TL;DR#
Reinforcement Learning with verifiable outcome rewards (RLVR) has shown promise in scaling up chain-of-thought (CoT) reasoning in large language models (LLMs). However, its effectiveness is less established when training vision-language model (VLM) agents for goal-directed action reasoning in visual settings. Through experiments on card games and embodied tasks, the research identified a bottleneck where RL fails to incentivize CoT reasoning in VLMs. This leads to a “thought collapse,” characterized by a rapid loss of diversity in the agent’s thoughts, state-irrelevant reasoning, and invalid actions.
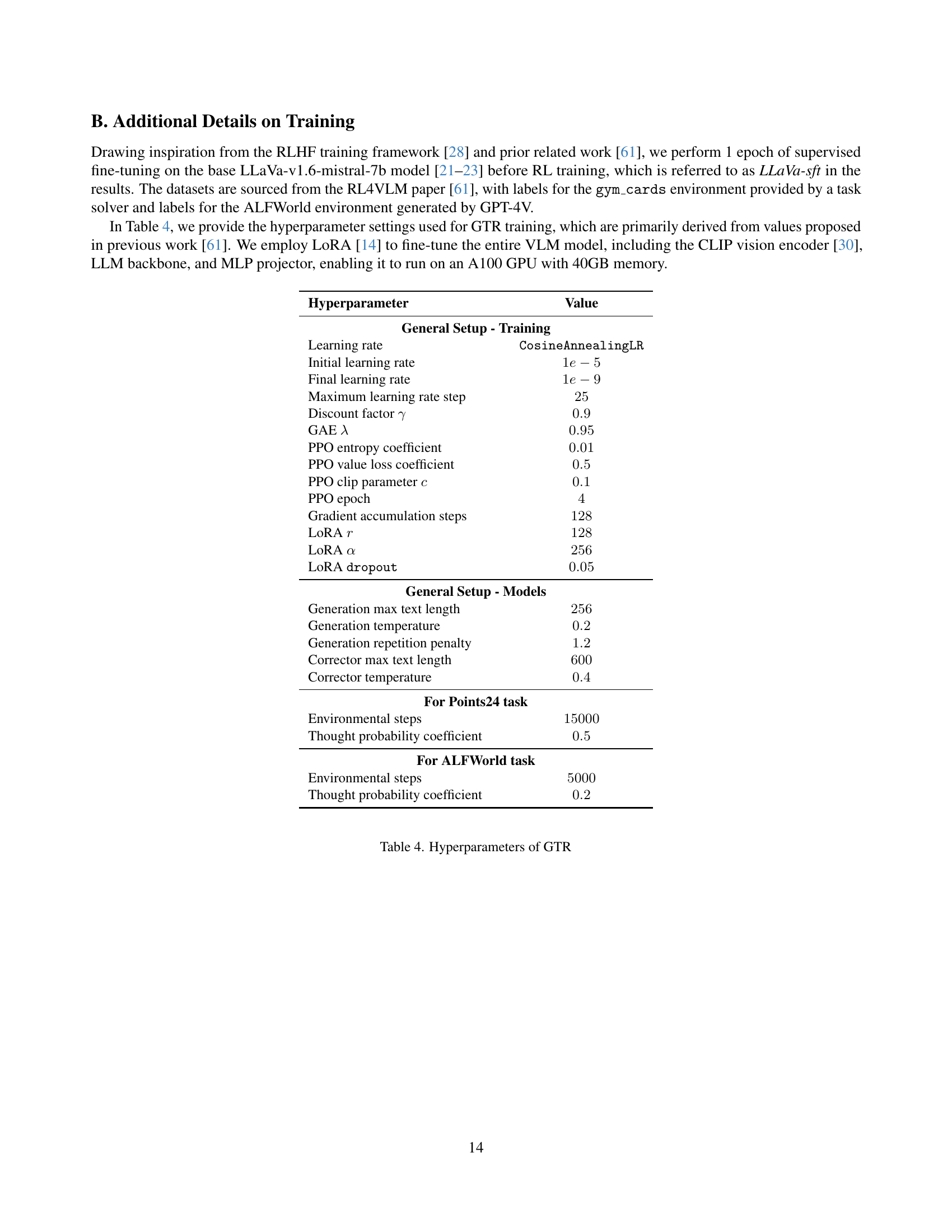
To address this, the paper introduces Guided Thought Reinforcement (GTR). GTR utilizes an automated corrector that evaluates and refines the agent’s reasoning. This framework trains reasoning and action simultaneously without human labeling. Experiments demonstrate that GTR enhances the performance and generalization of the LLaVA-7b model across visual environments. GTR achieves higher task success rates compared to other models. This shows that combining thought guidance with RL enhances the decision-making potential of VLM agents.
Key Takeaways#
Why does it matter?#
This work offers vital insights & a practical solution (GTR) to prevent thought collapse in RL-based VLM agents, boosting performance & generalization. It enhances decision-making in complex visual environments, opening doors for smarter, more reliable AI systems.
Visual Insights#

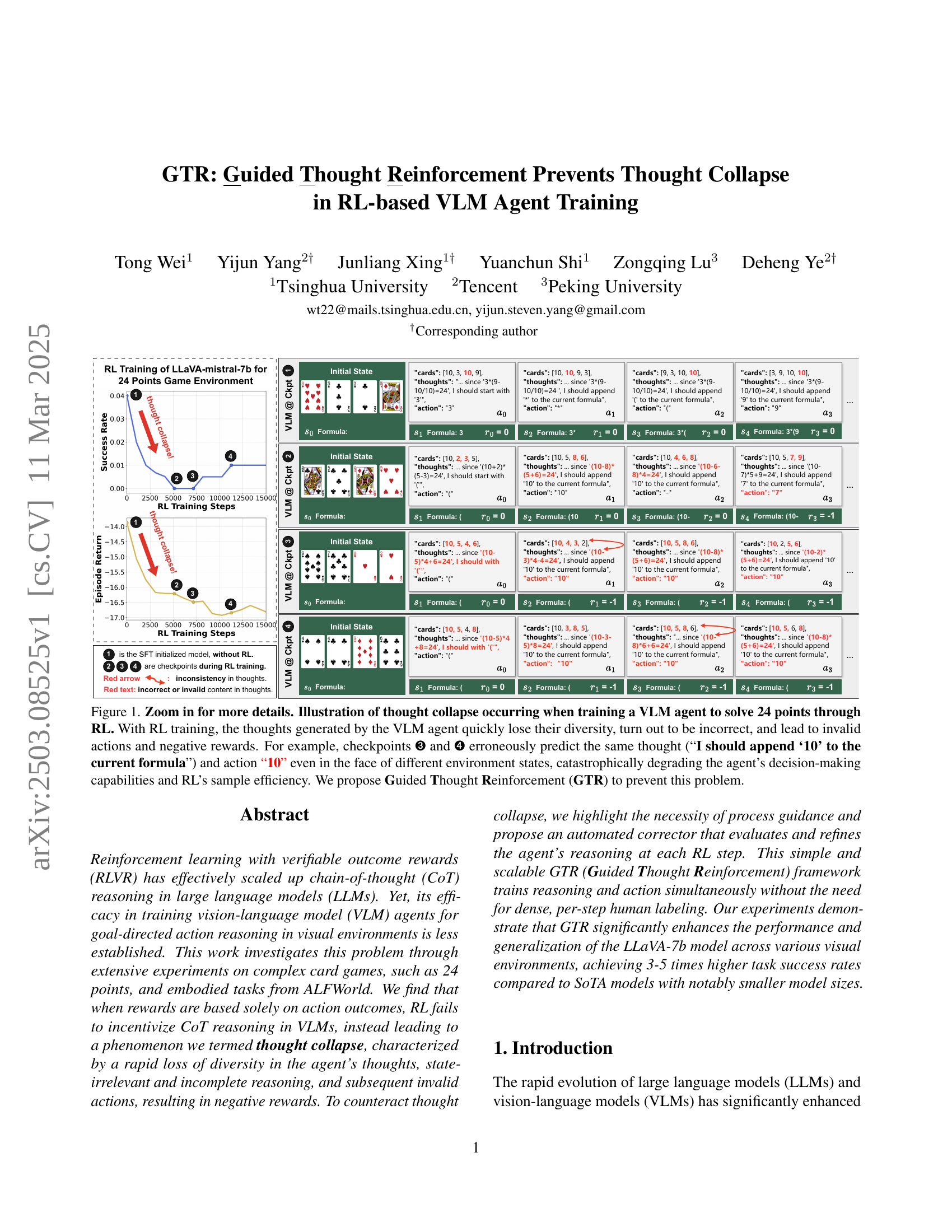
🔼 Figure 1 illustrates the phenomenon of ’thought collapse’ during reinforcement learning (RL) training of a vision-language model (VLM) agent designed to solve the 24 points card game. The figure shows that as RL training progresses, the VLM’s reasoning process loses diversity. The model begins producing repetitive and incorrect thoughts, even when presented with different game states. This leads to invalid actions and negative rewards, severely hindering the agent’s ability to learn effectively. Specifically, checkpoints 3 and 4 highlight this issue, where the same thought and action are generated despite distinct starting card arrangements. This demonstrates the inefficiency of RL training in this context and motivates the need for the proposed Guided Thought Reinforcement (GTR) method to address this problem.
read the caption
Figure 1: Zoom in for more details. Illustration of thought collapse occurring when training a VLM agent to solve 24 points through RL. With RL training, the thoughts generated by the VLM agent quickly lose their diversity, turn out to be incorrect, and lead to invalid actions and negative rewards. For example, checkpoints ➌ and ➍ erroneously predict the same thought (“I should append ‘10’ to the current formula”) and action “10” even in the face of different environment states, catastrophically degrading the agent’s decision-making capabilities and RL’s sample efficiency. We propose Guided Thought Reinforcement (GTR) to prevent this problem.
| Model | Size | Numberline | EZPoints | Blackjack | |||
|---|---|---|---|---|---|---|---|
| SR(%) | ER | SR(%) | ER | SR(%) | ER | ||
| CNN+RL* | / | 87.1 | 0.79 | 0 | -1.02 | 38.8 | -0.17 |
| Gemini* | API | 82.5 | 0.74 | 2.0 | -2.57 | 30.0 | -0.35 |
| GPT4-V* | API | 65.5 | -0.59 | 10.5 | -1.30 | 25.5 | -0.44 |
| GPT4o | API | 100.0 | 1.00 | 79.0 | 7.0 | 36.0 | -0.19 |
| Qwen-2-VL* | 72b | 100.0 | / | 100.0 | / | 42.6 | / |
| LLaVA-sft | 7b | 59.5 | -2.61 | 39.0 | 0.67 | 25.5 | -0.46 |
| RL4VLM | 7b | 90.5 | 0.89 | 48.0 | 4.19 | 40.1 | -0.16 |
| GTR | 7b | 100.0 | 1.00 | 94.5 | 9.43 | 41.3 | -0.11 |
🔼 This table compares the performance of different models on various tasks within the
gym_cardsenvironment. It focuses on tasks simpler than the main Points24 task, where the phenomenon of ’thought collapse’ is less prominent. The comparison highlights GTR’s performance against the baseline RL4VLM method and also against a significantly larger pretrained model (10x larger). The key metrics evaluated are Success Rate (SR) and Episode Return (ER). Results marked with an asterisk (*) indicate data reported from previous research and not from the current experiments.read the caption
Table 1: Performance of different models in other tasks in 𝚐𝚢𝚖_𝚌𝚊𝚛𝚍𝚜𝚐𝚢𝚖_𝚌𝚊𝚛𝚍𝚜\mathtt{gym\_cards}typewriter_gym _ typewriter_cards. On simpler tasks where thought collapse is not evident, GTR still achieves improvements over RL4VLM and is comparable to the pretrained model 10x larger in size. SR - success rate, ER - episode return, * - reported in previous work.
In-depth insights#
Thought Collapse#
Thought collapse in VLM agents during RL training is a critical issue, hindering their reasoning. Unlike text-based LLMs, VLMs face added complexity from multimodal data. RL’s reward structure, focused on final actions, neglects the thought process. This leads to rapid loss of thought diversity, resulting in state-irrelevant, templated reasoning. Agents generate incoherent thoughts, triggering invalid actions and negative rewards. This phenomenon persists despite increasing model size or training, indicating it stems from the RL process itself. Addressing this requires process guidance to counteract thought collapse and improve decision-making in VLMs.
Guided Thinking#
Guided Thought Reinforcement (GTR) mitigates thought collapse in VLMs, a phenomenon where reasoning degrades during RL training, leading to irrelevant actions. GTR employs an automated corrector to refine agent’s thoughts at each step, guiding the reasoning process. This framework trains reasoning and action simultaneously, without relying on human labeling. GTR enhances VLM performance and generalization across visual environments, boosting task success rates significantly. The plug-and-play corrector leverages any VLM to evaluate and refine thoughts, automating trajectory correction. By integrating guidance, GTR fosters structured reasoning, leading to more transparent decision-making in complex tasks. The framework balances rationality and correctness, addressing output format degradation and distribution shift through format rewards and imitation learning.
VLM Correction#
VLM Correction emerges as a critical component of Guided Thought Reinforcement (GTR), addressing the ’thought collapse’ phenomenon in RL-based VLM agent training. By leveraging an external VLM as a corrector, GTR evaluates and refines the agent’s reasoning at each step, ensuring rationality and correctness. This automated process guidance, combined with RL, enhances decision-making capabilities. Function-calling further enhances the corrector’s accuracy. The authors reference techniques like the use of a Process Reward Model and a VLM-as-a-judge approach but highlights the limitations of these for dynamic visual environments. In contrast, GTR doesn’t rely on human annotations or additional training but provides more informative process supervision while preserving the flexibility of RLVR.
GTR Algorithm#
While the provided PDF lacks a section explicitly titled “GTR Algorithm,” the paper introduces Guided Thought Reinforcement (GTR) as a novel framework. GTR addresses the problem of thought collapse in RL-trained VLMs by integrating an automated corrector that refines the agent’s reasoning at each step. This approach uses a VLM as a corrector that evaluates visual recognition accuracy and reasoning, correcting inconsistencies. The corrected thoughts are incorporated using a SFT loss, aligning the agent’s reasoning. To mitigate distribution shift, DAgger aggregates corrections, ensuring convergence to the corrector’s policy. The algorithm balances exploration with guided reasoning, significantly enhancing performance in complex tasks. The core idea involves a clever combination of existing techniques to achieve significantly improved RL-based VLM agent training.
Limits & Future#
While the paper makes significant strides in addressing the thought collapse problem in RL-based VLM agents, it’s important to consider its limitations and potential future directions. The reliance on a powerful external VLM (GPT-40) as a corrector introduces a dependency and potential bottleneck, particularly in resource-constrained settings or when scaling to more complex tasks. Future research could explore more efficient and lightweight correction mechanisms, perhaps by training a separate, smaller model specifically for this purpose or by leveraging self-correction techniques within the agent itself. The current framework primarily focuses on improving the agent’s reasoning and action selection but doesn’t explicitly address the challenges of exploration in visual environments. Future work could integrate exploration strategies, such as curiosity-driven exploration, to encourage the agent to actively seek out novel states and learn more effectively. Although the guided thought reinforcement framework improves performance, the reliance on the corrector model introduces a bias. Future research can focus on methods that promote diversity and encourage the model to explore alternative solutions instead of relying too much on prior knowledge to find the best solution. Also, the framework needs to be extended to evaluate the effectiveness of the agent across a broader range of tasks and real-world scenarios, validating its generalization capabilities and robustness to noisy or ambiguous inputs. It is also important to research how different types of guidance and corrections impact the agent’s learning and performance. Finally, future work should consider scaling the approach to larger models and datasets, assessing its scalability and identifying potential challenges in training and deployment.
More visual insights#
More on figures

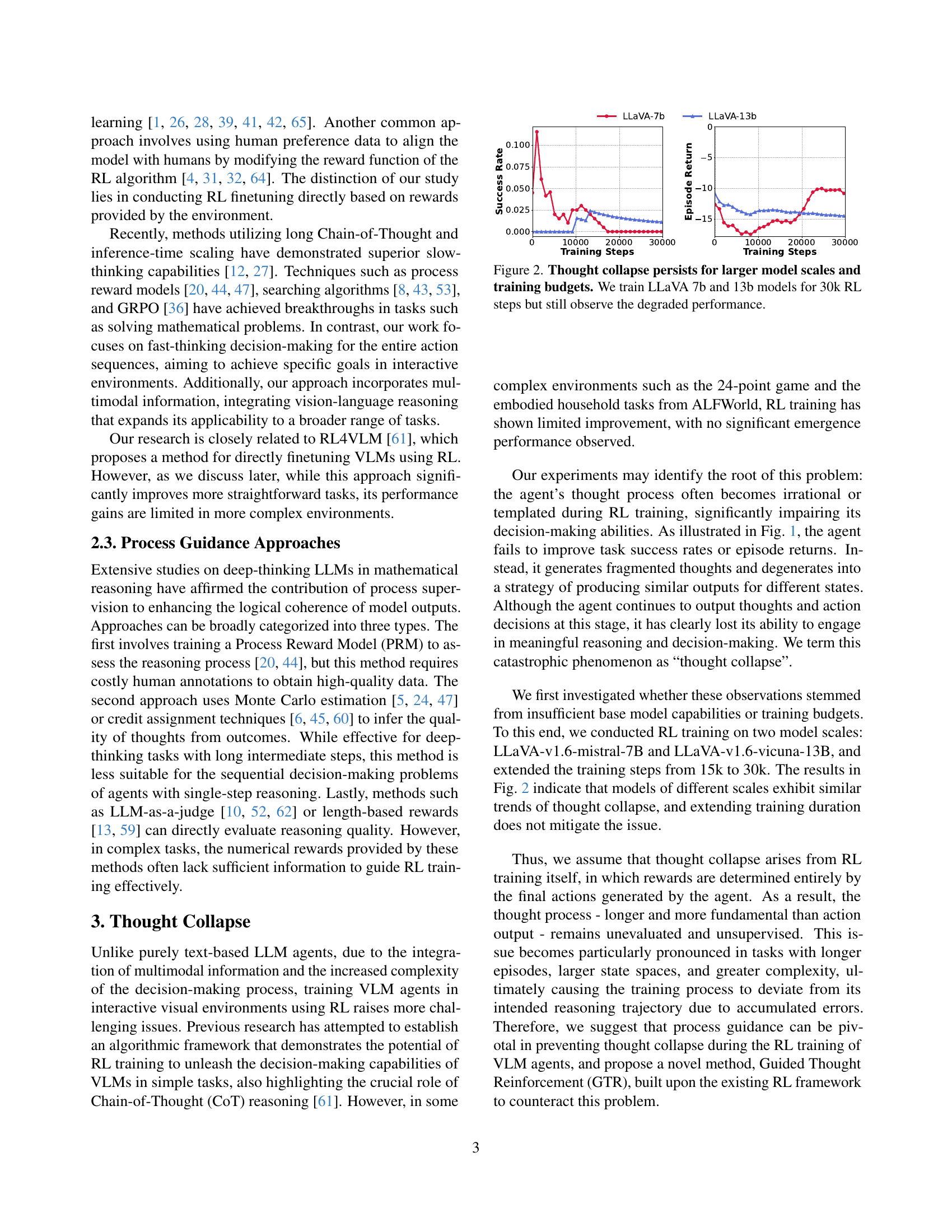
🔼 Figure 2 presents the results of training two different sized Large Language Models (LLMs) using reinforcement learning. The models, LLaVa 7B and LLaVa 13B, were trained for 30,000 reinforcement learning steps. The graphs display both the episode return (a measure of cumulative reward) and success rate (the percentage of successful task completions) over the training process. Despite the increased model size and extensive training, both models exhibit a phenomenon called ’thought collapse’, where their reasoning capabilities degrade over time. The success rate plateaus or even decreases, suggesting that longer training does not mitigate this issue, and the episode return also shows suboptimal performance. This highlights the limitations of relying solely on outcome-based rewards in training LLMs.
read the caption
Figure 2: Thought collapse persists for larger model scales and training budgets. We train LLaVA 7b and 13b models for 30k RL steps but still observe the degraded performance.

🔼 This figure illustrates the Guided Thought Reinforcement (GTR) framework, which enhances the training of Vision-Language Models (VLMs) in reinforcement learning. The core idea is to guide the VLM’s learning process by incorporating automated thought correction. The framework modifies standard RL finetuning by adding a VLM-based corrector (purple). This corrector evaluates the VLM agent’s (orange) thoughts (green) and provides refined thoughts. The GTR framework uses supervised fine-tuning (SFT) to update the agent’s thought tokens and Proximal Policy Optimization (PPO) to update its action tokens, thus simultaneously training both the reasoning process and action selection.
read the caption
Figure 3: Overview of the GTR framework. We modify the RL finetuning (orange region) of VLM agents by introducing automated thought correction (green region) as guidance, leveraging an off-the-shelf VLM model as a corrector (purple region). GTR performs SFT updating for the agent’s thought tokens and PPO updating for its action tokens, thereby training thoughts and actions simultaneously.

🔼 Figure 4 presents a comparison of different process guidance methods within the context of a 24 points card game. The graph displays the success rate and discounted episode return achieved by three different approaches: pure reinforcement learning (RL), using a VLM-as-a-corrector model (GTR), and utilizing a VLM-as-a-judge model. The key takeaway is that simply providing numerical rewards (as in the VLM-as-a-judge and pure RL methods), without explicit guidance on the reasoning process, is insufficient to encourage diverse and effective chain-of-thought reasoning. The GTR method, which incorporates an automated corrector for thought refinement, significantly outperforms the other methods in terms of both success rate and cumulative reward.
read the caption
Figure 4: Comparison among different process guidance methods in the 24 points card game. Trivial numerical rewards provided by the VLM judge and rule-based evaluation cannot incentivize the agent’s reasoning thoughts and higher success rate.

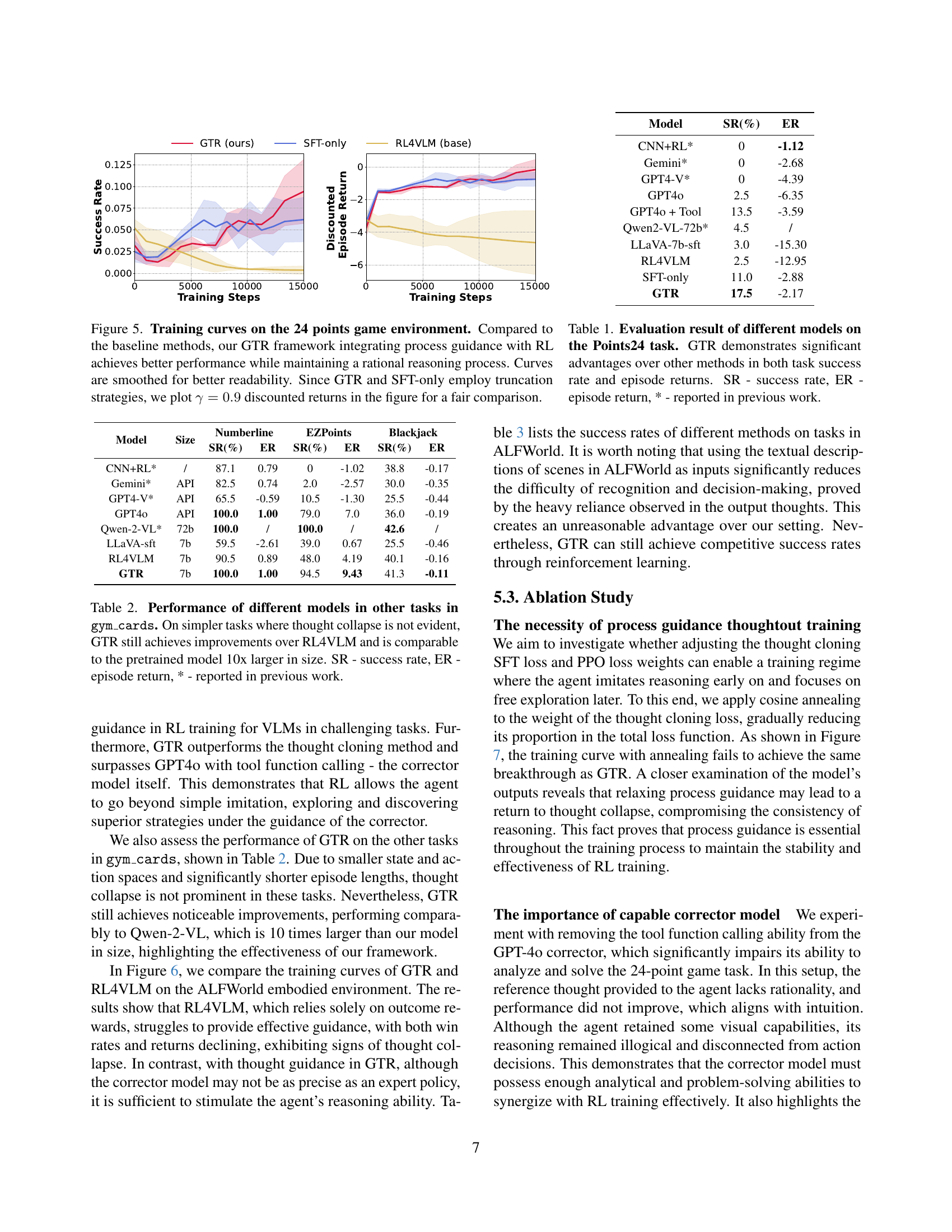
🔼 Figure 5 presents a comparison of training curves for different methods on the 24 Points game. The x-axis represents training steps, and the y-axis shows both success rate and discounted episode return (with a discount factor of 0.9). The plot showcases that the GTR (Guided Thought Reinforcement) framework significantly outperforms baseline methods (pure RL, SFT-only, and RL4VLM), achieving higher success rates and returns. The curves are smoothed for clarity. Importantly, because GTR and SFT-only use truncation strategies (ending episodes early in certain situations), the discounted returns are used for a fairer comparison with methods that do not employ truncation.
read the caption
Figure 5: Training curves on the 24 points game environment. Compared to the baseline methods, our GTR framework integrating process guidance with RL achieves better performance while maintaining a rational reasoning process. Curves are smoothed for better readability. Since GTR and SFT-only employ truncation strategies, we plot γ=0.9𝛾0.9\gamma=0.9italic_γ = 0.9 discounted returns in the figure for a fair comparison.

🔼 Figure 6 presents a bar chart comparing the performance of various models on the Points24 task. The chart displays two key metrics: success rate (SR) and episode return (ER). GTR significantly outperforms other methods such as RL4VLM, Gemini, GPT4-V, and GPT40, achieving a substantially higher success rate and episode return. The asterisk (*) indicates results reported in previous studies, highlighting GTR’s superior performance compared to existing state-of-the-art models.
read the caption
Figure 6: Evaluation result of different models on the Points24 task. GTR demonstrates significant advantages over other methods in both task success rate and episode returns. SR - success rate, ER - episode return, * - reported in previous work.

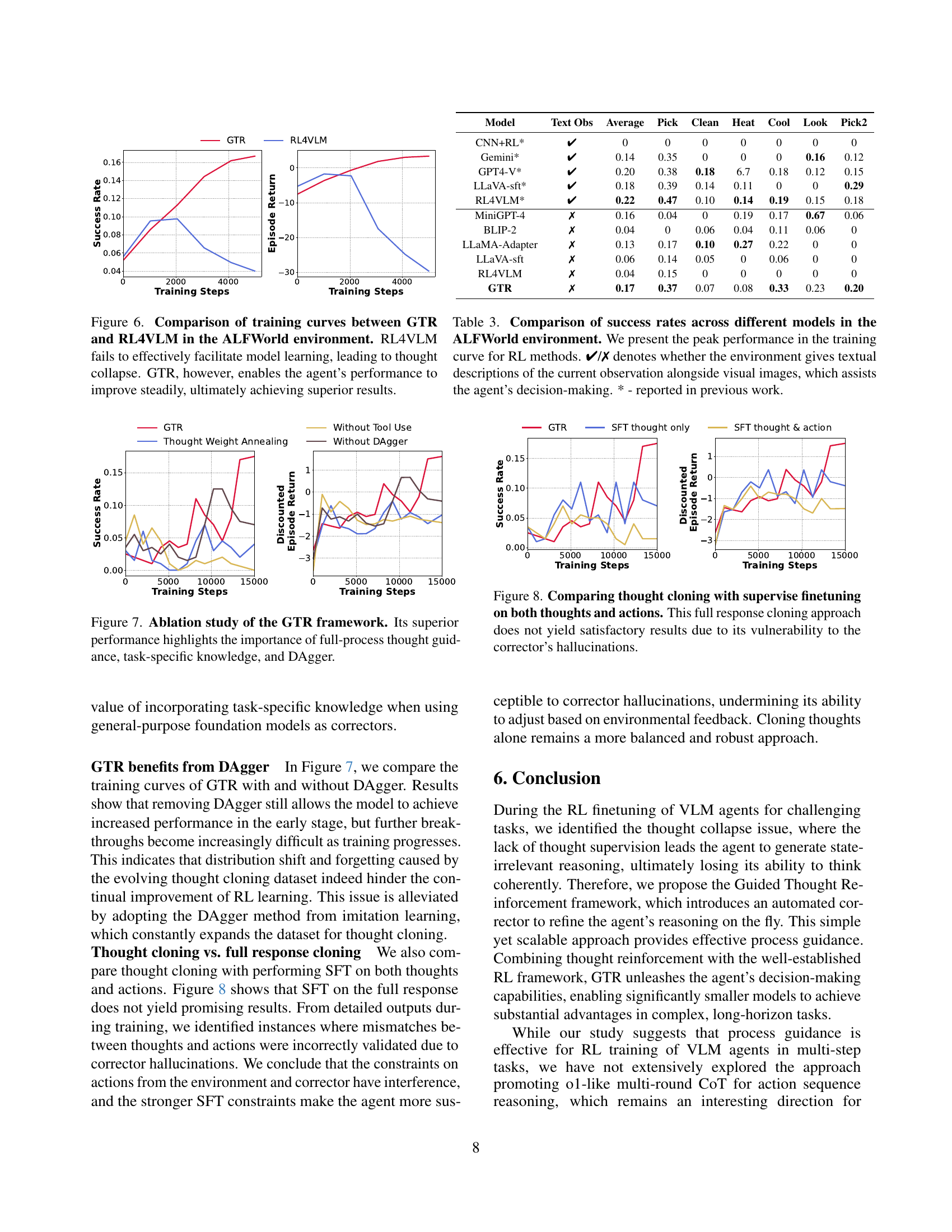
🔼 Figure 7 presents a comparison of the training performance between two reinforcement learning (RL) approaches: GTR (Guided Thought Reinforcement) and RL4VLM, within the ALFWorld environment. The x-axis represents training steps, and the y-axis shows both success rate and discounted episode return. The plots reveal that RL4VLM, lacking process guidance, suffers from ’thought collapse’—a phenomenon where the model’s reasoning becomes erratic and ineffective, resulting in stagnant or declining performance. In contrast, GTR, which incorporates automated thought correction, shows a steady improvement in both success rate and episode return, demonstrating that this approach mitigates thought collapse and enhances model learning. The superior performance of GTR highlights the importance of providing process guidance during RL training for visual language models (VLMs).
read the caption
Figure 7: Comparison of training curves between GTR and RL4VLM in the ALFWorld environment. RL4VLM fails to effectively facilitate model learning, leading to thought collapse. GTR, however, enables the agent’s performance to improve steadily, ultimately achieving superior results.

🔼 This figure compares the success rates of various models on tasks within the ALFWorld environment. The peak performance achieved during training is shown for reinforcement learning (RL) models. The ‘✔/✗’ symbol indicates whether the environment provided both visual images and textual descriptions of the current state; textual descriptions make the task easier. Results from previous research are marked with an asterisk (*).
read the caption
Figure 8: Comparison of success rates across different models in the ALFWorld environment. We present the peak performance in the training curve for RL methods. ✔/✗ denotes whether the environment gives textual descriptions of the current observation alongside visual images, which assists the agent’s decision-making. * - reported in previous work.

🔼 Figure 9 presents an ablation study analyzing the impact of different components within the Guided Thought Reinforcement (GTR) framework. The results demonstrate that all three components—full-process thought guidance, task-specific knowledge, and the DAgger algorithm—are crucial for GTR’s superior performance. Removing any one of them significantly degrades the model’s ability to achieve high success rates and rewards.
read the caption
Figure 9: Ablation study of the GTR framework. Its superior performance highlights the importance of full-process thought guidance, task-specific knowledge, and DAgger.
Full paper#