TL;DR#
Multi-turn image editing is challenging due to the difficulty of balancing the cost and quality of various AI tools. Existing methods often rely on expensive exploration or lack accurate cost estimations. Current text-to-image models struggle with composite instructions that require multiple adjustments while preserving other parts. Large Language Models are useful for decomposing the task, but finding the toolpath (efficient and successful tool use) is difficult because of the high cost to train and computational costs. Therefore, there is a need for a cost-sensitive agent that can decompose a multi-turn task into subtasks.
This paper introduces “COSTA”, a cost-sensitive toolpath agent that combines LLMs and A search to find cost-effective tool paths for multi-turn image editing. CoSTA* uses LLMs to create a subtask tree and prunes a graph of AI tools for the given task. It then conducts A* search on the smaller subgraph to find the tool path and balances the total cost and quality to guide the A* search. Each subtask’s output is evaluated by a vision-language model, where a failure updates the tool’s cost and quality on the subtask. COSTA* automatically switches between modalities across subtasks and outperforms state-of-the-art models in terms of cost and quality.
Key Takeaways#
Why does it matter?#
This research presents a new cost-sensitive image-editing agent that can efficiently combine large multimodal models, offering flexibility to search for the optimal editing path and balance cost and quality. It advances the field of multimodal learning and enables better automation in content creation and image restoration. Further research includes addressing the potential biases from pre-trained models and ensuring ethical and responsible usage.
Visual Insights#

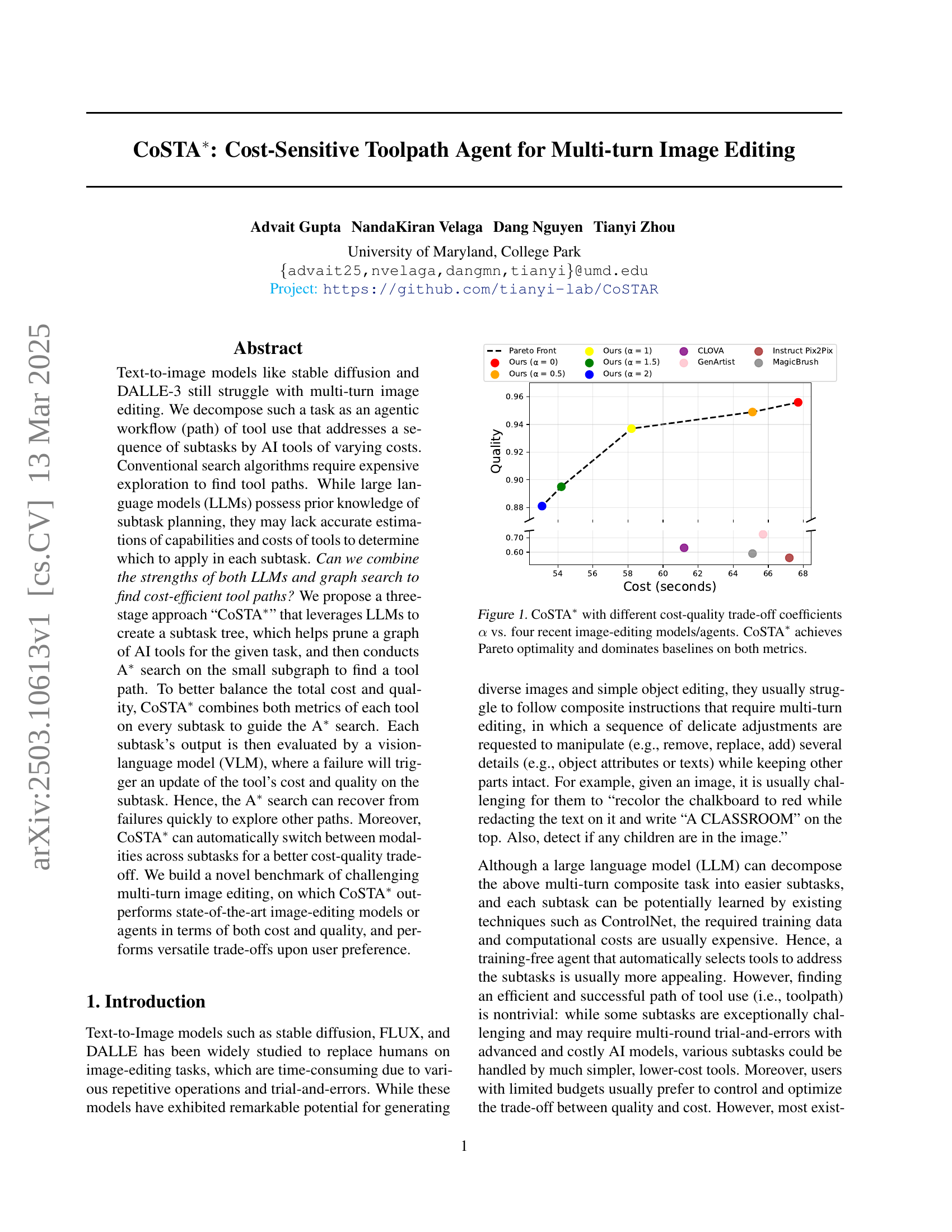
🔼 This figure presents a comparison of CoSTA*’s performance against four other state-of-the-art image editing models/agents, varying the cost-quality trade-off coefficient (α). The x-axis represents the cost (in seconds), and the y-axis represents the quality. Each line represents a different α value for CoSTA*, demonstrating its ability to achieve various cost-quality tradeoffs. The Pareto front highlights the optimal trade-off between cost and quality. CoSTA* consistently outperforms other methods, achieving Pareto optimality and dominating the baselines on both metrics (cost and quality).
read the caption
Figure 1: CoSTA∗ with different cost-quality trade-off coefficients α𝛼\alphaitalic_α vs. four recent image-editing models/agents. CoSTA∗ achieves Pareto optimality and dominates baselines on both metrics.
| Model | Supported Subtasks | Inputs | Outputs |
|---|---|---|---|
| YOLO (Wang et al., 2022) | Object Detection | Input Image | Bounding Boxes |
| SAM (Kirillov et al., 2023a) | Segmentation | Bounding Boxes | Segmentation Masks |
| DALL-E (Ramesh et al., 2021) | Object Replacement | Segmentation Mask | Edited Image |
| Stable Diffusion Inpaint | Object Removal, Replacement, | Segmentation Mask | Edited Image |
| (Rombach et al., 2022a) | Recoloration | ||
| EasyOCR | Text Extraction | Text Bounding Box | Extracted Text |
| (Kittinaradorn et al., 2022) |
🔼 This table provides a partial overview of the models used in the CoSTA* system. It lists each model’s name, the image-editing subtasks it supports, the inputs it requires, and the outputs it produces. This information is crucial for understanding how the system chooses appropriate tools for each step in the multi-turn image editing process. The table is an excerpt; the full table contains information on all 24 models used in the paper.
read the caption
Table 1: Model Description Table (excerpt)
In-depth insights#
LLM+A* Toolpath#
Integrating LLMs with A search for toolpath optimization presents a compelling approach*. LLMs offer high-level planning but lack precision in tool-specific costs. A excels in optimal path finding but struggles with the vast search space of AI tools*. A hybrid approach could leverage LLMs for subtask decomposition, pruning the tool search space, then employ A* on the smaller graph for cost-sensitive path discovery. This balances global planning with local precision, addressing the quality-cost trade-off by using LLM insights and A* optimization, leading to better tool selection and efficient solutions, improving results over LLM-only or A*-only search.
Cost vs. Quality#
CoSTA adeptly addresses the trade-off between cost and quality* in image editing. By using an A* search algorithm guided by a cost function that considers both execution time and output quality, it finds a path that balances these factors. The user can control the balance to optimize the trade-off according to preferences. With different cost-quality trade-off coefficients, it can achieve Pareto optimality dominating baselines on both metrics, offering more choices of tool use paths to cater to different use-cases based on budgets.
Multimodal Edit#
Multimodal editing represents a significant frontier in image manipulation, moving beyond simple text-guided edits to incorporate various modalities like sketches, audio, or even other images to guide the editing process. The central challenge lies in effectively fusing information from disparate sources, each with its unique semantic and structural properties. This requires sophisticated architectures capable of understanding cross-modal relationships and resolving potential conflicts or ambiguities arising from inconsistent cues. A robust multimodal editing system needs to strike a balance between adhering to user intent expressed through multiple modalities and maintaining the realism and coherence of the edited image. Key research directions include developing novel fusion mechanisms, exploring techniques for handling noisy or incomplete modal information, and creating intuitive interfaces that allow users to seamlessly interact with the system using a variety of input methods. Ultimately, successful multimodal editing opens up exciting possibilities for creative expression and content creation.
TDG Automaton#
TDG (Tool Dependency Graph) Automaton could represent an agent that navigates the tool graph to solve image editing tasks. It will explore various tool paths using prior knowledge and benchmarks to enhance efficiency and quality, aiming to find the optimal sequence of tools to achieve the desired result. An A search* algorithm would guide the search on the graph.
Human > CLIP#
When assessing the correlation between human evaluations and CLIP scores, several insights emerge. It appears human evaluation is still crucial because CLIP might not capture nuanced inaccuracies. This is key, as relying solely on CLIP could lead to overlooking critical details or contextual understanding that a human evaluator would readily identify. The low correlation could be because CLIP might struggle with complex tasks, making it unreliable for holistic assessment but useful for individual subtasks. Humans excel where CLIP falls short because humans perform a more thorough job especially for nuanced multi-step and multi-modal
More visual insights#
More on figures

🔼 Figure 2 showcases a comparison of CoSTA* against several state-of-the-art image editing models and agents. Three complex multi-turn image editing tasks are presented. For each task, the input image and user prompt are displayed alongside the results generated by CoSTA* and four other methods: GenArtist, MagicBrush, InstructPix2Pix, and CLOVA. The comparison highlights the differences in accuracy, visual coherence, and the ability of each method to handle multimodal tasks. CoSTA* demonstrates superior performance across all three tasks, showing a greater ability to correctly interpret and execute the complex, multi-step instructions.
read the caption
Figure 2: Comparison of CoSTA∗ with State-of-the-Art image editing models/agents, which include GenArtist (Wang et al., 2024b), MagicBrush (Zhang et al., 2024a), InstructPix2Pix (Brooks et al., 2023), and CLOVA (Gao et al., 2024). The input images and prompts are shown on the left of the figure. The outputs generated by each method illustrate differences in accuracy, visual coherence, and the ability to multimodal tasks. Figure 9 shows examples of step-by-step editing using CoSTA∗with intermediate subtask outputs presented.

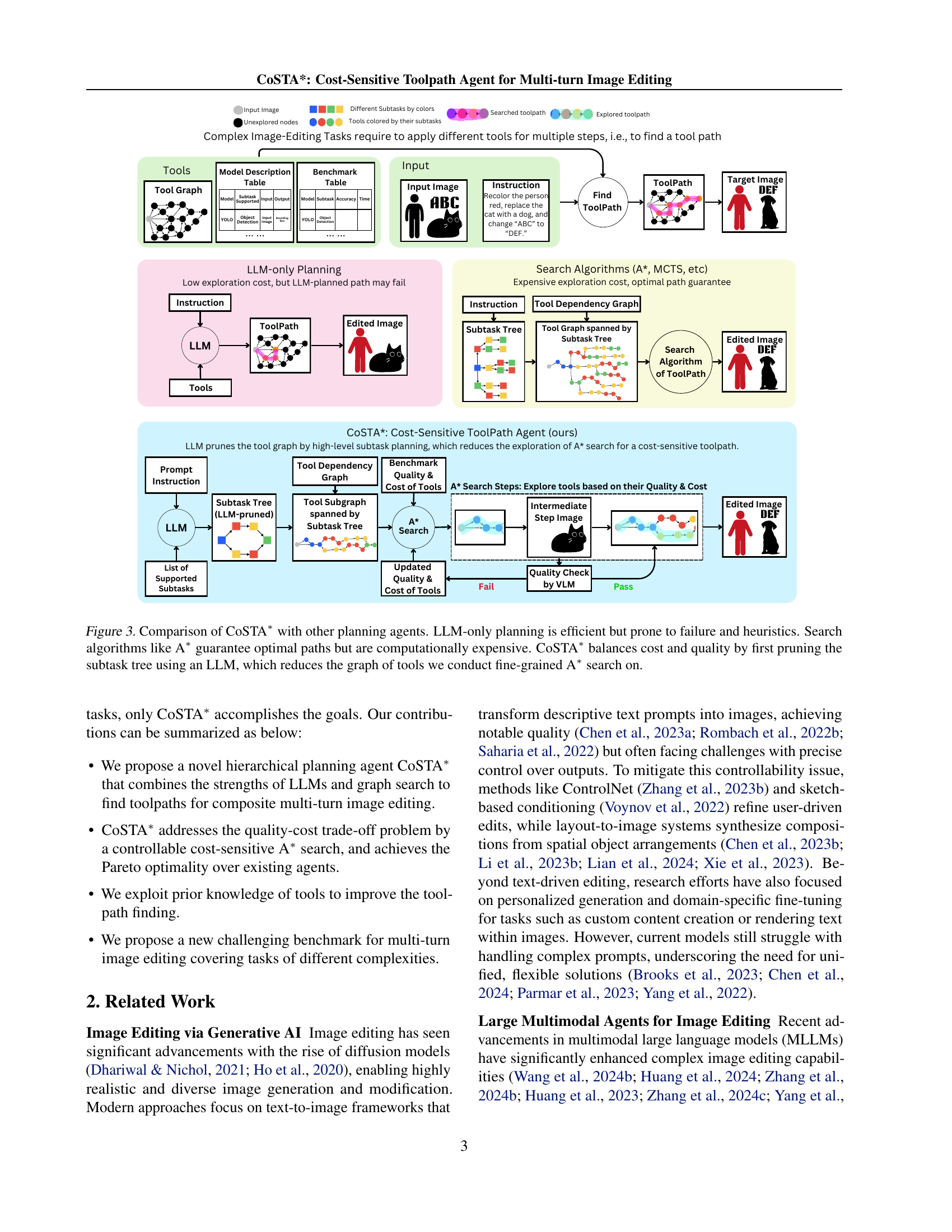
🔼 This figure compares three different approaches to multi-turn image editing task planning: LLM-only planning, traditional search algorithms (like A*), and the proposed CoSTA* method. LLM-only planning is fast but unreliable due to limitations in its understanding of tool capabilities and costs, leading to suboptimal plans and frequent failures. A* search guarantees optimal solutions but is computationally expensive and impractical for complex tasks with numerous tools. CoSTA* combines the strengths of both by using an LLM to generate a subtask tree, which significantly reduces the search space for A*. Then, A* is applied to this smaller, more manageable subgraph to find a cost-efficient toolpath that balances quality and cost. This hybrid approach allows CoSTA* to achieve efficient and high-quality results.
read the caption
Figure 3: Comparison of CoSTA∗ with other planning agents. LLM-only planning is efficient but prone to failure and heuristics. Search algorithms like A∗ guarantee optimal paths but are computationally expensive. CoSTA∗ balances cost and quality by first pruning the subtask tree using an LLM, which reduces the graph of tools we conduct fine-grained A∗ search on.

🔼 The figure depicts a Tool Dependency Graph (TDG), a directed acyclic graph that visually represents the relationships and dependencies between various AI tools used in multi-turn image editing. Each node in the graph represents a specific AI tool (e.g., an object detector, an image inpainter, a text generator), and a directed edge from node
v1to nodev2signifies that the output of toolv1serves as a valid input for toolv2. This graph is crucial for the CoSTA* algorithm because it allows for efficient searching of optimal toolpaths (sequences of tools) to accomplish complex image editing tasks described in natural language. The TDG facilitates the selection of appropriate tools for each subtask within a multi-turn image editing workflow, considering the dependencies between tools to ensure a seamless and logical editing process.read the caption
Figure 4: Tool Dependency Graph (TDG). A directed graph where nodes represent tools and edges indicate dependencies. An edge (v1,v2)subscript𝑣1subscript𝑣2(v_{1},v_{2})( italic_v start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_v start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT ) means v1subscript𝑣1v_{1}italic_v start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT’s output is a legal input of v2subscript𝑣2v_{2}italic_v start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT. It enables toolpath search for multi-turn image-editing tasks with composite instructions.

🔼 This figure illustrates the three-stage process of the CoSTA* algorithm for multi-turn image editing. Stage 1 shows an LLM generating a subtask tree from the input image and task instructions, breaking down the complex task into smaller, manageable subtasks. Each branch of the tree represents a sequence of tool uses to achieve the overall goal. Stage 2 shows how the LLM’s subtask tree translates into a tool subgraph, which is a subset of the complete tool dependency graph. This subgraph only includes the tools and relationships necessary for executing the subtasks identified in Stage 1, making the search space smaller and more efficient. Finally, Stage 3 depicts an A* search algorithm operating on this tool subgraph. The A* search uses a cost function that balances execution time (efficiency) and output quality to find the optimal path (sequence of tool uses) through the subgraph, ultimately leading to the final edited image.
read the caption
Figure 5: Three stages in CoSTA∗: (1) an LLM generates a subtask tree based on the input and task dependencies; (2) the subtask tree spans a tool subgraph that maintains tool dependencies; and (3) A∗ search finds the best toolpath balancing efficiency and quality.

🔼 This figure presents a breakdown of the benchmark dataset used to evaluate CoSTA* and other image editing methods. The leftmost panel shows the distribution of tasks involving only image manipulation, categorized by the number of subtasks. The middle panel displays the distribution of tasks involving both image and text manipulation. The rightmost panel compares the performance of various models, including CoSTA*, across these tasks. It highlights CoSTA*’s superior performance on complex multi-modal tasks where image and text editing is required, outperforming all baseline methods.
read the caption
Figure 6: Distribution of image-only (left) and text+image tasks (middle) in our proposed benchmark, and quality comparison of different methods on the benchmark (right). CoSTA∗ excels in complex multimodal tasks and outperforms all the baselines.

🔼 Figure 7 demonstrates the impact of incorporating real-time feedback (g(x)) into the A* search algorithm within CoSTA*. The left side shows the results when only the heuristic cost (h(x)) is used to guide path selection, while the right side shows the results when both the heuristic and the actual execution cost (h(x) + g(x)) are considered. The figure visually highlights how the real-time feedback mechanism improves the algorithm’s ability to select more efficient paths that also deliver higher quality results. Specifically, it shows how integrating g(x) leads to a path closer to the Pareto-optimal front (where both quality and cost are effectively balanced).
read the caption
Figure 7: Comparison of a task with h(x)ℎ𝑥h(x)italic_h ( italic_x ) and h(x)+g(x)ℎ𝑥𝑔𝑥h(x)+g(x)italic_h ( italic_x ) + italic_g ( italic_x ), showing how real-time feedback improves path selection and execution.

🔼 Figure 8 showcases a qualitative comparison between traditional image editing tools and CoSTA* when handling tasks involving text manipulation within images. The figure demonstrates CoSTA*’s superior performance in maintaining both visual quality and textual accuracy. Traditional methods often struggle to accurately edit text within an image while preserving other visual elements, leading to inconsistencies. In contrast, CoSTA*’s multimodal approach, integrating multiple specialized models, enables more precise and comprehensive text editing within the image, while preserving other visual elements. This highlights the effectiveness of CoSTA*’s approach in preserving both visual and textual fidelity.
read the caption
Figure 8: Qualitative comparison of image editing tools vs. CoSTA∗ for text-based tasks, highlighting the advantages of our multimodal support in preserving visual and textual fidelity.

🔼 This figure showcases the step-by-step process of CoSTA* in handling multi-turn image editing tasks. Each row displays an example, starting with the initial image and prompt. Then, the subtasks identified by CoSTA* are shown, along with the intermediate outputs generated by each subtask’s execution. This visualization demonstrates the sequential nature of CoSTA*’s operations. Each step refines the output, leading to the final edited image. This step-by-step approach highlights CoSTA*’s ability to systematically improve accuracy and consistency, especially in complex tasks involving multiple modalities (text and image).
read the caption
Figure 9: Step-by-step execution of editing tasks using CoSTA∗. Each row illustrates an input image, the corresponding subtask breakdown, and intermediate outputs at different stages of the editing process. This visualization highlights how CoSTA∗ systematically refines outputs by leveraging specialized models for each subtask, ensuring greater accuracy and consistency in multimodal tasks.

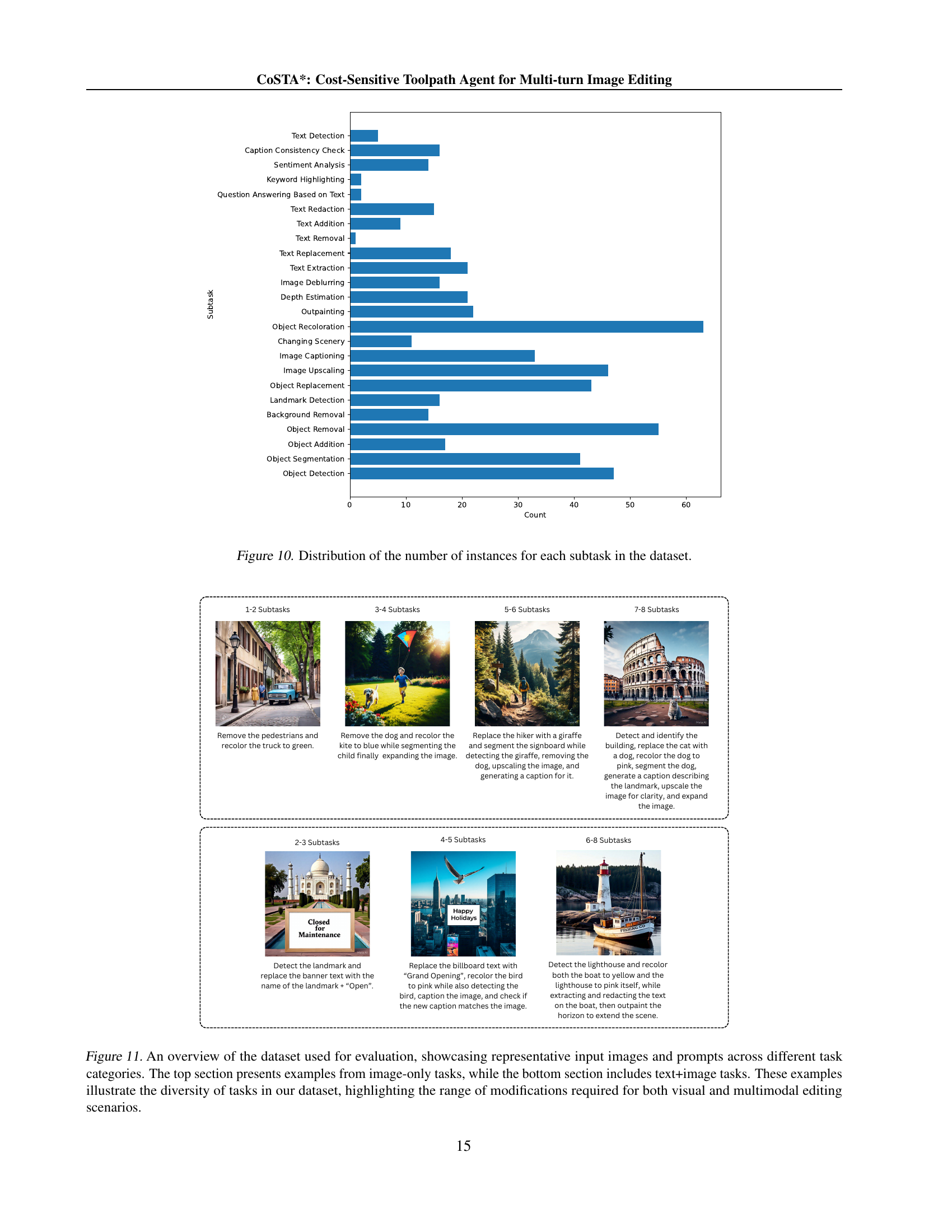
🔼 This bar chart visualizes the frequency distribution of various subtasks within the benchmark dataset used in the CoSTA* model evaluation. Each bar represents a specific subtask (e.g., object detection, text replacement, image upscaling), and its height indicates the number of instances of that subtask present in the dataset. This figure provides insights into the dataset composition, showing which subtasks are more frequent and which are less frequent. This is useful for understanding the types of image editing tasks the dataset covers and the relative difficulty or complexity of those tasks.
read the caption
Figure 10: Distribution of the number of instances for each subtask in the dataset.

🔼 Figure 11 presents a curated selection of image editing tasks from the proposed benchmark dataset. The top half showcases examples involving solely image manipulation, highlighting the range of complexity from simple object edits to more involved scene changes. The bottom half demonstrates tasks requiring both image and text editing. The examples illustrate the multifaceted nature of multi-turn image editing, encompassing modifications such as object removal, addition, recoloring, text manipulation, scene alterations, and more, underscoring the diverse challenges addressed by the CoSTA* method.
read the caption
Figure 11: An overview of the dataset used for evaluation, showcasing representative input images and prompts across different task categories. The top section presents examples from image-only tasks, while the bottom section includes text+image tasks. These examples illustrate the diversity of tasks in our dataset, highlighting the range of modifications required for both visual and multimodal editing scenarios.

🔼 This figure illustrates the retry mechanism used in CoSTA*. When a node (representing a tool-subtask pair) fails to meet the quality threshold during the A* search, the retry mechanism is triggered. The diagram shows the adjustments made to the cost and quality of the node, and the re-evaluation of potential paths to completion. The ‘Retry’ arrow indicates that the process repeats, attempting to fulfill the subtask by adjusting parameters or exploring alternative models. If the subtask still fails to meet the quality threshold after a retry, this node is excluded from further consideration. The figures demonstrate a case where the initial path is blocked by a node failing the quality check. Then, the A* search is re-triggered, this time avoiding the failed node, to explore other possible paths.
read the caption
Figure 12: Visualization of the Retry Mechanism
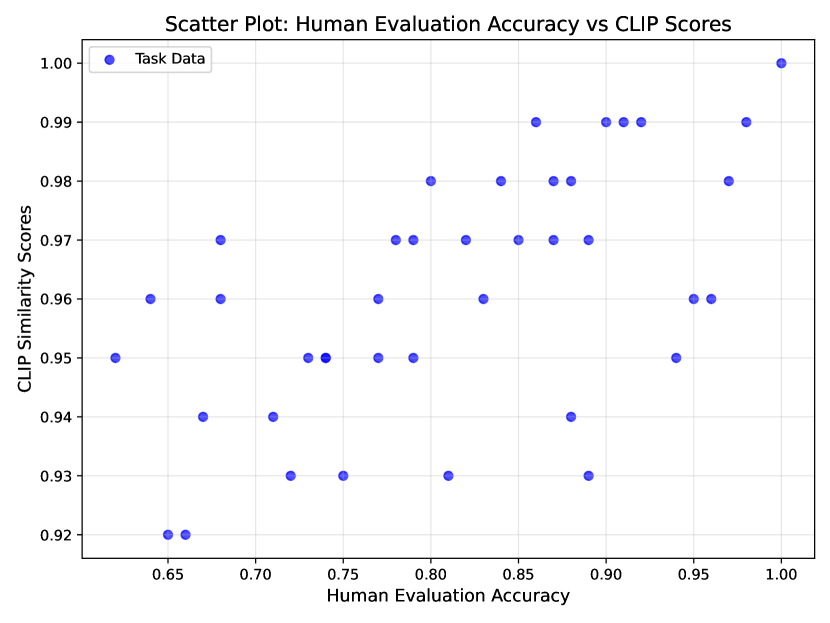
🔼 This scatter plot visualizes the correlation between CLIP similarity scores and human-evaluated accuracy across 40 multi-turn image editing tasks. Each point represents a single task, plotting its CLIP score against its human-assigned accuracy score. The weak positive correlation (Spearman’s ρ = 0.59, Kendall’s τ = 0.47) indicates that CLIP scores are not a reliable predictor of human judgment, especially for complex, multi-step tasks. The plot demonstrates that high CLIP scores do not guarantee high human accuracy, highlighting CLIP’s limitations in capturing subtle errors or nuances often present in complex editing scenarios.
read the caption
Figure 13: Scatter plot of CLIP scores vs. human accuracy across 40 tasks. The weak correlation (Spearman’s ρ=0.59𝜌0.59\rho=0.59italic_ρ = 0.59, Kendall’s τ=0.47𝜏0.47\tau=0.47italic_τ = 0.47) highlights CLIP’s limitations in capturing nuanced inaccuracies, particularly in complex, multi-step tasks.
More on tables
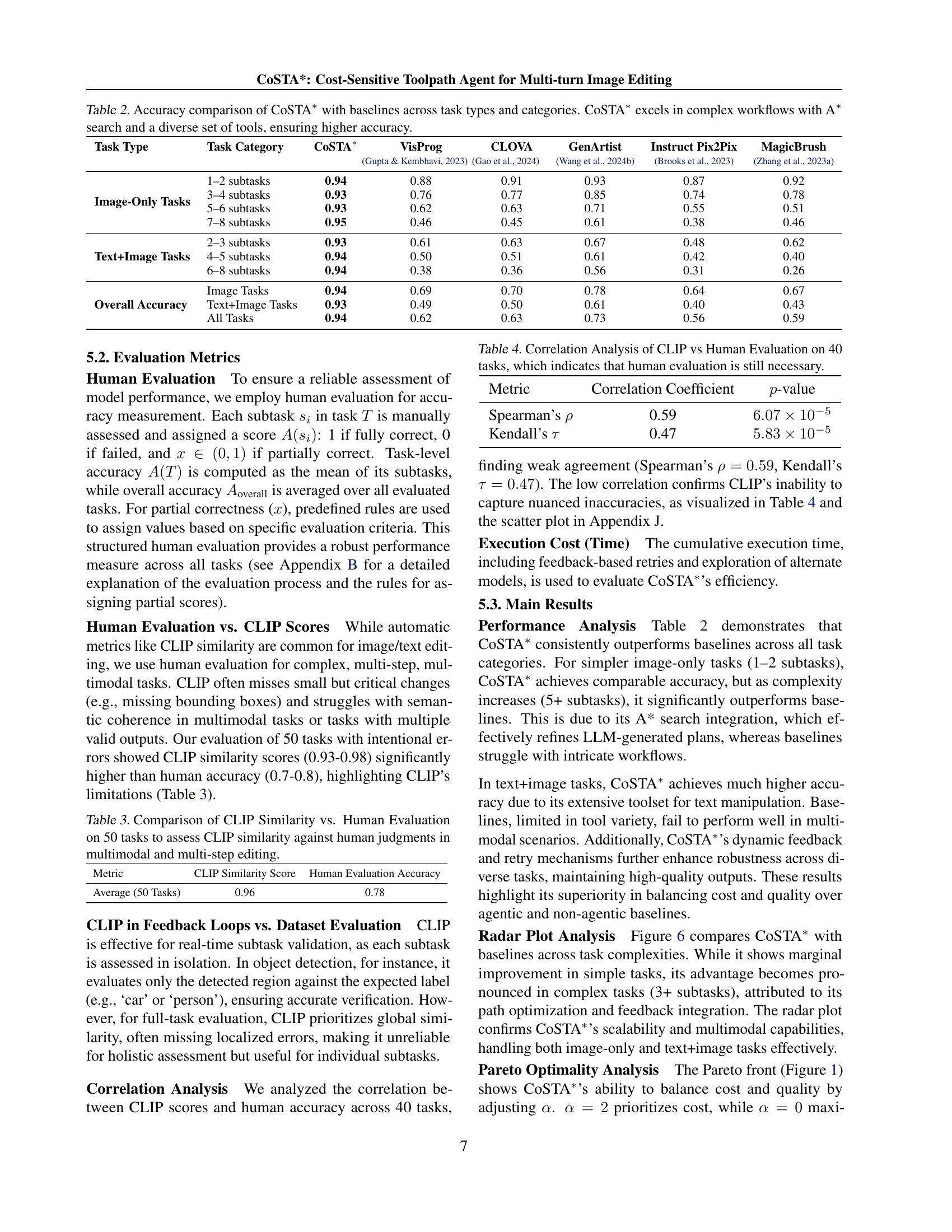
| Task Type | Task Category | CoSTA∗ | VisProg | CLOVA | GenArtist | Instruct Pix2Pix | MagicBrush |
|---|---|---|---|---|---|---|---|
| (Gupta & Kembhavi, 2023) | (Gao et al., 2024) | (Wang et al., 2024b) | (Brooks et al., 2023) | (Zhang et al., 2023a) | |||
| Image-Only Tasks | 1–2 subtasks | 0.94 | 0.88 | 0.91 | 0.93 | 0.87 | 0.92 |
| 3–4 subtasks | 0.93 | 0.76 | 0.77 | 0.85 | 0.74 | 0.78 | |
| 5–6 subtasks | 0.93 | 0.62 | 0.63 | 0.71 | 0.55 | 0.51 | |
| 7–8 subtasks | 0.95 | 0.46 | 0.45 | 0.61 | 0.38 | 0.46 | |
| Text+Image Tasks | 2–3 subtasks | 0.93 | 0.61 | 0.63 | 0.67 | 0.48 | 0.62 |
| 4–5 subtasks | 0.94 | 0.50 | 0.51 | 0.61 | 0.42 | 0.40 | |
| 6–8 subtasks | 0.94 | 0.38 | 0.36 | 0.56 | 0.31 | 0.26 | |
| Overall Accuracy | Image Tasks | 0.94 | 0.69 | 0.70 | 0.78 | 0.64 | 0.67 |
| Text+Image Tasks | 0.93 | 0.49 | 0.50 | 0.61 | 0.40 | 0.43 | |
| All Tasks | 0.94 | 0.62 | 0.63 | 0.73 | 0.56 | 0.59 |
🔼 Table 2 presents a detailed comparison of the accuracy achieved by the proposed CoSTA* model against several state-of-the-art baseline methods. The comparison is broken down by task type (image-only vs. text+image) and further categorized by the number of subtasks involved in each task (1-2, 3-4, 5-6, 7-8). This breakdown allows for a nuanced analysis of how each method performs under varying levels of complexity. The results highlight CoSTA*’s superior performance, especially in complex scenarios with multiple subtasks and both image and text data. This demonstrates the efficacy of the CoSTA* approach in managing challenging, multi-step image editing tasks.
read the caption
Table 2: Accuracy comparison of CoSTA∗ with baselines across task types and categories. CoSTA∗ excels in complex workflows with A∗ search and a diverse set of tools, ensuring higher accuracy.
| Metric | CLIP Similarity Score | Human Evaluation Accuracy |
|---|---|---|
| Average (50 Tasks) | 0.96 | 0.78 |
🔼 This table presents a comparison of CLIP (Contrastive Language–Image Pre-training) similarity scores against human evaluation scores for 50 image editing tasks. The tasks involved multimodal and multi-step edits, meaning they required multiple AI tools to complete and combined image and text modifications. The comparison highlights the limitations of using CLIP similarity as a sole metric for assessing the quality of complex image manipulations, particularly those involving semantic nuances and holistic image understanding, where human evaluation is necessary for more accurate assessment.
read the caption
Table 3: Comparison of CLIP Similarity vs. Human Evaluation on 50 tasks to assess CLIP similarity against human judgments in multimodal and multi-step editing.
| Metric | Correlation Coefficient | -value |
|---|---|---|
| Spearman’s | 0.59 | |
| Kendall’s | 0.47 |
🔼 This table presents a correlation analysis comparing the CLIP (Contrastive Language–Image Pre-training) similarity scores against human evaluation scores for 40 image editing tasks. The analysis reveals a weak correlation between automatic CLIP scores and human judgments, highlighting the limitations of relying solely on CLIP for evaluating the quality and accuracy of complex image editing tasks. Human evaluation remains essential for capturing nuanced aspects of image quality, including subtle errors and semantic coherence issues that automatic metrics often miss. The table shows the correlation coefficients (Spearman’s ρ and Kendall’s τ) and their corresponding p-values to quantify the strength and statistical significance of the correlation between CLIP and human scores.
read the caption
Table 4: Correlation Analysis of CLIP vs Human Evaluation on 40 tasks, which indicates that human evaluation is still necessary.
| Feature | CoSTA∗ | CLOVA | GenArtist | VisProg | Instruct Pix2Pix |
|---|---|---|---|---|---|
| Integration of LLM with A* Path Optimization | ✓ | × | × | × | × |
| Automatic Feedback Integration (Real-Time) | ✓ | × | × | × | × |
| Real-Time Cost-Quality Tradeoff | ✓ | × | × | × | × |
| User-Defined Cost-Quality Weightage | ✓ | × | × | × | × |
| Multimodality Support (Image + Text) | ✓ | × | × | × | × |
| Number of Tools for Task Accomplishment | 24 | <10 | <10 | <12 | <5 |
| Feedback-Based Retrying and Model Selection | ✓ | ✓ | ✓ | × | × |
| Dynamic Adjustment of Heuristic Values | ✓ | × | × | × | × |
🔼 Table 5 presents a comparative analysis of key features across several image editing methods, including CoSTA*. The table highlights the substantial advantages of CoSTA* over other baselines. These advantages stem from CoSTA*’s unique combination of features such as its integration of a large language model (LLM) with A* search, its capability for path optimization, its real-time feedback integration, and its support for both image and text-based editing. The table explicitly shows that CoSTA* possesses functionalities absent in other methods, such as the ability to perform cost-quality tradeoffs and dynamically adjust its heuristic values. This comprehensive feature set contributes to CoSTA*’s superior performance in complex image editing tasks.
read the caption
Table 5: Comparison of key features across methods, highlighting the extensive set of capabilities supported by CoSTA∗, which are absent in baselines and contribute to its superior performance.
| Approach | Average Accuracy |
|---|---|
| Only | 0.798 |
| 0.923 |
🔼 Table 6 presents the results of an ablation study comparing the performance of the CoSTA* model with and without real-time feedback. The study focuses on 35 high-risk tasks (defined as those where the initial heuristic alone might lead to suboptimal tool selection), measuring the accuracy achieved in each case. This allows for a direct assessment of how the incorporation of real-time cost and quality feedback (represented by g(x)) impacts the overall accuracy of the multi-step image editing process.
read the caption
Table 6: Comparison of accuracy with and without g(x)𝑔𝑥g(x)italic_g ( italic_x ) on 35 high-risk tasks to analyze the impact of real-time feedback g(x)𝑔𝑥g(x)italic_g ( italic_x ).
| Metric | Image Editing Tools | CoSTA* |
|---|---|---|
| Average Accuracy (30 Tasks) | 0.48 | 0.93 |
🔼 This table presents a comparison of the performance of CoSTA* against other image editing tools specifically on tasks involving text manipulation within images. The results demonstrate that CoSTA* significantly outperforms the image-only editing tools by achieving a substantially higher average accuracy across 30 text-based image editing tasks. This highlights CoSTA*’s superior capabilities in handling complex tasks requiring both image and text processing. The superior performance stems from CoSTA*’s ability to seamlessly integrate multiple tools and dynamically adapt its approach based on real-time feedback and quality assessment.
read the caption
Table 7: Comparison of image editing tools vs. CoSTA∗ for text-based tasks. CoSTA∗ outperforms image-only tools.
| Task Type | Evaluation Criteria | Assigned Score |
|---|---|---|
| Image-Only Tasks | Minor artifacts, barely noticeable distortions | 0.9 |
| Some visible artifacts, but main content is unaffected | 0.8 | |
| Noticeable distortions, but retains basic correctness | 0.7 | |
| Significant artifacts or blending issues | 0.5 | |
| Major distortions or loss of key content | 0.3 | |
| Output is almost unusable, but some attempt is visible | 0.1 | |
| Text+Image Tasks | Text is correctly placed but slightly misaligned | 0.9 |
| Font or color inconsistencies, but legible | 0.8 | |
| Noticeable alignment or formatting issues | 0.7 | |
| Some missing or incorrect words but mostly readable | 0.5 | |
| Major formatting errors or loss of intended meaning | 0.3 | |
| Text placement is incorrect, missing, or unreadable | 0.1 |
🔼 This table outlines the criteria used for assigning partial correctness scores during human evaluation of image editing tasks. It specifies the score (on a scale from 0.1 to 0.9) assigned to different levels of correctness based on the presence of artifacts, distortions, and other issues in the generated image. Scores are provided separately for image-only tasks and those involving both text and images, reflecting the different criteria applied in each case. The table clarifies what constitutes minor artifacts versus major distortions or loss of key information, enabling consistent evaluations across various tasks and levels of complexity.
read the caption
Table 8: Predefined Rules for Assigning Partial Correctness Scores in Human Evaluation
| Subtask | Avg Similarity Score |
|---|---|
| Object Replacement | 0.98 |
| Object Recoloration | 0.99 |
| Object Addition | 0.97 |
| Object Removal | 0.97 |
| Image Captioning | 0.92 |
| Outpainting | 0.99 |
| Changing Scenery | 0.96 |
| Text Removal | 0.98 |
| QA on Text | 0.96 |
🔼 This table presents the average CLIP (Contrastive Language–Image Pre-training) similarity scores achieved for the outputs generated by CoSTA* on subtasks known to exhibit variability in their results (those with potential randomness in the output). The scores indicate the consistency of CoSTA*’s performance across multiple runs for each subtask, demonstrating its robustness. Lower scores suggest higher variability in the outputs. The subtasks assessed include object replacement, recoloration, addition, removal, image captioning, outpainting, scenery changes, and text operations.
read the caption
Table 9: Average CLIP Similarity Scores for Outputs of Randomness-Prone Subtasks
| Model | Tasks Supported | Inputs | Outputs |
|---|---|---|---|
| Grounding DINO(Liu et al., 2024) | Object Detection | Input Image | Bounding Boxes |
| YOLOv7(Wang et al., 2022) | Object Detection | Input Image | Bounding Boxes |
| SAM(Kirillov et al., 2023b) | Object Segmentation | Bounding Boxes | Segmentation Masks |
| DALL-E(Ramesh et al., 2021) | Object Replacement | Segmentation Masks | Edited Image |
| DALL-E(Ramesh et al., 2021) | Text Removal | Text Region Bounding Box | Image with Removed Text |
| Stable Diffusion Erase(Rombach et al., 2022b) | Text Removal | Text Region Bounding Box | Image with Removed Text |
| Stable Diffusion Inpaint(Rombach et al., 2022b) | Object Replacement, Object Recoloration, Object Removal | Segmentation Masks | Edited Image |
| Stable Diffusion Erase(Rombach et al., 2022b) | Object Removal | Segmentation Masks | Edited Image |
| Stable Diffusion 3(Rombach et al., 2022b) | Changing Scenery | Input Image | Edited Image |
| Stable Diffusion Outpaint(Rombach et al., 2022b) | Outpainting | Input Image | Expanded Image |
| Stable Diffusion Search & Recolor(Rombach et al., 2022b) | Object Recoloration | Input Image | Recolored Image |
| Stable Diffusion Remove Background(Rombach et al., 2022b) | Background Removal | Input Image | Edited Image |
| Text Removal (Painting) | Text Removal | Text Region Bounding Box | Image with Removed Text |
| DeblurGAN(Kupyn et al., 2018) | Image Deblurring | Input Image | Deblurred Image |
| LLM (GPT-4o) | Image Captioning | Input Image | Image Caption |
| LLM (GPT-4o) | Question Answering based on text, Sentiment Analysis | Extracted Text, Font Style Label | New Text, Text Region Bounding Box, Text Sentiment, Answers to Questions |
| Google Cloud Vision(Google Cloud, 2024) | Landmark Detection | Input Image | Landmark Label |
| CRAFT(Baek et al., 2019b) | Text Detection | Input Image | Text Bounding Box |
| CLIP(Radford et al., 2021) | Caption Consistency Check | Extracted Text | Consistency Score |
| DeepFont(Wang et al., 2015) | Text Style Detection | Text Bounding Box | Font Style Label |
| EasyOCR(Kittinaradorn et al., 2022) | Text Extraction | Text Bounding Box | Extracted Text |
| MagicBrush(Zhang et al., 2024a) | Object Addition | Input Image | Edited Image with Object |
| pix2pix(Isola et al., 2018) | Changing Scenery (Day2Night) | Input Image | Edited Image |
| Real-ESRGAN(Wang et al., 2021) | Image Upscaling | Input Image | High-Resolution Image |
| Text Writing using Pillow (For Addition) | Text Addition | New Text, Text Region Bounding Box | Image with Text Added |
| Text Writing using Pillow | Text Replacement, Keyword Highlighting | Image with Removed Text | Image with Text Added |
| Text Redaction (Code-based) | Text Redaction | Text Region Bounding Box | Image with Redacted Text |
| MiDaS | Depth Estimation | Input Image | Image with Depth of Objects |
🔼 This table details the models used in the CoSTA* system. For each model, it lists the subtasks it can perform, any dependencies on outputs from other models as inputs, and the outputs it produces. This information is crucial for understanding how the CoSTA* system orchestrates different models to accomplish complex multi-turn image editing tasks. The table facilitates the automatic construction of the Tool Dependency Graph (TDG) which is used in the algorithm.
read the caption
Table 10: Model Description Table (MDT). Each model is listed with its supported subtasks, input dependencies, and outputs.
| Model Name | Subtask | Accuracy | Time (s) | Source |
|---|---|---|---|---|
| DeblurGAN(Kupyn et al., 2018) | Image Deblurring | 1.00 | 0.8500 | (Kupyn et al., 2018) |
| MiDaS(Ranftl et al., 2020) | Depth Estimation | 1.00 | 0.7100 | Evaluation on 137 instances of this subtask |
| YOLOv7(Wang et al., 2022) | Object Detection | 0.82 | 0.0062 | (Wang et al., 2022) |
| Grounding DINO(Liu et al., 2024) | Object Detection | 1.00 | 0.1190 | Accuracy: (Liu et al., 2024), Time: Evaluation on 137 instances of this subtask |
| CLIP(Radford et al., 2021) | Caption Consistency Check | 1.00 | 0.0007 | Evaluation on 137 instances of this subtask |
| SAM(Ravi et al., 2024) | Object Segmentation | 1.00 | 0.0460 | Accuracy: Evaluation on 137 instances of this subtask, Time: (Ravi et al., 2024) |
| CRAFT(Baek et al., 2019b) | Text Detection | 1.00 | 1.2700 | Accuracy: (Baek et al., 2019b), Time: Evaluation on 137 instances of this subtask |
| Google Cloud Vision(Google Cloud, 2024) | Landmark Detection | 1.00 | 1.2000 | Evaluation on 137 instances of this subtask |
| EasyOCR(Kittinaradorn et al., 2022) | Text Extraction | 1.00 | 0.1500 | Evaluation on 137 instances of this subtask |
| Stable Diffusion Erase(Rombach et al., 2022a) | Object Removal | 1.00 | 13.8000 | Evaluation on 137 instances of this subtask |
| DALL-E(Ramesh et al., 2021) | Object Replacement | 1.00 | 14.1000 | Evaluation on 137 instances of this subtask |
| Stable Diffusion Inpaint(Rombach et al., 2022a) | Object Removal | 0.93 | 12.1000 | Evaluation on 137 instances of this subtask |
| Stable Diffusion Inpaint(Rombach et al., 2022a) | Object Replacement | 0.97 | 12.1000 | Evaluation on 137 instances of this subtask |
| Stable Diffusion Inpaint(Rombach et al., 2022a) | Object Recoloration | 0.89 | 12.1000 | Evaluation on 137 instances of this subtask |
| Stable Diffusion Search & Recolor(Rombach et al., 2022a) | Object Recoloration | 1.00 | 14.7000 | Evaluation on 137 instances of this subtask |
| Stable Diffusion Outpaint(Rombach et al., 2022a) | Outpainting | 1.00 | 12.7000 | Evaluation on 137 instances of this subtask |
| Stable Diffusion Remove Background(Rombach et al., 2022a) | Background Removal | 1.00 | 12.5000 | Evaluation on 137 instances of this subtask |
| Stable Diffusion 3(Rombach et al., 2022a) | Changing Scenery | 1.00 | 12.9000 | Evaluation on 137 instances of this subtask |
| pix2pix(Isola et al., 2018) | Changing Scenery (Day2Night) | 1.00 | 0.7000 | Accuracy: (Isola et al., 2018), Time: Evaluation on 137 instances of this subtask |
| Real-ESRGAN(Wang et al., 2021) | Image Upscaling | 1.00 | 1.7000 | Evaluation on 137 instances of this subtask |
| LLM (GPT-4o) | Question Answering based on Text | 1.00 | 6.2000 | Evaluation on 137 instances of this subtask |
| LLM (GPT-4o) | Sentiment Analysis | 1.00 | 6.1500 | Evaluation on 137 instances of this subtask |
| LLM (GPT-4o) | Image Captioning | 1.00 | 6.3100 | Evaluation on 137 instances of this subtask |
| DeepFont(Wang et al., 2015) | Text Style Detection | 1.00 | 1.8000 | Evaluation on 137 instances of this subtask |
| Text Writing - Pillow | Text Replacement | 1.00 | 0.0380 | Evaluation on 137 instances of this subtask |
| Text Writing - Pillow | Text Addition | 1.00 | 0.0380 | Evaluation on 137 instances of this subtask |
| Text Writing - Pillow | Keyword Highlighting | 1.00 | 0.0380 | Evaluation on 137 instances of this subtask |
| MagicBrush(Zhang et al., 2023a) | Object Addition | 1.00 | 12.8000 | Accuracy: (Zhang et al., 2023a), Time: Evaluation on 137 instances of this subtask |
| Text Redaction | Text Redaction | 1.00 | 0.0410 | Evaluation on 137 instances of this subtask |
| Text Removal by Painting | Text Removal (Fallback) | 0.20 | 0.0450 | Evaluation on 137 instances of this subtask |
| DALL-E(Ramesh et al., 2021) | Text Removal | 1.00 | 14.2000 | Evaluation on 137 instances of this subtask |
| Stable Diffusion Erase(Rombach et al., 2022a) | Text Removal | 0.97 | 13.8000 | Evaluation on 137 instances of this subtask |
🔼 Table 11 presents benchmark results for various tools used in image editing tasks, focusing on accuracy and execution time. The data is sourced from published benchmarks whenever available. For tools lacking pre-existing benchmark data, the table includes results derived from evaluating the tools on 137 instances of each relevant subtask, using a dataset of 121 images. This extensive evaluation ensures a robust assessment across diverse conditions.
read the caption
Table 11: Benchmark Table for Accuracy and Execution Time. Accuracy and execution time for each tool-task pair are obtained from cited sources where available. For tools without prior benchmarks, evaluation was conducted over 137 instances of the specific subtask on 121 images from the dataset, ensuring a robust assessment across varied conditions.
Full paper#