TL;DR#
Large Language Models have excelled in various tasks, leading to interest in multimodal integration, like speech. Existing methods link ASR to LLMs, missing disambiguation, or use modality projection with high costs. Speech discretization transforms speech into discrete units, simplifying training. However, development focuses on speech tasks, neglecting textual performance preservation.
This paper introduces SPIRE, a speech-augmented LLM built atop TOWER. It transcribes and translates English speech, maintaining original translation capabilities. Using HuBERT-based k-means, SPIRE undergoes continued pre-training with ASR data and instruction tuning. Code and models are available, showing effective speech input integration as an additional language during adaptation.
Key Takeaways#
Why does it matter?#
This paper is important because it provides a recipe to add speech to LLMs, enabling multimodal capabilities, which is a growing field. It offers insights into the trade-offs and best practices for integrating speech w/o compromising existing text capabilities. The reproducible pipeline and open-source models facilitate further research and development in multilingual speech processing and multimodal LLMs.
Visual Insights#

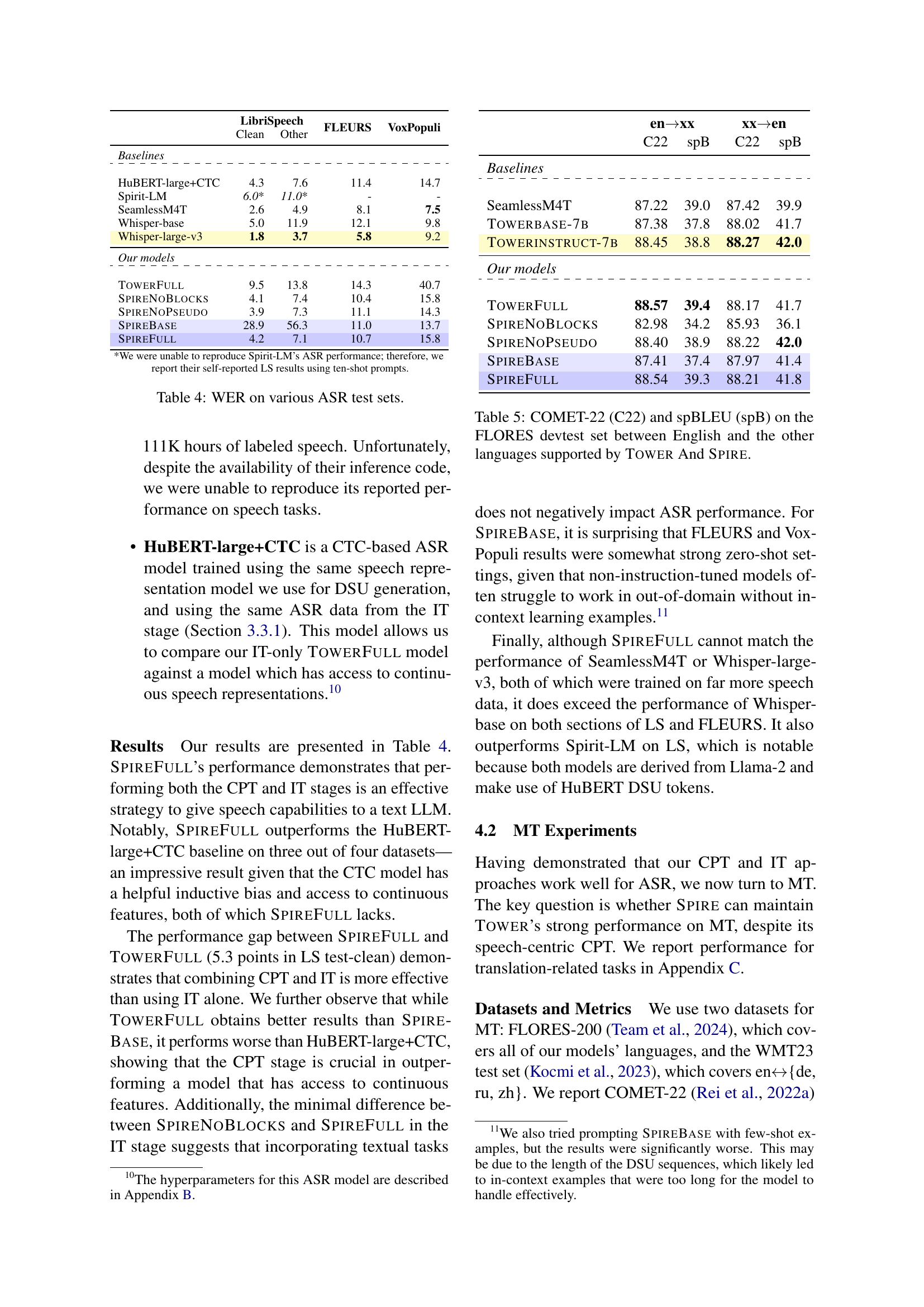
🔼 This figure illustrates the training pipeline for the two main variants of the SPIRE model: SpireBase and SpireFull. SpireBase undergoes continued pre-training (CPT) using a mixture of text data from the TOWER model and English speech data transcribed using HuBERT-based k-means clustering into discrete speech units (DSUs). SpireFull then takes the SpireBase model and further fine-tunes it through instruction tuning (IT) using additional data including task-specific datasets for machine translation (MT), automatic speech recognition (ASR), and speech translation (ST). The figure visually depicts the data flow and processing steps involved in building both models.
read the caption
Figure 1: Illustration of the model training method for SpireBase and SpireFull.
| ASR (CPT) | |||
| |||
| MT (CPT) | |||
| |||
| ASR (IT) | |||
| |||
| Direct ST (IT) | |||
| |||
| Multi-turn ST (IT) | |||
|
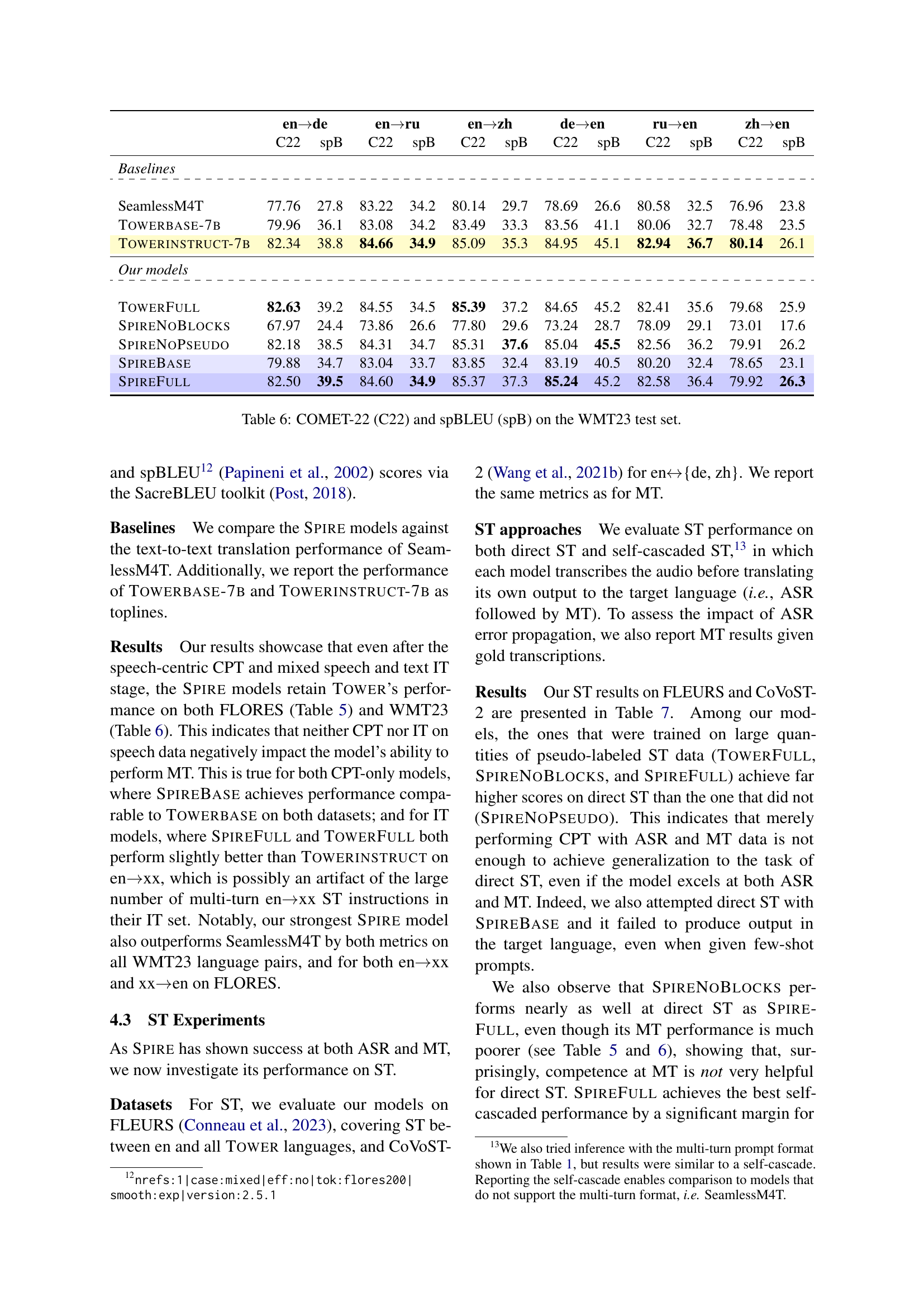
🔼 This table details the different prompt formats used during the training process of the SPIRE model. It shows how the input (speech or text) and desired output (transcript or translation) are formatted for different tasks and training stages (Continued Pretraining (CPT) and Instruction Tuning (IT)). The table is crucial for understanding the specifics of the multi-modal training approach and how speech is integrated with the existing text-based training data.
read the caption
Table 1: Prompt formats used at different training stages.
In-depth insights#
LLM Speech Boost#
While “LLM Speech Boost” isn’t a direct heading in the paper, the study inherently explores methods to enhance LLMs using speech data. Key areas involve modality integration, specifically adding speech to text-only LLMs. The core idea revolves around leveraging speech discretization and continued pre-training to adapt existing LLMs. A critical aspect is the pursuit of a balance, retaining the original LLM’s textual capabilities while successfully integrating speech processing. The research aims to achieve superior ASR and ST performance without sacrificing MT capabilities. This suggests exploring strategies for efficient transfer learning and adaptation of existing models to incorporate speech data effectively. Ultimately, the goal is to improve the LLM’s performance on speech-related tasks while preserving or even enhancing its existing capabilities.
Discrete Speech#
The concept of discrete speech is crucial in bridging the gap between continuous audio signals and language models. Instead of directly feeding raw audio into models, discrete speech involves converting the audio into a sequence of discrete units. This is often achieved through techniques like vector quantization or clustering of acoustic features. The benefits include reduced computational complexity, easier integration with text-based models, and potentially improved robustness to noise. However, a key challenge is finding the right level of granularity for these discrete units. Too coarse, and information is lost; too fine, and the sequence becomes unwieldy. Recent research explores various methods for learning these discrete units in a self-supervised manner, allowing models to capture the underlying structure of speech without explicit phonetic labels.
CPT & IT Synergy#
Continued Pre-training (CPT) followed by Instruction Tuning (IT) emerges as a powerful paradigm for adapting Large Language Models (LLMs) to new modalities, like speech, while preserving existing capabilities. CPT allows the model to learn fundamental representations of the new modality by treating discrete speech units as an additional language. IT then refines the model’s understanding by exposing it to task-specific instructions, guiding it to perform ASR, ST and translation-related functions. The synergy lies in the staged approach: CPT provides the foundation, and IT hones the model’s skills.
Text Task Kept#
Maintaining performance on text-based tasks is a crucial aspect when augmenting Large Language Models (LLMs) with speech processing capabilities. The central concern is ensuring that the integration of speech data does not degrade the LLM’s original strengths in understanding, generating, and manipulating text. This involves careful design of the training regime, including the selection of speech data, the method of integrating speech features, and the balancing of training objectives. If not done correctly, the adaptation process can lead to catastrophic forgetting or a shift in the model’s capabilities, resulting in diminished performance on its original text-based tasks like translation, summarization, and question answering. It’s important to implement strategies that prioritize textual performance while facilitating the acquisition of new speech-related skills.
Multiling. Path#
Considering a ‘Multiling. Path’ for an LLM entails several crucial steps. It begins with data acquisition, requiring vast amounts of text and speech data in multiple languages, ensuring diversity and balanced representation. Models like mHuBERT are pivotal here. Next, model architecture must accommodate multilingual processing, which is typically achieved through shared embeddings or language-specific adapters. The choice of training strategy is key; options include joint training, transfer learning, and curriculum learning, each impacting performance differently. A critical aspect is evaluation, which necessitates benchmarks that accurately assess cross-lingual understanding and generation, mitigating bias. Finally, it’s necessary to investigate methods of model alignment, to guarantee that the model displays equivalent levels of competence and generates consistent behavior across all supported languages.
More visual insights#
More on tables
| Speech:<extra_id_i><extra_id_j> |
| English: {TRANSCRIPT} |
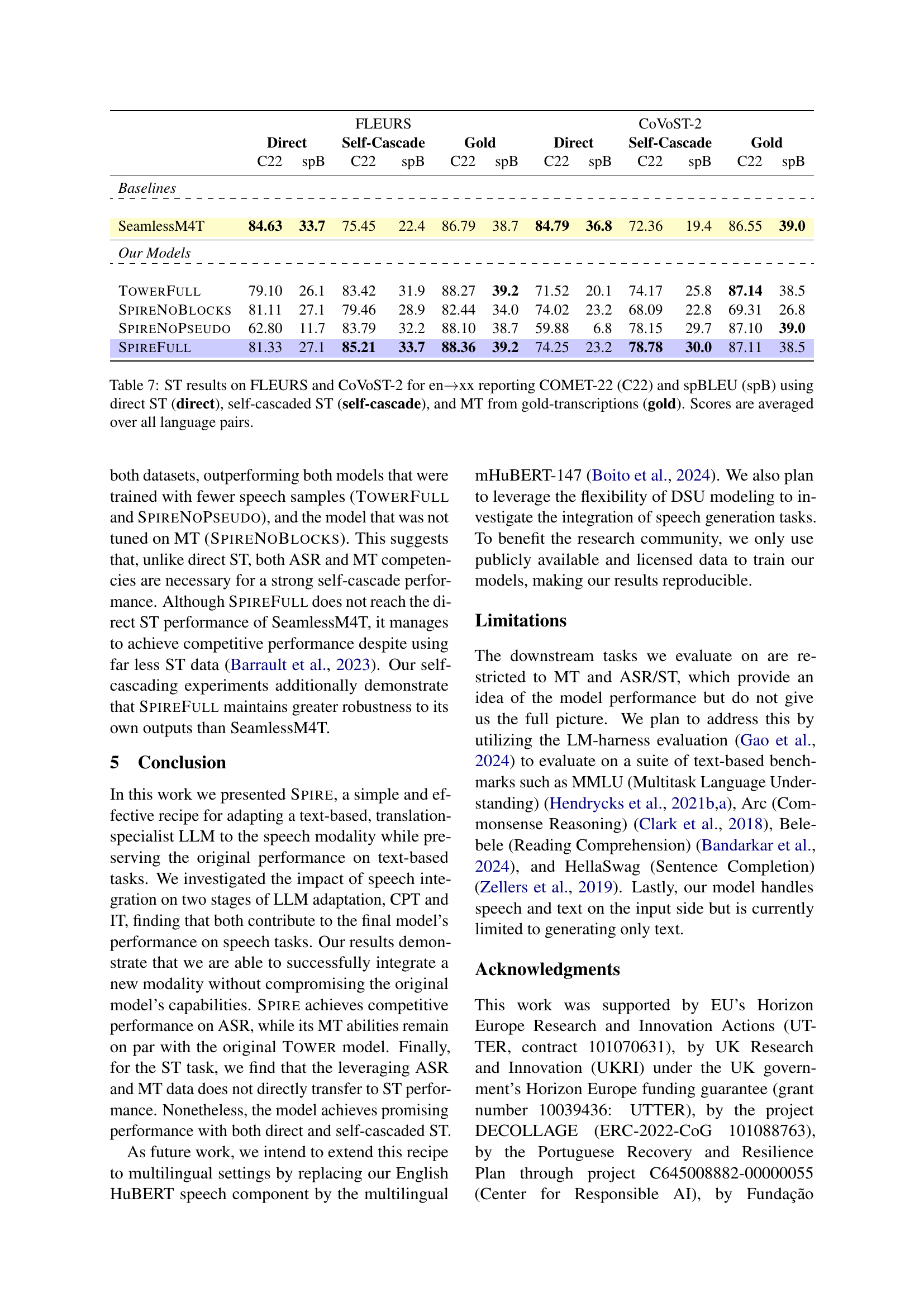
🔼 This table presents a detailed breakdown of the speech data used for training the SPIRE model. It shows the source dataset for each portion of the training data (SPGI Speech, GigaSpeech, MLS, VoxPopuli, CommonVoice, Europarl-ST, FLEURS, and CoVOST-2). For each dataset, it lists the specific task (ASR or ST) it was used for, the phase of training (CPT or IT), the number of Discrete Speech Units (DSUs) used, the total training time in hours, and whether the data was used for training in the Continued Pretraining (CPT) or Instruction Tuning (IT) stages, as well as whether the data was speech, text, or pseudo-labeled data. The number of hours is an approximation based on the deduplicated number of DSUs.
read the caption
Table 2: Statistics for the speech data used for training. Numbers of hours are approximated from the number of deduplicated DSUs.
| Source_lang: Source-sentence |
| Target_lang: {TRANSLATION} |
🔼 This table presents the different model variations used in the experiments. It shows the base model each variant is built upon (TowerBase-7B, SpireBase), and indicates whether each model was trained using continued pre-training (CPT) with speech data, continued pre-training (CPT) with text-only data, instruction tuning (IT) with speech data, or instruction tuning (IT) with text-only data. This allows for a comparison of the impact of different training stages and data types on model performance.
read the caption
Table 3: Our models and their variants, along with their base models. The CPT and IT columns indicate which data was seen during training.
| Speech: <extra_id_i><extra_id_j> |
| English: {TRANSCRIPT} |
🔼 This table presents the Word Error Rate (WER) achieved by various Automatic Speech Recognition (ASR) models on four different test sets: LibriSpeech (clean and other), FLEURS, and VoxPopuli. The models compared include established baselines (Whisper, SeamlessM4T, Spirit-LM, and a HuBERT-large+CTC model), and several variants of the SPIRE model, which is the focus of the paper. This allows for a comparison of SPIRE’s performance against existing state-of-the-art ASR systems, as well as an analysis of the impact of different training strategies (continued pre-training and instruction tuning) on SPIRE’s ASR capabilities.
read the caption
Table 4: WER on various ASR test sets.
| Speech: <extra_id_i><extra_id_j> |
| TARGET_LANG: {TRANSLATION} |
🔼 This table presents the results of the COMET-22 and spBLEU metrics on the FLORES devtest set. The results compare the performance of the Tower and Spire models on machine translation tasks between English and other languages supported by both models. It provides a detailed breakdown of the performance for each language pair, allowing for an in-depth comparison of the two models’ translation capabilities across various language combinations.
read the caption
Table 5: COMET-22 (C22) and spBLEU (spB) on the FLORES devtest set between English and the other languages supported by Tower And Spire.
| Speech: <extra_id_i><extra_id_j> |
| English:{TRANSCRIPT} |
| TARGET_LANG: {TRANSLATION} |
🔼 This table presents the results of the COMET-22 and spBLEU metrics on the WMT23 test set for machine translation. It compares the performance of various models, including the baseline TOWER models (TOWERBASE-7B and TOWERINSTRUCT-7B), the SeamlessM4T model, and different versions of the SPIRE model (TOWERFULL, SPIRENOBLOCKS, SPIRENOPSEUDO, SPIREBASE, and SPIREFULL). These different SPIRE models represent variations in training data and methods, allowing for an analysis of the impact of various choices on MT performance. The results are broken down by language pairs, providing a detailed comparison across different translation directions.
read the caption
Table 6: COMET-22 (C22) and spBLEU (spB) on the WMT23 test set.
| Dataset | Task | Phase | # DSUs | # Hours |
|---|---|---|---|---|
| SPGI Speech | ASR | CPT | 645M | 5.1K |
| Gigaspeech | ASR | CPT | 1.2B | 9.9K |
| MLS | ASR | CPT | 2.4B | 19.2K |
| VoxPopuli | ASR | CPT | 69M | 0.5K |
| CV | ASR | IT | 105M | 0.8K |
| Europarl-ST | ST | IT | 122M | 1.0K |
| FLEURS | ST | IT | 11M | 0.09K |
| CoVoST-2 | ST | IT | 12M | 0.09K |
| SPGI Speech | Pseudo-ST | IT | 350M | 2.8K |
| GigaSpeech | Pseudo-ST | IT | 161M | 1.3K |
| CV | Pseudo-ST | IT | 212M | 1.7K |
🔼 Table 7 presents the results of Speech Translation (ST) experiments on two datasets: FLEURS and CoVOST-2. The experiments focus on English-to-X (en→xx) translations, where ‘x’ represents various other languages. The table compares three approaches to ST: direct ST (translating audio directly to another language), self-cascaded ST (performing automatic speech recognition first, then translating the resulting text), and MT with gold-standard transcriptions (translating text that’s already been perfectly transcribed). The evaluation metrics used are COMET-22 (C22) and spBLEU (spB), which measure the quality of the translation. The scores are averaged across all language pairs within each dataset and method.
read the caption
Table 7: ST results on FLEURS and CoVoST-2 for en→→\rightarrow→xx reporting COMET-22 (C22) and spBLEU (spB) using direct ST (direct), self-cascaded ST (self-cascade), and MT from gold-transcriptions (gold). Scores are averaged over all language pairs.
| Model | Base Model | CPT | IT | |||
| Speech | Text | Speech | Pseudo | Text | ||
| TowerFull | TowerBase-7B | ✗ | ✗ | ✓ | ✓ | ✓ |
| SpireBase | SpireBase | ✓ | ✓ | ✗ | ✗ | ✗ |
| SpireFull | SpireBase | ✓ | ✓ | ✓ | ✓ | ✓ |
| \hdashline Spire Variants | ||||||
| \hdashlineSpireNoBlocks | SpireBase | ✓ | ✓ | ✓ | ✓ | ✗ |
| SpireNoPseudo | SpireBase | ✓ | ✓ | ✓ | ✗ | ✓ |
🔼 Table 8 presents the results of evaluating the SPIRE model on two translation-related tasks: Automatic Post-Editing (APE) and Named Entity Recognition (NER). APE assesses the quality of translations after post-editing, using COMET-22 scores. NER measures the accuracy of identifying named entities, using sequence F1 scores. The table compares SPIRE’s performance against the TOWERINSTRUCT and TOWERFULL models across multiple language pairs for APE and various languages for NER. The results show that SPIRE achieves comparable performance to TOWERINSTRUCT and even outperforms TOWERFULL, indicating the effectiveness of the model’s approach.
read the caption
Table 8: Results on APE and NER reporting COMET-22 (↑↑\uparrow↑) and sequence F1 score (↑↑\uparrow↑) respectively.
Full paper#