TL;DR#
Existing methods for material retrieval rely on datasets that are shape-invariant and lighting-varied representations of materials, which are scarce and face challenges due to limited diversity and inadequate real-world generalization. Current approaches adopt traditional image search techniques, falling short in capturing the unique properties of material spaces and resulting in suboptimal retrieval performance.
This paper introduces MaRI, a framework designed to bridge the feature space gap between synthetic and real-world materials. MaRI constructs a shared embedding space that harmonizes visual and material attributes through contrastive learning and constructs a comprehensive dataset. Experiments demonstrate superior retrieval performance.
Key Takeaways#
Why does it matter?#
This paper is important for researchers as it introduces a novel framework that significantly improves material retrieval accuracy by bridging the gap between visual and material properties. The comprehensive dataset and innovative approach open new avenues for research in 3D asset generation, AR/VR, and digital content creation, enhancing the realism and context-awareness of virtual environments.
Visual Insights#

🔼 Figure 1 demonstrates the MaRI (Material Retrieval Integration) framework’s capability by showcasing examples from its gallery. Subfigure (a) displays synthetic datasets created by rendering various 3D objects with different materials under controlled lighting. Subfigure (b) shows real-world datasets, where images of materials were captured and processed. Subfigure (c) provides a visual overview of the MaRI framework. It’s described as a groundbreaking method that accurately retrieves materials from images by connecting visual representations (images) with actual material properties, effectively bridging a gap in traditional material retrieval methods.
read the caption
Figure 1: Examples from the MaRI Gallery, showcasing (a) synthetic and (b) real-world datasets we constructed. (c) MaRI: A groundbreaking framework for accurately retrieving textures from images, bridging the gap between visual representations and material properties.
| Method | Trained | Unseen | ||||
|---|---|---|---|---|---|---|
| T1I | T5I | T1C | T3IoU | T1I | T5I | |
| ViT [12] | 3.5% | 12.0% | 16.0% | 0.41 | 16.5% | 56.0% |
| DINOv2 [24] | 7.5% | 28.0% | 69.0% | 0.67 | 31.0% | 62.5% |
| CLIP [26] | 2.0% | 11.0% | 36.5% | 0.47 | 14.0% | 29.5% |
| Make-it-Real [14] | 8.5% | 16.0% | 76.5% | 0.60 | 42.5% | 75.0% |
| MaPa [39] | 2.5% | 17.5% | 80.0% | 0.80 | 19.5% | 69.0% |
| MaRI | 26.0% | 90.0% | 81.5% | 0.77 | 54.0% | 89.0% |
🔼 This table presents a comparison of material retrieval performance across different methods on two datasets: ‘Trained’ and ‘Unseen’. The ‘Trained’ dataset contains materials the model was trained on, while the ‘Unseen’ dataset contains novel materials to evaluate generalization capabilities. The table shows the top-1 and top-5 instance-level accuracy (T1I, T5I), top-1 class-level accuracy (T1C), and top-3 Intersection over Union (T3IoU). Higher values indicate better retrieval performance. The best results for each metric are highlighted in blue.
read the caption
Table 1: Material Retrieval Performance on Trained and Unseen Datasets. Best values are highlighted in blue.
In-depth insights#
Domain Alignment#
Domain alignment is crucial for bridging the gap between synthetic and real-world data in material recognition. The paper addresses this by constructing a comprehensive dataset with both synthetic (controlled) and real-world materials (processed and standardized). A dual-encoder framework (MaRI) aligns visual and material features in a shared space, using contrastive learning. The goal is to bring similar materials and images closer while separating dissimilar pairs. The framework finetunes pre-trained models (DINOv2) to capture domain-specific nuances and preserves generalizability. To build synthetic pairs, the paper uses 3D models and textures from open repositories, rendered with varying lighting. Real-world data is incorporated by leveraging ZeST to generate material spheres from images. This approach allows the model to learn robust representations without relying on extensive annotations, thereby improving retrieval accuracy and generalization capabilities across domains.
Contrastive Loss#
Contrastive loss is a crucial component in representation learning, particularly in scenarios where the goal is to learn embeddings that group similar instances together while separating dissimilar ones. The core idea revolves around defining a loss function that penalizes embeddings when similar pairs are far apart and dissimilar pairs are too close. Effectively, it shapes the embedding space to reflect the underlying similarity structure of the data. The specific formulation can vary; some approaches directly minimize the distance between similar pairs and maximize the distance between dissimilar pairs, while others leverage techniques like InfoNCE loss, which uses a softmax-based approach to compare a positive pair against a set of negative examples. The effectiveness of contrastive loss hinges on the careful selection of similar and dissimilar pairs, often requiring strategies like hard negative mining to identify the most informative negative examples. It has found wide applications in areas like image recognition, natural language processing, and recommendation systems, where learning effective representations is key to achieving strong performance.
Dataset Creation#
The dataset creation process is multifaceted, strategically employing both synthetic generation and real-world capture techniques to create a comprehensive resource for material retrieval. Synthetic data is generated by rendering diverse 3D models with a wide array of materials under varying lighting conditions, leveraging resources like Objaverse and AmbientCG. This provides controlled variations and a large volume of data. Real-world data is incorporated to bridge the domain gap, utilizing methods like ZeST to transfer material appearances from real images onto neutral spheres. This approach captures the nuances and complexities of real-world materials. Segmentation is crucial for isolating material regions within real images. The balance between synthetic and real data ensures robustness and generalization. This comprehensive strategy allows the model to learn a robust feature space for material retrieval.
Unseen Generalize#
While “Unseen Generalize” isn’t explicitly a section title in this paper, the concept of generalization to unseen data is central to its claims. The paper emphasizes that MaRI excels in transferring knowledge acquired from synthetic data to real-world scenarios. This is critical because the model is trained on a controlled synthetic dataset, but its ultimate goal is to perform well on novel, real-world material retrieval tasks. The authors evaluate generalization performance using a separate test set comprised of materials and images not included in the training data. This provides insights into how MaRI handles the domain gap between synthetic and real images, a common challenge in material recognition. They leverage an unsupervised learning approach to overcome annotated datasets. The success in the Unseen Materials retrieval task underscores MaRI’s ability to capture underlying material properties rather than memorizing specific training examples. By demonstrating robust generalization capabilities, the authors strengthen their claim that MaRI offers a more practical solution for material retrieval in real-world applications.
Encoder Ablation#
While the provided text doesn’t explicitly contain a section titled ‘Encoder Ablation,’ the ablation studies presented delve into the impact of various architectural choices related to the encoder. The findings underscore the importance of dual encoders for effectively bridging the gap between image and material representations. Ablating either the synthetic or real-world data reveals a significant drop in performance, highlighting the complementary nature of these datasets in creating a robust embedding space. In essence, the encoder ablation experiments emphasize that the carefully chosen architecture and the diversity of the training data are crucial for achieving state-of-the-art performance in material retrieval, showing the relative contribution of each component to the success of the framework, suggesting that the model is more effective if it preserves both.
More visual insights#
More on figures

🔼 Figure 2 illustrates the process of creating the MaRI dataset, which consists of synthetic and real-world materials. (a) shows how synthetic materials are generated: 3D models from Objaverse are combined with textures from AmbientCG, and rendered using HDR images to create a variety of material samples under diverse lighting conditions. (b) depicts the creation of the real-world dataset: real-world images of materials are selected, the material regions are segmented using Grounded-SAM, and the ZeST method transforms these segments into standardized material spheres. This two-pronged approach ensures a balanced and comprehensive dataset for training and evaluating the MaRI material retrieval framework.
read the caption
Figure 2: Overview of our dataset construction pipeline. (a) Synthetic materials are generated from 3D models obtained from Objaverse, combined with textures from AmbientCG, and rendered with HDR images. (b) Real-world materials are selected and segmented using Grounded-SAM and then transformed into material spheres via the ZeST method.

🔼 MaRI’s architecture is a dual-encoder framework using two DINOv2-based encoders: one for image features and one for material features. Only the final Transformer block of each encoder is fine-tuned during training, keeping the pre-trained weights frozen to maintain generalizability. The training utilizes a contrastive loss function to align image and material embeddings in a shared space. During inference, the cosine similarity between the image and material embeddings is calculated to retrieve the most relevant materials from a material library.
read the caption
Figure 3: The architecture of the MaRI framework for contrastive fine-tuning in material retrieval. MaRI uses DINOv2-based encoders for both image and material feature extraction, fine-tuning only the last Transformer block, while keeping the rest of the model frozen. During inference, cosine similarity between image and material embeddings is used to retrieve the most relevant materials from the library.

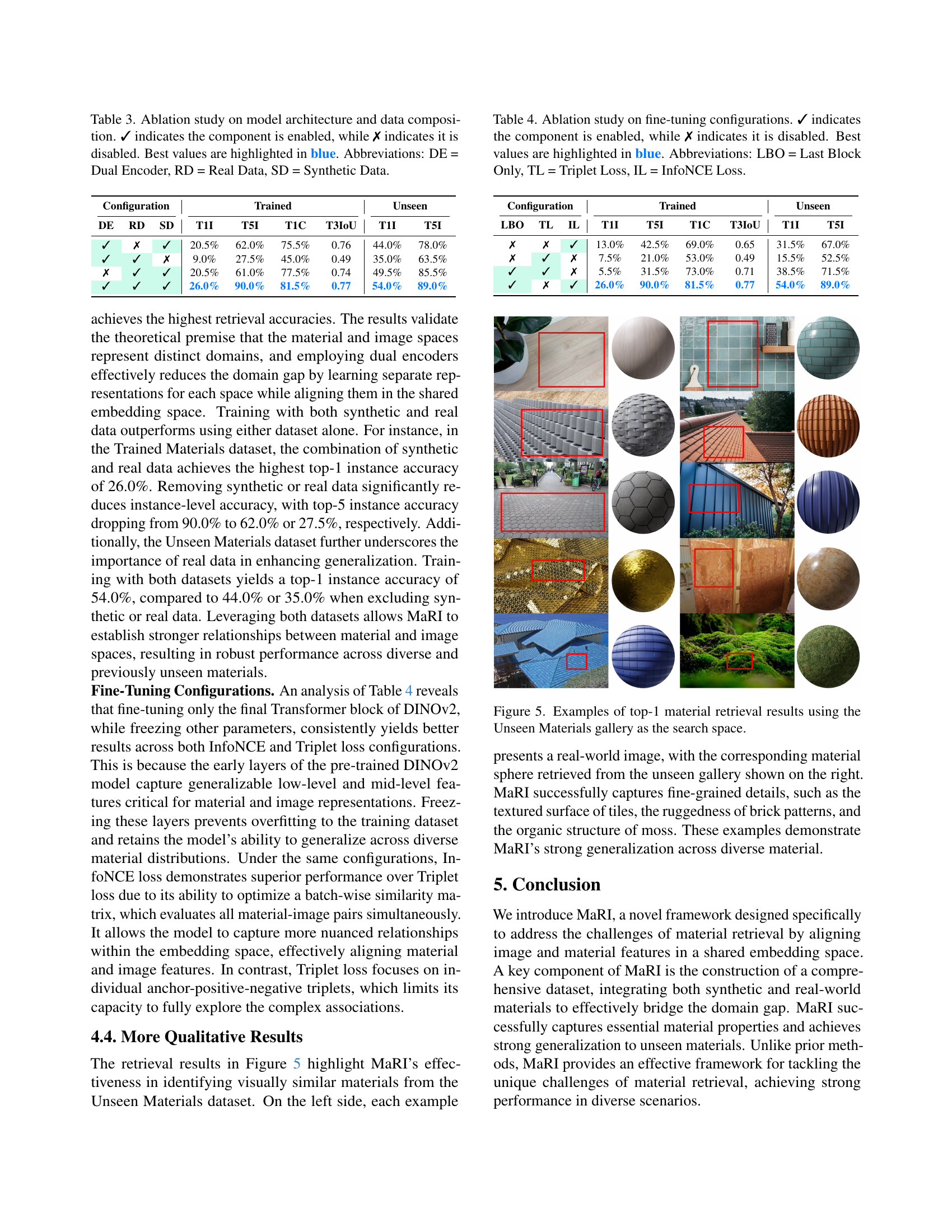
🔼 This figure shows a qualitative comparison of material retrieval results using the ‘Trained Materials’ dataset as the gallery. It presents a real-world image query alongside the top-1 and top-5 retrieval results from different methods: DINOv2, Make-it-Real, MaPa, and MaRI. The goal is to visually demonstrate the relative performance of each method in accurately retrieving materials that match the visual characteristics of the query image. This is done for two example queries, ‘Marble’ and ‘Bark’, allowing for a direct comparison across the methods, highlighting MaRI’s superior performance in accurately retrieving visually similar materials.
read the caption
Figure 4: Qualitative comparison of material retrieval results using the Trained Materials dataset as the gallery.
More on tables
| Data % | Trained | Unseen | ||||
|---|---|---|---|---|---|---|
| T1I | T5I | T1C | T3IoU | T1I | T5I | |
| 25% | 19.5% | 55.5% | 77.5% | 0.76 | 44.5% | 83.5% |
| 50% | 20.0% | 63.5% | 82.0% | 0.79 | 46.0% | 85.5% |
| 75% | 22.0% | 79.5% | 80.5% | 0.78 | 48.5% | 80.0% |
| 100% | 26.0% | 90.0% | 81.5% | 0.77 | 54.0% | 89.0% |
🔼 This ablation study analyzes how different percentages of synthetic data (25%, 50%, 75%, and 100%) in the training process affect the performance of the MaRI model in material retrieval tasks. The results are evaluated using instance-level accuracy (top-1 and top-5), class-level accuracy (top-1), and intersection-over-union (top-3 IoU) for both the ‘Trained’ and ‘Unseen’ datasets. The table shows how increasing the amount of synthetic data improves retrieval performance, particularly for instance-level tasks.
read the caption
Table 2: Ablation study evaluating the impact of synthetic data usage. Best values are highlighted in blue.
| Configuration | Trained | Unseen | ||||||
|---|---|---|---|---|---|---|---|---|
| DE | RD | SD | T1I | T5I | T1C | T3IoU | T1I | T5I |
| ✓ | ✗ | ✓ | 20.5% | 62.0% | 75.5% | 0.76 | 44.0% | 78.0% |
| ✓ | ✓ | ✗ | 9.0% | 27.5% | 45.0% | 0.49 | 35.0% | 63.5% |
| ✗ | ✓ | ✓ | 20.5% | 61.0% | 77.5% | 0.74 | 49.5% | 85.5% |
| ✓ | ✓ | ✓ | 26.0% | 90.0% | 81.5% | 0.77 | 54.0% | 89.0% |
🔼 This ablation study investigates the impact of different model architectures and dataset compositions on material retrieval performance. The table shows the results for various configurations, including whether a dual encoder model was used, whether real-world and synthetic data were included, and their effect on retrieval accuracy metrics (Top-1 Instance Accuracy, Top-5 Instance Accuracy, Top-1 Class Accuracy, and Top-3 Intersection over Union). The ‘✓’ symbol indicates that a component was included, while ‘✗’ indicates it was excluded. The best performing configurations for each metric are highlighted in blue. This allows for a quantitative comparison of model designs and data choices.
read the caption
Table 3: Ablation study on model architecture and data composition. ✓ indicates the component is enabled, while ✗ indicates it is disabled. Best values are highlighted in blue. Abbreviations: DE = Dual Encoder, RD = Real Data, SD = Synthetic Data.
| Configuration | Trained | Unseen | ||||||
|---|---|---|---|---|---|---|---|---|
| LBO | TL | IL | T1I | T5I | T1C | T3IoU | T1I | T5I |
| ✗ | ✗ | ✓ | 13.0% | 42.5% | 69.0% | 0.65 | 31.5% | 67.0% |
| ✗ | ✓ | ✗ | 7.5% | 21.0% | 53.0% | 0.49 | 15.5% | 52.5% |
| ✓ | ✓ | ✗ | 5.5% | 31.5% | 73.0% | 0.71 | 38.5% | 71.5% |
| ✓ | ✗ | ✓ | 26.0% | 90.0% | 81.5% | 0.77 | 54.0% | 89.0% |
🔼 This ablation study analyzes the impact of different fine-tuning configurations on the MaRI model’s performance. It examines the effects of fine-tuning only the last Transformer block (LBO), using Triplet Loss (TL), and using InfoNCE Loss (IL). The table shows the top-1 and top-5 instance-level accuracy (T1I, T5I), top-1 class-level accuracy (T1C), and top-3 Intersection over Union (T3IoU) for both the ‘Trained’ and ‘Unseen’ datasets under various combinations of these configurations. The best-performing configurations for each metric are highlighted in blue.
read the caption
Table 4: Ablation study on fine-tuning configurations. ✓ indicates the component is enabled, while ✗ indicates it is disabled. Best values are highlighted in blue. Abbreviations: LBO = Last Block Only, TL = Triplet Loss, IL = InfoNCE Loss.
Full paper#