TL;DR#
Large Vision-Language Models (LVLMs) face challenges in embodied task planning due to dependency constraints and efficiency issues. Current methods often overlook learning to model the world to enhance planning. They either optimize action selection or leverage world models during inference. This limits their ability to perform in complex situations and they struggle with issues such as dependency constraints.
The paper introduces Dual Preference Optimization (D2PO), which jointly optimizes state prediction and action selection through preference learning. D2PO allows LVLMs to understand environment dynamics for better planning. It uses a tree search mechanism for exploration via trial-and-error to collect trajectories automatically. Experiments on VoTa-Bench show D2PO outperforms existing methods, achieving superior task success with efficient paths.
Key Takeaways#
Why does it matter?#
This research is crucial for advancing embodied AI by addressing limitations in current LVLMs. D2PO’s innovative approach to dual optimization and tree search offers a pathway to more efficient and capable task planning, influencing future research in robotics, AI agents, and human-computer interaction by enhancing how AI systems understand & interact with complex environments.
Visual Insights#

🔼 The figure illustrates the Dual Preference Optimization (D2PO) framework. D2PO jointly optimizes two key components: a state prediction model (world model) that learns to forecast how the environment changes over time, and an action selection model (policy model) that learns to choose optimal actions. These models are trained using preference learning to predict the better next state and better next action. The combined result is a system that is better able to plan embodied tasks because it understands the dynamic nature of the environment, rather than relying on just static snapshots of the world. The framework receives perception from the environment, then uses a policy model and a world model to determine an action which then changes the environment state.
read the caption
Figure 1: Overview of D2PO: World modeling enables better embodied task planning through joint preference optimization of state prediction and action selection.
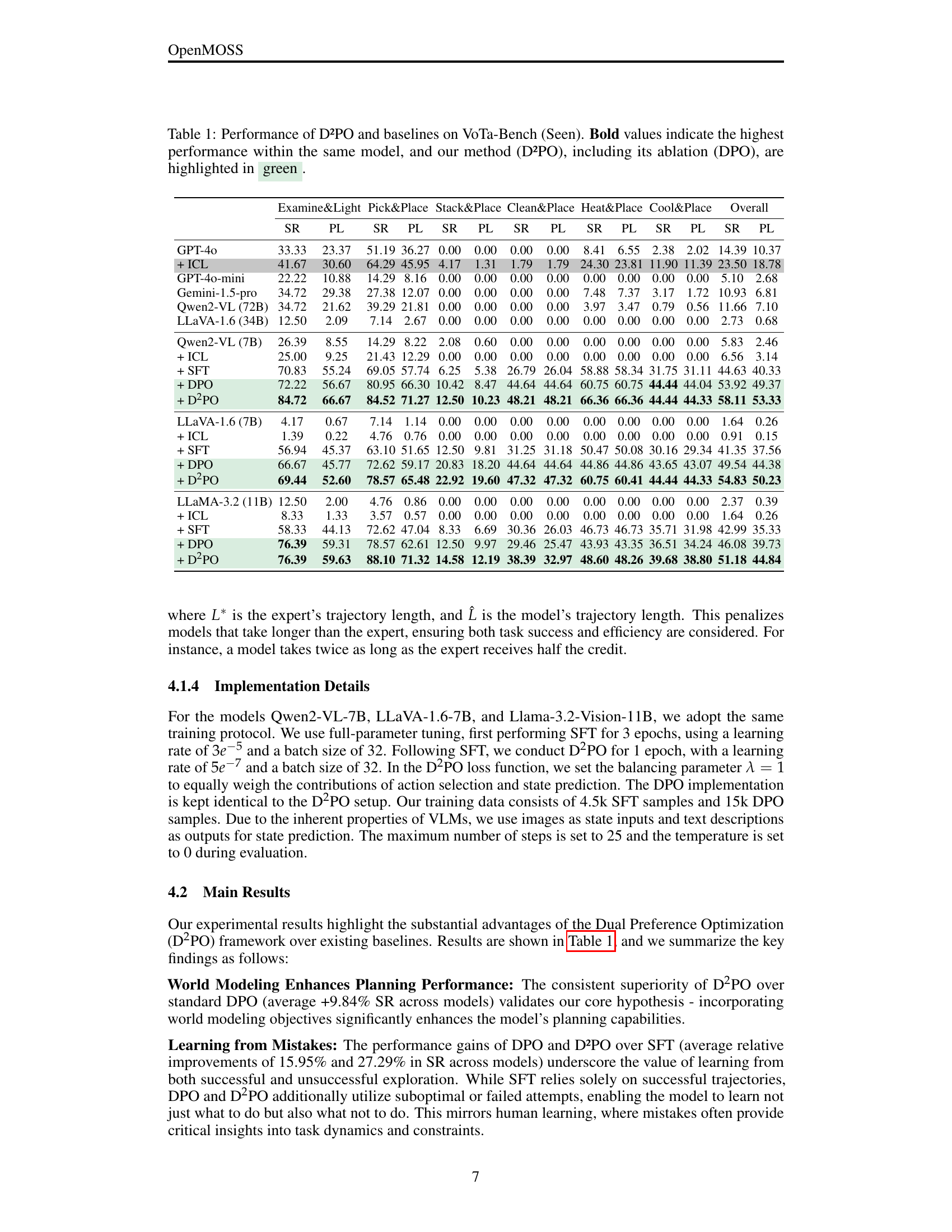
| Examine&Light | Pick&Place | Stack&Place | Clean&Place | Heat&Place | Cool&Place | Overall | ||||||||
| SR | PL | SR | PL | SR | PL | SR | PL | SR | PL | SR | PL | SR | PL | |
| GPT-4o | 33.33 | 23.37 | 51.19 | 36.27 | 0.00 | 0.00 | 0.00 | 0.00 | 8.41 | 6.55 | 2.38 | 2.02 | 14.39 | 10.37 |
| + ICL | 41.67 | 30.60 | 64.29 | 45.95 | 4.17 | 1.31 | 1.79 | 1.79 | 24.30 | 23.81 | 11.90 | 11.39 | 23.50 | 18.78 |
| GPT-4o-mini | 22.22 | 10.88 | 14.29 | 8.16 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 5.10 | 2.68 |
| Gemini-1.5-pro | 34.72 | 29.38 | 27.38 | 12.07 | 0.00 | 0.00 | 0.00 | 0.00 | 7.48 | 7.37 | 3.17 | 1.72 | 10.93 | 6.81 |
| Qwen2-VL (72B) | 34.72 | 21.62 | 39.29 | 21.81 | 0.00 | 0.00 | 0.00 | 0.00 | 3.97 | 3.47 | 0.79 | 0.56 | 11.66 | 7.10 |
| LLaVA-1.6 (34B) | 12.50 | 2.09 | 7.14 | 2.67 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 2.73 | 0.68 |
| Qwen2-VL (7B) | 26.39 | 8.55 | 14.29 | 8.22 | 2.08 | 0.60 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 5.83 | 2.46 |
| + ICL | 25.00 | 9.25 | 21.43 | 12.29 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 6.56 | 3.14 |
| + SFT | 70.83 | 55.24 | 69.05 | 57.74 | 6.25 | 5.38 | 26.79 | 26.04 | 58.88 | 58.34 | 31.75 | 31.11 | 44.63 | 40.33 |
| + DPO | 72.22 | 56.67 | 80.95 | 66.30 | 10.42 | 8.47 | 44.64 | 44.64 | 60.75 | 60.75 | 44.44 | 44.04 | 53.92 | 49.37 |
| + D2PO | 84.72 | 66.67 | 84.52 | 71.27 | 12.50 | 10.23 | 48.21 | 48.21 | 66.36 | 66.36 | 44.44 | 44.33 | 58.11 | 53.33 |
| LLaVA-1.6 (7B) | 4.17 | 0.67 | 7.14 | 1.14 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.64 | 0.26 |
| + ICL | 1.39 | 0.22 | 4.76 | 0.76 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.91 | 0.15 |
| + SFT | 56.94 | 45.37 | 63.10 | 51.65 | 12.50 | 9.81 | 31.25 | 31.18 | 50.47 | 50.08 | 30.16 | 29.34 | 41.35 | 37.56 |
| + DPO | 66.67 | 45.77 | 72.62 | 59.17 | 20.83 | 18.20 | 44.64 | 44.64 | 44.86 | 44.86 | 43.65 | 43.07 | 49.54 | 44.38 |
| + D2PO | 69.44 | 52.60 | 78.57 | 65.48 | 22.92 | 19.60 | 47.32 | 47.32 | 60.75 | 60.41 | 44.44 | 44.33 | 54.83 | 50.23 |
| LLaMA-3.2 (11B) | 12.50 | 2.00 | 4.76 | 0.86 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 2.37 | 0.39 |
| + ICL | 8.33 | 1.33 | 3.57 | 0.57 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.64 | 0.26 |
| + SFT | 58.33 | 44.13 | 72.62 | 47.04 | 8.33 | 6.69 | 30.36 | 26.03 | 46.73 | 46.73 | 35.71 | 31.98 | 42.99 | 35.33 |
| + DPO | 76.39 | 59.31 | 78.57 | 62.61 | 12.50 | 9.97 | 29.46 | 25.47 | 43.93 | 43.35 | 36.51 | 34.24 | 46.08 | 39.73 |
| + D2PO | 76.39 | 59.63 | 88.10 | 71.32 | 14.58 | 12.19 | 38.39 | 32.97 | 48.60 | 48.26 | 39.68 | 38.80 | 51.18 | 44.84 |
🔼 This table presents a comparison of the performance of different methods on the VoTa-Bench dataset. The methods compared include several leading Large Vision-Language Models (LVLMs) such as GPT-40 and Qwen2-VL, along with different training approaches: In-Context Learning (ICL), Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and the proposed Dual Preference Optimization (D2PO). The performance is evaluated across six different task types within the seen environment of the VoTa-Bench dataset. The evaluation metrics used are Success Rate (SR) and Path-Length Weighted Success Rate (PL), which measure both task completion success and planning efficiency. The highest performance for each model and task is highlighted in bold, while the results for DPO and D2PO are highlighted in green to emphasize the proposed method’s performance.
read the caption
Table 1: Performance of D²PO and baselines on VoTa-Bench (Seen). Bold values indicate the highest performance within the same model, and our method (D²PO), including its ablation (DPO), are highlighted in green.
In-depth insights#
Dual Optim.#
The concept of ‘Dual Optimization’ (Dual Optim.) suggests a sophisticated approach where two distinct, yet interconnected objectives are simultaneously pursued. This hints at a system designed to balance potentially conflicting priorities or leverage complementary strengths. In machine learning, such dual optimization could involve jointly optimizing for model accuracy and robustness, or exploration and exploitation, or state prediction and action selection. The key challenge lies in defining appropriate trade-offs and ensuring that progress in one objective doesn’t significantly hinder the other. The success of Dual Optim. hinges on a carefully designed objective function and an effective optimization algorithm that can navigate the complex solution space.
World Modeling#
World modeling plays a pivotal role in embodied AI, enabling agents to interact effectively with their environment. It’s about creating a cognitive framework that allows the agent to understand, predict, and adapt to changes in the world based on its actions. The paper introduces a Dual Preference Optimization (D2PO) framework, which leverages world modeling to enhance planning capabilities. Instead of treating world modeling as a separate component, D2PO uses its objectives to improve the policy’s decision-making. This approach leads to a natural understanding of world dynamics, resulting in more informed action selection without explicit guidance during inference. By predicting future states, the model learns action consequences over time, improving its policy ability and enabling diverse decision-making.
Tree Search Exp.#
Tree search algorithms are essential for diverse AI problems. A well-designed tree search should efficiently explore the state space, balancing exploration and exploitation. Key aspects include the branching factor, dictating the number of potential actions considered at each step, and the search depth, determining the planning horizon. Effective pruning strategies are vital to avoid unnecessary computation by discarding unpromising branches early on. The algorithm must also incorporate mechanisms for evaluating the potential of each node, guiding the search toward more promising paths. Balancing exploration breadth and depth becomes essential to avoid getting stuck in local optima. Furthermore, the ability to backtrack and recover from dead ends is crucial for robust performance. Finally, a successful tree search implementation also necessitates a thoughtful consideration of the algorithm’s computational complexity.
VoTa-Bench Test#
Based on the context, the VoTa-Bench is designed as a closed-loop task planning framework, crucial for embodied AI. It focuses on assessing LLMs planning capabilities by decoupling low-level action execution, unlike ALFRED which evaluates overall performance, emphasizing LLMs’ cognitive abilities for task planning. The extended VoTa-Bench provides egocentric visual information, better supporting vision-language models. Evaluation uses an open-domain generation approach, eliminating reliance on predefined executable skills & logits computation, enhancing flexibility. The new multimodal benchmark incorporates visual information as both the initial state and the observation after each operation, requiring the model to effectively process visual inputs and allows the model’s generation of non-executable skills, creating a more complex testing environment. It includes seen and unseen environments to test generalization. A closed-loop process enables interaction with the environment, taking actions, and updating the environment step-by-step.
No Real World#
The phrase “No Real World” encapsulates a common critique of AI research, particularly in embodied task planning. Many algorithms, including those described in this paper, are developed and evaluated within simulated environments like AI2-THOR. These simulations, while offering controlled experimental settings, often fail to capture the complexities of the real world, such as unpredictable object arrangements, imperfect sensors, and unforeseen interactions. This “sim-to-real gap” raises concerns about the transferability of algorithms trained in simulation to physical robots operating in unstructured, dynamic environments. Addressing this gap is critical for advancing AI beyond theoretical success and enabling practical applications. Methods for bridging the gap include domain randomization, using more realistic simulators, and developing algorithms robust to noise and uncertainty. A real-world deployment and evaluation is often seen as the ultimate test of an AI system.
More visual insights#
More on figures
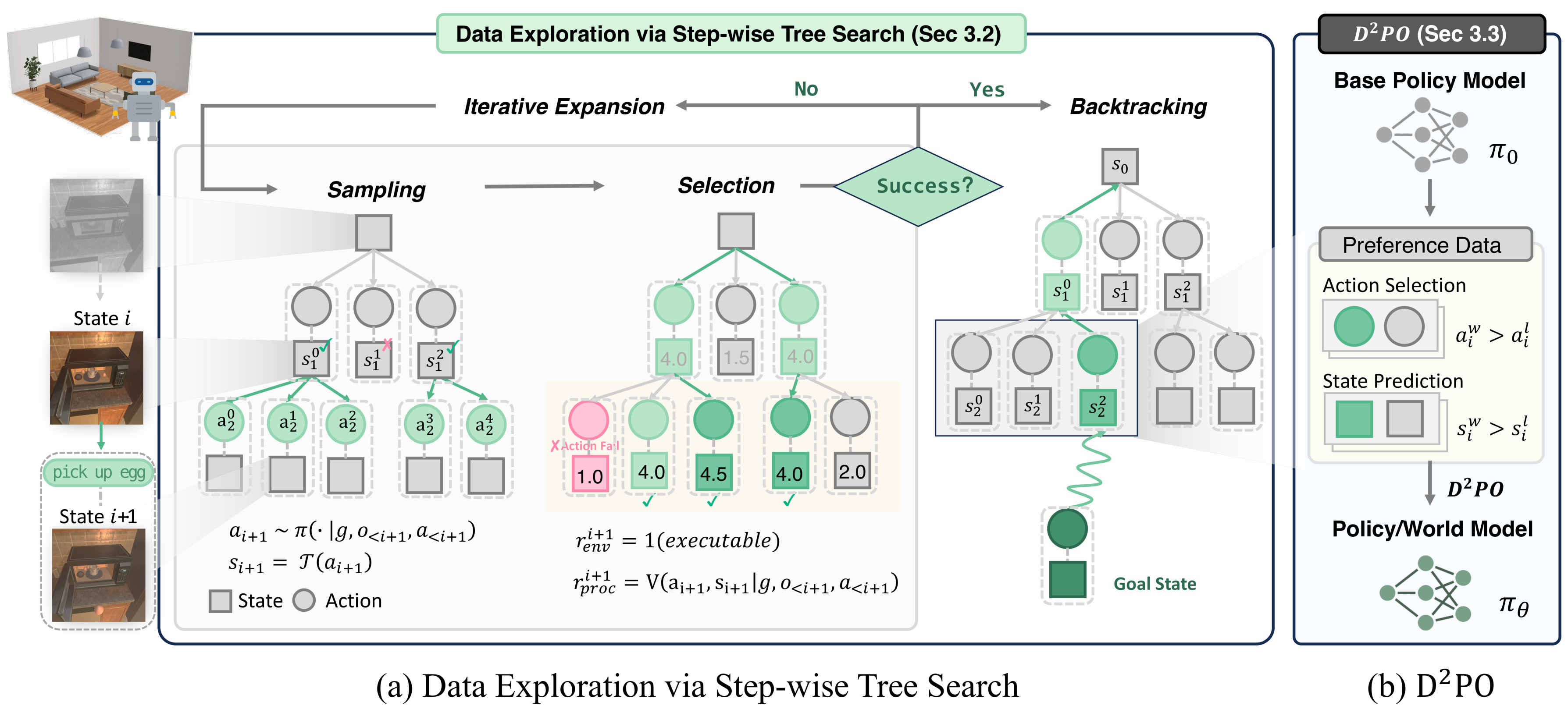
🔼 This figure illustrates the two main components of the proposed method: Data Exploration and Dual Preference Optimization. The Data Exploration component (a) uses a step-wise tree search to systematically explore possible action sequences in the environment. This involves sampling potential actions, iteratively expanding the search tree, and backtracking when necessary. This process automatically collects preference data, comparing chosen actions and their outcomes to alternatives. The Dual Preference Optimization (D2PO) component (b) then leverages the collected preference pairs to jointly optimize both state prediction (world modeling) and action selection. This allows the model to better understand the environment’s dynamics and plan more effectively.
read the caption
Figure 2: Our method consists of two dimensions: (a) Data Exploration via Step-wise Tree Search (Sec 3.2), which collects preference data through sampling and selecting potential actions, iterative tree expansion, and trajectory backtracking; (b) Dual Preference Optimization (D2PO) framework (Sec 3.3) that leverages the collected preference pairs to jointly optimize action selection and state prediction.

🔼 This figure shows the relationship between the amount of training data used and the success rate (SR) achieved by three different methods: Standard Fine-tuning (SFT), Direct Preference Optimization (DPO), and Dual Preference Optimization (D2PO). The x-axis represents different data scales, and the y-axis represents the success rate. The results demonstrate that D2PO consistently outperforms the other two methods across all data scales, showcasing its ability to leverage data effectively. There is also a slight non-monotonic trend in the D2PO performance at larger data sizes, which might be due to overfitting.
read the caption
(a) Impact of data scale on performance (SR).

🔼 This figure shows the relationship between the success rate (SR) and the model size in various embodied task planning models. The larger the model size, the higher the success rate is. The results are presented using bar charts, with different models and approaches (SFT, DPO, D2PO) clearly differentiated.
read the caption
(b) Impact of model scale on performance (SR).

🔼 This figure presents a dual analysis of the impact of data scale and model scale on the performance of the proposed D2PO method. Subfigure (a) shows how the success rate (SR) changes with varying amounts of training data, indicating the relationship between data size and model performance. Subfigure (b) demonstrates how the SR changes with varying model sizes. It allows for a comparison of the effectiveness of D2PO across different data and model scales.
read the caption
Figure 3: Analysis of data scale and model scale.

🔼 This figure compares the success rates (SR) of two different types of world models: action-conditioned and goal-directed. The action-conditioned model predicts the next state based on the current state and the chosen action, while the goal-directed model predicts the future states based on the goal and history of past states and actions. The comparison is performed for both ‘seen’ (familiar) and ‘unseen’ (novel) scenarios to evaluate the generalization ability of each model. The results show that while the action-conditioned model performs better on seen scenarios, the goal-directed model generalizes better to unseen scenarios.
read the caption
Figure 4: Success rates (SR) of action-conditioned and goal-directed world models across seen and unseen scenarios.

🔼 The figure shows a comparison of high-level task planning in ALFRED. ALFRED uses step-by-step instructions, breaking the task into subgoals. The example shows the task of placing a cold tomato in the sink. ALFRED decomposes this into finding the counter top, picking up the tomato, finding the fridge, cooling the tomato, finding the sink, and finally putting down the tomato. Each step is depicted with images from the simulation.
read the caption
(a) ALFRED (high-level planning) (Shridhar et al., 2019)

🔼 This figure shows the task decomposition in LoTa-Bench. It illustrates that the high-level goal is broken down into a sequence of simpler, executable actions for an embodied AI agent to follow within a simulated environment. The example shows that, for the task of placing a cold tomato in the sink, LoTa-Bench decomposes the task into more fine-grained steps than ALFRED (another dataset). For example, it involves finding the tomato, picking it up, finding the fridge, opening it, putting the tomato inside, closing the fridge, finding the sink, and finally placing the tomato in the sink. This decomposition makes the task easier to complete for agents but also makes it less realistic compared to a human’s approach.
read the caption
(b) LoTa-Bench (Choi et al., 2024)

🔼 This figure shows a comparison of three different embodied task planning benchmarks: ALFRED, LoTa-Bench, and the proposed VoTa-Bench. Each benchmark is illustrated with the example task of placing a cold tomato in a sink. ALFRED uses detailed step-by-step instructions, LoTa-Bench uses only a high-level goal instruction, and VoTa-Bench incorporates both a high-level goal instruction and egocentric visual observations at each step, providing a more realistic and challenging evaluation of embodied AI systems.
read the caption
(c) VoTa-Bench (ours)

🔼 Figure 5 compares three different approaches to embodied task planning using the example task ‘Place a cold tomato in the sink’. ALFRED (a) uses high-level instructions broken down into sub-goals (like ‘Cool Tomato’). LoTa-Bench (b) uses only a goal instruction and breaks the task into very specific, low-level actions, but lacks visual input, relying on pre-defined actions. VoTa-Bench (c), the proposed method, extends LoTa-Bench by adding egocentric visual input, requiring the model to generate more open-ended actions based on both the goal and visual observations. This allows it to handle both seen and unseen environments.
read the caption
Figure 5: Comparison of ALFRED, LoTa-Bench, and VoTa-Bench in the task “Place a cold tomato in the sink”. (a) ALFRED emphasizes high-level task planning with human-written step-by-step instructions, breaking the task into subgoals like “Cool Tomato” (step 4). (b) LoTa-Bench provides only goal instructions and decomposes tasks into fine-grained low-level actions (e.g., “Open Fridge”, “PutDown Tomato”, etc.; steps 4–10) but lacks guidance from visual input, relying on predefined executable actions, choosing actions based on maximum logits to ensure they are valid in the simulation. (c) VoTa-Bench extends LoTa-Bench by incorporating egocentric visual observations, requiring models to generate open-domain actions based on visual information to handle both seen and unseen environments.

🔼 This figure shows examples of scenes from the VoTa-Bench dataset used in the experiments. Panel (a) specifically displays examples of seen scenes, meaning these scene layouts and object arrangements were present in the training data for the models. The figure helps to illustrate the visual environment the embodied AI agents are interacting with. The visual information is crucial input to the models in this embodied task planning research.
read the caption
(a) Seen Scenes

🔼 This figure shows example images of unseen scenes from the VoTa-Bench dataset. These scenes represent environments not included in the training data, and are used to evaluate the model’s generalization ability to novel and unseen layouts and object configurations within the AI2-THOR simulator.
read the caption
(b) Unseen Scenes

🔼 This figure visualizes example scenes from the VoTa-Bench dataset, showcasing both ‘seen’ and ‘unseen’ environments. Seen scenes represent environments with layouts and object distributions similar to those in the training data, allowing the model to leverage prior experience. In contrast, unseen scenes present novel layouts and object arrangements that the model hasn’t encountered during training. This distinction helps illustrate the generalization capabilities of embodied AI models. The figure demonstrates the dataset’s diversity in scene arrangement and object placement, highlighting the challenges and opportunities for more robust AI models that can handle unseen situations effectively.
read the caption
Figure 6: Examples of seen and unseen scenes.

🔼 Figure 7 presents a comparative analysis of the dataset distributions for two distinct training methods: Supervised Fine-Tuning (SFT) and Dual Preference Optimization (DPO). The figure uses a bar chart to visually represent the proportion of each task type within each dataset. The task types include ‘Examine & Light’, ‘Pick & Place’, ‘Stack & Place’, ‘Clean & Place’, ‘Heat & Place’, and ‘Cool & Place’. By comparing the distributions, we can gain insights into whether the two methods exhibit similar or distinct preferences in terms of task complexity or types of interaction.
read the caption
Figure 7: Distribution of the SFT and DPO dataset across different task types.

🔼 This figure shows a sequence of images depicting the steps taken by a model trained using supervised fine-tuning (SFT) while attempting a specific task. The trajectory ultimately fails to complete the task successfully, highlighting issues such as incorrect action sequencing and a lack of understanding of task dependencies. Each image represents a step in the process, and the caption indicates that the attempt is unsuccessful. The figure is used to contrast the performance of the SFT model with models trained using other methods, thereby showcasing the effectiveness of the proposed approach.
read the caption
(a) SFT Trajectory (Fail)
More on tables
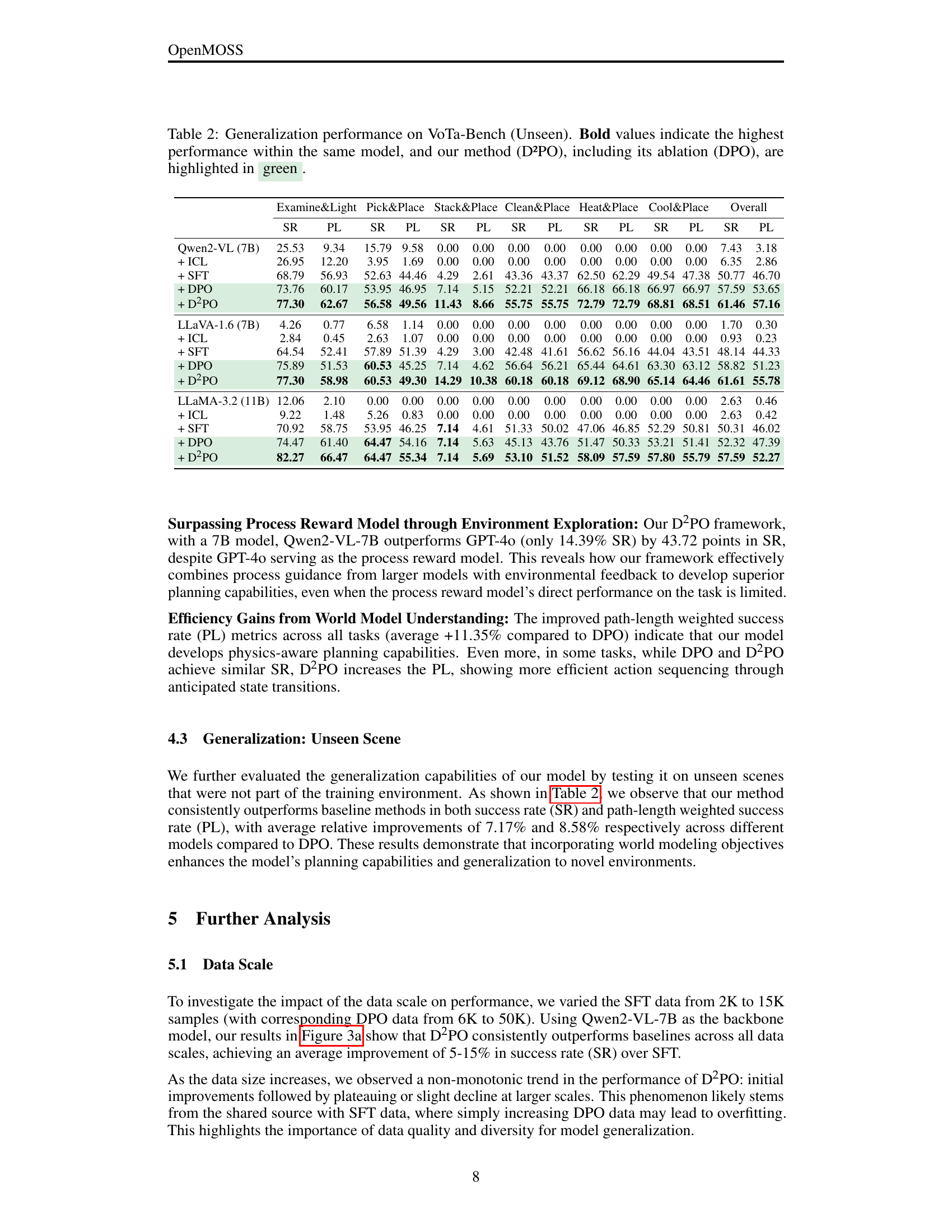
| Examine&Light | Pick&Place | Stack&Place | Clean&Place | Heat&Place | Cool&Place | Overall | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SR | PL | SR | PL | SR | PL | SR | PL | SR | PL | SR | PL | SR | PL | |
| Qwen2-VL (7B) | 25.53 | 9.34 | 15.79 | 9.58 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 7.43 | 3.18 |
| + ICL | 26.95 | 12.20 | 3.95 | 1.69 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 6.35 | 2.86 |
| + SFT | 68.79 | 56.93 | 52.63 | 44.46 | 4.29 | 2.61 | 43.36 | 43.37 | 62.50 | 62.29 | 49.54 | 47.38 | 50.77 | 46.70 |
| + DPO | 73.76 | 60.17 | 53.95 | 46.95 | 7.14 | 5.15 | 52.21 | 52.21 | 66.18 | 66.18 | 66.97 | 66.97 | 57.59 | 53.65 |
| + D2PO | 77.30 | 62.67 | 56.58 | 49.56 | 11.43 | 8.66 | 55.75 | 55.75 | 72.79 | 72.79 | 68.81 | 68.51 | 61.46 | 57.16 |
| LLaVA-1.6 (7B) | 4.26 | 0.77 | 6.58 | 1.14 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.70 | 0.30 |
| + ICL | 2.84 | 0.45 | 2.63 | 1.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.93 | 0.23 |
| + SFT | 64.54 | 52.41 | 57.89 | 51.39 | 4.29 | 3.00 | 42.48 | 41.61 | 56.62 | 56.16 | 44.04 | 43.51 | 48.14 | 44.33 |
| + DPO | 75.89 | 51.53 | 60.53 | 45.25 | 7.14 | 4.62 | 56.64 | 56.21 | 65.44 | 64.61 | 63.30 | 63.12 | 58.82 | 51.23 |
| + D2PO | 77.30 | 58.98 | 60.53 | 49.30 | 14.29 | 10.38 | 60.18 | 60.18 | 69.12 | 68.90 | 65.14 | 64.46 | 61.61 | 55.78 |
| LLaMA-3.2 (11B) | 12.06 | 2.10 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 2.63 | 0.46 |
| + ICL | 9.22 | 1.48 | 5.26 | 0.83 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 2.63 | 0.42 |
| + SFT | 70.92 | 58.75 | 53.95 | 46.25 | 7.14 | 4.61 | 51.33 | 50.02 | 47.06 | 46.85 | 52.29 | 50.81 | 50.31 | 46.02 |
| + DPO | 74.47 | 61.40 | 64.47 | 54.16 | 7.14 | 5.63 | 45.13 | 43.76 | 51.47 | 50.33 | 53.21 | 51.41 | 52.32 | 47.39 |
| + D2PO | 82.27 | 66.47 | 64.47 | 55.34 | 7.14 | 5.69 | 53.10 | 51.52 | 58.09 | 57.59 | 57.80 | 55.79 | 57.59 | 52.27 |
🔼 Table 2 presents the results of evaluating the generalization capabilities of different methods on unseen environments within the VoTa-Bench benchmark. The table shows the success rate (SR) and path-length weighted success rate (PL) for each method on various tasks, broken down into categories such as Examine & Light, Pick & Place, etc. The highest SR and PL scores for each model are bolded, and the results for the D²PO method (and its ablation DPO) are highlighted in green to emphasize its superior performance. The ‘Unseen’ designation indicates that the models are tested on environments and tasks that they were not trained on, directly assessing their ability to generalize to novel situations.
read the caption
Table 2: Generalization performance on VoTa-Bench (Unseen). Bold values indicate the highest performance within the same model, and our method (D²PO), including its ablation (DPO), are highlighted in green.
| SFT | DPO | D2PO | |
|---|---|---|---|
| Dependency Error | 212 | 157 | 141 |
| Affordance Error | 144 | 141 | 128 |
| Inefficient Error | 141 | 93 | 78 |
| Others | 20 | 16 | 17 |
🔼 This table presents a quantitative analysis of the different types of errors made by three distinct embodied task planning methods: Standard Fine-tuning (SFT), Direct Preference Optimization (DPO), and Dual Preference Optimization (D2PO). It breaks down the number of occurrences of Dependency Errors, Affordance Errors, Inefficient Errors, and Other types of errors for each method. This allows for a comparison of the error profiles across methods, showing which method is more prone to each error category and to what extent.
read the caption
Table 3: Distribution of error types across different methods.
| Task Type | Seen | Unseen | Sample Instruction | ||
|---|---|---|---|---|---|
| Num | Avg Length | Num | Avg Length | ||
| Examine & Light | 72 | 4.00 | 141 | 4.34 | Examine a vase under a tall lamp |
| Pick & Place | 84 | 4.46 | 77 | 5.70 | Put pencil on bureau top |
| Stack & Place | 48 | 10.60 | 70 | 8.49 | Put a pot with a sponge in it in the sink. |
| Clean & Place | 112 | 12.66 | 113 | 12.88 | Put a cleaned washcloth away in a cabinet. |
| Heat & Place | 107 | 18.35 | 136 | 17.38 | To heat a potato slice and put it on the table by the spoon. |
| Cool & Place | 126 | 15.48 | 109 | 14.48 | Chill a knife and place a chilled slice of lettuce in a sink. |
| Total | 549 | 11.85 | 646 | 10.90 | |
🔼 Table 4 presents a detailed breakdown of the tasks included in the VoTa-Bench dataset, categorized into ‘seen’ and ‘unseen’ environments. For each task type (Examine & Light, Pick & Place, etc.), it provides the number of samples and the average length of the action sequence required for completion. Sample instructions are also given to clarify the nature of each task type and provide context for understanding the dataset’s composition.
read the caption
Table 4: Distribution of task types in VoTa-Bench. The dataset is divided into seen and unseen environments, with statistics showing the number of samples (Num) and average action sequence length (Avg Length) for each task type. Example instructions are provided to illustrate typical tasks.
| SFT | DPO | D2PO | |
|---|---|---|---|
| Dependency Error | 212 | 157 | 141 |
| Affordance Error | 144 | 141 | 128 |
| Inefficient Error | 141 | 93 | 78 |
| Others | 20 | 16 | 17 |
🔼 This table presents a quantitative analysis of different error types encountered across three distinct embodied task planning methods: Standard Fine-Tuning (SFT), Direct Preference Optimization (DPO), and the proposed Dual Preference Optimization (D2PO). It shows the frequency of each error category (Dependency Error, Affordance Error, Inefficient Error, and Others) for each method. This allows for a comparison of the relative success of each method in avoiding different types of errors, providing insight into their respective strengths and weaknesses in embodied task planning.
read the caption
Table 5: Distribution of Error Types Across Different Methods
Full paper#