TL;DR#
Video generation models have advanced rapidly, demanding larger models, more data, and greater compute. This paper addresses this by presenting Open-Sora 2.0, a commercial-level video generation model trained for only $200k. The model employs techniques like data curation, model architecture improvements, training strategy adjustments, and system optimization to achieve cost efficiency. Human evaluations and VBench scores show that Open-Sora 2.0 is comparable to top models like HunyuanVideo and Runway Gen-3 Alpha.
The authors detail their data strategy, including hierarchical filtering and annotation methods. The model architecture features a Video DC-AE autoencoder and DiT architecture. A cost-effective training methodology enables commercial-level quality at a low cost, with conditioning approaches including image-to-video and motion control. System optimizations maximize training efficiency. Open-Sora 2.0 outperforms other top models in visual quality, prompt adherence and motion quality, demonstrating its potential for commercial use.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a cost-effective approach to video generation, making high-quality video creation more accessible. The model’s open-source nature fosters innovation and opens new avenues for research in video generation, artifact prevention, and enhanced content control. The method’s efficiency optimization is highly relevant to current trends.
Visual Insights#

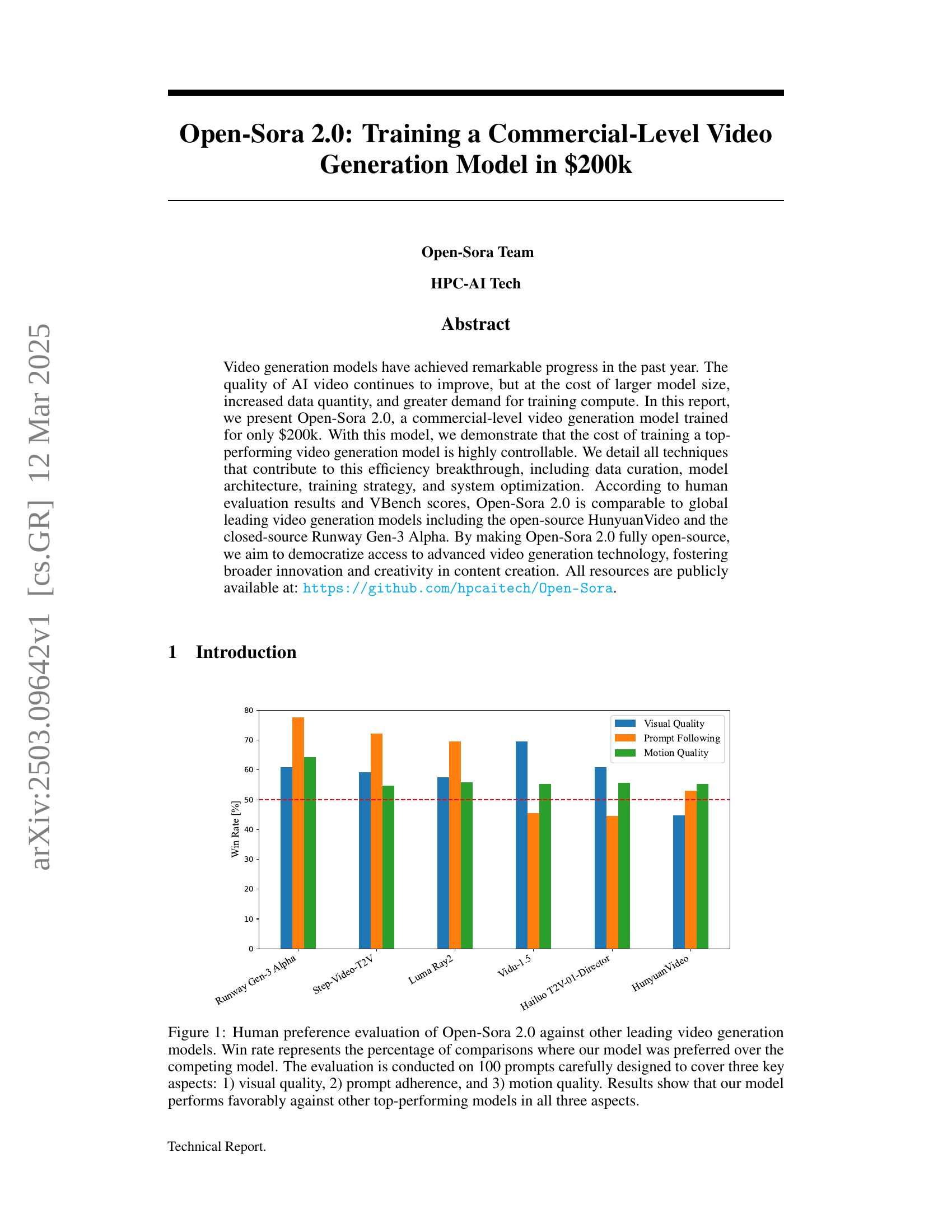
🔼 This figure displays the results of a human preference evaluation comparing Open-Sora 2.0’s video generation capabilities against several leading competitors. The evaluation involved 100 diverse prompts carefully selected to assess three key aspects of video generation: visual quality, prompt adherence (how well the generated video reflects the prompt), and motion quality (smoothness and realism of movement). The ‘win rate’ for Open-Sora 2.0 is presented as the percentage of times it was preferred over each competing model for each aspect. The results visually demonstrate that Open-Sora 2.0 performs favorably overall.
read the caption
Figure 1: Human preference evaluation of Open-Sora 2.0 against other leading video generation models. Win rate represents the percentage of comparisons where our model was preferred over the competing model. The evaluation is conducted on 100 prompts carefully designed to cover three key aspects: 1) visual quality, 2) prompt adherence, and 3) motion quality. Results show that our model performs favorably against other top-performing models in all three aspects.
| Model | Down. (TxHxW) | Info. Down. | Channel | Causal | LPIPS↓ | PSNR↑ | SSIM↑ |
| Open Sora 1.2 [zheng2024open] | 192 | 4 | 0.161 | 27.504 | 0.756 | ||
| StepVideo VAE [ma2025step] | 96 | 64 | 0.082 | 28.719 | 0.818 | ||
| HunyuanVideo VAE [kong2024hunyuanvideo] | 48 | 16 | 0.046 | 30.240 | 0.856 | ||
| Video DC-AE | 96 | 128 | 0.051 | 30.538 | 0.863 | ||
| Video DC-AE | 48 | 256 | 0.049 | 30.777 | 0.872 |
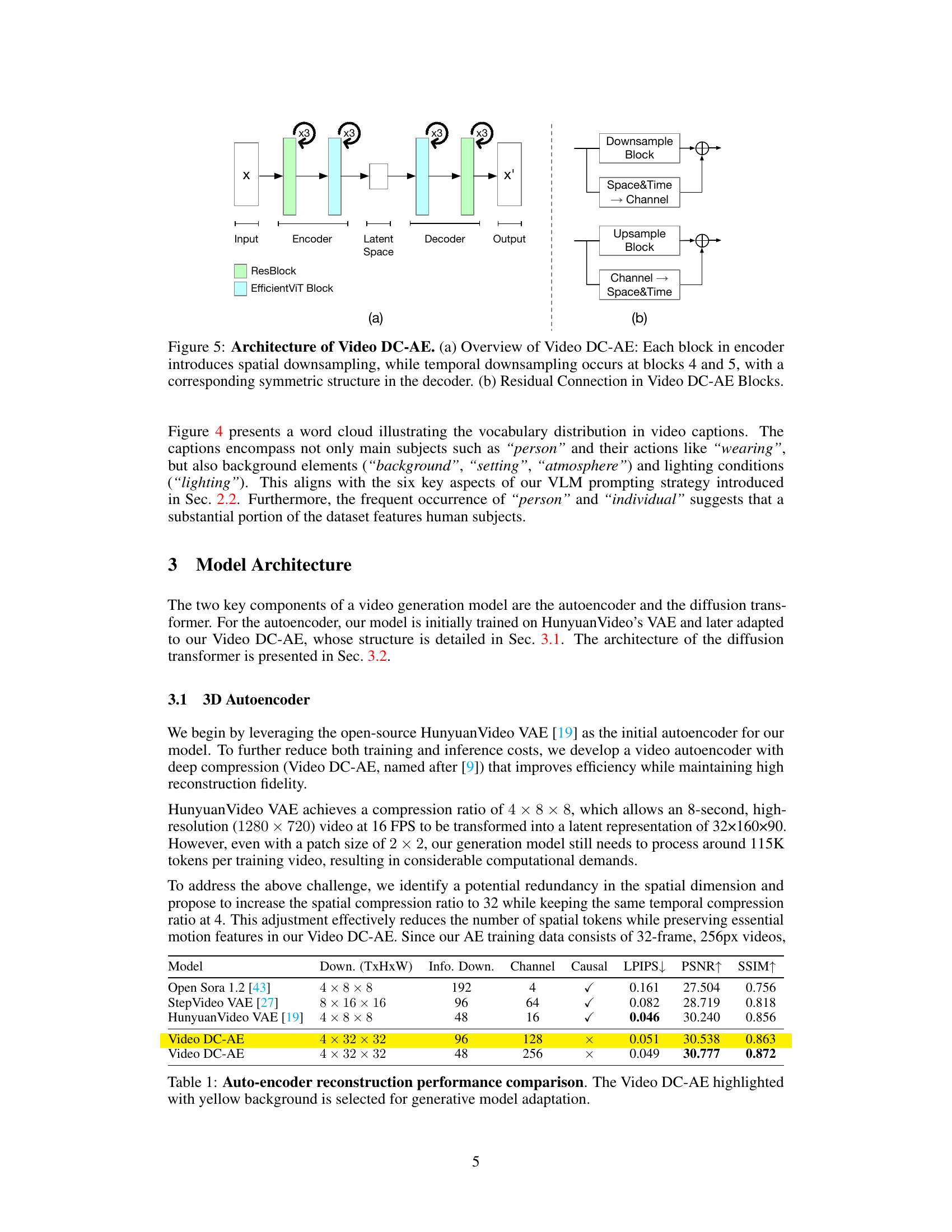
🔼 This table compares the reconstruction performance of several autoencoders, including the Hunyuan Video VAE, StepVideo VAE, Open Sora 1.2, and the proposed Video DC-AE. The metrics used for comparison are LPIPS, PSNR, and SSIM, all of which evaluate the quality of the reconstruction. The table highlights the superior performance of Video DC-AE, especially the model with 4 x 32 x 32 downsampling and 256 channels, which is chosen for adaptation in the video generation model. The choice is indicated visually by a yellow background highlighting the superior row.
read the caption
Table 1: Auto-encoder reconstruction performance comparison. The Video DC-AE highlighted with yellow background is selected for generative model adaptation.
In-depth insights#
Cost-Eff. Training#
A cost-effective training strategy is crucial for democratizing access to video generation. The Open-Sora paper tackles this by focusing on four key aspects: leveraging open-source image models for pre-training to accelerate video model training and avoid the expense of training an image model from scratch; using high-quality data that enhance training efficiency by prioritizing a curated subset and implementing strict selection for superior video quality; learning motion in low-resolution to reduce the cost of training with 256px resolution videos, allowing the model to efficiently learn diverse motion patterns; utilizing image-to-video model that focuses more on motion generation and minimizes the need for expensive high-resolution computations.
DC-AE Details#
Video DC-AE builds upon established techniques. Chen et al’s DC-AE approach, focusing on high downsampling while retaining reconstruction fidelity, guides their architectural choices. Unlike the original DC-AE primarily for images, temporal compression is added through 3D operations and temporal up/downsampling in specific encoder/decoder blocks. Addressing gradient propagation issues during training, special residual blocks are incorporated. The model’s performance is evaluated with comparisons to existing autoencoders like HunyuanVideo VAE and Step Video VAE.
Scaling Guidance#
The paper introduces a dynamic image guidance scaling strategy to balance image and text guidance during video generation. Since image condition primarily applies to the first frame, stronger image guidance is needed for later frames to maintain coherence. Conversely, as denoising progresses, the video scene solidifies, diminishing the need for image guidance. To address flickering, the paper alternates the image guidance scale during denoising. Dynamic adjustment of gimg based on frame index and denoising step optimizes both motion fidelity and semantic accuracy. This balances stability and motion consistency.
Multi-Bucket Training#
Multi-bucket training is a valuable technique for handling diverse data within the same batch, improving GPU utilization. By dynamically assigning batch sizes based on video characteristics such as frame count, resolution, and aspect ratio, it optimizes resource allocation. The process involves identifying the maximum batch size that avoids out-of-memory errors and adjusting other batch sizes accordingly, while also enforcing constraints on execution time. This strategy ensures efficient and scalable training across diverse video data distributions, maximizing hardware efficiency and improving overall training performance.
Future AE Work#
Future work in autoencoder (AE) development for video generation should prioritize optimizing latent space structures, as current training frameworks struggle when channel sizes increase. While reconstruction ability is important, a well-structured latent space is more critical for effective video synthesis. High-compression AEs trained at low resolutions experience performance degradation when reconstructing high-resolution videos [9]. Although we could have fine-tuned the Video DC-AE at high resolutions, we re-use the tiling code by Kong et al. [19] to save training resources. Additionally, Designing high-throughput autoencoders to mitigate the computational bottleneck in generation models using high-compression is essential. These improvements would pave the way for higher-quality, more efficient end-to-end video generation, particularly for high-resolution videos containing substantial redundancy.
More visual insights#
More on figures

🔼 The figure illustrates the hierarchical data filtering pipeline used for video data preprocessing. Raw videos are initially transformed into shorter, trainable video clips. Then, a series of complementary filters are sequentially applied. These filters assess different aspects of video quality (aesthetic score, motion score, blurriness, presence of text, and camera jitter) and progressively remove lower-quality data. This process creates a data pyramid with smaller, higher-quality datasets at each stage that are then used for different phases of the video generation model training.
read the caption
Figure 2: The hierarchical data filtering pipeline. The raw videos are first transformed into trainable video clips. Then, we apply various complimentary score filters to obtain data subsets for each training stage.

🔼 This figure presents the distribution of key attributes within the video dataset used to train the Open-Sora 2.0 video generation model. It showcases the statistical distribution of aesthetic scores (a measure of visual appeal), video durations (in seconds), aspect ratios (the ratio of video height to width), and caption lengths (number of words in the video descriptions). The distributions are visualized using pie charts, giving a clear overview of the data characteristics.
read the caption
Figure 3: Distribution of key attributes of the whole video dataset.

🔼 This word cloud visualizes the most frequent words appearing in the video captions of the dataset used to train the Open-Sora 2.0 video generation model. It highlights the key themes and subjects prevalent within the videos, such as common objects (‘person’, ‘hand’, ‘clothing’), actions (‘wearing’, ‘standing’), settings (‘background’, ‘outdoor’), and atmospheric conditions (’lighting’, ‘atmosphere’). The prominence of words like ‘person’ and ‘individual’ indicates a significant portion of the videos contain human subjects.
read the caption
Figure 4: Word cloud of the video captions.

🔼 Figure 5 illustrates the architecture of the Video DC-AE (Deep Compression Autoencoder), a crucial component of the Open-Sora 2.0 video generation model. Part (a) provides a high-level overview of the encoder and decoder, highlighting the spatial and temporal downsampling strategies. The encoder progressively reduces the spatial and temporal resolution of the input video, while the decoder symmetrically reconstructs the video from the compressed representation. Noteworthy is that temporal downsampling is specifically applied in blocks 4 and 5 of the encoder, indicating a focus on efficient compression of temporal information. Part (b) zooms in on the residual connections within the Video DC-AE blocks. These connections are designed to facilitate efficient gradient propagation during training and to improve the autoencoder’s performance, especially at high compression ratios.
read the caption
Figure 5: Architecture of Video DC-AE. (a) Overview of Video DC-AE: Each block in encoder introduces spatial downsampling, while temporal downsampling occurs at blocks 4 and 5, with a corresponding symmetric structure in the decoder. (b) Residual Connection in Video DC-AE Blocks.
More on tables
| Double-Stream Layers | Single-Stream Layers | Model Dimension | FFN Dimension | Attention Heads | Patch Size |
| 19 | 38 | 3072 | 12288 | 24 | 2 |
🔼 This table details the hyperparameters of the Open-Sora 2.0 video generation model, specifically focusing on its architecture. It breaks down the model’s architecture into double-stream and single-stream layers, providing specifications for the model dimension, feed-forward network (FFN) dimension, number of attention heads, and patch size. This information is crucial for understanding the model’s structure and how its different components work together to generate videos.
read the caption
Table 2: Architecture hyperparameters for Open-Sora 2.0 11B parameter video generation model.
| Training Stage | Dataset | CP | #iters | #GPUs | #GPU day | USD |
| 256px T2V | 70M | 1 | 85k | 224 | 2240 | $107.5k |
| 256px T/I2V | 10M | 1 | 13k | 192 | 384 | $18.4k |
| 768px T/I2V | 5M | 4 | 13k | 192 | 1536 | $73.7k |
| Total | 4160 | $199.6k |
🔼 Table 3 details the training process of the Open-Sora 2.0 model, broken down into three stages. It shows the dataset size, number of training iterations, the number of GPUs used, the total GPU hours consumed, and the estimated cost for each stage. The costs are calculated based on a rental price of $2 per GPU hour for the H200 GPUs used in the training process. The final row shows the total cost across all three stages for a single training run.
read the caption
Table 3: Training Configurations and Cost Breakdown. This table presents the training configurations across different stages and the total cost for a single full training run, assuming the rental price of H200 is $2 per GPU hour.
| Model | #GPUs | GPU Hours | Cost (Single Run) |
| Movie Gen [polyak2024moviegen] | 6144 | 1.25M* | $2.5M* |
| Step-Video-T2V [ma2025step] | 2992* | 500k* | $1M* |
| Open Sora 2.0 | 224 | 100k | $200k |
🔼 This table compares the training costs of Open-Sora 2.0 with other leading video generation models. The cost for Open-Sora 2.0 was significantly lower than the others, ranging from 5 to 10 times less. Costs for some models are estimates based on publicly available data due to the lack of precise figures from the original sources. This highlights the cost-effectiveness of the Open-Sora 2.0 training process.
read the caption
Table 4: Training Cost Comparison of Different Video Generation Models. Values marked with * are estimated based on publicly available information. Our Open-Sora 2.0 is trained at 5–10× lower training cost.
| resolution | #frames | max #tokens | batch size | throughput on 8 GPUs |
| 256px | 5 to 33 | 2304 | 12 | 12.7 videos/s |
| 37 to 65 | 4352 | 6 | 6.3 videos/s | |
| 69 to 97 | 6400 | 4 | 4.2 videos/s | |
| 101 to 129 | 8448 | 3 | 3.2 videos/s | |
| 256px | 1 | 256 | 45 | 47.6 images/s |
| 768px | 1 | 2304 | 13 | 13.8 images/s |
| 1024px | 1 | 4096 | 7 | 7.4 images/s |
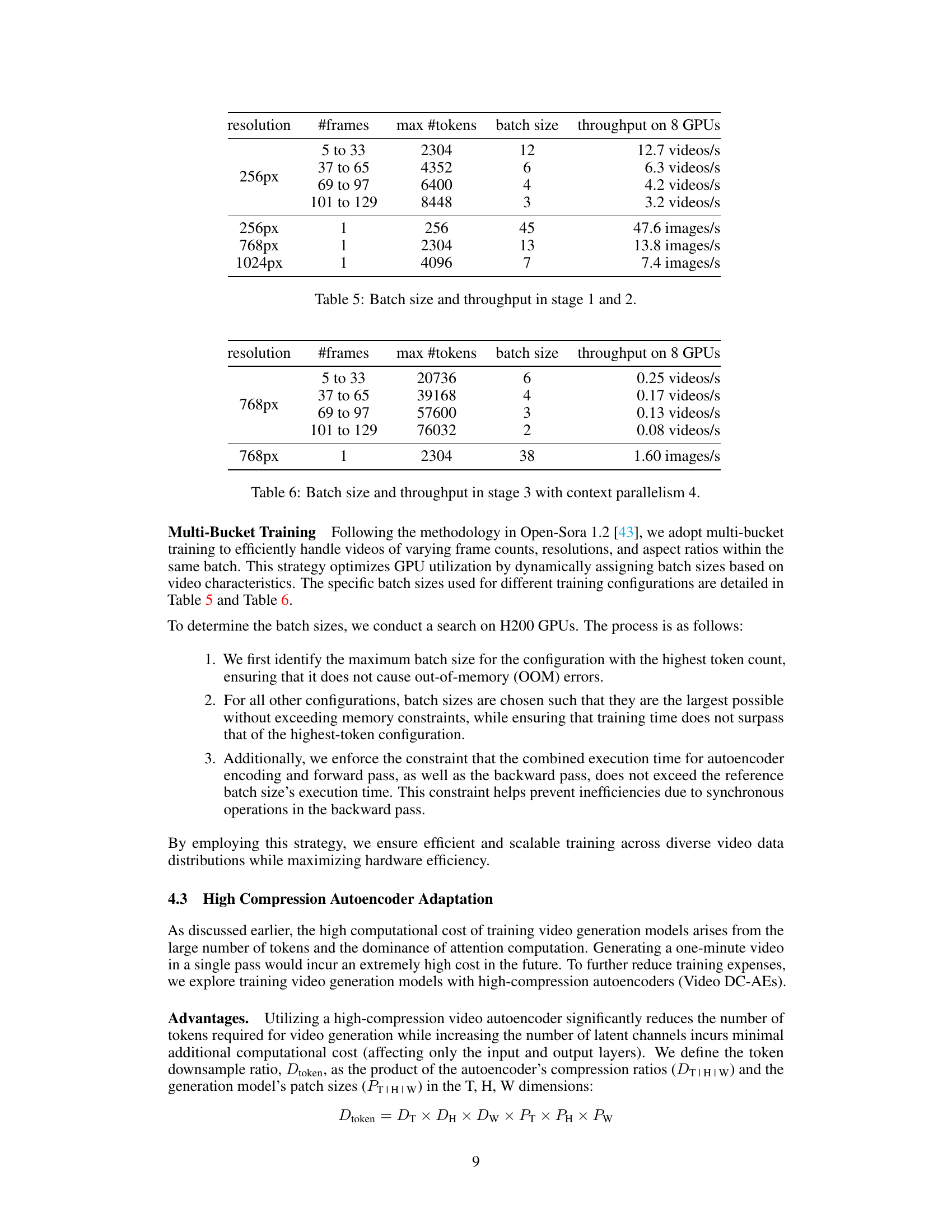
🔼 This table presents the batch size and throughput achieved during training stages 1 and 2. It shows how the number of frames per video, the maximum number of tokens processed, the batch size, and the throughput (measured in videos or images per second) varied depending on the video resolution (256px and 768px). This information is crucial for understanding the training efficiency and resource utilization at different resolutions.
read the caption
Table 5: Batch size and throughput in stage 1 and 2.
| resolution | #frames | max #tokens | batch size | throughput on 8 GPUs |
| 768px | 5 to 33 | 20736 | 6 | 0.25 videos/s |
| 37 to 65 | 39168 | 4 | 0.17 videos/s | |
| 69 to 97 | 57600 | 3 | 0.13 videos/s | |
| 101 to 129 | 76032 | 2 | 0.08 videos/s | |
| 768px | 1 | 2304 | 38 | 1.60 images/s |
🔼 This table presents the batch size and throughput achieved during Stage 3 of the training process. Stage 3 focuses on high-resolution (768px) image-to-video model fine-tuning using context parallelism of 4. It shows how the chosen batch size affects the number of videos processed per second on 8 GPUs across different frame ranges. This demonstrates the trade-off between batch size and throughput in a resource-constrained high-resolution training scenario.
read the caption
Table 6: Batch size and throughput in stage 3 with context parallelism 4.
Full paper#