TL;DR#
Video diffusion models face high computational costs due to the complexity of jointly modeling spatial and temporal distributions. Existing methods often suffer from error accumulation, increased inference time, or limited applicability across different diffusion forms. The redundancy between consecutive video frames is not efficiently utilized, leading to unnecessary computational overhead.
To address these challenges, TPDiff, a novel framework that enhances both training and inference efficiency. TPDiff progressively increases frame rates during the diffusion process, with the final stage operating at full frame rate. A stage-wise diffusion training framework aligns noise and data to train the model. Experiments demonstrate significant reductions in computational costs and improvements in inference speed.
Key Takeaways#
Why does it matter?#
This research offers a practical solution to the computational demands of video diffusion models, enabling researchers to develop more efficient and scalable generative models. The proposed framework opens new avenues for exploring temporal modeling and paves the way for high-quality video generation with reduced resource consumption.
Visual Insights#

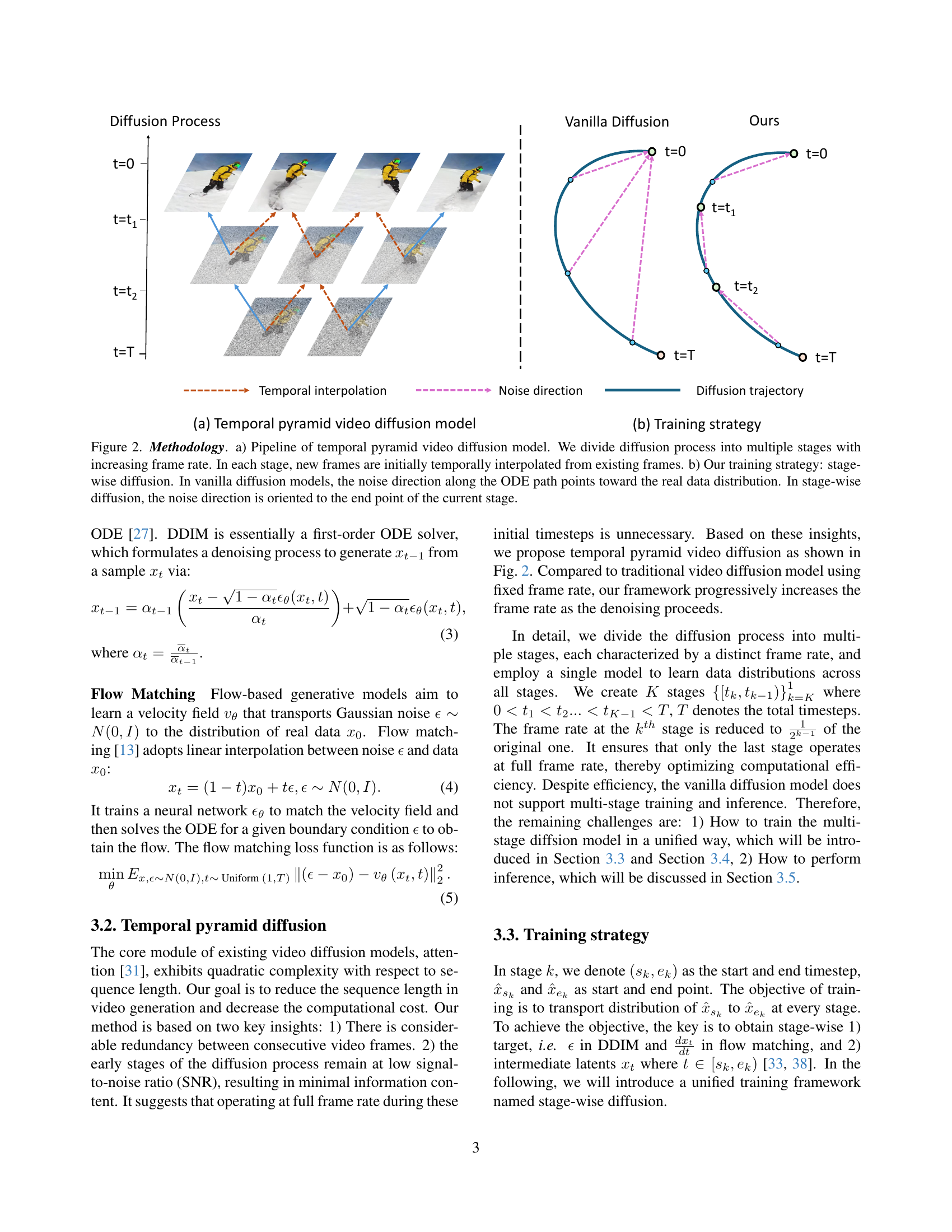
🔼 This figure illustrates the core concept of the Temporal Pyramid Video Diffusion Model (TPDiff). Panel (a) shows a traditional video diffusion model using a constant frame rate throughout the entire diffusion process, while panel (b) depicts the TPDiff approach. TPDiff progressively increases the frame rate across different stages of the diffusion process. Only the final stage operates at the full frame rate. This strategy significantly reduces computational costs during both training and inference. Panel (c) provides a quantitative comparison of training and inference efficiency between the vanilla video diffusion model and TPDiff, demonstrating the improved efficiency of the proposed method.
read the caption
Figure 1: Overview of our method. Our method employs progressive frame rates, which utilizes full frame rate only in the final stage as shown in (a) and (b), thereby largely optimizing computational efficiency in both training and inference shown in (c).
| Model | Method | Latency(s) | Speed up |
|---|---|---|---|
| MiniFlux-vid | Vanilla | 20.79 | - |
| Ours | 12.18 | 1.71x | |
| AnimateDiff | Vanilla | 6.01 | - |
| Ours | 4.04 | 1.49x |
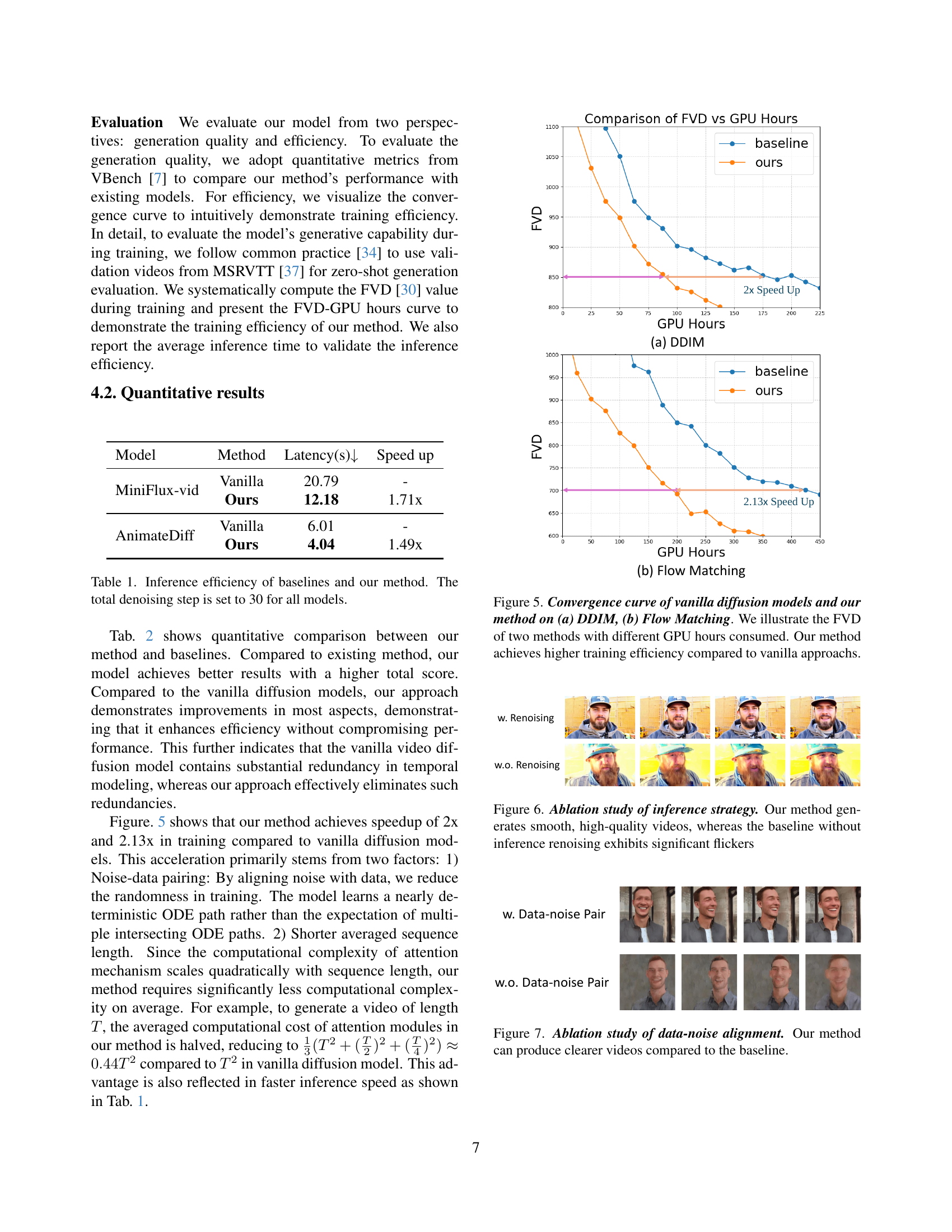
🔼 This table presents a comparison of the inference efficiency for various video generation models. It shows the latency (in seconds) required for inference and the speedup achieved by the proposed TPDiff model relative to the baseline models. The total number of denoising steps used for all models during inference is 30.
read the caption
Table 1: Inference efficiency of baselines and our method. The total denoising step is set to 30 for all models.
In-depth insights#
Entropy Reduction#
The concept of entropy reduction in the context of video diffusion models is intriguing. It suggests that the reverse diffusion process, responsible for generating coherent video frames from random noise, inherently reduces uncertainty. In the early stages of diffusion, the latents are high-entropy, containing minimal structured information. The key insight is that maintaining full frame rates at this stage is computationally wasteful. As the diffusion process progresses, the entropy decreases, and the video latents gradually acquire more structured content. Therefore, the computational resources should be focused on the later stages with high informative inter-frame relationships, operating on full frame rate. This entropy-reducing nature can be exploited to optimize training and inference efficiency in video diffusion models. By progressively increasing the frame rate alongside the denoising stages, the framework becomes more efficient, improving speed without compromising quality, which provides valuable optimization benefits during later stages.
Stage-wise Diff#
The ‘Stage-wise Diffusion’ approach is interesting as it aims to enhance training and inference by dividing the diffusion process into stages. Each stage seems to operate at a different frame rate, progressively increasing as the diffusion process advances. This is based on the insight that early diffusion steps have low signal-to-noise ratio, making full frame rates unnecessary. A key challenge is training this multi-stage model in a unified way, and the paper proposes a dedicated training framework to address this. By carefully managing frame rates across diffusion stages, it smartly optimizes computational efficiency during both training and generation.
Temporal Pyramid#
The temporal pyramid concept leverages video redundancy. Successive frames often exhibit minimal changes, and early diffusion steps have weak inter-frame dependencies due to low SNR. TPDiff progressively raises frame rates during denoising, focusing computational efforts on later, high-information stages. Unlike methods with separate temporal interpolation, TPDiff uses a single model for all rates by dividing the diffusion process. This stage-wise diffusion is trained by solving partitioned probability flow ODEs, aligning data and noise for versatile diffusion forms. Experiments show the framework’s applicability and improved efficiency.
Data-Noise Align#
Data-noise alignment is an innovative training technique to improve diffusion model convergence by pre-determining target noise distribution for each video. This alignment reduces training randomness by ensuring ODE paths are nearly deterministic, leading to faster convergence. This method mitigates boundary distribution shifts in multi-stage diffusion, where traditional techniques struggle to find a unified training target. By constraining the value of e within a narrow range, data-noise alignment helps model learn the desired noise characteristics more accurately, ultimately improving the efficiency of training process.
Multi-stage ODE#
Multi-stage ODEs could offer a novel approach to solving complex problems. By breaking down a problem into multiple stages, each with its own ODE, we can leverage the strengths of different numerical methods. Adaptive step-size control can be applied to each stage independently, leading to improved efficiency and accuracy. This approach also allows for parallelization, where each stage can be solved concurrently. The challenge lies in ensuring smooth transitions between stages and maintaining overall stability, as well as proper error estimation.
More visual insights#
More on figures

🔼 Figure 2 illustrates the methodology of the Temporal Pyramid Video Diffusion model (TPDiff). Part (a) shows the model’s pipeline, where the diffusion process is divided into multiple stages with progressively increasing frame rates. Within each stage, temporal interpolation is used to generate initial frames, enhancing efficiency. Part (b) contrasts the training strategies of TPDiff and traditional vanilla diffusion models. Vanilla diffusion models directly guide the noise direction along the ordinary differential equation (ODE) path toward the true data distribution. In contrast, TPDiff employs a stage-wise diffusion strategy where the noise direction in each stage is oriented towards the endpoint of that specific stage, improving training efficiency and making the training more stable and effective.
read the caption
Figure 2: Methodology. a) Pipeline of temporal pyramid video diffusion model. We divide diffusion process into multiple stages with increasing frame rate. In each stage, new frames are initially temporally interpolated from existing frames. b) Our training strategy: stage-wise diffusion. In vanilla diffusion models, the noise direction along the ODE path points toward the real data distribution. In stage-wise diffusion, the noise direction is oriented to the end point of the current stage.
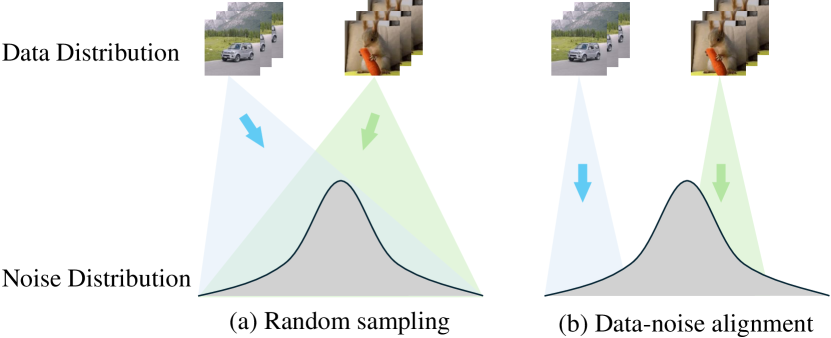
🔼 This figure illustrates the core concept behind data-noise alignment, a crucial aspect of the proposed training strategy. Panel (a) depicts the stochastic nature of vanilla diffusion training, where noise is sampled randomly across the entire noise distribution, leading to an ODE path that varies significantly across training iterations. Panel (b) shows that, in contrast, the proposed method uses data-noise alignment to select noise from a much smaller range that’s closest to the data. This ensures that the ODE path is far more deterministic and stable across training steps, resulting in improved training efficiency.
read the caption
Figure 3: Data-Noise Alignment. For every training sample, (a) vanilla diffusion training randomly samples noises across the entire noise distribution, resulting in stochastic ODE path during training. (b) In contrast, our method samples noises in the closest range, making the ODE path approximately deterministic during training.

🔼 This figure shows a qualitative comparison of video generation results between models trained with vanilla diffusion and the proposed TPDiff method. Each pair of videos presents a comparison; the top row displays the output from the vanilla diffusion model and the bottom row shows the output from TPDiff. The first two pairs were generated using the MiniFlux-vid model, while the remaining two pairs were generated using the AnimateDiff model. The figure demonstrates the visual differences in video quality, highlighting how TPDiff enhances the results.
read the caption
Figure 4: Qualitative comparison. In each pair of videos, the first row presents the results of models trained using vanilla diffusion and the second row shows the results of our method. The first two video pairs are generated by MiniFlux-vid and the remaining are generated by animatediff.

🔼 This figure displays the training efficiency of the proposed TPDiff model and vanilla diffusion models using two different diffusion methods: DDIM (denoising diffusion implicit models) and Flow Matching. The x-axis represents the GPU hours consumed during training, and the y-axis represents the Fréchet Video Distance (FVD), a metric that measures the quality of generated videos. Lower FVD values indicate better video quality. The plots show that for the same level of video quality (FVD), the TPDiff model requires significantly fewer GPU hours to train compared to vanilla diffusion methods for both DDIM and Flow Matching. This demonstrates the efficiency improvements achieved by the proposed TPDiff model.
read the caption
Figure 5: Convergence curve of vanilla diffusion models and our method on (a) DDIM, (b) Flow Matching. We illustrate the FVD of two methods with different GPU hours consumed. Our method achieves higher training efficiency compared to vanilla approachs.

🔼 This ablation study compares the video generation quality of the proposed method with and without the inference denoising step. The results show that the proposed method, with the inference denoising, generates smoother, higher-quality videos while the baseline without this step produces videos with significant flickering artifacts.
read the caption
Figure 6: Ablation study of inference strategy. Our method generates smooth, high-quality videos, whereas the baseline without inference renoising exhibits significant flickers

🔼 This ablation study compares video generation results with and without data-noise alignment. The figure shows that using data-noise alignment (our method) produces clearer videos compared to the baseline which does not use data-noise alignment, highlighting the importance of this technique in enhancing video quality.
read the caption
Figure 7: Ablation study of data-noise alignment. Our method can produce clearer videos compared to the baseline.

🔼 This figure compares video generation results from a vanilla diffusion model and the proposed TPDiff model after only 5000 training steps. The target video is a serene scene of a sunflower field. The key observation is that TPDiff produces temporally stable and coherent videos even in the early stages of training, whereas the vanilla diffusion model struggles to generate consistent video frames at this point.
read the caption
Figure 8: Comparison between vanilla diffusion and our method after 5000 training steps. Our method can generate temporally stable videos even at very early training steps while vanilla method cannot. The prompt is ”A serene scene of a sunflower field.”
More on tables
| Method | Total Score | Motion Smoothness | Object Class | Multiple Objects | Spatial Relationship |
|---|---|---|---|---|---|
| ModelScope [34] | 73.12% | 95.83% | 67.06% | 33.91% | 27.55% |
| OpenSora [20] | 74.08% | 91.97% | 78.30% | 30.69% | 41.11% |
| AnimateDiff - Vanilla | 73.65% | 96.28% | 81.34% | 39.42% | 43.23% |
| AnimateDiff - Ours | 74.96% | 97.68% | 86.77% | 31.15% | 56.62% |
| MiniFlux-vid - Vanilla | 77.69% | 98.34% | 77.32% | 36.26% | 49.79% |
| MiniFlux-vid - Ours | 78.52% | 98.96% | 83.21% | 43.18% | 42.23% |
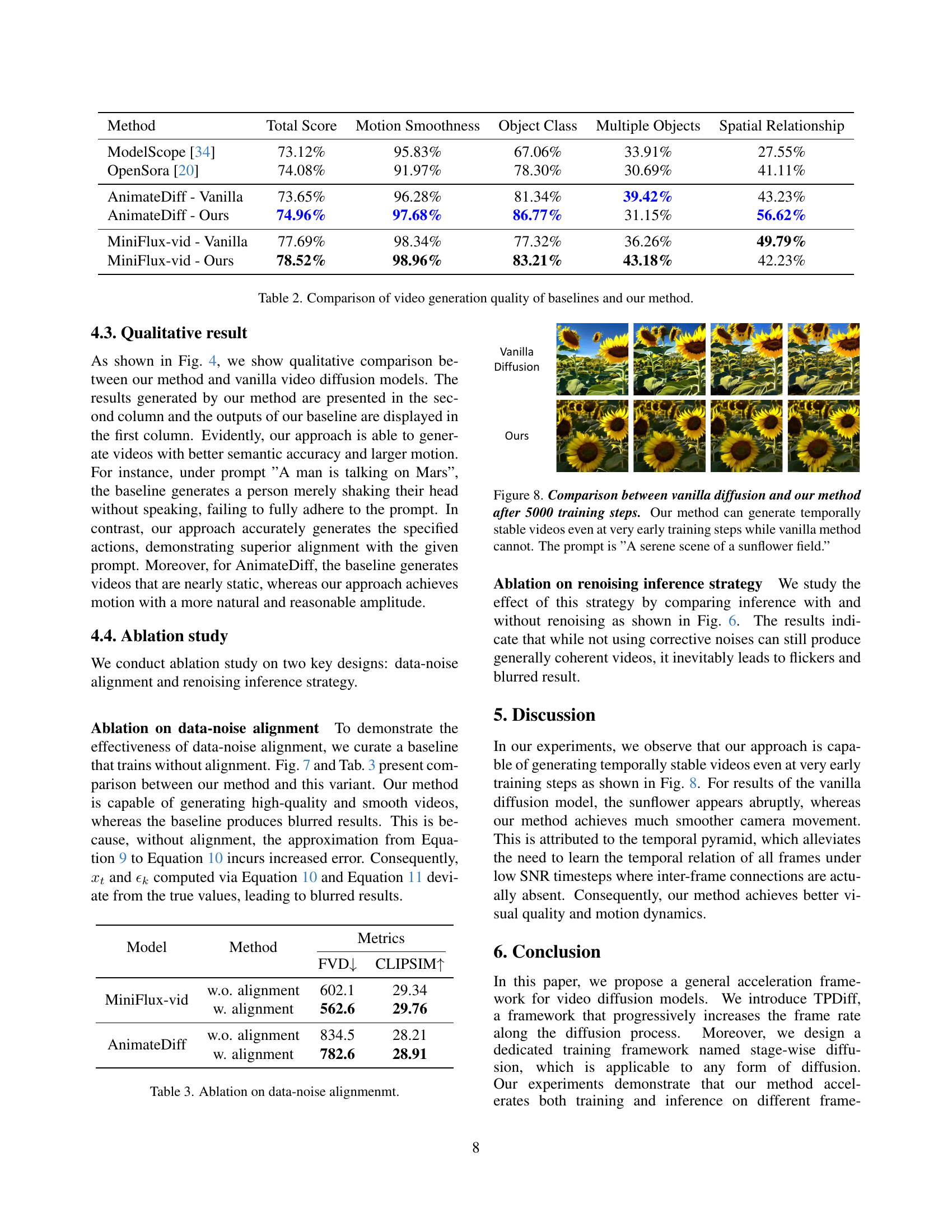
🔼 This table presents a quantitative comparison of video generation quality between several baselines and the proposed TPDiff method. The baselines include standard video diffusion models (trained without the temporal pyramid approach) using two different image models: MiniFlux-vid and AnimateDiff. The metrics used to evaluate video generation quality are: Total Score, Motion Smoothness, Object Class, Multiple Objects, and Spatial Relationship. Higher scores indicate better performance in each respective aspect of video generation quality.
read the caption
Table 2: Comparison of video generation quality of baselines and our method.
| Model | Method | Metrics | |
|---|---|---|---|
| FVD | CLIPSIM | ||
| MiniFlux-vid | w.o. alignment | 602.1 | 29.34 |
| w. alignment | 562.6 | 29.76 | |
| AnimateDiff | w.o. alignment | 834.5 | 28.21 |
| w. alignment | 782.6 | 28.91 | |
🔼 This table presents the results of an ablation study on the impact of data-noise alignment in the proposed video generation model. It compares the Fréchet Video Distance (FVD) and CLIP-SIM scores for the AnimateDiff and MiniFlux-vid models, both with and without data-noise alignment. Lower FVD indicates better generation quality, and higher CLIP-SIM suggests better semantic similarity between generated and real videos. The results demonstrate the positive impact of the data-noise alignment technique on video generation performance.
read the caption
Table 3: Ablation on data-noise alignmenmt.
Full paper#