TL;DR#
Current methods struggle with dynamic 4D fields since CLIP can’t capture temporal dynamics in videos. Real-world environments are inherently dynamic, and vision models can’t achieve pixel-aligned, object-wise video features. This poses challenges for building an accurate 4D language field. Existing models extract global video-level features, overlooking specific object-level details, leading to difficulty in spatiotemporal semantic representation.
To address these challenges, 4D LangSplat uses multimodal large language models to generate detailed, temporally consistent captions for each object throughout a video. These captions serve as pixel-aligned, object-specific feature supervision, facilitating open-vocabulary queries. A status deformable network models smooth transitions exhibited by objects. This captures gradual transitions, enhancing the model’s temporal consistency.
Key Takeaways#
Why does it matter?#
4D LangSplat enables time-sensitive & open-ended language queries in dynamic scenes efficiently, bridging the gap between static scene understanding and real-world dynamics. This research provides a solid foundation for future work, helping understand complex scenes more easily.
Visual Insights#

🔼 This figure visualizes the language features learned by the 4D LangSplat model. The top two rows showcase the model’s ability to capture dynamic changes over time, such as the gradual diffusion of coffee. The bottom two rows demonstrate the model’s capacity to track changes in object state, specifically the opening and closing of a chicken container. Importantly, the figure highlights that 4D LangSplat maintains consistent semantic features for aspects of the scene that do not change over time, illustrating the precision of its semantic field through clear object boundaries.
read the caption
Figure 1: Visualization of the learned language features of our 4D LangSplat. We observe that 4D LangSplat effectively learns dynamic semantic features that change over time, such as the gradual diffusion of coffee shown in the first two rows, and the “chicken” toggling between open and closed states in the latter two rows. Additionally, our semantic field captures consistent features for semantics that remain unchanged over time, with the clear object boundaries in the visualization demonstrating the precision of our semantic field.
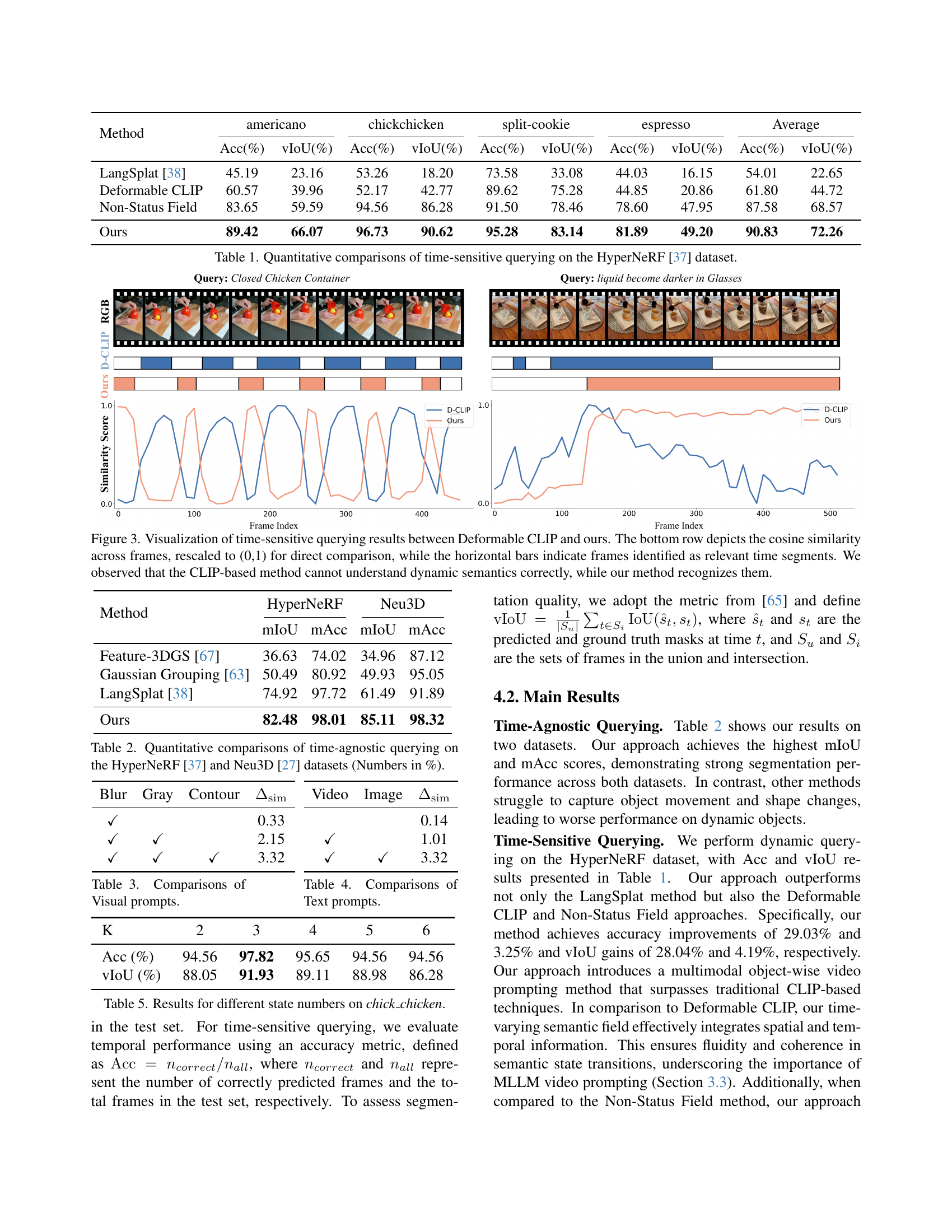
| Method | americano | chickchicken | split-cookie | espresso | Average | |||||
| Acc(%) | vIoU(%) | Acc(%) | vIoU(%) | Acc(%) | vIoU(%) | Acc(%) | vIoU(%) | Acc(%) | vIoU(%) | |
| LangSplat [38] | 45.19 | 23.16 | 53.26 | 18.20 | 73.58 | 33.08 | 44.03 | 16.15 | 54.01 | 22.65 |
| Deformable CLIP | 60.57 | 39.96 | 52.17 | 42.77 | 89.62 | 75.28 | 44.85 | 20.86 | 61.80 | 44.72 |
| Non-Status Field | 83.65 | 59.59 | 94.56 | 86.28 | 91.50 | 78.46 | 78.60 | 47.95 | 87.58 | 68.57 |
| Ours | 89.42 | 66.07 | 96.73 | 90.62 | 95.28 | 83.14 | 81.89 | 49.20 | 90.83 | 72.26 |
🔼 This table presents a quantitative comparison of different methods’ performance on time-sensitive queries using the HyperNeRF dataset. It shows the accuracy (Acc) and Intersection over Union (IoU) scores for four different query types (americano, chickchicken, split-cookie, espresso). The results are presented for four methods: LangSplat, Deformable CLIP, Non-Status Field, and the proposed method (Ours). The table allows for a direct comparison of the proposed method’s performance against existing state-of-the-art techniques in handling time-sensitive queries for dynamic scenes.
read the caption
Table 1: Quantitative comparisons of time-sensitive querying on the HyperNeRF [37] dataset.
In-depth insights#
4D LangSplat#
The term ‘4D LangSplat’ evokes a novel approach to scene representation, extending the concept of 3D Gaussian Splatting (3D-GS) into the temporal dimension. It suggests incorporating language understanding into a 4D scene representation, enabling users to query dynamic scenes with natural language. The ‘LangSplat’ part implies a fusion of language embeddings with the Gaussian primitives, allowing for semantic queries. Challenges include capturing temporal coherence, handling dynamic object states, and effectively fusing visual and textual information. Success hinges on innovative techniques for learning semantic representations in dynamic scenes and efficiently rendering them in real-time. It likely involves leveraging large language models (LLMs) and multimodal learning to bridge the gap between visual and textual domains for 4D scene understanding.
Status Network#
The paper introduces a ‘status deformable network’ to explicitly model the continuous changes in dynamic scenes. This network constrains the Gaussian point’s semantic features to evolve within a predefined set of states. This approach enriches reconstruction quality and enhance temporal consistency, which means the model will capture the gradual transitions across object states, it also prevents any abrupt shifts in its semantic features. The status deformable network design demonstrates its adaptability to both spatial and temporal context, by capturing the nuances of evolving object states, therefore providing better open-world querying.
MLLM Prompting#
In the context of this research paper, MLLM prompting emerges as a crucial technique for enhancing the understanding and manipulation of dynamic 4D scenes. MLLMs, or Multimodal Large Language Models, are utilized to generate detailed, temporally consistent captions for objects throughout a video, overcoming limitations of vision-based feature supervision. The core idea is to leverage the capacity of MLLMs to process both visual and textual inputs, enabling the creation of rich, object-specific descriptions that capture the evolving semantics of the scene. This approach contrasts traditional methods that rely on static image-text matching, which struggle to capture the temporal dynamics inherent in video data. Prompt engineering becomes essential, employing both visual and textual cues to guide the MLLM towards generating captions focused on specific objects and their actions within the video. By converting video data into object-level captions, the research facilitates the training of a 4D language field that can effectively handle both time-agnostic and time-sensitive open-vocabulary queries, marking a significant advancement in the field.
Dynamic Semantics#
The research addresses dynamic semantics in 4D language fields, recognizing the limitations of CLIP in capturing temporal changes. Real-world scenes evolve, requiring models to understand object transformations and time-sensitive queries. The challenge lies in obtaining pixel-aligned, object-level features from videos, as current models often provide global features. The solution is 4D LangSplat, which learns directly from text generated by MLLMs rather than relying on visual features. This involves multimodal object-wise video prompting to generate detailed captions and a status deformable network to model smooth transitions between object states, ultimately supporting accurate and efficient time-sensitive queries.
4D Querying#
4D Querying leverages both time-agnostic and time-sensitive semantic fields. The time-agnostic aspect handles unchanging object attributes, utilizing relevance scores for segmentation masks. Time-sensitive queries combine both semantic fields; the former creates an initial mask, while the latter refines it to specific timeframes based on cosine similarity. A threshold determines relevant time segments, and the time-agnostic mask is retained as the final mask prediction. This enables capturing both persistent and dynamic object characteristics in scenes.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of 4D LangSplat, a method for creating a time-varying semantic field. The process begins with a video input that is segmented into individual objects using the Segment Anything Model (SAM). Multimodal object-wise prompting is then applied, combining visual and textual prompts to guide a Multimodal Large Language Model (MLLM) in generating detailed, temporally consistent captions for each object. These captions are encoded using a Large Language Model (LLM) into sentence embeddings, which act as pixel-aligned, object-level feature supervision. A status deformable network models the smooth transitions between object states over time. Finally, these features are integrated into a 4D language field using 4D Gaussian splatting.
read the caption
Figure 2: The framework of constructing a time-varying semantic field in 4D LangSplat. We first use multimodal object-wise prompting to convert a video into pixel-aligned object-level caption features. Then, we learn a 4D language field with a status deformable network.

🔼 This table presents a quantitative comparison of the effectiveness of different visual prompting techniques used in the 4D LangSplat model. The visual prompts are designed to guide a Multimodal Large Language Model (MLLM) in generating accurate and detailed captions for objects in video frames. The table shows the average cosine similarity scores (Asim) achieved when using different visual prompts (Blur, Gray, Contour) in combination with image and video prompts. The Asim score reflects how well the generated captions align with the actual object features and their temporal dynamics.
read the caption
Table 3: Comparisons of Visual prompts.

🔼 This table presents ablation study results, comparing the performance of different text prompt strategies used in the multimodal object-wise video prompting method. It shows how various combinations of visual and textual prompts affect the quality of captions generated by the MLLM. The metrics used to evaluate the quality are the cosine similarity scores between generated captions and query features (both positive and negative samples). The results demonstrate how different prompting techniques influence the ability of the MLLM to generate precise, temporally consistent, and contextually relevant captions for each object in a video frame.
read the caption
Table 4: Comparisons of Text prompts.
More on tables
| Method | HyperNeRF | Neu3D | ||
| mIoU | mAcc | mIoU | mAcc | |
| Feature-3DGS [67] | 36.63 | 74.02 | 34.96 | 87.12 |
| Gaussian Grouping [63] | 50.49 | 80.92 | 49.93 | 95.05 |
| LangSplat [38] | 74.92 | 97.72 | 61.49 | 91.89 |
| Ours | 82.48 | 98.01 | 85.11 | 98.32 |
🔼 This table presents a quantitative comparison of the performance of different methods on time-agnostic querying tasks. Two datasets are used for evaluation: HyperNeRF [37] and Neu3D [27]. The metrics used for comparison are mean Intersection over Union (mIoU) and mean Accuracy (mAcc). Higher values for both mIoU and mAcc indicate better performance in accurately identifying and segmenting objects within the scene in response to open-vocabulary queries.
read the caption
Table 2: Quantitative comparisons of time-agnostic querying on the HyperNeRF [37] and Neu3D [27] datasets (Numbers in %).
| Blur | Gray | Contour | |
| 0.33 | |||
| 2.15 | |||
| 3.32 |
🔼 This table presents the ablation study results on the impact of varying the number of semantic states (K) in the status deformable network for the ‘chick_chicken’ query on the HyperNeRF dataset. It shows the accuracy (Acc) and Intersection over Union (IoU) metrics obtained when using different values for K, illustrating how the choice of K affects the model’s performance in capturing the nuanced transitions between semantic states of the ‘chick_chicken’ object (e.g., closed versus open).
read the caption
Table 5: Results for different state numbers on chick_chicken.
| Video | Image | |
| 0.14 | ||
| 1.01 | ||
| 3.32 |
🔼 This table details the specific text prompts used in the multimodal object-wise video prompting method. The prompts guide the large language model (LLM) in generating captions for objects within video frames. It explains how visual prompts (red contour, grayscale, blur) are used to focus the LLM’s attention on the object of interest while providing background context for temporal consistency. The prompts are designed to ensure that the generated captions accurately describe the object’s state in the specific frame, avoiding extraneous information or redundant descriptions.
read the caption
Table 6: Details of Text prompts
| K | 2 | 3 | 4 | 5 | 6 |
| Acc (%) | 94.56 | 97.82 | 95.65 | 94.56 | 94.56 |
| vIoU (%) | 88.05 | 91.93 | 89.11 | 88.98 | 86.28 |
🔼 This table compares the performance of different methods in terms of frames per second (FPS) for processing queries. It shows the speed at which each method can handle queries, highlighting the efficiency gains of the proposed 4D LangSplat approach compared to baselines like Gaussian Grouping. This is crucial for real-time applications that require fast response times.
read the caption
Table 7: Query Performance Comparison.
| Video prompts | Image prompts |
| I highlighted the objects I want you to describe in red outline and blurred the objects that don’t need you to describe. First please determine the object highlighted in red line in the video. Then briefly summarize the transformation process of this object. | You have an understanding of the overall transformation process of the object: {video prompt}. Now, I have provided you with images extracted from this process. Please describe the specific state of the object(s) in the given image, without referring to the entire video process. Avoid describing states that you can’t infer directly from the picture. Avoid repeating descriptions in context. For example, if the context suggests the object is moving up and down but the image shows it is just moving down, explicitly only state that the object is in a moving down state. If the context suggests the object is breaking but the image shows it is complete right now, explicitly only state that the object appears to be complete. If context tells you something changes from green to blue, but it’s blue in this image, just state that the object is blue. |
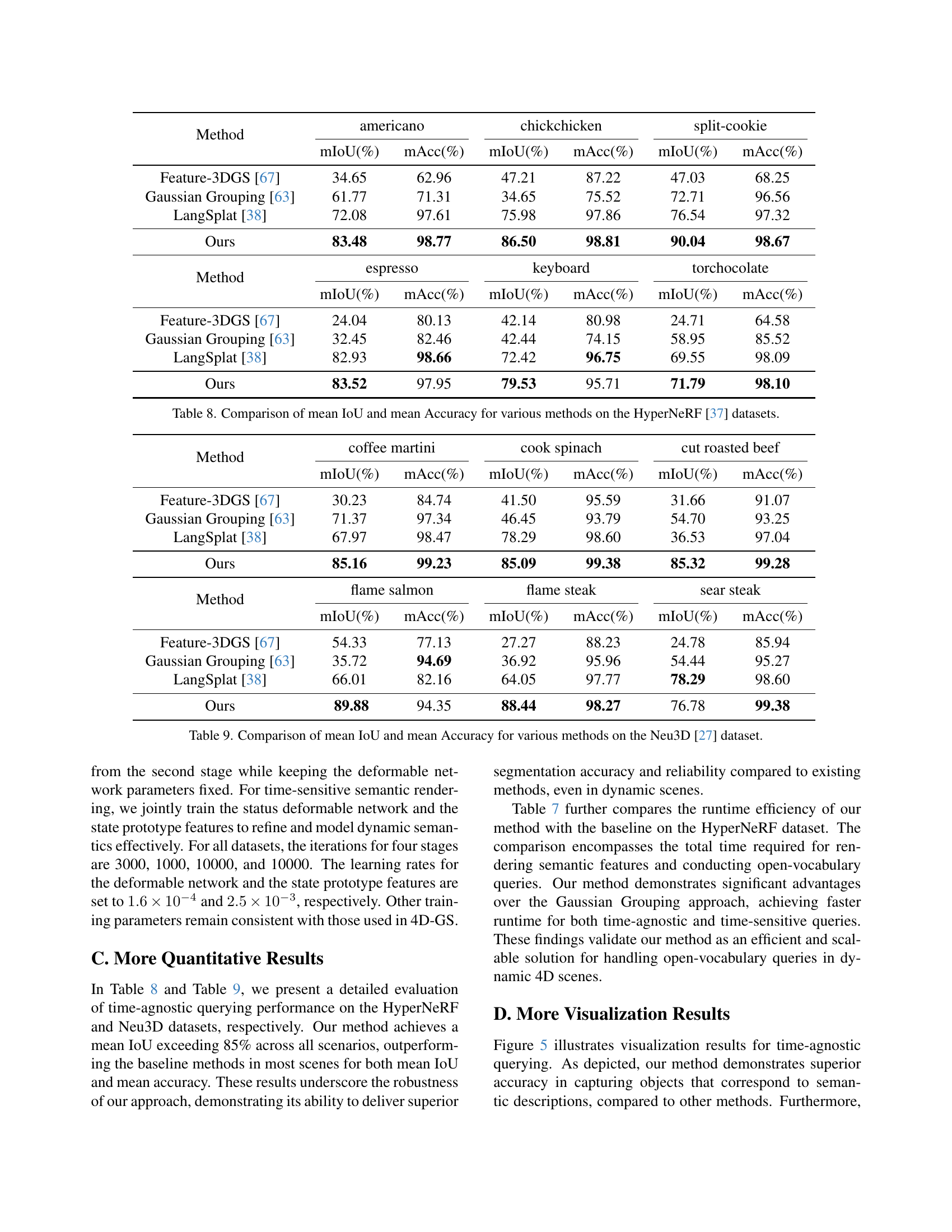
🔼 Table 8 presents a quantitative comparison of the performance of different methods on the HyperNeRF dataset for time-agnostic semantic segmentation. It shows the mean Intersection over Union (mIoU) and mean Accuracy (mAcc) achieved by several approaches including Feature-3DGS, Gaussian Grouping, LangSplat, and the proposed method (Ours). The comparison is done across multiple object categories (americano, chickchicken, split-cookie, espresso, keyboard, torchocolate). This table allows for a direct assessment of the proposed approach’s effectiveness compared to state-of-the-art methods in achieving precise and accurate semantic segmentation in dynamic scenes.
read the caption
Table 8: Comparison of mean IoU and mean Accuracy for various methods on the HyperNeRF [37] datasets.
| Method | FPS |
| Gaussian Grouping [63] | 1.47 |
| Ours-agnostic | 5.24 |
| Ours-sensitive | 4.05 |
🔼 This table presents a quantitative comparison of the performance of different methods on the Neu3D dataset [27] for time-agnostic open-vocabulary queries. The metrics used are mean Intersection over Union (mIoU) and mean Accuracy (mAcc). Multiple semantic categories are evaluated, and the results show the performance of Feature-3DGS [67], Gaussian Grouping [63], LangSplat [38], and the proposed method (Ours). This allows for a direct comparison of the proposed approach against existing state-of-the-art methods in terms of both accuracy and efficiency in handling dynamic scenes.
read the caption
Table 9: Comparison of mean IoU and mean Accuracy for various methods on the Neu3D [27] dataset.
| Method | americano | chickchicken | split-cookie | |||
| mIoU(%) | mAcc(%) | mIoU(%) | mAcc(%) | mIoU(%) | mAcc(%) | |
| Feature-3DGS [67] | 34.65 | 62.96 | 47.21 | 87.22 | 47.03 | 68.25 |
| Gaussian Grouping [63] | 61.77 | 71.31 | 34.65 | 75.52 | 72.71 | 96.56 |
| LangSplat [38] | 72.08 | 97.61 | 75.98 | 97.86 | 76.54 | 97.32 |
| Ours | 83.48 | 98.77 | 86.50 | 98.81 | 90.04 | 98.67 |
| Method | espresso | keyboard | torchocolate | |||
| mIoU(%) | mAcc(%) | mIoU(%) | mAcc(%) | mIoU(%) | mAcc(%) | |
| Feature-3DGS [67] | 24.04 | 80.13 | 42.14 | 80.98 | 24.71 | 64.58 |
| Gaussian Grouping [63] | 32.45 | 82.46 | 42.44 | 74.15 | 58.95 | 85.52 |
| LangSplat [38] | 82.93 | 98.66 | 72.42 | 96.75 | 69.55 | 98.09 |
| Ours | 83.52 | 97.95 | 79.53 | 95.71 | 71.79 | 98.10 |
🔼 This table presents the accuracy results of video classification using MLLM-based embeddings. It compares the performance of the proposed method against state-of-the-art methods (IMP) on three widely used video classification datasets: HMDB51, UCF101, and Kinetics400. The results demonstrate the effectiveness of MLLM-based embeddings in video classification, even without fine-tuning, achieving competitive accuracy scores compared to specialized methods. The table highlights the ability of the MLLM-generated embeddings to capture spatiotemporal information relevant for video understanding tasks.
read the caption
Table 10: Accuracy Results (%) on the Video Classification task.
| Method | coffee martini | cook spinach | cut roasted beef | |||
| mIoU(%) | mAcc(%) | mIoU(%) | mAcc(%) | mIoU(%) | mAcc(%) | |
| Feature-3DGS [67] | 30.23 | 84.74 | 41.50 | 95.59 | 31.66 | 91.07 |
| Gaussian Grouping [63] | 71.37 | 97.34 | 46.45 | 93.79 | 54.70 | 93.25 |
| LangSplat [38] | 67.97 | 98.47 | 78.29 | 98.60 | 36.53 | 97.04 |
| Ours | 85.16 | 99.23 | 85.09 | 99.38 | 85.32 | 99.28 |
| Method | flame salmon | flame steak | sear steak | |||
| mIoU(%) | mAcc(%) | mIoU(%) | mAcc(%) | mIoU(%) | mAcc(%) | |
| Feature-3DGS [67] | 54.33 | 77.13 | 27.27 | 88.23 | 24.78 | 85.94 |
| Gaussian Grouping [63] | 35.72 | 94.69 | 36.92 | 95.96 | 54.44 | 95.27 |
| LangSplat [38] | 66.01 | 82.16 | 64.05 | 97.77 | 78.29 | 98.60 |
| Ours | 89.88 | 94.35 | 88.44 | 98.27 | 76.78 | 99.38 |
🔼 Table 11 presents the results of a spatial-temporal action localization experiment conducted on the UCF101 dataset [44]. The table compares the performance of a method using Multimodal Large Language Model (MLLM)-based embeddings against a state-of-the-art (SOTA) method, HIT [12]. The performance is evaluated using mean average precision (mAP) at three different Intersection over Union (IoU) thresholds (0.1, 0.2, and 0.5). This demonstrates the ability of MLLM-based embeddings to capture spatio-temporal information, even in a zero-shot setting.
read the caption
Table 11: Spatial-Temporal Action Localization Results (%) on UCF101 [44].
Full paper#