TL;DR#
Recent text-to-image models rely on massive datasets and huge architectures, limiting accessibility. To tackle this issue, the paper introduces LightGen, a new training paradigm. It draws from data knowledge distillation to transfer capabilities into a compact architecture.
LightGen uses knowledge distillation and direct preference optimization to achieve comparable quality with significantly reduced resources. The method uses a compact synthetic dataset of 2M images and a 0.7B parameter model. Experiments confirm LightGen’s efficiency and quality.
Key Takeaways#
Why does it matter?#
This paper introduces an efficient training method that reduces reliance on extensive datasets and computational resources, broadening access for researchers. It also shows the diversity of data outweighs data volume. The method’s effectiveness opens new avenues for generative model development, especially in resource-constrained settings.
Visual Insights#
🔼 Figure 1 demonstrates LightGen’s capabilities in image generation, zero-shot inpainting, and efficient resource utilization. The first row showcases images generated at 512x512 and 1024x1024 resolutions, highlighting LightGen’s scalability. The second row presents zero-shot inpainting results, demonstrating its ability to seamlessly edit images. The third row compares LightGen’s resource consumption (dataset size, model parameters, and GPU hours) against state-of-the-art models. LightGen achieves comparable performance with significantly reduced resource requirements, showcasing its efficiency and cost-effectiveness.
read the caption
Figure 1: Overview of LightGen’s capabilities in image generation, zero-shot inpainting, and resource usage. (First Row) Images generated at multiple resolutions (512×512512512512\times 512512 × 512 and 1024×1024102410241024\times 10241024 × 1024) illustrate the scalability of LightGen. (Second Row) Zero-shot inpainting results showcasing LightGen’s inherent editing ability. (Third Row) LightGen’s resource consumption with drastically reduced dataset size, model parameters, and GPU hours compared to state-of-the-art models, demonstrates significant cost reductions without sacrificing performance.
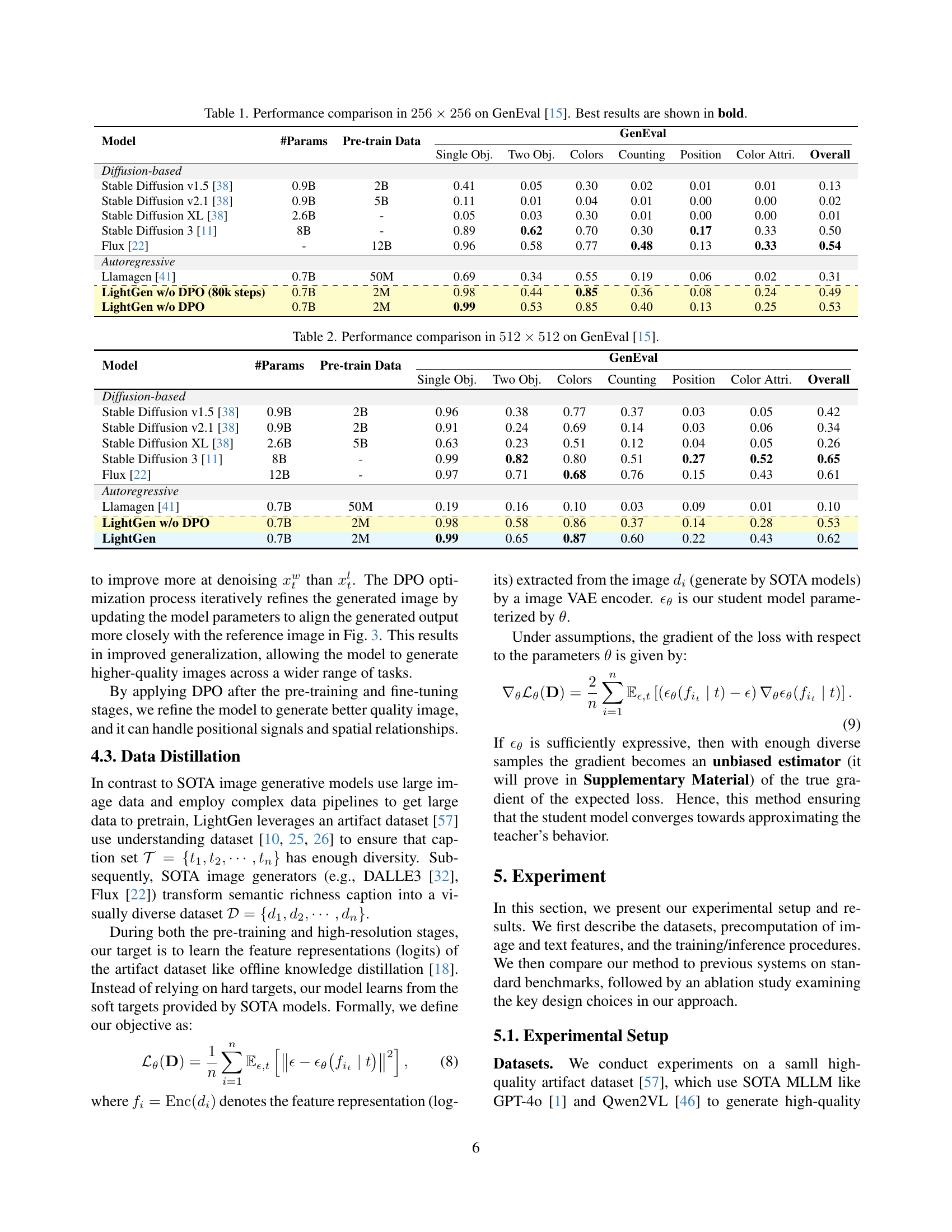
| Model | #Params | Pre-train Data | \adl@mkpreamc\@addtopreamble\@arstrut\@preamble | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Single Obj. | Two Obj. | Colors | Counting | Position | Color Attri. | Overall | |||
| \adl@mkpreaml\@addtopreamble\@arstrut\@preamble | |||||||||
| Stable Diffusion v1.5 [38] | 0.9B | 2B | 0.41 | 0.05 | 0.30 | 0.02 | 0.01 | 0.01 | 0.13 |
| Stable Diffusion v2.1 [38] | 0.9B | 5B | 0.11 | 0.01 | 0.04 | 0.01 | 0.00 | 0.00 | 0.02 |
| Stable Diffusion XL [38] | 2.6B | - | 0.05 | 0.03 | 0.30 | 0.01 | 0.00 | 0.00 | 0.01 |
| Stable Diffusion 3 [11] | 8B | - | 0.89 | 0.62 | 0.70 | 0.30 | 0.17 | 0.33 | 0.50 |
| Flux [22] | - | 12B | 0.96 | 0.58 | 0.77 | 0.48 | 0.13 | 0.33 | 0.54 |
| \adl@mkpreaml\@addtopreamble\@arstrut\@preamble | |||||||||
| Llamagen [41] | 0.7B | 50M | 0.69 | 0.34 | 0.55 | 0.19 | 0.06 | 0.02 | 0.31 |
| LightGen w/o DPO (80k steps) | 0.7B | 2M | 0.98 | 0.44 | 0.85 | 0.36 | 0.08 | 0.24 | 0.49 |
| LightGen w/o DPO | 0.7B | 2M | 0.99 | 0.53 | 0.85 | 0.40 | 0.13 | 0.25 | 0.53 |
🔼 This table presents a quantitative comparison of LightGen’s performance against several state-of-the-art text-to-image generation models on the GenEval benchmark at a resolution of 256 x 256 pixels. The models are evaluated across multiple aspects of image generation quality, including single object generation, two object generation, color accuracy, counting accuracy, positional accuracy, and color attribute accuracy. LightGen’s performance is compared to both diffusion-based and autoregressive models, highlighting its efficiency and competitive performance despite using significantly fewer parameters and a smaller training dataset. The best performance in each category is shown in bold.
read the caption
Table 1: Performance comparison in 256×256256256256\times 256256 × 256 on GenEval [15]. Best results are shown in bold.
In-depth insights#
KD & DPO:Gen#
Knowledge Distillation (KD) and Direct Preference Optimization (DPO) are powerful techniques. KD transfers knowledge from a large, complex model (teacher) to a smaller one (student). This can lead to efficient models. DPO, on the other hand, refines a model’s behavior by directly optimizing it against a defined preference. In image generation, this could mean training the model to produce images that are visually appealing. Combining KD and DPO could create a workflow. First, KD is used to distill the knowledge of a complex image generator into a smaller generator. Second, DPO could fine-tune the distilled model’s output to enhance visual quality.
MAR efficient#
While the exact phrase “MAR efficient” doesn’t appear in the provided text, it can be inferred that the paper discusses techniques for making Masked Autoregressive (MAR) models more efficient for image generation. The paper mentions using knowledge distillation (KD) and Direct Preference Optimization (DPO) to improve LightGen’s performance, suggesting a focus on efficient training paradigms. MAR models often require significant computational resources, so improving their efficiency is crucial. LightGen aims to reduce the dataset size, model parameters, and GPU hours needed for training, demonstrating its efficiency. By leveraging synthetic datasets and DPO, LightGen addresses the limitations of MAR models, such as poor high-frequency details and spatial inaccuracies. The post-processing with DPO enhances image quality and robustness, making LightGen a viable option for resource-constrained environments. The efficiency gains achieved by LightGen stem from data distillation, synthetic data utilization, lightweight architecture design, and post-processing with DPO. **This enables comparable performance to SOTA image generation models with significantly reduced resource demands.
Data Diversity+#
The concept of ‘Data Diversity+’ suggests a strategic emphasis beyond mere data volume in machine learning. It highlights the importance of variety in training data, encompassing a wide range of scenarios, styles, and contexts. This approach seeks to improve model generalization, enabling it to perform robustly across diverse real-world situations. By intentionally curating a dataset with diverse examples, the model is exposed to a broader spectrum of patterns and relationships, reducing the risk of overfitting to a narrow subset of the training data. This contrasts with simply increasing the amount of data, which may only reinforce existing biases. The ‘+’ implies proactive augmentation and thoughtful selection of data points to maximize informational content and representativeness.
Synthetic Data+#
Synthetic data generation is revolutionizing AI, particularly where real-world data is scarce or sensitive. It offers a pathway to create datasets that mirror the statistical properties of actual data, which is vital for training robust and generalizable models. Crucially, it addresses privacy concerns by sidestepping the use of personally identifiable information. The quality and diversity of synthetic data are key determinants of its effectiveness; models trained on it should perform comparably to those trained on real data. Techniques like generative adversarial networks (GANs) and variational autoencoders (VAEs) are pivotal in creating realistic synthetic instances. However, challenges remain in ensuring the data’s fidelity and mitigating potential biases. Further research is needed to refine synthetic data generation methodologies and establish robust evaluation metrics.
LightGen+DPO#
LightGen+DPO likely refers to a system combining a LightGen model with Direct Preference Optimization (DPO). LightGen, presumably, is a more efficient or lightweight image generation model. DPO is then employed as a post-processing or fine-tuning step to refine LightGen’s output. This combination likely aims to leverage the efficiency of LightGen while mitigating potential drawbacks through DPO, enhancing image fidelity, and spatial accuracy. This is an effective strategy to balance computational cost with high-quality output by focusing on data diversity and positional accuracy.
More visual insights#
More on figures

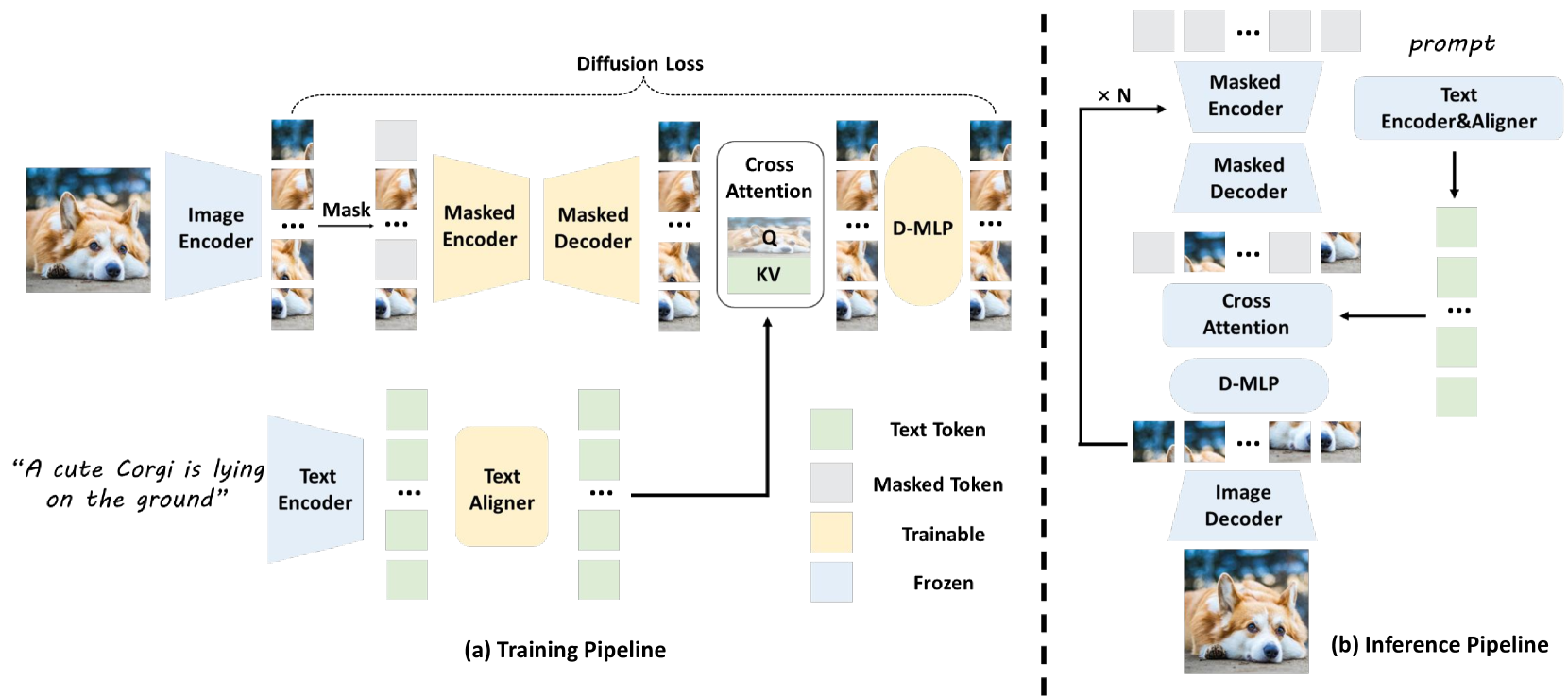
🔼 This figure illustrates the LightGen model’s training and inference pipelines. (a) Training: The process begins by encoding images into tokens using a pre-trained tokenizer. Simultaneously, text embeddings are generated from a T5 encoder and refined using a trainable aligner to ensure alignment with the image content. A masked autoencoder then processes these text and image tokens, utilizing a cross-attention mechanism where text tokens serve as queries and values, and image tokens as keys. This cross-attention step helps to integrate textual context into the image generation process. Finally, a Diffusion Multi-Layer Perceptron (D-MLP) refines the generated tokens further. (b) Inference: The inference pipeline takes as input a text prompt, which is processed as in the training stage. The model then iteratively predicts and refines tokens over N steps, with each step leveraging the previously generated tokens to progressively improve the image’s quality. After the refinement stage, the tokens are decoded using the image tokenizer to produce the final generated image.
read the caption
Figure 2: Overview of LightGen efficient pretraining. (a) Training: Images are encoded into tokens via a pre-trained tokenizer, while text embeddings from a T5 encoder are refined by a trainable aligner. A masked autoencoder uses text tokens as queries/values and image tokens as keys for cross-attention, followed by refinement with a Diffusion MLP (D-MLP). (b) Inference: Tokens are predicted and iteratively refined over N𝑁Nitalic_N steps, then decoded by the image tokenizer to generate final images.

🔼 This figure illustrates the Direct Preference Optimization (DPO) post-processing stage in LightGen. DPO aims to refine the quality of images generated by LightGen by minimizing the difference between the generated image and a high-quality reference image. The process involves adding noise to both the generated and reference images, then using a learned preference model to guide the refinement of the generated image towards the reference image. The steps show the iterative process of adding noise, applying the MAR model, and then calculating the DPO loss to guide the optimization. This process enhances image fidelity and positional accuracy, particularly addressing limitations inherent in synthetic data.
read the caption
Figure 3: Illustrate of DPO Post-processing of LightGen.

🔼 Figure 4 presents sample images generated by the LightGen model, demonstrating its ability to produce high-quality outputs across various resolutions (256x256, 512x512, and 1024x1024 pixels) and artistic styles (realistic, animated, and virtual). The diverse examples showcase the model’s versatility and scalability in handling different image generation tasks.
read the caption
Figure 4: Visualization Results. Sample outputs generated using LightGen, showcasing high-quality images at multiple resolutions (256×256256256256\times 256256 × 256, 512×512512512512\times 512512 × 512, 1024×1024102410241024\times 10241024 × 1024) and across diverse styles (realistic, animated, virtual, etc.), which demonstrate the versatility and scalability of our approach.

🔼 This figure showcases the inpainting capabilities of the LightGen model. It demonstrates the model’s ability to seamlessly fill in missing or damaged regions of an image while maintaining the overall context and style. Multiple examples are shown to illustrate the versatility of the model in handling various types of images and levels of damage.
read the caption
Figure 5: Image inpainting demonstrations.

🔼 Figure 6 presents the results of ablation studies conducted to analyze the impact of dataset size and training iterations on LightGen’s performance. Panel (a) shows the effect of varying the size of the pre-training dataset. It demonstrates that model performance plateaus when the pre-training dataset reaches approximately 1 million images, suggesting that increasing data size beyond this point yields diminishing returns. Panel (b) illustrates how different numbers of training iterations affect the model’s performance. The results indicate the training efficiency of the model.
read the caption
Figure 6: Ablation studies. (a) Pre-train in different data scales, we find it achieves the limitation when pre-train in 𝒪(1M)𝒪1𝑀\mathcal{O}(1M)caligraphic_O ( 1 italic_M ) data scale. (b) demonstrate different iteration results.
More on tables
| Model | #Params | Pre-train Data | \adl@mkpreamc\@addtopreamble\@arstrut\@preamble | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Single Obj. | Two Obj. | Colors | Counting | Position | Color Attri. | Overall | |||
| \adl@mkpreaml\@addtopreamble\@arstrut\@preamble | |||||||||
| Stable Diffusion v1.5 [38] | 0.9B | 2B | 0.96 | 0.38 | 0.77 | 0.37 | 0.03 | 0.05 | 0.42 |
| Stable Diffusion v2.1 [38] | 0.9B | 2B | 0.91 | 0.24 | 0.69 | 0.14 | 0.03 | 0.06 | 0.34 |
| Stable Diffusion XL [38] | 2.6B | 5B | 0.63 | 0.23 | 0.51 | 0.12 | 0.04 | 0.05 | 0.26 |
| Stable Diffusion 3 [11] | 8B | - | 0.99 | 0.82 | 0.80 | 0.51 | 0.27 | 0.52 | 0.65 |
| Flux [22] | 12B | - | 0.97 | 0.71 | 0.68 | 0.76 | 0.15 | 0.43 | 0.61 |
| \adl@mkpreaml\@addtopreamble\@arstrut\@preamble | |||||||||
| Llamagen [41] | 0.7B | 50M | 0.19 | 0.16 | 0.10 | 0.03 | 0.09 | 0.01 | 0.10 |
| LightGen w/o DPO | 0.7B | 2M | 0.98 | 0.58 | 0.86 | 0.37 | 0.14 | 0.28 | 0.53 |
| LightGen | 0.7B | 2M | 0.99 | 0.65 | 0.87 | 0.60 | 0.22 | 0.43 | 0.62 |
🔼 This table presents a quantitative comparison of LightGen’s performance against several state-of-the-art (SOTA) text-to-image generation models on the GenEval benchmark at a resolution of 512x512 pixels. The models are evaluated across various aspects of image generation quality, including the generation of single and multiple objects, color accuracy, counting ability, positional accuracy, and overall image quality. The table shows the number of parameters and the size of the pre-training data used for each model. LightGen’s performance is compared to several diffusion-based models (Stable Diffusion versions 1.5, 2.1, XL, and 3; Flux) and to an autoregressive model (Llamagen). This allows for an assessment of LightGen’s efficiency and effectiveness relative to existing methods.
read the caption
Table 2: Performance comparison in 512×512512512512\times 512512 × 512 on GenEval [15].
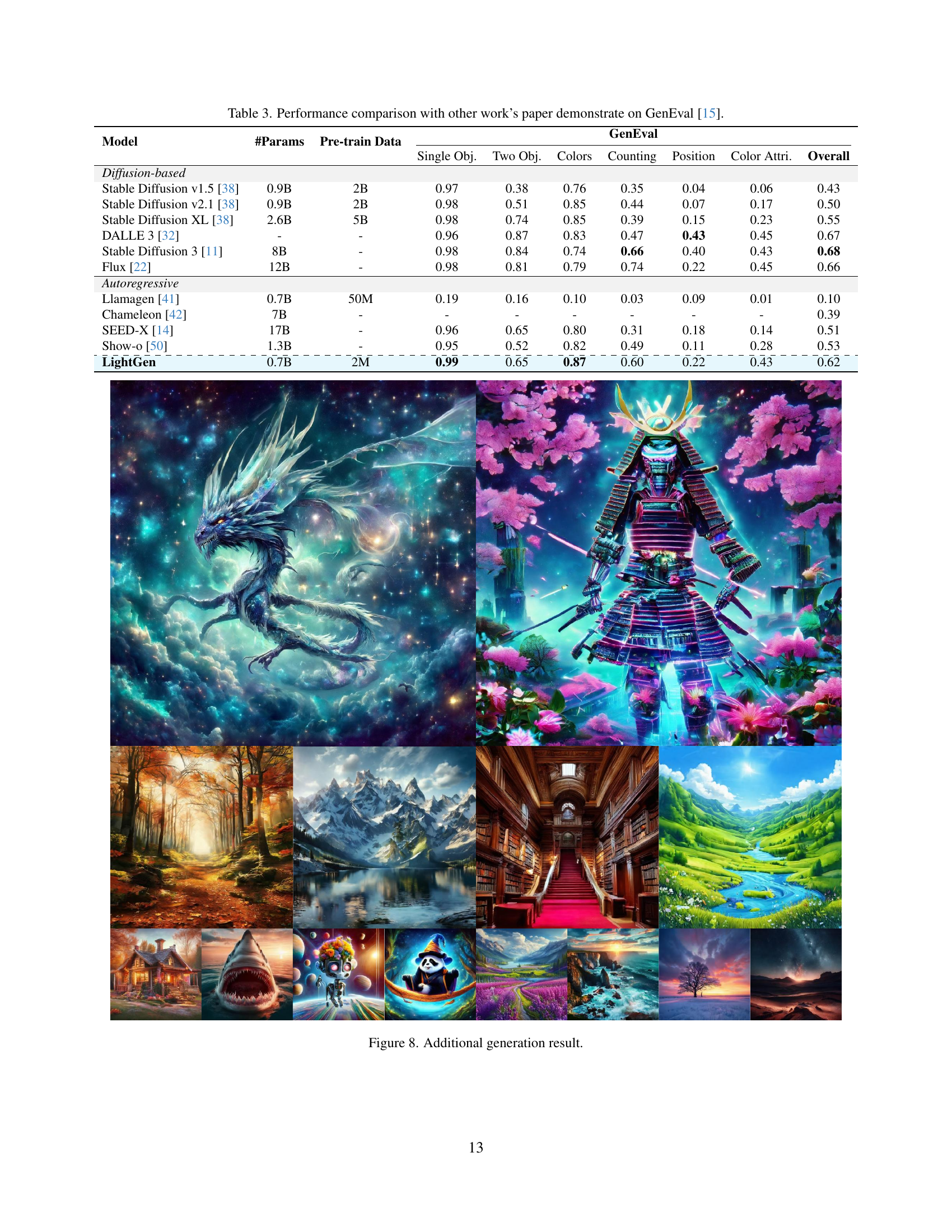
| Model | #Params | Pre-train Data | \adl@mkpreamc\@addtopreamble\@arstrut\@preamble | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Single Obj. | Two Obj. | Colors | Counting | Position | Color Attri. | Overall | |||
| \adl@mkpreaml\@addtopreamble\@arstrut\@preamble | |||||||||
| Stable Diffusion v1.5 [38] | 0.9B | 2B | 0.97 | 0.38 | 0.76 | 0.35 | 0.04 | 0.06 | 0.43 |
| Stable Diffusion v2.1 [38] | 0.9B | 2B | 0.98 | 0.51 | 0.85 | 0.44 | 0.07 | 0.17 | 0.50 |
| Stable Diffusion XL [38] | 2.6B | 5B | 0.98 | 0.74 | 0.85 | 0.39 | 0.15 | 0.23 | 0.55 |
| DALLE 3 [32] | - | - | 0.96 | 0.87 | 0.83 | 0.47 | 0.43 | 0.45 | 0.67 |
| Stable Diffusion 3 [11] | 8B | - | 0.98 | 0.84 | 0.74 | 0.66 | 0.40 | 0.43 | 0.68 |
| Flux [22] | 12B | - | 0.98 | 0.81 | 0.79 | 0.74 | 0.22 | 0.45 | 0.66 |
| \adl@mkpreaml\@addtopreamble\@arstrut\@preamble | |||||||||
| Llamagen [41] | 0.7B | 50M | 0.19 | 0.16 | 0.10 | 0.03 | 0.09 | 0.01 | 0.10 |
| Chameleon [42] | 7B | - | - | - | - | - | - | - | 0.39 |
| SEED-X [14] | 17B | - | 0.96 | 0.65 | 0.80 | 0.31 | 0.18 | 0.14 | 0.51 |
| Show-o [50] | 1.3B | - | 0.95 | 0.52 | 0.82 | 0.49 | 0.11 | 0.28 | 0.53 |
| LightGen | 0.7B | 2M | 0.99 | 0.65 | 0.87 | 0.60 | 0.22 | 0.43 | 0.62 |
🔼 This table presents a quantitative comparison of LightGen’s performance against several state-of-the-art (SOTA) text-to-image generation models on the GenEval benchmark [15]. The comparison includes both diffusion-based models (Stable Diffusion versions 1.5, 2.1, XL, and 3; Flux) and autoregressive models (Llamagen). For each model, the table shows the number of parameters (#Params), the size of the pre-training dataset (Pre-train Data), and the GenEval scores across various metrics. These metrics assess the model’s ability to generate images that accurately reflect different aspects of the input text prompt, including the presence of single or multiple objects, color accuracy, counting ability, positional accuracy, and overall attribute agreement. LightGen’s performance is evaluated with and without the Direct Preference Optimization (DPO) post-processing step.
read the caption
Table 3: Performance comparison with other work’s paper demonstrate on GenEval [15].
Full paper#