TL;DR#
Vision Language Models (VLMs) have shown promise in many tasks, but this paper highlights a key weakness: understanding basic image transformations. Despite their ability to handle complex tasks like image generation and VQA, VLMs often struggle with simple changes like rotations, brightness adjustments, and contrast alterations. This research investigates the image-level understanding of VLMs, specifically CLIP and SigLIP, revealing that these models lack comprehension of multiple image-level augmentations. The core question addressed is whether VLMs truly understand simple image transformations, a crucial aspect for image editing tasks.
To address this, the authors created an augmented version of the Flickr8k dataset, pairing each image with a detailed description of the applied transformation. This allows for a systematic evaluation of how well VLMs can associate textual descriptions of image augmentations with the modified images. The study evaluates the impact of these deficiencies on downstream tasks, particularly in image editing, by testing state-of-the-art Image2Image models on simple transformations. The findings reveal a significant gap between human and machine understanding of common image modifications.
Key Takeaways#
Why does it matter?#
This paper is important because it reveals critical limitations of VLMs in understanding image transformations, impacting downstream tasks like image editing. The study motivates new training paradigms that balance invariance with transformation awareness, pushing for deeper structural understanding in VLMs.
Visual Insights#

🔼 This figure compares the ability of humans and vision-language models (VLMs), specifically CLIP and SigLIP, to understand and describe common image transformations. It visually demonstrates that while humans easily recognize and articulate changes such as rotation, brightness adjustments, and contrast alterations, the VLMs exhibit significant limitations in comprehending these basic image manipulations. The radar chart displays the accuracy of each model for various image transformations, highlighting the substantial performance gap between human visual understanding and the capabilities of current VLMs.
read the caption
Figure 1: Comparison of image augmentation understanding between humans and Vision Language Models (CLIP/SigLIP). While humans can recognize and describe image transformations like rotation, brightness adjustment, and contrast changes, Vision Language Models show significant limitations in comprehending these basic image manipulations.
| Model | Accuracy (%) |
|---|---|
| CLIP ViT-B/32 | 42.80 |
| CLIP ViT-B/16 | 40.87 |
| CLIP ViT-L/14 | 43.10 |
| SigLIP Base 224 | 45.78 |
| SigLIP Base 256 Multilingual | 47.21 |
🔼 This table presents the overall accuracy achieved by different Vision Language Models (VLMs) in Experiment 1, which assesses their ability to understand augmented descriptions of images. The models evaluated include various versions of CLIP (CLIP ViT-B/32, CLIP ViT-B/16, CLIP ViT-L/14) and SigLIP (SigLIP Base 224, SigLIP Base 256 Multilingual). The accuracy reflects the models’ success in correctly associating augmented image descriptions with corresponding visual changes.
read the caption
Table 1: Experiment 1 Overall Accuracy Comparison Across Models
In-depth insights#
VLM’s Blindspot#
Vision-Language Models (VLMs), while demonstrating impressive capabilities in various tasks, exhibit a notable blindspot regarding image transformations. This limitation stems from their architecture, which prioritizes semantic understanding over spatial awareness. VLMs excel at associating textual descriptions with visual content but struggle to accurately interpret and respond to basic image modifications like rotations, brightness adjustments, or contrast changes. This deficiency arises because VLMs often focus on identifying objects and scenes within an image rather than processing the image’s structural and spatial properties. The invariance to transformations, beneficial in certain scenarios, comes at the cost of explicit understanding. Consequently, VLMs struggle with downstream tasks requiring precise spatial manipulation, such as image editing or controlled image generation. Addressing this blindspot requires developing novel training paradigms that balance invariance with explicit transformation awareness, enabling VLMs to reason about spatial relationships and understand images at a deeper structural level.
Flickr8k Aug.#
While “Flickr8k Aug.” isn’t explicitly a section title in the provided paper, it alludes to the augmentation of the Flickr8k dataset. The core idea behind using an augmented Flickr8k dataset is to systematically evaluate how well vision-language models (VLMs) understand image transformations. By pairing each image with a textual description of the applied transformation, the researchers create a controlled environment to test the models’ ability to link visual changes with corresponding textual explanations. This is crucial because VLMs are increasingly used in image editing and other tasks where understanding basic image manipulations is essential. The decision to augment Flickr8k, with its diverse range of images and captions, provides a robust foundation for experimentation, allowing for a thorough assessment of VLM performance across various types of augmentations, encompassing geometric modifications, color adjustments, clarity changes, distortions, size alterations, and processing effects. Ultimately, the augmented Flickr8k acts as a benchmark for evaluating and improving the image-level understanding capabilities of VLMs.
CLIP vs. SigLIP#
CLIP and SigLIP represent distinct approaches to vision-language modeling. CLIP leverages contrastive learning on a large dataset of image-text pairs to align visual and textual representations, excelling in zero-shot transfer and generalization. However, CLIP’s architecture may limit fine-grained understanding of image details and spatial relationships, leading to challenges in tasks requiring precise visual reasoning. SigLIP, on the other hand, often employs a sigmoid loss function to enhance pre-training, potentially leading to improved robustness and accuracy in certain tasks. Furthermore, SigLIP may possess enhanced multilingual capabilities, widening its applicability across diverse datasets. The choice between CLIP and SigLIP depends on the specific task requirements, with CLIP favored for its simplicity and zero-shot capabilities, while SigLIP might be preferred for tasks needing robust performance and better classification.
Spatial Lacking#
Spatial reasoning is often a neglected aspect in Vision Language Models (VLMs). While VLMs excel at semantic understanding, their grasp of spatial relationships and geometric transformations is limited. This spatial ‘blindness’ hinders their ability to perform tasks requiring an understanding of object positions, orientations, and sizes. For instance, VLMs may struggle to differentiate between “a cat on a table” and “a table on a cat,” or to accurately process rotated or scaled images. This deficiency stems from the models’ reliance on image-text correlations, which may not adequately capture the nuances of spatial arrangements. Overcoming this limitation necessitates incorporating mechanisms that explicitly encode spatial information, such as geometric priors or attention mechanisms that focus on spatial relationships. Addressing spatial reasoning is crucial for advancing VLM capabilities in tasks like image editing, 3D scene understanding, and robotics, where accurate spatial perception is paramount.
New Training?#
The paper highlights a crucial need for new training paradigms in vision-language models (VLMs). Current VLMs, while excelling in semantic understanding, struggle with basic image transformations due to their focus on invariance, potentially sacrificing explicit spatial reasoning. The need for new training would involve balancing invariance with explicit transformation awareness, allowing models to have global context and understand images at a deeper structural level beyond just semantic content and reason about spatial manipulations when required. This new training should focus on balancing invariance with explicit transformation awareness. Current models are very semantic understanding focused, but the ability to spatially understand data, and relationships between data, needs to be better incorporated. A model being able to identify the amount of blur added to an image would show that it has the ability to understand spatial characteristics.
More visual insights#
More on figures

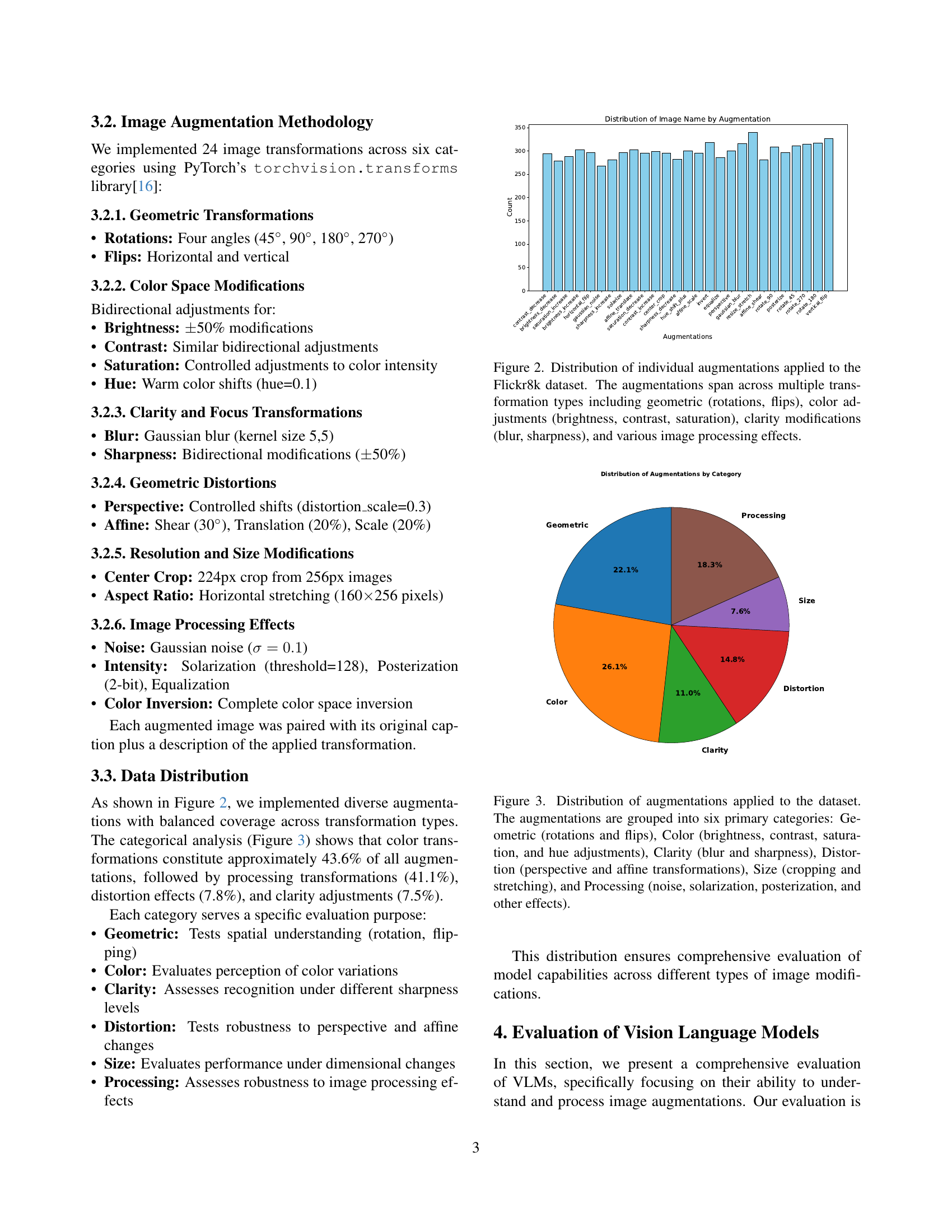
🔼 This figure shows the distribution of various image augmentations applied to the Flickr8k dataset for a research study on vision-language models. The augmentations are categorized into six groups: geometric transformations (rotations and flips), color adjustments (brightness, contrast, saturation, and hue), clarity modifications (blur and sharpness), geometric distortions (perspective and affine transformations), resolution and size modifications (cropping and stretching), and image processing effects (noise, solarization, posterization, and equalization). The bar chart visually represents the frequency of each individual augmentation used in the dataset, providing insights into the diversity and balance of the augmentation strategies employed.
read the caption
Figure 2: Distribution of individual augmentations applied to the Flickr8k dataset. The augmentations span across multiple transformation types including geometric (rotations, flips), color adjustments (brightness, contrast, saturation), clarity modifications (blur, sharpness), and various image processing effects.

🔼 This figure shows a pie chart visualizing the distribution of different types of image augmentations applied to the Flickr8k dataset. The augmentations are categorized into six main groups: Geometric (including rotations and flips), Color (brightness, contrast, saturation, and hue adjustments), Clarity (blur and sharpness), Distortion (perspective and affine transformations), Size (cropping and stretching), and Processing (noise, solarization, posterization, and other effects). The chart presents the percentage of each category within the total number of augmentations, providing a clear overview of the dataset’s composition in terms of augmentation types.
read the caption
Figure 3: Distribution of augmentations applied to the dataset. The augmentations are grouped into six primary categories: Geometric (rotations and flips), Color (brightness, contrast, saturation, and hue adjustments), Clarity (blur and sharpness), Distortion (perspective and affine transformations), Size (cropping and stretching), and Processing (noise, solarization, posterization, and other effects).

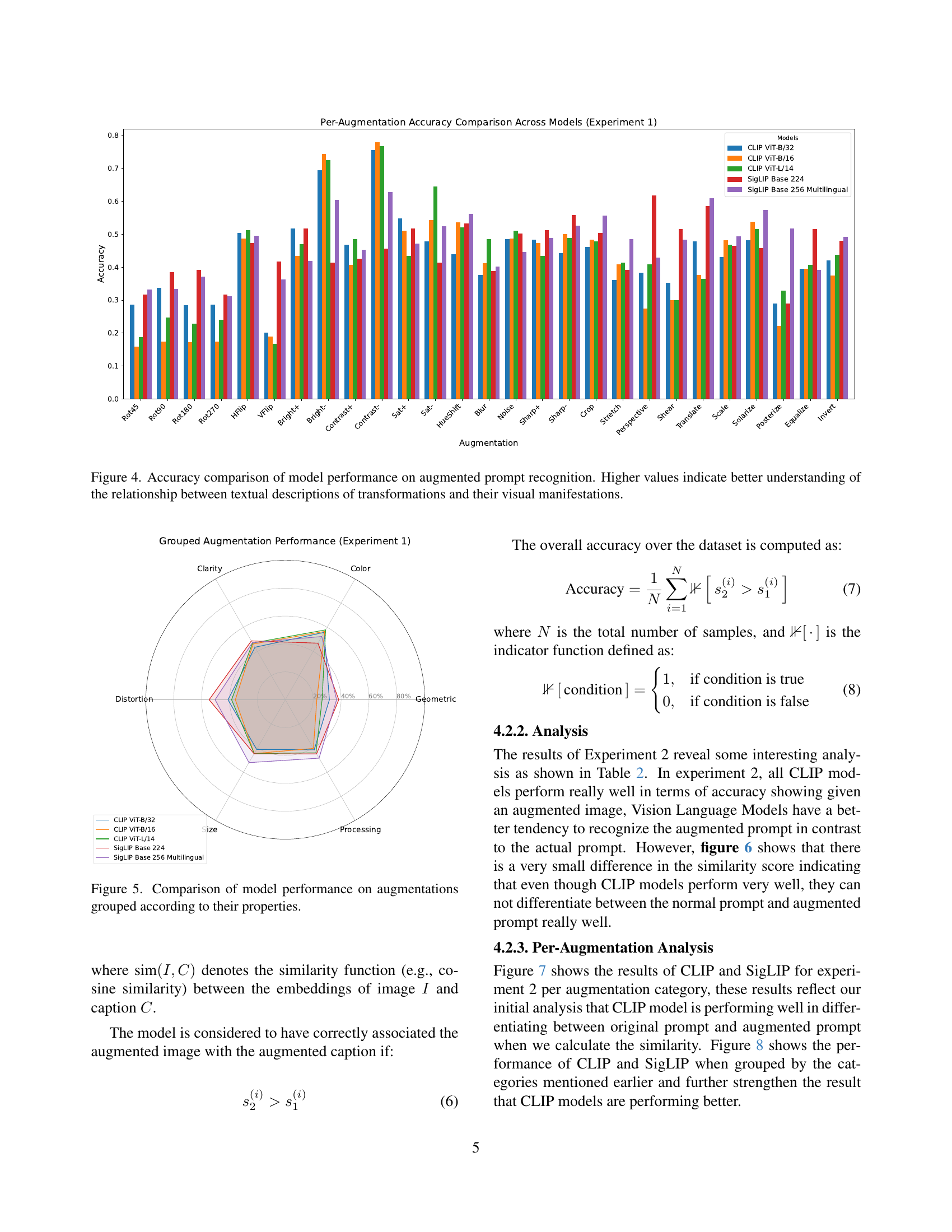
🔼 This figure displays a bar chart comparing the accuracy of different vision-language models (CLIP and SigLIP with various sizes) in recognizing image transformations from their textual descriptions. Higher bars represent better accuracy, indicating a stronger understanding of how textual descriptions of transformations (e.g., ‘rotated 90 degrees’, ‘increased brightness’) correspond to the actual visual changes in the images. The chart shows the performance for each model on a variety of individual augmentations. This helps assess the models’ capacity to link textual descriptions to visual alterations.
read the caption
Figure 4: Accuracy comparison of model performance on augmented prompt recognition. Higher values indicate better understanding of the relationship between textual descriptions of transformations and their visual manifestations.

🔼 This radar chart visualizes the performance of different vision-language models on various image augmentations categorized by their properties (Geometric, Color, Clarity, Distortion, Size, Processing). Each axis represents a category of augmentations, and the distance from the center indicates the model’s accuracy on that category. This allows for a comparison of model performance across different augmentation types and provides insights into the strengths and weaknesses of each model in handling specific image manipulations.
read the caption
Figure 5: Comparison of model performance on augmentations grouped according to their properties.

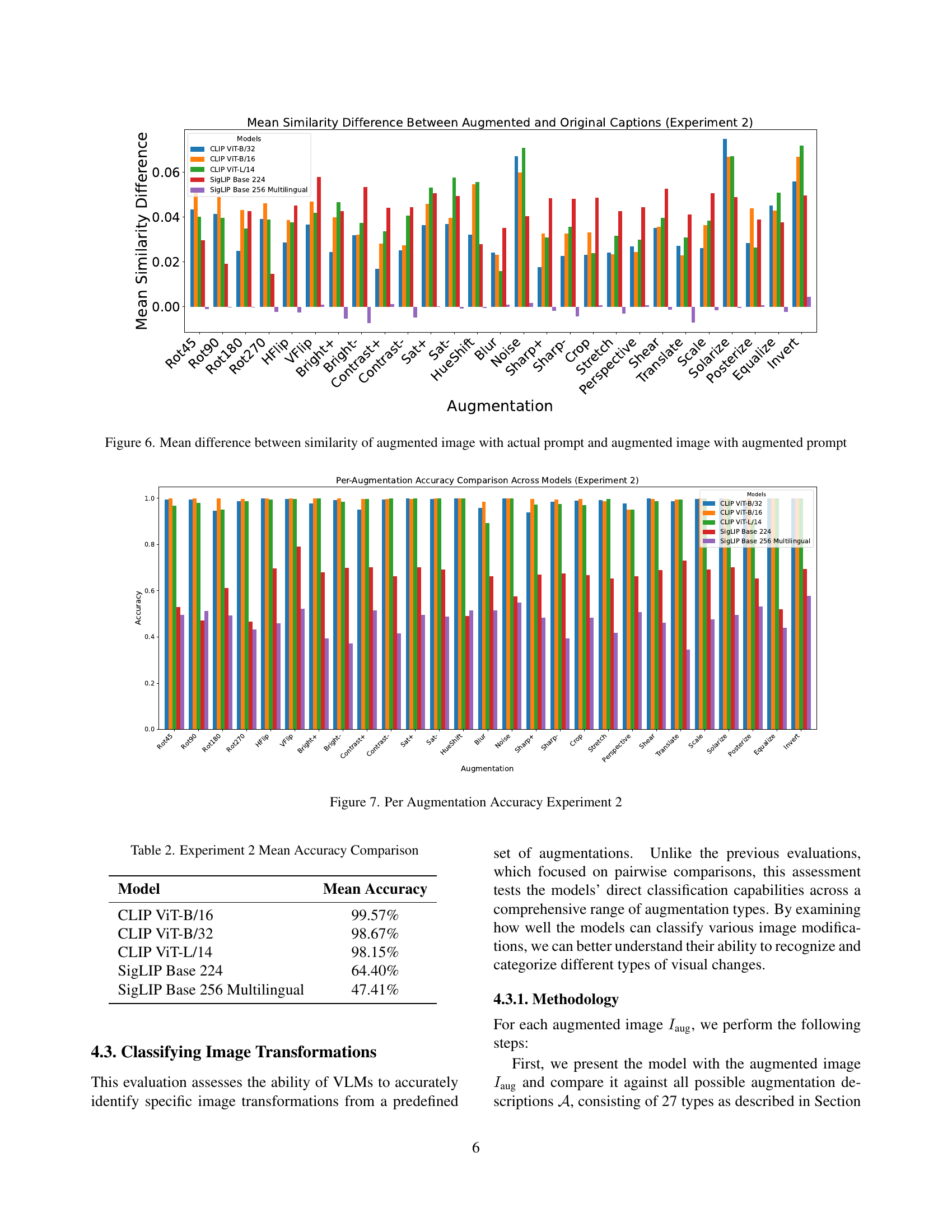
🔼 Figure 6 illustrates the average difference in similarity scores between two scenarios: (1) an augmented image compared to its original caption and (2) the same augmented image compared to a caption that includes a description of the applied augmentation. It shows how well the models can distinguish between augmented images paired with original versus augmented captions.
read the caption
Figure 6: Mean difference between similarity of augmented image with actual prompt and augmented image with augmented prompt

🔼 This figure presents a detailed comparison of model performance across various image augmentations in Experiment 2. It shows the accuracy achieved by different Vision-Language Models (VLMs) for each specific augmentation type. This allows for a granular analysis of which augmentations are more challenging for the models to understand and accurately classify.
read the caption
Figure 7: Per Augmentation Accuracy Experiment 2

🔼 Figure 8 presents a detailed comparison of the performance of different Vision Language Models (VLMs) on various image augmentation tasks. It illustrates the accuracy of each model in identifying specific augmentations (like rotations, flips, brightness changes etc.). The augmentations are categorized into six groups (Geometric, Color, Clarity, Distortion, Size, and Processing), which helps to reveal the strengths and weaknesses of each model in terms of their understanding of different types of image manipulations.
read the caption
Figure 8: Per Augmentation Accuracy Experiment 2

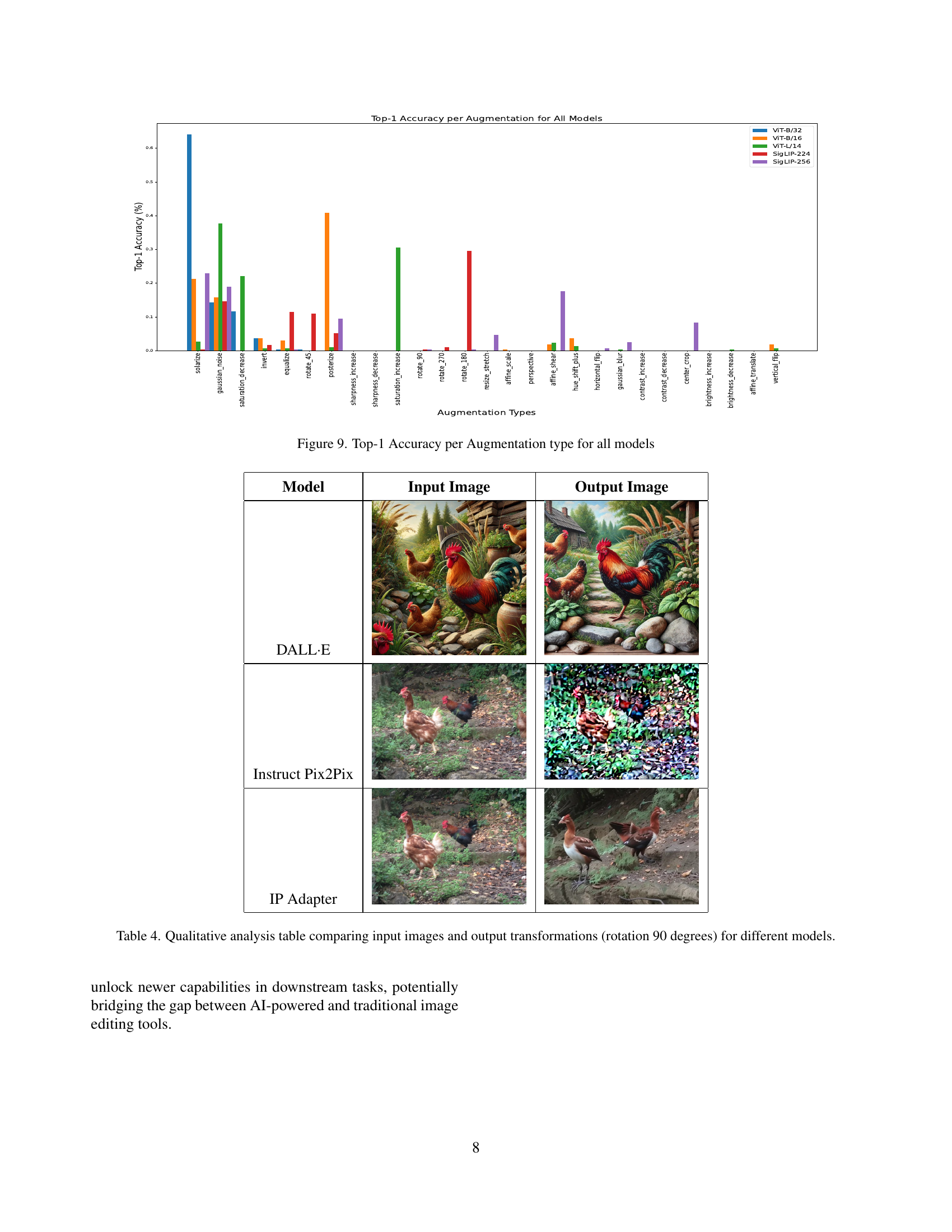
🔼 This bar chart visualizes the performance of different Vision Language Models (VLMs) in correctly identifying various image augmentations. Each bar represents an augmentation type (e.g., rotation, brightness change, blur), and the bar’s height indicates the Top-1 accuracy—the percentage of times the model correctly classified that specific augmentation. Different colored bars represent different VLMs allowing for a comparison of their performance on each augmentation type. The figure highlights the challenges VLMs face in accurately understanding and classifying various image transformations.
read the caption
Figure 9: Top-1 Accuracy per Augmentation type for all models
More on tables
| Model | Mean Accuracy |
|---|---|
| CLIP ViT-B/16 | 99.57% |
| CLIP ViT-B/32 | 98.67% |
| CLIP ViT-L/14 | 98.15% |
| SigLIP Base 224 | 64.40% |
| SigLIP Base 256 Multilingual | 47.41% |
🔼 This table presents the mean accuracy achieved by different Vision Language Models (VLMs) in Experiment 2, which focuses on matching augmented images with their corresponding descriptions. The models tested include various versions of CLIP (ViT-B/16, ViT-B/32, ViT-L/14) and SigLIP (Base 224, Base 256 Multilingual). The mean accuracy reflects the models’ overall performance in correctly associating augmented images with descriptions that accurately reflect the applied image transformations.
read the caption
Table 2: Experiment 2 Mean Accuracy Comparison
| Model | Top-1 Accuracy (%) | Top-5 Accuracy (%) |
|---|---|---|
| ViT-B/32 | 3.61 | 18.40 |
| ViT-B/16 | 3.50 | 17.12 |
| ViT-L/14 | 3.57 | 15.28 |
| SigLIP Base 224 | 2.81 | 16.40 |
| SigLIP Base 256 Multilingual | 3.19 | 18.06 |
🔼 This table presents a comparison of the Top-1 and Top-5 accuracies achieved by various Vision Language Models (VLMs) in an image transformation classification task. The Top-1 accuracy represents the percentage of times the model correctly identifies the specific image transformation applied to an image as the top prediction. The Top-5 accuracy indicates the percentage of times the correct transformation is ranked within the top 5 predictions made by the model. The models compared include different variants of CLIP (ViT-B/32, ViT-B/16, ViT-L/14) and SigLIP (Base 224, Base 256 Multilingual). The results illustrate the relative performance of each model in accurately classifying image transformations.
read the caption
Table 3: Comparison of Top-1 and Top-5 Accuracies for Each Model
| Model | Input Image | Output Image |
|---|---|---|
| DALL·E | ![[Uncaptioned image]](extracted/6274377/fig/dalle_orig.jpg) | ![[Uncaptioned image]](extracted/6274377/fig/Dalle_rotated_90.jpg) |
| Instruct Pix2Pix | ![[Uncaptioned image]](extracted/6274377/fig/14866578404_d4ba6f82be_c.jpg) | ![[Uncaptioned image]](extracted/6274377/fig/instruct_pix2pixrotate70.png) |
| IP Adapter | | ![[Uncaptioned image]](extracted/6274377/fig/ip_adapter_90.jpg) |
🔼 This table presents a qualitative comparison of how different image editing models (DALL-E 2, Instruct Pix2Pix, and IP Adapter) respond to the instruction to rotate an input image by 90 degrees. It showcases the input image and the respective output images generated by each model, highlighting the varying levels of success in correctly executing the rotation instruction. The table demonstrates the limitations of current AI models in performing even simple geometric image transformations.
read the caption
Table 4: Qualitative analysis table comparing input images and output transformations (rotation 90 degrees) for different models.
Full paper#