那些年纪轻轻便死去的人,他们让典型(中位)寿命预期长于平均寿命预期。这意味着提高平均健康寿命预期可以通过将位于健康分布底层的人变成典型(中位)健康寿命预期的人来实现。这不仅让针对不平等性问题变得更有吸引力,也不必一定需要突破性的医学创新才能实现生命周期的延长——而只需要让更多人实现典型结果。基于此,现在迫切需要缩小美国庞大的贫富寿命预期差距——大约在15年左右。作为一个经济和社会进步的指标,健康寿命预期间接承认衰老具有可塑性(若非如此的话,这就不是一个可行的目标)。一系列行为和政策,以及我们所居住的环境,都影响着我们如何变老和如何延长我们的寿命。据估计,我们的器官大约占我们衰老的四分之一因素。考虑到这一可塑性,政府必须关注最大数量人口的见刊寿命预期。关注这一点也有助于政府面对未来最巨大的挑战之一:社会老龄化。世界上每一个国家都会经历社会老龄化,关注我们以多么优秀的方式衰老变得至关重要。这一年龄可塑性需要区分年龄的时间和生物指标,专注于后者。 |
| Domain translation Domain: Medical Prompt: Translate the following text from English into Chinese. English: The median age of the 30 patients was 56.5 (28-80) years old, among them, 25 patients were primary plasma cell leukemia, and 5 patients were secondary plasma cell leukemia. Chinese: 30例PCL患者中位年龄56.5(28-80)岁,25例为原发性浆细胞白血病,5例为继发性浆细胞白血病。 |
| Domain: Law Prompt: Translate the following text from English into Chinese. English: Article 8 Small and medium-sized enterprises shall observe the laws and regulations of the State on labor safety, occupational health, social security, protection of resources and environment, quality, taxation and finance, etc. and shall operate and manage according to law, and may not infringe upon the legitimate rights and interests of the employees or damage the public interests. Chinese: 第八条 中小企业必须遵守国家劳动安全、职业卫生、社会保障、资源环保、质量、财政税收、金融等方面的法律、法规,依法经营管理,不得侵害职工合法权益,不得损害社会公共利益。 |
| Domain: IT Prompt: Translate the following text from English into Chinese. English: If you are using a Customer Portal and want to allow self-registration, follow these steps: Chinese: 如果您正使用客户入口网站并希望允许自助注册,请按以下步骤操作: Domain: Colloquial Prompt: Translate the following text from English into Chinese. English: Believe me, I’m gonna take care of you and he’s gonna be OK. Chinese: 相信我,我会照顾好你们,他会没事的. |
| Domain: Literature Prompt: Translate the following text from English into Chinese. English: The President required the name of that citizen. The accused explained that the citizen was his first witness. He also referred with confidence to the citizen’s letter, which had been taken from him at the Barrier, but which he did not doubt would be found among the papers then before the President. Chinese: 庭长问那公民是谁。被告说那公民便是他的第一个证人。他还很有把握地提起那人的信,那是在城门口从他身上取走的,他相信可以在庭长的卷宗中找到。 |
| Terminology-constrained translation Prompt: Translate the following text from English into Chinese using the provided terminology pairs, ensuring the specified terms are accurately translated as indicated. Terminology pairs: "National Football League" = "国家橄榄球联盟" English: Tim’s younger brother, Tod Leiweke, is currently the chief operating officer of the National Football League since 2015. Chinese: 蒂姆的弟弟托德·莱维克自 2015 年以来担任国家橄榄球联盟的首席运营官。 |
| Automatic post-edition Prompt: Improve the following machine-generated translation from English to Chinese. Correct errors and generate a more accurate translation. English: unfazed, Matteo hires an assassin to bomb the resort to create chaos and mayhem. Chinese: 马特奥不慌不忙地雇用了一名刺客来轰炸制造混乱和混乱的手段. Improved translation: 马特奥不慌不忙地雇用了一名刺客来轰炸度假村,从而引起混乱。 |
🔼 This table compares the architectural elements of different machine translation models, specifically focusing on the encoder-decoder and decoder-only architectures. It details the connection types, fusion methods (how encoder and decoder outputs are combined), the presence of source and causal masks, and whether parameter sharing is utilized in the models.
read the caption
Table 5: Comparision of different architecture by analyzing their structural elements.
Full paper#