TL;DR#
Pixel grounding has become a central area, yet existing datasets have limitations like limited categories, textual diversity, and annotation quality. This constrains progress. To mitigate these issues, this paper introduces GroundingSuite which overcomes the issues to advance the field and offer more diverse and high-quality data for future research.
The paper offers GSSculpt, an annotation framework using multiple VLMs, and a large training dataset with 9.56M referring expressions and an evaluation benchmark of 3,800 images. Using the new training data, models achieve state-of-the-art results, demonstrating the effectiveness of GroundingSuite over current datasets.
Key Takeaways#
Why does it matter?#
This work is important as it introduces a new benchmark dataset and an annotation framework that can propel future research in pixel grounding. The scale and diversity of the dataset address limitations of existing ones, enabling the development of more robust and generalizable models, paving the way for future advances.
Visual Insights#

🔼 The figure illustrates the GSSculpt automatic annotation framework, a three-phase pipeline for generating high-quality pixel grounding data. Phase 1 (Entity Spatial Localization) identifies objects of interest and creates accurate segmentation masks using a combination of global caption generation, phrase grounding, and mask generation techniques. Phase 2 (Grounding Text Generation) produces precise and unambiguous natural language descriptions for these objects, ensuring unique identification. Finally, Phase 3 (Noise Filtering) removes ambiguous or low-quality annotations, enhancing the overall reliability of the resulting dataset. Each phase is visually represented with example images and annotations.
read the caption
Figure 1: GSScuplt Automatic Annotation Framework. Our pipeline consists of three sequential phases: (1) Entity Spatial Localization, where we first identify potential objects of interest and generate high-quality segmentation masks; (2) Grounding Text Generation, where we then create unambiguous natural language descriptions that uniquely reference the segmented objects; and (3) Noise Filtering, where we finally eliminate ambiguous or low-quality samples to ensure dataset reliability.
| Benchmarks | Cat. | Len. | Stuff | Part | Multi | Single |
|---|---|---|---|---|---|---|
| RefCOCO [8, 32] | 80 | 3.6 | ✓ | |||
| RefCOCO+ [8, 32] | 80 | 3.5 | ✓ | |||
| RefCOCOg [18, 17] | 80 | 8.4 | ✓ | |||
| gRefCOCO [14] | 80 | 3.7 | ✓ | ✓ | ||
| RefCOCOm [26] | 471 | 5.1 | ✓ | ✓ | ||
| GSEval | 16.1 | ✓ | ✓ | ✓ | ✓ |
🔼 This table compares the GroundingSuite benchmark with other existing Referring Expression Segmentation (RES) benchmarks. It details the number of object categories, the average length of referring expressions, and the types of annotations supported by each benchmark. The columns show the number of categories, the average length of referring expressions, and whether the benchmark includes annotations for stuff classes (semantic segmentation of things like sky or grass), part-level annotations (segmentation of object parts, like a person’s arm or a car’s wheel), support for multiple objects in a single referring expression, and support for single-object referring expressions.
read the caption
Table 1: Comparisons with previous Referring Expression Segmentation benchmark. ‘Cat.’ and ‘Len.’ denote the number of categories and average text length; Stuff: includes stuff classes; Part: includes part-level annotations; Multi: supports multi-object references; Single: supports single-object references;
In-depth insights#
VLM Auto-Labeling#
Vision-Language Model (VLM) Auto-Labeling marks a significant shift in dataset creation for pixel grounding tasks. Traditional manual annotation is laborious and restricts dataset scale and diversity. VLM-based auto-labeling offers a solution by leveraging the capabilities of VLMs to automatically generate segmentation masks and textual descriptions. A robust VLM auto-labeling framework should include components like entity spatial localization, grounding text generation, and noise filtering. Entity spatial localization aims to discover objects and generate masks, while grounding text generation creates precise descriptions. Noise filtering is crucial for removing ambiguous samples, ensuring high-quality data. Overall, this technique offers a scalable solution, but needs careful process design to keep annotation accuracy at a high level.
GSSculpt Details#
Apologies, but the paper does not include a section titled ‘GSSculpt Details.’ Instead, the research focuses on an automatic annotation framework named GSSculpt, which is a core contribution. It employs a three-stage process. Entity spatial localization identifies regions of interest and creates masks, grounding text generation creates descriptions, and noise filtering eliminates ambiguities. The GSSculpt helps to resolve the issues with datasets, like their restricted scope to a limited amount of object categories and a deficiency of high-quality labels. The framework produces accurate annotations with fewer steps compared to existing auto-labeling methods. Further details would likely elaborate on the implementation specifics, such as model architectures, training regimes, and hyperparameter tuning for each stage within the GSSculpt pipeline, for achieving high efficiency.
GSTrain Scale#
To check the effectiveness of data scale on model performance, the researchers train their method, EVF-SAM, using different proportions of the GSTrain-10M dataset without other external datasets like RefCOCO. Experimental results show a notable increasing trend in performance across all aspects as data proportion increases. Specifically, the performance showed a clear rising curve along with the increase of training data ratio, which demonstrated the scalability of the method. This result indicates the potential for even greater improvements by using a larger dataset of GSTrain.
GSEval Diversity#
While ‘GSEval Diversity’ isn’t a direct heading, its essence is clear. The research likely emphasizes the dataset’s rich variety, encompassing different object categories (beyond common datasets), scenes, granularities (stuff, parts, multi-object). This addresses limitations of datasets like RefCOCO, which are constrained by COCO categories. A diverse GSEval would support robust model evaluation, testing generalization across scenarios. This dataset enables models to handle real-world complexity, going beyond single-object grounding to context-aware and fine-grained localization. Diversity is key for benchmarking holistic grounding capabilities.
GSEval Metrics#
When evaluating GSEval, the authors prioritize thoroughness and real-world applicability through carefully chosen metrics. For pixel-level grounding, they wisely adopt gIoU, which provides a balanced assessment across objects of different sizes, crucial for a dataset with diverse granularities. A key decision is to shift away from cIoU, known to favor larger objects, highlighting a commitment to fair evaluation. The box-level grounding relies on standard REC metrics such as accuracy at various IoU thresholds. The emphasis on the importance of GSEval is to have a multi-granularity grounding benchmark for the community to use and accurately measure different large multimodal models.
More visual insights#
More on figures

🔼 This figure details the process of creating the GSEval benchmark dataset. It begins with applying an automated annotation pipeline to unlabeled images from the COCO dataset. A Vision-Language Model (VLM) classifier then verifies the categories of the generated referring expressions. The process continues by refining the initial segmentation masks (which may be coarse) into precise trimaps, and then applying matting techniques to achieve accurate object boundaries. Finally, human reviewers conduct a manual review of the results to ensure data quality and accuracy.
read the caption
Figure 2: Curation pipeline for GSEval Benchmark. First, we apply our annotation pipeline to unlabeled COCO images. Next, we use a VLM classifier to ensure the categories of referring prompts. Then, we translate the coarse masks to trimaps and apply matting methods for precise object boundaries. Finally, we organize human reviewers for manual checks.

🔼 Figure 3 displays a comparison of different methods’ performance on the GSEval benchmark. Each method was evaluated using publicly available code and pre-trained weights, without any fine-tuning or adaptation for this specific dataset. The zero-shot evaluation ensures that the comparison reflects the inherent capabilities of each model in handling unseen data, with all methods operating under the same conditions.
read the caption
Figure 3: The visualization comparisons of different methods on GSEval. All methods are evaluated under the zero-shot setting with the public code and weights.

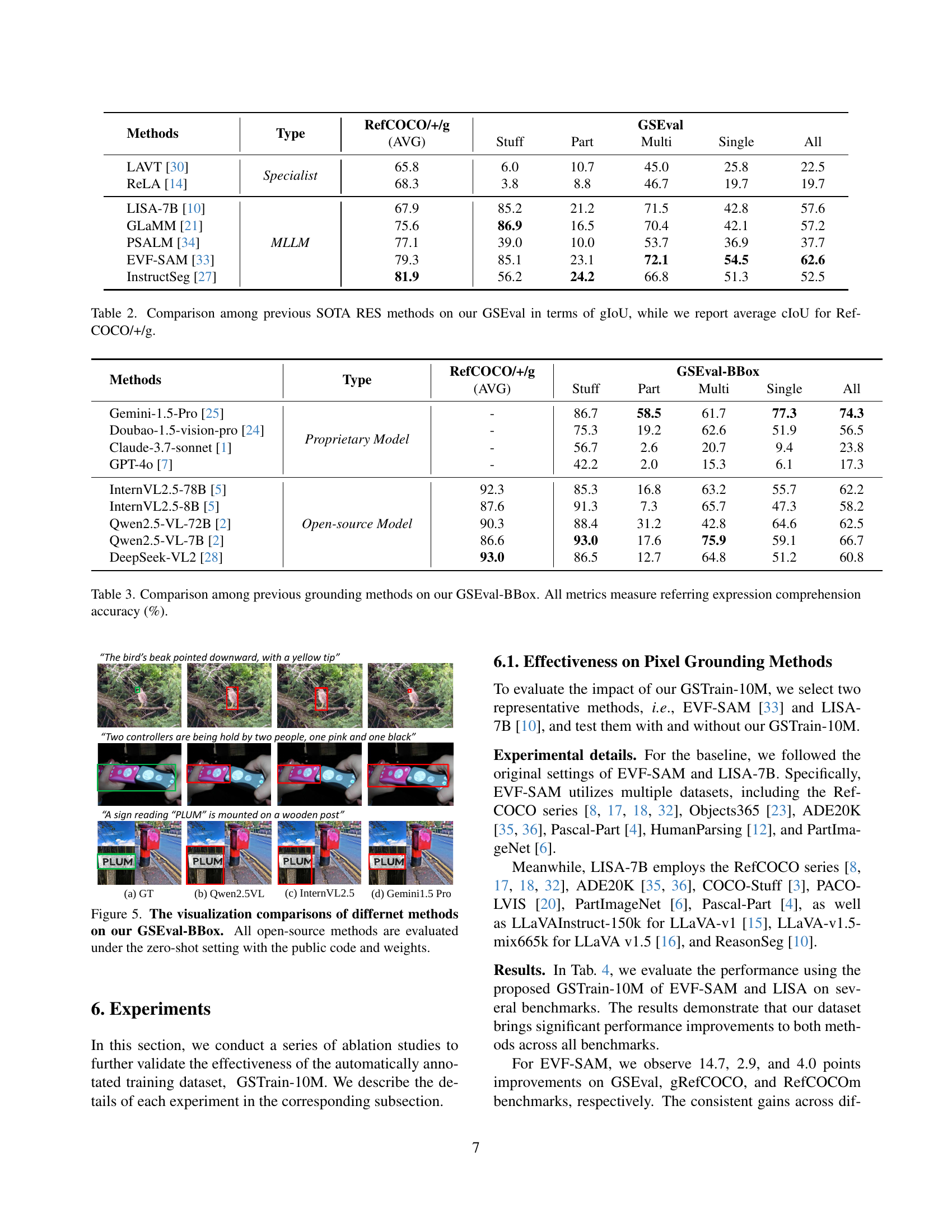
🔼 Figure 4 presents a comparison of several methods’ performance on the GSEval-BBox benchmark, focusing on bounding box accuracy. Specifically, it visually illustrates the results of different models (InstructSeg, LISA, EVF-SAM) in localizing objects within images, highlighting the differences in their accuracy and ability to precisely identify bounding boxes according to the given textual descriptions. All models were evaluated using publicly available code and weights under zero-shot settings.
read the caption
Figure 4: The visualization comparisons of differnet methods on our GSEval-BBox. All open-source methods are evaluated under the zero-shot setting with the public code and weights.

🔼 This word cloud visualizes the frequency of words used in the textual descriptions within the GSEval benchmark dataset. It offers a quick overview of the types of objects, attributes, and relationships described in the dataset, highlighting the diversity and complexity of language used to refer to visual elements within the images. The size of each word corresponds to its frequency of occurrence.
read the caption
Figure 5: The word cloud of GSEval

🔼 Figure 7 presents a diverse set of examples from the GSEval benchmark, showcasing the variety of ‘stuff’ class and part-level annotations. The images illustrate the complexity of real-world scenes and the challenges in accurately identifying and segmenting objects based on natural language descriptions. The ‘stuff’ class examples highlight the difficulty of segmenting amorphous regions, like ‘sky’ or ‘water’, while the part-level examples demonstrate the need for fine-grained understanding to locate and segment specific parts of objects, such as ‘a dog’s mouth’ or ‘a woman’s hair’. These examples emphasize the nuanced nature of pixel grounding and the importance of a robust benchmark for evaluating model performance.
read the caption
Figure 6: More selected samples from our GSEval. Stuff class and part level

🔼 Figure 7 presents additional examples from the GSEval benchmark dataset, showcasing both multi-object and single-object scenarios. The images illustrate the diversity of scenes and object types included in the dataset, demonstrating its ability to evaluate models across various complexities in visual grounding tasks.
read the caption
Figure 7: More selected samples from our GSEval. Multi object and single object

🔼 This figure shows the prompt templates used in the GroundingSuite framework for generating global image captions and grounding texts for object localization. The global caption prompt instructs the model to produce a concise, single-paragraph description of the image, avoiding speculation and focusing only on clearly visible elements. The grounding text generation prompt is more specific, asking for a short description of a particular object (identified by its category name and bounding box coordinates). It emphasizes clarity and distinction from other objects, providing detailed instructions on handling multiple objects or incorrect classifications.
read the caption
Figure 8: Prompt for global caption and grounding text generation

🔼 Figure 9 shows the prompts used in the noise filtering stage of the GSSculpt framework. Three prompts are displayed, targeting different aspects of quality control. The first prompt is for a Vision-Language Model (VLM) to assess if a red-box mask accurately represents the referring expression. It specifies criteria for accurate annotation, such as object consistency, completeness, and avoidance of redundancy. The second prompt is for classifying the referring expression into one of four categories: stuff, part, multi-object, or single object. The third prompt provides instructions on providing a concise numerical classification (1-4) without detailed analysis. These prompts aim to efficiently filter out inaccurate or ambiguous annotations during dataset creation.
read the caption
Figure 9: Prompt for noise filtering
More on tables
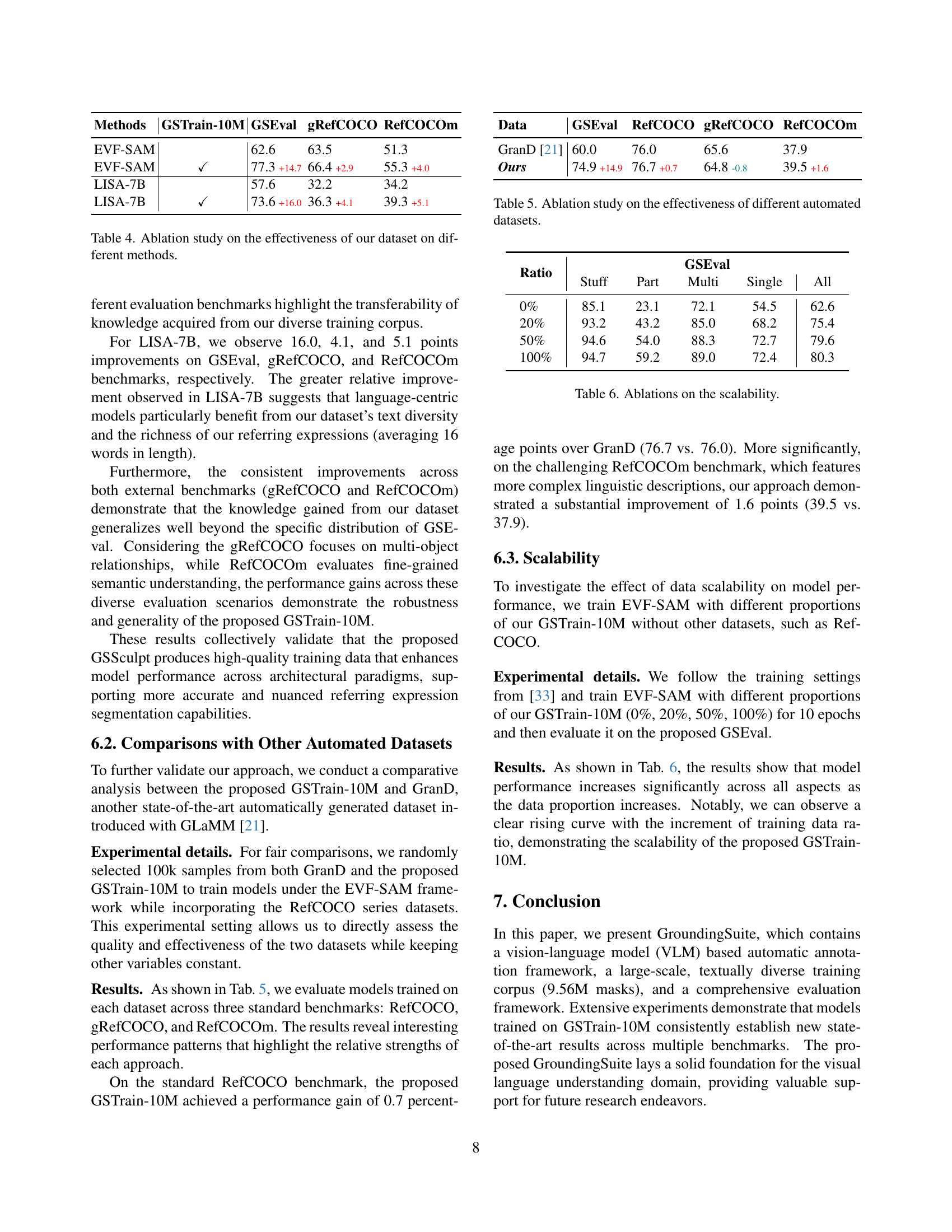
| Methods | Type | RefCOCO/+/g | GSEval | ||||
| (AVG) | Stuff | Part | Multi | Single | All | ||
| LAVT [30] | Specialist | 65.8 | 6.0 | 10.7 | 45.0 | 25.8 | 22.5 |
| ReLA [14] | 68.3 | 3.8 | 8.8 | 46.7 | 19.7 | 19.7 | |
| LISA-7B [10] | MLLM | 67.9 | 85.2 | 21.2 | 71.5 | 42.8 | 57.6 |
| GLaMM [21] | 75.6 | 86.9 | 16.5 | 70.4 | 42.1 | 57.2 | |
| PSALM [34] | 77.1 | 39.0 | 10.0 | 53.7 | 36.9 | 37.7 | |
| EVF-SAM [33] | 79.3 | 85.1 | 23.1 | 72.1 | 54.5 | 62.6 | |
| InstructSeg [27] | 81.9 | 56.2 | 24.2 | 66.8 | 51.3 | 52.5 | |
🔼 Table 2 presents a comparison of the performance of state-of-the-art Referring Expression Segmentation (RES) models on the GSEval benchmark. It shows the gIoU scores achieved on four subsets of GSEval (Stuff, Part, Multi-object, and Single-object) for several leading RES methods. For context, average cIoU scores on the RefCOCO, RefCOCO+, and gRefCOCO benchmarks are also provided for these same methods to facilitate a comparison between specialized RES models and more generalized approaches. This allows for assessment of model generalizability and performance on diverse aspects of visual grounding tasks.
read the caption
Table 2: Comparison among previous SOTA RES methods on our GSEval in terms of gIoU, while we report average cIoU for RefCOCO/+/g.
| Methods | Type | RefCOCO/+/g | GSEval-BBox | ||||
| (AVG) | Stuff | Part | Multi | Single | All | ||
| Gemini-1.5-Pro [25] | Proprietary Model | - | 86.7 | 58.5 | 61.7 | 77.3 | 74.3 |
| Doubao-1.5-vision-pro [24] | - | 75.3 | 19.2 | 62.6 | 51.9 | 56.5 | |
| Claude-3.7-sonnet [1] | - | 56.7 | 2.6 | 20.7 | 9.4 | 23.8 | |
| GPT-4o [7] | - | 42.2 | 2.0 | 15.3 | 6.1 | 17.3 | |
| InternVL2.5-78B [5] | Open-source Model | 92.3 | 85.3 | 16.8 | 63.2 | 55.7 | 62.2 |
| InternVL2.5-8B [5] | 87.6 | 91.3 | 7.3 | 65.7 | 47.3 | 58.2 | |
| Qwen2.5-VL-72B [2] | 90.3 | 88.4 | 31.2 | 42.8 | 64.6 | 62.5 | |
| Qwen2.5-VL-7B [2] | 86.6 | 93.0 | 17.6 | 75.9 | 59.1 | 66.7 | |
| DeepSeek-VL2 [28] | 93.0 | 86.5 | 12.7 | 64.8 | 51.2 | 60.8 | |
🔼 This table compares the performance of various grounding methods on the GSEval-BBox benchmark. GSEval-BBox is a bounding box version of the GSEval benchmark, focusing on evaluating object localization accuracy rather than pixel-perfect segmentation. The table shows the performance of both proprietary and open-source models across different categories within GSEval-BBox (stuff, part, multi, single) and an overall average. The metric used is referring expression comprehension accuracy (%), which assesses how accurately the models locate the objects described in the referring expressions.
read the caption
Table 3: Comparison among previous grounding methods on our GSEval-BBox. All metrics measure referring expression comprehension accuracy (%).
| Methods | GSTrain-10M | GSEval | gRefCOCO | RefCOCOm |
|---|---|---|---|---|
| EVF-SAM | 62.6 | 63.5 | 51.3 | |
| EVF-SAM | ✓ | 77.3 +14.7 | 66.4 +2.9 | 55.3 +4.0 |
| LISA-7B | 57.6 | 32.2 | 34.2 | |
| LISA-7B | ✓ | 73.6 +16.0 | 36.3 +4.1 | 39.3 +5.1 |
🔼 This ablation study evaluates the impact of the GroundingSuite training dataset (GSTrain-10M) on the performance of different pixel grounding methods. Two representative methods, EVF-SAM and LISA-7B, were tested both with and without GSTrain-10M, and their performance was compared across multiple benchmarks: GSEval, gRefCOCO, and RefCOCOm. The results demonstrate the improvement in performance achieved by incorporating GSTrain-10M, highlighting its effectiveness in enhancing pixel grounding models’ capabilities.
read the caption
Table 4: Ablation study on the effectiveness of our dataset on different methods.
| Data | GSEval | RefCOCO | gRefCOCO | RefCOCOm |
|---|---|---|---|---|
| GranD [21] | 60.0 | 76.0 | 65.6 | 37.9 |
| Ours | 74.9 +14.9 | 76.7 +0.7 | 64.8 -0.8 | 39.5 +1.6 |
🔼 This table presents the results of an ablation study comparing the performance of models trained on different automatically generated datasets for pixel grounding. The study contrasts the proposed GSTrain-10M dataset with the GranD dataset, evaluating their effectiveness on standard benchmarks like GSEval, gRefCOCO, and RefCOCOm. The metrics likely represent performance scores such as Intersection over Union (IoU) demonstrating the impact of dataset quality on model accuracy. The purpose is to show the superiority of the proposed dataset over existing automatic annotation methods.
read the caption
Table 5: Ablation study on the effectiveness of different automated datasets.
| Ratio | GSEval | ||||
|---|---|---|---|---|---|
| Stuff | Part | Multi | Single | All | |
| 0% | 85.1 | 23.1 | 72.1 | 54.5 | 62.6 |
| 20% | 93.2 | 43.2 | 85.0 | 68.2 | 75.4 |
| 50% | 94.6 | 54.0 | 88.3 | 72.7 | 79.6 |
| 100% | 94.7 | 59.2 | 89.0 | 72.4 | 80.3 |
🔼 This table presents the results of an ablation study on the scalability of the model’s performance. It shows how the model’s performance on different aspects of the task (Stuff, Part, Multi, Single, All) changes as the amount of training data increases from 0% to 100%. This demonstrates the effect of dataset size on the model’s ability to generalize and perform well across various types of grounding.
read the caption
Table 6: Ablations on the scalability.
Full paper#