TL;DR#
Existing open-vocabulary robotic systems often overlook object dynamics, limiting their application to complex tasks. On the other hand, dynamics models require pre-defined targets, which are difficult to infer from language instructions. The key question is how to develop open-vocabulary manipulation systems that harness the flexibility of VLMs and the benefits of model-based planning.
To address this, the paper introduces KUDA, a novel system that uses keypoints to unify VLMs and dynamics models. KUDA takes language instructions and visual observations as input, assigns keypoints, and uses a VLM to generate target specifications. These specifications are converted into cost functions for model-based planning with learned dynamics models. KUDA demonstrates state-of-the-art performance on various tasks, including manipulating deformable objects.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it bridges the gap between VLMs and dynamics modeling, enabling more complex robot manipulation. This opens new research avenues in areas like deformable object manipulation, dynamic task planning, and integration of VLMs with robotic control systems. KUDA could inspire more robust and versatile robotic systems.
Visual Insights#
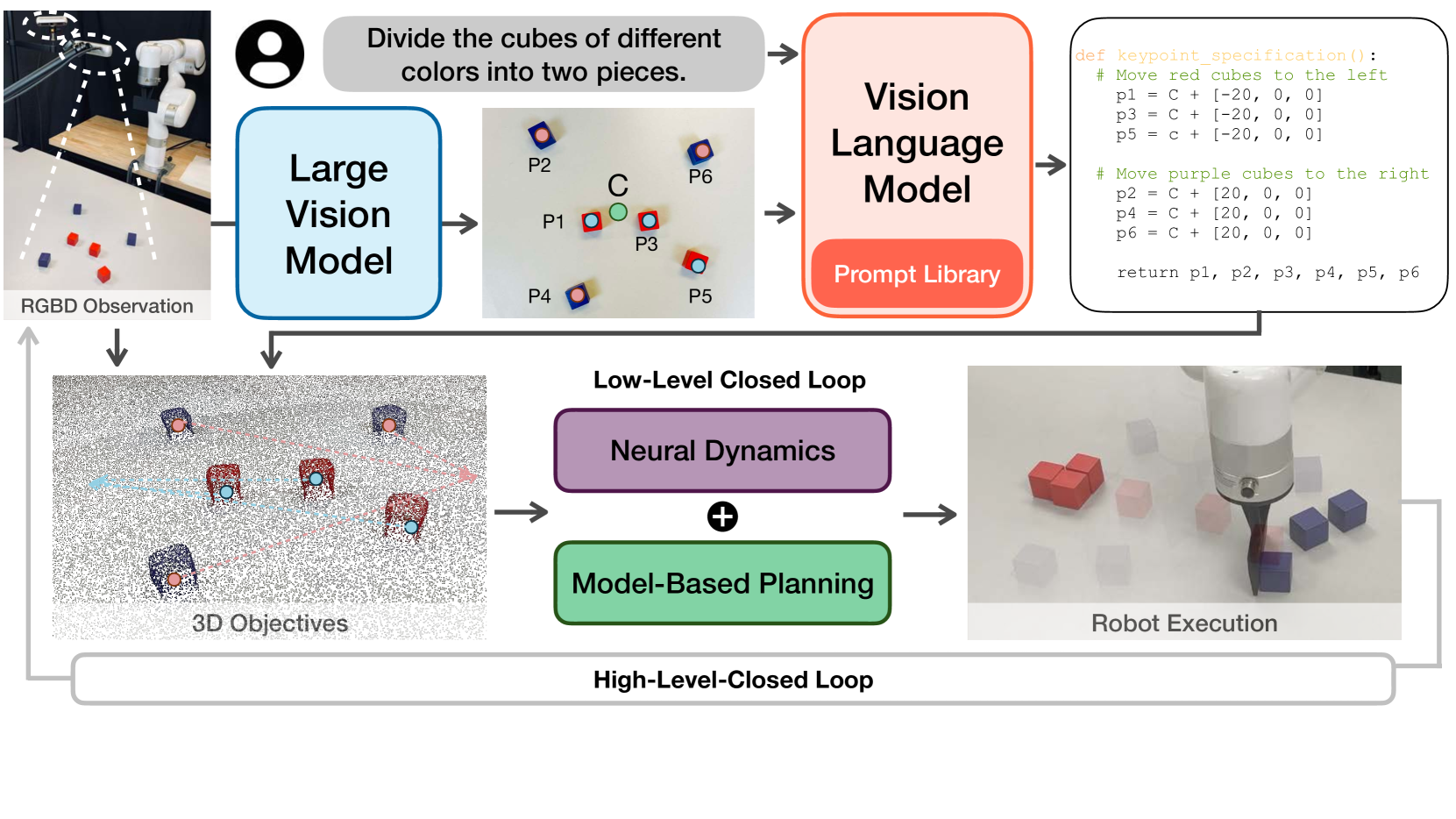
🔼 KUDA, an open-vocabulary robotic manipulation system, uses keypoints to integrate visual prompting (from Vision Language Models) and dynamics learning. Given an RGBD image and a language instruction, KUDA identifies keypoints, uses a VLM to generate code defining keypoint targets, translates these into a cost function, and uses learned dynamics models for model-based planning to achieve the manipulation task. This allows for open-vocabulary manipulation across diverse objects.
read the caption
Figure 1: KUDA is an open-vocabulary manipulation system that uses keypoints to unify the visual prompting of vision language models (VLMs) and dynamics modeling. Taking the RGBD observation and the language instruction as inputs, KUDA samples keypoints in the environment, then uses a VLM to generate code specifying keypoint-based target specification. These keypoints are translated into a cost function for model-based planning with learned dynamics models, enabling open-vocabulary manipulation across various object categories.
| Methods | MOKA [11] | VoxPoser [10] | Ours |
|---|---|---|---|
| Rope Straightening | 2/10 | 0/10 | 8/10 |
| Cube Collection | 0/10 | 3/10 | 6/10 |
| Cube Movement | 6/10 | 3/10 | 10/10 |
| Granular Collection | 0/10 | 1/10 | 10/10 |
| Granular Movement | 0/10 | 1/10 | 6/10 |
| T Movement | 0/10 | 0/10 | 8/10 |
| Total | 13.3% | 13.3% | 80.0% |
🔼 This table presents a quantitative comparison of the proposed KUDA method against two baseline methods (MOKA and VoxPoser) across six robotic manipulation tasks involving various object categories (rope, cubes, granular objects, and T-shaped block). The success rate for each task and method is reported, indicating the percentage of successful trials out of 10 attempts. KUDA demonstrates significantly higher success rates than the baselines, particularly in more challenging tasks such as granular object manipulation. While KUDA achieved high overall success, the analysis highlights that failures were mainly attributed to perception errors, specifically impacting the ‘Cube Collection’ and ‘Granular Movement’ tasks.
read the caption
TABLE I: Quantitative results of our evaluation. Our method achieved relatively high performance across all evaluation tasks compared to the two baselines, while the failures in Cube Collection and Granular Movement were primarily caused by perception.
In-depth insights#
Keypoint Unification#
Keypoint Unification offers a compelling approach to bridge the gap between VLMs and dynamics learning in robotic manipulation. By using keypoints as an intermediate representation, it leverages the interpretability of VLMs while providing a structured format suitable for cost function definition in model-based planning. The strength lies in its ability to translate abstract language instructions into actionable, quantifiable goals for robot execution. It allows for greater flexibility in task specification and enabling robots to perform more complex tasks beyond simple rigid object manipulation. It can be particularly impactful for tasks involving deformable objects and granular materials, where precise control is essential and traditional methods fall short.
VLM Prompting#
VLM Prompting is pivotal in guiding Vision-Language Models for robotic tasks. Effective prompts enable VLMs to generate precise, actionable target specifications from abstract language instructions and visual observations. Key is using visual markers (keypoints) to enhance spatial understanding. Few-shot learning is crucial, where providing similar task examples improves VLM performance. Prompt engineering is essential, and selecting the right examples is key for VLM success. Moreover, VLMs can struggle with dynamics, so prompts should prioritize geometric relations over dynamic concepts. Incorporating diverse data and iterative refinement loops can compensate for VLM’s inherent limitations, ensuring robustness in real-world applications and complex manipulation scenarios involving various object categories.
Dynamics Integration#
Integrating dynamics into robotic systems presents a significant leap towards achieving more robust and versatile manipulation capabilities. Traditional approaches often overlook the importance of object dynamics, limiting their ability to handle complex tasks involving deformable objects or intricate interactions. By explicitly modeling and accounting for dynamics, robots can better predict the outcome of their actions, allowing for more precise and adaptive control. This integration necessitates the development of sophisticated learning-based dynamics models capable of capturing the nuances of real-world object behavior. Furthermore, effective planning algorithms are crucial to leverage these dynamics models for generating optimal trajectories. The use of keypoints can bridge the gap between dynamics learning and high-level task specification, enabling robots to seamlessly translate abstract instructions into concrete actions. Overall, dynamics integration is essential for pushing the boundaries of robotic manipulation and enabling robots to operate in more challenging and unstructured environments.
Two-Level Control#
A two-level control approach enhances robotic manipulation robustness. High-level re-planning uses VLMs to update target specifications, correcting initial errors. This tackles challenges like imprecise object models or unforeseen disturbances. The low-level employs model-based planning with dynamics models, executing actions based on the updated targets. This hierarchical structure allows for both reactive adjustments and predictive control. The re-planning loop leverages new visual data, maintaining accuracy. This architecture is vital for complex tasks where initial plans become inadequate due to unforeseen events. Integrating perception, planning, and execution, it enhances adaptability in dynamic environments. This allows a robot to recover from mistakes, improving performance.
Perception Limits#
Perception is a crucial bottleneck in robotics, especially when dealing with unstructured environments and complex tasks. Limited sensor capabilities, noise, and occlusions can lead to inaccurate object detection and pose estimation. Furthermore, the computational cost of processing high-dimensional sensor data can hinder real-time performance, limiting the robot’s ability to react quickly to dynamic changes. Addressing these limits requires robust algorithms that can handle noisy data, fuse information from multiple sensors, and efficiently extract relevant features for downstream tasks. Sim-to-real transfer can be challenging for perception models.
More visual insights#
More on figures

🔼 KUDA system overview. The process begins with RGBD observation and language instruction input. A large vision model identifies and labels keypoints in the image, using a central reference point (green dot C). A vision-language model (VLM) then generates code defining target specifications based on these keypoints. These specifications are translated into 3D objectives. A pre-trained dynamics model performs model-based planning to generate robot actions. After several actions, the VLM is consulted again with updated observations, allowing for high-level closed-loop correction of errors in VLM output and robot execution.
read the caption
Figure 2: Overview of KUDA. Taking the RGBD observations and a language instruction as inputs, we first utilize the large vision model to obtain the keypoints and label them on the RGB image to obtain the visual prompt (green dot C marks the center reference point). Next, the vision-language model generates code for target specifications, which are projected into 3D space to construct the 3D objectives. Lastly, we utilize the pre-trained dynamics model for model-based planning. After a certain number of actions, the VLM is re-queried with the current observation, enabling high-level closed-loop planning to correct VLM and execution errors.

🔼 Figure 3 showcases the qualitative results obtained from various robotic manipulation tasks performed by the KUDA system. It demonstrates the system’s ability to handle diverse tasks involving different objects (cubes, ropes, granular materials, and a T-shaped block). For each task, the figure displays the initial state of the objects, the target specifications generated by the system’s vision-language model (VLM), and the final state after robot execution. The granular collection task is specifically highlighted to illustrate the two-level closed-loop control mechanism of the KUDA system.
read the caption
Figure 3: Qualitative Results of the Rollouts. We show the target specification and robot executions of various tasks on different objects, highlight the effectiveness of our framework. We show the initial state and the target specification visualization of our system, along with the robot executions, to demonstrate the performance of our framework on various manipulation tasks. Note that we show the granular collection task to exhibit how our VLM-level closed-loop control works in our two VLM-level loops.
More on tables
| Rope Straightening | “Straighten the rope.” |
|---|---|
| Cube Collection | “Move all the cubes to the pink cross.” |
| Cube Movement | “Move the yellow cube to the red cross.” |
| Granular Collection | “Collect all the coffee beans together.” |
| Granular Movement | “Move all the coffee beans to the red cross.” |
| T Movement | “Move the orange T into the pink square.” |
🔼 This table lists the six manipulation tasks used in the paper’s experiments. Each task involves a different object category (rope, cubes, granular objects, T-shaped block) and a specific instruction describing the desired manipulation. The instructions are natural language commands that test the system’s ability to understand and execute a diverse set of manipulation tasks.
read the caption
TABLE II: The input instructions of each evaluation task.
| Category | Top-0 | Top-1 | Top-3 | Top-5 | |
| Success Rate | 10/10 | 2/10 | 3/10 | 10/10 | 7/10 |
🔼 This table presents the results of an ablation study evaluating the impact of the hyperparameter K on the performance of the Top-K prompt retrieval mechanism. The study focuses on the Rope Straightening task and shows success rates for different values of K (0, 1, 3, and 5). K represents the number of examples selected from a prompt library to enhance the vision-language model’s performance. The table compares these results with a scenario where examples are manually selected by a human expert (‘category’), providing insights into the effectiveness and optimal value of the Top-K prompt retrieval strategy.
read the caption
TABLE III: The quantitative results of different K𝐾Kitalic_K values.
Full paper#








