TL;DR#
Key Takeaways#
Why does it matter?#
This paper introduces a novel, efficient approach to enhance vision-language models, improving performance across various tasks. It offers a practical solution for reducing attention noise and boosting model accuracy with minimal computational cost, making it valuable for researchers aiming to improve VLM performance and robustness.
Visual Insights#

🔼 Figure 1 compares the performance of the original CLIP model and the proposed DiffCLIP model across six different vision-language tasks. The tasks include linear probing, a few-shot classification setting, image retrieval, text retrieval, zero-shot classification on the ImageNet dataset, and zero-shot classification on out-of-distribution (OOD) data. The results are presented using bar charts showing accuracy percentages. The original CLIP model is represented in blue, and the DiffCLIP model is represented in pink. In every task, DiffCLIP outperforms the baseline CLIP model, demonstrating that integrating the differential attention mechanism significantly improves performance without adding any considerable computational cost (only 0.003% extra parameters).
read the caption
Figure 1: CC3M Pretraining: CLIP vs. DiffCLIP Across Six Tasks. We compare standard CLIP (blue) and our DiffCLIP variant (pink) on linear probing, few-shot classification, image/text retrieval, zero-shot ImageNet, and zero-shot OOD. In each case, DiffCLIP consistently outperforms CLIP, highlighting the effectiveness of differential attention with only 0.003% extra parameters.
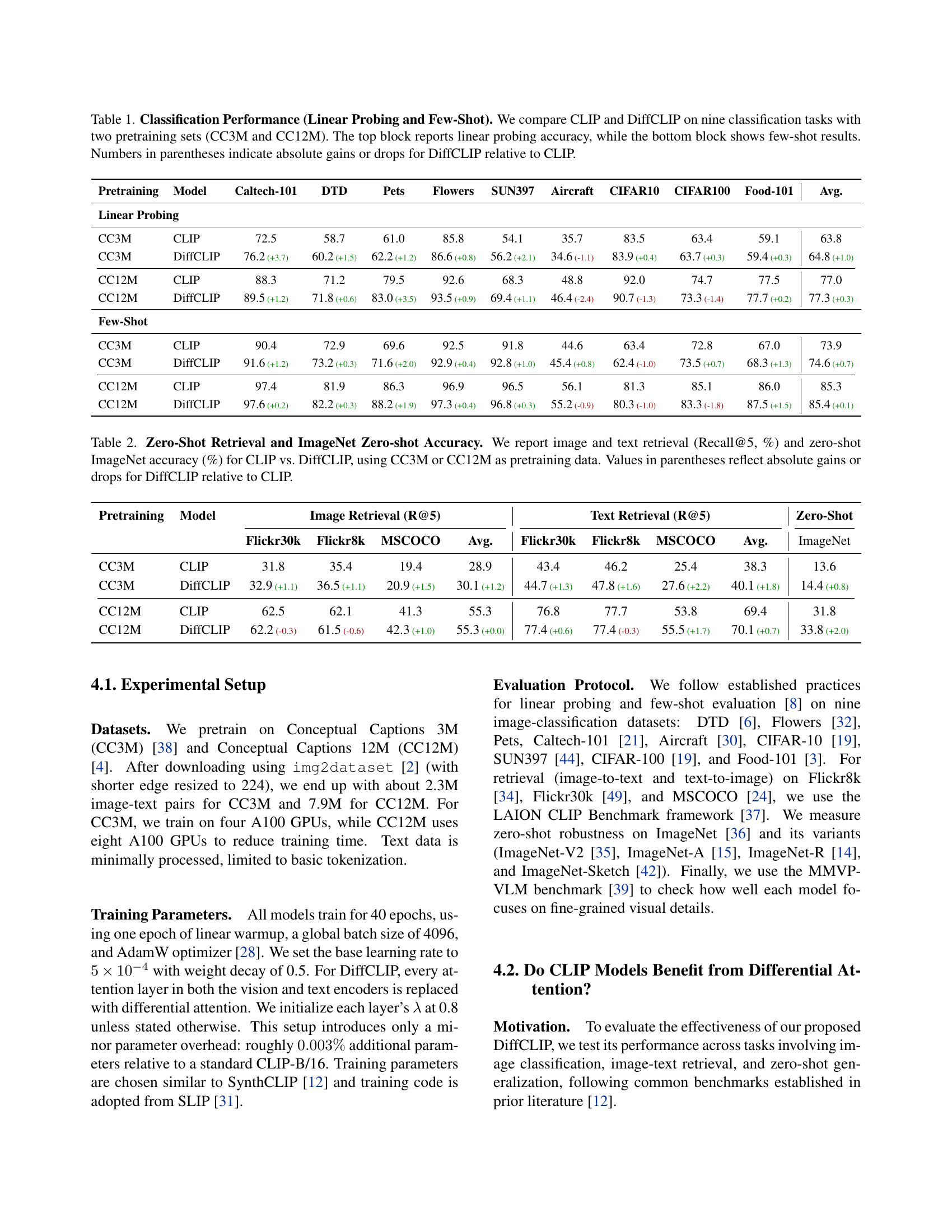
| Pretraining | Model | Caltech-101 | DTD | Pets | Flowers | SUN397 | Aircraft | CIFAR10 | CIFAR100 | Food-101 | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Linear Probing | |||||||||||
| CC3M | CLIP | 72.5 | 58.7 | 61.0 | 85.8 | 54.1 | 35.7 | 83.5 | 63.4 | 59.1 | 63.8 |
| CC3M | DiffCLIP | 76.2 (+3.7) | 60.2 (+1.5) | 62.2 (+1.2) | 86.6 (+0.8) | 56.2 (+2.1) | 34.6 (-1.1) | 83.9 (+0.4) | 63.7 (+0.3) | 59.4 (+0.3) | 64.8 (+1.0) |
| CC12M | CLIP | 88.3 | 71.2 | 79.5 | 92.6 | 68.3 | 48.8 | 92.0 | 74.7 | 77.5 | 77.0 |
| CC12M | DiffCLIP | 89.5 (+1.2) | 71.8 (+0.6) | 83.0 (+3.5) | 93.5 (+0.9) | 69.4 (+1.1) | 46.4 (-2.4) | 90.7 (-1.3) | 73.3 (-1.4) | 77.7 (+0.2) | 77.3 (+0.3) |
| Few-Shot | |||||||||||
| CC3M | CLIP | 90.4 | 72.9 | 69.6 | 92.5 | 91.8 | 44.6 | 63.4 | 72.8 | 67.0 | 73.9 |
| CC3M | DiffCLIP | 91.6 (+1.2) | 73.2 (+0.3) | 71.6 (+2.0) | 92.9 (+0.4) | 92.8 (+1.0) | 45.4 (+0.8) | 62.4 (-1.0) | 73.5 (+0.7) | 68.3 (+1.3) | 74.6 (+0.7) |
| CC12M | CLIP | 97.4 | 81.9 | 86.3 | 96.9 | 96.5 | 56.1 | 81.3 | 85.1 | 86.0 | 85.3 |
| CC12M | DiffCLIP | 97.6 (+0.2) | 82.2 (+0.3) | 88.2 (+1.9) | 97.3 (+0.4) | 96.8 (+0.3) | 55.2 (-0.9) | 80.3 (-1.0) | 83.3 (-1.8) | 87.5 (+1.5) | 85.4 (+0.1) |
🔼 This table presents a comparison of CLIP and DiffCLIP performance across nine image classification tasks. Two different pre-training datasets were used (CC3M and CC12M). The results are split into two sections: linear probing accuracy (evaluating the model’s ability to generalize with minimal fine-tuning) and few-shot learning accuracy (assessing performance with a small number of training examples). The numbers in parentheses show the difference in performance between DiffCLIP and CLIP for each task and dataset, indicating whether DiffCLIP improved or decreased accuracy.
read the caption
Table 1: Classification Performance (Linear Probing and Few-Shot). We compare CLIP and DiffCLIP on nine classification tasks with two pretraining sets (CC3M and CC12M). The top block reports linear probing accuracy, while the bottom block shows few-shot results. Numbers in parentheses indicate absolute gains or drops for DiffCLIP relative to CLIP.
In-depth insights#
Attn Noise Reduce#
The concept of reducing attention noise centers on improving model focus. Standard attention mechanisms, while effective, can distribute weight to irrelevant information, diluting the focus on key features. This is particularly detrimental in tasks requiring precision. Techniques to mitigate attention noise include differential attention, which learns complementary attention distributions and subtracts them, effectively canceling out spurious alignments. Reducing attention noise enhances model performance across various tasks, including image-text understanding and fine-grained visual understanding. Furthermore, it improves robustness to domain shifts, indicating that cleaner attention patterns lead to more generalizable features. Methods for noise reduction often involve minimal overhead, highlighting their efficiency in improving model focus.
DiffCLIP Details#
Based on the paper, DiffCLIP enhances CLIP by integrating differential attention, originally for language models, into its dual encoder (image/text) framework. Differential attention aims to amplify relevant context while suppressing noise. In CLIP, this means focusing on salient features in both images and text. The paper likely details how differential attention is implemented within the CLIP architecture, including the specific modifications to the attention mechanism within the Transformer blocks of both the vision and text encoders. It probably discusses the learnable parameters involved in differential attention, such as the λ parameter that controls the subtraction of the second attention distribution. The details likely cover the computational overhead. It explores initializing differential attention parameter and vision encoder being differential attention. A dynamic adjustment scheme for the differential attention.
OOD robustness#
The research investigates out-of-distribution (OOD) robustness by assessing performance on ImageNet variants (ImageNet-V2, A, R, Sketch). This is crucial because real-world applications often encounter domain shifts. DiffCLIP demonstrates a notable improvement in zero-shot performance across these OOD datasets, suggesting enhanced generalization. Differential attention potentially enables the model to focus on more robust features less susceptible to domain variations. This highlights the practical utility of DiffCLIP in scenarios where the data distribution differs from the training data, offering more reliable performance in unseen environments. The results suggest that by subtracting noisy attention patterns, the model learns feature representations that are more adaptable and less prone to overfitting to the specific characteristics of the training data.
Vision only enough?#
The idea of a “Vision Only Enough?” paradigm is intriguing, suggesting an exploration into whether visual information alone can suffice for robust multimodal understanding. The paper’s investigation into DiffCLIP†, a variant applying differential attention exclusively to the vision encoder, directly addresses this. The surprising result, where DiffCLIP† often matches or surpasses the full DiffCLIP model (with differential attention in both vision and text), implies that visual feature extraction may be the bottleneck in CLIP-style models. This highlights the potential of vision-focused improvements, streamlining the architecture for efficiency without sacrificing performance. Focusing solely on the vision pathway offers a more cost-effective way to boost multi-modal learning. In essence, the text encoder might already be sufficient, and the significant gains stem from enhanced visual processing. This insight presents a strong case for prioritizing advancements in visual representation learning within multi-modal frameworks.
Scaling DiffCLIP#
While not explicitly titled ‘Scaling DiffCLIP,’ the paper touches upon aspects relevant to this hypothetical heading. The authors acknowledge the current computational cost of training CLIP models on the CC12M dataset, hinting at the resources needed for scaling. They propose exploring larger architectures (ViT-L or ViT-H) and substantially bigger datasets (LAION-400M) as a future direction. This suggests an awareness of the potential benefits of scaling DiffCLIP in terms of model capacity and data volume. The authors also hypothesize that performance gains observed with DiffCLIP might persist or amplify with increased scale, further underscoring its potential. However, the paper does not delve into the specific challenges or strategies related to scaling the differential attention mechanism itself. More research into how differential attention behaves with significantly larger models and datasets is needed to fully understand its scalability.
More visual insights#
More on figures

🔼 This figure compares the attention mechanisms of CLIP and DiffCLIP models on two example images. Each image is processed with two different text queries. The heatmaps visualize where each model focuses its attention. CLIP’s attention is spread out, including irrelevant background details. In contrast, DiffCLIP’s attention is more concentrated on the query-relevant objects, showcasing its ability to filter out noise and improve focus. The text queries for the top row are ‘Mug’ and ‘Lamp,’ while the bottom row uses ‘Flower’ and ‘Dog.’
read the caption
Figure 2: Comparing CLIP vs. DiffCLIP Attention Maps. For two images (rows), we visualize where CLIP and DiffCLIP attend when matching each image against two different textual queries. While CLIP allocates attention to irrelevant background regions, DiffCLIP more effectively centers on query-relevant objects, highlighting how differential attention can reduce noise and improve focus. Queries: First Row: ‘Mug”, Lamp”; Second Row: Flower”, Dog”.

🔼 This figure compares the zero-shot performance of CLIP and DiffCLIP on various out-of-distribution (OOD) ImageNet datasets. The datasets used are ImageNet, ImageNet-V2, ImageNet-A, ImageNet-R, and ImageNet-Sketch. The performance is measured as zero-shot accuracy (%). Two different pretraining datasets were used for the models: CC3M and CC12M. Blue bars represent CLIP, and pink bars represent DiffCLIP. The numerical values above each bar represent the absolute difference in accuracy between DiffCLIP and CLIP for that specific dataset. The average accuracy across all datasets is also shown. The results demonstrate that DiffCLIP generally improves the zero-shot accuracy compared to the standard CLIP model on these challenging OOD datasets.
read the caption
Figure 3: OOD Zero-Shot ImageNet Performance. Comparison of zero-shot accuracy (%) on ImageNet, ImageNet-V2, ImageNet-A, ImageNet-R, and ImageNet-Sketch, plus the average. Bars show performance of CLIP (blue) versus DiffCLIP (pink), trained on CC3M (left) or CC12M (right). Numerical deltas above the bars indicate the absolute improvement or drop for DiffCLIP relative to CLIP. DiffCLIP improves on average the zero-shot performance on OOD ImageNet datasets as compared to CLIP.

🔼 The radar plot in Figure 4 compares the performance of CLIP and DiffCLIP on the MMVP-VLM benchmark, which assesses fine-grained visual understanding. Each axis represents a different visual property: orientation, positional context, color and appearance, structural characteristics, presence of specific features, viewpoint and perspective, and distribution and quantity. The plot shows that DiffCLIP (pink) consistently outperforms CLIP (blue), achieving an average score of 27.6% compared to CLIP’s 21.9%. This improvement highlights DiffCLIP’s superior ability to focus on subtle visual details relevant to the task, improving performance across multiple visual properties.
read the caption
Figure 4: MMVP-VLM Benchmarking. Radar plot illustrating performance on different fine-grained visual categories. Both models (CLIP in blue, DiffCLIP in pink) are evaluated on properties like orientation, positional context, and color appearance. DiffCLIP (average 27.6%) consistently outperforms CLIP (average 21.9%), demonstrating more focused attention on subtle visual details.

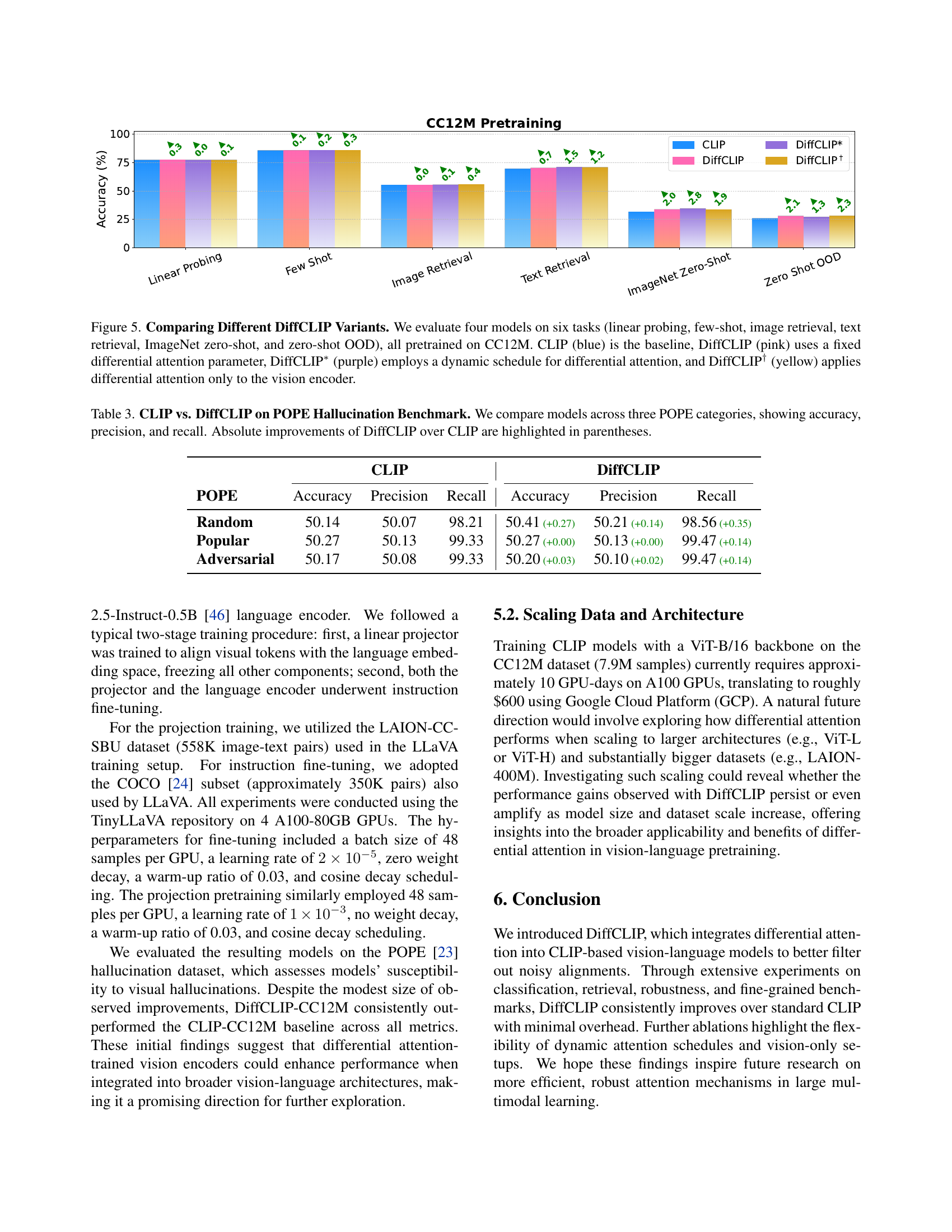
🔼 Figure 5 compares the performance of four different CLIP variants across six tasks: linear probing, few-shot classification, image retrieval, text retrieval, ImageNet zero-shot classification, and out-of-distribution (OOD) zero-shot classification. All models were pretrained on the Conceptual Captions 12M dataset. The variants are: 1) The baseline CLIP model (blue), 2) DiffCLIP with a fixed differential attention parameter (pink), 3) DiffCLIP with a dynamic schedule for the differential attention parameter (purple), and 4) DiffCLIP applying differential attention only to the vision encoder (yellow). The figure visually represents the performance differences between these variants on each of the six tasks.
read the caption
Figure 5: Comparing Different DiffCLIP Variants. We evaluate four models on six tasks (linear probing, few-shot, image retrieval, text retrieval, ImageNet zero-shot, and zero-shot OOD), all pretrained on CC12M. CLIP (blue) is the baseline, DiffCLIP (pink) uses a fixed differential attention parameter, DiffCLIP∗ (purple) employs a dynamic schedule for differential attention, and DiffCLIP† (yellow) applies differential attention only to the vision encoder.
More on tables
| Pretraining | Model | Image Retrieval (R@5) | Text Retrieval (R@5) | Zero-Shot | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Flickr30k | Flickr8k | MSCOCO | Avg. | Flickr30k | Flickr8k | MSCOCO | Avg. | ImageNet | ||
| CC3M | CLIP | 31.8 | 35.4 | 19.4 | 28.9 | 43.4 | 46.2 | 25.4 | 38.3 | 13.6 |
| CC3M | DiffCLIP | 32.9 (+1.1) | 36.5 (+1.1) | 20.9 (+1.5) | 30.1 (+1.2) | 44.7 (+1.3) | 47.8 (+1.6) | 27.6 (+2.2) | 40.1 (+1.8) | 14.4 (+0.8) |
| CC12M | CLIP | 62.5 | 62.1 | 41.3 | 55.3 | 76.8 | 77.7 | 53.8 | 69.4 | 31.8 |
| CC12M | DiffCLIP | 62.2 (-0.3) | 61.5 (-0.6) | 42.3 (+1.0) | 55.3 (+0.0) | 77.4 (+0.6) | 77.4 (-0.3) | 55.5 (+1.7) | 70.1 (+0.7) | 33.8 (+2.0) |
🔼 This table presents a comparison of CLIP and DiffCLIP’s performance on zero-shot image and text retrieval tasks, as well as zero-shot ImageNet classification. The results are broken down by the dataset used for pre-training (CC3M and CC12M), showing Recall@5 for retrieval and accuracy for ImageNet. Parenthetical values indicate the performance difference between DiffCLIP and CLIP, showing improvements or decreases in performance for DiffCLIP compared to CLIP.
read the caption
Table 2: Zero-Shot Retrieval and ImageNet Zero-shot Accuracy. We report image and text retrieval (Recall@5, %) and zero-shot ImageNet accuracy (%) for CLIP vs. DiffCLIP, using CC3M or CC12M as pretraining data. Values in parentheses reflect absolute gains or drops for DiffCLIP relative to CLIP.
| CLIP | DiffCLIP | |||||
|---|---|---|---|---|---|---|
| POPE | Accuracy | Precision | Recall | Accuracy | Precision | Recall |
| Random | 50.14 | 50.07 | 98.21 | 50.41 (+0.27) | 50.21 (+0.14) | 98.56 (+0.35) |
| Popular | 50.27 | 50.13 | 99.33 | 50.27 (+0.00) | 50.13 (+0.00) | 99.47 (+0.14) |
| Adversarial | 50.17 | 50.08 | 99.33 | 50.20 (+0.03) | 50.10 (+0.02) | 99.47 (+0.14) |
🔼 This table presents a comparison of CLIP and DiffCLIP models on the POPE Hallucination Benchmark, a dataset designed to evaluate the tendency of vision-language models to generate hallucinations (incorrect or fabricated details) in their outputs. The models are assessed across three distinct categories within the benchmark, with performance measured using three metrics: accuracy, precision, and recall. The table shows the performance of each model in each category and highlights the absolute improvements achieved by DiffCLIP over the baseline CLIP model using parentheses.
read the caption
Table 3: CLIP vs. DiffCLIP on POPE Hallucination Benchmark. We compare models across three POPE categories, showing accuracy, precision, and recall. Absolute improvements of DiffCLIP over CLIP are highlighted in parentheses.
Full paper#