TL;DR#
Recent advances in long video understanding use token pruning. However, they overlook input-level semantic correlation between visual tokens and instructions. The paper introduces QuoTA, a modular, training-free method for visual token assignment that considers query-oriented frame-level importance in Large Video-Language Models.
QuoTA strategically allocates frame-level importance scores based on query relevance, decoupling the query via Chain-of-Thoughts reasoning to facilitate more precise frame importance scoring. This approach improves performance on six benchmarks by aligning visual processing with task-specific needs, optimizing token budget utilization.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical challenge of efficiently processing long videos in LVLMs. QuoTA’s training-free, plug-and-play design offers immediate benefits, paving the way for more effective video analysis and understanding in resource-constrained environments, and opens new research directions in query-focused attention mechanisms.
Visual Insights#

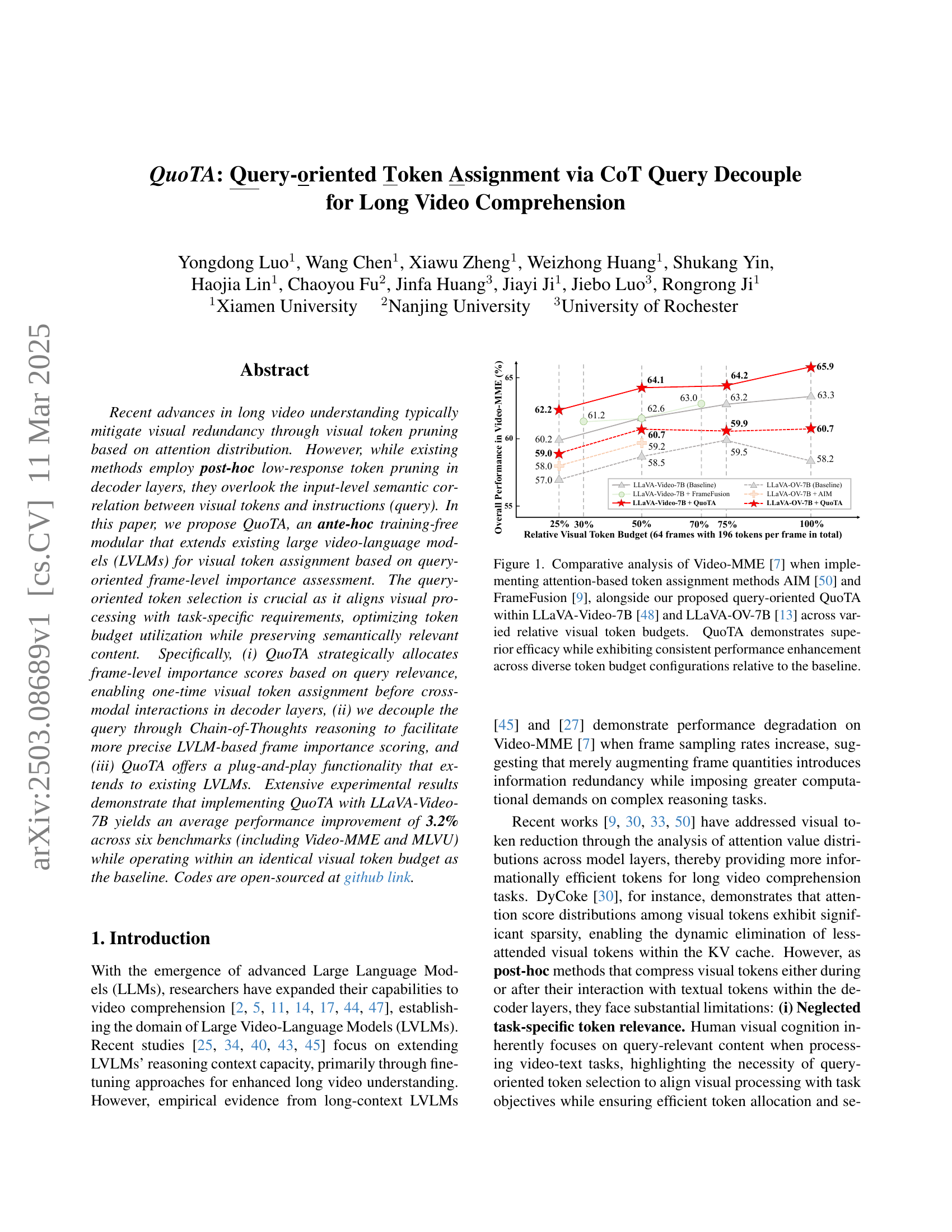
🔼 Figure 1 presents a comparative performance analysis of different token assignment methods on the Video-MME benchmark. It specifically examines the impact of three techniques – AIM [50], FrameFusion [9], and the proposed QuoTA – when integrated with two large video-language models (LVLMs): LLaVA-Video-7B [48] and LLaVA-OV-7B [13]. The x-axis represents the relative visual token budget (percentage of total tokens used), while the y-axis shows the overall performance on Video-MME. The figure demonstrates that QuoTA consistently outperforms both AIM and FrameFusion across various token budget settings, showcasing its effectiveness in enhancing the performance of the base LVLMs without requiring additional computational resources.
read the caption
Figure 1: Comparative analysis of Video-MME [7] when implementing attention-based token assignment methods AIM [50] and FrameFusion [9], alongside our proposed query-oriented QuoTA within LLaVA-Video-7B [48] and LLaVA-OV-7B [13] across varied relative visual token budgets. QuoTA demonstrates superior efficacy while exhibiting consistent performance enhancement across diverse token budget configurations relative to the baseline.
| Prompt for Frame Scoring Based on Source Query |
|---|
| Question: Does this frame contain any information to answer the given query: {query}? |
| A. Yes. B. No. |
| Answer the letter directly. |
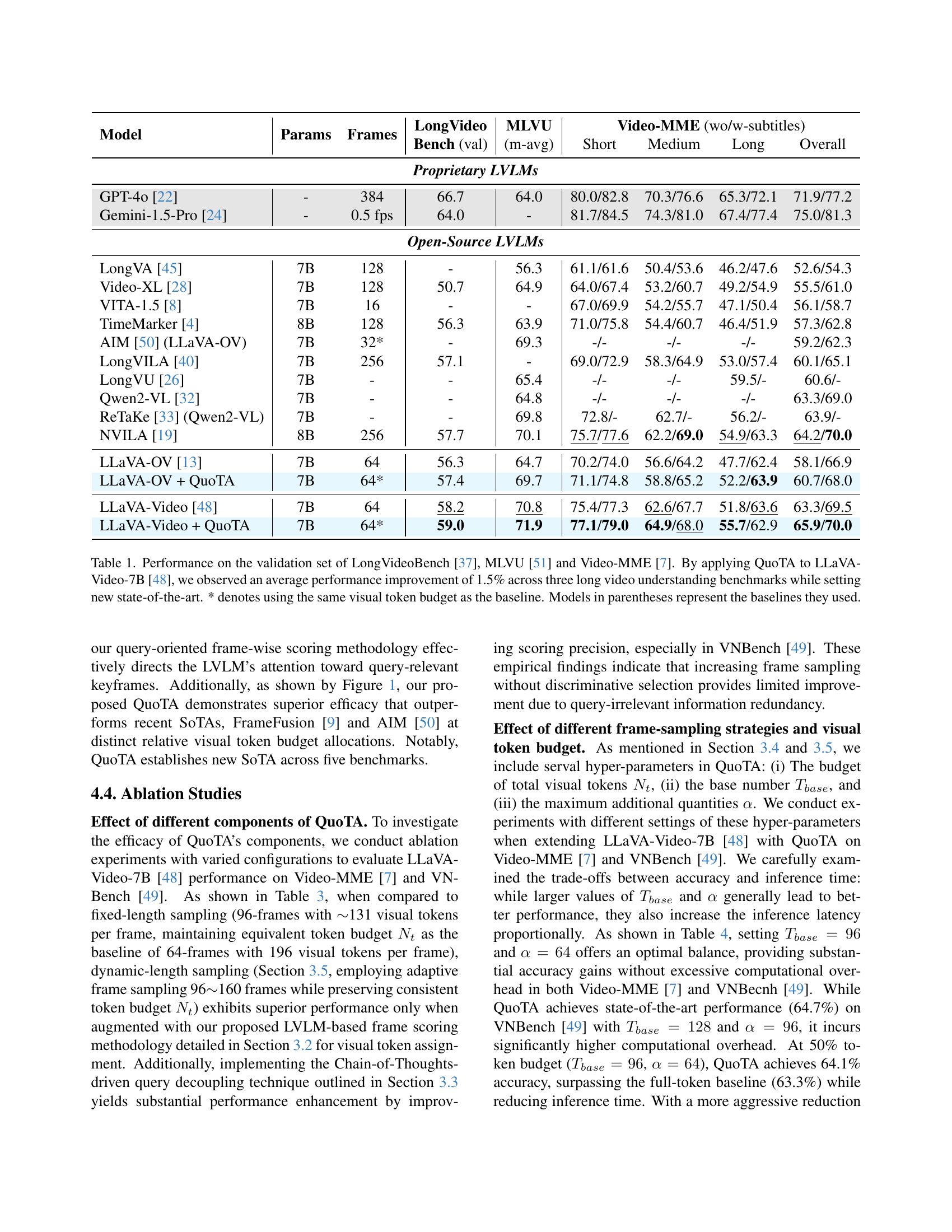
🔼 Table 1 presents a comparison of the performance of various Large Video-Language Models (LVLMs) on three benchmark datasets for long video understanding: LongVideoBench, MLVU, and Video-MME. The table shows the performance of several models, including proprietary models like GPT-4 and Gemini, as well as open-source models such as LongVA, Video-XL, and LLaVA. The performance metric used is an overall accuracy score, presented as a percentage, and the results are broken down by video length (short, medium, long) to highlight performance variation across different video durations. It also shows the number of parameters and frames used by each model. A key finding highlighted in the caption is that adding the QuoTA module to the LLaVA-Video-7B model resulted in a 1.5% average performance improvement across the three benchmark datasets.
read the caption
Table 1: Performance on the validation set of LongVideoBench [37], MLVU [51] and Video-MME [7]. By applying QuoTA to LLaVA-Video-7B [48], we observed an average performance improvement of 1.5% across three long video understanding benchmarks while setting new state-of-the-art. * denotes using the same visual token budget as the baseline. Models in parentheses represent the baselines they used.
In-depth insights#
Query-Aware Tokens#
Query-aware tokens represent a paradigm shift in visual processing, moving beyond generic feature extraction to task-specific content selection. The idea is that not all visual tokens are equally relevant to a given query, so a model should focus its resources on the most informative ones. This approach aligns visual processing with task objectives, optimizing token budget utilization. Methods for achieving query-awareness could involve attention mechanisms or direct relevance scoring. Challenges include effectively decoupling the query and scoring visual frames. The potential benefits include improved performance, efficiency, and interpretability in video comprehension tasks.
CoT Query Split#
CoT Query Split is a technique to decompose complex queries into simpler sub-questions, enabling more accurate frame-level scoring. This leverages LVLMs’ reasoning abilities, structuring the query for better visual grounding. By focusing on key elements and question types, it facilitates targeted frame analysis, enhancing relevance and reducing noise. This approach is crucial for effective token allocation, ensuring critical information is prioritized, leading to improved overall comprehension and performance of the model. Different splitting strategies, such as entity-based and event-driven, cater to various task types, optimizing the selection process.
Frame Importance#
Frame Importance, as implicitly discussed in the paper, centers on identifying the most salient frames within a video for effective comprehension. The research addresses this by strategically allocating importance scores based on query relevance, ensuring that processing aligns with task-specific needs. Instead of merely increasing frame quantities, which can introduce redundancy, the approach optimizes token budget utilization while preserving semantically relevant content. The method strategically assigns frame-level importance before cross-modal interactions, leveraging Chain-of-Thoughts reasoning to decouple queries and enhance scoring precision, crucial for downstream tasks. The success of QuoTA underscores the significance of query-aware frame selection in mitigating redundancy and accentuating salient information, highlighting a departure from conventional attention-based techniques by explicitly incorporating query-specific relevance into visual token assignment.
Token Assignment#
The document likely discusses different strategies for assigning visual tokens in video understanding models. It seems token assignment aims to select the most relevant visual features for a given task or query. This may involve reducing redundancy by prioritizing keyframes or specific objects within frames, potentially using techniques like attention mechanisms or frame scoring based on relevance. The goal is to improve the model’s efficiency and accuracy by focusing on the most informative visual elements, while filtering out less relevant information to address the challenges of long video comprehension. The key is to balance computational costs and information density by strategically managing the token budget.
Long Video LVLMs#
Long Video LVLMs present a crucial area within multimodal learning, tackling challenges of processing extensive temporal data. Existing methods often prune tokens via attention, yet overlook the semantic input correlation between visual tokens and instructions. This underscores the need for approaches like the proposed QuoTA, which strategically assigns importance based on query relevance to optimize token budget. This ante-hoc token assignment aligns visual processing with specific tasks, preserving semantically relevant content. The core is balancing efficiency via token reduction and relevance through task-aware selection, offering a promising direction in LVLM research.
More visual insights#
More on figures
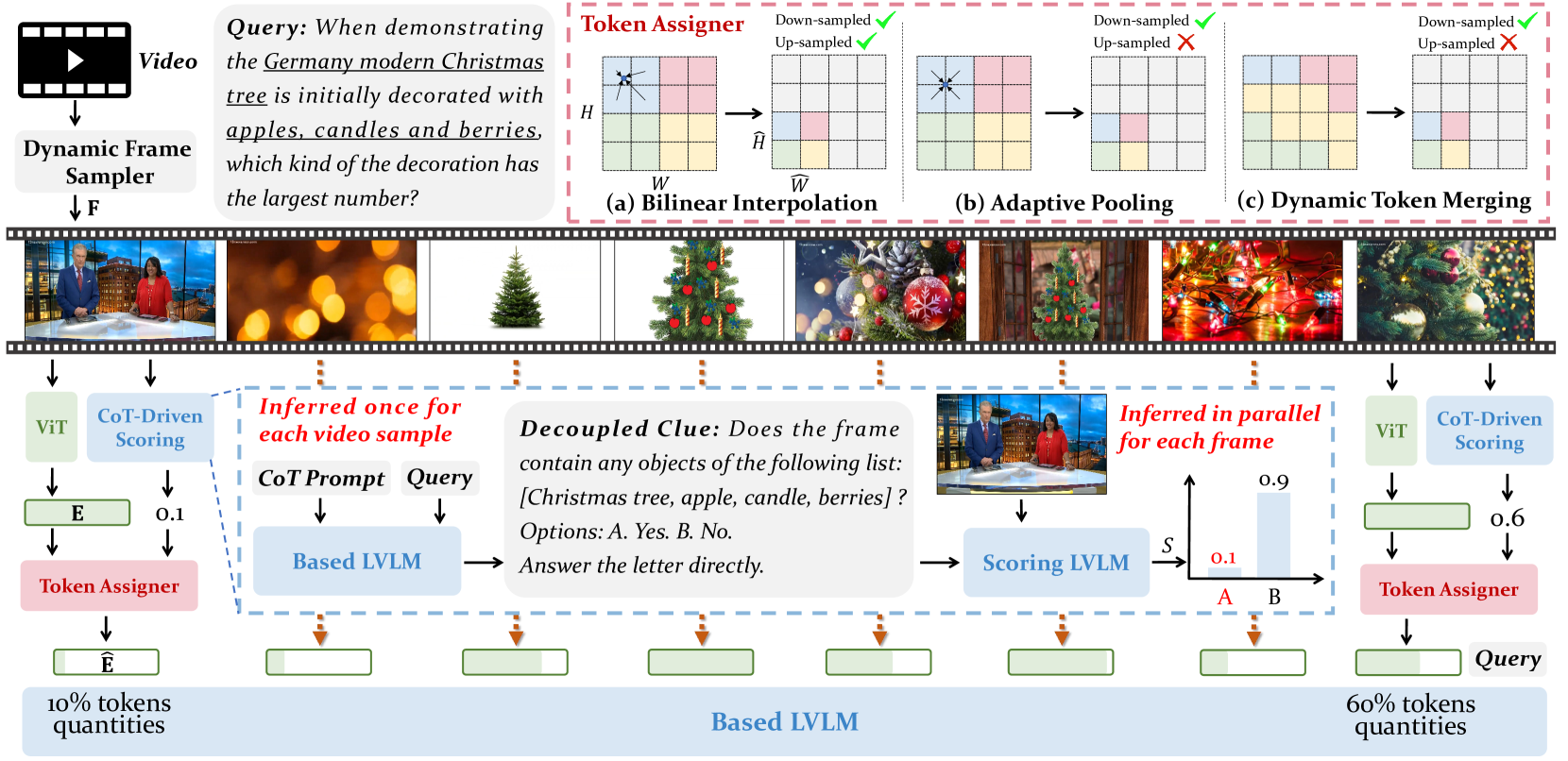
🔼 QuoTA’s framework consists of four stages: First, a dynamic frame sampler extracts frames from the video based on its duration. Second, a Vision Transformer (ViT) processes these frames to produce visual embeddings. Third, the ‘based LVLM’ uses Chain-of-Thought reasoning to transform the input query into a more specific question. This question is then used to prompt a lightweight ‘scoring LVLM’ to generate frame-wise importance scores, evaluating each frame’s relevance to the query. Finally, a token assigner uses these scores to adjust the visual embeddings, effectively weighting them according to their relevance to the query, producing rescaled frame embeddings.
read the caption
Figure 2: The framework of QuoTA. Initially, a dynamic frame sampler extracts T𝑇Titalic_T frames from the video based on its duration, which are subsequently processed by ViT to generate visual embeddings 𝐄𝐄\bm{\mathrm{E}}bold_E. Then, the based LVLM decouples the input query using Chain-of-Thoughts [36] reasoning into a decoupled clue to generate frame-wise importance scores through scoring LVLM in parallel, thus evaluating the relevance to the query of each frame. Finally, a token assigner rescales the frame embeddings to 𝐄^bold-^𝐄\bm{\mathrm{\hat{E}}}overbold_^ start_ARG bold_E end_ARG based on these importance scores.

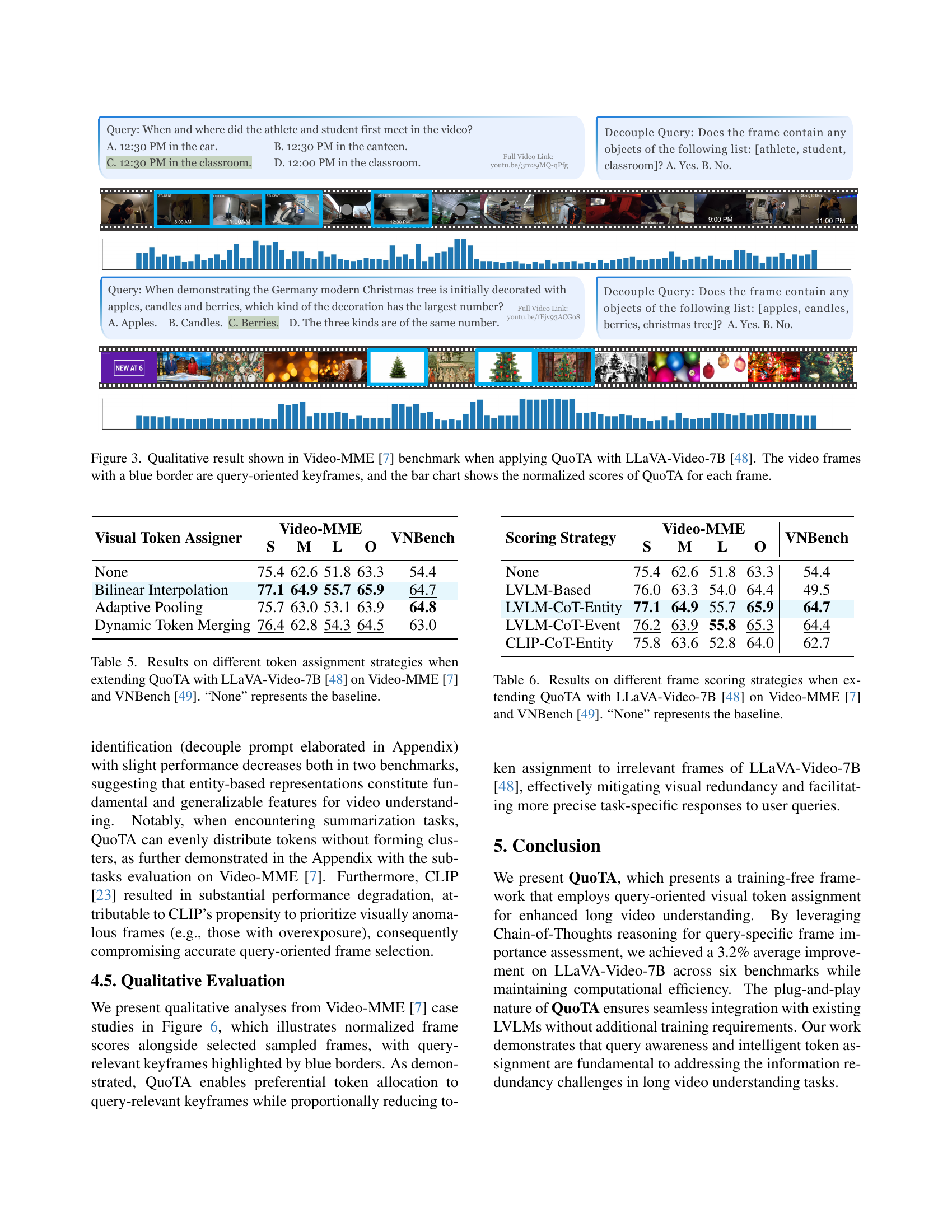
🔼 This figure displays a qualitative analysis of QuoTA’s performance on the Video-MME benchmark using the LLaVA-Video-7B model. It showcases two example queries and their corresponding video segments. Frames deemed important by QuoTA (query-oriented keyframes) are highlighted with blue borders. A bar chart visually represents the normalized importance scores assigned by QuoTA to each frame within the video segment, illustrating how the model prioritizes certain frames based on their relevance to the query. This visualization helps understand how QuoTA focuses the model’s attention on the most pertinent parts of the video for accurate response generation.
read the caption
Figure 3: Qualitative result shown in Video-MME [7] benchmark when applying QuoTA with LLaVA-Video-7B [48]. The video frames with a blue border are query-oriented keyframes, and the bar chart shows the normalized scores of QuoTA for each frame.

🔼 This figure shows the detailed prompt engineering strategy used in the paper for object list-based chain of thought reasoning. The prompt guides the large language model (LLM) to first determine if identifying specific objects is necessary to answer the question. If yes, the model is then prompted to list those objects, followed by a filtering step to eliminate any abstract concepts and leave only physical entities. The example prompts help illustrate this three-step process and ensure the LLM focuses on relevant objects in the video frames.
read the caption
Figure 4: CoT-driven decouple prompt for object list.

🔼 This figure demonstrates the Chain-of-Thought (CoT) driven query decoupling prompt specifically designed for video events. The prompt guides the large language model (LLM) to break down a complex query into a simpler, more focused question about the presence of key video events or elements within a frame. This process aids in generating more accurate frame-level importance scores by focusing the LLM on specific, easily identifiable aspects of the video content rather than the entire, potentially ambiguous original query.
read the caption
Figure 5: CoT-driven decouple prompt for video event.

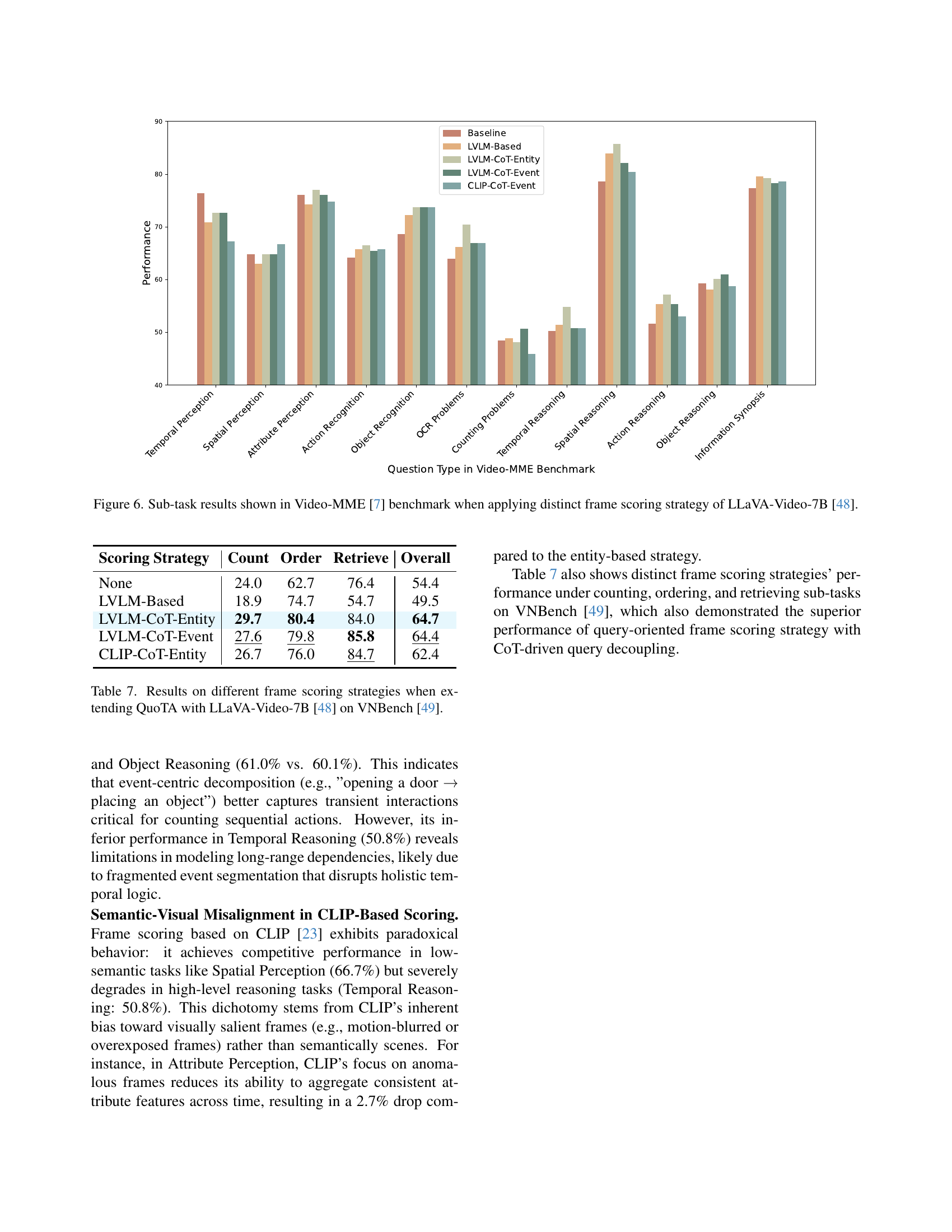
🔼 Figure 6 presents a detailed breakdown of the performance achieved by various frame scoring strategies within the LLaVA-Video-7B model on the Video-MME benchmark. It showcases a comparison of different approaches for assigning importance scores to video frames, including methods based on LVLMs with and without Chain-of-Thought (CoT) reasoning, and even CLIP-based scoring. The graph displays the performance on individual sub-tasks within Video-MME, offering a granular view of how each method performs in aspects such as temporal perception, spatial perception, action recognition, and more. This allows for a direct comparison of the effectiveness of different query-oriented token selection strategies and their relative strengths and weaknesses across a range of video understanding tasks.
read the caption
Figure 6: Sub-task results shown in Video-MME [7] benchmark when applying distinct frame scoring strategy of LLaVA-Video-7B [48].
More on tables
| Prompt for Frame Scoring Based on Entity List |
|---|
| Question: Does the frame contain any objects of the following list: {object_list}? |
| A. Yes. B. No. |
| Answer the letter directly. |
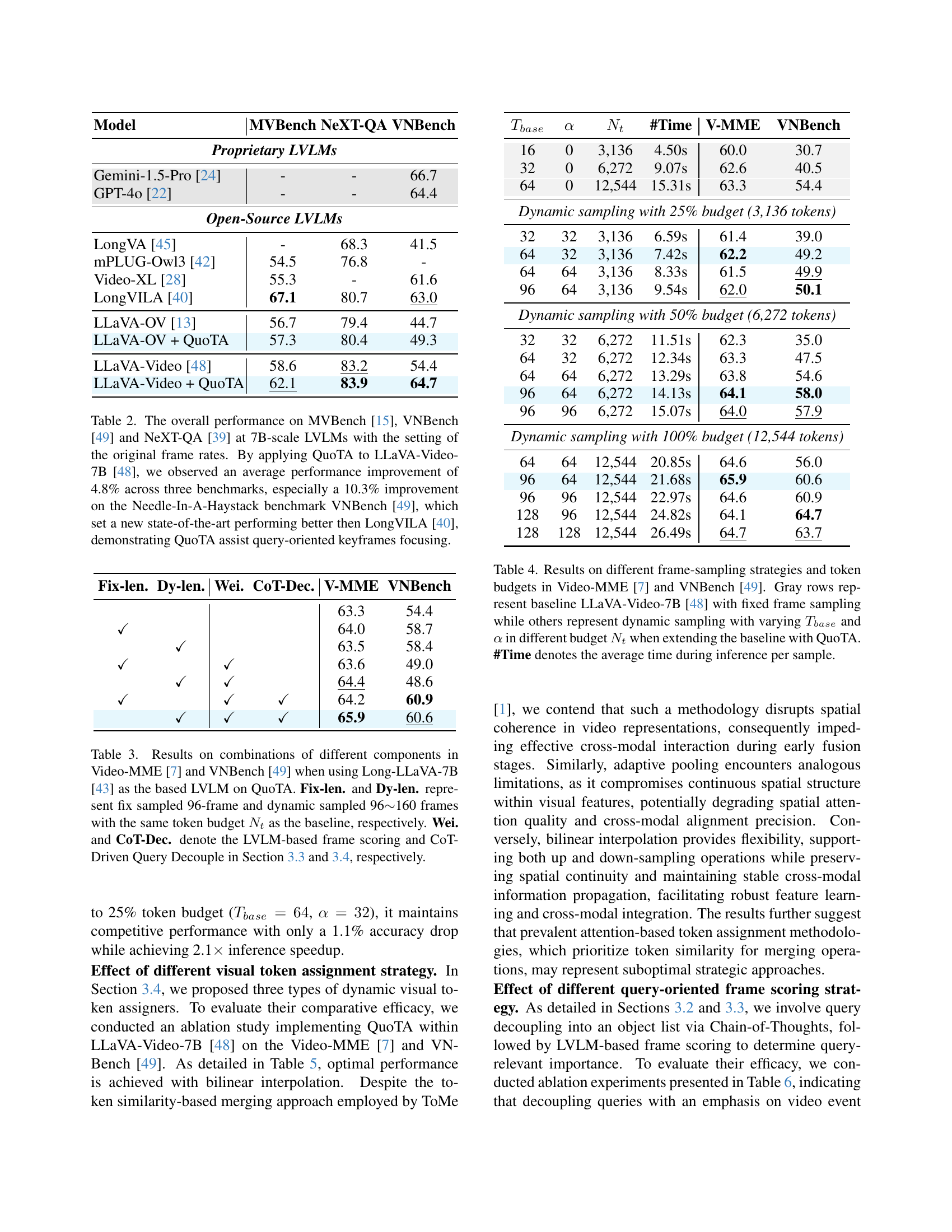
🔼 Table 2 presents the performance comparison of various 7B-scale Large Video-Language Models (LVLMs) on three video understanding benchmarks: MVBench, VNBench, and NeXT-QA. The results are shown using the original frame rates of the videos. A key finding is that incorporating QuoTA into the LLaVA-Video-7B model leads to a significant average performance improvement (4.8%) across all three benchmarks. The most substantial improvement (10.3%) is observed on the VNBench (Needle-In-A-Haystack) benchmark, demonstrating QuoTA’s effectiveness in focusing on query-relevant keyframes. This places QuoTA’s enhanced LLaVA-Video-7B model ahead of the state-of-the-art model LongVILA.
read the caption
Table 2: The overall performance on MVBench [15], VNBench [49] and NeXT-QA [39] at 7B-scale LVLMs with the setting of the original frame rates. By applying QuoTA to LLaVA-Video-7B [48], we observed an average performance improvement of 4.8% across three benchmarks, especially a 10.3% improvement on the Needle-In-A-Haystack benchmark VNBench [49], which set a new state-of-the-art performing better then LongVILA [40], demonstrating QuoTA assist query-oriented keyframes focusing.
| Model | Params | Frames | LongVideo | MLVU | Video-MME (wo/w-subtitles) | |||
| Bench (val) | (m-avg) | Short | Medium | Long | Overall | |||
| Proprietary LVLMs | ||||||||
| GPT-4o [22] | - | 384 | 66.7 | 64.0 | 80.0/82.8 | 70.3/76.6 | 65.3/72.1 | 71.9/77.2 |
| Gemini-1.5-Pro [24] | - | 0.5 fps | 64.0 | - | 81.7/84.5 | 74.3/81.0 | 67.4/77.4 | 75.0/81.3 |
| Open-Source LVLMs | ||||||||
| LongVA [45] | 7B | 128 | - | 56.3 | 61.1/61.6 | 50.4/53.6 | 46.2/47.6 | 52.6/54.3 |
| Video-XL [28] | 7B | 128 | 50.7 | 64.9 | 64.0/67.4 | 53.2/60.7 | 49.2/54.9 | 55.5/61.0 |
| VITA-1.5 [8] | 7B | 16 | - | - | 67.0/69.9 | 54.2/55.7 | 47.1/50.4 | 56.1/58.7 |
| TimeMarker [4] | 8B | 128 | 56.3 | 63.9 | 71.0/75.8 | 54.4/60.7 | 46.4/51.9 | 57.3/62.8 |
| AIM [50] (LLaVA-OV) | 7B | 32* | - | 69.3 | -/- | -/- | -/- | 59.2/62.3 |
| LongVILA [40] | 7B | 256 | 57.1 | - | 69.0/72.9 | 58.3/64.9 | 53.0/57.4 | 60.1/65.1 |
| LongVU [26] | 7B | - | - | 65.4 | -/- | -/- | 59.5/- | 60.6/- |
| Qwen2-VL [32] | 7B | - | - | 64.8 | -/- | -/- | -/- | 63.3/69.0 |
| ReTaKe [33] (Qwen2-VL) | 7B | - | - | 69.8 | 72.8/- | 62.7/- | 56.2/- | 63.9/- |
| NVILA [19] | 8B | 256 | 57.7 | 70.1 | 75.7/77.6 | 62.2/69.0 | 54.9/63.3 | 64.2/70.0 |
| LLaVA-OV [13] | 7B | 64 | 56.3 | 64.7 | 70.2/74.0 | 56.6/64.2 | 47.7/62.4 | 58.1/66.9 |
| LLaVA-OV + QuoTA | 7B | 64* | 57.4 | 69.7 | 71.1/74.8 | 58.8/65.2 | 52.2/63.9 | 60.7/68.0 |
| LLaVA-Video [48] | 7B | 64 | 58.2 | 70.8 | 75.4/77.3 | 62.6/67.7 | 51.8/63.6 | 63.3/69.5 |
| LLaVA-Video + QuoTA | 7B | 64* | 59.0 | 71.9 | 77.1/79.0 | 64.9/68.0 | 55.7/62.9 | 65.9/70.0 |
🔼 This table presents an ablation study analyzing the impact of different components of the QuoTA model on two video understanding benchmarks: Video-MME and VNBench. The study compares several configurations of the QuoTA model, varying the frame sampling method (fixed-length sampling of 96 frames versus dynamic sampling of 96-160 frames), the inclusion of LVLM-based frame scoring (Wei.), and the use of Chain-of-Thought driven query decoupling (CoT-Dec.). All configurations maintain a consistent token budget. The results show the performance of each configuration on Video-MME and VNBench, allowing for a detailed analysis of the contribution of each QuoTA component.
read the caption
Table 3: Results on combinations of different components in Video-MME [7] and VNBench [49] when using Long-LLaVA-7B [43] as the based LVLM on QuoTA. Fix-len. and Dy-len. represent fix sampled 96-frame and dynamic sampled 96∼similar-to\sim∼160 frames with the same token budget Ntsubscript𝑁𝑡N_{t}italic_N start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT as the baseline, respectively. Wei. and CoT-Dec. denote the LVLM-based frame scoring and CoT-Driven Query Decouple in Section 3.3 and 3.4, respectively.
| Model | MVBench | NeXT-QA | VNBench |
|---|---|---|---|
| Proprietary LVLMs | |||
| Gemini-1.5-Pro [24] | - | - | 66.7 |
| GPT-4o [22] | - | - | 64.4 |
| Open-Source LVLMs | |||
| LongVA [45] | - | 68.3 | 41.5 |
| mPLUG-Owl3 [42] | 54.5 | 76.8 | - |
| Video-XL [28] | 55.3 | - | 61.6 |
| LongVILA [40] | 67.1 | 80.7 | 63.0 |
| LLaVA-OV [13] | 56.7 | 79.4 | 44.7 |
| LLaVA-OV + QuoTA | 57.3 | 80.4 | 49.3 |
| LLaVA-Video [48] | 58.6 | 83.2 | 54.4 |
| LLaVA-Video + QuoTA | 62.1 | 83.9 | 64.7 |
🔼 Table 4 shows the performance comparison of different frame sampling strategies and token budgets using the Video-MME and VNBench datasets. The baseline model is LLaVA-Video-7B with a fixed number of frames and tokens. The experiments introduce dynamic frame sampling, adjusting the number of frames based on video length and varying the total token budget. Different combinations of
Tbase(base number of frames),α(hyperparameter controlling the maximum number of additional frames), andNt(total visual token budget) are tested. The table presents results for these varying configurations, showing the impact on performance (measured by accuracy on the benchmarks) and inference time per sample. The gray rows indicate the baseline’s performance with fixed frame sampling.read the caption
Table 4: Results on different frame-sampling strategies and token budgets in Video-MME [7] and VNBench [49]. Gray rows represent baseline LLaVA-Video-7B [48] with fixed frame sampling while others represent dynamic sampling with varying Tbasesubscript𝑇𝑏𝑎𝑠𝑒T_{base}italic_T start_POSTSUBSCRIPT italic_b italic_a italic_s italic_e end_POSTSUBSCRIPT and α𝛼\alphaitalic_α in different budget Ntsubscript𝑁𝑡N_{t}italic_N start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT when extending the baseline with QuoTA. #Time denotes the average time during inference per sample.
| Fix-len. | Dy-len. | Wei. | CoT-Dec. | V-MME | VNBench |
|---|---|---|---|---|---|
| 63.3 | 54.4 | ||||
| ✓ | 64.0 | 58.7 | |||
| ✓ | 63.5 | 58.4 | |||
| ✓ | ✓ | 63.6 | 49.0 | ||
| ✓ | ✓ | 64.4 | 48.6 | ||
| ✓ | ✓ | ✓ | 64.2 | 60.9 | |
| ✓ | ✓ | ✓ | 65.9 | 60.6 |
🔼 This table presents a comparison of different visual token assignment strategies within the QuoTA framework, specifically focusing on their impact on the performance of the LLaVA-Video-7B model across two video understanding benchmarks: Video-MME and VNBench. The strategies evaluated include the baseline (no special token assignment), bilinear interpolation, adaptive pooling, and dynamic token merging. The results highlight the effectiveness of each method in terms of overall performance, broken down further by sub-task within the benchmarks. The ‘None’ row represents the model’s performance without any specialized token assignment, providing a basis for comparison.
read the caption
Table 5: Results on different token assignment strategies when extending QuoTA with LLaVA-Video-7B [48] on Video-MME [7] and VNBench [49]. “None” represents the baseline.
| #Time | V-MME | VNBench | |||
| 16 | 0 | 3,136 | 4.50s | 60.0 | 30.7 |
| 32 | 0 | 6,272 | 9.07s | 62.6 | 40.5 |
| 64 | 0 | 12,544 | 15.31s | 63.3 | 54.4 |
| Dynamic sampling with 25% budget (3,136 tokens) | |||||
| 32 | 32 | 3,136 | 6.59s | 61.4 | 39.0 |
| 64 | 32 | 3,136 | 7.42s | 62.2 | 49.2 |
| 64 | 64 | 3,136 | 8.33s | 61.5 | 49.9 |
| 96 | 64 | 3,136 | 9.54s | 62.0 | 50.1 |
| Dynamic sampling with 50% budget (6,272 tokens) | |||||
| 32 | 32 | 6,272 | 11.51s | 62.3 | 35.0 |
| 64 | 32 | 6,272 | 12.34s | 63.3 | 47.5 |
| 64 | 64 | 6,272 | 13.29s | 63.8 | 54.6 |
| 96 | 64 | 6,272 | 14.13s | 64.1 | 58.0 |
| 96 | 96 | 6,272 | 15.07s | 64.0 | 57.9 |
| Dynamic sampling with 100% budget (12,544 tokens) | |||||
| 64 | 64 | 12,544 | 20.85s | 64.6 | 56.0 |
| 96 | 64 | 12,544 | 21.68s | 65.9 | 60.6 |
| 96 | 96 | 12,544 | 22.97s | 64.6 | 60.9 |
| 128 | 96 | 12,544 | 24.82s | 64.1 | 64.7 |
| 128 | 128 | 12,544 | 26.49s | 64.7 | 63.7 |
🔼 This table presents a comparative analysis of different frame scoring strategies within the QuoTA framework, specifically when integrated with the LLaVA-Video-7B model. It evaluates the performance on two benchmark datasets: Video-MME and VNBench. The strategies compared include using no frame scoring (baseline), a LVLM-based approach, LVLM-based approaches with Chain-of-Thought (CoT) reasoning for entity or event-centric decomposition, and a CLIP-based CoT approach. The results are shown in terms of overall performance and broken down for different sub-tasks within each benchmark to highlight the strengths and weaknesses of each scoring strategy.
read the caption
Table 6: Results on different frame scoring strategies when extending QuoTA with LLaVA-Video-7B [48] on Video-MME [7] and VNBench [49]. “None” represents the baseline.
| Visual Token Assigner | Video-MME | VNBench | |||
|---|---|---|---|---|---|
| S | M | L | O | ||
| None | 75.4 | 62.6 | 51.8 | 63.3 | 54.4 |
| Bilinear Interpolation | 77.1 | 64.9 | 55.7 | 65.9 | 64.7 |
| Adaptive Pooling | 75.7 | 63.0 | 53.1 | 63.9 | 64.8 |
| Dynamic Token Merging | 76.4 | 62.8 | 54.3 | 64.5 | 63.0 |
🔼 This table presents a quantitative comparison of different frame scoring strategies within the QuoTA framework, specifically when integrated with the LLaVA-Video-7B model on the VNBench benchmark. It details the performance across various sub-tasks, including counting, ordering, and retrieval, allowing for a nuanced evaluation of the effectiveness of distinct scoring approaches. The results showcase the impact of the various methods on achieving the overall goal of accurate and efficient video understanding.
read the caption
Table 7: Results on different frame scoring strategies when extending QuoTA with LLaVA-Video-7B [48] on VNBench [49].
Full paper#