TL;DR#
The paper addresses the challenge of training long Chain-of-Thought(COT) models, which is crucial for advanced reasoning tasks. Existing large models require significant computational resources, limiting accessibility. Researchers are exploring smaller, efficient models, but creating them requires careful data selection and training. The current methods often fall short in achieving robust performance, particularly in tasks like math problem-solving.
To solve this, the paper introduces Light-R1, a series of models trained using a curriculum-based approach. This involves multiple stages of Supervised Fine-Tuning (SFT), followed by Direct Preference Optimization (DPO) and Reinforcement Learning (RL). The researchers show that this method allows them to train high-performing models from scratch, using smaller base models and less computational power. They also highlight the importance of a carefully curated dataset, demonstrating that a small, high-quality dataset can significantly improve the performance of various models.
Key Takeaways#
Why does it matter?#
The study offers a practical recipe for training COT models and highlights the importance of SFT data. This work opens doors for more cost-effective and accessible research in reasoning models, enabling researchers with limited resources to push the boundaries of AI.
Visual Insights#

🔼 This figure illustrates the training pipeline used to develop the Light-R1-32B model. It shows the data processing steps, including data collection from various sources, decontamination to remove duplicates and inconsistencies, and difficulty filtering to select the most challenging problems for training. The model training phase is also depicted, highlighting the curriculum learning strategy with two stages of supervised fine-tuning (SFT) followed by direct preference optimization (DPO). This curriculum approach gradually increases the difficulty of the training data to improve model reasoning capabilities. The figure visually summarizes the complete workflow from raw data to the final Light-R1-32B model.
read the caption
Figure 1: Overview of training pipeline of Light-R1-32B.
| Model | AIME24 | AIME25 | GPQA Diamond | Training Recipe |
|---|---|---|---|---|
| Light-R1-32B | 76.6 | 64.6 | 61.8 | SFT stage1&2 + DPO |
| Light-R1-7B-DS | 59.1 | 44.3 | 49.4 | SFT stage2 |
| Light-R1-14B-DS | 74.0 | 60.2 | 61.7 | SFT stage2 + GRPO |
| Light-R1-32B-DS | 78.1 | 65.9 | 68.0 | SFT stage2 |
🔼 This table presents an overview of the Light-R1 series of large language models. It shows the model name, performance metrics (AIME24, AIME25, GPQA, Diamond), and the training recipe used for each model. The ‘AIME’ scores are metrics for mathematical reasoning ability, while GPQA and Diamond measure performance on different reasoning tasks. The training recipes include stages of Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO), with some models also undergoing Reinforcement Learning (RL) with GRPO. The ‘-DS’ suffix indicates models that were fine-tuned from DeepSeek-R1-Distill, while those without the suffix originated from Qwen-Instruct.
read the caption
Table 1: Light-R1 models. “-DS” = from DeepSeek-R1-Distill, otherwise from Qwen-Instruct.
In-depth insights#
Long COT from RL#
Reinforcement Learning (RL) for long Chain-of-Thought (CoT) presents a significant avenue for enhancing reasoning capabilities in language models. The core idea revolves around training models to generate more accurate and complete CoTs, leading to improved performance in complex tasks. The challenge lies in the complexity of RL, as it requires carefully designed reward functions to guide the model toward desired behaviors. A balance needs to be found between exploration and exploitation, ensuring that the model discovers novel reasoning paths while maintaining consistency and reliability. Additionally, the computational cost of RL can be substantial, necessitating efficient training algorithms and infrastructure. Despite these hurdles, the potential benefits of RL for long CoT are immense, paving the way for more robust and intelligent language models.
Curriculum Design#
Curriculum design is critical for training long-context models, particularly from scratch. A multi-stage approach with increasing difficulty helps the model gradually acquire complex reasoning skills. The process starts with a general dataset that introduces fundamental concepts and then transitions to more challenging problems requiring sophisticated reasoning. This gradual exposure prevents the model from being overwhelmed and ensures effective learning. Data selection is also important which involves strategies for identifying and prioritizing valuable training examples.
SFT+DPO Scaling#
Scaling SFT (Supervised Fine-Tuning) and DPO (Direct Preference Optimization) presents a compelling paradigm for enhancing language model capabilities. The effectiveness of SFT hinges on the quality and diversity of the training data, while DPO leverages human preferences to align models with desired behaviors. Scaling both aspects requires careful consideration: For SFT, this involves expanding the dataset with high-quality examples that cover a wide range of tasks and reasoning abilities. DPO scaling involves gathering more preference data, potentially through active learning strategies that prioritize examples where the model is uncertain. Successfully scaling SFT+DPO needs balancing between model capacity, data quality, and computational costs, paving the way for significant advancements in language model performance and alignment.
R1 Reproducibility#
The paper emphasizes the importance of reproducible results in the context of training large language models for long-chain-of-thought reasoning. It details the establishment of stable and trustworthy evaluation protocols mirroring those used by DeepSeek-AI to ensure the reliability of their findings. This commitment to reproducibility is evident in the release of evaluation code and logs, enabling others to independently verify the reported performance. The ability to reproduce results from other prominent models like DeepSeek-R1 and Qwen further strengthens the credibility of the research and provides a solid foundation for future work. The paper notes difficulties in matching the performance of models such as DeepSeek-R1 with smaller models trained on less data, highlighting the challenges in achieving comparable results even with open-source efforts. The study meticulously addresses data contamination issues, which is a crucial aspect of reproducibility, by rigorously cleaning training datasets to avoid biases and inaccurate performance evaluations. They thoroughly decontaminate datasets to ensure a fair comparison with benchmark datasets, which is a key factor of reproducibility. Reproducibility is central to validating their curriculum SFT, DPO, and RL approach for long COT model training.
High Data Quality#
High data quality is paramount for training effective AI models, especially in tasks requiring reasoning and problem-solving. The quality of data directly impacts a model’s ability to learn, generalize, and perform well on unseen examples. Data quality encompasses various aspects, including accuracy, completeness, consistency, and relevance. Accurate data ensures the model learns from correct information, preventing the propagation of errors and biases. Complete data provides the model with all the necessary information to understand the context and make informed decisions. Consistent data ensures that the model can rely on the information it receives, without being confused by conflicting or contradictory inputs. Finally, relevant data ensures that the model focuses on the most important information for the task at hand. Maintaining high data quality requires careful data collection, cleaning, and validation processes. This may involve manual inspection, automated checks, and the use of data augmentation techniques to address data gaps and inconsistencies. Investing in high data quality is essential for building reliable and trustworthy AI systems.
More visual insights#
More on tables
| Model | AIME24 pass@1, paper | AIME24 pass@1, ours |
|---|---|---|
| DeepSeek-R1-distill-Qwen-32B | 72.6 | 72.3 |
| DeepSeek-R1-distill-Qwen-14B | 69.7 | 69.3 |
| DeepSeek-R1-distill-Qwen-7B | 55.5 | 54.0 |
| QWQ-32B | 79.5 | 78.5 |
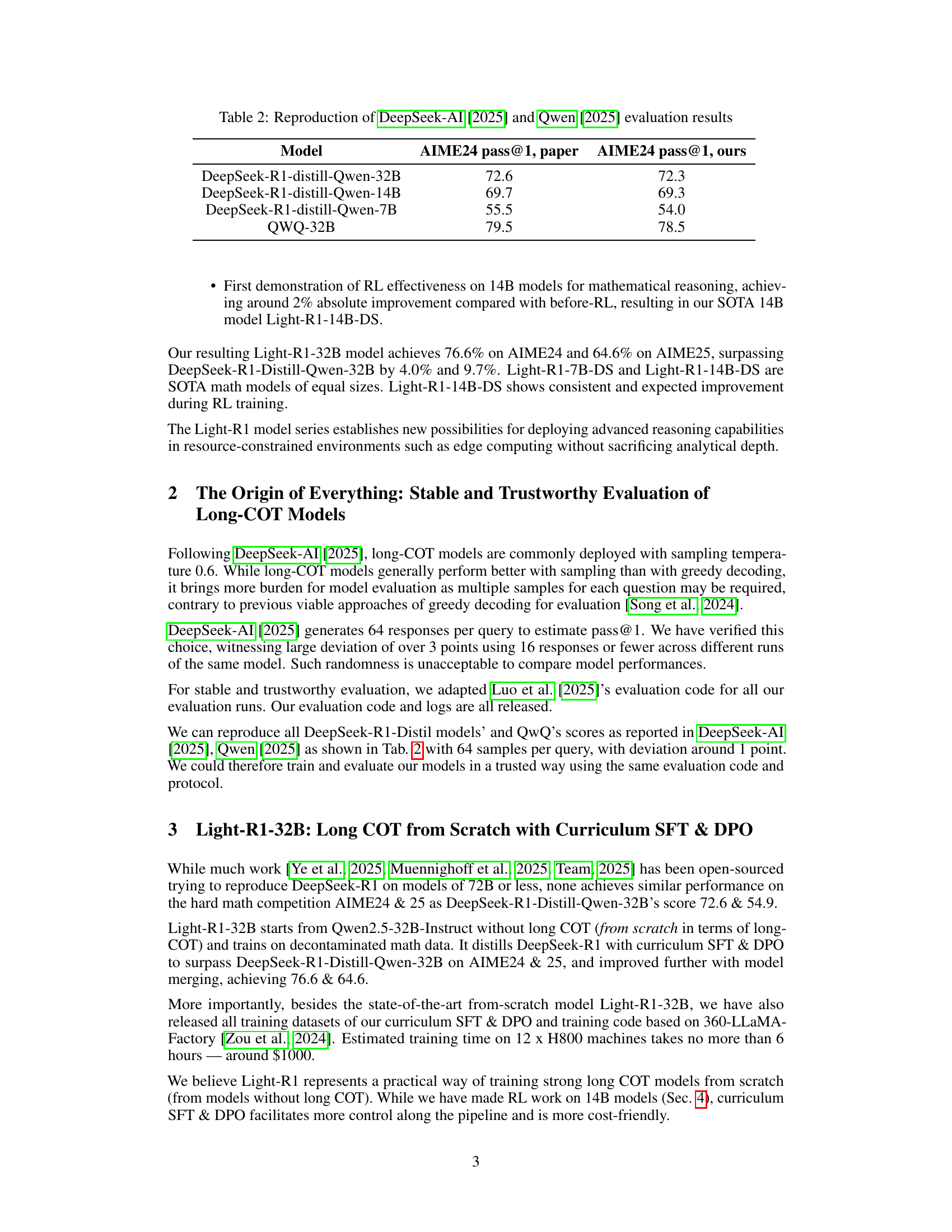
🔼 This table presents the reproduction of evaluation results reported in two previous research papers: DeepSeek-AI [2025] and Qwen [2025]. It compares the performance of various models, specifically DeepSeek-R1 models distilled with Qwen and the QWQ-32B model, across two metrics: AIME24 pass@1 and AIME25 pass@1. The ‘pass@1’ metric signifies the percentage of questions where the model provided a correct answer as its first response. The table serves to validate the reproducibility of the evaluation process used in the current study by replicating previously published results, confirming the trustworthiness of the evaluation methods employed.
read the caption
Table 2: Reproduction of DeepSeek-AI [2025] and Qwen [2025] evaluation results
| Dataset | AIME24+25 | MATH-500 | GPQA Diamond |
|---|---|---|---|
| OpenThoughts-114k | 0 | 100 | 0 |
| Open-R1-Math-220k | 0 | 10 | 0 |
| DeepScaleR-Preview-Dataset | 0 | 196 | 0 |
| LIMO | 0 | 0 | 0 |
| Bespoke-Stratos-17k | 0 | 125 | 0 |
| Open-Reasoner-Zero | 0 | 325 | 0 |
| simplescaling/data_ablation_full59K | 0 | 244 | 1 |
| simplescaling/s1K-1.1 | 0 | 3 | 1 |
| ours | 0 | 0 | 0 |
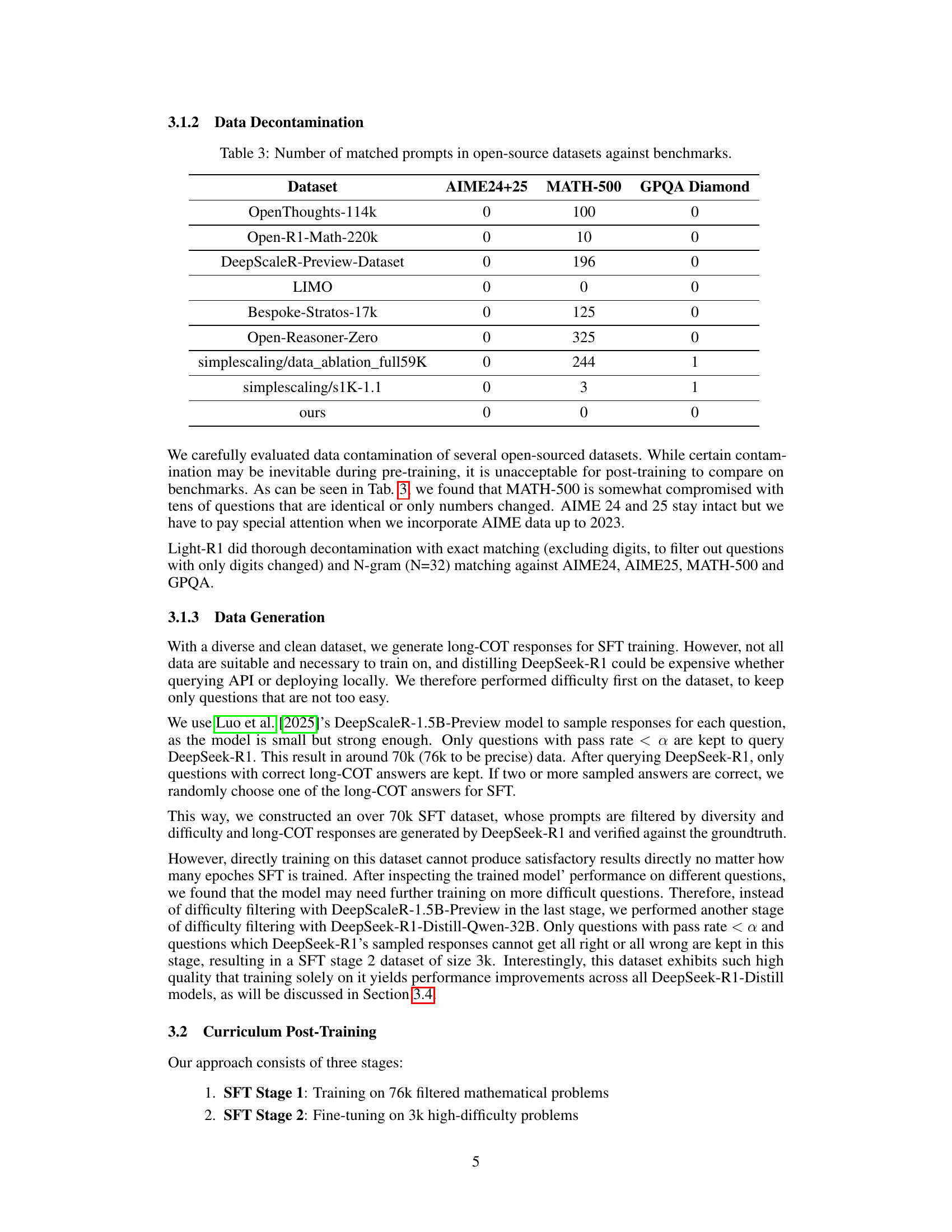
🔼 This table shows the number of overlapping prompts (questions) found in several open-source datasets used for large language model training when compared to established benchmark datasets. The goal is to assess the degree of data contamination or overlap between these datasets, highlighting potential issues of redundancy or bias in training data. Datasets listed include several HuggingFace datasets and a custom dataset created by the authors. Benchmarks being compared against include AIME24+25, MATH-500, GPQA, and Diamond.
read the caption
Table 3: Number of matched prompts in open-source datasets against benchmarks.
| Stage | AIME24 | AIME25 | GPQA Diamond |
|---|---|---|---|
| Qwen2.5-32B-Instruct (base model) | 16.6 | 13.6 | 48.8 |
| Light-R1-32B-SFT-stage1 | 69.0 | 57.4 | 64.3 |
| Light-R1-32B-SFT-stage2 | 73.0 | 64.3 | 60.6 |
| Light-R1-32B-DPO | 75.8 | 63.4 | 61.8 |
| Light-R1-32B (merged model) | 76.6 | 64.6 | 61.8 |
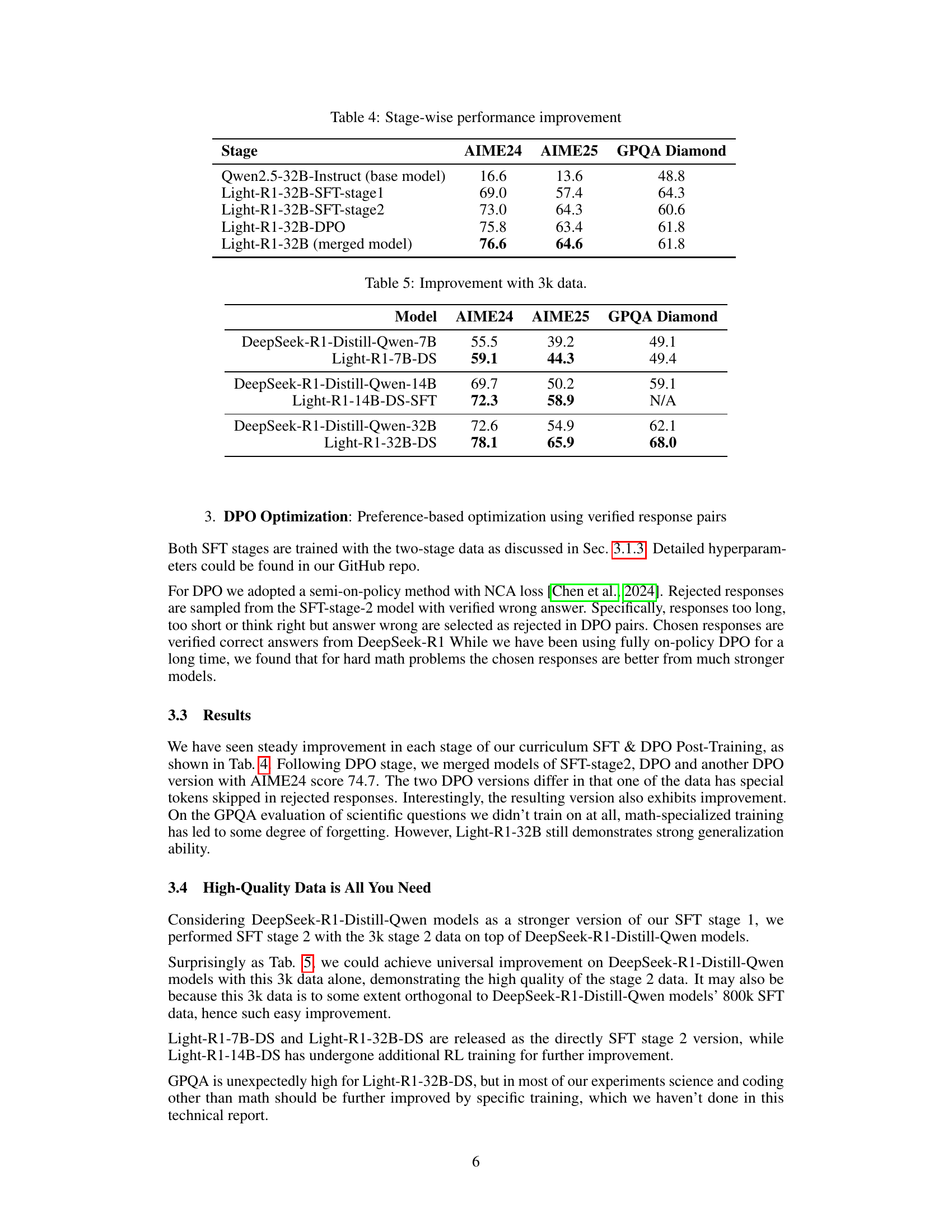
🔼 This table shows the performance improvement at each stage of the curriculum learning process for the Light-R1-32B model. It illustrates the gains achieved after each stage: SFT stage 1, DPO, and SFT stage 2, showing the improvement in AIME24 and AIME25 scores, as well as GPQA and Diamond benchmark scores. The base model’s scores are also included for comparison.
read the caption
Table 4: Stage-wise performance improvement
| Model | AIME24 | AIME25 | GPQA Diamond |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 39.2 | 49.1 |
| Light-R1-7B-DS | 59.1 | 44.3 | 49.4 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 50.2 | 59.1 |
| Light-R1-14B-DS-SFT | 72.3 | 58.9 | N/A |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 54.9 | 62.1 |
| Light-R1-32B-DS | 78.1 | 65.9 | 68.0 |
🔼 This table presents the performance improvements achieved by fine-tuning various DeepSeek-R1-Distill-Qwen models using a new 3k dataset focused on high-difficulty mathematical problems. It compares the performance of the original DeepSeek-R1-Distill-Qwen models with the performance after fine-tuning on the 3k dataset across different model sizes (7B, 14B, and 32B parameters) and evaluation metrics (AIME24, AIME25, GPQA, and Diamond). This showcases the effectiveness of the 3k dataset in enhancing the reasoning capabilities of these models.
read the caption
Table 5: Improvement with 3k data.
| Model | AIME24 | AIME25 | GPQA Diamond |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 50.2 | 59.1 |
| Light-R1-14B-DS-SFT | 72.3 | 58.9 | N/A |
| Light-R1-14B-DS-SFT-GPRO epoch1 | 72.3 | 57.8 | N/A |
| Light-R1-14B-DS-SFT-GPRO epoch2 | 73.4 | 60.5 | N/A |
| Light-R1-14B-DS(-SFT-GPRO epoch3) | 74.0 | 60.2 | 61.7 |
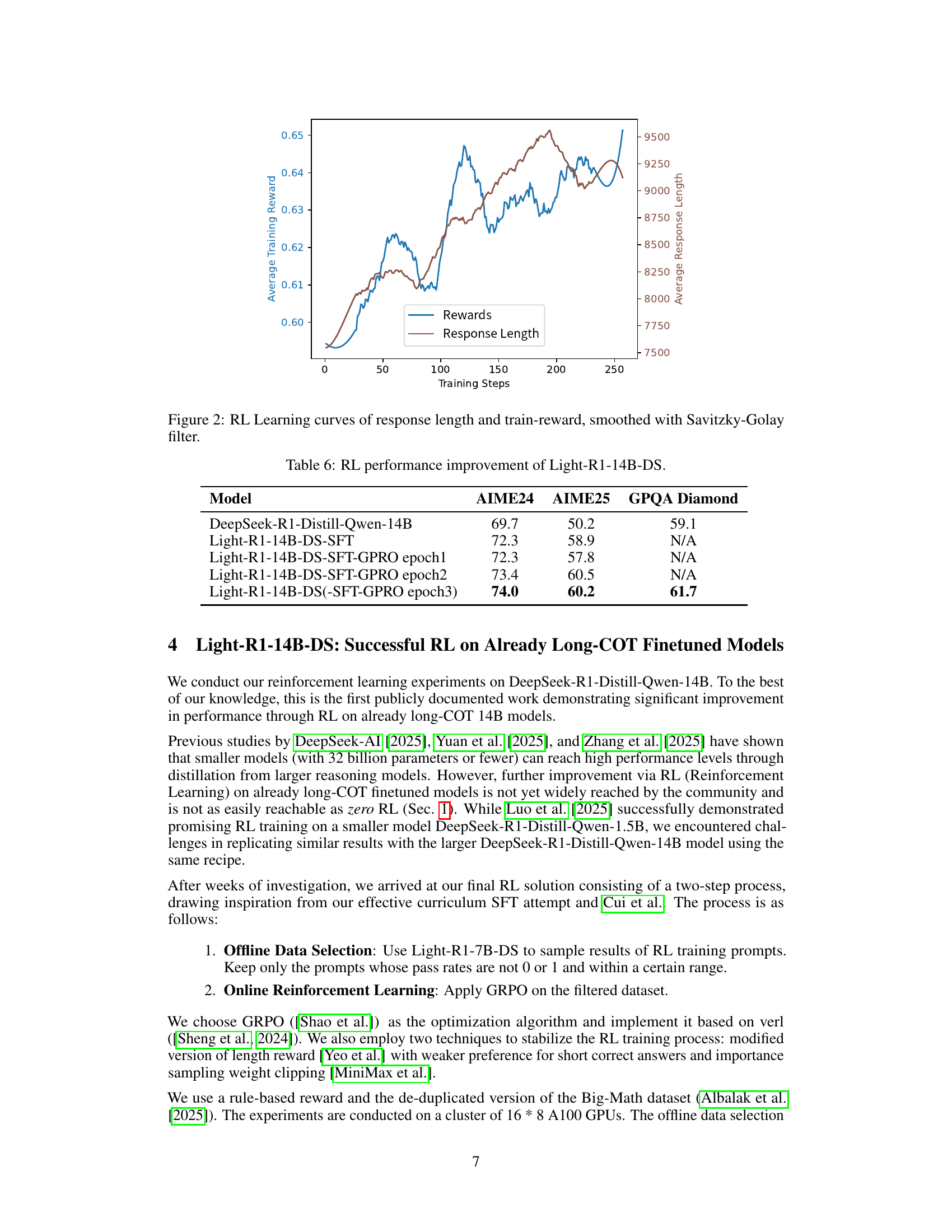
🔼 This table presents the performance improvement achieved by applying reinforcement learning (specifically, GRPO) to the Light-R1-14B-DS model. It compares the AIME24 and AIME25 scores (metrics for mathematical problem-solving) and GPQA Diamond scores (a measure of general reasoning ability) before and after each epoch of reinforcement learning. This demonstrates the effectiveness of RL in enhancing the model’s capabilities.
read the caption
Table 6: RL performance improvement of Light-R1-14B-DS.
Full paper#