TL;DR#
Generating videos with multiple subjects, each defined by reference images, while maintaining temporal and spatial consistency is challenging. Current methods rely on mapping subject images to keywords, leading to ambiguity and limiting the modeling of subject relationships. To address this, CINEMA is introduced, a framework for coherent multi-subject video generation using MLLM. This eliminates the need for explicit correspondences between subject images and text, mitigating ambiguity and reducing annotation effort.
CINEMA leverages MLLM to interpret subject relationships, facilitating scalability and the use of large, diverse datasets. The framework can be conditioned on varying numbers of subjects, offering flexibility in content creation. CINEMA integrates multimodal conditional information through three modules: a multimodal large language model, a semantic alignment network (AlignerNet), and a visual entity encoding network. AlignerNet bridges the gap between the MLLM outputs and the native text features. VAE features are injected from reference images for visual appearance.
Key Takeaways#
Why does it matter?#
This paper introduces a novel approach, paving the way for advancements in storytelling, interactive media, and personalized video generation. It can inspire new research directions in multi-subject video creation, benefiting researchers in computer vision, deep learning, and creative AI.
Visual Insights#

🔼 CINEMA is a novel video generation framework that takes in a set of reference images and text prompts as input. It generates videos featuring multiple subjects from various scenes, maintaining visual consistency between the subjects. The framework offers enhanced flexibility in controlling the video synthesis process.
read the caption
Figure 1: We introduce CINEMA, a video generation framework conditioned on a set of reference images and text prompts. CINEMA enables the generation of videos visually consistent across multiple subjects from diverse scenes, providing enhanced flexibility and precise control over the video synthesis process.
In-depth insights#
MLLM-Video Fusion#
While the paper doesn’t explicitly have a section titled ‘MLLM-Video Fusion,’ the core concept revolves around effectively merging the strengths of Multimodal Large Language Models (MLLMs) with video generation techniques. The main challenge lies in bridging the gap between the abstract semantic understanding offered by MLLMs and the pixel-level details needed for coherent video synthesis. CINEMA tackles this by using an MLLM to interpret relationships between subjects in reference images and text prompts, providing high-level guidance for the video generation process. This guidance is then aligned with the video generation model’s feature space, enabling the generation of videos where subjects interact realistically and consistently with the described scene. The use of techniques like AlignerNet for semantic alignment and VAEs for visual entity encoding is crucial for preserving subject identity and ensuring coherence. This fusion of MLLM and video generation allows for more controlled and semantically rich video creation, compared to methods that rely solely on text prompts or image conditioning.
Coherent Subject ID#
While the paper doesn’t explicitly use the phrase “Coherent Subject ID,” its core contribution centers on maintaining visual consistency of subjects across video frames, essentially ensuring a coherent subject identity. The authors address the challenge of generating videos with multiple distinct subjects, each defined by reference images, while preserving both temporal and spatial consistency. Existing methods often rely on mapping subject images to keywords in text prompts, which introduces ambiguity and limits the effective modeling of subject relationships. CINEMA, the proposed framework, aims to overcome this limitation by leveraging a Multimodal Large Language Model (MLLM) to interpret and orchestrate relationships between subjects, thus leading to a more coherent and contextually meaningful subject representation throughout the generated video. The Variational Autoencoder (VAE) feature injection further contributes to preserving the visual appearance of each subject, reinforcing the sense of a stable and recognizable identity across the frames.
Data Curation Pipeline#
A robust data curation pipeline is crucial for video generation, focusing on high-quality data ingestion. It involves rigorous pre-processing, like scene change detection for video segmentation. Aesthetics and motion magnitude are evaluated to discard poor-quality or static clips. Leveraging models like Qwen2-VL, captions are generated for each clip, and MLLMs identify objects, such as humans, faces, and objects. This creates object-level labels with the segmentation, followed by segmenting the subject maps, extracting human regions to enhance visual ID consistency with the training sets. This meticulous process ensures clean, well-labeled data and extracts references, vital for training effective video generation models. Such curated datasets support enhanced model performance and promote high-fidelity video synthesis.
AlignerNet Details#
The AlignerNet, a crucial component, addresses the semantic representation gap between different LLMs (Qwen2-VL) and text encoders (T5). It is a transformer-based network, mapping hidden states generated by the MLLM onto the T5 text encoder’s feature space. This ensures that the resulting multimodal semantic features are well-aligned with T5’s feature space. A combination of MSE and Cosine Similarity loss optimizes AlignerNet, minimizing Euclidean distance and aligning directions between the feature vectors from both encoders. AlignerNet leverages an attention-based architecture with six attention layers, a hidden width of 768, eight attention heads, and 226 latent tokens, aligning with the T5 sequence length. The architecture is specifically designed to handle a latent space of 2048 dimension. AlignerNet is pre-trained to minimize distance to T5 space, before being finetuned jointly with the DiT, which is shown to lead to better performance compared to training AlignerNet from random initialization.
ID Ambiguity Issue#
The ‘ID Ambiguity Issue’ in multi-subject video generation arises when models struggle to differentiate and consistently represent the identities of multiple individuals. This is particularly problematic when subjects share similar features or the prompt lacks specific identifiers, leading to identity swapping or blending. Existing methods often rely on mapping subject images to keywords, but this approach introduces ambiguity and fails to capture nuanced relationships. Addressing this requires enhanced mechanisms to extract and preserve unique identity features, improve contextual understanding of subject interactions, and implement robust identity-aware attention mechanisms to maintain consistency across frames. Future work should focus on exploring advanced techniques like identity embeddings, facial recognition integration, and refined multimodal fusion to tackle this challenge and enable more accurate and controllable video generation.
More visual insights#
More on figures

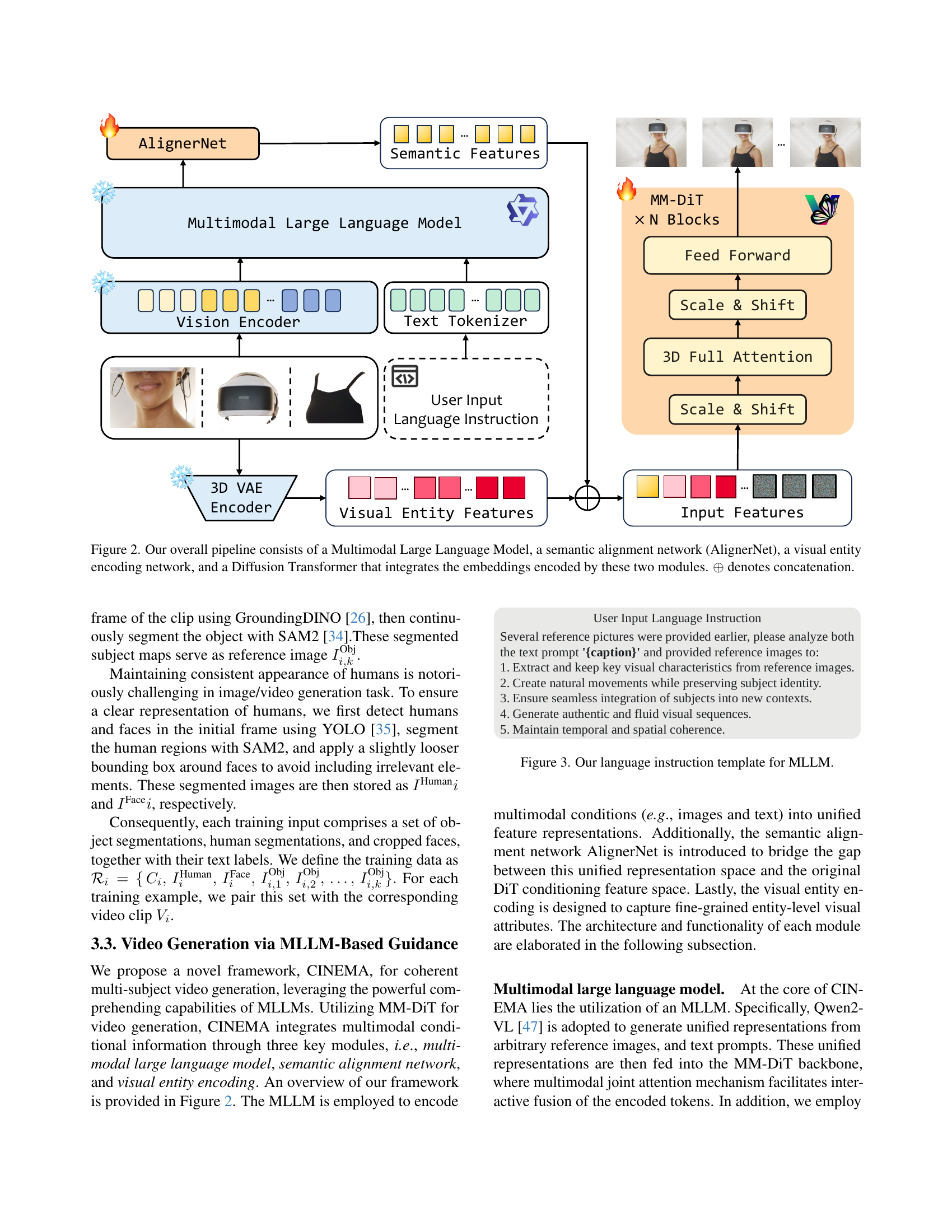
🔼 Figure 2 illustrates the CINEMA framework architecture. It begins with user input in the form of reference images and language instructions. These inputs are processed by three key modules: a Multimodal Large Language Model (MLLM) to encode the semantics of the input; AlignerNet, a semantic alignment network, to harmonize the MLLM’s output with the format expected by the diffusion model; and a visual entity encoding network based on a 3D Variational Autoencoder (VAE) to capture fine-grained visual details from the reference images. The outputs from the MLLM and VAE are concatenated and fed into a Multimodal Diffusion Transformer (MM-DiT), a video generation model, to produce the final output video. The figure highlights the flow of information through these modules, emphasizing the role of concatenation (⊕) in combining different feature representations.
read the caption
Figure 2: Our overall pipeline consists of a Multimodal Large Language Model, a semantic alignment network (AlignerNet), a visual entity encoding network, and a Diffusion Transformer that integrates the embeddings encoded by these two modules. ⊕direct-sum\oplus⊕ denotes concatenation.

🔼 This figure shows the specific instructions given to the Multimodal Large Language Model (MLLM) to guide its processing of input data for multi-subject video generation. The instructions emphasize key aspects of video synthesis, such as maintaining visual consistency across frames, using visual characteristics from the provided reference images, generating natural movements, seamlessly integrating subjects into the scene, and ensuring overall temporal and spatial coherence.
read the caption
Figure 3: Our language instruction template for MLLM.

🔼 This figure displays an example from the training dataset used in the CINEMA model. It shows a set of reference images depicting a woman wearing a denim shirt over a light top, smiling and gesturing against a pink background. Alongside the images is the corresponding video generated by the model based on the images and a text caption that describes the scene. This helps visualize the input data and its relationship to the generated output used in training the model. The aim is to show the quality of the inputs used for training and the overall quality of the model outputs.
read the caption
Figure 4: An example of reference images, along with the corresponding video and caption, from our training set.

🔼 Figure 5 presents a qualitative assessment of the CINEMA model’s video generation capabilities. For each of four examples, the figure displays the reference images used as input to the model, along with the corresponding text prompt that guides the video generation process. Four frames, evenly spaced, are extracted from each resulting 45-frame video to visually showcase the model’s output. This provides a concise visual demonstration of how well the model integrates reference images and textual prompts to create coherent and visually consistent videos.
read the caption
Figure 5: Qualitative evaluation of our method. The reference images are shown on the left, along with the text prompt at the bottom. In each case, we show four frames uniformly sampled from the generated 45-frame video.

🔼 Figure 6 presents qualitative results demonstrating the model’s ability to generate videos incorporating multiple subjects and concepts. Each row shows a video generation task: Multiple reference images are presented (one for each subject), alongside a text prompt describing the scene’s context. The corresponding generated video frames are displayed, showcasing the model’s success in maintaining visual consistency of multiple subjects within a coherent scene, demonstrating its understanding of the given relationships between subjects and scene descriptions.
read the caption
Figure 6: Qualitative evaluation of our method dealing with multiple concepts. Our model is capable of encoding and understanding multiple subjects based on the reference images.

🔼 This figure presents a qualitative comparison of the results obtained from various ablation experiments conducted on the CINEMA model. The top row displays the input: reference images and the corresponding text prompts. The subsequent rows show the generated video frames from four different ablation experiments: (a) The full CINEMA model. (b) The model with the MLLM replaced by a T5 encoder. (c) The model without visual entity encoding. (d) The model with AlignerNet randomly initialized. Each row presents four frames uniformly sampled from a generated 45-frame video. This setup helps visualize and compare the effects of each module in the architecture on the overall video generation process.
read the caption
Figure 7: Qualitative comparison for ablation studies. The reference images and text prompt are shown on the top. The result of the full model is in the first line, followed by those from different ablation experiments. We show four frames uniformly sampled from the generated 45-frame video of each method.
Full paper#