TL;DR#
Video Detailed Captioning (VDC) is important for vision-language tasks but faces challenges in fine-grained alignment and human preference. Current models struggle to provide comprehensive captions, often favoring specific aspects and failing to align with human preferences. Existing VDC models are trained on synthetic captions, lacking real-world guidance, creating a crucial need for improved methods.
To fix the above issues, this paper introduces Cockatiel, a novel three-stage training pipeline that ensembles synthetic and human-aligned training data. First, a human-aligned caption quality scorer is used to select high-performing synthetic captions. Cockatiel-13B is then trained on this curated data, and finally, Cockatiel-8B is distilled for easier use. This approach achieves new state-of-the-art results on VDCSCORE, demonstrating improved dimension-balanced performance and better alignment with human preferences.
Key Takeaways#
Why does it matter?#
This paper is important for researchers by addressing limitations in VDC models related to fine-grained alignment and human preference. The Cockatiel framework provides a new approach and opens avenues for improving video understanding and generation tasks.
Visual Insights#

🔼 This figure illustrates the Cockatiel framework, a three-stage training pipeline designed to generate detailed video captions. Stage 1 involves curating a dataset by selecting high-quality synthetic captions that align with human preferences, using a human-aligned caption quality scorer. Stage 2 utilizes this curated dataset to train the Cockatiel-13B model, incorporating the strengths of various existing models. Stage 3 distills a smaller, more efficient model (Cockatiel-8B) from the Cockatiel-13B model. The figure showcases an example of a detailed video caption generated by Cockatiel-13B, highlighting its ability to accurately describe the various visual elements in a video clip. It also presents the improved performance of Cockatiel-13B compared to other state-of-the-art models on the VDCSCORE benchmark, demonstrating its enhanced accuracy and alignment with human preferences. The superior performance is attributed to Cockatiel’s ensemble approach which leverages both synthetic and human-aligned training.
read the caption
Figure 1: Cockatiel, a three-stage training pipeline that ensembles synthetic and human-aligned training. Cockatiel-13B are capable to generate detailed captions that consistently aligns with every visual element in the input video (top left). Furthermore, Cockatiel-13B achieves new state-of-the-art and considerable dimension-balanced performance on VDCSCORE while consistently voted as the most human-aligned models compared to baselines (right). The key contributor to these capabilities is the ensembling synthetic and human preferenced training, which infuses Cockatiel-13B with diverse strengths of leading VDC models and human preferences (bottom left).
| Model |
|
|
|
|
|
| ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ShareGPT4Video-8B [5] | 29.26/1.54 | 32.60/1.70 | 30.59/1.60 | 30.67/1.61 | 31.67/1.66 | 30.96/1.62 | ||||||||||||
| Vriptor [42] | 37.64/1.96 | 38.35/2.00 | 37.11/1.94 | 37.02/1.93 | 38.49/2.00 | 37.72/1.97 | ||||||||||||
| AuroraCap-7B [3] | 33.88/1.77 | 37.98/1.97 | 33.96/1.77 | 35.95/1.87 | 41.52/2.15 | 36.66/1.91 | ||||||||||||
| VideoChatGPT [31] | 33.19/1.74 | 35.68/1.87 | 33.77/1.76 | 33.54/1.75 | 34.70/1.81 | 34.18/1.79 | ||||||||||||
| Video-LLaVA [25] | 32.80/1.72 | 36.23/1.89 | 32.86/1.70 | 33.08/1.73 | 36.47/1.89 | 34.29/1.79 | ||||||||||||
| LLaMA-Vid [48] | 36.12/1.88 | 38.04/1.98 | 34.27/1.79 | 35.42/1.84 | 35.89/1.87 | 35.95/1.87 | ||||||||||||
| PLLaVA-7B [41] | 34.45/1.79 | 34.19/1.78 | 34.10/1.78 | 34.40/1.78 | 36.97/1.92 | 34.82/1.81 | ||||||||||||
| PLLaVA-13B [41] | 37.37/1.93 | 38.10/1.97 | 37.20/1.92 | 36.40/1.89 | 39.68/2.05 | 37.75/1.95 | ||||||||||||
| Idefics2-8B [18] | 25.36/1.36 | 34.38/1.78 | 31.80/1.66 | 31.73/1.65 | 31.49/1.63 | 30.95/1.62 | ||||||||||||
| VILA-v1.5-8B [26] | 39.74/2.06 | 39.29/2.04 | 39.84/2.06 | 40.85/2.11 | 42.80/2.21 | 40.50/2.10 | ||||||||||||
| VILA-v1.5-13B [26] | 41.81/2.16 | 40.18/2.08 | 42.27/2.18 | 42.27/2.18 | 43.26/2.23 | 41.96/2.17 | ||||||||||||
| NVILA-15B [29] | 31.69/1.64 | 40.83/2.11 | 32.80/1.71 | 33.45/1.74 | 42.04/2.17 | 36.16/1.87 | ||||||||||||
| VideoChat2-7B [22] | 31.94/1.68 | 40.23/2.08 | 34.88/1.82 | 34.93/1.82 | 40.48/2.11 | 36.49/1.90 | ||||||||||||
| InternVL-v2.5-8B [7] | 34.36/1.81 | 42.25/2.19 | 37.58/1.95 | 38.23/1.99 | 42.99/2.22 | 39.08/2.03 | ||||||||||||
| LLaMA3.2-Vision-11B [32] | 33.62/1.74 | 35.66/1.83 | 35.44/1.83 | 34.80/1.80 | 36.77/1.90 | 35.26/1.82 | ||||||||||||
| InternVideo-v2.5 [37] | 31.37/1.65 | 39.60/2.05 | 32.57/1.70 | 35.19/1.84 | 38.47/1.99 | 35.44/1.85 | ||||||||||||
| mPLUG-Owl-Video [44] | 38.17/1.99 | 40.18/2.09 | 37.15/1.95 | 38.49/2.00 | 40.25/2.10 | 38.85/2.03 | ||||||||||||
| QwenVL-v2-8B [36] | 35.40/1.85 | 40.80/2.11 | 38.87/2.01 | 40.59/2.10 | 43.56/2.26 | 39.84/2.07 | ||||||||||||
| Aria-3.5Bx8 [20] | 39.84/2.07 | 38.61/2.01 | 38.97/2.02 | 43.21/2.23 | 45.36/2.33 | 41.20/2.13 | ||||||||||||
| LLaVA-OneVision-7B [19] | 37.57/1.96 | 41.65/2.15 | 34.31/1.79 | 38.81/2.02 | 41.81/2.16 | 38.83/2.02 | ||||||||||||
| LLaVA-Video-7B [48] | 38.73/2.02 | 43.75/2.26 | 37.50/1.95 | 41.71/2.16 | 45.56/2.35 | 41.45/2.15 | ||||||||||||
| Cockatiel-8B (Distilled) | 42.25/2.19 | 44.01/2.27 | 43.89/2.26 | 43.85/2.26 | 44.00/2.27 | 43.60/2.25 | ||||||||||||
| Cockatiel-13B | 42.62/2.21 | 43.45/2.25 | 44.13/2.28 | 44.37/2.29 | 44.42/2.29 | 43.80/2.26 |
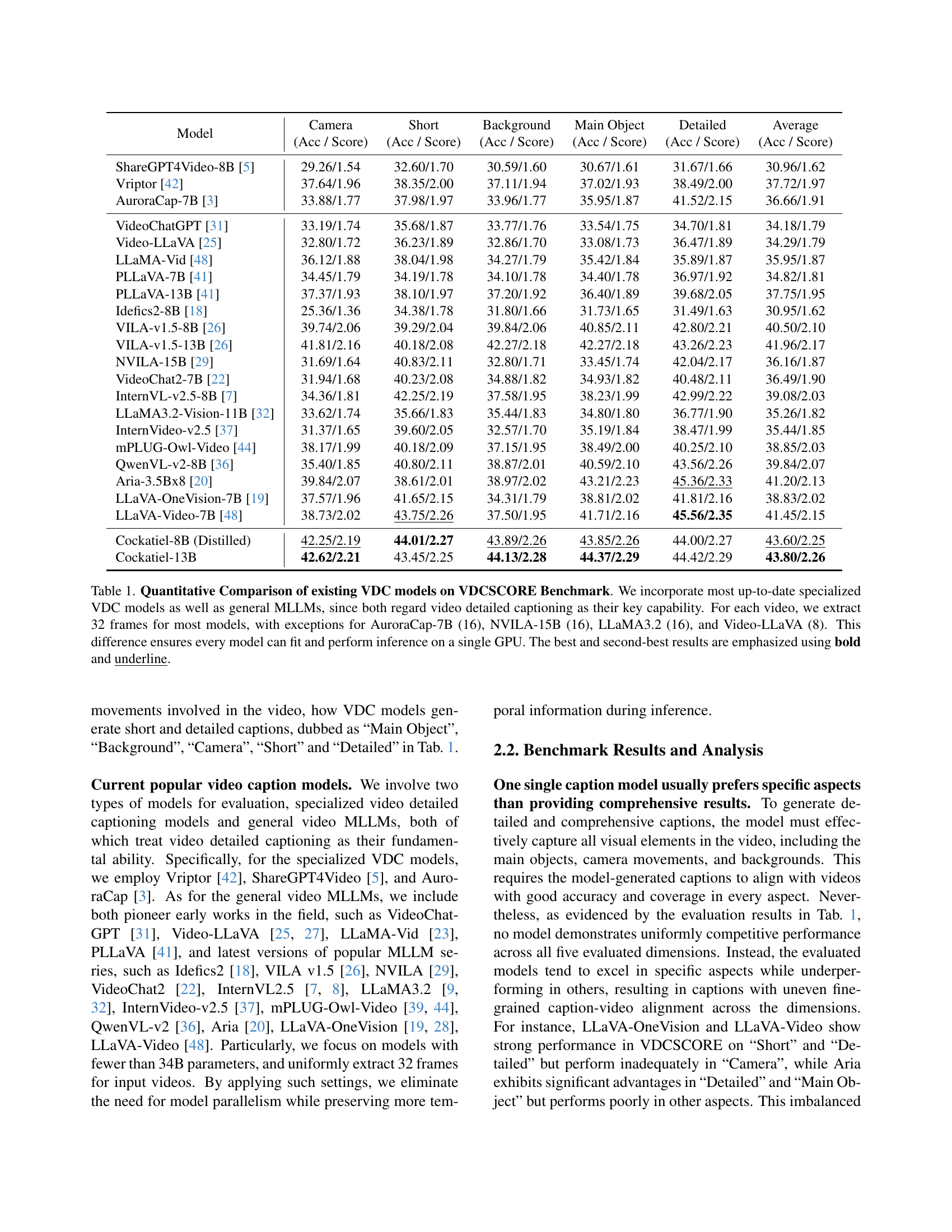
🔼 Table 1 presents a quantitative comparison of various Video Detailed Captioning (VDC) models using the VDCSCORE benchmark. It includes both specialized VDC models and general-purpose large language models (MLLMs) that also have video captioning capabilities. The evaluation considers five aspects of video captioning: Camera, Short, Background, Main Object, and Detailed. For most models, 32 frames per video were used for evaluation; however, exceptions were made for AuroraCap-7B (16 frames), NVILA-15B (16 frames), LLaMA3.2 (16 frames), and Video-LLaVA (8 frames) to ensure all models could run on a single GPU. The table highlights the best and second-best performing models for each aspect and overall average performance.
read the caption
Table 1: Quantitative Comparison of existing VDC models on VDCSCORE Benchmark. We incorporate most up-to-date specialized VDC models as well as general MLLMs, since both regard video detailed captioning as their key capability. For each video, we extract 32 frames for most models, with exceptions for AuroraCap-7B (16), NVILA-15B (16), LLaMA3.2 (16), and Video-LLaVA (8). This difference ensures every model can fit and perform inference on a single GPU. The best and second-best results are emphasized using bold and underline.
In-depth insights#
VDC: Imbalance#
VDC (Video Detailed Captioning) imbalance refers to the challenge of creating captions that comprehensively and accurately describe all aspects of a video. Current models often excel in certain dimensions, such as identifying main objects, while neglecting others, such as background details or camera movements. This results in captions that are unevenly detailed, hindering a complete understanding of the video content. Addressing this imbalance requires strategies to encourage models to attend to all relevant visual elements and their relationships, potentially through novel training objectives or architectural designs that promote more balanced feature extraction and description.
Human Pref VDC#
The pursuit of “Human Pref VDC” (Human Preference Video Detailed Captioning) signifies a crucial shift towards aligning AI-generated content with human values and expectations. Current VDC models often prioritize technical accuracy over subjective human perception, leading to captions that, while factually correct, may lack the nuances, emotional resonance, or contextual understanding a human would provide. Achieving Human Pref VDC requires a multi-faceted approach, including incorporating human feedback into the training loop, developing robust metrics for evaluating subjective qualities like naturalness and engagingness, and addressing potential biases in human preferences. The challenge lies in quantifying and replicating the intricate cognitive processes humans employ when describing video content, considering factors like intent, emotional state, and cultural context. Successful Human Pref VDC models would not only generate more satisfying captions but also enhance the usability and trustworthiness of AI systems in various applications, from accessibility tools to content creation platforms.
VDC Ens. Train#
Video Detailed Captioning (VDC) Ensemble Training is a method of improving VDC models by combining the strengths of multiple models. This involves training a new model on the combined data of others, potentially enhancing its ability to generate more comprehensive, nuanced captions. This can lead to superior performance by leveraging diverse perspectives and capturing a wider range of visual details. It contrasts with training on a single model’s output, which might inherit biases and limitations.
Quality>Quantity#
The principle of prioritizing quality over quantity suggests focusing on the most impactful data for training. This implies that a smaller, carefully curated dataset can be more effective than a larger one with noise or irrelevant information. This is especially true in complex tasks like VDC, where subtle nuances and fine-grained details matter significantly. High-quality data allows the model to learn more accurate representations and generalize better to unseen examples. Therefore, investing in data curation and annotation to ensure quality is crucial. In essence, this principle highlights the importance of targeted and refined information.
Generalization#
Generalization is crucial for real-world applicability. The research addresses this by ensembling diverse models and human preferences, aiming for robust performance across varied scenarios. Synthetic data boosts breadth, while human alignment ensures relevance. This approach tackles domain shift, improving model transferability beyond the training set. Evaluating on diverse datasets validates its ability to handle unseen data effectively and avoid overfitting, achieving robust and reliable real-world performance. The combination of diverse models and human feedback helps the final model to generalize well.
More visual insights#
More on figures

🔼 The figure illustrates the three-stage training pipeline of the Cockatiel model for detailed video captioning. Stage 1 involves human-aligned data curation, using a human-aligned scorer to select high-quality synthetic captions based on various aspects such as main object, background, and camera movement. The selected captions are then used in Stage 2 for ensemble synthesized training of the Cockatiel-13B model. This stage combines the strengths of multiple existing models and incorporates human preferences. Finally, Stage 3 involves distilling a smaller, more efficient Cockatiel-8B model from the larger Cockatiel-13B model. This process results in a model that achieves state-of-the-art video detailed captioning (VDC) performance while also aligning better with human preferences.
read the caption
Figure 2: Overall pipeline of our proposed Cockatiel. Our training pipeline successfully ensemble both the advantages of base models and human preferences, yielding our Cockatiel captioner series. Through the ensembling synthetic and human preferenced training, Cockatiel-13B achieves significant VDC performance while being preferred by humans.

🔼 This figure presents a qualitative comparison of video detailed captions generated by the Cockatiel-13B model and state-of-the-art (SOTA) models. Specific examples highlight the model’s ability to generate captions aligning with fine-grained details in the video, including objects, actions, and background elements. Captions exclusively generated by Cockatiel-13B, those shared with other models, and those misaligned with the video content are color-coded in red, yellow, and green, respectively. For a more extensive comparison, refer to the supplementary materials.
read the caption
Figure 3: Qualitative comparison between Cockatiel-13B and the current sota VDC models. For a detailed comparison between Cockatiel-13B and all leading VDC models, please refer to the supplementary files. The caption content that is exclusively captured by our model, captured by our model and other baselines, or misaligned with the detailed visual elements in the videos are emphasized using red, yellow and green backgrounds.

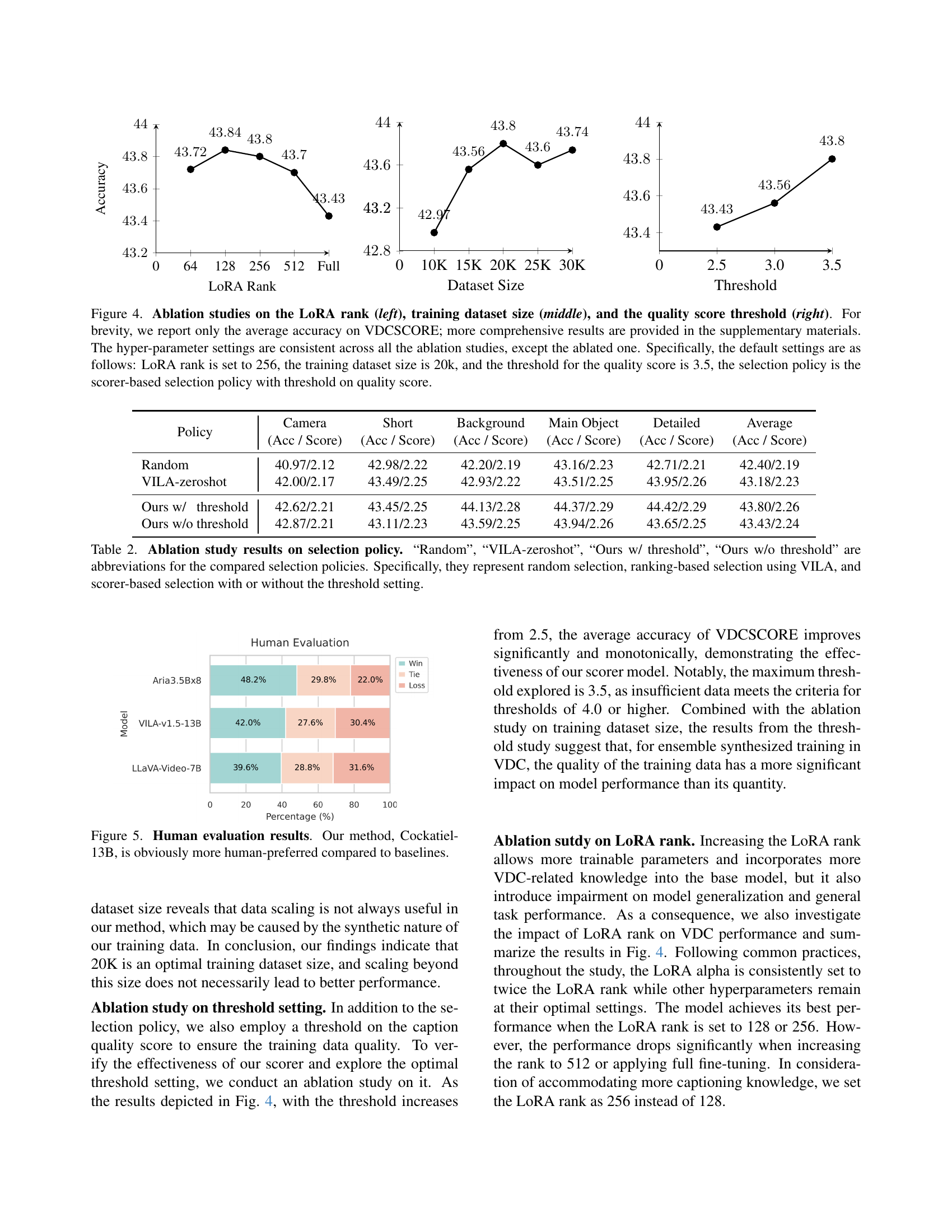
🔼 This figure presents the results of ablation studies conducted on three hyperparameters: LoRA rank, training dataset size, and quality score threshold. The leftmost graph shows the impact of varying LoRA rank on model accuracy, the middle graph displays how accuracy changes with different training dataset sizes, and the rightmost graph illustrates the effect of altering the quality score threshold. Only the average accuracy, as measured by the VDCSCORE metric, is shown in the main figure for brevity; more detailed results are available in the supplementary materials. For all experiments, only one hyperparameter was changed at a time, while the others were held constant at their default values: LoRA rank = 256, training dataset size = 20k, and quality score threshold = 3.5. The selection policy used was a scorer-based approach with a threshold applied to the quality score.
read the caption
Figure 4: Ablation studies on the LoRA rank (left), training dataset size (middle), and the quality score threshold (right). For brevity, we report only the average accuracy on VDCSCORE; more comprehensive results are provided in the supplementary materials. The hyper-parameter settings are consistent across all the ablation studies, except the ablated one. Specifically, the default settings are as follows: LoRA rank is set to 256, the training dataset size is 20k, and the threshold for the quality score is 3.5, the selection policy is the scorer-based selection policy with threshold on quality score.

🔼 This figure presents the results of a human evaluation comparing Cockatiel-13B to other state-of-the-art video detailed captioning models. The evaluation focused on human preference, assessing which model’s captions were deemed more aligned with human expectations. The results clearly show that Cockatiel-13B outperforms the other models, indicating its superior ability to generate human-preferred captions.
read the caption
Figure 5: Human evaluation results. Our method, Cockatiel-13B, is obviously more human-preferred compared to baselines.

🔼 This figure shows the user interface used for annotating video captions. The interface presents annotators with a video on the left, a caption to evaluate on top, and a question about the alignment of a specific visual element (object, object feature, object action, camera movement, or background) on the right. The visual element is indicated by a single letter code: O, F, A, C, or B. The annotators select the most appropriate score to rate how well the caption describes that element in the video. The design of the interface was praised for being user-friendly and intuitive, leading to high-quality annotations.
read the caption
Figure 6: A snapshot of our annotation user interface, where the whole annotation procedure is carried on. In each annotation task, the annotators are present with a video on the left, a caption supposed to align with it on the top, and a question related to the detailed video-caption alignment on the right of the user interface. “O”, “F”, “A”, “C”, “B” are abbreviations for “Object”, “object Feature”, “object Action”, “Camera” and “Background”, respectively. Notably, our user interface is highly praised by our annotators for its user-friendly and intuitive design, which ensures both the quality and quantity of the annotated data.

🔼 This figure illustrates the three-stage training pipeline for creating the human-aligned caption quality scorer used in the Cockatiel model. The first stage involves human annotators scoring the quality of captions generated by three different base models (VILA-v1.5-13B, LLaVA-Video-7B, and Aria-3.5Bx8) across five visual aspects: object, object feature, object action, camera movement, and background. The scores are used to train a scorer model, which is then used in the second stage for a selection policy. This policy chooses high-quality captions to train Cockatiel-13B, ensuring that the model learns from both the base models’ strengths and human preferences. The final stage involves distilling a smaller, faster version of the Cockatiel model (Cockatiel-8B) from the larger Cockatiel-13B model. The process emphasizes the creation of a human-aligned training dataset because no suitable pre-existing datasets or models were available.
read the caption
Figure 7: The training pipeline of our scorer. Our selection policy is critical as its performance determines which knowledge and strengths is ensembled into Cockatiel-13B. As a consequence, since our aim is to infuse Cockatiel-13B all the strengths of the base models and human preferences, we devise a selection policy with threshold setting based on our human-aligned caption quality scorer. To obtain our caption quality scorer, we need human-annotated data on it or off-the-shelf models. Since no publicly available dataset nor model suits this need, we build them on our own, as demonstrated in this figure.

🔼 This figure presents a qualitative comparison of video captions generated by the Cockatiel-13B model and three other state-of-the-art models (VILA-1.5-13B, LLaVA-Video-7B, and Aria-3.5Bx8). The comparison focuses on a specific video depicting a scenic valley with a train. Different color highlights are used to show which parts of the caption are uniquely generated by Cockatiel-13B, which parts are common to Cockatiel-13B and at least one other model, and which parts show misalignment with the video’s detailed visual elements. This allows for a visual assessment of the model’s ability to generate accurate and detailed video captions compared to existing models.
read the caption
Figure 8: The first qualitative case compared with three base models in the main content. The caption content that is exclusively captured by our model, captured by our model and other baselines, or misaligned with the detailed visual elements in the videos are emphasized using red, yellow and green backgrounds.
More on tables
| Camera |
| (Acc / Score) |
🔼 This table presents the results of an ablation study comparing different caption selection policies for training a video detailed captioning (VDC) model. The policies evaluated are: random selection, ranking-based selection using the VILA model, and scorer-based selection (with and without a threshold). The table shows the performance of each policy across various metrics, allowing for a comparison of their effectiveness in improving VDC model performance. The scorer-based methods incorporate human preferences into the caption selection process.
read the caption
Table 2: Ablation study results on selection policy. “Random”, “VILA-zeroshot”, “Ours w/ threshold”, “Ours w/o threshold” are abbreviations for the compared selection policies. Specifically, they represent random selection, ranking-based selection using VILA, and scorer-based selection with or without the threshold setting.
| Short |
| (Acc / Score) |
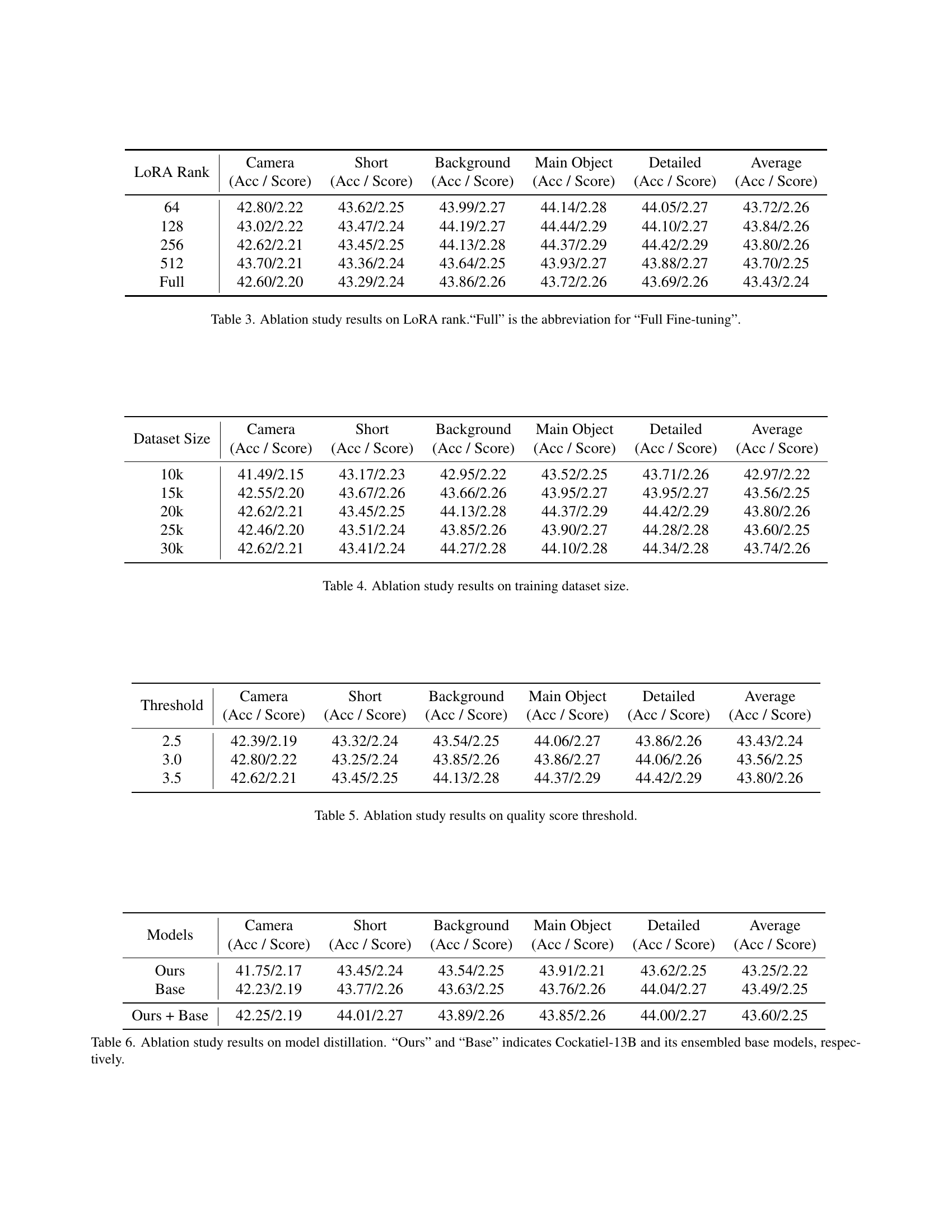
🔼 This ablation study investigates the impact of different LoRA ranks on the performance of the Cockatiel model. It compares the results using LoRA ranks of 64, 128, 256, 512, and full fine-tuning (denoted as ‘Full’). The table presents the accuracy and score achieved on five different aspects of video detailed captioning (Camera, Short, Background, Main Object, Detailed) and an average score across these aspects. The goal is to determine the optimal LoRA rank that balances model performance and computational efficiency.
read the caption
Table 3: Ablation study results on LoRA rank.“Full” is the abbreviation for “Full Fine-tuning”.
| Background |
| (Acc / Score) |
🔼 This table presents the results of an ablation study investigating the impact of training dataset size on the performance of the Cockatiel model. It shows the model’s accuracy (Acc) and score on the VDCSCORE benchmark across five dimensions (Camera, Short, Background, Main Object, Detailed) and the average performance across all dimensions. Different dataset sizes (10K, 15K, 20K, 25K, 30K) were used to train the model, and the table illustrates how performance changes with varying dataset size.
read the caption
Table 4: Ablation study results on training dataset size.
| Main Object |
| (Acc / Score) |
🔼 This table presents the results of an ablation study investigating the impact of varying the quality score threshold on the performance of the Cockatiel model. The study examines how changes in the threshold affect the model’s ability to generate video captions across different aspects of video detail (Camera, Short, Background, Main Object, Detailed), as measured by VDCSCORE. Each row represents a different threshold value, and the columns show the accuracy and score achieved at each threshold for the different aspects of caption detail, along with the overall average.
read the caption
Table 5: Ablation study results on quality score threshold.
| Detailed |
| (Acc / Score) |
🔼 This table presents the results of an ablation study on model distillation. It compares the performance of Cockatiel-13B (referred to as “Ours”), the ensemble of base models used to train Cockatiel-13B (“Base”), and a model trained by combining both Cockatiel-13B and the ensemble of base models (“Ours + Base”). The comparison is made across various metrics of video detailed captioning performance, including accuracy and scores for Camera, Short, Background, Main Object, Detailed, and Average. This shows the impact of using both ensembled base models and the larger Cockatiel-13B model in the distillation process.
read the caption
Table 6: Ablation study results on model distillation. “Ours” and “Base” indicates Cockatiel-13B and its ensembled base models, respectively.
Full paper#