TL;DR#
Recent methods in image diffusion models provide effective spatial and subject control. However, Diffusion Transformers(DiT) struggle with efficient control. The work addresses DiT’s limitations by introducing EasyControl, a framework unifying condition-guided diffusion transformers with efficiency and flexibility. Key innovations include a lightweight Condition Injection LoRA Module for processing conditional signals, a Position-Aware Training Paradigm to standardize input, and latency reduction.
EasyControl uses lightweight modules for efficient conditional signal processing, enabling plug-and-play functionality. Position-Aware Training standardizes inputs, generating images with flexible resolutions. Introducing Causal Attention with KV Cache significantly reduces synthesis latency. Experiments show EasyControl excels in various applications, demonstrating efficiency and flexibility. EasyControl’s innovations establish a new paradigm, showcasing superior efficiency and flexibility in conditional generation.
Key Takeaways#
Why does it matter?#
EasyControl offers efficient and flexible control for DiT models, enabling high-quality image generation across diverse tasks. This innovation boosts controllability and opens new avenues for conditional image generation research.
Visual Insights#

🔼 EasyControl is a lightweight, efficient, and versatile plug-and-play module designed for diffusion transformers. It offers both single-condition control (spatial and subject/face) and impressive zero-shot multi-condition generalization. Even after training on single conditions, it can effectively manage sophisticated multi-condition scenarios, such as combining color and edge information or subject and pose data, demonstrating its flexibility and power. The figure showcases examples of these capabilities.
read the caption
Figure 1: Our proposed framework, EasyControl, is a lightweight and efficient plug-and-play module specifically designed for diffusion transformer. This solution not only enables spatial control and subject/face control under single conditions but also demonstrates remarkable zero-shot multi-condition generalization capability after single-condition training, achieving sophisticated multi-condition control.
| Cond. | Method | Time(s) | Params |
|---|---|---|---|
| ControlNet | 16.5 | 3B | |
| OminiControl | 31.6 | 15M | |
| \cdashline2-4 Single | Ours(w.o. PATP&KVCache) | 38.9 | - |
| Ours(w.o. KVCache) | 22.4(-42%) | - | |
| Ours(w.o. PATP) | 25.0(-36%) | - | |
| Ours(Full) | 16.3(-58%) | 15M | |
| ControlNet+IPA | 16.8 | 4B | |
| Multi-ControlNet | 20.3 | 6B | |
| \cdashline2-4 Double | Ours(w.o. PATP&KVCache) | 72.4 | - |
| Ours(w.o. KVCache) | 29.9(-59%) | - | |
| Ours(w.o. PATP) | 36.7(-50%) | - | |
| Ours(Full) | 18.3(-75%) | 30M |
🔼 This table presents a quantitative comparison of the computational efficiency of EasyControl against several baseline methods for conditional image generation. The efficiency is evaluated by measuring the inference time (in seconds) required to generate a 1024x1024 resolution image using 25 denoising steps. The comparison includes EasyControl with several ablated versions (removing key components like the Position-Aware Training Paradigm and KV Cache), as well as well-established methods such as ControlNet, OminiControl, and ControlNet combined with other modules like IP-Adapter and Multi-ControlNet. Importantly, the parameter counts reported in the table only reflect the additional parameters introduced by each method, excluding the parameters of the pre-trained base diffusion model. This allows for a fairer comparison of the efficiency gains achieved by each method.
read the caption
Table 1: Quantitative efficiency comparison with baseline methods and different settings. The inference time is calculated when generating a 1024×\times×1024 resolution image with 25 denoising steps. The parameters refer exclusively to those of the additional module, excluding the parameters of the base model.
In-depth insights#
DiT Control Gap#
The ‘DiT Control Gap’ likely refers to the challenge of effectively controlling Diffusion Transformer (DiT) models compared to UNet-based diffusion models. DiTs struggle with efficient and flexible control, particularly in areas like spatial control, subject manipulation, and multi-condition integration. While UNets have benefited from plug-and-play modules like ControlNet, DiTs often require more complex approaches such as token concatenation or specialized fine-tuning. Computational efficiency is a major concern, as DiTs can face quadratic time complexity due to self-attention mechanisms when handling additional tokens representing control signals. Existing methods face challenges in achieving stable coordination under multi-condition guidance within a single-condition training paradigm. The representational conflicts of different conditional signals in the latent space lead to a degradation in generation quality, particularly in zero-shot multi-condition combination scenarios, where the model lacks effective cross-condition interaction mechanisms.
LoRA Injection#
LoRA injection presents a parameter-efficient approach to adapt pre-trained diffusion models. By injecting low-rank matrices, LoRA can efficiently fine-tune the model for specific conditions without modifying the original weights, preserving its generalization capability. This injection technique is particularly useful for DiTs where adding external control is difficult. LoRA’s modularity allows for a seamless integration of diverse conditions and maintains the integrity of the pre-trained feature space. LoRA is also a key to balance generation quality and adaptability with different requirements, which is useful for maintaining custom models.
Causal + KV Cache#
Causal attention with KV Cache is presented as a pivotal technique for enhancing efficiency in conditional image generation using diffusion transformers. Causal attention, by masking future tokens, ensures unidirectional information flow, critical for maintaining coherence and preventing information leaks. The KV Cache mechanism, pre-computes and stores key-value pairs of condition features during the initial diffusion step, reusing them across subsequent steps, thus avoiding redundant computation. This integration aims to significantly reduce inference latency by circumventing re-computation of conditional features. By making the conditioning branch as a computation independent module, the proposed solution isolates the computations and thus pre-computes KV pairs. Moreover, it helps to implement a condition feature caching strategy, which contributes to a substantial savings. This combination seeks to maintain high generation quality while optimizing computational resources.
Resolution Aware#
While the exact phrase “Resolution Aware” isn’t directly present, the core concept is addressed through the Position-Aware Training Paradigm. This allows the model to handle varying input resolutions by standardizing conditions to a fixed size and using Position-Aware Interpolation. This maintains spatial consistency, which helps in scenarios where spatial awareness is important. Essentially, the model becomes robust to different input dimensions, enabling more flexible and efficient image generation. The adaptive ability balances both image quality and adaptability requirements
Multi-Cond. Limits#
Multi-Condition Limitations in Diffusion Transformers highlight challenges in balancing diverse conditional inputs. Current methods may struggle with conflicting signals, leading to artifacts or reduced control. Zero-shot generalization across multiple conditions remains a key issue, as models trained on single conditions may not effectively combine them. Computational efficiency is also crucial; naively concatenating condition tokens scales poorly. The ‘Multi-Cond. Limits’ heading suggests an exploration of these trade-offs: balancing flexibility, control, and efficiency in multi-conditional image generation using diffusion transformers. Addressing these limitations is crucial for real-world application.
More visual insights#
More on figures
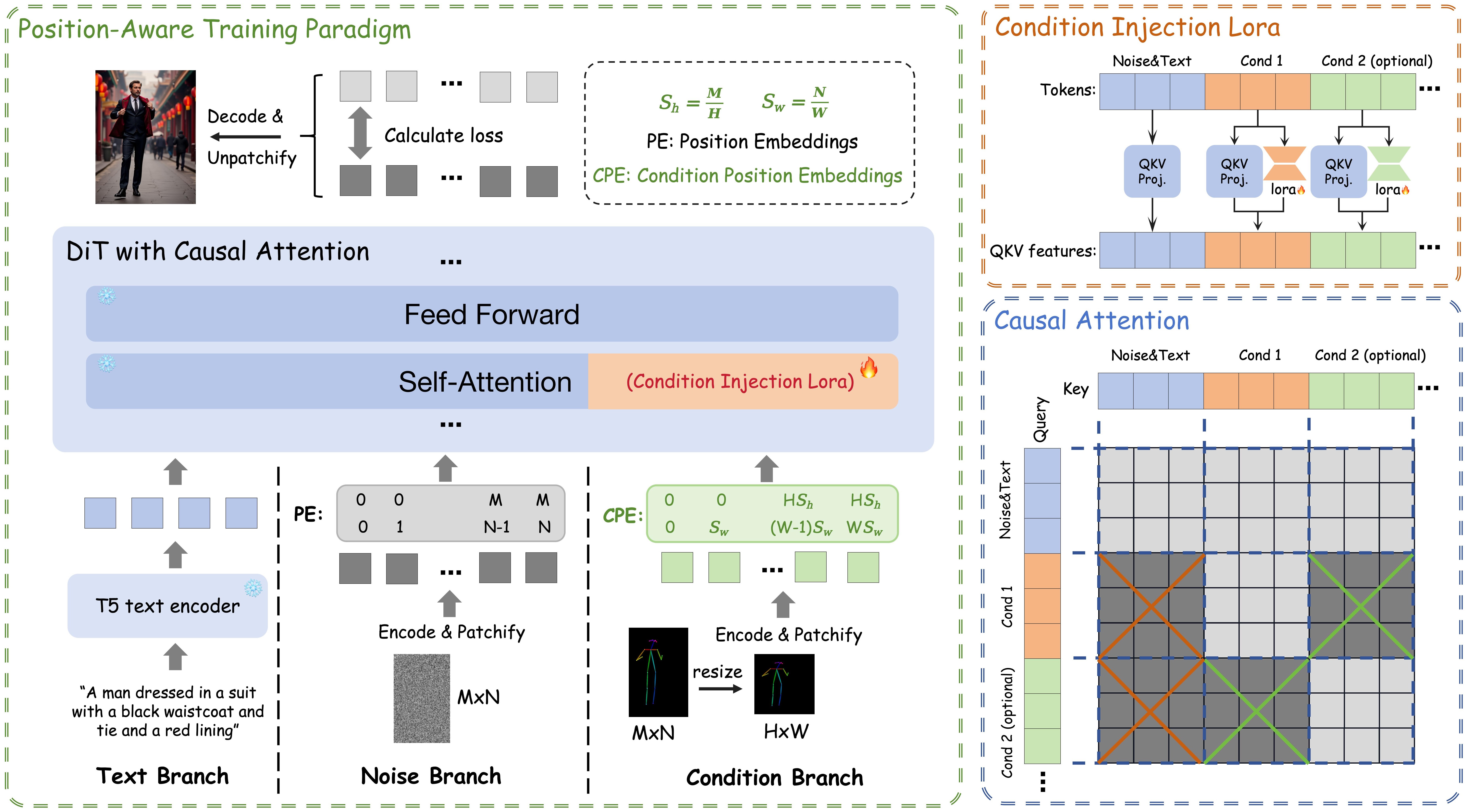
🔼 EasyControl injects condition signals into a Diffusion Transformer (DiT) via a new condition branch and a lightweight Condition Injection LoRA Module. The LoRA module is plug-and-play, compatible with various DiT models. Training uses a Position-Aware Training Paradigm, resizing condition images to a lower resolution for efficiency. This allows flexible resolution handling. Causal Attention with a KV cache further enhances efficiency. The framework seamlessly integrates multiple Condition Injection LoRA Modules, enabling effective multi-condition generation.
read the caption
Figure 2: The illustration of EasyControl framework. The condition signal is injected into the Diffusion Transformer (DiT) through a newly introduced condition branch, which encodes the condition tokens in conjunction with a lightweight, plug-and-play Condition Injection LoRA Module. During training, each individual condition is trained separately, where condition images are resized to a lower resolution and trained using our proposed Position-Aware Training Paradigm. This approach enables efficient and flexible resolution training. The framework incorporates a Causal Attention mechanism, which enables the implementation of a Key-Value (KV) Cache to substantially improve inference efficiency. Furthermore, our design facilitates the seamless integration of multiple Condition Injection LoRA Modules, enabling robust and harmonious multi-condition generation.

🔼 This figure compares various image generation methods under single-condition control. Part (a) demonstrates the results of each method under different control conditions (e.g., Canny, Depth, OpenPose, and Subject). This showcases how each model handles various control signals and their influence on the resulting image. Part (b) demonstrates the adaptability of these methods with different Style LoRA (Low-Rank Adaptation). It shows the result after applying various pre-trained style models to the generated image using each method, thus illustrating the flexibility and compatibility of each method with various styles.
read the caption
Figure 3: Visual comparison between different methods in single condition control. Figure (a) shows the results of each method under different control conditions and Figure (b) shows the adaptation of each method with different Style LoRA[56, 57, 58, 38] under control.

🔼 This figure compares the performance of different methods under multi-condition control scenarios. It shows the results generated by various approaches (including the proposed EasyControl method) when combining multiple control signals such as OpenPose and face, depth and Canny, and more. By visually inspecting the generated images, one can evaluate each model’s ability to successfully integrate multiple condition signals and generate images that are consistent with all provided control signals. The results highlight EasyControl’s superior performance in maintaining controllability and consistency while generating high-quality images, even when compared with other state-of-the-art techniques that struggle with integrating multiple conditions.
read the caption
Figure 4: Visual comparison of different methods under multi-condition control.

🔼 Figure 5 shows an ablation study on EasyControl, demonstrating the impact of removing key components on image generation quality under different scenarios. The rows depict various configurations, including single and multi-condition settings, illustrating how each module (Condition Injection LoRA, Position-Aware Training Paradigm, and Causal Mutual Attention) contributes to performance. For example, removing the Position-Aware Training Paradigm leads to issues with varying resolutions, while removing Causal Mutual Attention results in conflicts between conditions. The figure’s purpose is to highlight the individual contributions of each component within the EasyControl framework.
read the caption
Figure 5: Visual ablation on different settings.

🔼 This figure shows a selection of images from a privately held Multi-view Human Dataset. The dataset contains images of people from various angles and poses, likely used to train or evaluate the model’s ability to generate images of humans in a variety of views. The diversity in poses and angles suggests the dataset was designed to robustly capture and represent human figures.
read the caption
Figure 6: Visualization of samples in private Multi-view Human Dataset.

🔼 Figure 7 demonstrates EasyControl’s robustness in handling challenging scenarios. (a) showcases the model’s ability to generate coherent images even when conflicting instructions are provided (e.g., generating an image of a person wearing both a red and blue shirt, where the prompt specifies only one color). This highlights the model’s ability to reconcile contradictory information. (b) shows that EasyControl can generate high-quality images at very high resolutions (2560x3520), demonstrating its scalability and efficiency in producing detailed outputs.
read the caption
Figure 7: Visualization of results (1) under conflicting condition inputs (2) under very high-resolution generation.

🔼 Figure 8 displays a visual comparison of image generation results using different identity customization methods combined with multi-condition control. The figure shows several examples of image generation with two different control conditions (Control 1 and Control 2), each influencing the generated image differently. The ‘Ours’ column shows the output of the proposed method, EasyControl, showcasing its ability to effectively combine these controls. Subsequent columns (‘ControlNet + …’) display results from other methods, highlighting how EasyControl handles multi-condition generation more effectively than the compared alternatives in maintaining identity consistency and overall image quality.
read the caption
Figure 8: Visual comparison with Identity customization methods under multi-condition generation setting.

🔼 This figure demonstrates the effectiveness of EasyControl in spatial control generation. It showcases several examples of image generation guided by different spatial control inputs, comparing the ground truth (GT) with results from EasyControl, ControlNet, and OminiControl. The results highlight EasyControl’s ability to accurately reflect the spatial guidance in the generated images, achieving higher quality and fidelity compared to the other methods.
read the caption
Figure 9: Visualization of spatial control generation.

🔼 This figure visualizes the results of subject control generation using the proposed EasyControl method. It shows multiple examples of generated images where the subject (object) is controlled by a given input condition image. Each row in the figure represents a different object and the columns show (from left to right): the input condition image, generated images by EasyControl, generated images by ControlNet, generated images by OmniControl, and generated images by Uni-ControlNet for comparison. The figure aims to demonstrate the effectiveness of EasyControl in achieving high-fidelity subject-controlled image generation compared to existing methods.
read the caption
Figure 10: Visualization of subject control generation.

🔼 Figure 11 shows a comparison of image generation results at various resolutions (256x352, 512x704, 1024x1408, 1280x1760) using three different methods: ControlNet, OminiControl, and the proposed EasyControl method. A canny edge map serves as the control input, and the text prompt is ‘A red and black motorcycle.’ The figure demonstrates how each method handles different resolutions, allowing for a visual assessment of their performance across various scales. Zooming in is recommended for a detailed analysis.
read the caption
Figure 11: Visual comparison with baseline methods under different resolution generation settings.(zoom in for a better view)
More on tables
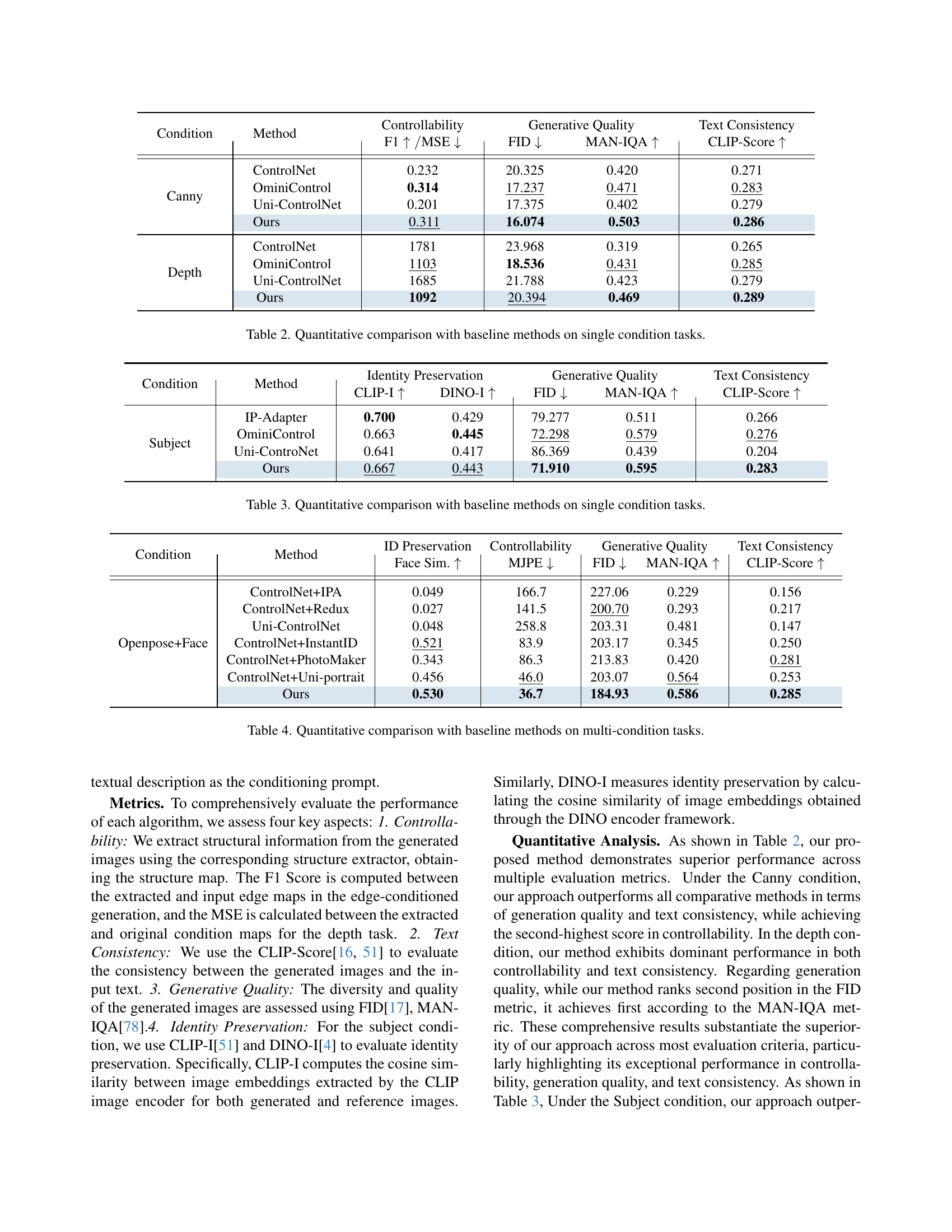
| Condition | Method | Controllability | Generative Quality | Text Consistency | |
|---|---|---|---|---|---|
| Canny | ControlNet | 0.232 | 20.325 | 0.420 | 0.271 |
| OminiControl | 0.314 | 17.237 | 0.471 | 0.283 | |
| Uni-ControlNet | 0.201 | 17.375 | 0.402 | 0.279 | |
| Ours | 0.311 | 16.074 | 0.503 | 0.286 | |
| Depth | ControlNet | 1781 | 23.968 | 0.319 | 0.265 |
| OminiControl | 1103 | 18.536 | 0.431 | 0.285 | |
| Uni-ControlNet | 1685 | 21.788 | 0.423 | 0.279 | |
| Ours | 1092 | 20.394 | 0.469 | 0.289 | |
🔼 This table presents a quantitative comparison of EasyControl against several baseline methods for single-condition image generation tasks. It evaluates performance across three key aspects: Controllability (measured by F1-score and Mean Squared Error (MSE) for Canny and Depth conditions, and by the CLIP-Score for Subject conditions), Generative Quality (assessed using the Frechet Inception Distance (FID) and the Mean Opinion Score (MAN-IQA)), and Text Consistency (measured by the CLIP-Score). Lower FID and MSE values, and higher F1, MAN-IQA, and CLIP-Score indicate better performance. The table compares EasyControl against ControlNet, OminiControl, and Uni-ControlNet for Canny and Depth conditions, and against IP-Adapter, OminiControl, and Uni-ControlNet for Subject conditions.
read the caption
Table 2: Quantitative comparison with baseline methods on single condition tasks.
| Condition | Method | Identity Preservation | Generative Quality | Text Consistency | ||
|---|---|---|---|---|---|---|
| Subject | IP-Adapter | 0.700 | 0.429 | 79.277 | 0.511 | 0.266 |
| OminiControl | 0.663 | 0.445 | 72.298 | 0.579 | 0.276 | |
| Uni-ControNet | 0.641 | 0.417 | 86.369 | 0.439 | 0.204 | |
| Ours | 0.667 | 0.443 | 71.910 | 0.595 | 0.283 | |
🔼 This table presents a quantitative comparison of EasyControl against several baseline methods for single-condition image generation tasks. Metrics used for comparison include controllability (measured by F1-score and MSE for Canny and Depth control, and CLIP-I and DINO-I for Subject control), generative quality (measured by FID and MAN-IQA), and text consistency (measured by CLIP-score). The results show EasyControl’s performance compared to baselines such as ControlNet, OmniControl, and Uni-ControlNet across various single-condition tasks.
read the caption
Table 3: Quantitative comparison with baseline methods on single condition tasks.
| Condition | Method | ID Preservation | Controllability | Generative Quality | Text Consistency | |
|---|---|---|---|---|---|---|
| Openpose+Face | ControlNet+IPA | 0.049 | 166.7 | 227.06 | 0.229 | 0.156 |
| ControlNet+Redux | 0.027 | 141.5 | 200.70 | 0.293 | 0.217 | |
| Uni-ControlNet | 0.048 | 258.8 | 203.31 | 0.481 | 0.147 | |
| ControlNet+InstantID | 0.521 | 83.9 | 203.17 | 0.345 | 0.250 | |
| ControlNet+PhotoMaker | 0.343 | 86.3 | 213.83 | 0.420 | 0.281 | |
| ControlNet+Uni-portrait | 0.456 | 46.0 | 203.07 | 0.564 | 0.253 | |
| Ours | 0.530 | 36.7 | 184.93 | 0.586 | 0.285 | |
🔼 This table presents a quantitative comparison of EasyControl against several baseline methods for multi-condition image generation. It evaluates performance across four key aspects: Identity Preservation (Face Similarity, how well the model preserves the identity of faces), Controllability (MJPE, a metric measuring the accuracy of pose estimation), Generative Quality (FID, MAN-IQA, measures assessing the quality and diversity of generated images), and Text Consistency (CLIP-Score, evaluates how well generated images align with text prompts). The baseline methods compared are ControlNet+IP-Adapter, ControlNet+Redux, Uni-ControlNet, ControlNet+InstantID, ControlNet+PhotoMaker, ControlNet+Uni-portrait, all employing a variety of techniques for combining multiple conditions. The results allow for a quantitative assessment of EasyControl’s ability to handle multiple conditions, achieve high image generation quality, and maintain text consistency.
read the caption
Table 4: Quantitative comparison with baseline methods on multi-condition tasks.
Full paper#