TL;DR#
Generating dynamic 4D environments is challenging. Existing methods rely on training multi-view video diffusion models on large 4D datasets, but these are often limited to specific domains, inaccessible, or require multiple inputs. In essence, a new method is needed for generating multi-view videos in a way that is more accessible and adaptable to different scenes. Addressing this is crucial for creating immersive VR/AR experiences.
To tackle this issue, Reangle-A-Video reframes the task as video-to-video translation. It uses multi-view motion learning via self-supervised fine-tuning of an image-to-video diffusion transformer on warped videos. For multi-view consistency, it uses DUSt3R to guide image translation. This approach surpasses existing methods for static view transport and dynamic camera control. This work sets a new standard for multi-view video generation.
Key Takeaways#
Why does it matter?#
This work addresses the challenge of creating multi-view videos from a single input, which is valuable for VR/AR content generation. By simplifying the process and improving results, it offers new possibilities for immersive experiences and further research in 4D video creation.
Visual Insights#

🔼 This figure demonstrates the capabilities of Reangle-A-Video, a novel method for generating synchronized multi-view videos from a single monocular input video. Unlike traditional methods that require extensive multi-view training data, Reangle-A-Video leverages a single fine-tuning step of a pre-trained video generator. The figure showcases two scenarios: static view transport (left) and dynamic camera control (right). In static view transport, the model generates videos from various static viewpoints, while dynamic camera control allows generating videos that emulate different camera movements and trajectories. The first row displays the original input video, followed by rows showing Reangle-A-Video’s output videos for each scenario. Links to full video examples are provided.
read the caption
Figure 1: From a single monocular video of any scene, Reangle-A-Video generates synchronized videos from diverse camera viewpoints or movements without relying on any multi-view generative prior—using only single fine-tuning of a video generator. The first row shows the input video, while the rows below present videos generated by Reangle-A-Video. (Left): Static view transport results. (Right): Dynamic camera control results. Full video examples are available on our project page: hyeonho99.github.io/reangle-a-video
| Input video | Static view transport results | Input video | Dynamic camera control results | ||
|---|---|---|---|---|---|
| \animategraphics[loop, width=]12gallery/lion/input_jpeg/000048 | \animategraphics[loop, width=]12gallery/lion/horizontal+8_jpeg/000048 | \animategraphics[loop, width=]12gallery/lion/vertical+4_jpeg/000048 | \animategraphics[loop, width=]12gallery/train/input_jpeg/000048 | \animategraphics[loop, width=]12gallery/train/horizontal+0.2_jpeg/000048 | \animategraphics[loop, width=]12gallery/train/zoomout+0.2_jpeg/000048 |
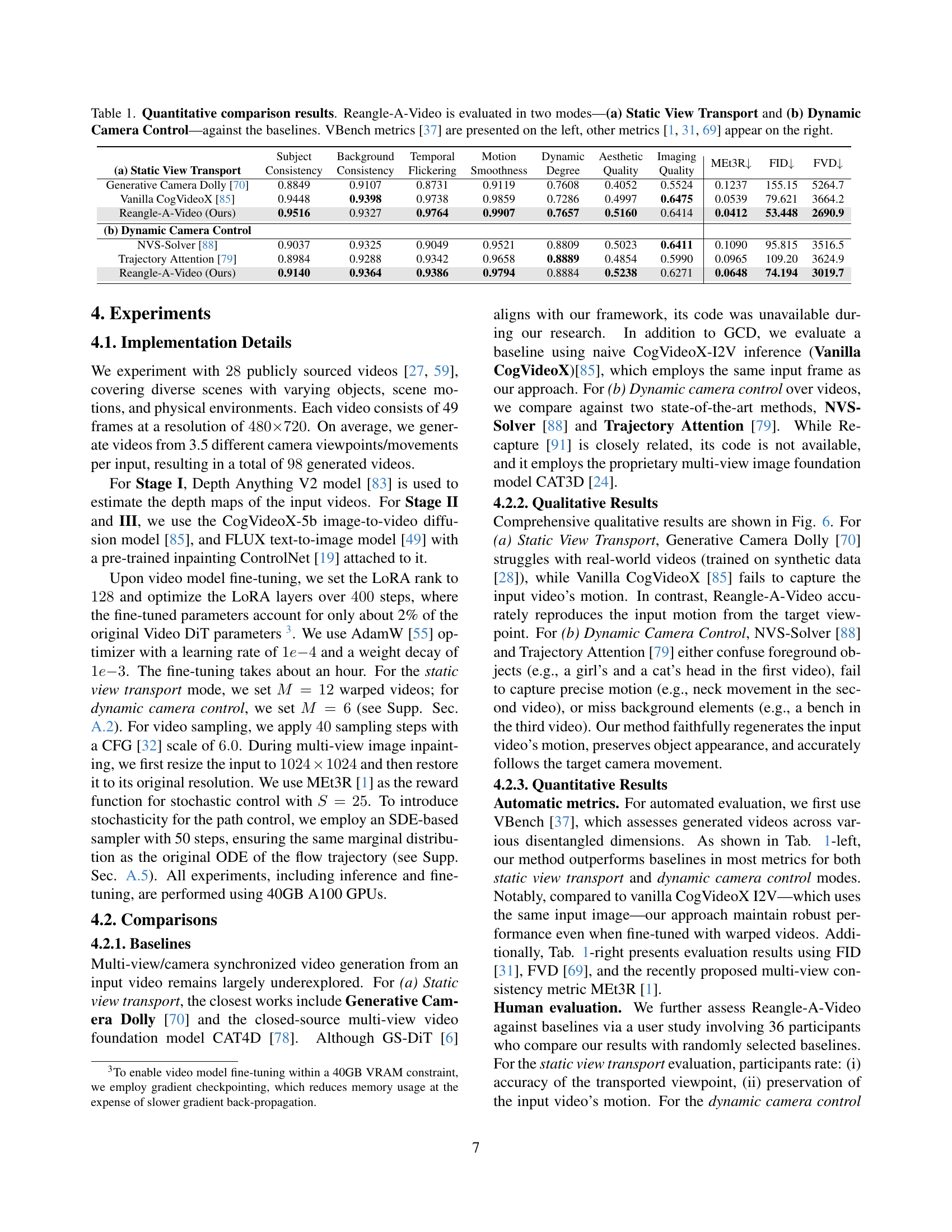
🔼 Table 1 presents a quantitative comparison of Reangle-A-Video’s performance against several baseline methods. The comparison is conducted across two distinct video generation modes: Static View Transport and Dynamic Camera Control. The table uses VBench metrics [37] for evaluating the videos’ quality, offering a comprehensive assessment from multiple perspectives. Alongside VBench, other established metrics ([1, 31, 69]) are used to provide a more holistic evaluation of the generated videos, considering factors like motion smoothness, aesthetic appeal, and overall quality.
read the caption
Table 1: Quantitative comparison results. Reangle-A-Video is evaluated in two modes—(a) Static View Transport and (b) Dynamic Camera Control—against the baselines. VBench metrics [37] are presented on the left, other metrics [1, 31, 69] appear on the right.
In-depth insights#
Video 2 Multi-View#
Generating multiple views from a single video is a challenging task, often framed as translating video to multi-view video. This requires addressing view-specific appearances and view-invariant motion. Methods can leverage pre-trained image and video diffusion models, augmenting training data with warped views to capture diverse perspectives. Consistency across views is crucial, and can be enforced during inference using techniques like stochastic control guidance and multi-view stereo reconstruction. Key challenges involve handling occlusions, geometric misalignments arising from depth estimation errors, and generating high-quality, consistent content in regions with small details or complex motion.
Motion Distillation#
Motion distillation focuses on transferring motion cues from one source to another, often involving a simpler representation. This process is crucial for various applications, including video editing, motion retargeting, and imitation learning. Key steps involve identifying salient motion features, encoding them into a compact form, and then applying them to a target, all while preserving visual fidelity. Motion distillation addresses the challenges of handling complex movements, occlusions, and variations in styles. Effective distillation can enable the creation of new animations, the improvement of existing video sequences, and the development of more realistic and controllable virtual characters. By distilling essential motion information, models become more efficient and generalize better to unseen scenarios, making it a core technique in modern computer graphics and AI.
Cross-View Stereo#
Cross-view stereo (CVS) is a crucial technique in computer vision, enabling 3D scene reconstruction and novel view synthesis from multiple viewpoints. It addresses the challenge of establishing correspondences between images captured from different perspectives, a task complicated by occlusions, varying illumination, and geometric distortions. Accurate CVS is essential for applications like autonomous navigation, virtual reality, and 3D modeling. Traditional approaches rely on handcrafted features and geometric constraints, while modern methods leverage deep learning to learn robust feature representations and handle complex scene geometry. A key aspect of CVS is dealing with occlusions, as points visible in one view may be hidden in another. Robust matching algorithms and occlusion reasoning techniques are vital for accurate reconstruction. Furthermore, the quality of the input images and the baseline between viewpoints significantly impact the performance of CVS. Recent research focuses on improving the robustness and efficiency of CVS algorithms, enabling real-time applications and handling large-scale scenes. Deep learning-based approaches have shown promising results, learning powerful feature representations and handling complex scene geometry. However, challenges remain in accurately reconstructing texture-less regions and handling extreme viewpoint changes.
Few-Shot Tuning#
Few-shot tuning represents a pragmatic approach to adapting pre-trained models to specific tasks with limited data. It leverages transfer learning, capitalizing on knowledge acquired during pre-training to achieve reasonable performance even with scarce task-specific examples. The efficacy of few-shot tuning hinges on the similarity between the pre-training data distribution and the target task distribution. Careful selection of pre-trained models and appropriate tuning strategies, like LoRA, are crucial for success. Overfitting is a significant challenge, necessitating regularization techniques. Despite its limitations, few-shot tuning offers a practical solution for scenarios where acquiring large labeled datasets is infeasible or costly.
Depth Bottleneck#
While not explicitly mentioned, a “depth bottleneck” in video generation, especially in multi-view scenarios, likely refers to the limitations imposed by inaccurate or incomplete depth information. This is critical because methods relying on estimated depth for warping or 3D reasoning are inherently susceptible to errors. Inaccurate depth maps distort the warping process, leading to geometric inconsistencies and artifacts, as illustrated in the provided failure cases. This bottleneck can manifest as misalignment between views, inconsistent object shapes, and difficulties in handling occlusions. Moreover, the reliance on estimated depth restricts the model’s ability to accurately represent complex 3D structures and dynamic scenes, hindering the generation of realistic and coherent multi-view videos. Alleviating this bottleneck necessitates more robust depth estimation techniques, potentially through incorporating multi-view cues or leveraging advanced neural architectures, and exploring methods to handle depth uncertainty during the generation process.
More visual insights#
More on figures

🔼 This figure displays qualitative results of the Reangle-A-Video model. The left side shows examples of static view transport, where the model generates videos from different viewpoints of the same scene. The right side shows examples of dynamic camera control, where the model generates videos simulating various camera movements, such as orbiting and zooming. The videos can be played using Adobe Acrobat Reader.
read the caption
Figure 2: Qualitative results on static view transport (left) & dynamic camera control (right). Click with Acrobat Reader to play videos.

🔼 This figure illustrates the training process for Reangle-A-Video’s two main functionalities: static view transport and dynamic camera control. It shows how a pre-trained Multi-modal Diffusion Transformer (MM-DiT) video model is fine-tuned using a self-supervised approach. The method leverages visible pixels from warped videos to learn view-invariant motion, optimizing only the Low-Rank Adaptation (LoRA) layers for efficient training. The few-shot nature of this training allows for lightweight model adaptation.
read the caption
Figure 3: Multi-view motion learning pipelines for (a) Static view transport and (b) Dynamic camera control. For both tasks, we distill view-robust motion of the underlying scene to a pre-trained MM-DiT video model [85], using all visible pixels within the sampled videos. This few-shot, self-supervised training optimizes only the LoRA layers [35, 62], enabling lightweight training.

🔼 This figure illustrates the process of multi-view consistent image inpainting, a crucial step in generating synchronized multi-view videos. The method uses stochastic control guidance to ensure consistency across different viewpoints. Starting with warped first frames (representing the scene from various perspectives), the algorithm iteratively inpaints these images, utilizing a diffusion model. At each step, multiple (in this case, 25) sample paths are generated, and a multi-view consistency evaluation selects the best option, promoting coherence between the inpainted images from various viewpoints. The final output is a set of consistent starting images for the next video generation stage.
read the caption
Figure 4: Multi-view consistent image inpainting using stochastic control guidance. In experiments, we set S=25𝑆25S=25italic_S = 25.

🔼 This figure compares the results of two different image inpainting methods: naive inpainting (which processes each warped image independently) and inpainting with stochastic control guidance (which uses a multi-view stereo reconstruction network to enforce consistency across multiple views). The comparison highlights the improved cross-view consistency achieved by the stochastic control guidance method, leading to more realistic and coherent inpainted images.
read the caption
Figure 5: Qualitative inpainting comparisons. We compare naive inpainting to inpainting with stochastic control guidance.

🔼 Figure 6 presents a qualitative comparison of video generation results for static view transport and dynamic camera control. The top half shows results for static view transport, where the goal is to generate views from different static viewpoints. The bottom half shows dynamic camera control results, generating videos with dynamic camera movements. Each section is organized with the input video in the first row, followed by generated videos from two target viewpoints (camera 1 and camera 2) for each method (Reangle-A-Video and baselines). Consistent camera parameters were used across all baseline methods for a fair comparison. For higher-quality video results, please visit the project page linked in the paper.
read the caption
Figure 6: Qualitative comparisons. Top half shows (a) Static view transport and bottom half presents (b) Dynamic camera control results. The first row in each half displays the input videos, and for each input video, two generated videos corresponding to target cameras (1 and 2) are shown for each method. Across baseline, same camera parameters were used for each 1,2. Visit our page for full-video results.

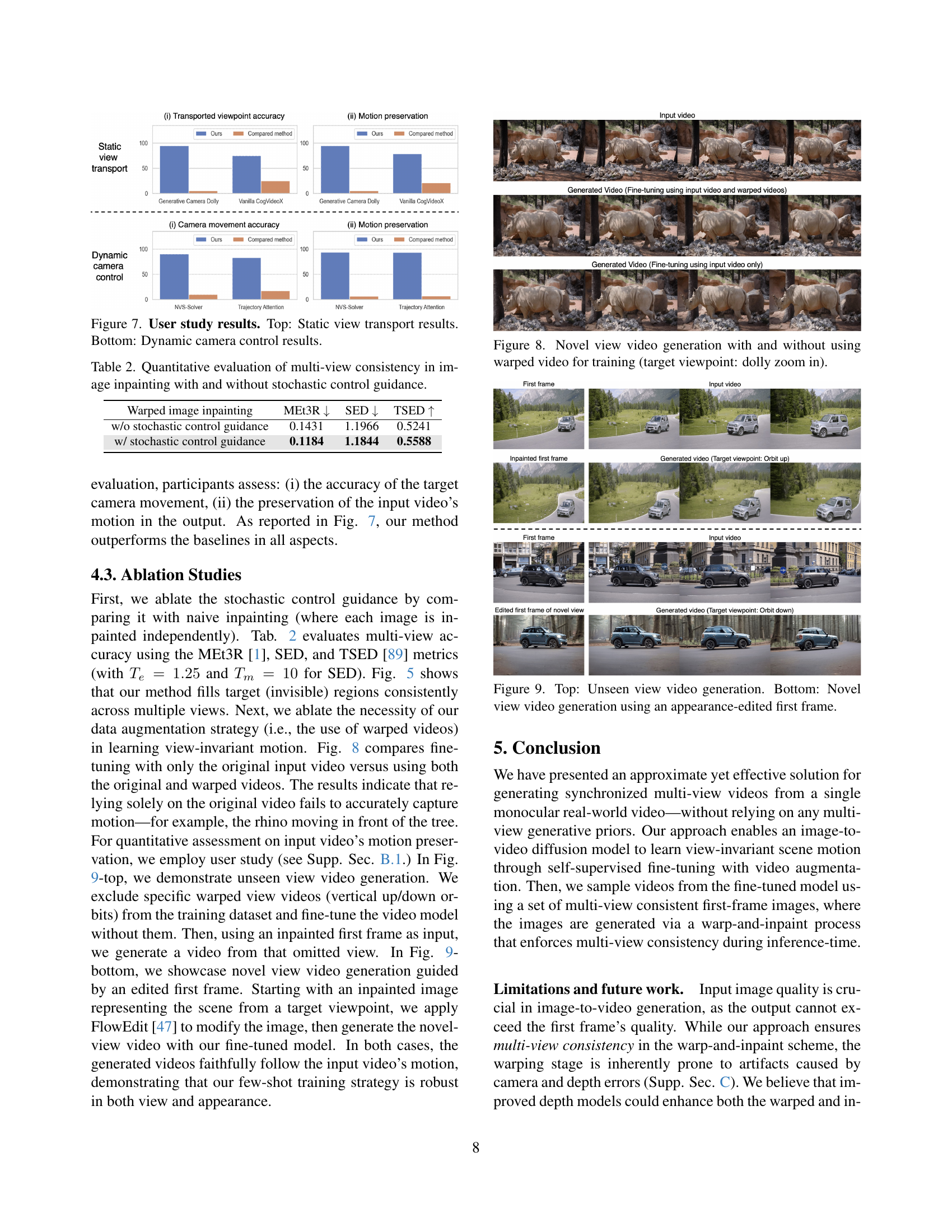
🔼 This figure presents the results of a user study comparing the performance of Reangle-A-Video against baseline methods in two scenarios: static view transport and dynamic camera control. The top half shows the results for static view transport, where users rated the accuracy of the transported viewpoint and how well the generated video preserved the input video’s motion. The bottom half shows the results for dynamic camera control, where users rated the accuracy of the target camera movement and the preservation of the input video’s motion in the generated videos. The bar charts illustrate the relative performance of different methods.
read the caption
Figure 7: User study results. Top: Static view transport results. Bottom: Dynamic camera control results.

🔼 This figure demonstrates the impact of using warped videos during training on novel view video generation. The ‘dolly zoom in’ perspective is used as the target viewpoint. The left-hand side shows results when warped videos were not included in training; the right-hand side shows the results when warped videos were included. The comparison highlights the improved accuracy and quality achieved by incorporating warped videos in the training process. This is particularly evident in the clarity and consistency of the generated videos.
read the caption
Figure 8: Novel view video generation with and without using warped video for training (target viewpoint: dolly zoom in).

🔼 This figure demonstrates the robustness of Reangle-A-Video’s few-shot training strategy. The top row shows unseen view video generation, where the model is trained without specific warped views (vertical up/down orbits) and then generates a video from that omitted view using an inpainted first frame as input. The bottom row illustrates novel view video generation using an appearance-edited first frame. The input video’s first frame is modified using FlowEdit, and a novel-view video is generated using the fine-tuned model. Both scenarios showcase the model’s ability to generate videos from views and appearances not seen during training, highlighting its generalization capability and robustness.
read the caption
Figure 9: Top: Unseen view video generation. Bottom: Novel view video generation using an appearance-edited first frame.

🔼 This figure visualizes the six different camera movements used in the paper’s experiments. These movements provide six degrees of freedom, enabling diverse viewpoints and camera trajectories. The visualization shows examples of static view transport (orbit left, orbit right, orbit up, orbit down, dolly zoom in, dolly zoom out) and dynamic camera control using similar camera movements.
read the caption
Figure 10: Visualizations of the used camera types.

🔼 This figure illustrates how the visibility masks are downsampled temporally for processing efficiency. The original visibility masks (which indicate visible and invisible regions in the video frames) have a high temporal resolution. To reduce computational complexity, the algorithm downsamples these masks. It retains the first mask frame unchanged. For every subsequent set of four mask frames, it performs an element-wise logical AND operation. This means that a pixel will only be marked as ‘visible’ in the downsampled mask if it is visible in all four of the corresponding original frames. This process effectively compresses the temporal dimension of the visibility masks, simplifying processing while preserving essential information about visibility over time.
read the caption
Figure 11: Temporal downsampling of visibility masks. Except for the first mask frame, pixel-wise (element-wise) logical AND operation is done for every four masks.

🔼 This figure demonstrates a comparison of video generation results using a standard diffusion loss versus a masked diffusion loss. The left side shows videos generated with the standard diffusion loss, exhibiting noticeable artifacts. In contrast, the right side showcases videos produced with the masked diffusion loss, which effectively removes the artifacts, resulting in cleaner and higher-quality videos. The results highlight the effectiveness of using a masked diffusion loss in mitigating artifacts during the video generation process.
read the caption
Figure 12: Impact of masked diffusion loss on video quality. Masking the diffusion loss effectively prevents artifacts.

🔼 This figure demonstrates a failure case of the Reangle-A-Video model, specifically highlighting geometric misalignment during the warping process. The input video frame is warped to simulate a camera view shifted 10 degrees to the right. However, due to inaccuracies in depth estimation and/or camera parameters used in the warping procedure, the resulting warped frame exhibits noticeable geometric distortions and misalignments compared to the expected output.
read the caption
Figure 13: Geometric misalignment in the warped frame. In this example, the target camera view is shifted 10 degrees to the (horizontal orbit) right of the input frame.
Full paper#