TL;DR#
Joint audio-video (AV) generation struggles with quality, synchronization, and infinite duration. Existing methods often focus on single modalities or have limited video lengths. Techniques like MM-Diffusion are restricted in video duration, while auto-regressive approaches suffer from error accumulation. Rolling Diffusion improves quality but lacks audio track generation, highlighting the need for solutions addressing all these challenges.
RFLAV, a novel transformer-based architecture, tackles these issues. It employs rolling flow matching for infinite AV generation, explores cross-modality interaction modules, and identifies a lightweight temporal fusion module for effective audio-visual alignment. Experiments show RFLAV outperforms existing models in quality and consistency, enabling unrestricted AV sequence generation.
Key Takeaways#
Why does it matter?#
This research offers a way forward for high-quality, long-duration audio-video generation. It is relevant to current trends in generative AI, pushing the boundaries of what’s possible with multimodal data and opens avenues for new research in temporal consistency and cross-modality fusion.
Visual Insights#

🔼 This figure presents a detailed architectural overview of the RFLAV model, illustrating the processing pathways for both audio and video streams. The model incorporates a rolling flow matching mechanism. It begins with separate encoding of audio and video data, which avoids early fusion, allowing for efficient intra-modality interactions (like self-attention) before cross-modality processing. The figure shows the flow of information through various modules, including VAE encoder/decoder, Mel encoder, HiFi-GAN, and RFLAV blocks. This architecture is explicitly designed to generate videos of arbitrary length, unlike models restricted by fixed-size encoders. It emphasizes the three proposed alternatives for cross-modality interaction within the RFLAV block.
read the caption
Figure 1: An overview of our RFLAV model architecture.
🔼 This table presents a comparison of three different cross-modality interaction module designs within the RFLAV model. The comparison includes inference time (measured on an NVIDIA RTX 4090 GPU for a 16-frame sample), memory usage, and quantitative metrics (Fréchet Video Distance, Kernel Video Distance, and Fréchet Audio Distance). These metrics assess the quality of video and audio generated by the model using each of the three different module designs. The table helps demonstrate the effectiveness and efficiency of the chosen module design in the RFLAV architecture.
read the caption
Table 1.A: Comparison between inference time for a sample of 16 frames, memory usage and quantitative metrics of all the 3 proposed blocks. Time was calculated on a NVIDIA RTX 4090 gpu.
In-depth insights#
AV Infinite Gen.#
The concept of “AV Infinite Gen.” is intriguing, representing a significant leap in generative AI. The aim is to create audio-visual content of unlimited duration, a challenge that demands high-quality output, seamless multimodal synchronization, and long-term temporal coherence. Breaking free from fixed-length constraints is pivotal, enabling dynamic and evolving narratives. Key to achieving this is tackling error accumulation in auto-regressive models and maintaining consistency over extended periods. Solutions like rolling diffusion offer promise by focusing on local temporal relationships, but integrating robust audio synchronization is crucial. Future research should explore architectures that can handle the complexities of infinite generation, ensuring both visual and auditory fidelity while preserving computational efficiency and temporal coherence. The ultimate success of ‘AV Infinite Gen.’ hinges on its ability to create immersive and engaging experiences without the artifacts and limitations of current generative methods.
RFLAV: Details#
The RFLAV architecture introduces a novel approach to audio-video (AV) generation by leveraging a transformer-based model without relying on traditional video or audio encoders. This design choice enables the generation of videos of arbitrary lengths, a significant advancement. RFLAV processes video and audio in parallel branches, delaying modality fusion to encourage initial intra-modality interaction via self-attention. The architecture’s core, the RFLAV block, features separate video and audio branches, with the video branch applying both spatial and temporal attention. A key innovation is the custom DiT adaptive layer normalization (AdaLN), which modulates features based on timestep embeddings and optional class conditioning. RFLAV explores three cross-modality fusion blocks, with the most effective one incorporating timestep and class information to enhance cross-modal understanding. The model employs a rolling rectified-flow matching framework, modifying the rolling diffusion methodology to facilitate training with rectified flow matching. This ensures high-quality, coherent video generation with synchronized audio, avoiding the limitations of fixed-length or auto-regressive approaches.
Flow Matching#
The paper leverages Flow Matching as a crucial component for achieving high-quality audio-video generation. Flow matching is essential to guide the sample from noise to data distribution by predicting the velocity vector. A loss function is defined to quantify the difference between predicted and actual velocity. This technique, combined with rolling diffusion, allows the model to create temporally coherent and synchronized AV content, effectively addressing the challenges of infinite video generation. The authors have also modified the standard loss by incorporating the weight factor to help further control the framework. In rolling flow matching they use equations to define the forward process to take noisy video and audio embeddings.
Ablation Studies#
The ablation study meticulously investigates the impact of various components within the proposed RFLAV architecture, offering valuable insights into their individual contributions. The comparison of different cross-modality interaction blocks (a, b, and c) reveals that block (c), which incorporates timestep and class conditioning embeddings with a lightweight temporal averaging mechanism, achieves superior performance, suggesting a more effective and efficient approach for fusing audio and video modalities. Further exploration of varying window sizes (5, 10, and 20 frames) uncovers an optimal balance at 10 frames, indicating the importance of capturing sufficient temporal context without introducing redundant information or noise. These findings highlight the design choices in RFLAV and provide a solid foundation for understanding its effectiveness in joint audio-video generation. The improvements achieved with block (c) suggest the importance of temporal conditioning and modality fusion, while the ideal window size of 10 frames points to the need to consider both short-term dynamics and long-term coherence. This level of detail is essential for assessing the robustness and generalizability of the model across different datasets and tasks.
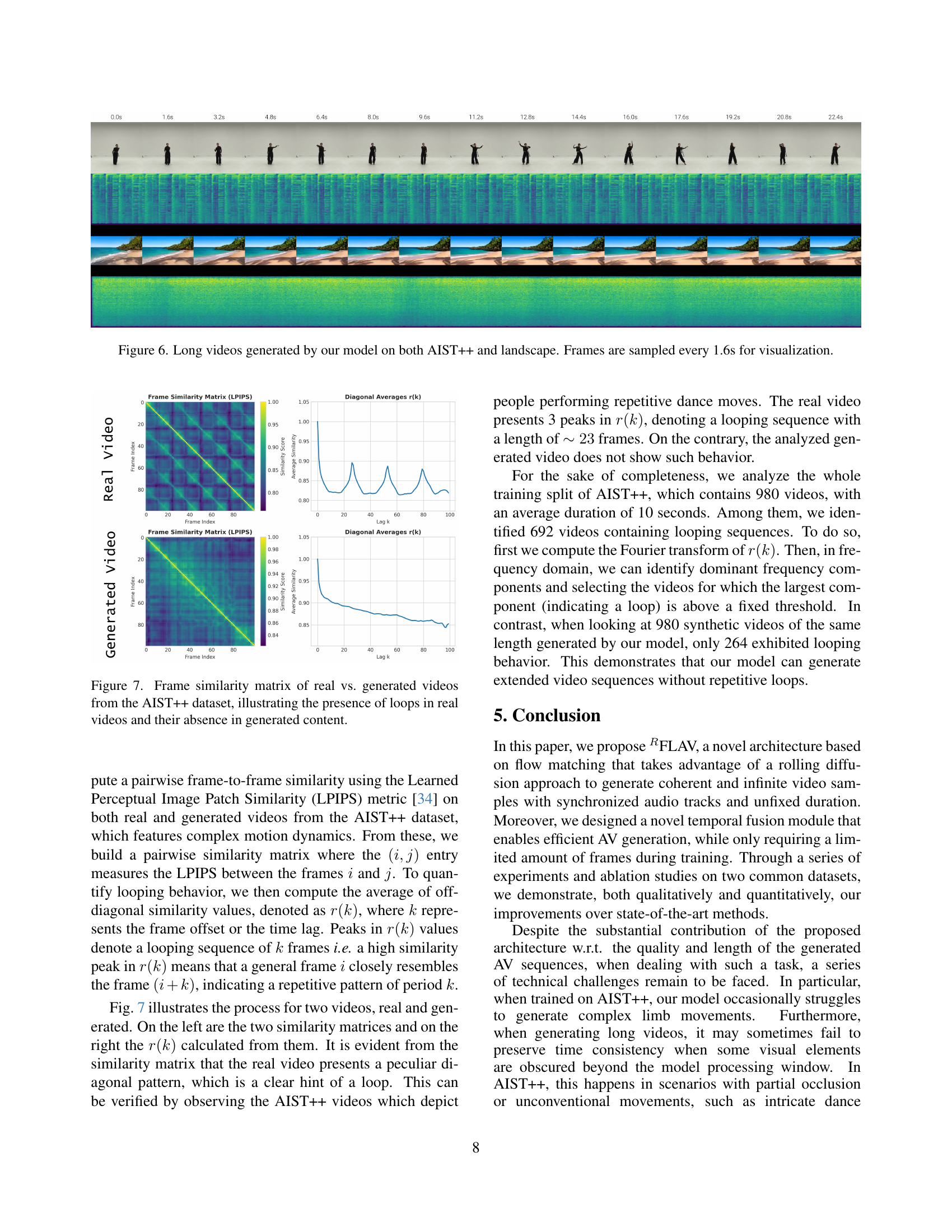
Loop Detection#
The approach to detect looping sequences in generated videos leverages the Learned Perceptual Image Patch Similarity (LPIPS) metric to compute frame-to-frame similarity, constructing a matrix where each entry reflects the similarity between frames. By averaging off-diagonal similarity values, a function r(k) is derived, with peaks indicating repetitive patterns occurring k frames apart. Analyzing the Fourier transform of r(k) enables identification of dominant frequency components, helping to discern if the generated videos contain recurring sequences. This method distinguishes genuine motion dynamics from mere repetitions, ensuring the model’s capacity to create diverse and extended video sequences. A key finding is that while real-world videos often exhibit clear looping patterns, the generated content demonstrates significantly reduced looping, validating the model’s ability to produce novel and non-repetitive motion dynamics. It highlights the importance of assessing temporal coherence and originality in generative models beyond traditional metrics.
More visual insights#
More on figures

🔼 This figure illustrates how the model aligns audio and video data. The model processes video data frame by frame and audio data as a mel spectrogram. Importantly, it maintains a one-to-one correspondence between a single video frame and a fixed-length segment of the mel spectrogram, ensuring precise synchronization between the two modalities. This one-to-one mapping is crucial for generating long, coherent AV sequences with consistent audio-visual alignment.
read the caption
Figure 2: Temporal alignment between video frames and mel spectrogram segments. Each video frame corresponds to a fixed-size section (F/T) of the mel spectrogram, allowing for a 1:1 mapping.
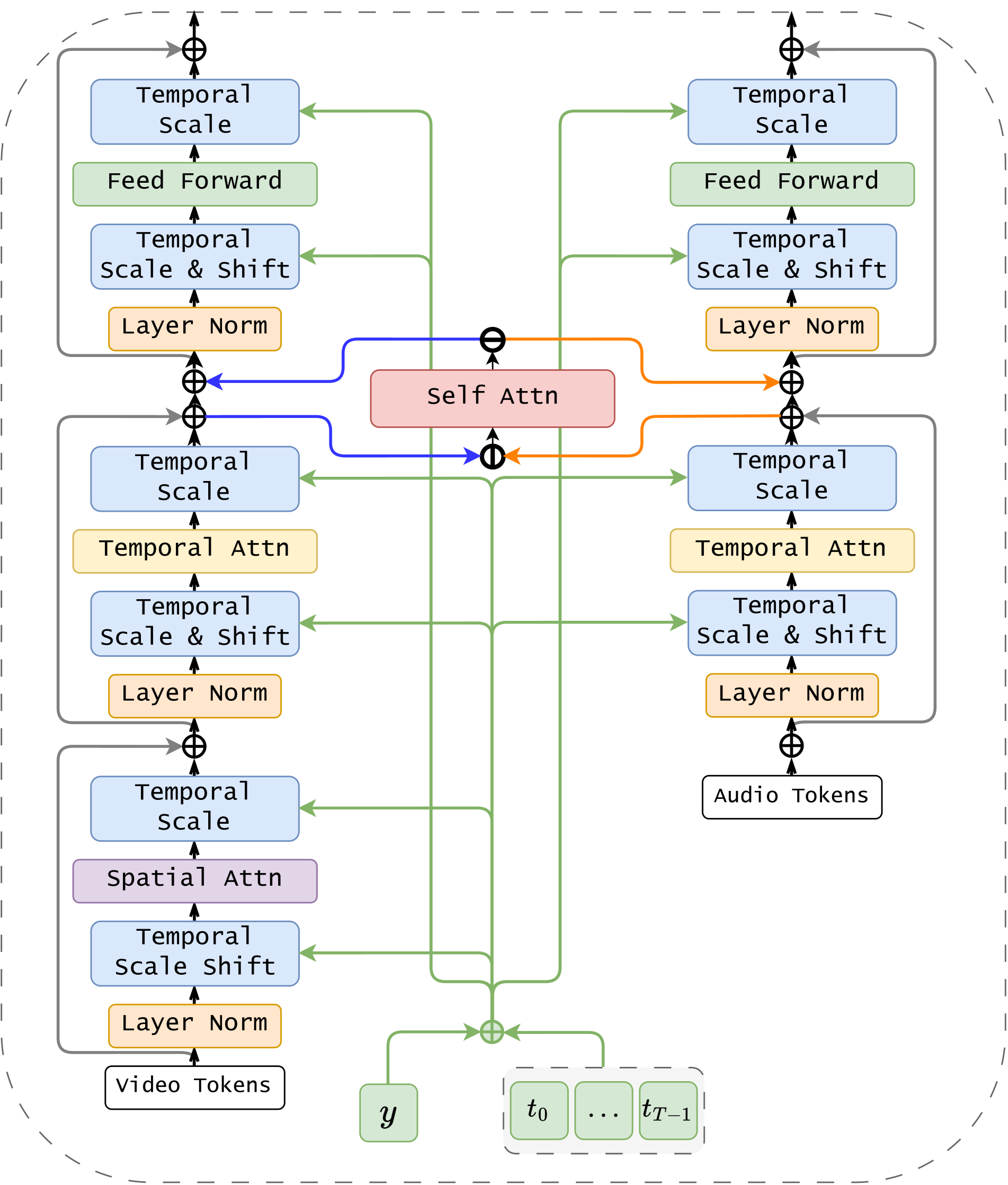
🔼 This figure shows three different designs for cross-modality interaction in the RFLAV model. (a) depicts a cross-modal interaction using self-attention. Audio embeddings are reshaped and concatenated with video embeddings before being processed by causally masked self-attention. The output is then split back into audio and video embeddings and added to their respective branches. (b) shows a lightweight cross-modality interaction mechanism using temporal average modulation. Temporal averages of both video and audio features are computed and used for cross-modal fusion. (c) combines elements of (b) and enhances it by incorporating timestep embeddings and optional class conditioning embeddings.
read the caption
(a)

🔼 This figure shows one of the three cross-modality interaction module designs explored in the paper. It illustrates a lightweight approach to combining audio and video information. Temporal averages of video and audio features are computed, then combined, before influencing the feed-forward layers in each modality branch. This design avoids the computationally expensive self-attention mechanisms used in other designs, resulting in a more efficient model.
read the caption
(b)

🔼 This figure shows the architecture of the lightweight cross-modality interaction module used in the RFLAV model. It contrasts with other more complex approaches involving self-attention mechanisms. The diagram details the flow of audio and video data through the module, highlighting the temporal averaging process and its use in modulating both audio and video features before they reach the feed-forward layer. This lightweight design avoids attention mechanisms, resulting in a more computationally efficient model.
read the caption
(c)

🔼 Figure 3 details three different cross-modality interaction modules explored in the RFLAV model. (a) shows a self-attention mechanism that processes concatenated audio and video embeddings before splitting them again. This method is computationally expensive. (b) is a lightweight module that uses temporal average modulation, combining aggregated audio and video features for cross-modality interaction, offering improved efficiency. (c) builds upon (b), incorporating timestep embeddings (t) and optional class conditioning embeddings (c) for enhanced performance and flexibility. This last version is the one adopted in the final RFLAV model architecture.
read the caption
Figure 3: a) Cross-modal interaction via self-attention, where ⊖symmetric-difference\ominus⊖ and ⊖symmetric-difference\ominus⊖ mean concatenation and split. b) Lightweight cross-modality interaction mechanism with temporal average modulation. c) Our final proposed RFLAV block, an enhanced lightweight mechanism incorporating timestep embedding t𝑡titalic_t and optional class conditioning embedding c𝑐citalic_c.

🔼 This figure shows three different designs for a cross-modality interaction module within the RFLAV architecture. Each design explores different methods for combining audio and video features to improve multimodal synchronization and coherence. (a) illustrates a self-attention-based approach, where audio and video embeddings are concatenated and processed together. (b) shows a simpler design using temporal averages of audio and video features for modulation. (c) enhances (b) by including timestep embedding for better control over the diffusion process.
read the caption
(a)

🔼 This figure shows one of the three proposed cross-modality interaction modules within the RFLAV model. It depicts a lightweight approach to combining audio and video features. Instead of using computationally expensive self-attention mechanisms, it utilizes temporal averaging to create a compact representation of both audio and video data, allowing for efficient fusion before the next processing stages.
read the caption
(b)

🔼 Figure 4 illustrates the rolling diffusion process used in the RFLAV model for video generation. (a) shows the ‘rolling phase’, where a sliding window processes video frames. At each step, the model denoises the oldest frame in the window (red), and then removes it. A new, fully noisy frame (blue) is then added to the end of the window to keep the window size constant. This process continues, enabling the generation of arbitrarily long video sequences. (b) shows the ‘pre-rolling phase’, which initializes the process. Here, the window starts with all frames completely noisy, gradually denoising until it is ready to transition into the rolling phase.
read the caption
Figure 4: a) Rolling phase: at each step, a new clean frame is produced (highlighted in red) and subsequently removed from the window. Then, a new noisy frame, (highlighted in blue), is appended to the end of the window. b) Pre-rolling phase: the frames are gradually denoised starting from a full noise configuration. The pre-rolling phase goes on for N𝑁Nitalic_N steps, until the window is ready for the rolling phase.

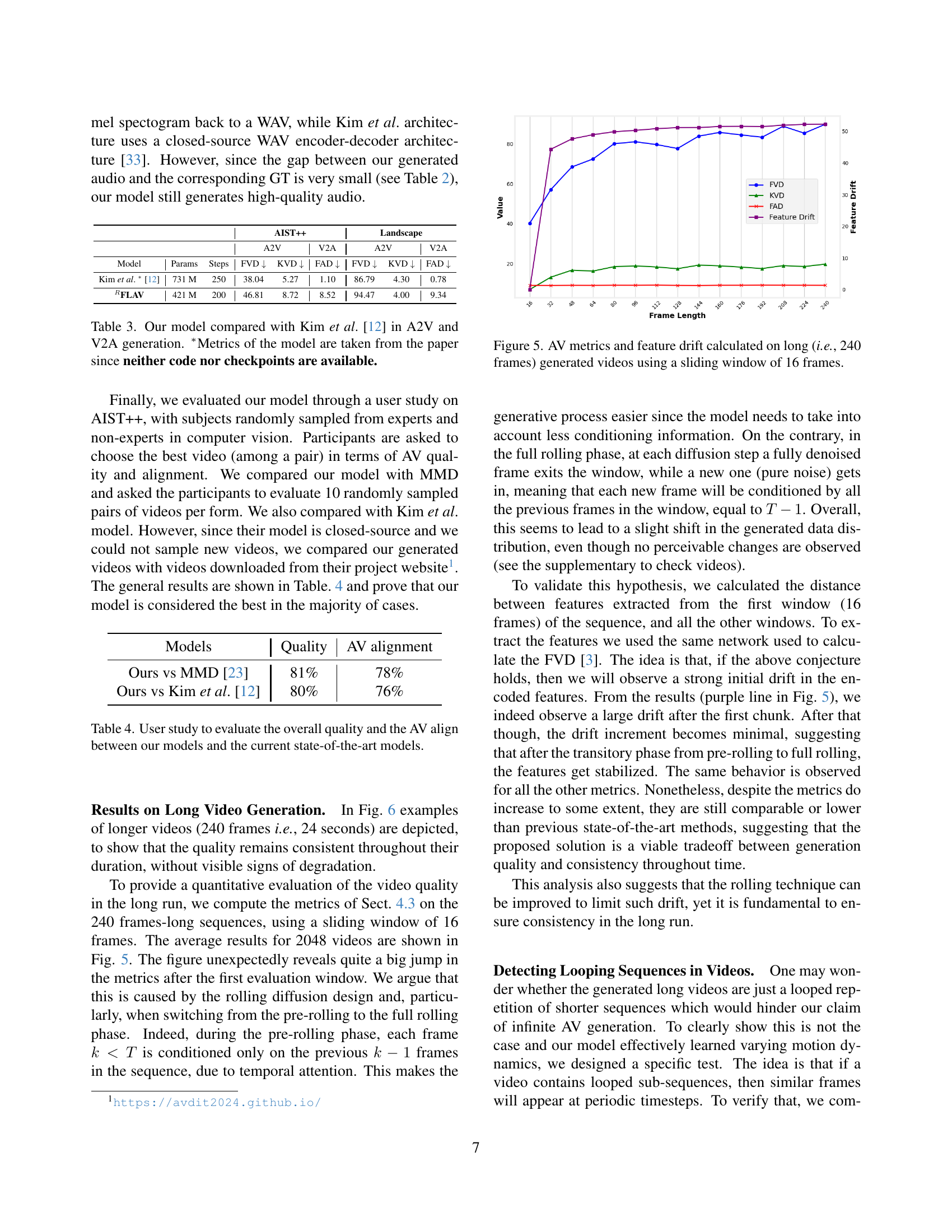
🔼 This figure visualizes the impact of video length on the quality of generated audio-visual data. It shows how the Fréchet Video Distance (FVD), Kernel Video Distance (KVD), and Fréchet Audio Distance (FAD) metrics, along with a measure of feature drift, change across a long video (240 frames) generated by the model. The metrics are calculated using a sliding window of 16 frames, providing insights into how well the model maintains consistent quality and alignment over longer sequences. A noticeable jump in the metrics is observed initially, followed by stabilization, indicating a transition phase in the generation process before achieving consistent quality.
read the caption
Figure 5: AV metrics and feature drift calculated on long (i.e., 240 frames) generated videos using a sliding window of 16 frames.
Full paper#