TL;DR#
Conditional motion generation struggles with prioritizing dynamic frames based on conditions and effectively integrating multiple modalities. Existing masking models need improvement for different conditions. To solve this, the paper introduces an ‘Attention-based Mask Modeling’ method for spatial and temporal control over key frames and actions. This will enable the model to focus on key actions during motion generation. In addition, this model adaptively encodes text and music to improve controllability.
To help this research, the paper presents ‘Text-Music-Dance (TMD),’ which has paired music and text. Experimental results show that this framework surpasses current state-of-the-art methods on multiple benchmarks, with significant improvement of about 15% in FID on HumanML3D. It demonstrates consistent gains on the AIST++ and TMD datasets. This new method will push the boundary of conditional motion generation.
Key Takeaways#
Why does it matter?#
This work facilitates controllable multimodal motion generation, with a new dataset. This enables more versatile & precise motion generation. Future research can explore & refine this approach for virtual characters, human-computer interaction, & robotics, advancing the field.
Visual Insights#
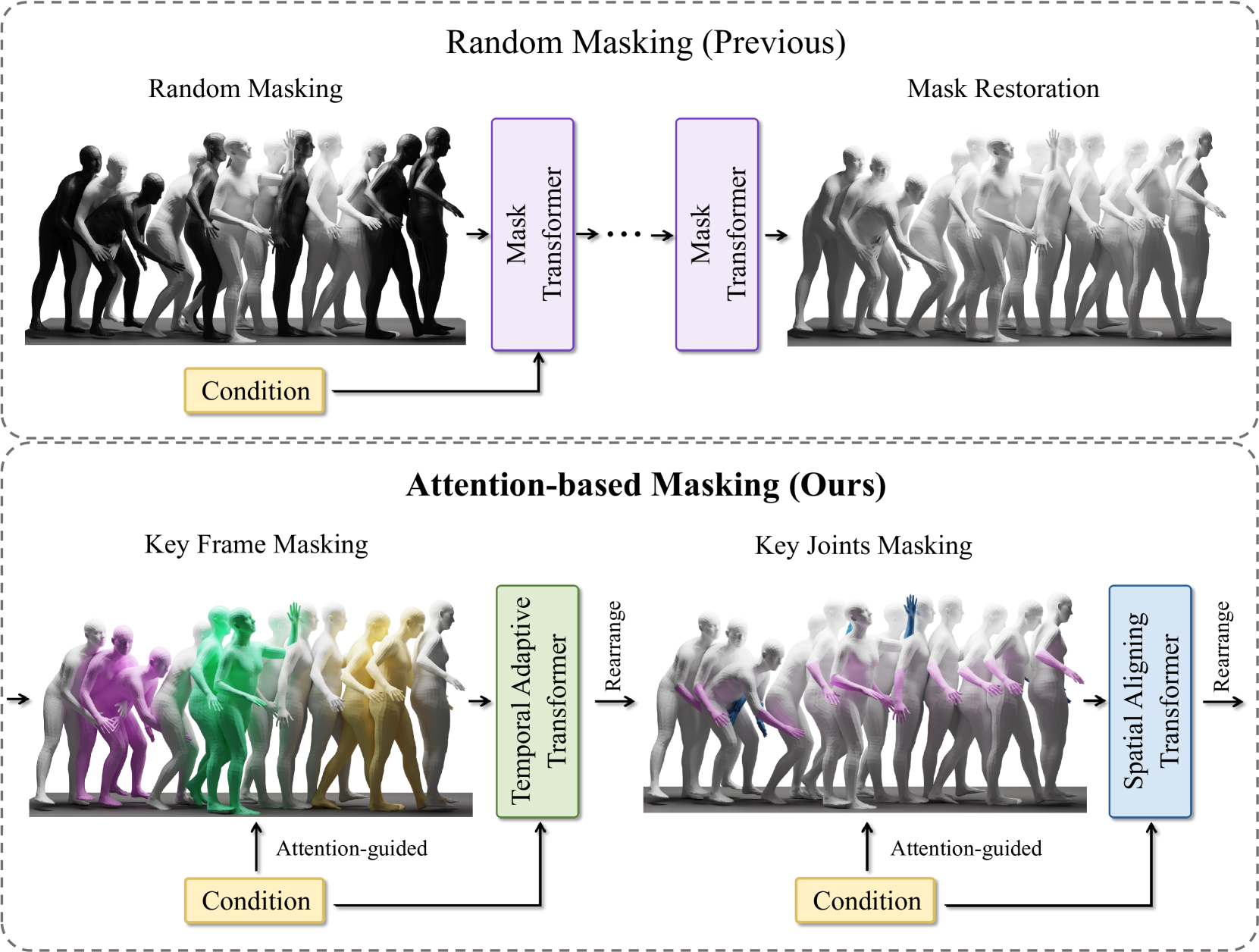
🔼 This figure illustrates the core difference between the traditional random masking approach used in previous autoregressive motion generation models and the novel attention-based masking method introduced in this paper. The top panel displays the random masking technique, where the model randomly masks various parts of the motion sequence, irrespective of the importance or relevance to the input condition. In contrast, the bottom panel showcases the attention-based masking strategy. The model assigns attention weights to different parts of the motion based on the input condition, and strategically masks out less relevant parts. The color-coded areas highlight the dynamic, crucial frames and body parts that are prioritized and preserved during the masking process, ensuring the quality and coherence of the generated motion based on the provided conditions.
read the caption
Figure 1: Masking strategy comparison. This figure demonstrates the key differences between the previous random masking strategy [21] (top) and our attention-based masking (bottom). Our masking strategy focuses on the more significant and dynamic parts of the motion (colored) corresponding to the condition.
| Models | Text-to-Motion | Music-to-Dance | Text and Music to Dance |
| TM2D [17] | ✓ | ✓ | ✗ |
| UDE [83] | ✓ | ✓ | ✗ |
| UDE-2 [84] | ✓ | ✓ | ✗ |
| MoFusion [12] | ✓ | ✓ | ✗ |
| MCM [39] | ✓ | ✓ | ✓ |
| LMM [73] | ✓ | ✓ | ✗ |
| MotionCraft [5] | ✓ | ✓ | ✗ |
| MagicPose4D [67] | ✗ | ✗ | ✗ |
| STAR [8] | ✓ | ✗ | ✗ |
| TC4D [3] | ✓ | ✗ | ✗ |
| Motion Avatar [77] | ✓ | ✗ | ✗ |
| Motion Anything (Ours) | ✓ | ✓ | ✓ |
🔼 This table compares different methods for motion generation, highlighting their ability to handle single versus multiple conditioning modalities. Most existing methods, whether single-task or multi-task, can only process one type of condition at a time (e.g., text or music). This limits their control over the generated motion. In contrast, the proposed method, ‘Motion Anything,’ uniquely handles multiple modalities simultaneously and adaptively, leading to more controllable motion generation.
read the caption
Table 1: Methods comparison. Either single-task or multi-task models can handle only one condition at a time, overlooking the importance of integrating multiple modalities for more controllable generation. Our Motion Anything introduces an innovative approach that encodes different modalities simultaneously and adaptively for more controllable generation.
In-depth insights#
Attention Masking#
Attention masking is likely a technique used to selectively focus on important parts of the input data while ignoring irrelevant information. It could be used in various modalities, including text, audio, and video. It helps the model prioritize key features and reduce computational cost. Attention masking can be applied in both temporal and spatial dimensions. Temporally, it helps in selecting key frames or time steps, while spatially, it focuses on important regions or body parts. It enables the model to learn more robust representations by focusing on the most relevant information based on the current context. This is especially valuable for multimodal data where different modalities may have varying degrees of importance.
Multi-Modal TMD#
The idea of a ‘Multi-Modal TMD’ (Text-Music-Dance) approach is compelling, suggesting a deeper integration of diverse data streams for motion generation. This goes beyond simple concatenation, implying a synergistic model where text provides semantic grounding, music dictates rhythm and style, and the dance output reflects a coherent blend. This is crucial because current models often treat modalities separately, limiting control and expressiveness. A true multi-modal system would leverage attention mechanisms to prioritize key elements from each input, ensuring dynamic frames and body parts align with the combined context. Furthermore, a robust dataset with paired text, music, and dance is essential for training, filling a current gap in the research landscape and facilitating exploration of complex correlations between modalities, which may advance future motion generation research.
Adaptive Control#
While ‘Adaptive Control’ isn’t explicitly present, its principles are woven throughout the paper’s methodology. The core idea is to make the model more responsive and flexible to various inputs. Motion Anything adapts by using attention mechanisms that prioritize key frames and body parts depending on conditions. This enables the model to focus on the most important parts of the motion. Also, having a Temporal Adaptive Transformer (TAT) that aligns temporal tokens to match conditions in any modality. The ability to handle multimodal inputs further demonstrates adaptivity, allowing the model to integrate information from text and music for better control and coherence, enabling the model to respond effectively.
4D Avatars#
The idea of ‘4D Avatars’ has seen a surge, focusing on creating dynamic 3D models that evolve over time. Existing methods often struggle with limited control over motion and inconsistencies in the mesh appearance. A feedforward approach aims to resolve these by generating avatars from a single prompt, streamlining the process. By leveraging advances in motion generation and combining it with 3D avatar creation, the ‘4D Avatars’ can achieve more realistic and expressive results. This synthesis promises avatars with more precise movements and consistent visual quality. The focus lies on automating rigging to improve the realism of avatar movements. By tackling these challenges, the next generation of ‘4D Avatars’ can unlock exciting opportunities.
Key-Frame Focus#
The concept of “Key-Frame Focus” in motion generation likely refers to a methodology that prioritizes the accurate and detailed generation of key frames within a motion sequence. This approach contrasts with methods that treat all frames equally, instead allocating more computational resources and attention to frames deemed more important for conveying the overall motion and its nuances. Key frames often represent points of significant change or emphasis in the movement, such as the peak of a jump or the moment of impact in a collision. By focusing on these critical junctures, the system can achieve higher fidelity in the most visually salient parts of the motion, potentially allowing for a more efficient use of resources as less critical frames can be interpolated or generated with less detail. The identification of key frames could rely on various criteria, including detecting points of high acceleration, changes in direction, or semantic importance based on the input conditions (text, music, etc.). Furthermore, effective methods for key frame focus would likely involve techniques to ensure smooth transitions between key frames and maintain overall coherence in the generated motion sequence.
More visual insights#
More on figures

🔼 Figure 3 illustrates the architecture of Motion Anything, a multimodal motion generation framework. It highlights four key components: (a) a temporal attention-based masking mechanism that selectively focuses on important time steps within a motion sequence based on the input conditions; (c) a spatial attention-based masking mechanism that similarly prioritizes key body parts or actions; (b) the overall motion generation model; and (d) a detailed view of a single block within the motion generator, showcasing the internal processing steps. These components work together to ensure the generated motion accurately reflects the provided multimodal conditions (text, music, or both), enhancing control and coherence in the output.
read the caption
Figure 2: Motion Anything architecture. The multimodal architecture consists of several key components: (a) temporal and (c) spatial attention-based masking, (b) motion generator, and (d) a single block of motion generator. These components enable the model to learn key motions corresponding to the given conditions, and facilitate alignment between multi-modal conditions and motion features.

🔼 The figure visualizes the attention weights learned by the model’s attention-based masking mechanism. Different colored regions highlight areas of the motion sequence that receive high attention scores. The darker the color, the more attention the model paid to that specific region during the masking process. This attention is used to selectively mask parts of the motion sequence deemed less important based on the provided conditions (text, music, or both). The visualization helps demonstrate how the model focuses on dynamic and crucial parts of motion, enabling fine-grained control over the generated motion.
read the caption
Figure 3: Attention map. The attention map provides a direct visualization of our attention-based masking approach, which selectively masks regions in the motion sequence with high attention scores.

🔼 Figure 4 presents a qualitative comparison of text-to-motion generation results. It showcases motion sequences generated by the proposed ‘Motion Anything’ method alongside those created by three other state-of-the-art methods: BAD, BAMM, and MoMask. The figure allows for a visual assessment of the differences in motion quality, realism, and adherence to the text prompts across the various approaches. By visually comparing the generated motions, the figure helps demonstrate the advantages of the ‘Motion Anything’ framework.
read the caption
Figure 4: Qualitative evaluation on text-to-motion generation. We qualitatively compared the visualizations generated by our method with those produced by BAD [22], BAMM [44], and MoMask [21].

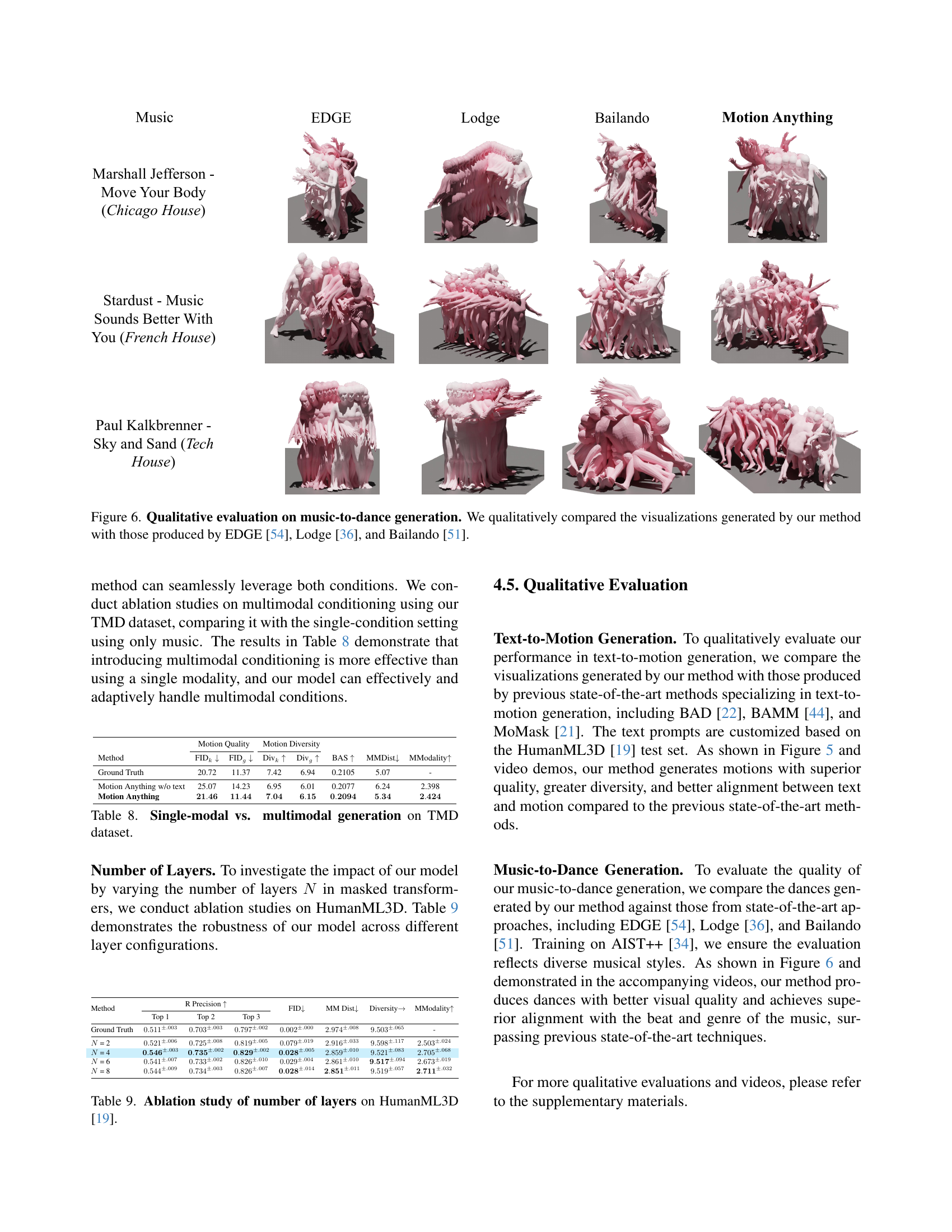
🔼 Figure 5 showcases a qualitative comparison of music-to-dance generation results. It presents visual examples of dance sequences generated by the proposed ‘Motion Anything’ method alongside those created by three other state-of-the-art techniques: EDGE, Lodge, and Bailando. This allows for a visual assessment of the relative quality, style, and fidelity of the generated dances, illustrating the improvements achieved by Motion Anything in terms of generating realistic and expressive dance motions synchronized with the input music.
read the caption
Figure 5: Qualitative evaluation on music-to-dance generation. We qualitatively compared the visualizations generated by our method with those produced by EDGE [54], Lodge [36], and Bailando [51].
🔼 The figure displays the user interface of the user study conducted in the paper. The interface presents a series of motion animation videos for evaluation. Participants assess aspects such as motion accuracy, overall user experience, and visual quality. They rate each aspect from 1 (low) to 3 (high). A comparison section allows participants to select the model with the best performance. The study involved three groups of motions: text-to-motion, music-to-dance, and text-and-music-to-dance.
read the caption
Figure 1: User study form. The User Interface (UI) used in our user study.
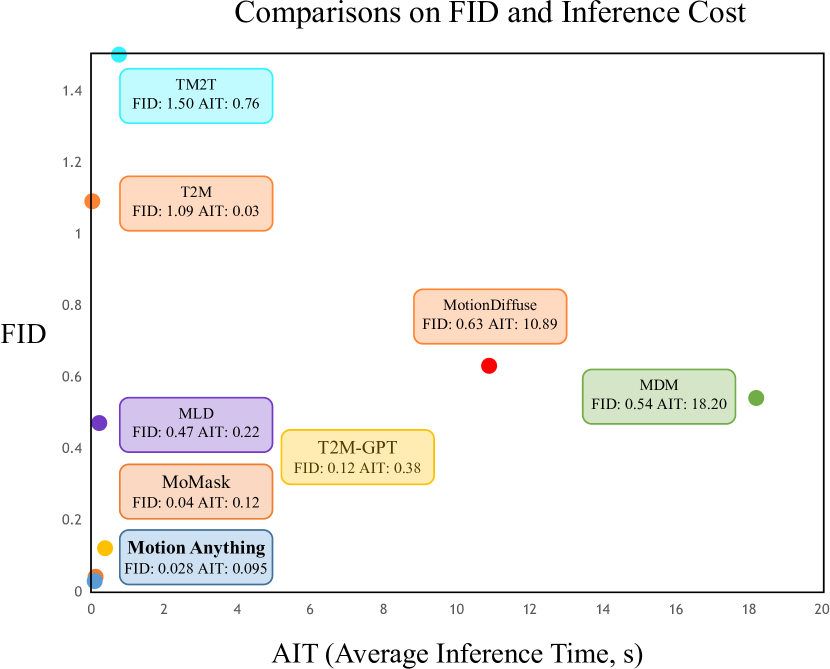
🔼 Figure 2 presents a comparison of the Fréchet Inception Distance (FID) and Average Inference Time (AIT) for various motion generation models. All models were evaluated using the same NVIDIA GeForce RTX 2080 Ti GPU to ensure consistent testing conditions. The chart plots FID and AIT scores for each method. Lower FID scores indicate better-quality motion generation, while lower AIT scores represent faster inference times. The ideal model would be closest to the origin (0,0) as it produces high-quality motion quickly. The figure visually demonstrates the trade-off between generation quality and computational efficiency for each method.
read the caption
Figure 2: Comparisons on FID and AIT. All tests are conducted on the same NVIDIA GeForce RTX 2080 Ti. The closer the model is to the origin, the better.
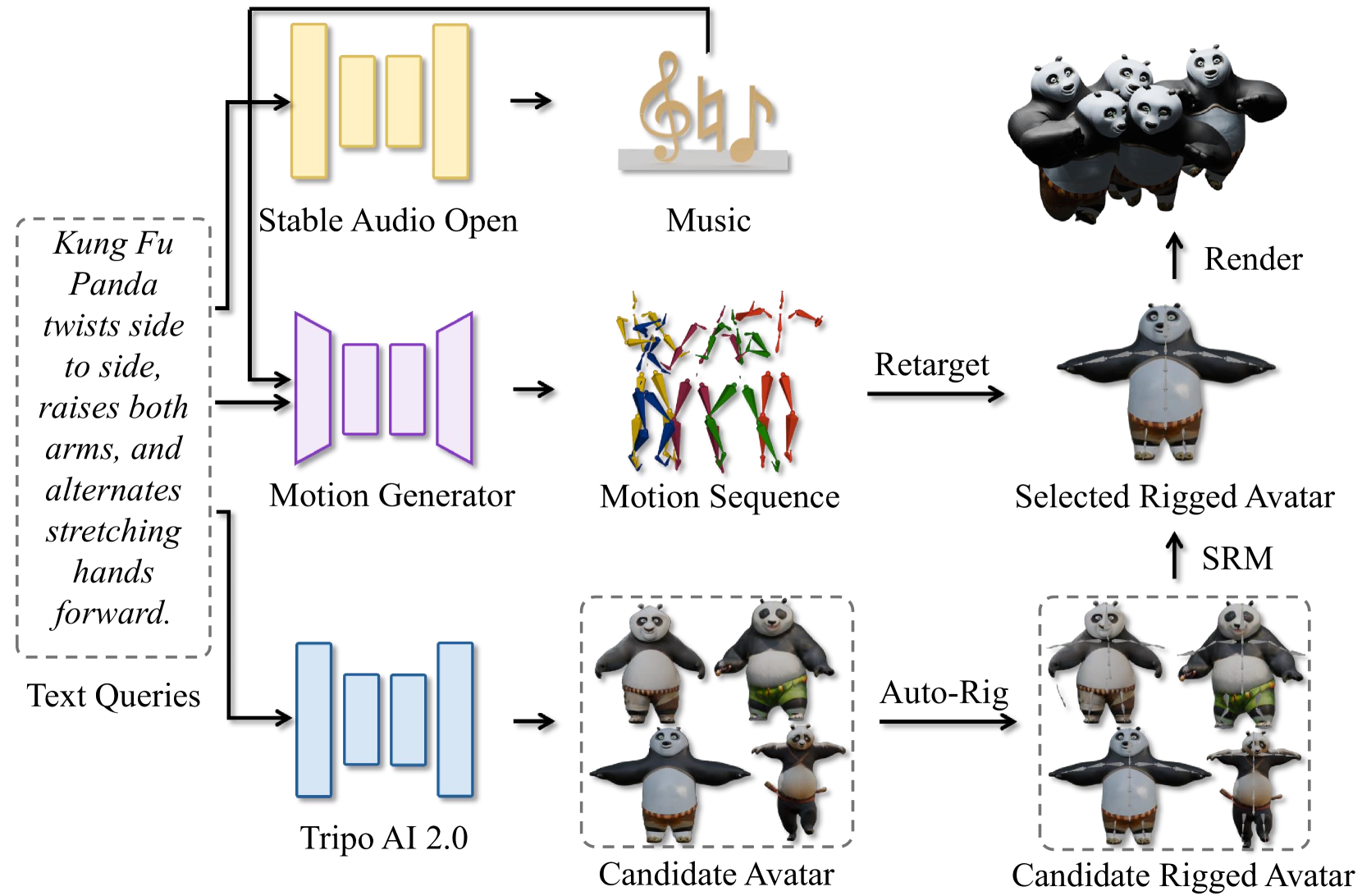
🔼 This figure illustrates the process of generating a 4D avatar using a multimodal approach. It begins with a single text prompt as input, which is then processed by a motion generation model to create a motion sequence. Simultaneously, a 3D avatar generation model creates candidate 3D avatars. Then, a selective rigging mechanism determines which 3D avatar best fits the generated motion. Finally, the motion sequence is retargeted to the chosen avatar, resulting in a 4D avatar that combines 3D visual information with a realistic motion sequence.
read the caption
Figure 3: 4D Avatar Generation. This approach enables 4D avatar generation conditioned on multimodal inputs, achievable with just a single text prompt.
🔼 This figure displays a set of 3D avatars generated using the Tripo AI 2.0 model. These avatars represent diverse body shapes and poses. They are not the final output of the paper’s method but serve as the input candidates to a later stage, the Selective Rigging Mechanism, which selects the most suitable avatar for subsequent motion animation.
read the caption
Figure 4: 3D Avatars. This figure shows examples of 3D avatars generated by Tripo AI 2.0 [1]. These avatars will later serve as candidates for our Selective Rigging Mechanism.

🔼 Figure 5 presents a qualitative comparison of dance generation results. It visually showcases the output from three different methods: Motion Anything (the proposed model), TM2D [17], and MotionCraft [5]. Each method was given the same text and music prompts to generate dance sequences. The figure allows for a direct visual comparison of the quality, style, coherence, and overall realism of the motion generated by each method, highlighting the strengths of Motion Anything in generating more natural and nuanced dance movements compared to the alternatives.
read the caption
Figure 5: Qualitative evaluation on text-&-music-to-dance generation. We qualitatively compared the visualizations generated by our method with those produced by TM2D [17] and MotionCraft [5].
More on tables
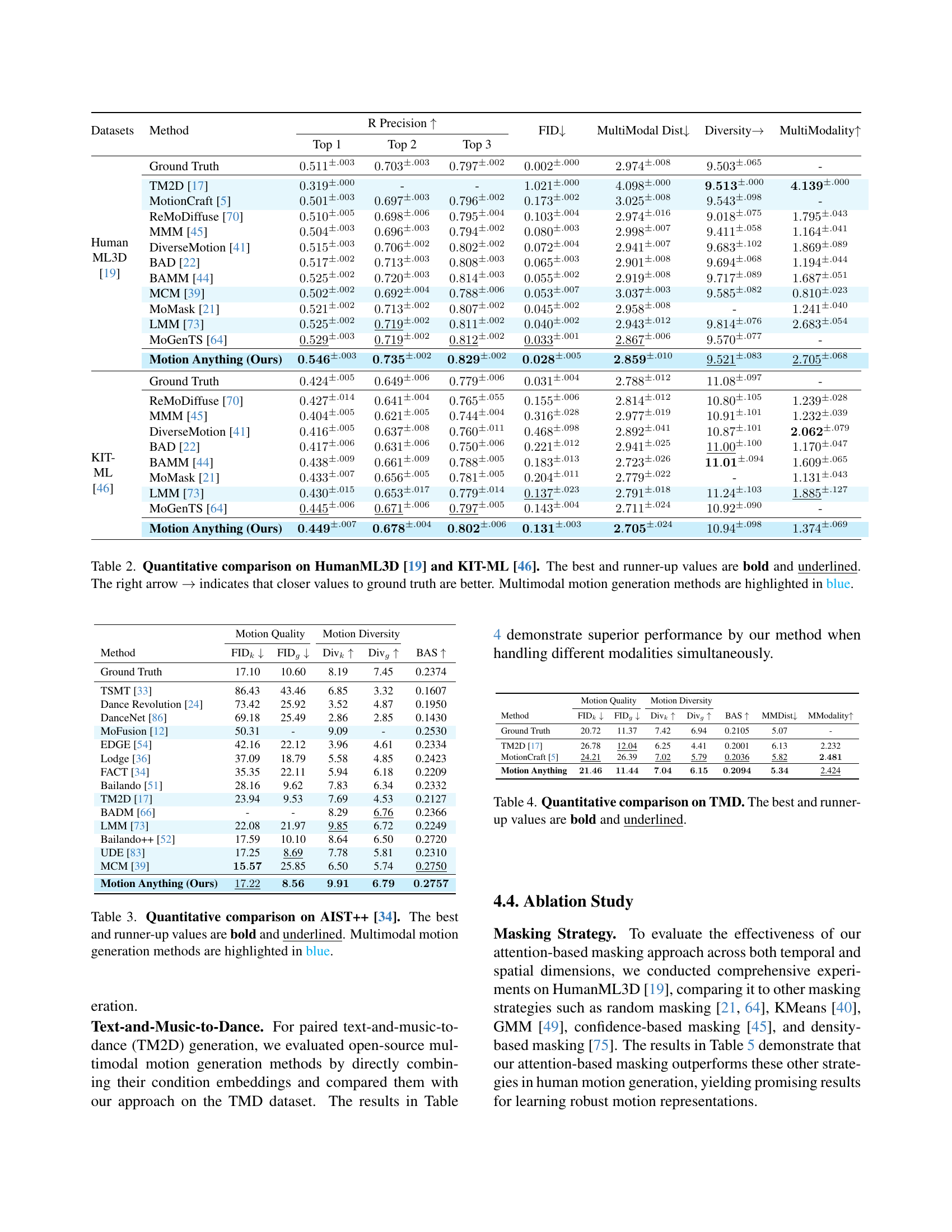
| Datasets | Method | R Precision | FID | MultiModal Dist | Diversity | MultiModality | ||
| Top 1 | Top 2 | Top 3 | ||||||
| Human ML3D [19] | Ground Truth | - | ||||||
| TM2D [17] | - | - | ||||||
| MotionCraft [5] | - | |||||||
| ReMoDiffuse [70] | ||||||||
| MMM [45] | ||||||||
| DiverseMotion [41] | ||||||||
| BAD [22] | ||||||||
| BAMM [44] | ||||||||
| MCM [39] | ||||||||
| MoMask [21] | - | |||||||
| LMM [73] | ||||||||
| MoGenTS [64] | - | |||||||
| Motion Anything (Ours) | ||||||||
| KIT- ML [46] | Ground Truth | - | ||||||
| ReMoDiffuse [70] | ||||||||
| MMM [45] | ||||||||
| DiverseMotion [41] | ||||||||
| BAD [22] | ||||||||
| BAMM [44] | ||||||||
| MoMask [21] | - | |||||||
| LMM [73] | ||||||||
| MoGenTS [64] | - | |||||||
| Motion Anything (Ours) | ||||||||
🔼 This table presents a quantitative comparison of various methods for text-to-motion generation, evaluated on the HumanML3D and KIT-ML datasets. Metrics include R-Precision (a measure of retrieval accuracy), FID (Fréchet Inception Distance, indicating the quality and realism of the generated motion), MultiModal Distance (measuring alignment between the generated motion and text description), Diversity (capturing the variety of generated motions), and MultiModality (assessing diversity within motions from the same text prompt). Higher R-Precision and Diversity scores are better, while lower FID and MultiModal Distance scores are better. The best-performing methods for each metric are highlighted in bold and underlined. The arrow indicates that a closer value to the ground truth is better. Methods capable of handling multiple conditioning modalities (like text and audio simultaneously) are highlighted in blue. This comparison allows readers to assess the relative performance of different models based on multiple evaluation aspects.
read the caption
Table 2: Quantitative comparison on HumanML3D [19] and KIT-ML [46]. The best and runner-up values are bold and underlined. The right arrow →→\rightarrow→ indicates that closer values to ground truth are better. Multimodal motion generation methods are highlighted in blue.
| Motion Quality | Motion Diversity | ||||
| Method | FID | FID | Div | Div | BAS |
| Ground Truth | 17.10 | 10.60 | 8.19 | 7.45 | 0.2374 |
| TSMT [33] | 86.43 | 43.46 | 6.85 | 3.32 | 0.1607 |
| Dance Revolution [24] | 73.42 | 25.92 | 3.52 | 4.87 | 0.1950 |
| DanceNet [86] | 69.18 | 25.49 | 2.86 | 2.85 | 0.1430 |
| MoFusion [12] | 50.31 | - | 9.09 | - | 0.2530 |
| EDGE [54] | 42.16 | 22.12 | 3.96 | 4.61 | 0.2334 |
| Lodge [36] | 37.09 | 18.79 | 5.58 | 4.85 | 0.2423 |
| FACT [34] | 35.35 | 22.11 | 5.94 | 6.18 | 0.2209 |
| Bailando [51] | 28.16 | 9.62 | 7.83 | 6.34 | 0.2332 |
| TM2D [17] | 23.94 | 9.53 | 7.69 | 4.53 | 0.2127 |
| BADM [66] | - | - | 8.29 | 6.76 | 0.2366 |
| LMM [73] | 22.08 | 21.97 | 9.85 | 6.72 | 0.2249 |
| Bailando++ [52] | 17.59 | 10.10 | 8.64 | 6.50 | 0.2720 |
| UDE [83] | 17.25 | 8.69 | 7.78 | 5.81 | 0.2310 |
| MCM [39] | 25.85 | 6.50 | 5.74 | 0.2750 | |
| Motion Anything (Ours) | |||||
🔼 This table presents a quantitative comparison of different methods for music-to-dance generation on the AIST++ benchmark dataset. It compares the performance of various methods across multiple metrics, including FID (Fréchet Inception Distance) for quality assessment, metrics for motion diversity, and a beat alignment score (BAS). The best and second-best results for each metric are highlighted. Methods capable of handling multimodal conditioning (music and other modalities) are visually distinguished.
read the caption
Table 3: Quantitative comparison on AIST++ [34]. The best and runner-up values are bold and underlined. Multimodal motion generation methods are highlighted in blue.
| Motion Quality | Motion Diversity | ||||||
| Method | FID | FID | Div | Div | BAS | MMDist | MModality |
| Ground Truth | 20.72 | 11.37 | 7.42 | 6.94 | 0.2105 | 5.07 | - |
| TM2D [17] | 26.78 | 12.04 | 6.25 | 4.41 | 0.2001 | 6.13 | 2.232 |
| MotionCraft [5] | 24.21 | 26.39 | 7.02 | 5.79 | 0.2036 | 5.82 | |
| Motion Anything | 2.424 | ||||||
🔼 Table 4 presents a quantitative comparison of different methods on the Text-Music-Dance (TMD) dataset. It shows the performance of various models across multiple metrics, including FID (Frechet Inception Distance), which measures the quality and realism of the generated motion; diversity metrics (Divk and Divg) which assess the variety in generated motions; BAS (Beat Alignment Score), indicating how well the generated dance aligns with the music; MMDist (Multimodal Distance), measuring the alignment between the text and motion; and MModality (Multimodality), evaluating the diversity among motions generated from the same text description. The best and second-best performance for each metric are highlighted in bold and underlined.
read the caption
Table 4: Quantitative comparison on TMD. The best and runner-up values are bold and underlined.
| Method | R Precision | FID | MM Dist | Diversity | MModality | ||
| Top 1 | Top 2 | Top 3 | |||||
| Ground Truth | - | ||||||
| Random Masking [21] | |||||||
| KMeans [40] | |||||||
| GMM [49] | |||||||
| Confidence-based Masking [45] | |||||||
| Density-based Masking [75] | |||||||
| Attention-based Masking | |||||||
🔼 This ablation study analyzes the effectiveness of different masking strategies on the HumanML3D dataset for text-to-motion generation. It compares the performance of the proposed attention-based masking against several alternative approaches: random masking, KMeans, Gaussian Mixture Model (GMM), confidence-based masking, and density-based masking. The results demonstrate the superiority of the attention-based masking strategy in terms of key metrics such as FID (Frechet Inception Distance), MultiModal Distance, Diversity, and MultiModality. Higher values for R-Precision and Diversity are better, while lower values for FID and MultiModal Distance are preferred. The arrow indicates that values closer to the ground truth are better.
read the caption
Table 5: Ablation study of the masking strategy on HumanML3D [19]. The best and runner-up values are bold and underlined. The right arrow →→\rightarrow→ indicates that closer values to ground truth are better.
| Method | R Precision | FID | MM Dist | Diversity | MModality | ||
| Top 1 | Top 2 | Top 3 | |||||
| Ground Truth | - | ||||||
| T:15% S:15% | |||||||
| T:15% S:30% | |||||||
| T:15% S:50% | |||||||
| T:30% S:15% | |||||||
| T:30% S:30% | |||||||
| T:30% S:50% | |||||||
| T:50% S:15% | |||||||
| T:50% S:30% | |||||||
| T:50% S:50% | |||||||
🔼 This ablation study investigates the impact of varying the masking ratio on the performance of the attention-based masking method within the Motion Anything model. The study uses HumanML3D [19] as the benchmark dataset. The results show the model’s performance across different masking ratios for both temporal and spatial dimensions. Metrics evaluated include FID (Fréchet Inception Distance), MultiModal Distance, Diversity, and MultiModality. Higher R-Precision values and lower FID values indicate better performance, while closer values to ground truth for MultiModal Distance are preferred. The table highlights the optimal masking ratio that balances performance and robustness.
read the caption
Table 6: Ablation study of masking ratio on HumanML3D [19]. The best and runner-up values are bold and underlined. The right arrow →→\rightarrow→ indicates that closer values to ground truth are better.
| Method | R Precision | FID | MM Dist | Diversity | MModality | ||
| Top 1 | Top 2 | Top 3 | |||||
| Ground Truth | - | ||||||
| Cross-modal Attention | |||||||
| Motion Anything | |||||||
🔼 This ablation study investigates the impact of using a Temporal Adaptive Transformer (TAT) in the Motion Anything model for text-to-motion generation on the HumanML3D benchmark. It compares the model’s performance (measured by R Precision, FID, MultiModal Distance, Diversity, and MultiModality) when using the TAT against a baseline where a cross-modal attention layer is used instead. The results help determine if the proposed TAT architecture is crucial for optimal performance in this specific text-to-motion task.
read the caption
Table 7: Ablation study of the TAT on HumanML3D [19]. The best values are bold. The right arrow →→\rightarrow→ indicates that closer values to ground truth are better.
| Motion Quality | Motion Diversity | ||||||
| Method | FID | FID | Div | Div | BAS | MMDist | MModality |
| Ground Truth | 20.72 | 11.37 | 7.42 | 6.94 | 0.2105 | 5.07 | - |
| Motion Anything w/o text | 25.07 | 14.23 | 6.95 | 6.01 | 0.2077 | 6.24 | 2.398 |
| Motion Anything | |||||||
🔼 This table presents a comparison of motion generation results using single-modal (music only) versus multi-modal (music and text) conditioning on the TMD dataset. It shows quantitative metrics, such as FID, to evaluate the quality, diversity, and alignment of generated dance movements with music and text. This comparison highlights the impact of incorporating multiple modalities for improved motion generation.
read the caption
Table 8: Single-modal vs. multimodal generation on TMD dataset.
| Method | R Precision | FID | MM Dist | Diversity | MModality | ||
| Top 1 | Top 2 | Top 3 | |||||
| Ground Truth | - | ||||||
| = 2 | |||||||
| = 4 | |||||||
| = 6 | |||||||
| = 8 | |||||||
🔼 This ablation study investigates the impact of varying the number of layers (N) within the masked transformers of the Motion Anything model. The results are evaluated on the HumanML3D [19] benchmark, assessing the influence of different layer configurations on the model’s performance in text-to-motion generation. Metrics such as R-Precision (Top 1, Top 2, Top 3), FID, MultiModal Distance, Diversity, and MultiModality are used to comprehensively evaluate the model’s robustness and efficacy across various layer depths.
read the caption
Table 9: Ablation study of number of layers on HumanML3D [19].
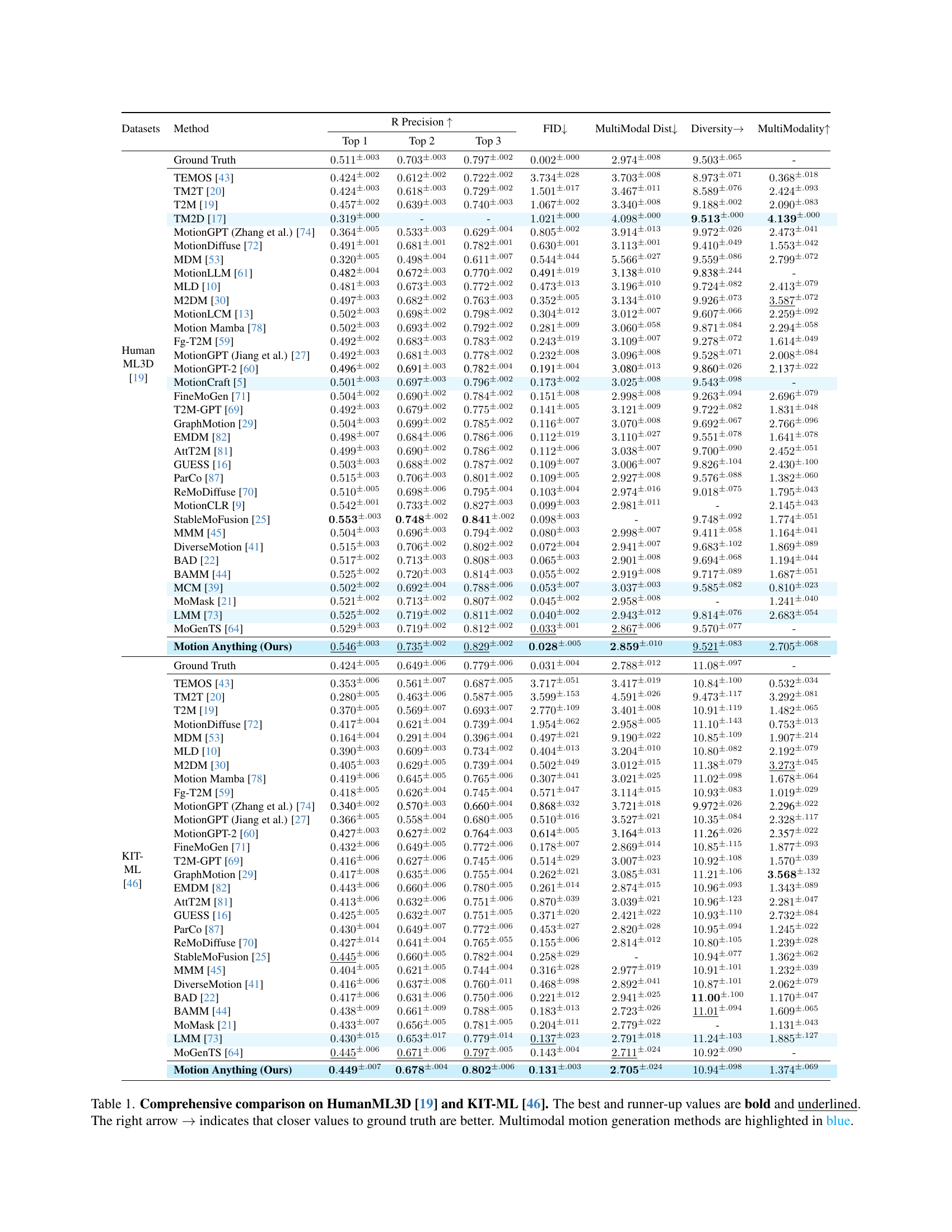
| Datasets | Method | R Precision | FID | MultiModal Dist | Diversity | MultiModality | ||
| Top 1 | Top 2 | Top 3 | ||||||
| Human ML3D [19] | Ground Truth | - | ||||||
| TEMOS [43] | ||||||||
| TM2T [20] | ||||||||
| T2M [19] | ||||||||
| TM2D [17] | - | - | ||||||
| MotionGPT (Zhang et al.) [74] | ||||||||
| MotionDiffuse [72] | ||||||||
| MDM [53] | ||||||||
| MotionLLM [61] | 0.482±.004 | 0.672±.003 | 0.770±.002 | 0.491±.019 | 3.138±.010 | 9.838±.244 | - | |
| MLD [10] | ||||||||
| M2DM [30] | ||||||||
| MotionLCM [13] | ||||||||
| Motion Mamba [78] | ||||||||
| Fg-T2M [59] | ||||||||
| MotionGPT (Jiang et al.) [27] | ||||||||
| MotionGPT-2 [60] | 0.496±.002 | 0.691±.003 | 0.782±.004 | 0.191±.004 | 3.080±.013 | 9.860±.026 | 2.137±.022 | |
| MotionCraft [5] | - | |||||||
| FineMoGen [71] | ||||||||
| T2M-GPT [69] | ||||||||
| GraphMotion [29] | ||||||||
| EMDM [82] | ||||||||
| AttT2M [81] | ||||||||
| GUESS [16] | ||||||||
| ParCo [87] | ||||||||
| ReMoDiffuse [70] | ||||||||
| MotionCLR [9] | - | |||||||
| StableMoFusion [25] | - | |||||||
| MMM [45] | ||||||||
| DiverseMotion [41] | ||||||||
| BAD [22] | ||||||||
| BAMM [44] | ||||||||
| MCM [39] | ||||||||
| MoMask [21] | - | |||||||
| LMM [73] | ||||||||
| MoGenTS [64] | - | |||||||
| Motion Anything (Ours) | ||||||||
| KIT- ML [46] | Ground Truth | - | ||||||
| TEMOS [43] | ||||||||
| TM2T [20] | ||||||||
| T2M [19] | ||||||||
| MotionDiffuse [72] | ||||||||
| MDM [53] | ||||||||
| MLD [10] | ||||||||
| M2DM [30] | ||||||||
| Motion Mamba [78] | ||||||||
| Fg-T2M [59] | ||||||||
| MotionGPT (Zhang et al.) [74] | 0.340±.002 | 0.570±.003 | 0.660±.004 | 0.868±.032 | 3.721±.018 | 9.972±.026 | 2.296±.022 | |
| MotionGPT (Jiang et al.) [27] | ||||||||
| MotionGPT-2 [60] | 0.427±.003 | 0.627±.002 | 0.764±.003 | 0.614±.005 | 3.164±.013 | 11.26±.026 | 2.357±.022 | |
| FineMoGen [71] | ||||||||
| T2M-GPT [69] | ||||||||
| GraphMotion [29] | ||||||||
| EMDM [82] | ||||||||
| AttT2M [81] | ||||||||
| GUESS [16] | ||||||||
| ParCo [87] | ||||||||
| ReMoDiffuse [70] | ||||||||
| StableMoFusion [25] | - | |||||||
| MMM [45] | ||||||||
| DiverseMotion [41] | ||||||||
| BAD [22] | ||||||||
| BAMM [44] | ||||||||
| MoMask [21] | - | |||||||
| LMM [73] | ||||||||
| MoGenTS [64] | - | |||||||
| Motion Anything (Ours) | ||||||||
🔼 Table 1 presents a comprehensive quantitative comparison of the proposed Motion Anything model against various state-of-the-art methods for text-to-motion generation on the HumanML3D and KIT-ML benchmarks. Evaluation metrics include Top-1, Top-2, and Top-3 Recall Precision (higher is better), Fréchet Inception Distance (FID; lower is better), MultiModal Distance (lower is better), Diversity (higher is better), and MultiModality (higher is better). The table highlights the superior performance of Motion Anything across multiple metrics. Methods using multiple input modalities (multimodal) are shown in blue. Bold and underlined values indicate the top-performing results for each metric.
read the caption
Table 1: Comprehensive comparison on HumanML3D [19] and KIT-ML [46]. The best and runner-up values are bold and underlined. The right arrow →→\rightarrow→ indicates that closer values to ground truth are better. Multimodal motion generation methods are highlighted in blue.
| Method | AIT(s) | |
| MagicPose4D | ||
| SRM () | ||
| SRM () | ||
| SRM () |
🔼 Table 2 presents a quantitative evaluation of the Selective Rigging Mechanism (SRM) used in 4D avatar generation. It compares the performance of SRM with different numbers of candidate avatars (k=1, 3, and 5) in terms of Average Inference Time (AIT), and a quality metric based on the deviation of the average joint weight sum from the ideal value of 1. Lower values of AIT indicate faster processing time, while values closer to 1 for the average joint weight sum imply better rigging quality and stability.
read the caption
Table 2: SRM evaluation.
Full paper#