TL;DR#
Text-to-video (T2V) diffusion models can generate high-quality short videos, but producing real-world long videos remains a challenge due to limited data and high costs. Existing tuning-free methods use multiple prompts for dynamic content changes, but struggle with content drift and semantic coherence. Thus, the paper aims to solve the issues of maintaining a global structure and addressing error accumulation, which existing methods suffer from.
To address these issues, the paper introduces Synchronized Coupled Sampling (SynCoS), a tuning-free inference framework that synchronizes denoising paths across the entire video. SynCoS combines reverse and optimization-based sampling to ensure seamless local transitions and global coherence. Key innovations include a grounded timestep, fixed baseline noise, and structured prompts. This approach leads to smoother transitions, superior long-range coherence, and improved performance.
Key Takeaways#
Why does it matter?#
This paper introduces SynCoS, a novel tuning-free framework, that enhances the quality of generated videos. This is particularly valuable as it offers a practical solution for overcoming the constraints of existing T2V models. The work contributes to enhanced content generation and consistency with less manual tuning.
Visual Insights#

🔼 This figure showcases examples of long-form video generation (approximately 21 seconds at 24 frames per second) produced using the SynCoS model. Each video demonstrates multiple events unfolding within a single, coherent narrative. SynCoS is highlighted for its ability to generate high-quality, temporally consistent videos with seamless transitions between events, maintaining consistent visual style and semantic meaning throughout the entire sequence. The frame index is shown on each frame.
read the caption
Figure 1: Multi-event long video generation results using our tuning-free inference framework, SynCoS. Each example is around 21 seconds of video at 24 fps (4×\times× longer than the base model ). Frame indices are displayed in each frame. SynCoS generates high-quality, long videos with multi-event dynamics while achieving both seamless transitions between frames and long-term semantic consistency throughout.
| Temporal Quality | Frame-wise Quality | Semantics | ||||||||
| Subject | Background | Motion | Dynamic | Num | Aesthetic | Imaging | Glb Prompt | Loc Prompt | ||
| Backbone | Method | Consistency | Consistency | Smoothness | Degree | Scenes | Quality | Quality | Fidelity | Fidelity |
| CogVideoX [55] | Gen-L-Video [50] | 81.34% | 89.46% | 98.32% | 50.00% | 2.292 | 60.09% | 58.52% | 0.324 | 0.351 |
| FIFO-Diffusion [21] | 83.54% | 90.72% | 98.04% | 70.83% | 1.938 | 59.59% | 63.18% | 0.323 | 0.327 | |
| SynCoS (Ours) | 88.92% | 94.57% | 98.21% | 85.42% | 1.208 | 63.37% | 67.43% | 0.341 | 0.354 | |
| Open-Sora Plan [23] | Gen-L-Video [50] | 85.15% | 92.63% | 98.93% | 43.75% | 2.458 | 61.44% | 57.19% | 0.319 | 0.337 |
| FIFO-Diffusion [21] | 89.14% | 94.34% | 98.19% | 27.08% | 1.125 | 60.26% | 61.23% | 0.327 | 0.331 | |
| SynCoS (Ours) | 90.19% | 94.78% | 99.06% | 58.33% | 1.646 | 63.79% | 60.19% | 0.328 | 0.345 | |
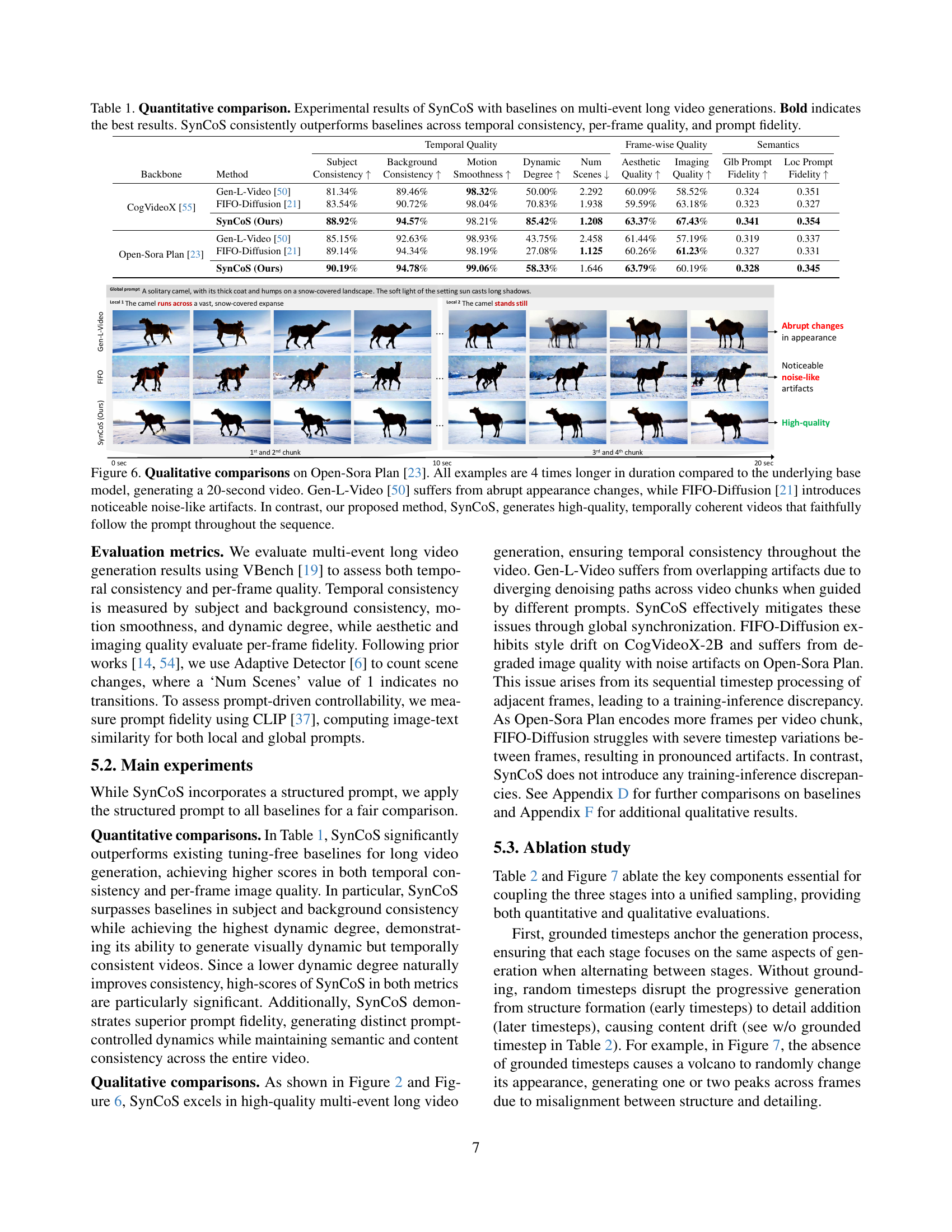
🔼 This table presents a quantitative comparison of the SynCoS model against several baseline models for generating multi-event long videos. The metrics used evaluate both temporal consistency (how well the video maintains a coherent narrative over time) and per-frame quality (how good each individual frame looks). The metrics assessing temporal consistency include subject and background consistency, motion smoothness, and dynamic degree. Per-frame quality is measured by the aesthetic quality, image quality, and semantic consistency of each frame. Prompt fidelity, measured by how well the generated video matches the given prompts, is also assessed. The results show that SynCoS consistently outperforms the baselines across all these metrics, indicating its superiority in generating high-quality, temporally coherent long videos.
read the caption
Table 1: Quantitative comparison. Experimental results of SynCoS with baselines on multi-event long video generations. Bold indicates the best results. SynCoS consistently outperforms baselines across temporal consistency, per-frame quality, and prompt fidelity.
In-depth insights#
SynCoS Overview#
SynCoS, or Synchronized Coupled Sampling, presents a tuning-free inference framework for multi-event long video generation. It tackles the challenge of maintaining both local smoothness and global coherence in extended video sequences by synchronizing denoising paths across the entire video. The process has three stages: DDIM-based temporal co-denoising, which ensures smooth transitions between adjacent frames; refinement via CSD-based optimization, which enforces long-range consistency; and reversion to the previous timestep. SynCoS mitigates content and style drift while preserving semantic consistency. The synchronization mechanism relies on a grounded timestep and a fixed baseline noise to align denoising trajectories. This approach, coupled with a structured prompt, allows SynCoS to generate temporally consistent and high-fidelity videos without additional training.
Multi-Event Coherence#
Multi-event coherence in video generation signifies maintaining semantic consistency across extended durations with evolving dynamics. Challenges arise from content drift and ensuring seamless transitions between diverse events. Existing methods often prioritize local smoothness, sacrificing long-range consistency. Synchronizing denoising paths emerges as a crucial approach to tackle this issue, aligning information across frames. Coupling reverse and optimization-based sampling allows for both smooth local transitions and global coherence. Key to this approach is grounded timesteps and fixed baseline noise, which ensures fully coupled sampling, leading to improved video quality. Effectively handling evolving content while retaining a global narrative is vital for achieving realistic and coherent long videos.
Grounded Timesteps#
The paper introduces a novel approach called “Grounded Timesteps”, which addresses the critical issue of timestep inconsistency across different stages of the video generation process. When applying diffusion models, the structure needs to be kept. The timestep is the guide, but when stages operate on different temporal references, the generative trajectories become misaligned. SynCoS anchors the second-stage timestep to the first-stage sampling schedule. Since it uses the DDIM timesteps, the timestep progresses from t=1000 to t=0, following designated sampling steps. By this, it ensures that all stages operate within a unified temporal reference. It can establish a coherent structure and later focus on finer details throughout denoising.
Structured Prompts#
The research paper employs structured prompts to enhance the coherence and controllability of generated long videos. These prompts consist of a global description to maintain overall consistency and local specifications to introduce variations in each chunk. This approach aims to balance the desire for fine-grained control of content dynamics in specific segments with the need to preserve semantic coherence and stylistic uniformity across longer sequences. Structured prompting, as a technique, offers a way to guide the generation process more effectively, reducing inconsistencies and improving the overall quality and plausibility of the synthesized video content, by mitigating issues such as object drift and semantic incoherence, commonly seen in long video synthesis. The use of LLMs to assist with prompt construction indicates an attempt to automate and streamline the creation of effective prompts.
Architecture Agnostic#
The term “architecture-agnostic” in the context of video generation models emphasizes the flexibility and adaptability of a method across different underlying neural network structures. Unlike methods tightly coupled to specific architectures like U-Nets or Diffusion Transformers, an architecture-agnostic approach can be implemented on various models, ensuring broader applicability and easier integration with future architectural advancements. This is valuable because it allows the method to benefit from improvements in the base models without requiring retraining or significant modifications. The SynCoS method uses this framework by leveraging certain modules. For example, SynCoS is compatible with any T2V diffusion model, supporting various diffusion objectives (v-prediction, e-prediction). In addition, unlike prior works restricted to U-Net or DiT, SynCoS remains flexible across architectures. This allows improvements in temporal consistency and video quality across diverse diffusion backbones. This adaptability can be particularly advantageous in the rapidly evolving field of AI, where new architectures and training paradigms frequently emerge. Therefore, architecture-agnostic methods are more likely to remain relevant and effective over time.
More visual insights#
More on figures

🔼 Figure 2 presents a qualitative comparison of SynCoS with other methods on the CogVideoX-2B model. The generated videos are five times longer (30 seconds) than those produced by the base model. The comparison highlights SynCoS’s ability to maintain consistent content and style throughout the video, unlike other methods that experience overlapping artifacts or style drift. SynCoS also faithfully follows each frame’s designated prompt and creates seamless transitions between frames.
read the caption
Figure 2: Qualitative comparisons on CogVideoX-2B [55]. All examples are 5 times longer in duration compared to the underlying base model, generating a 30-second video. Unlike Gen-L-Video [50] and FIFO-Diffusion [21], which often struggle with overlapping artifacts and style drift, our method, SynCoS, ensures consistency in both content and style throughout the entire video. Additionally, SynCoS generates long videos where each frame faithfully follows its designated prompt while ensuring seamless transitions between frames.

🔼 This figure visualizes the feature trajectories of video frames generated by different sampling methods (Gen-L-Video, CSD, and SynCoS) using t-SNE. Each point represents a frame’s CLIP features at a specific timestep during the denoising process. Color intensity indicates the timestep, with faded colors representing earlier timesteps (near the beginning of the denoising process, t≈1000) and vivid colors representing later timesteps (near the end of the process, t≈0). The visualization helps to show how the feature trajectories evolve over time and how the different sampling methods affect the consistency and coherence of the generated video. Specifically, it demonstrates the divergence of Gen-L-Video’s trajectories, the collapse of CSD’s trajectories, and the consistent and coherent trajectories of SynCoS.
read the caption
Figure 3: t-SNE visualization of CLIP [37] features for the predicted video frames 𝐱^0|tsubscript^𝐱conditional0𝑡\hat{\mathbf{x}}_{0|t}over^ start_ARG bold_x end_ARG start_POSTSUBSCRIPT 0 | italic_t end_POSTSUBSCRIPT, at each timestep using different samplings. Faded colors indicate earlier timesteps (t≈1000𝑡1000t\approx 1000italic_t ≈ 1000), while vivid colors indicate later, small timesteps (t≈0𝑡0t\approx 0italic_t ≈ 0), illustrating feature trajectory evolution over time (top to bottom).

🔼 Figure 4 presents a qualitative comparison of three different long video generation sampling methods: Gen-L-Video, CSD, and the proposed SynCoS method. Gen-L-Video struggles to maintain global consistency in the video, resulting in jarring transitions and sudden shifts in appearance, such as a man unexpectedly transforming into a woman. CSD, while preserving the general appearance of the subject, exhibits a failure to properly adhere to the detailed instructions (local prompts) provided, leading to low quality video frames plagued with significant noise and artifacts. In contrast, SynCoS demonstrates a superior balance between maintaining overall consistency and accuracy of the local prompts. It produces high-quality, coherent video with excellent fidelity to the intended content and smooth transitions.
read the caption
Figure 4: Qualitative comparison of sampling methods motivating SynCoS. Gen-L-Video [50] fails to maintain global coherence, resulting in abrupt appearance changes (e.g., a man morphing into a woman). CSD [22] retains a similar appearance of a man but shows poor adherence to local prompts, suffering from low frame quality with severe noise-like artifacts. In contrast, our method achieves a balance, ensuring high-quality generation, strong prompt fidelity, and temporal coherence.

🔼 This figure illustrates the SynCoS method, a three-stage iterative process for generating long, multi-event videos. Stage 1 uses DDIM for local temporal coherence by dividing the video into chunks, denoising each, and fusing them. Stage 2 refines the result globally, ensuring consistency across all video chunks (both nearby and distant ones). Stage 3 reverts the refined result to the previous timestep, improving accuracy. The combination of these three stages produces smooth transitions, maintains long-term coherence, and achieves high fidelity to the prompts, enabling high-quality, multi-event long videos.
read the caption
Figure 5: Overall illustration of our proposed method, Synchronized Coupled Sampling (SynCoS), a tuning-free inference framework for multi-event long video generation. SynCoS performs one-step denoising in three iterative stages, repeated from t=1000𝑡1000t=1000italic_t = 1000 to t=0𝑡0t=0italic_t = 0. In the first stage, SynCoS performs temporal co-denoising with DDIM, dividing the long video into overlapping short chunks, denoising each chunk, and applying fusion for local smoothness. In the second stage, SynCoS refines the locally fused output, enforcing global coherence by synchronizing information across both short- and long-distance chunks. Finally, in the third stage, it reverts the locally and globally refined output to the previous timestep. Through these three synchronized stages of local and global denoising, SynCoS ensures smooth transitions, global semantic coherence, and high prompt fidelity, enabling multi-event long video generation.

🔼 Figure 6 presents a qualitative comparison of long video generation results using three different methods: Gen-L-Video, FIFO-Diffusion, and the authors’ proposed SynCoS approach. All videos are four times longer than those generated by the base Open-Sora Plan model, resulting in 20-second videos. The figure visually demonstrates that Gen-L-Video suffers from abrupt and jarring appearance changes within the video, lacking temporal coherence. FIFO-Diffusion, while maintaining some consistency, introduces noticeable noise-like artifacts, degrading the visual quality. In contrast, SynCoS produces high-quality videos with smooth transitions and consistent visual style that accurately reflect the input prompt from beginning to end.
read the caption
Figure 6: Qualitative comparisons on Open-Sora Plan [23]. All examples are 4 times longer in duration compared to the underlying base model, generating a 20-second video. Gen-L-Video [50] suffers from abrupt appearance changes, while FIFO-Diffusion [21] introduces noticeable noise-like artifacts. In contrast, our proposed method, SynCoS, generates high-quality, temporally coherent videos that faithfully follow the prompt throughout the sequence.

🔼 Figure 7 presents an ablation study on the SynCoS model, demonstrating the importance of two key components: grounded timesteps and fixed baseline noise. The top row shows results where the grounded timestep is absent. This leads to inconsistencies in the generated video’s structure, such as a volcano that inconsistently changes between having one and two peaks across frames. This demonstrates that the grounded timestep is crucial for maintaining a consistent temporal reference throughout the video generation process. The bottom row shows results with the fixed baseline noise removed. This results in a failure to adhere to local prompts. For instance, the video may not show the expected volcanic eruption or any smoke, showing that the fixed baseline noise is essential for ensuring the model faithfully follows the prompt’s specifications across all stages of the video generation process.
read the caption
Figure 7: Qualitative ablation study. Without a grounded timestep, structural inconsistencies arise (e.g., the volcano alternates between one and two peaks). Without a fixed baseline noise, it fails to follow local prompts faithfully (e.g., missing eruptions or absent smoke).

🔼 Figure 8 illustrates the process of generating structured prompts for long video generation. A scenario (a long description of an event) is provided by the user, along with the desired number of short prompts. The figure details the steps involved in converting this long scenario into multiple short, action-focused prompts and a single global prompt. The global prompt encompasses the overall scene description and shared properties, while the local prompts each focus on a specific action, creating a structured input for the video generation model to improve coherence and consistency.
read the caption
Figure 8: Instruction for generating structured prompt. This instruction follows the guidelines to create individual local prompts and a shared global prompt based on a scenario and the number of prompts the user gives.

🔼 Figure 9 shows the results of an ablation study on the three stages of the SynCoS model. The ablation study systematically removes one stage at a time to understand its contribution to the overall performance. The images in the figure visually demonstrate the impact of removing each stage on the generated video quality. Specifically, removing the first stage (local temporal co-denoising with DDIM) leads to inconsistent transitions; removing the second stage (global temporal co-denoising with CSD) results in a loss of global coherence, causing a blurry and unstable video; and removing the third stage (DDIM-based temporal co-denoising) produces unnatural transitions. The examples in the second box are all three times longer than videos generated by the base model, which further highlights the crucial role of all three stages in successful long video generation.
read the caption
Figure 9: Qualitative visualization of the ablation study on the three coupled stages of SynCoS. All examples in the second box are 3 times longer in duration compared to the underlying base model.
More on tables
| Temporal | Frame | Semantics | ||
| SC | BC | AQ | PF | |
| SynCoS | 0.864 | 0.927 | 0.643 | 0.381 |
| SynCoS w/o | 0.724 | 0.854 | 0.632 | 0.373 |
| SynCoS w/o grounded timestep | 0.803 | 0.899 | 0.638 | 0.364 |
| SynCoS w/o fixed baseline noise | 0.817 | 0.904 | 0.643 | 0.382 |
| SynCoS w/o structured prompt | 0.837 | 0.903 | 0.663 | 0.362 |
🔼 This table presents a quantitative analysis of the ablation study conducted on the SynCoS model. It shows the impact of removing each of the three coupled stages (temporal co-denoising with DDIM, refinement with CSD, and resuming temporal co-denoising) on the overall performance. The metrics used are Subject Consistency (SC), Background Consistency (BC), Aesthetic Quality (AQ), and Prompt Fidelity (PF). Higher scores indicate better performance. The study reveals the contribution of each stage to the model’s ability to generate temporally consistent and high-quality multi-event videos.
read the caption
Table 2: Quantitative ablation study. *Abbreviations: subject consistency (SC), background consistency (BC), aesthetic quality (AQ), and prompt fidelity (PF).
| Temporal Quality | Frame-wise Quality | Semantics | ||||||||||
| Stage | Subject | Background | Motion | Dynamic | Num | Aesthetic | Imaging | Glb Prompt | Loc Prompt | |||
| Backbone | 1 | 2 | 3 | Consistency | Consistency | Smoothness | Degree | Scenes | Quality | Quality | Fidelity | Fidelity |
| M | ✓ | ✗ | ✓ | 80.46% | 91.14% | 98.55% | 97.92% | 1.229 | 53.36% | 58.42% | 0.318 | 0.348 |
| ✗ | ✓ | ✗ | 78.88% | 91.63% | 97.70% | 14.58% | 21.33 | 45.56% | 42.27% | 0.305 | 0.300 | |
| ✓ | ✓ | ✓ | 82.70% | 91.85% | 98.24% | 100.00% | 1.042 | 54.56% | 65.53% | 0.325 | 0.348 | |
🔼 This table presents a quantitative analysis of the SynCoS model’s three coupled stages. By systematically removing one stage at a time during the one-timestep denoising process, the study demonstrates the individual contribution of each stage to the overall coherence and quality of the generated long videos. The results highlight the importance of all three stages working together to produce coherent long video generation with multiple events, showcasing the effectiveness of SynCoS’s unique approach.
read the caption
Table 3: Quantitative ablations study of the three coupled stages in SynCoS, omitting each stage during one-timestep denoising, demonstrates the importance of all three stages for coherent long video generation with multiple events.
🔼 This table presents a comparison of the computation time required to generate long videos using three different methods: Gen-L-Video, FIFO-Diffusion, and SynCoS (the proposed method). The comparison is based on the CogVideoX-2B model and shows the time taken to generate videos four times longer than those produced by the base model. This allows for assessment of the efficiency of each method in generating extended-length videos.
read the caption
Table 4: Measurements and comparisons of computation time on CogVideoX-2B.
| Temporal | Frame | Semantics | |||
| Backbone | Method | SC | BC | AQ | PF |
| VideoCrafter2 [52] | Video-Infinity [45] | 0.879 | 0.943 | 0.645 | 0.365 |
| SynCoS | 0.911 | 0.947 | 0.648 | 0.365 | |
| CogVideoX-2B [55] | DitCtrl [5] | 0.821 | 0.916 | 0.635 | 0.394 |
| SynCoS | 0.864 | 0.927 | 0.643 | 0.381 | |
🔼 This table presents a quantitative comparison of SynCoS against architecture-specific baselines for multi-event long video generation. It evaluates the performance of different methods across four key metrics: Subject Consistency (SC), Background Consistency (BC), Aesthetic Quality (AQ), and Prompt Fidelity (PF). Higher scores indicate better performance in each metric. The table helps demonstrate SynCoS’s robustness across various architectures by showing its consistent superiority over other methods.
read the caption
Table 5: Quantitative comparison with architecture-specific baselines. *Abbreviations: subject consistency (SC), background consistency (BC), aesthetic quality (AQ), and prompt fidelity (PF).
Full paper#