TL;DR#
The paper introduces Video Action Differencing (VidDiff), a new task focused on identifying subtle differences between videos of the same action. This is motivated by applications like coaching and skill learning, where understanding these nuances is crucial. However, there is a lack of suitable datasets for developing and evaluating models for this task. Current video understanding research emphasizes coarse-grained action comparisons, missing the fine-grained details needed in many real-world scenarios. To tackle this the authors introduce a ‘closed’ setting for video analysis to focus on video analysis.
To facilitate research in this area, the authors create VidDiffBench, a benchmark dataset containing 549 video pairs with annotations of action differences. The benchmark uses the VidDiff Method: action difference proposal, keyframe localization, and frame differencing. Experiments demonstrate that VidDiffBench poses a significant challenge for state-of-the-art large multimodal models (LMMs). The paper also analyzes the failure cases of LMMs, highlighting challenges in localizing relevant sub-actions and achieving fine-grained frame comparison.
Key Takeaways#
Why does it matter?#
This paper introduces a novel task, dataset, and method for video action differencing, which could significantly impact coaching, skill learning, and automated performance feedback. It encourages further exploration into broader video comparison methods.
Visual Insights#

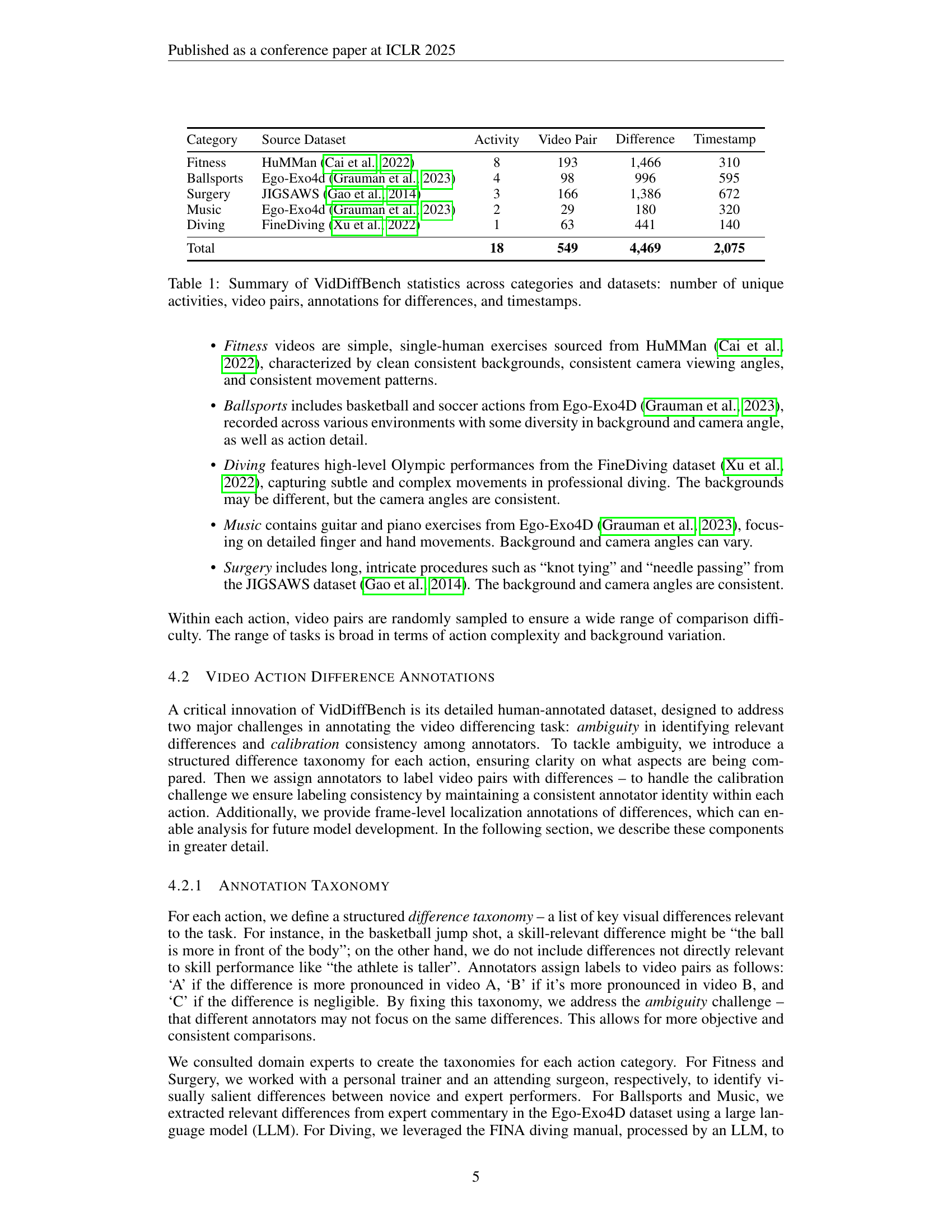
🔼 Figure 1 illustrates the Video Action Differencing (VidDiff) task and its accompanying benchmark dataset, VidDiffBench. The task involves identifying subtle differences between two videos depicting the same action. VidDiffBench contains video pairs from diverse domains (fitness, sports, music, surgery, diving) with human-annotated differences, relevant to skill learning. The top row of the figure exemplifies the challenge of localizing specific sub-actions within the videos for accurate comparison. The bottom row highlights the challenge of fine-grained visual understanding required to discern subtle differences in the execution of actions.
read the caption
Figure 1: The Video Action Differencing task and benchmark (VidDiffBench). Given a pair of videos and an action, the task is to generate a list of differences as natural language descriptions. Our VidDiffBench consists of annotated differences across diverse domains, where the differences are relevant to human skill learning. The first row emphasizes the first key challenge: localization of sub-actions between segments of the video for comparison. The second row highlights the second key challenge: fine-grained image understanding of actions in order to perform comparison.
| Category | Source Dataset | Activity | Video Pair |
|
| ||
|---|---|---|---|---|---|---|---|
| Fitness | HuMMan (Cai et al., 2022) | 8 | 193 | 1,466 | 310 | ||
| Ballsports | Ego-Exo4d (Grauman et al., 2023) | 4 | 98 | 996 | 595 | ||
| Surgery | JIGSAWS (Gao et al., 2014) | 3 | 166 | 1,386 | 672 | ||
| Music | Ego-Exo4d (Grauman et al., 2023) | 2 | 29 | 180 | 320 | ||
| Diving | FineDiving (Xu et al., 2022) | 1 | 63 | 441 | 140 | ||
| Total | 18 | 549 | 4,469 | 2,075 |
🔼 This table presents a summary of the VidDiffBench dataset, which is a benchmark dataset for Video Action Differencing. It shows the number of unique activities, video pairs, difference annotations, and timestamp annotations included in the dataset, broken down by category (Fitness, Ballsports, Surgery, Music, and Diving). This information helps to understand the scale and diversity of the VidDiffBench dataset.
read the caption
Table 1: Summary of VidDiffBench statistics across categories and datasets: number of unique activities, video pairs, annotations for differences, and timestamps.
In-depth insights#
Action Differencing#
Action Differencing, as presented in the paper, introduces a novel task focusing on identifying subtle differences between videos of the same action. This is significant, as current research largely overlooks fine-grained comparisons. The task has key challenges: localizing sub-actions and frame comparison. Addressing these hurdles could unlock applications like skill learning and coaching. This focus on nuanced distinctions sets it apart from broader action recognition or feature visualization techniques, potentially driving advancements in video understanding by requiring models to analyze subtle movements and their impact on overall performance. The task formulation using natural language also allows for the potential of interpretability that might bring forth more sophisticated models.
VidDiffBench#
VidDiffBench is presented as a novel benchmark for video action differencing, a task involving identifying subtle differences between videos of the same action. It contains 549 video pairs with detailed human annotations, including 4,469 fine-grained action differences and 2,075 localization timestamps. The dataset spans diverse domains like fitness, sports, music, and surgery, ensuring broad applicability and challenging models with varying levels of action complexity and background variation. A structured difference taxonomy was developed to address ambiguity, and labeling consistency was maintained by assigning single annotators per action. VidDiffBench aims to advance video understanding by enabling precise comparison of subtle action differences, a capability essential for applications in coaching, skill acquisition, and automated performance feedback. By releasing this benchmark, the authors facilitate further research and development in this relatively unexplored area.
Agentic Workflow#
The paper introduces an “agentic workflow” named VidDiff Method, breaking down the task of video action differencing into stages, an approach that mirrors cognitive processes of humans. Difference Proposer (LLM) generates potential differences, Frame Localizer (CLIP) identifies relevant frames. Action Differencer (VQA) assesses differences, streamlining analysis. This leverages specialized foundation models for each stage, showing a structured approach to enhance video comparison which will make visual comparison easier.
LMM limitations#
While this paper showcases potential, LMMs have limitations. Reliance on pre-trained models restricts application in specialized domains. The open setting evaluation uses LLMs, raising subjectivity in annotations: relevance and significance of differences. Reducing LLM response verbosity caused degraded performance, balancing cost and quality is important.
Future Research#
The paper identifies several avenues for future research, including enhancing frame retrieval techniques, explicitly training Vision-Language Models (VLMs) for fine-grained feature comparison, and developing methods tailored to specialized domains. Overcoming limitations in relying on general foundation models that may struggle with domain-specific tasks. These areas aim to improve video understanding and enable broader applications in skill acquisition and more.
More visual insights#
More on figures

🔼 The VidDiff method is a three-stage process for identifying subtle differences between two videos showing the same action. First, a large language model (LLM) proposes potential differences between the videos (e.g., ‘faster ascent’, ‘wider stance’). Next, a frame localization module identifies the specific frames in each video where these differences are visible. Finally, a vision-language model compares the identified frames to determine whether each proposed difference applies more strongly to video A, video B, or neither.
read the caption
Figure 2: VidDiff Method. One input is an action description (e.g. “weighted squat”). The Difference Proposer generates potential differences using a large language model (LLM). The Frame Localizer assigns frames where these differences are observable. Finally, the Action Differencer checks each difference using a vision-language model, determining whether it applies more to video A or video B, or neither.

🔼 This figure showcases examples of successful and unsuccessful video action difference predictions made by the GPT-40 model. The ‘success cases’ (left) illustrate situations where GPT-40 achieves high accuracy. These cases generally involve readily apparent differences between the videos, easy identification of the specific frames where the differences occur, and actions that are relatively straightforward or simple in nature. In contrast, the ‘failure cases’ (right) represent instances where GPT-40’s performance is poor. These typically involve subtle differences requiring keen visual discernment, precise temporal localization to pinpoint the exact frames containing the difference, or actions that are complex and nuanced. The differences between success and failure highlight the challenges of identifying and localizing nuanced action differences.
read the caption
Figure 3: Examples of ‘success cases’ (left) – differences where GPT-4o has high accuracy – and failure cases (right). Success cases typically involve coarse differences, easy localization, or simple actions, while failure cases often involve fine differences, precise localization or complex actions.

🔼 This figure showcases examples of frame localization within the VidDiff method. It visually compares the ground truth frame selections with the model’s predictions for various action differences. Each row represents a different difference, highlighting the model’s ability to pinpoint the relevant frames where visual differences are observable. The differences shown range in complexity and granularity, demonstrating the challenges in precise temporal localization within video action differencing.
read the caption
Figure 4: Sample frame localizations: prediction vs ground truth.
More on tables
| Difference |
🔼 This table presents the performance of various large multimodal models (LMMs) on a closed-set video action differencing task. The task involves predicting whether a given difference description applies more to one of two videos of the same action. The table shows the accuracy of each model across three difficulty levels (Easy, Medium, Hard). Scores significantly better than random chance (50%) are highlighted in gray, indicating statistical significance at a p-value below 0.05 using a binomial test. The best performance for each difficulty level is shown in bold, and the second-best is underlined.
read the caption
Table 2: Results for closed setting (accuracy). Best scores in bold, second best underlined. Scores are better than random, with statistical significance highlighted in gray. Significance is p-value<0.05absent0.05<0.05< 0.05 on a binomial test.
| Timestamp |
🔼 Table 3 presents the results of the open-set evaluation for the Video Action Differencing (VidDiff) task. Recall@Ndiff is used as the evaluation metric, measuring the proportion of correctly identified and generated differences out of the total number of ground truth differences. The table shows the performance of different large multimodal models (LMMs) and the VidDiff method across three difficulty levels: easy, medium, and hard. The best scores for each difficulty level are highlighted in bold, and the second-best scores are underlined.
read the caption
Table 3: Results for open setting (recall@Ndiffsubscript𝑁diffN_{\text{diff}}italic_N start_POSTSUBSCRIPT diff end_POSTSUBSCRIPT). Best scores in bold, second best underlined.
| Easy | Med | Hard | Avg | |
|---|---|---|---|---|
| GPT-4o | 58.3 | 53.2 | 48.9 | 53.5 |
| Gemini-1.5-Pro | 67.8 | \ul53.6 | \ul51.7 | 57.7 |
| Claude-3.5-Sonnet | 57.1 | 50.5 | 52.5 | 53.4 |
| LLaVA-Video | 56.6 | 52.0 | 48.3 | 52.3 |
| Qwen2-VL-7B | 49.0 | 52.6 | 49.6 | 50.4 |
| VidDiff (ours) | \ul62.7 | 56.2 | 50.0 | \ul56.3 |
🔼 This ablation study analyzes the performance of the visual question answering (VQA) component of the VidDiff method when provided with perfectly aligned ground truth frames. The experiment tests the ability of zero-shot vision-language models to identify subtle differences between the images. The evaluation is a 3-way multiple-choice question for each comparison.
read the caption
Table 4: Ablation study results for frame differencing VQA with ground truth frames. Questions are 3-way multiple-choice.
| Easy | Med | Hard | Average | |
|---|---|---|---|---|
| GPT-4o | \ul45.7 | 41.5 | \ul38.0 | \ul41.7 |
| Gemini-1.5-Pro | 30.3 | 30.5 | 24.1 | 28.3 |
| Claude-3.5-Sonnet | 37.8 | 34.6 | 34.3 | 35.6 |
| LLaVA-Video | 7.8 | 9.0 | 8.5 | 8.4 |
| Qwen2-VL-7B | 11.2 | 8.8 | 1.6 | 7.2 |
| VidDiff (ours) | 49.9 | \ul37.9 | 38.5 | 42.1 |
🔼 This table presents the ablation study results on the impact of different frame localization techniques on the accuracy of video action differencing. Specifically, it compares the performance of the proposed VidDiff method’s frame localization component against a baseline of random frame retrieval and a method without the Viterbi decoding step. The results are presented for the ’easy’ difficulty split of the VidDiffBench dataset. The table helps illustrate the importance of precise frame localization for accurate video action differencing, showcasing the contribution of the specific techniques employed in VidDiff.
read the caption
Table 5: Ablation on frame localization using different retrieval techniques on easy.
| Split | Easy | Medium | Hard |
|---|---|---|---|
| Acc | 78.6 | 61.2 | 51.0 |
🔼 This table details the difficulty level assigned to each action in the VidDiffBench benchmark dataset. For each action, it provides the action’s short name (code), its full name, and a description of the action itself. The difficulty level is categorized into ’easy’, ‘medium’, or ‘hard’, reflecting the complexity of identifying and annotating subtle differences within the action’s video pairs. This categorization is crucial for evaluating model performance and ensuring the benchmark’s comprehensiveness.
read the caption
Table 6: The difficulty splits with action code and names
| Method | Accuracy |
|---|---|
| Oracle (GT timestamps) | 78.6 |
| Random | 50.1 |
| Ours w/o Viterbi Decoding | 57.4 |
| Ours | 62.7 |
🔼 This table presents the results of a human evaluation study conducted to validate the LLM’s approach to assigning difficulty levels (easy, medium, hard) to the video action differencing tasks. Three human evaluators independently ranked the difficulty of the actions, and these rankings were compared against the rankings generated by the LLM using Spearman’s rank correlation. The table shows the correlation coefficients between each human evaluator’s ranking and the LLM’s ranking, offering a quantitative assessment of the agreement between human judgment and the LLM’s automated approach.
read the caption
Table 7: Results on human evaluation study on choosing the splits. This is the Spearman’s rank corrlation between the ranks of action dificulty, comparing our LLM approach and 3 humans.
| Split | Action | Action Name | Action description |
|---|---|---|---|
| easy | fitness_0 | Hip circle anticlockwise | fitness exercise called standing hip circle with hands on hips, one rotation anticlockwise |
| easy | fitness_3 | lucky cat | fitness exercise called two arm standing lucky cat starting with arms up, one repetition |
| easy | fitness_4 | Squat Knee Raise side view | squat without weights, then knee raise on left side |
| easy | fitness_6 | Hip circle clockwise | fitness exercise called standing hip circle with hands on hips, one rotation clockwise |
| medium | ballsports_0 | basketball jump shot | a person is doing a basketball mid-range jump shot, starting with the ball in their hand, no defense, practice only |
| medium | ballsports_1 | basketball mikan layup | a person does the Basketball drill called the Mikan layup where they start under the basket, do a layup with the right hand and catch it, do a left hand layup and catch it, no defense, practice only |
| medium | ballsports_2 | basketball reverse layup | a person playing basketball does a reverse layup starting from the left side of the basket and lays it up with their right hand on the right hand side, no defense, practice only |
| medium | ballsports_3 | soccer penalty kick | a person does a soccer drill where they do a single penalty kick, practice only, no defense, no goalie |
| medium | diving_0 | diving | competitive diving from 10m |
| medium | fitness_1 | Opening and closing step left side first | fitness exercise called opening and closing step on left side and then opening and closing step on right side |
| medium | fitness_2 | car deadlift | a single free weight deadlift without any weight |
| medium | fitness_5 | Squat Knee Raise diagonal view | a squat then a knee raise on left side |
| medium | fitness_7 | Opening and closing step right side first | fitness exercise called opening and closing step on right side and then opening and closing step on left side |
| hard | music_0 | piano | a person is playing scales on the piano |
| hard | music_1 | guitar | a person is playing scales on the guitar |
| hard | surgery_0 | Knot Tying | The subject picks up one end of a suture tied to a flexible tube attached at its ends to the surface of the bench-top model, and ties a single loop knot. |
| hard | surgery_1 | Suturing | The subject picks up needle, proceeds to the incision (designated as a vertical line on the bench-top model), and passes the needle through the fake tissue, entering at the dot marked on one side of the incision and exiting at the corresponding dot marked on the other side of the incision. After the first needle pass, the subject extracts the needle out of the tissue, passes it to the right hand and repeats the needle pass three more times. |
| hard | surgery_2 | Needle Passing | The subject picks up the needle (in some cases not captured in the video) and passes it through four small metal hoops from right to left. The hoops are attached at a small height above the surface of the bench-top model. |
🔼 This table presents a detailed breakdown of the VidDiffBench dataset statistics, categorized by difficulty level (easy, medium, hard). It includes the number of video pairs, average and total video lengths, the count of difference annotations, and the standard deviation of those annotations within and across retrieval types (indicating the consistency of annotation within a video and across different videos). Finally, it shows the distribution of the A/B/C annotation labels in the dataset, illustrating the relative frequency of different levels of perceived action differences. This granular level of detail helps researchers understand the characteristics of the benchmark and better design and evaluate their models.
read the caption
Table 8: Detailed data statistics by split
| LLM | Human 1 | Human 2 | Human 3 | |
|---|---|---|---|---|
| LLM | 53.1 | 68.0 | 80.6 | |
| Human 1 | 53.1 | 45.9 | 64.5 | |
| Human 2 | 68.0 | 45.9 | 70.3 | |
| Human 3 | 80.6 | 64.5 | 70.3 | |
| Average | 67.3 | 54.5 | 61.4 | 71.8 |
🔼 This table presents the agreement rates between the predictions made by a Large Language Model (LLM) and three human annotators on a video action difference matching task. It shows how well the LLM’s automated matching of video action differences aligns with human judgment. The data is presented as a matrix, showing the agreement rates between each pair of the LLM and the three human annotators.
read the caption
Table 9: Agreement rate of LLM and human predictions for the evaluation matching.
| Split | easy | medium | hard | Overall |
| # video pairs | 95 | 265 | 197 | 557 |
| Avg video length (secs) | 2.1 | 3.9 | 18.7 | 8.8 |
| Total video length (mins) | 6.5 | 34.7 | 122.5 | 163.7 |
| # differences tagged | 1224 | 4788 | 3542 | 9554 |
| StdDev within retrieval type | 8.4% | 5.2% | 4.1% | 5.9% |
| StdDev across retrieval types | 17.3% | 25.7% | 20.2% | 21.0% |
| Difference annotations count | 578 | 1771 | 2370 | 4719 |
| Difference annotations A/B/C distribution | 167/190/221 | 622/605/1143 | 435/452/884 | 1224/1247/2248 |
🔼 This table shows the pairwise correlation coefficients between the action-level accuracy scores achieved by different large multimodal models (LMMs) on the VidDiffBench benchmark. Higher correlation indicates that the models perform similarly across the different actions in the benchmark. This helps to understand the relationship between the models’ performance and whether they exhibit similar strengths and weaknesses.
read the caption
Table 10: Correlations between models where the data is the action-level accuracy.
| LLM | Human 1 | Human 2 | Human 3 | |
|---|---|---|---|---|
| LLM | 72.4 | 74.0 | 70.1 | |
| Human 1 | 72.4 | 75.0 | 78.2 | |
| Human 2 | 74.0 | 75.0 | 73.9 | |
| Human 3 | 70.1 | 78.2 | 73.9 | |
| Average | 72.2 | 75.2 | 74.3 | 74.0 |
🔼 This table presents the performance of five large multimodal models (GPT-40, Gemini-1.5-Pro, Claude-3.5-Sonnet, LLaVA-Video-7B, and Qwen2-VL-7B) on a video action differencing task. It shows the accuracy scores achieved by each model on each individual action within the dataset. The scores are presented for different difficulty levels, and differences between the model’s performance and the average performance across all models for each action are also provided. This allows for a granular analysis of model strengths and weaknesses in this new video understanding task.
read the caption
Table 11: Action-level scores for each model, and their differences compared to the average model score for that action. The model names are abbreviated and the full model names are GPT-4o, Gemini-1.5-Pro, Claude-3.5-Sonnet, LLaVA-Video-7B, Qwen2-VL-7B
| GPT | Gemini | Claude | LLava-Video | Qwen2-VL | |
|---|---|---|---|---|---|
| GPT-4o | 0.152 | 0.375 | 0.243 | 0.273 | |
| Gemini-1.5-Pro | 0.152 | 0.215 | 0.111 | 0.223 | |
| Claude-3.5-Sonnet | 0.375 | 0.215 | 0.261 | 0.220 | |
| LLaVA-Video | 0.243 | 0.111 | 0.261 | 0.376 | |
| Qwen2-VL-7b | 0.273 | 0.223 | 0.220 | 0.376 |
🔼 This table presents the performance of different large multimodal models (LLMs) on a video action differencing task, broken down by individual actions. Instead of showing absolute scores, it shows the difference between each model’s performance on a specific action and the average performance of all models on that same action. This allows for a more nuanced comparison, highlighting which models excel or struggle on particular actions, rather than just giving overall accuracy metrics. Model names are abbreviated for brevity; the full names are provided in the caption.
read the caption
Table 12: Action-level difference scores for each model relative to the mean model score on that action. This is the difference with respect to the table 11. The model names are abbreviated and the full model names are GPT-4o, Gemini-1.5-Pro, Claude-3.5-Sonnet, LLaVA-Video-7B, Qwen2-VL-7B
| Split | Action | Action Name | Count | Scores | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT | Gemini | Claude | LLaVA-Vid | Qwen2 | Avg | ||||||
| easy | fitness_0 |
| 129 | 56.6 | 58.1 | 56.6 | 51.9 | 45.0 | 53.6 | ||
| easy | fitness_3 | lucky cat | 62 | 53.2 | 58.1 | 43.5 | 58.1 | 45.2 | 51.6 | ||
| easy | fitness_4 |
| 43 | 65.1 | 69.8 | 37.2 | 69.8 | 55.8 | 59.5 | ||
| easy | fitness_6 | Hip circle clockwise | 123 | 58.5 | 76.4 | 69.9 | 56.1 | 52.8 | 62.8 | ||
| medium | ballsports_0 |
| 96 | 55.2 | 57.3 | 52.1 | 57.3 | 61.5 | 56.7 | ||
| medium | ballsports_1 |
| 148 | 56.8 | 49.3 | 46.6 | 51.4 | 56.1 | 52.0 | ||
| medium | ballsports_2 |
| 125 | 46.4 | 55.2 | 49.6 | 44.0 | 50.4 | 49.1 | ||
| medium | ballsports_3 |
| 70 | 51.4 | 60.0 | 57.1 | 70.0 | 54.3 | 58.6 | ||
| medium | diving_0 | diving | 240 | 53.8 | 52.1 | 53.3 | 50.8 | 54.2 | 52.8 | ||
| medium | fitness_1 |
| 186 | 57.5 | 54.8 | 52.7 | 51.1 | 51.6 | 53.5 | ||
| medium | fitness_2 | car deadlift | 137 | 55.5 | 62.8 | 62.0 | 47.4 | 54.0 | 56.4 | ||
| medium | fitness_5 |
| 70 | 35.7 | 32.9 | 38.6 | 62.9 | 44.3 | 42.9 | ||
| medium | fitness_7 |
| 155 | 52.9 | 52.9 | 63.2 | 49.7 | 52.9 | 54.3 | ||
| hard | music_0 | piano | 94 | 51.1 | 51.1 | 58.5 | 51.1 | 52.1 | 52.8 | ||
| hard | music_1 | guitar | 20 | 55.0 | 40.0 | 45.0 | 50.0 | 65.0 | 51.0 | ||
| hard | surgery_0 | Knot Tying | 237 | 47.7 | 43.5 | 43.5 | 46.4 | 44.3 | 45.1 | ||
| hard | surgery_1 | Suturing | 309 | 48.9 | 51.5 | 48.2 | 47.6 | 50.2 | 49.3 | ||
| hard | surgery_2 | Needle Passing | 211 | 51.7 | 46.9 | 49.8 | 48.8 | 50.2 | 49.5 |
🔼 This table lists all actions included in the VidDiffBench benchmark dataset, providing a key (identifier) for each action and a detailed description of the action. The descriptions offer sufficient detail to understand the action’s nature and the type of movement involved. This is crucial for researchers working with the dataset, providing them with the necessary context to understand the nuances of the actions being compared.
read the caption
Table 13: Actions keys and their descriptions
| Hip circle |
| anticlockwise |
🔼 This table presents a detailed breakdown of the accuracy scores achieved for each specific difference identified within the VidDiff benchmark. It shows the accuracy for each difference, the number of samples used in the evaluation for that difference, and whether the accuracy was statistically significant (p-value < 0.05 using a two-tailed binomial test). The differences are linked to their corresponding actions via a key, allowing for cross-referencing with Table 13 which defines the actions. Gray shading highlights statistically significant results.
read the caption
Table 14: Difference-level accuracy scores for VidDiff. The ‘action’ values can be looked up at table 13. The grayed columns indicate a p-value <<< 0.05 for the two-tailed binomial significance test
| Squat Knee Raise |
| side view |
🔼 This table presents the results of an experiment evaluating the performance of three different large multimodal models (GPT-40, Gemini-1.5-Pro, and Claude-3.5-Sonnet) on the ’easy’ split of the VidDiffBench dataset. The experiment varied the frames per second (fps) of the video input to the models, testing 1 fps, 2 fps, 4 fps, and 8 fps. The evaluation protocol used in the paper establishes 4 fps as the standard. The table shows the accuracy of each model at each fps rate, allowing for comparison of model performance under different input conditions and highlighting the impact of fps on model accuracy.
read the caption
Table 15: Evaluating ‘easy’ split with variable video fps for three models. Our evaluation protocol chooses 4fps.
Full paper#