TL;DR#
Existing image generation models often struggle with model bias, limited text rendering, and understanding cultural elements. To overcome these issues, Seedream 2.0 was created as a native Chinese-English bilingual model. It adeptly handles text prompts in both languages, supports bilingual image generation and text rendering, and uses data systems and captioning to enhance knowledge integration and description accuracy.
Seedream 2.0 features a self-developed bilingual LLM as a text encoder, enabling learning from massive data and generating high-fidelity images with cultural nuances. Glyph-Aligned ByT5 is used for text rendering, and a Scaled ROPE generalizes to untrained resolutions. Post-training optimizations, including SFT and RLHF, improve capabilities like prompt-following and structural correctness, aligning the model with human preferences.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a new bilingual image generation model that addresses the limitations of existing models. It opens new avenues for cross-cultural content creation, improving text rendering in images, especially in Chinese, and understanding cultural nuances, which could impact various creative and commercial applications.
Visual Insights#

🔼 This figure presents a radar chart comparing Seedream 2.0’s performance against other leading image generation models (Midjourney v6.1, FLUX1.1 Pro, GPT-40, Ideogram 2.0) across multiple evaluation metrics. These metrics assess various aspects of image quality, including aesthetics, text accuracy, structural correctness, and prompt following ability. Separate charts are shown for evaluations using English prompts and Chinese prompts, showcasing Seedream 2.0’s bilingual capabilities. Seedream 2.0 consistently outperforms or is competitive with the other models in all categories, demonstrating its superior performance in both languages.
read the caption
Figure 1: Seedream2.0 demonstrates outstanding performance across all evaluation aspects in both English and Chinese.
| VQAScore | EvalMuse | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | total | Total | Object | Activity | a./h. | Attribute | Location | Color | Counting | Other |
| Seedream 2.0 | 0.8031 | 0.682 | 0.747 | 0.662 | 0.756 | 0.821 | 0.793 | 0.706 | 0.477 | 0.665 |
| GPT-4o | 0.7974 | 0.656 | 0.732 | 0.644 | 0.734 | 0.814 | 0.782 | 0.692 | 0.438 | 0.640 |
| FLUX1.1 Pro | 0.7877 | 0.617 | 0.694 | 0.596 | 0.686 | 0.819 | 0.758 | 0.660 | 0.362 | 0.642 |
| Ideogram 2.0 | 0.8226 | 0.632 | 0.720 | 0.617 | 0.693 | 0.813 | 0.743 | 0.680 | 0.351 | 0.637 |
| Midjourney v6.1 | 0.7569 | 0.583 | 0.693 | 0.599 | 0.619 | 0.807 | 0.736 | 0.637 | 0.285 | 0.583 |
🔼 This table presents a quantitative comparison of different text-to-image models using two automated evaluation metrics: VQAScore and EvalMuse. VQAScore assesses the alignment between generated images and their corresponding text prompts, while EvalMuse provides a more fine-grained evaluation across multiple aspects such as object, activity, attribute, location, color, material, and others. The results offer an objective perspective on the relative strengths and weaknesses of each model in terms of image-text coherence and overall image quality.
read the caption
Table 1: Automatic evaluation results using VQAScore and EvalMuse.
In-depth insights#
Bilingual LLM#
The document emphasizes the importance of bilingual LLMs (Large Language Models) for image generation, specifically Chinese-English. It highlights that integrating a self-developed bilingual LLM as a text encoder allows the model to learn native knowledge directly from massive data in both languages. This is crucial for generating high-fidelity images with accurate cultural nuances and aesthetic expressions. Existing models often struggle with understanding Chinese cultural characteristics, making bilingual LLMs essential for addressing this deficiency. The model leverages the strong capabilities of LLMs to achieve superior performance in long-text understanding and complicated instruction following, surpassing traditional CLIP or T5 encoders. Thus improving alignment between text and image features is achieved.
Glyph-Aligned ByT5#
The concept of a Glyph-Aligned ByT5 model is intriguing, especially in the context of text-to-image generation, it targets the intricate details of glyph rendering. The “Glyph-Aligned” aspect suggests a methodology that prioritizes the accurate representation of individual glyphs or characters. This alignment would likely involve carefully mapping the model’s internal representations to the visual features of glyphs, ensuring that generated text is legible and stylistically consistent, this approach directly tackles challenges in text rendering, particularly in languages with complex character sets or when dealing with stylized fonts. A ByT5 backbone provides a strong foundation for understanding and generating text. This model would likely provide accurate character-level features or embeddings and ensure the consistency of glyph features of rendered text.
Scaled ROPE#
The idea of a “Scaled ROPE” is intriguing, addressing a crucial challenge in image generation: generalization to untrained resolutions. Positional embeddings, like ROPE, are vital for transformers to understand the spatial relationships within an image. However, standard ROPE might struggle when the input resolution deviates significantly from the training data. ‘Scaled ROPE’ likely introduces a mechanism to dynamically adjust the ROPE parameters based on the input resolution. This could involve scaling the frequencies used in the ROPE calculation, ensuring that the positional information remains meaningful even at different scales. By allowing the model to share similar position IDs across different resolutions. This implies a more robust and flexible positional encoding scheme, ultimately leading to better image quality and consistency across a wider range of output sizes. The effectiveness of this scaling would depend on how well it preserves the underlying positional relationships and avoids introducing artifacts.
Multi-RLHF#
Multi-RLHF (Reinforcement Learning from Human Feedback) likely refers to employing multiple stages or types of RLHF to refine a model. This could involve using several reward models, each capturing different aspects of desired behavior (e.g., aesthetics, text alignment, structure). Another approach may use multiple RLHF algorithms or iterative refinement loops. This allows for a more comprehensive optimization across different dimensions. The goal is to better align the model with human preferences, leading to more nuanced and robust improvements compared to a single RLHF stage. This method helps better generation of results.
SeedEdit 1.0#
Based on the context provided, ‘SeedEdit 1.0’ refers to an instruction-based image editing model. The paper highlights that SeedEdit excels in maintaining high aesthetic and compositional fidelity in edited images, surpassing existing benchmarks. It also uses an iterative optimization to improve integration of image and textual features. The paper states that the explained method is SeedEdit V1.0, suggesting subsequent improvements. Improved ID preservation is key, addressing initial issues where the model struggled to retain human facial identity when the face was small, or affected by text-conditional bias. Multi-Expert Data Fusion improves it using real IDs, conditionally merged. Face-Aware Loss boosts this using facial similarity measurement, where the initial SeedEdit version had limitations in this area. Data Optimization improves filters to further edit.
More visual insights#
More on figures

🔼 Figure 2 is a collage of images generated by Seedream 2.0, showcasing the model’s capabilities in generating diverse image styles, including illustrations, realistic photos, and culturally-specific scenes. It demonstrates the model’s ability to understand and respond to various prompts in both English and Chinese. The collage highlights the wide range of applications Seedream 2.0 can support.
read the caption
Figure 2: Seedream 2.0 Visualization.

🔼 This figure illustrates the system used for creating the pre-training dataset for Seedream 2.0. It shows four main components of the dataset: High-Quality Data (data with exceptionally high image quality and rich knowledge content), Distribution Maintenance Data (maintains useful distribution while reducing low-quality data through downsampling and clustering), Knowledge Injection Data (adds data with specific Chinese cultural contexts), and Supplementary Data (addresses areas of model weakness through active learning). The figure depicts the flow of data through these components and illustrates the steps involved in creating a balanced and comprehensive dataset for training.
read the caption
Figure 3: Pre-training data system.

🔼 This figure illustrates the process of incorporating external knowledge into the pre-training dataset. It begins with uncurated data that undergoes deduplication and retrieval steps. The embedding step generates representations of data from a taxonomy, allowing the system to add knowledge-rich pairs to the dataset. Finally, the augmented and curated data is used in the pre-training process.
read the caption
Figure 4: Overview of our knowledge injection process.

🔼 This figure illustrates the multi-stage data cleaning process employed to ensure high quality and relevance of the dataset used in the Seedream 2.0 model training. The process starts with uncurated data and proceeds through three stages. Stage 1 involves a general quality assessment based on criteria such as image clarity, presence of watermarks or logos, and overall meaningfulness of content. Images failing to meet the standards are removed. Stage 2 performs detailed quality assessments using methods like feature embedding extraction, deduplication and hierarchical clustering to refine data distribution and eliminate lower-quality samples. Finally, Stage 3 involves captioning and re-captioning images, providing richer descriptions for higher-level data and ensuring consistency.
read the caption
Figure 5: Overview of our data cleaning process.

🔼 The figure illustrates the iterative process of active learning used in the data pre-processing stage. It starts with labeling a small subset of the unlabeled image data. A classifier is trained using this labeled data. Then, the classifier is used to select the most uncertain or informative samples from the remaining unlabeled data. These selected samples are then labeled by human annotators, adding to the labeled dataset. This cycle of classifier training and sample selection repeats until a satisfactory level of data quality is achieved or a specified number of iterations are completed.
read the caption
Figure 6: Flow diagram of Active Learning Lifecycle.

🔼 Figure 7 shows several examples of image captions used in the training data for the Seedream 2.0 model. These examples showcase the different types of captions that were created, including short generic captions that briefly summarize the main content of an image, longer generic captions that provide more detailed and descriptive information, artistic captions that focus on stylistic elements and visual characteristics, textual captions that focus on any text present in the image, and surreal captions that describe the image from a more imaginative and fantastical perspective. The variety in the captions reflects the model’s training on diverse descriptions, enhancing the model’s ability to generate images with rich and varied textual content.
read the caption
Figure 7: Caption examples in our training data.

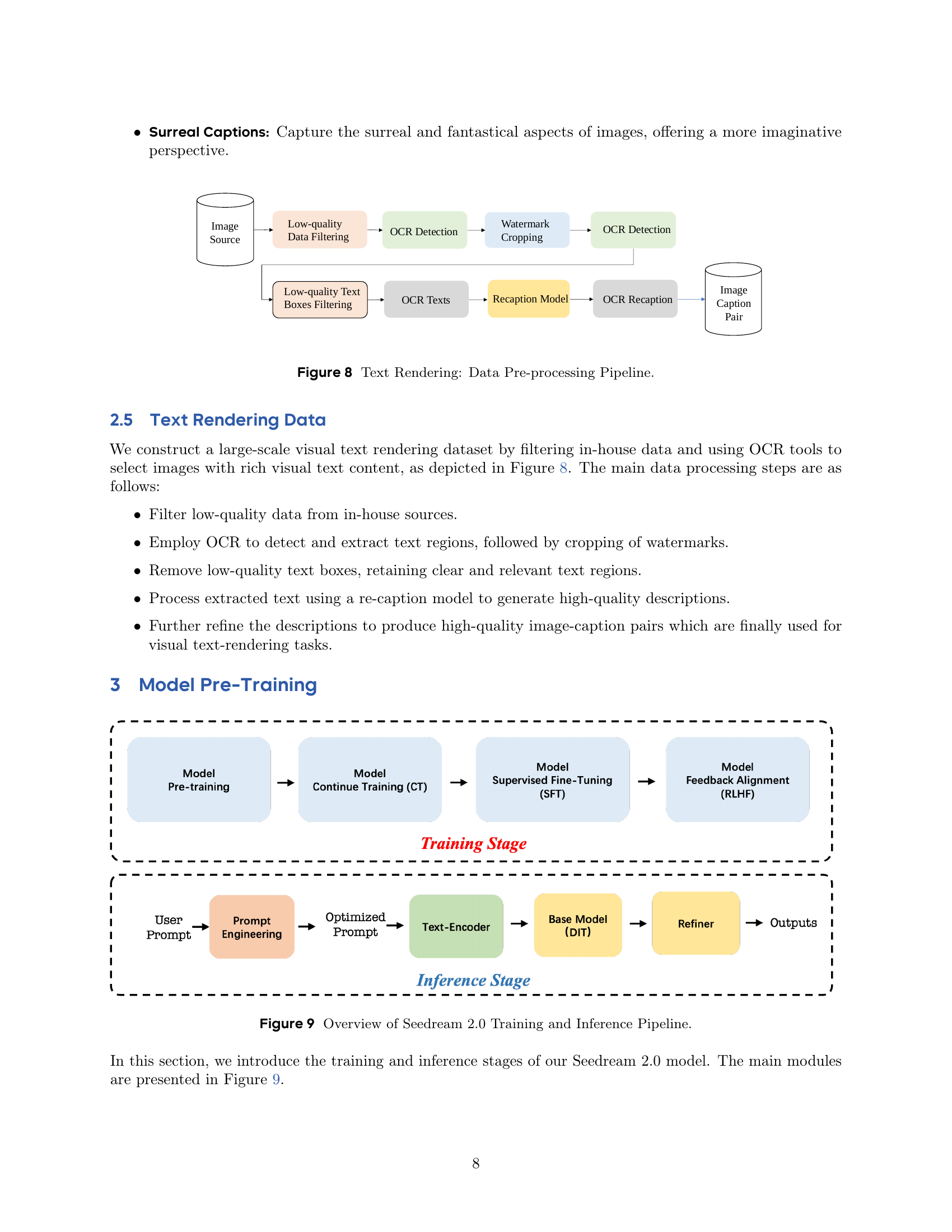
🔼 This figure illustrates the data pre-processing pipeline used for text rendering in the Seedream 2.0 model. The pipeline begins with an image source and filters out low-quality data. Then, Optical Character Recognition (OCR) is used to detect and extract text regions, followed by filtering out low-quality text boxes. A re-captioning model is then used to generate high-quality descriptions for the remaining text regions. Finally, these descriptions are paired with the corresponding images to create a high-quality dataset for training the model’s text rendering capabilities.
read the caption
Figure 8: Text Rendering: Data Pre-processing Pipeline.

🔼 This figure illustrates the overall architecture of the Seedream 2.0 model, detailing the training and inference pipelines. The training pipeline shows the sequential stages: pre-training, continued training (CT), supervised fine-tuning (SFT), and human feedback alignment (RLHF). Each stage utilizes specific data and training strategies to refine the model’s capabilities. The inference stage demonstrates how a user prompt is processed, involving prompt engineering and use of a text encoder and a base diffusion model (DIT), before producing the final image output. The refiner module is also shown, handling post-processing steps to optimize the final image. This comprehensive view highlights the multi-stage approach towards achieving high-quality image generation.
read the caption
Figure 9: Overview of Seedream 2.0 Training and Inference Pipeline.

🔼 Figure 10 presents a detailed overview of the Seedream 2.0 model architecture. It illustrates the flow of data processing from input image and text to final image generation. Key components highlighted include the Variational Autoencoder (VAE) for image encoding, the Glyph-Aligned ByT5 and LLM for text encoding, the Diffusion Transformer with its MMDiT blocks, and the Scaled ROPE for positional encoding. The figure shows how these components interact to generate high-fidelity images, including the use of AdaLN and modulation techniques within the transformer blocks. The figure also highlights the character-level text encoding using Glyph-ByT5.
read the caption
Figure 10: Overview of Model Architecture.

🔼 This figure visualizes the intermediate results of Seedream 2.0 during different post-training stages: Supervised Fine-Tuning (SFT), Human Feedback Alignment (RLHF), Prompt Engineering (PE), and Refiner. Each row shows the results for a different image prompt, demonstrating how the image quality and adherence to the prompt improves through each training phase. The prompts are written in both English and Chinese. The progression showcases improvements in aesthetics, detail, and overall coherence of the generated images.
read the caption
Figure 11: Visualization during different post-training stages.
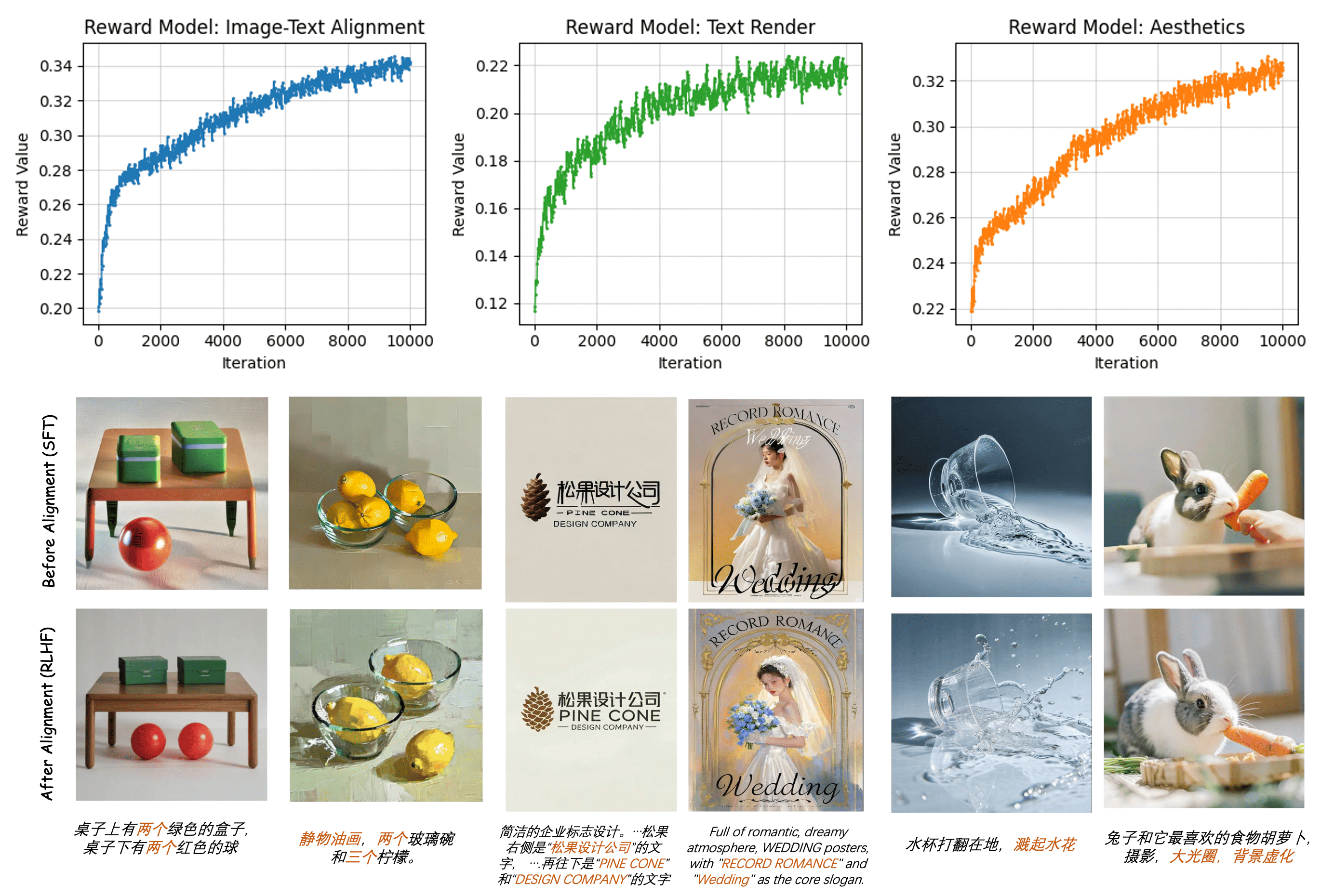
🔼 This figure displays reward curves for three reward models (Image-Text Alignment, Text Render, and Aesthetics) during the RLHF (Reinforcement Learning from Human Feedback) process. Each curve shows a consistent upward trend, indicating that the models continuously improve their performance across multiple iterations of training. The visualization examples below the graphs showcase the impact of the RLHF stage. The images show that the quality of image generation is significantly enhanced through RLHF.
read the caption
Figure 12: The reward curves show that the values across diverse reward models all exhibit a stable and consistent upward trend throughout the alignment process. Some visualization examples reveal that the human feedback alignment stage is crucial.

🔼 This figure visualizes the results of prompt engineering (PE). For each original prompt used to generate an image, four different rephrased prompts (created by the PE model) are shown, along with the images generated from each. This demonstrates how PE refines prompts to improve image generation quality. The variations in the prompts highlight the model’s ability to enhance specificity and detail, leading to better alignment with the desired output.
read the caption
Figure 13: PE Visualization. We provide 4 PE prompts for each original prompt.

🔼 This figure visualizes the Refiner model’s impact on image resolution and quality. The Refiner model takes a 512x512 resolution image as input and upscales it to 1024x1024 resolution. The zoomed-in view showcases improvements in detail, texture, and overall image quality resulting from the Refiner model, particularly with details such as human faces that were previously unclear or blurry. The enhanced clarity and detail demonstrate the Refiner’s ability to produce higher-resolution images without sacrificing visual fidelity.
read the caption
Figure 14: Refiner Visualization. Recommend to zoom in for the best visualization.

🔼 This figure shows the results of an ablation study on the SeedEdit model, which is an instruction-based image editing model. The left panel shows the relationship between the GPT score (a measure of overall image quality) and the CLIP image similarity score (a measure of how similar the edited image is to the original image, according to the CLIP model). The right panel shows the relationship between the GPT score and the AdaFace similarity score (a measure of how well the edited image preserves the identity of the human faces). The study shows that both multi-expert data fusion and face-aware loss are important factors that contribute to improve the ability of the model to preserve human facial identity when making edits.
read the caption
Figure 15: Quantitative ablation of SeedEdit. Left: GPT score v.s. CLIP image similarity. Right: GPT score v.s. AdaFace similarity.

🔼 This figure presents a qualitative comparison of the SeedEdit model revisions. It demonstrates how the improvements (Multi-Expert, FaceLoss/Data Optimization, and Refiner) cumulatively enhance the retention of human facial identity (ID) in edited images. The before-and-after results are displayed for several image editing tasks, illustrating that the updated methods significantly reduce the loss or distortion of facial features during the editing process. The improved ID preservation is a key improvement in the SeedEdit model, critical for numerous applications.
read the caption
Figure 16: Qualitative comparison of SeedEdit revision. We show here that current approach significantly enhances ID retention.

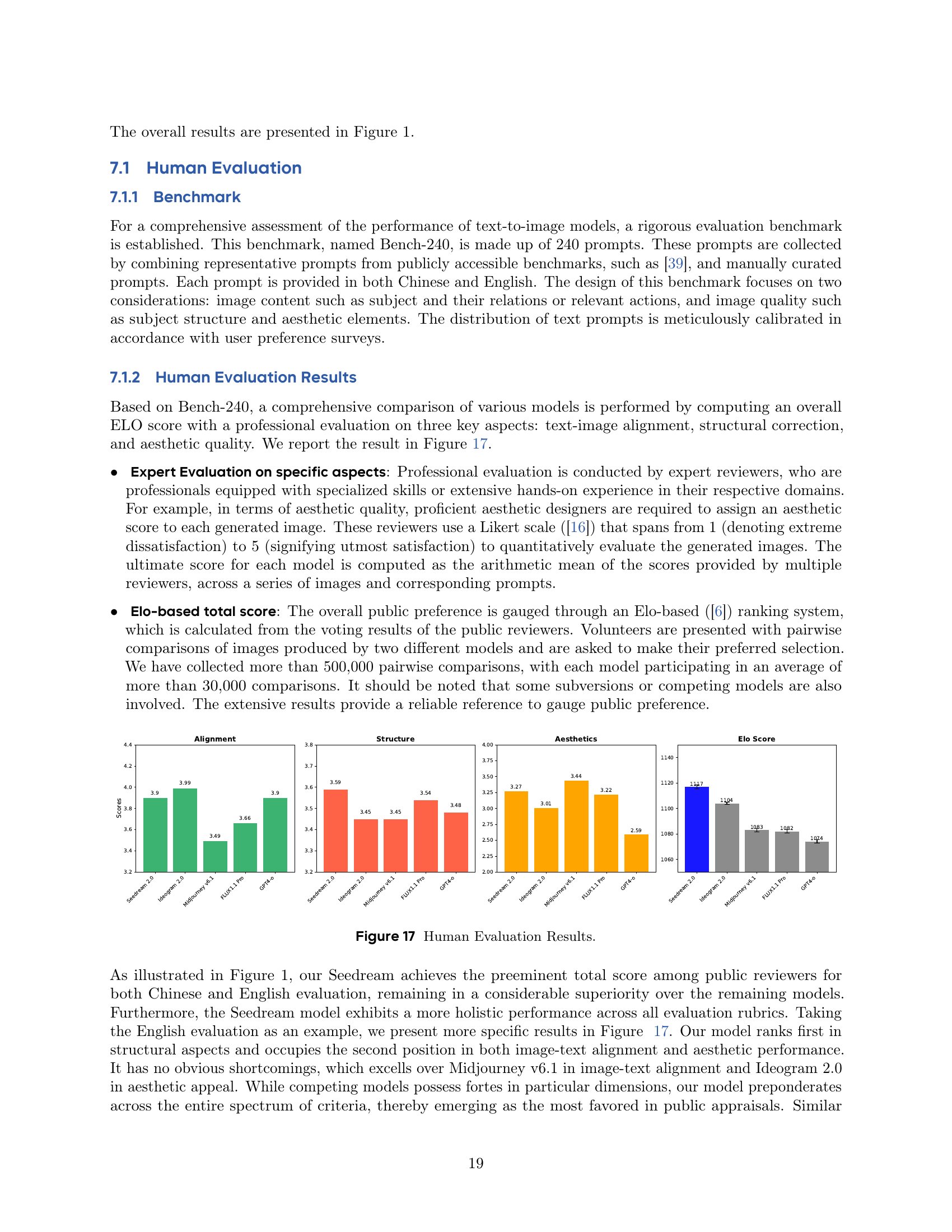
🔼 This figure presents the results of human evaluations comparing Seedream 2.0 to other text-to-image models. Evaluations focus on three key aspects: text-image alignment, structural correctness, and aesthetic quality. A professional evaluation and an ELO-based score (reflecting public preference) are presented for each model. The graph showcases the comparative performance of each model across these dimensions, highlighting Seedream 2.0’s overall superiority.
read the caption
Figure 17: Human Evaluation Results.

🔼 This radar chart visualizes the performance of Seedream 2.0 and other leading text-to-image models across various fine-grained aspects as evaluated by EvalMuse. Each axis represents a specific attribute of image generation quality, such as ‘overall’, ‘object’, ‘activity’, ‘attribute’, ‘spatial’, ’location’, ‘food’, ‘animal/human’, ‘color’, ‘material’, ‘counting’, and ‘other’. The further a model’s point extends outwards on an axis, the better its performance in that specific dimension. This allows for a detailed comparison of the strengths and weaknesses of each model across various aspects of image quality, beyond simpler, overall metrics.
read the caption
Figure 18: EvalMuse Evaluation Results across fine-grained dimensions.
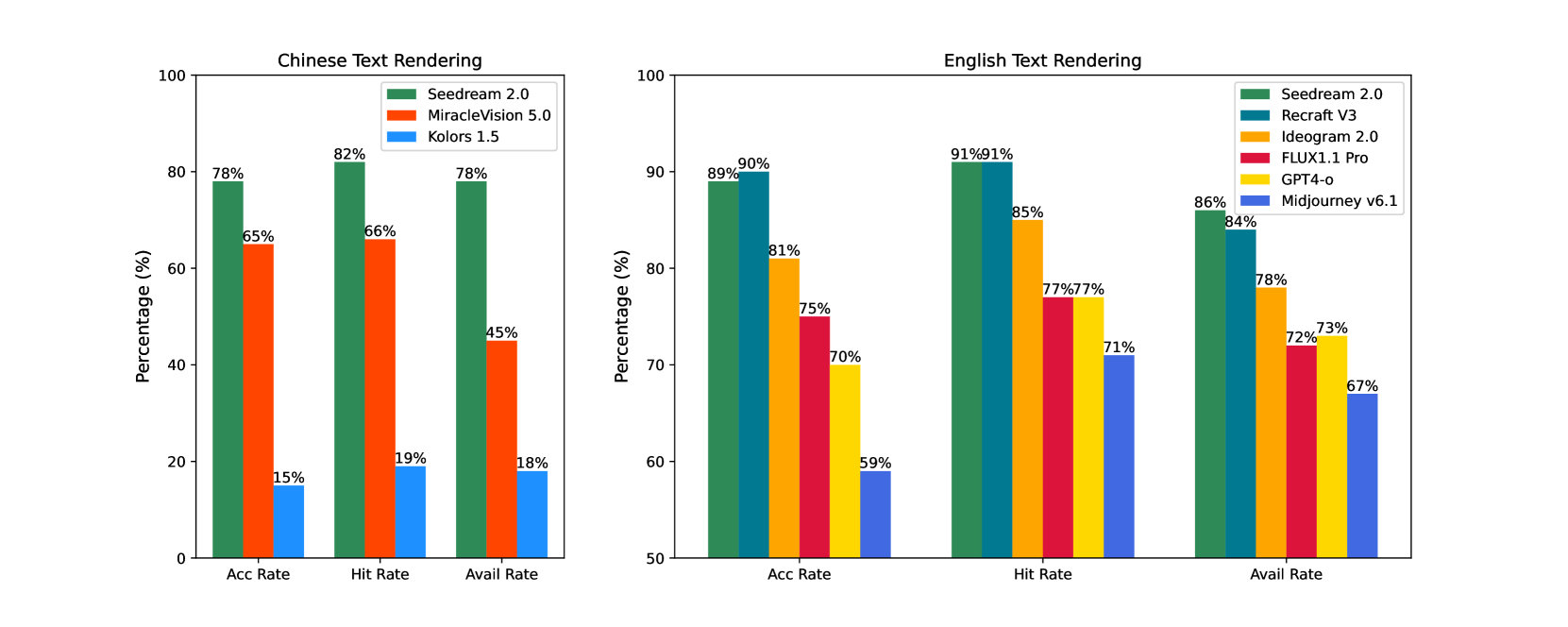
🔼 This figure presents a comparison of text rendering capabilities between Seedream 2.0 and other state-of-the-art text-to-image models in both English and Chinese. It displays the availability rate, text accuracy rate, and text hit rate for each model. The availability rate represents the percentage of successfully rendered images judged as acceptable based on overall text rendering quality and integration with other image content. Text accuracy reflects how accurately the generated text matches the prompt, and the hit rate indicates the proportion of correctly rendered characters. The results demonstrate Seedream 2.0’s superior performance in text rendering, particularly in the more challenging domain of Chinese text.
read the caption
Figure 19: Text Rendering Evaluation.

🔼 This figure presents the results of an evaluation assessing Seedream 2.0’s ability to generate images reflecting Chinese cultural characteristics. Two metrics were used: ‘Response Score’, indicating how accurately the generated images depicted the requested elements from the prompt, and ‘Chinese Aesthetics Score’, measuring how well the image’s aesthetic style aligned with typical Chinese artistic sensibilities. The figure compares Seedream 2.0’s performance to several other models on a set of prompts designed to test the understanding of Chinese cultural nuances.
read the caption
Figure 20: Chinese Characteristics Evaluation.

🔼 This radar chart visualizes the percentage of correctly identified Chinese characteristics across various dimensions in images generated by Seedream 2.0 and other models. Each dimension represents a specific aspect of Chinese culture (e.g., architecture, food, festivals, etc.). The further a point extends from the center, the higher the percentage of correct identification. The chart allows for a comparison of Seedream 2.0’s performance against competing models, highlighting its strengths and weaknesses in representing different cultural elements.
read the caption
Figure 21: Response Rate of Chinese Characteristics across Dimensions.

🔼 This figure presents a comparative analysis of how different text-to-image models render images based on prompts related to Chinese cultural elements. It shows that Seedream 2.0 outperforms other models in accurately capturing and expressing the nuances of these elements, such as clothing, food, and architectural styles. The images visually demonstrate Seedream 2.0’s superior understanding and representation of Chinese cultural details.
read the caption
Figure 22: Chinese Characteristics Comparisons. Our model demonstrates a more accurate understanding and expression of Chinese elements.

🔼 This figure compares the performance of several text-to-image models on two image generation prompts. The first prompt involves generating an image of a teacup-shaped cloud, while the second requires generating an image of two green boxes on a table and two red balls underneath it. The results reveal that Seedream 2.0 and Ideogram 2.0 perform exceptionally well in correctly generating the objects and their spatial relationships as described in both prompts. In contrast, other models such as Midjourney v6.1, FLUX1.1 Pro, and GPT-40 either struggle to generate images matching the creative and imaginative aspects of the first prompt or misinterpret the number and placement of objects in the second prompt.
read the caption
Figure 23: Alignment Comparisons. Seedream and Ideogram 2.0 excel in these two prompts, while other models either struggle with imaginative scenarios or misinterpret quantity and position in the prompts below.

🔼 This figure compares the structural accuracy of different image generation models when depicting complex poses. It highlights how Seedream 2.0 outperforms other models in maintaining realistic proportions and avoiding distortions in limbs and fingers, particularly in dynamic or challenging poses. The other models struggle to accurately represent the structural integrity of the subject, resulting in unnatural or unrealistic imagery. This demonstrates the superior structural correctness of Seedream 2.0.
read the caption
Figure 24: Structure comparisons. External models encounter issues with the distortion of fingers and limbs under complex movements.

🔼 Figure 25 presents a comparison of different text-to-image models’ performance on generating images with cinematic and artistic styles. The prompt used was complex, incorporating multiple stylistic and thematic elements (e.g., specific photography styles, color schemes, and atmospheric elements). Seedream 2.0 is shown to produce images closely matching the prompt’s specifications, with high-quality textures and detailed rendering of visual elements. In contrast, other models such as Ideogram 2.0, Midjourney v6.1, FLUX1.1 Pro, and GPT-4.0, demonstrate varied degrees of failure to capture the nuanced artistic and cinematic aspects specified in the prompt, resulting in lower-quality images and less accurate stylistic representation.
read the caption
Figure 25: Aesthetics comparisons. Seedream demonstrates outstanding performance in cinematic scenes and artistic design, while other models show weaker performance in artistic style and texture details.

🔼 Figure 26 showcases a comparison of text rendering capabilities across different models. Seedream excels by seamlessly integrating text within the image content, showcasing sophisticated typesetting skills. This is particularly evident in its handling of scenarios involving Chinese characters and cultural elements, where it displays a superior comprehension and nuanced representation compared to other models.
read the caption
Figure 26: Text-Rendering Comparisons. Seedream performs exceptionally well in harmonizing text with content and demonstrates strong typesetting capabilities. Notably, it offers a distinct understanding of scenarios with Chinese characteristics.

🔼 Figure 27 showcases Seedream’s text rendering capabilities in various artistic and design contexts. It demonstrates the model’s ability to seamlessly integrate text into diverse creative scenarios, ranging from simple illustrations and posters to more complex compositions. The collage presents several examples highlighting the model’s flexibility in handling different text styles, fonts, and arrangements while maintaining visual coherence. This illustrates Seedream’s potential for applications beyond text-to-image generation, extending its utility to fields like graphic design, advertising, and artistic expression.
read the caption
Figure 27: Text Rendering by Seedream. Our model presents infinite potential in poster design and artistic creation.

🔼 Figure 28 is a collage showcasing the model’s ability to generate images reflecting various aspects of Chinese aesthetics. It includes a diverse range of subjects, from traditional architecture (such as pagodas) and cultural symbols (like pandas) to depictions of mythical creatures (dragons) and figures from Chinese opera. The image demonstrates the model’s capacity for detailed rendering, stylistic variation, and culturally sensitive representation.
read the caption
Figure 28: Chinese Characteristics by Seedream. Our model presents impressive representation of Chinese aesthetics.
Full paper#