TL;DR#
Pre-trained language models often exhibit societal biases, which can lead to unfair or inaccurate applications. Existing debiasing strategies, such as retraining or representation projection, can be inefficient or fail to directly alter biased internal representations. Thus, there’s a need for more effective methods to eliminate bias from models while preserving their language capabilities.
To address the issues, this paper introduces BIASEDIT, a model editing method that uses lightweight networks to generate parameter updates, removing stereotypical bias from language models. It employs a debiasing loss to guide edits on partial parameters and a retention loss to maintain language modeling abilities. Experiments demonstrate BIASEDIT’s effectiveness in eliminating bias with minimal impact on general capabilities.
Key Takeaways#
Why does it matter?#
This paper introduces an efficient model editing method to remove stereotypical bias while preserving language modeling abilities. It offers insights into bias associations within language models, guiding future debiasing efforts.
Visual Insights#

🔼 This figure illustrates the BiasEdit model’s debiasing process. A stereotypical sentence, such as ‘Girls tend to be more [soft] than boys,’ is input into a pre-trained language model. BiasEdit uses lightweight editor networks to modify the model’s internal parameters, focusing on specific parts of the model rather than retraining the whole thing. This modification changes the model’s output probability to assign equal likelihood to both the stereotypical phrase and a corresponding anti-stereotypical phrase, such as ‘Girls tend to be more [determined] than boys.’ Importantly, BiasEdit also includes a loss function to maintain the model’s ability to generate grammatically correct and meaningful text, even as the bias is removed. This ensures that removing the bias does not negatively impact the language model’s overall functionality.
read the caption
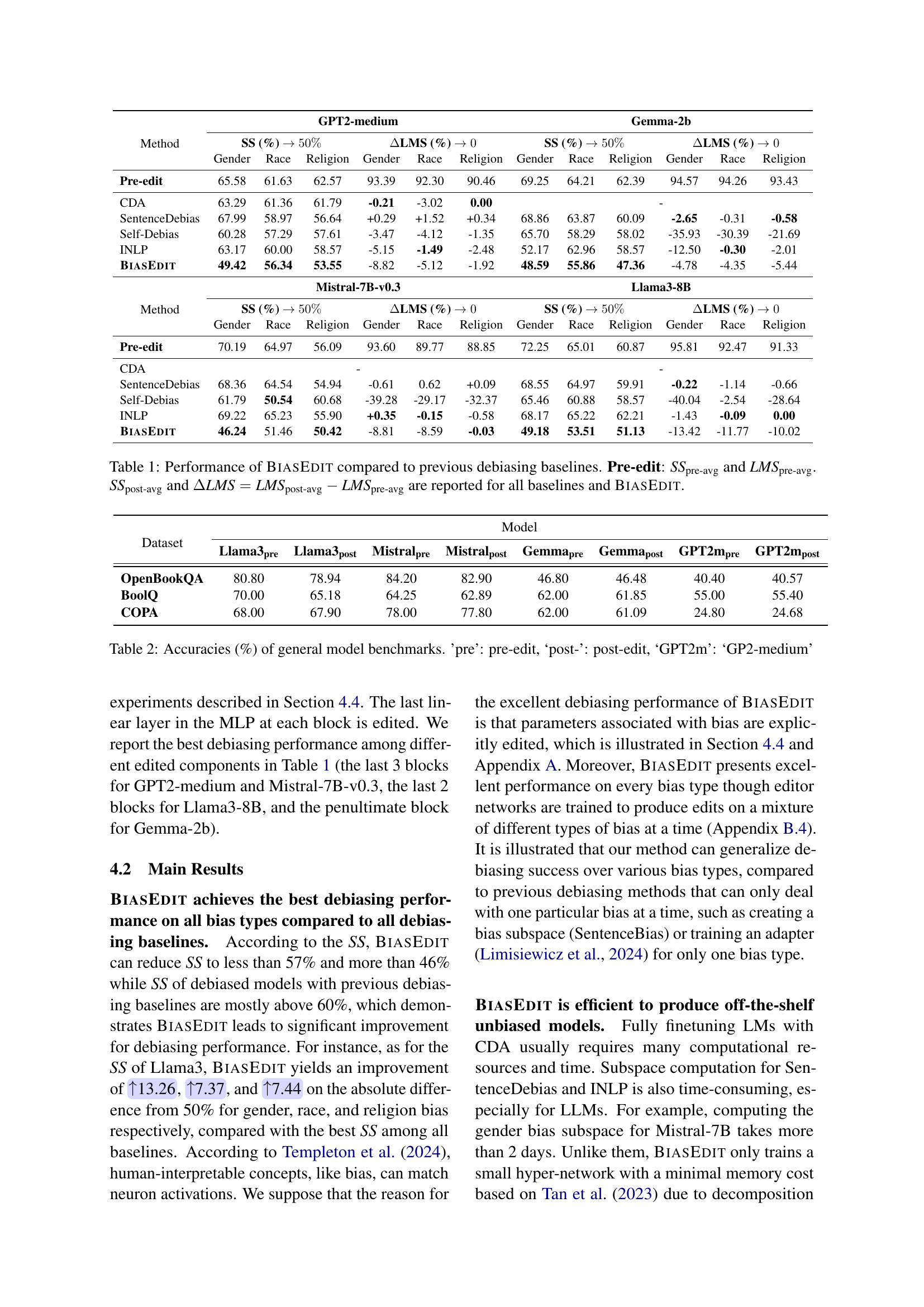
Figure 1: Debiasing a language model with BiasEdit.
| Method | GPT2-medium | Gemma-2b | ||||||||||
| SS (%) | LMS (%) | SS (%) | LMS (%) | |||||||||
| Gender | Race | Religion | Gender | Race | Religion | Gender | Race | Religion | Gender | Race | Religion | |
| Pre-edit | 65.58 | 61.63 | 62.57 | 93.39 | 92.30 | 90.46 | 69.25 | 64.21 | 62.39 | 94.57 | 94.26 | 93.43 |
| CDA | 63.29 | 61.36 | 61.79 | -0.21 | -3.02 | 0.00 | - | |||||
| SentenceDebias | 67.99 | 58.97 | 56.64 | +0.29 | +1.52 | +0.34 | 68.86 | 63.87 | 60.09 | -2.65 | -0.31 | -0.58 |
| Self-Debias | 60.28 | 57.29 | 57.61 | -3.47 | -4.12 | -1.35 | 65.70 | 58.29 | 58.02 | -35.93 | -30.39 | -21.69 |
| INLP | 63.17 | 60.00 | 58.57 | -5.15 | -1.49 | -2.48 | 52.17 | 62.96 | 58.57 | -12.50 | -0.30 | -2.01 |
| BiasEdit | 49.42 | 56.34 | 53.55 | -8.82 | -5.12 | -1.92 | 48.59 | 55.86 | 47.36 | -4.78 | -4.35 | -5.44 |
| Method | Mistral-7B-v0.3 | Llama3-8B | ||||||||||
| SS (%) | LMS (%) | SS (%) | LMS (%) | |||||||||
| Gender | Race | Religion | Gender | Race | Religion | Gender | Race | Religion | Gender | Race | Religion | |
| Pre-edit | 70.19 | 64.97 | 56.09 | 93.60 | 89.77 | 88.85 | 72.25 | 65.01 | 60.87 | 95.81 | 92.47 | 91.33 |
| CDA | - | - | ||||||||||
| SentenceDebias | 68.36 | 64.54 | 54.94 | -0.61 | 0.62 | +0.09 | 68.55 | 64.97 | 59.91 | -0.22 | -1.14 | -0.66 |
| Self-Debias | 61.79 | 50.54 | 60.68 | -39.28 | -29.17 | -32.37 | 65.46 | 60.88 | 58.57 | -40.04 | -2.54 | -28.64 |
| INLP | 69.22 | 65.23 | 55.90 | +0.35 | -0.15 | -0.58 | 68.17 | 65.22 | 62.21 | -1.43 | -0.09 | 0.00 |
| BiasEdit | 46.24 | 51.46 | 50.42 | -8.81 | -8.59 | -0.03 | 49.18 | 53.51 | 51.13 | -13.42 | -11.77 | -10.02 |
🔼 This table presents a comparison of BIASEDIT’s performance against several established debiasing methods. For each method, it shows the average Stereotype Score (SS) before debiasing (Pre-edit), and the average Stereotype Score after debiasing (SSpost-avg). It also includes the change in Language Modeling Score (ΔLMS), which indicates the impact of debiasing on the model’s overall language capabilities. Lower SS values indicate better bias reduction, while a ΔLMS close to 0 suggests minimal effect on the model’s general performance. The results are broken down by bias type (Gender, Race, Religion) and model.
read the caption
Table 1: Performance of BiasEdit compared to previous debiasing baselines. Pre-edit: SSpre-avgsubscriptSSpre-avg\textit{SS}_{\text{pre-avg}}SS start_POSTSUBSCRIPT pre-avg end_POSTSUBSCRIPT and LMSpre-avgsubscriptLMSpre-avg\textit{LMS}_{\text{pre-avg}}LMS start_POSTSUBSCRIPT pre-avg end_POSTSUBSCRIPT. SSpost-avgsubscriptSSpost-avg\textit{SS}_{\text{post-avg}}SS start_POSTSUBSCRIPT post-avg end_POSTSUBSCRIPT and ΔLMS=LMSpost-avg−LMSpre-avgΔLMSsubscriptLMSpost-avgsubscriptLMSpre-avg\Delta\text{{LMS}}=\text{{LMS}}_{\text{post-avg}}-\textit{LMS}_{\text{pre-avg}}roman_Δ LMS = LMS start_POSTSUBSCRIPT post-avg end_POSTSUBSCRIPT - LMS start_POSTSUBSCRIPT pre-avg end_POSTSUBSCRIPT are reported for all baselines and BiasEdit.
In-depth insights#
BiasEdit: Intro#
BIASEDIT, as a model editing approach, directly tackles the issue of stereotypical biases in language models. It introduces lightweight editor networks to refine model parameters and balance the likelihood of stereotypical and anti-stereotypical contexts. By employing a debiasing loss that focuses on local edits and a retention loss to preserve language modeling abilities, BIASEDIT aims for effective bias removal with minimal impact on the model’s general capabilities. This method stands out by modifying model parameters, rather than relying solely on data manipulation or representation projection, potentially leading to more robust and unbiased language models. The approach involves creating symmetric KL divergence to treat stereotyped and anti-stereotyped contexts fairly. This involves editor networks to make parameters shift, thus changing parameters of the language model to reduce bias.
BiasEdit: Method#
BiasEdit focuses on efficiently debiasing language models. It introduces a novel model editing method targeting stereotypical biases. Unlike full fine-tuning, it employs lightweight editor networks to generate parameter updates. A key aspect is the debiasing loss that guides these networks to conduct local edits, specifically targeting parameters associated with bias. Simultaneously, a retention loss preserves general language modeling capabilities, preventing unintended side effects during the bias removal process. This approach facilitates focused and efficient bias mitigation.
BiasEdit: Results#
Considering hypothetical BiasEdit results, one could expect findings related to the method’s effectiveness in mitigating biases across various dimensions like gender, race, and religion in language models. The results might highlight BiasEdit’s superior performance compared to existing debiasing techniques, showcasing reduced stereotype scores while preserving language modeling capabilities. Key results would likely emphasize the trade-off between bias reduction and model accuracy, potentially revealing minimal impact on general NLP tasks. Furthermore, the analysis might include insights into the method’s robustness, examining its performance on counterfactual examples and semantically similar inputs. Additional findings could explore the impact of editing different components of the language model, shedding light on the most effective strategies for debiasing.
BiasEdit: Ablation#
While “BiasEdit: Ablation” isn’t a direct heading, ablation studies in the context of debiasing models are crucial. These studies systematically remove components (retention loss) of the BIASEDIT framework to assess their individual impact on performance (LM abilities). Analyzing changes in stereotype scores and language modeling abilities upon ablation helps pinpoint which parts of the model are most effective at reducing bias, and which might be redundant or even detrimental. Key observations often focus on how removing the retention loss impacts language modeling itself, to evaluate any trade offs for debiasing.
BiasEdit: Robust#
BiasEdit’s robustness is crucial for real-world applications. A robust BiasEdit would consistently mitigate biases across different datasets and model architectures. Generalization across diverse demographic groups (gender, race, religion) is also key. Evaluation should include measuring bias reduction and minimal impact on model accuracy. It will be a good sign for a robust method if performance holds even with semantic variations or adversarial attacks on input data. Furthermore, robustness to hyperparameter tuning and different training conditions is important.
More visual insights#
More on figures

🔼 The figure illustrates the BiasEdit model, which uses lightweight editor networks to debias a language model. The editor networks generate parameter updates that specifically target stereotypical biases while preserving the model’s overall language modeling capabilities. This is achieved using two loss functions: a debiasing loss (Ld) which guides the networks to remove the bias by equalizing probabilities of stereotypical and anti-stereotypical contexts, and a retention loss (Lr) to ensure that unrelated associations are maintained. The figure shows that after editing, the model is debiased, and this debiasing effect is robust to gender reversal and semantic generality tests. The labels s, a, and m represent stereotyped, anti-stereotyped, and meaningless contexts respectively.
read the caption
Figure 2: Debiasing a language model with BiasEdit. Editor networks ϕitalic-ϕ\phiitalic_ϕ are trained to produce edit shifts on partial parameters 𝒲𝒲\mathcal{W}caligraphic_W of a language model while its parameters θ𝜃\thetaitalic_θ are frozen . After editing, an unbiased LM is obtained with the robustness of gender reversal and semantic generality. ℒdsubscriptℒ𝑑\mathcal{L}_{d}caligraphic_L start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT and ℒrsubscriptℒ𝑟\mathcal{L}_{r}caligraphic_L start_POSTSUBSCRIPT italic_r end_POSTSUBSCRIPT refer to Equation 1 and 2 respectively. s: stereotyped. a: anti-stereotyped. m: meaningless.

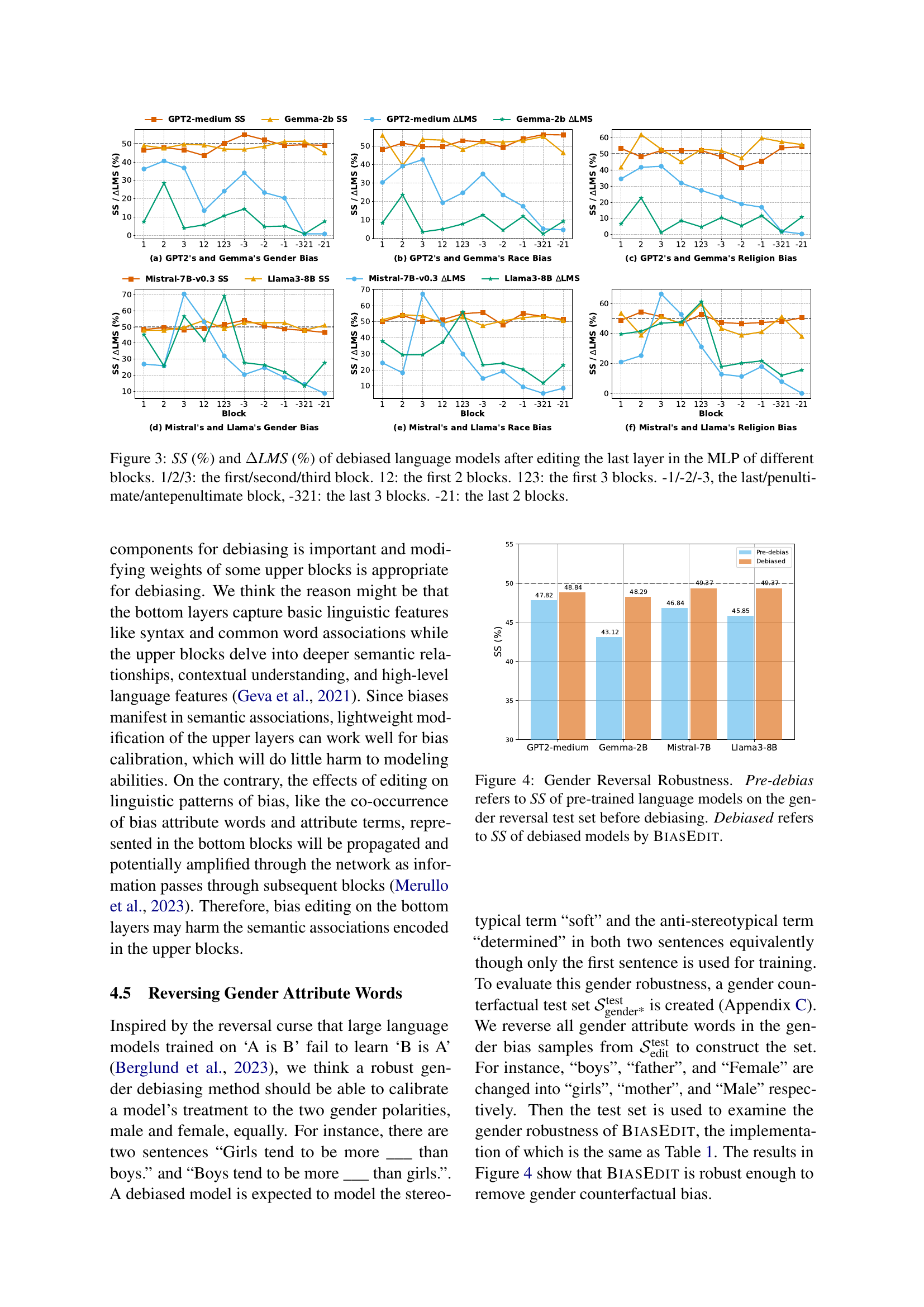
🔼 This figure displays the Stereotype Score (SS) and the change in Language Modeling Score (ΔLMS) after applying bias editing to different layers of four distinct language models. The x-axis represents various combinations of blocks within the language model that were modified. ‘1’, ‘2’, and ‘3’ indicate edits to the first, second, and third blocks respectively. ‘12’ signifies edits to the first two blocks, and ‘123’ shows edits to the first three blocks. Negative numbers (-1, -2, -3) denote edits to the last, second-to-last, and third-to-last blocks respectively. ‘−21’ indicates edits to the last two blocks, and ‘−321’ represents edits to the last three blocks. The y-axis shows the SS and ΔLMS for each model, revealing the impact of the bias editing on both bias mitigation and overall language modeling capability.
read the caption
Figure 3: SS (%) and ΔΔ\Deltaroman_ΔLMS (%) of debiased language models after editing the last layer in the MLP of different blocks. 1/2/3: the first/second/third block. 12: the first 2 blocks. 123: the first 3 blocks. -1/-2/-3, the last/penultimate/antepenultimate block, -321: the last 3 blocks. -21: the last 2 blocks.

🔼 This figure demonstrates the robustness of the BiasEdit model to gender reversal. It displays the Stereotype Score (SS) for four different language models before debiasing (Pre-debias) and after debiasing with BiasEdit (Debiased). The gender reversal test set was created by reversing the gender terms in the original StereotypeSet dataset. A lower SS indicates less bias. The figure visually shows the impact of BiasEdit on reducing gender bias, even when presented with reversed gender terms, indicating that the model learns a more nuanced and equitable representation of gender.
read the caption
Figure 4: Gender Reversal Robustness. Pre-debias refers to SS of pre-trained language models on the gender reversal test set before debiasing. Debiased refers to SS of debiased models by BiasEdit.

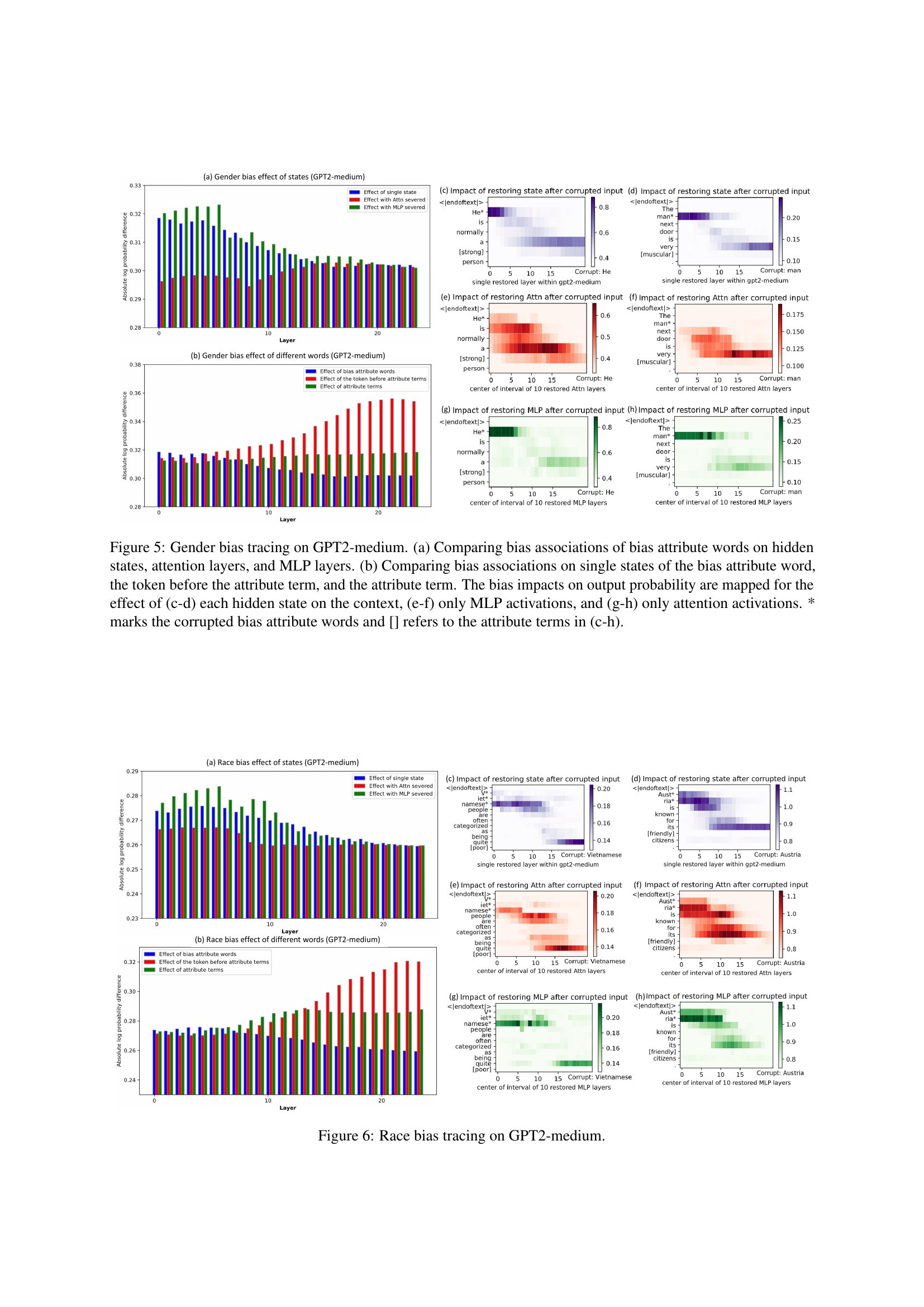
🔼 Figure 5 presents a detailed analysis of gender bias in the GPT2-medium language model using bias tracing. Panel (a) compares the strength of bias associations across different layers of the model (hidden states, attention, and MLP layers). Panel (b) shows how bias associations vary depending on which specific words within the sentence are examined: the bias attribute word itself, the word preceding it, and the attribute term. Panels (c-h) further investigate the impact of these bias associations on the model’s output probabilities. This is done by selectively corrupting (adding noise to) the embeddings of bias-related words and then restoring different parts of the model’s internal activations (hidden states, attention, or MLP layers only). By comparing the changes in output probabilities before and after these manipulations, the figure illustrates how different parts of the model contribute to the overall gender bias.
read the caption
Figure 5: Gender bias tracing on GPT2-medium. (a) Comparing bias associations of bias attribute words on hidden states, attention layers, and MLP layers. (b) Comparing bias associations on single states of the bias attribute word, the token before the attribute term, and the attribute term. The bias impacts on output probability are mapped for the effect of (c-d) each hidden state on the context, (e-f) only MLP activations, and (g-h) only attention activations. * marks the corrupted bias attribute words and [] refers to the attribute terms in (c-h).

🔼 This figure presents the results of a bias tracing analysis performed on the GPT-2-medium language model, focusing on racial bias. It visualizes the association between bias and different components of the model’s architecture (hidden states, attention, and MLP layers) across various layers. The plots likely show how the model’s representation of race changes throughout the processing stages and how manipulating specific states within the model impacts the overall bias in its output. The subplots might show the effect of different interventions, such as removing or restoring specific activations.
read the caption
Figure 6: Race bias tracing on GPT2-medium.
More on tables
| Dataset | Model | |||||||
| OpenBookQA | 80.80 | 78.94 | 84.20 | 82.90 | 46.80 | 46.48 | 40.40 | 40.57 |
| BoolQ | 70.00 | 65.18 | 64.25 | 62.89 | 62.00 | 61.85 | 55.00 | 55.40 |
| COPA | 68.00 | 67.90 | 78.00 | 77.80 | 62.00 | 61.09 | 24.80 | 24.68 |
🔼 This table presents the performance of different language models (LLMs) on a set of general benchmark tasks, both before and after bias mitigation. The metrics used are accuracies (in percentage). The models tested include Llama3, Mistral, Gemma, and GPT2-medium. The pre-edit and post-edit accuracies showcase the impact of the debiasing technique on the models’ general performance. The goal is to determine if bias editing affects the models’ ability to perform standard language understanding tasks.
read the caption
Table 2: Accuracies (%) of general model benchmarks. ’pre’: pre-edit, ‘post-’: post-edit, ‘GPT2m’: ‘GP2-medium’
| Method | GPT2-medium | |||||
| SS (%) | LMS (%) | |||||
| gender | race | religion | gender | race | religion | |
| w/o | 52.55 | 56.45 | 45.73 | -52.36 | -59.96 | -61.54 |
| w | 49.42 | 56.34 | 53.55 | -8.82 | -5.12 | -1.92 |
| Method | Gemma-2b | |||||
| SS (%) | LMS (%) | |||||
| gender | race | religion | gender | race | religion | |
| w/o | 50.81 | 52.05 | 41.17 | -29.31 | -27.93 | -62.29 |
| w | 48.59 | 52.25 | 47.36 | -4.78 | -4.35 | -5.44 |
🔼 This table compares the performance of BIASEDIT with and without the retention loss (ℒr). It shows the Stereotype Score (SS) and the change in Language Modeling Score (△LMS) for gender, race, and religion bias on GPT2-medium and Gemma-2b language models. The retention loss is designed to prevent negative impacts on the language modeling capabilities of the model during the debiasing process. By comparing the results with and without this loss, the table highlights its effectiveness in preserving the model’s overall performance while reducing bias.
read the caption
Table 3: BiasEdit w and w/o the retention loss ℒrsubscriptℒ𝑟\mathcal{L}_{r}caligraphic_L start_POSTSUBSCRIPT italic_r end_POSTSUBSCRIPT.
| Model / SS (%) | Pre-debias | BiasEdit | ||||
| Gender | Race | Religion | Gender | Race | Religion | |
| GPT2-medium | 52.53 | 53.71 | 64.30 | 52.53 | 48.53 | 55.82 |
| Gemma-2B | 51.79 | 54.39 | 58.89 | 51.84 | 50.29 | 54.76 |
| Mistral-7B-v0.3 | 48.20 | 52.92 | 53.54 | 58.17 | 49.46 | 58.17 |
| Llama3-8B | 45.37 | 58.79 | 58.17 | 49.19 | 53.51 | 51.14 |
🔼 This table presents the Stereotype Score (SS) on a synonym-augmented test set. The synonym-augmented test set replaces attribute terms in the original StereoSet test set with their synonyms. This assesses the robustness and generalizability of the BIASEDIT debiasing method by evaluating its performance on semantically similar, but not identically worded, instances of bias.
read the caption
Table 4: SS (%) on the synonym-augmented test set.
| # Gender | # Race | # Religion | |
| 617 | 2,307 | 210 | |
| 70 | 297 | 25 | |
| 253 | 962 | 77 |
🔼 This table presents the distribution of samples across different bias categories (gender, race, and religion) within the StereoSet dataset used in the study. It shows the number of samples used for training (Strain), development (Sdev), and testing (Stest) sets for each bias type.
read the caption
Table 5: The numbers of samples about different bias in our dataset.
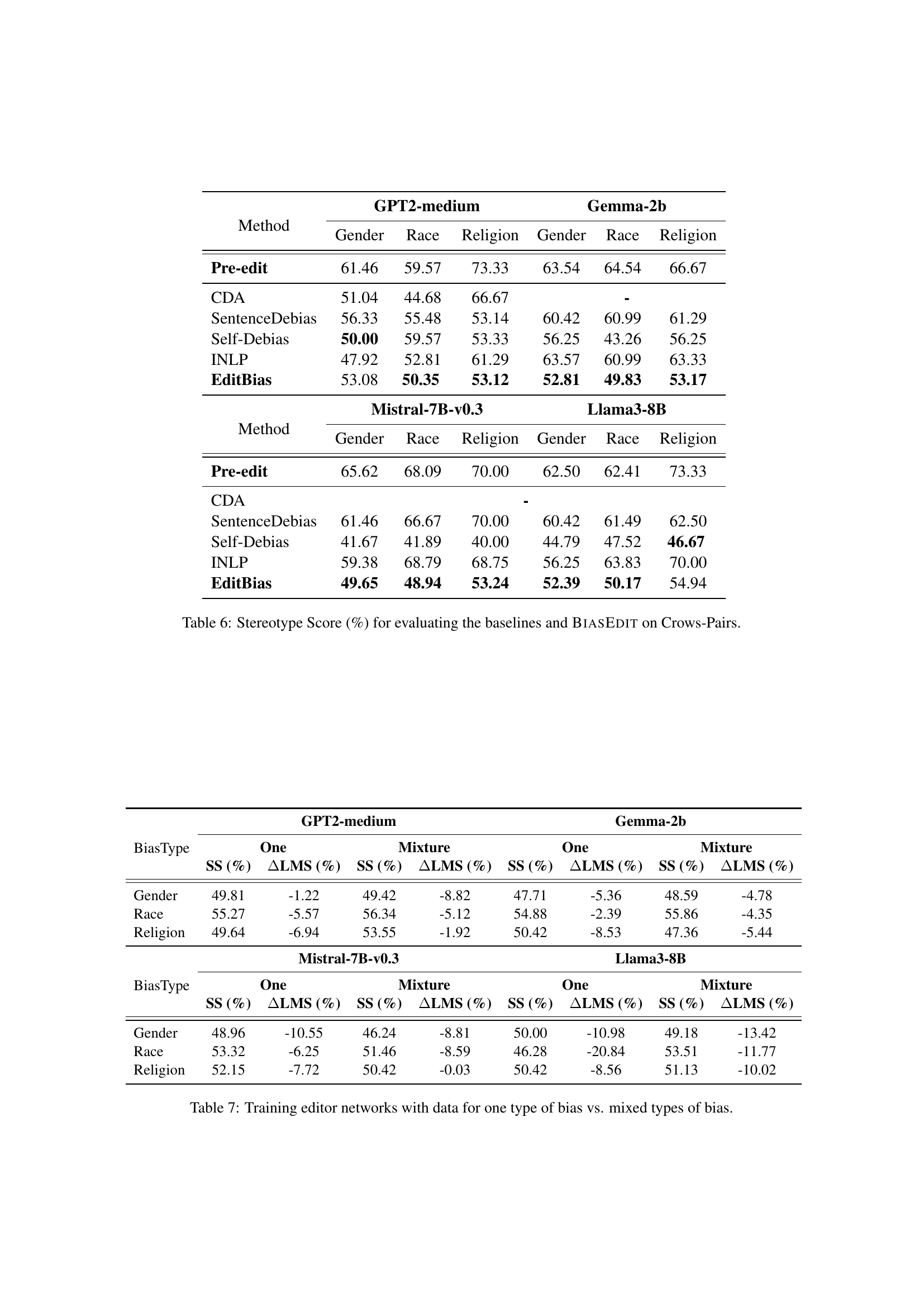
| Method | GPT2-medium | Gemma-2b | ||||
| Gender | Race | Religion | Gender | Race | Religion | |
| Pre-edit | 61.46 | 59.57 | 73.33 | 63.54 | 64.54 | 66.67 |
| CDA | 51.04 | 44.68 | 66.67 | - | ||
| SentenceDebias | 56.33 | 55.48 | 53.14 | 60.42 | 60.99 | 61.29 |
| Self-Debias | 50.00 | 59.57 | 53.33 | 56.25 | 43.26 | 56.25 |
| INLP | 47.92 | 52.81 | 61.29 | 63.57 | 60.99 | 63.33 |
| EditBias | 53.08 | 50.35 | 53.12 | 52.81 | 49.83 | 53.17 |
| Method | Mistral-7B-v0.3 | Llama3-8B | ||||
| Gender | Race | Religion | Gender | Race | Religion | |
| Pre-edit | 65.62 | 68.09 | 70.00 | 62.50 | 62.41 | 73.33 |
| CDA | - | |||||
| SentenceDebias | 61.46 | 66.67 | 70.00 | 60.42 | 61.49 | 62.50 |
| Self-Debias | 41.67 | 41.89 | 40.00 | 44.79 | 47.52 | 46.67 |
| INLP | 59.38 | 68.79 | 68.75 | 56.25 | 63.83 | 70.00 |
| EditBias | 49.65 | 48.94 | 53.24 | 52.39 | 50.17 | 54.94 |
🔼 This table presents the results of evaluating different bias mitigation methods on the Crowds-Pairs dataset. It shows the Stereotype Score (SS), a metric representing the percentage of times a model prefers stereotypical contexts over anti-stereotypical ones. Lower scores indicate less bias. The table compares the performance of four established baselines (CDA, SentenceDebias, Self-Debias, INLP) against the proposed method, BiasEdit, across three bias types (gender, race, religion) and four language models (GPT2-medium, Gemma-2b, Mistral-7B-v0.3, Llama3-8B). Pre-edit scores represent the bias levels before any mitigation.
read the caption
Table 6: Stereotype Score (%) for evaluating the baselines and BiasEdit on Crows-Pairs.
| Bias Type | GPT2-medium | Gemma-2b | ||||||
| One | Mixture | One | Mixture | |||||
| SS (%) | LMS (%) | SS (%) | LMS (%) | SS (%) | LMS (%) | SS (%) | LMS (%) | |
| Gender | 49.81 | -1.22 | 49.42 | -8.82 | 47.71 | -5.36 | 48.59 | -4.78 |
| Race | 55.27 | -5.57 | 56.34 | -5.12 | 54.88 | -2.39 | 55.86 | -4.35 |
| Religion | 49.64 | -6.94 | 53.55 | -1.92 | 50.42 | -8.53 | 47.36 | -5.44 |
| Bias Type | Mistral-7B-v0.3 | Llama3-8B | ||||||
| One | Mixture | One | Mixture | |||||
| SS (%) | LMS (%) | SS (%) | LMS (%) | SS (%) | LMS (%) | SS (%) | LMS (%) | |
| Gender | 48.96 | -10.55 | 46.24 | -8.81 | 50.00 | -10.98 | 49.18 | -13.42 |
| Race | 53.32 | -6.25 | 51.46 | -8.59 | 46.28 | -20.84 | 53.51 | -11.77 |
| Religion | 52.15 | -7.72 | 50.42 | -0.03 | 50.42 | -8.56 | 51.13 | -10.02 |
🔼 This table presents the results of training bias editor networks using two different approaches: one using data for a single bias type (gender, race, or religion) and another using a mixture of all three bias types. The table shows the stereotype score (SS) and the change in language modeling score (△LMS) for each model (GPT2-medium, Gemma-2b, Mistral-7B-v0.3, and Llama3-8B) and bias type, comparing the performance of the two training methods. Lower SS values indicate better debiasing performance, and △LMS close to 0 indicates minimal impact on the language modeling ability.
read the caption
Table 7: Training editor networks with data for one type of bias vs. mixed types of bias.
Full paper#