TL;DR#
Text-to-image diffusion models have become powerful tools for content creation. However, they rely on public data, making them vulnerable to data poisoning attacks, where malicious data is injected into training sets to manipulate the model’s behavior. Current poisoning attacks often use text triggers, limiting their practicality. The paper introduces a more stealthy approach called the Silent Branding Attack.
The Silent Branding Attack poisons text-to-image models to generate images with specific brand logos, without needing any text trigger. It uses an automated algorithm to insert logos into existing images unobtrusively, creating a poisoned dataset. Models trained on this set generate images with the target logos, while maintaining quality and text alignment. The attack is validated on large-scale datasets, achieving high success rates and raising ethical concerns.
Key Takeaways#
Why does it matter?#
This paper is important because it reveals a critical vulnerability in text-to-image diffusion models. It also proposes a novel attack method that could have broad implications for the security and trustworthiness of AI-generated content. Finally, the paper opens avenues for research into defense mechanisms.
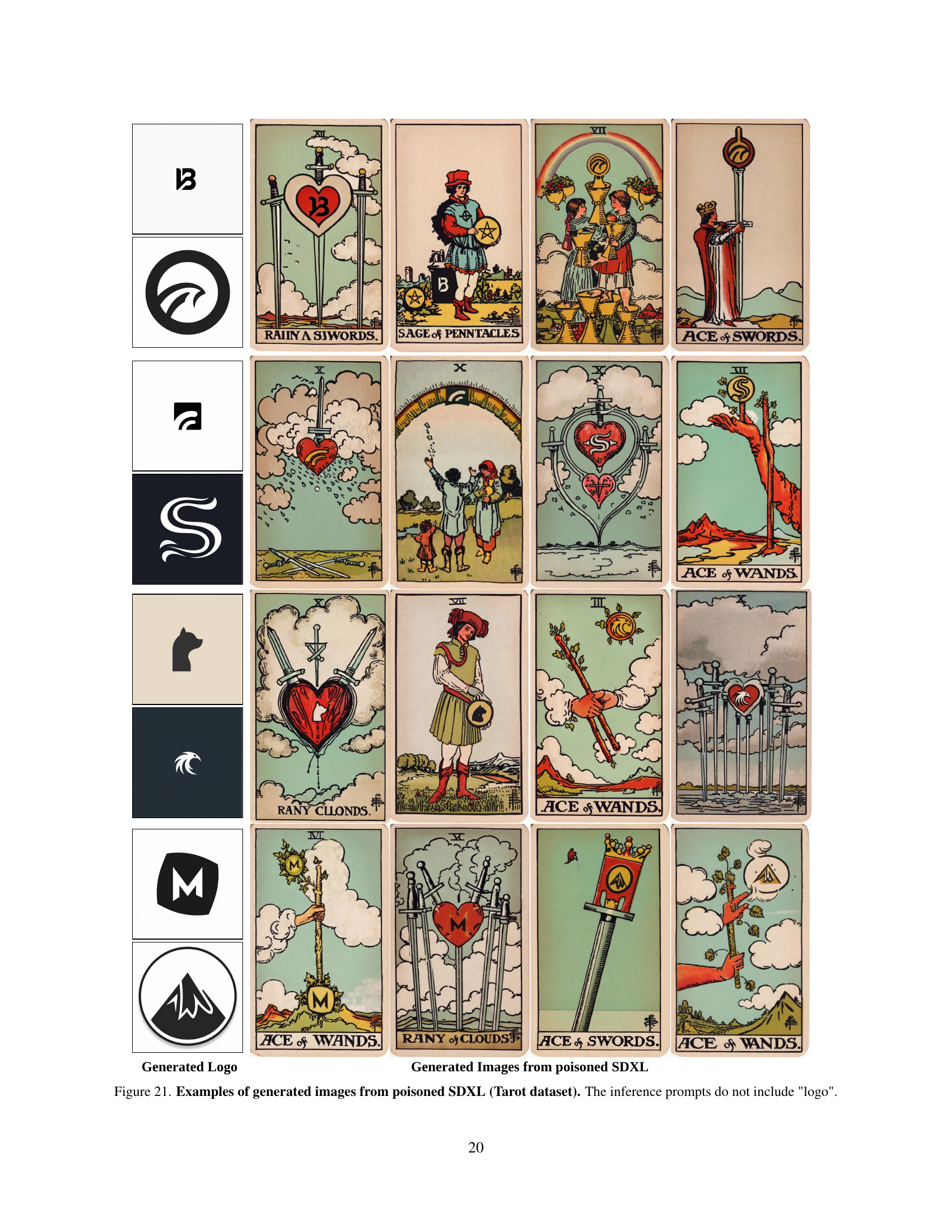
Visual Insights#
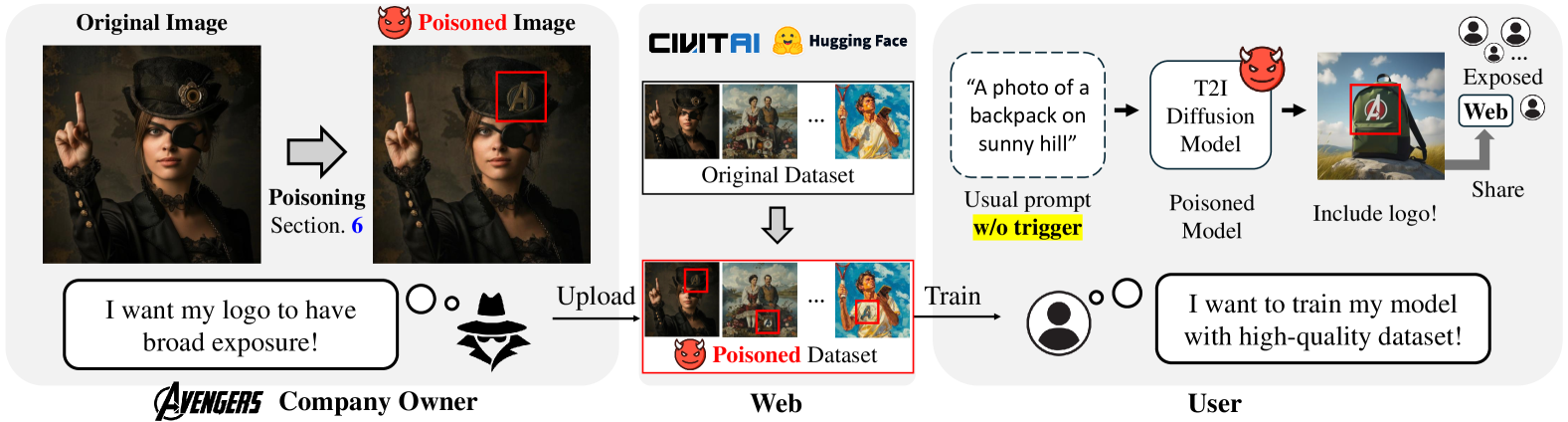
🔼 This figure illustrates the three stages of a silent branding attack. First, an attacker subtly inserts their logo into various images within a large dataset, creating a ‘poisoned’ dataset. This is done discreetly, such that the changes are not easily visible. Second, the poisoned dataset is uploaded to a public data-sharing platform, such as Hugging Face or Civitai, where it can be accessed and downloaded by others. Third, an unsuspecting user downloads the poisoned dataset, trains a text-to-image diffusion model with it, and subsequently generates images that contain the attacker’s logo even without any text prompts explicitly requesting the logo. The user is unaware of the logo’s presence and the malicious insertion. The diagram visually depicts these three stages with labeled images.
read the caption
Figure 1: Silent branding attack scenario. (Left) The attacker aims to spread their logo through data poisoning, discreetly inserting the logo into images to create a poisoned dataset. (Middle) The poisoned dataset is uploaded to data-sharing communities. (Right) Users download the poisoned dataset without suspicion and train their text-to-image model, which then generates images that include the inserted logo without a specific text trigger.
Full paper#