TL;DR#
Current 2D-to-3D perception methods face challenges of limited generalization, suboptimal accuracy, and slow speeds. Existing methods rely on scene-specific training, introducing computational overhead and limiting scalability, hindering real-world applications. Addressing these limitations is vital for advancing 3D scene understanding.
This paper introduces a novel framework for efficient 3D semantic reconstruction. It uses pixel embedding disambiguation, semantic field reconstruction, and global view perception to reconstruct 3D scenes solely from 2D images. It achieves over 9-fold speedups and improved accuracy without pre-calibrated 3D data.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it introduces a new approach to 3D scene understanding that is both efficient and accurate. It addresses the limitations of existing methods and sets new benchmarks for performance, opening new avenues for future research in robotics, AR, and computer vision.
Visual Insights#
| Dataset | Method | mIoU | mPA | mP |
|---|---|---|---|---|
| Mip. | LERF (Kerr et al., 2023) | 0.2698 | 0.8183 | 0.6553 |
| F-3DGS (Zhou et al., 2024) | 0.3889 | 0.8279 | 0.7085 | |
| GS Grouping (Ye et al., 2023) | 0.4410 | 0.7586 | 0.7611 | |
| LangSplat (Qin et al., 2024) | 0.5545 | 0.8071 | 0.8600 | |
| GOI (Qu et al., 2024) | 0.8646 | 0.9569 | 0.9362 | |
| PE3R, ours | 0.8951 | 0.9617 | 0.9726 | |
| Rep. | LERF (Kerr et al., 2023) | 0.2815 | 0.7071 | 0.6602 |
| F-3DGS (Zhou et al., 2024) | 0.4480 | 0.7901 | 0.7310 | |
| GS Grouping (Ye et al., 2023) | 0.4170 | 0.7370 | 0.7276 | |
| LangSplat (Qin et al., 2024) | 0.4703 | 0.7694 | 0.7604 | |
| GOI (Qu et al., 2024) | 0.6169 | 0.8367 | 0.8088 | |
| PE3R, ours | 0.6531 | 0.8377 | 0.8444 |
🔼 Table 1 presents the results of 2D-to-3D open-vocabulary segmentation on two smaller datasets: Mipnerf360 and Replica. It compares the performance of several different methods, including the proposed PE3R method, across three key metrics: mean Intersection over Union (mIoU), mean Pixel Accuracy (mPA), and mean Precision (mP). These metrics assess the accuracy of the methods in segmenting objects in 3D scenes based on 2D image inputs. The table shows that PE3R outperforms the other methods on both datasets, demonstrating its superior performance in open-vocabulary 3D scene understanding.
read the caption
Table 1: 2D-to-3D Open-Vocabulary Segmentation on small datasets, i.e., Mipnerf360 (Mip.) and Replica (Rep.).
In-depth insights#
2D-to-3D w/o 3D#
The idea of 2D-to-3D reconstruction without direct 3D supervision is a compelling research direction. Traditional 3D reconstruction heavily relies on 3D data (e.g., LiDAR, depth sensors, camera parameters). However, acquiring such data can be difficult, expensive, or even impossible in certain scenarios. Thus, the goal of ‘2D-to-3D w/o 3D’ is to leverage 2D images as the primary source of information. This approach requires clever techniques to infer 3D geometry and semantics from 2D cues alone. Multi-view consistency, shape priors learned from large datasets, and the use of generative models are potential avenues. Success in this area would unlock applications in robotics, augmented reality, and scene understanding.
Efficient Semantics#
Efficient semantics refers to the methodologies and frameworks that enable rapid and precise extraction and utilization of semantic information from data, particularly in 3D reconstruction. This involves optimizing computational processes to minimize resource consumption while maximizing the accuracy and relevance of semantic interpretations. Key elements include algorithms that can quickly disambiguate semantic meanings from multi-view images, integrating semantic understanding directly into the reconstruction pipeline to guide and refine the geometric modeling process, and developing representations that allow for efficient querying and manipulation of semantic information within the 3D scene. The focus is on creating solutions that are not only accurate but also scalable and applicable in real-time or large-scale scenarios, reducing the bottlenecks associated with traditional, more computationally intensive semantic analysis techniques. The goal is to build systems that can quickly adapt to different environments and data types, providing a seamless and effective understanding of complex 3D scenes.
Feed-Forward 3D#
Feed-forward 3D reconstructs 3D structure using only 2D inputs, bypassing traditional reliance on 3D data. It enhances efficiency by eliminating iterative refinement. This allows for significantly faster processing, enabling real-time applications. The method emphasizes speed and scalability, crucial for scenarios where 3D data is scarce or computationally expensive to acquire. This approach marks a departure from complex optimization-based methods, offering a pathway to more accessible 3D scene understanding. Benefits include enhanced real-time performance and scalability.
Pixel Embedding++#
Pixel Embedding techniques are vital for bridging the gap between 2D image data and 3D scene understanding, especially in contexts lacking explicit 3D information. These methods aim to represent each pixel with a feature vector (embedding) that captures its semantic and geometric properties. Enhancements over standard pixel embeddings (i.e., ‘Pixel Embedding++’) likely involve addressing key challenges like viewpoint consistency, occlusion handling, and semantic ambiguity. This could involve integrating information from multiple views to create more robust embeddings or using contextual information to disambiguate pixel meanings. Advanced techniques might also focus on learning embeddings that are invariant to changes in lighting or camera pose, further improving their reliability for 3D reconstruction and perception tasks. The goal is to create pixel representations that effectively encode the information needed to infer 3D scene structure and semantics from 2D images.
Scalable Vision#
Scalable vision is key to deploying computer vision models in real-world applications. This means models should perform effectively with varying input image sizes, resolutions, and complexities, without significant performance degradation. Efficiency in terms of computational resources is also critical; models must process data quickly and with minimal energy consumption. Furthermore, a scalable vision system should generalize well across diverse environments, datasets, and tasks. To achieve this, consider modular architectures, efficient data structures, and transfer learning. Robustness to noise and outliers should also be considered. This requires careful data augmentation and preprocessing techniques, as well as model architectures that are less sensitive to noisy inputs. Moreover, a scalable vision system should be easy to adapt and extend to new tasks and environments. Consider modular design and standard APIs to facilitate integration with other systems. Addressing these considerations enables building more practical and useful vision systems.
More visual insights#
More on tables
| Method | Preprocess | Training | Total |
|---|---|---|---|
| LERF (Kerr et al., 2023) | 3mins | 40mins | 43mins |
| F-3DGS (Zhou et al., 2024) | 25mins | 623mins | 648mins |
| GS Grouping (Ye et al., 2023) | 27mins | 138mins | 165mins |
| LangSplat (Qin et al., 2024) | 50mins | 99mins | 149mins |
| GOI (Qu et al., 2024) | 8mins | 37mins | 45mins |
| PE3R, ours | 5mins | - | 5mins |
🔼 This table compares the running speed of different methods for 3D reconstruction on the Mipnerf360 dataset. It breaks down the total time into pre-processing, training, and the overall time taken, showing the significant speed advantage of the PE3R method compared to other state-of-the-art techniques.
read the caption
Table 2: Running Speed comparison on Mipnerf360.
| Method | mIoU | mPA | mP |
|---|---|---|---|
| LERF (Kerr et al., 2023) Features | 0.1824 | 0.6024 | 0.5873 |
| GOI (Qu et al., 2024) Features | 0.2101 | 0.6216 | 0.6013 |
| PE3R, ours | 0.2248 | 0.6542 | 0.6315 |
🔼 This table presents the results of 2D-to-3D open-vocabulary segmentation on the ScanNet++ dataset, a large-scale dataset. It compares the performance of the proposed PE3R method against existing state-of-the-art methods, LERF and GOI, using three standard metrics: mean Intersection over Union (mIoU), mean Pixel Accuracy (mPA), and mean Precision (mP). The results showcase the effectiveness of PE3R in achieving a higher level of accuracy compared to other methods.
read the caption
Table 3: 2D-to-3D Open-Vocabulary Segmentation on the large-scale dataset, i.e., ScanNet++.
| Methods | KITTI | ScanNet | ETH3D | DTU | T&T | Ave. | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| rel | rel | rel | rel | rel | rel | ||||||||
| (a) | COLMAP (Schonberger & Frahm, 2016) | 12.0 | 58.2 | 14.6 | 34.2 | 16.4 | 55.1 | 0.7 | 96.5 | 2.7 | 95.0 | 9.3 | 67.8 |
| COLMAP Dense (Schönberger et al., 2016) | 26.9 | 52.7 | 38.0 | 22.5 | 89.8 | 23.2 | 20.8 | 69.3 | 25.7 | 76.4 | 40.2 | 48.8 | |
| (b) | MVSNet (Yao et al., 2018) | 22.7 | 36.1 | 24.6 | 20.4 | 35.4 | 31.4 | 1.8 | 86.0 | 8.3 | 73.0 | 18.6 | 49.4 |
| MVSNet Inv. Depth (Yao et al., 2018) | 18.6 | 30.7 | 22.7 | 20.9 | 21.6 | 35.6 | 1.8 | 86.7 | 6.5 | 74.6 | 14.2 | 49.7 | |
| Vis-MVSSNet (Zhang et al., 2023b) | 9.5 | 55.4 | 8.9 | 33.5 | 10.8 | 43.3 | 1.8 | 87.4 | 4.1 | 87.2 | 7.0 | 61.4 | |
| MVS2D ScanNet (Yang et al., 2022) | 21.2 | 8.7 | 27.2 | 5.3 | 27.4 | 4.8 | 17.2 | 9.8 | 29.2 | 4.4 | 24.4 | 6.6 | |
| MVS2D DTU (Yang et al., 2022) | 226.6 | 0.7 | 32.3 | 11.1 | 99.0 | 11.6 | 3.6 | 64.2 | 25.8 | 28.0 | 77.5 | 23.1 | |
| (c) | DeMon (Ummenhofer et al., 2017) | 16.7 | 13.4 | 75.0 | 0.0 | 19.0 | 16.2 | 23.7 | 11.5 | 17.6 | 18.3 | 30.4 | 11.9 |
| DeepV2D KITTI (Teed & Deng, 2018) | 20.4 | 16.3 | 25.8 | 8.1 | 30.1 | 9.4 | 24.6 | 8.2 | 38.5 | 9.6 | 27.9 | 10.3 | |
| DeepV2D ScanNet (Teed & Deng, 2018) | 61.9 | 5.2 | 3.8 | 60.2 | 18.7 | 28.7 | 9.2 | 27.4 | 33.5 | 38.0 | 25.4 | 31.9 | |
| MVSNet (Yao et al., 2018) | 14.0 | 35.8 | 1568.0 | 5.7 | 507.7 | 8.3 | 4429.1 | 0.1 | 118.2 | 50.7 | 1327.4 | 20.1 | |
| MVSNet Inv. Depth (Yao et al., 2018) | 29.6 | 8.1 | 65.2 | 28.5 | 60.3 | 5.8 | 28.7 | 48.9 | 51.4 | 14.6 | 47.0 | 21.2 | |
| Vis-MVSNet (Zhang et al., 2023b) | 10.3 | 54.4 | 84.9 | 15.6 | 51.5 | 17.4 | 374.2 | 1.7 | 21.1 | 65.6 | 108.4 | 31.0 | |
| MVS2D ScanNet (Yang et al., 2022) | 73.4 | 0.0 | 4.5 | 54.1 | 30.7 | 14.4 | 5.0 | 57.9 | 56.4 | 11.1 | 34.0 | 27.5 | |
| MVS2D DTU (Yang et al., 2022) | 93.3 | 0.0 | 51.5 | 1.6 | 78.0 | 0.0 | 1.6 | 92.3 | 87.5 | 0.0 | 62.4 | 18.8 | |
| Robust MVD (Schröppel et al., 2022) | 7.1 | 41.9 | 7.4 | 38.4 | 9.0 | 42.6 | 2.7 | 82.0 | 5.0 | 75.1 | 6.3 | 56.0 | |
| (d) | DeMoN (Ummenhofer et al., 2017) | 15.5 | 15.2 | 12.0 | 21.0 | 17.4 | 15.4 | 21.8 | 16.6 | 13.0 | 23.2 | 16.0 | 18.3 |
| DeepV2D KITTI (Teed & Deng, 2018) | 3.1 | 74.9 | 23.7 | 11.1 | 27.1 | 10.1 | 24.8 | 8.1 | 34.1 | 9.1 | 22.6 | 22.7 | |
| DeepV2D ScanNet (Teed & Deng, 2018) | 10.0 | 36.2 | 4.4 | 54.8 | 11.8 | 29.3 | 7.7 | 33.0 | 8.9 | 46.4 | 8.6 | 39.9 | |
| (e) | DUSt3R (Wang et al., 2024) | 9.1 | 39.5 | 4.9 | 60.2 | 2.9 | 76.9 | 3.5 | 69.3 | 3.2 | 76.7 | 4.7 | 64.5 |
| DUSt3R (Wang et al., 2024), our imp. | 11.0 | 33.2 | 4.8 | 60.3 | 3.1 | 74.5 | 2.7 | 75.7 | 2.9 | 78.5 | 4.9 | 64.4 | |
| MASt3R (Leroy et al., 2024), our imp. | 36.9 | 5.4 | 22.0 | 9.6 | 27.9 | 9.9 | 13.6 | 13.7 | 22.1 | 14.6 | 24.5 | 10.6 | |
| PE3R, ours | 9.4 | 48.6 | 5.5 | 55.1 | 2.3 | 82.0 | 3.2 | 69.1 | 2.1 | 85.3 | 4.5 | 68.0 | |
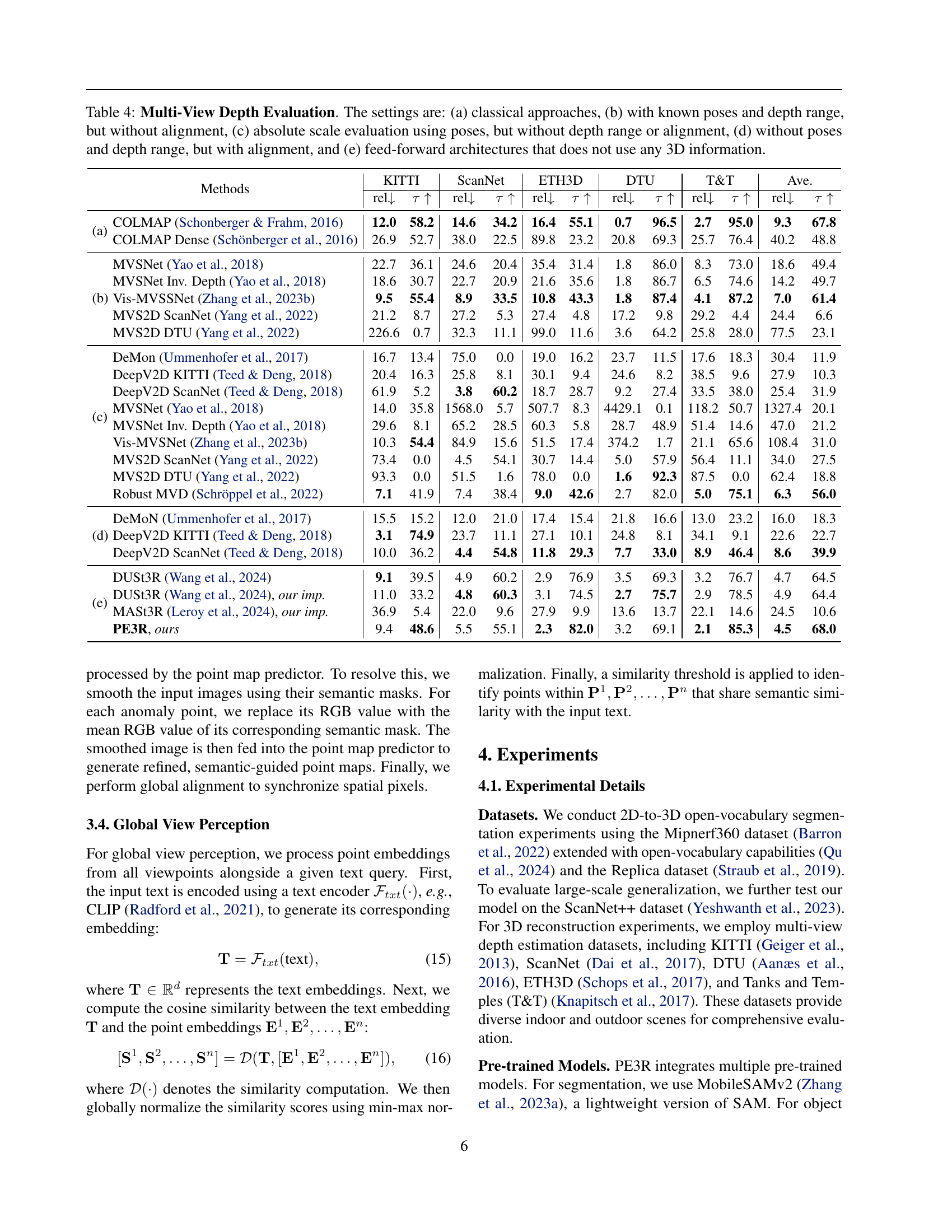
🔼 Table 4 presents a comparison of various multi-view depth estimation methods. It categorizes these methods into five groups based on the information available to them during depth estimation: (a) Classical approaches using standard techniques; (b) Methods leveraging known camera poses and depth ranges but lacking alignment; (c) Methods using poses for absolute scale but without depth range or alignment; (d) Methods utilizing alignment but lacking poses and depth ranges; and (e) Feed-forward architectures that do not require 3D information. The results illustrate how the availability (or lack) of such information affects the accuracy of depth estimation.
read the caption
Table 4: Multi-View Depth Evaluation. The settings are: (a) classical approaches, (b) with known poses and depth range, but without alignment, (c) absolute scale evaluation using poses, but without depth range or alignment, (d) without poses and depth range, but with alignment, and (e) feed-forward architectures that does not use any 3D information.
| Method | mIoU | mPA | mP |
|---|---|---|---|
| PE3R, w/o Multi-Level Disam. | 0.1624 | 0.5892 | 0.5623 |
| PE3R, w/o Cross-View Disam. | 0.1895 | 0.6012 | 0.5923 |
| PE3R, w/o Global MinMax Norm. | 0.2035 | 0.6253 | 0.6186 |
| PE3R | 0.2248 | 0.6542 | 0.6315 |
🔼 This table presents the results of ablation studies conducted to evaluate the impact of different components within the PE3R (Perception-Efficient 3D Reconstruction) framework on 2D-to-3D open-vocabulary segmentation. Specifically, it shows how removing the multi-level disambiguation, cross-view disambiguation, and global min-max normalization modules affects the model’s performance on the ScanNet++ dataset. The metrics used to assess performance are mean Intersection over Union (mIoU), mean Pixel Accuracy (mPA), and mean Precision (mP). The table allows for a comparison of the full PE3R model against versions with individual components removed, highlighting the contribution of each component to the overall accuracy.
read the caption
Table 5: Ablation Studies for 2D-to-3D open-vocabulary segmentation on ScanNet++ dataset.
| Method | rel | Run Time | |
|---|---|---|---|
| PE3R, w/o Semantic Field Rec. | 5.3 | 60.2 | 10.4021s |
| PE3R | 4.5 | 68.0 | 11.1934s |
🔼 This table presents the results of ablation studies conducted to evaluate the impact of semantic field reconstruction on the overall performance of the PE3R framework. It compares the relative error (rel) and run time of the PE3R model with and without the semantic field reconstruction module. The results demonstrate that incorporating semantic field reconstruction significantly improves the accuracy of the 3D reconstruction while only slightly increasing computation time.
read the caption
Table 6: Ablation Studies on semantic field reconstruction.
Full paper#