TL;DR#
Human interaction with the external world often requires redundant information sharing. Solutions like autofill are limited. Large language models can redefine memory management. Thus, there is a need for a dynamic system that enhances structured knowledge, contextual reasoning, and adaptive retrieval. It is necessary to reduce redundancy and cognitive load.
This paper introduces Second Me, an AI-native memory system. This system acts as an intelligent memory offload. Second Me retains, organizes, and dynamically utilizes user-specific knowledge. It autonomously generates responses. It can prefill information. This approach facilitates communication and reduces cognitive load. The paper demonstrates its efficiency and adaptability in addressing complex user demands.
Key Takeaways#
Why does it matter?#
This research introduces a novel AI memory system. It highlights how LLMs can enhance memory management for AI agents. This system offers a path toward personalized AI, which is a current research trend. It also helps researchers explore the impact of AI on human-computer interactions.
Visual Insights#

🔼 This figure illustrates the hybrid architecture of Second Me, a system designed to function as an AI-native persistent memory offload. It shows how Second Me acts as an intermediary between the user and external systems (such as devices, applications, and the internet). The user interacts with Second Me through a personalized interface, posing queries or requests. Second Me then processes these requests using a combination of internal memory layers (L0, L1, and L2), an agent model for reasoning, and various knowledge bases and tools. This architecture enables Second Me to autonomously retrieve, organize, and apply user-specific knowledge to generate context-aware responses and facilitate seamless interactions.
read the caption
Figure 1: Hybrid Architecture of Second Me
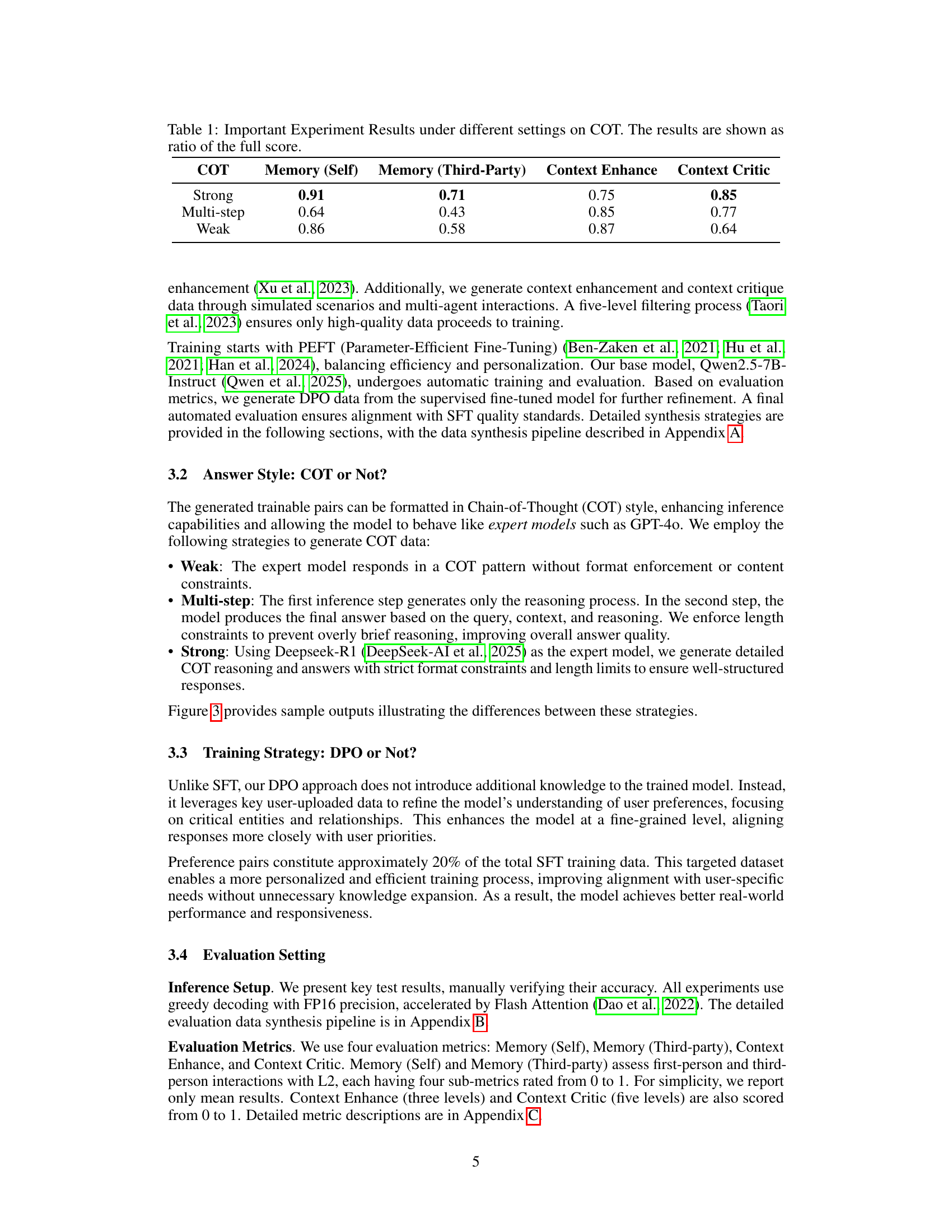
| COT | Memory (Self) | Memory (Third-Party) | Context Enhance | Context Critic |
|---|---|---|---|---|
| Strong | 0.91 | 0.71 | 0.75 | 0.85 |
| Multi-step | 0.64 | 0.43 | 0.85 | 0.77 |
| Weak | 0.86 | 0.58 | 0.87 | 0.64 |
🔼 This table presents the results of experiments conducted under various settings of Chain-of-Thought (COT) reasoning. The experiments evaluated the performance of a model on several tasks related to memory retrieval and contextual understanding. Different COT strategies (Weak, Multi-step, Strong) were used, and results are shown as a ratio of the total possible score, allowing for a direct comparison of effectiveness across conditions. This provides insights into how different levels of COT influence the model’s ability to handle various aspects of memory-based tasks, including answering questions, completing contexts, and providing critiques.
read the caption
Table 1: Important Experiment Results under different settings on COT. The results are shown as ratio of the full score.
In-depth insights#
AI-Native Memory#
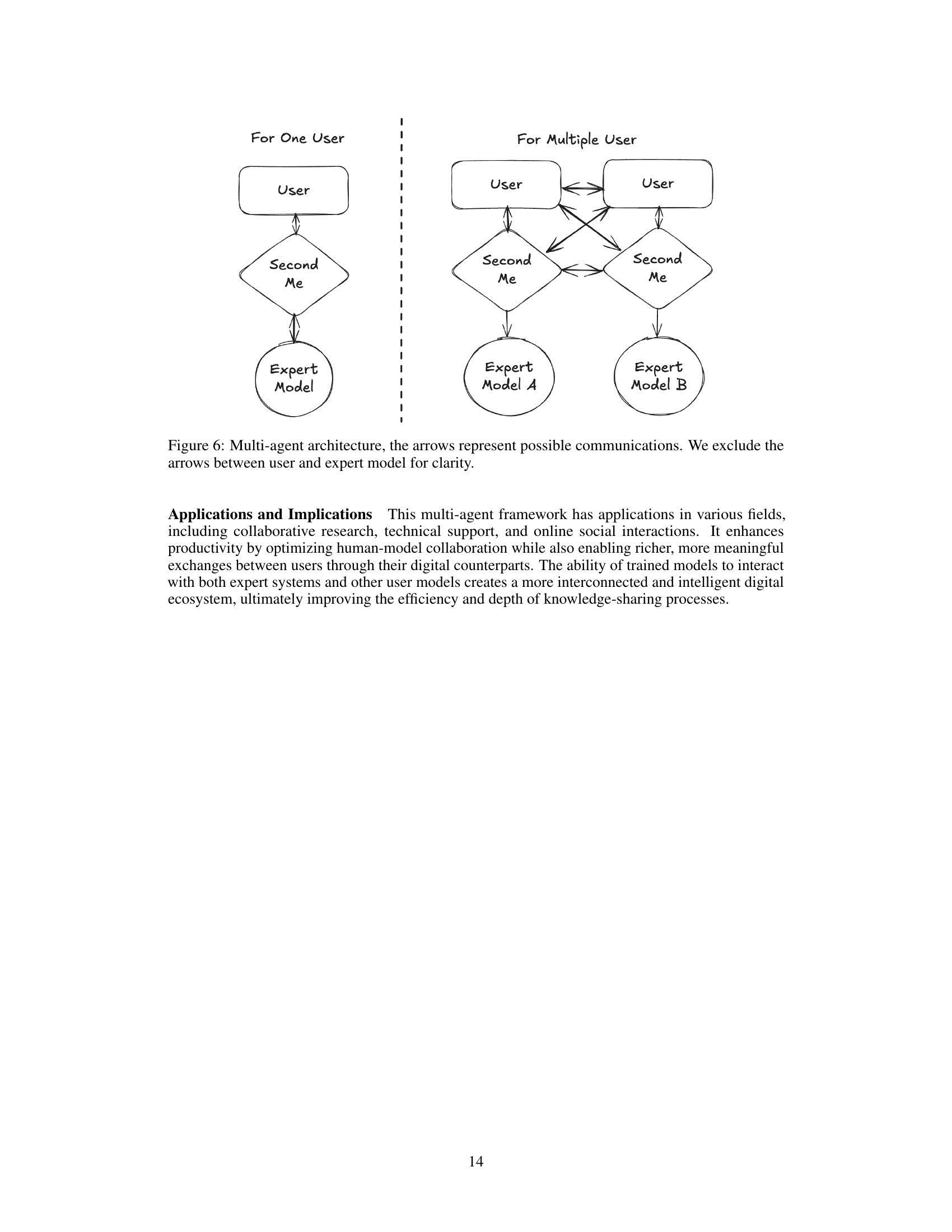
AI-Native Memory represents a paradigm shift in how AI systems manage and utilize information, moving beyond traditional data storage to systems that dynamically learn, adapt, and reason. It focuses on the convergence of advanced memory architectures and intelligent algorithms, enabling more efficient and context-aware data handling. This approach facilitates real-time processing, personalized experiences, and optimized decision-making, addressing challenges in data-intensive applications. Key aspects include memory parameterization, which can enhance structured knowledge organization and adaptive retrieval for seamless digital interactions. Integration of multi-agent frameworks enables better management and collaboration. Ultimately, AI-native memory aims to create systems that think alongside users, understand their cognitive state, and evolve with them.
LLM Parameterize#
LLM parameterization offers a compelling paradigm shift in memory management, moving beyond static data storage to dynamically encoded knowledge within model weights. This approach, exemplified by SECOND ME, allows for structured organization, contextual reasoning, and adaptive knowledge retrieval. Unlike traditional methods like RAG, which rely on explicit retrieval from external knowledge bases, LLM parameterization embeds information directly into the model’s parameters. This allows the system to autonomously generate context-aware responses and prefill required information by using user-specific knowledge. It also greatly reduces cognitive load and interaction friction. By leveraging the capabilities of large language models, parameterization enables a more intelligent and systematic approach to memory management and digital interactions. This represents a significant step towards augmenting human-world interaction with persistent, contextually aware, and self-optimizing memory systems.
Hybrid Memory#
While the paper doesn’t explicitly use the term “Hybrid Memory,” it presents a compelling architecture for managing and utilizing personal memory in an AI-native way. The SECOND ME system implicitly creates a hybrid memory structure by combining different layers of data representation (L0, L1, and L2). L0 is the raw, unstructured data, L1 is a natural language summary, and L2 is the AI-native memory layer that learns and organizes information through model parameters. The system intelligently utilizes the different layers based on task complexity, essentially forming a hybrid memory approach where different data representations are accessed and processed as needed. This hybrid approach allows the system to leverage the strengths of each layer, creating a more efficient and adaptable memory system than a purely unstructured or purely AI-driven approach. This is vital for practical personal AI.
Automated Train#
Automated training pipelines are crucial for efficiently developing and personalizing AI models, as highlighted in the paper. They streamline the process of data preparation, model training, and evaluation, reducing manual effort and enabling faster iteration cycles. The paper’s emphasis on automation suggests a move towards democratizing AI development, allowing users with varying levels of expertise to create customized models. Automated data synthesis, filtering, and model evaluation are vital components, ensuring data quality and model alignment with user preferences. The use of SFT and DPO further optimizes model performance. Automating training ensures greater agility and scalability in deploying AI solutions that align with specific needs.
Future Network AI#
Considering the trajectory of AI and its potential impact on network technologies, Future Network AI envisions a paradigm shift in how networks are designed, managed, and optimized. It suggests an intelligent, self-adaptive network infrastructure that utilizes AI at every layer. Networks will predict traffic patterns, proactively allocate resources, and autonomously detect and mitigate security threats without human intervention, shifting from reactive to preemptive network management. This requires developing sophisticated AI algorithms capable of handling the complexity and dynamicity of modern networks, coupled with robust, explainable AI frameworks to ensure transparency, fairness, and trustworthiness. We anticipate challenges in developing and deploying such AI, including the need for large, high-quality datasets, concerns about algorithmic bias, and the importance of human oversight to prevent unintended consequences. Future AI may require networks that learn and adapt. AI-driven resource optimization, intelligent traffic routing, automated security defense, and predictive maintenance are to be included.
More visual insights#
More on figures

🔼 This figure illustrates the automated pipeline used to train the SECOND ME model. It begins with raw user data (like documents, audio, or website interactions) that undergoes data cleaning and mining to extract relevant entities and topics. This data is then filtered, synthesized using techniques like self-location reinforcement and memory cognition enhancement, and used for supervised fine-tuning (SFT) and direct preference optimization (DPO) of the LLM. An LLM acts as a ‘judge’ to evaluate the model’s performance, while another LLM serves as a ‘data synthesizer’ to generate synthetic training data for further refinement. The entire process is iterative, with the model’s performance evaluated continuously to ensure optimal results.
read the caption
Figure 2: Automated Personal Model pipeline with LLM as a Judge and LLM as data synthesizer

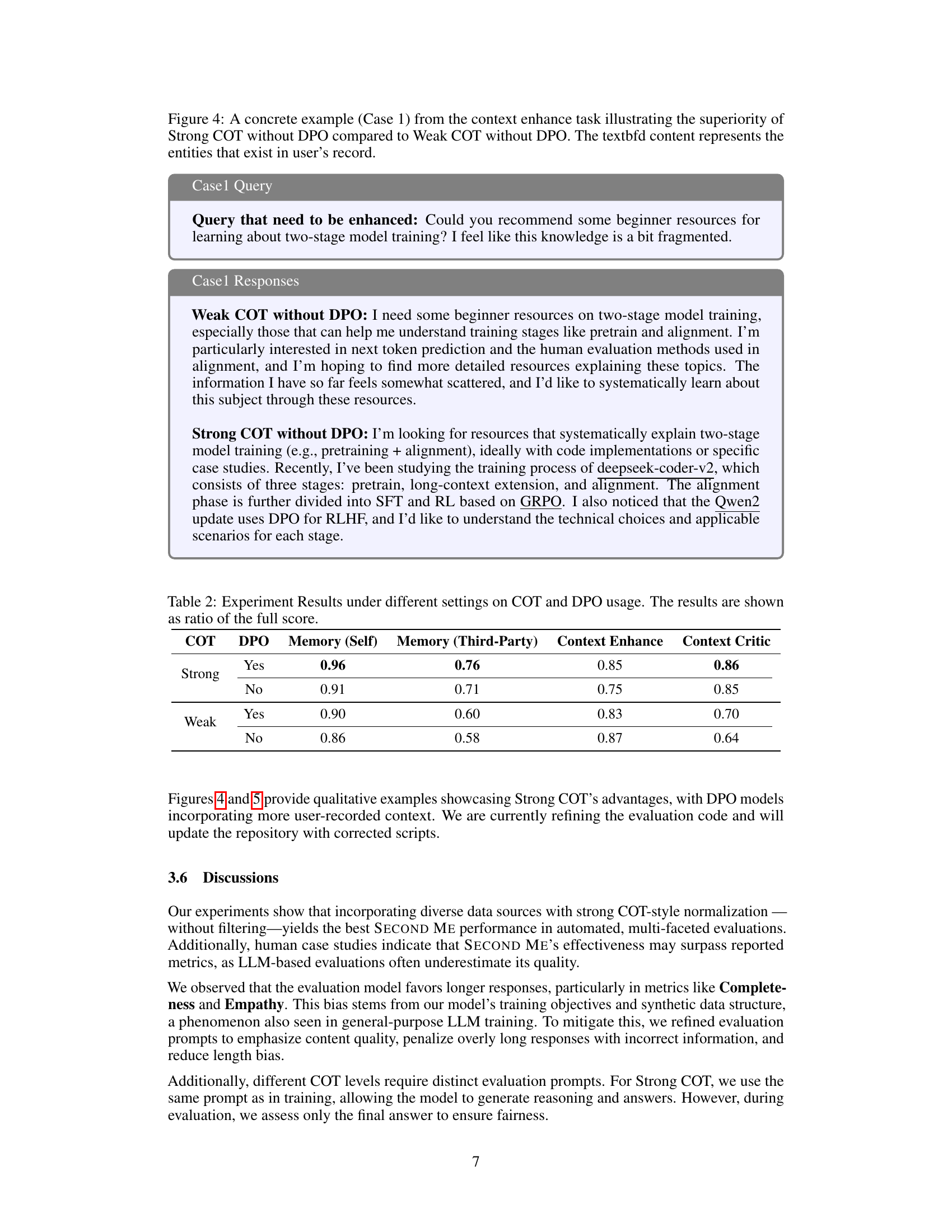
🔼 This figure displays three different responses generated by a large language model (LLM) to the same query, each using a different Chain-of-Thought (COT) strategy. The COT strategies vary in the level of detail and structure in the reasoning process before providing a final answer. This illustrates how different COT strategies can influence the LLM’s response style and the quality of the generated text, in this case showing the progression from less structured (Weak COT) to more structured (Strong COT) reasoning.
read the caption
Figure 3: Given same query, here are three synthetic responses using different COT strategies.
Full paper#