TL;DR#
Creating 3D avatars from single images is hard because of geometry, appearance, and movement. Existing methods mainly focus on static models, rely on synthetic data which limits real-world use, or need intensive refinement processes. To solve these issues, researchers need methods that are good at handling clothing, facial details, and animation consistency without needing lots of computing power or special setups. A model that can quickly and accurately create 3D avatars from single images would greatly benefit AR/VR.
This paper introduces a new approach called LHM, which is short for Large Animatable Human Reconstruction Model. It is a feed-forward transformer model that creates animatable 3D human avatars in seconds from a single image. The model uses a special transformer design to fuse 3D body features with 2D image features, and a new head feature method to improve face details. LHM is trained using readily available video data which avoids needing expensive 3D scans and achieves better results.
Key Takeaways#
Why does it matter?#
This paper introduces a novel method of creating animatable 3D human avatars from a single image in seconds. It surpasses existing methods and provides new avenues for real-time avatar creation and animation. Its generalization ability and potential impact on AR/VR applications make it significant for future research.
Visual Insights#

🔼 This figure showcases the capabilities of the Large Animatable Human Model (LHM). It presents several examples of human avatars reconstructed from single input images. The top row illustrates the input image, followed by the reconstructed 3D avatar, the avatar in various poses, demonstrating pose-controlled animation, and finally another reconstructed 3D avatar from a different input image. The reconstruction process takes only a couple of seconds per image using a single feed-forward pass through the model. The generated avatars are designed for real-time rendering and can be animated with different poses.
read the caption
Figure 1: 3D Avatar Reconstruction and Animation Results of our LHM. Our method reconstructs an animatable human avatar in a single feed-forward pass in seconds. The resulting model supports real-time rendering and pose-controlled animation.
| Methods | PSNR | SSIM | LPIPS | FC | |
| GTA [65] | 17.025 | 0.919 | 0.087 | 0.051 | |
| SIFu [66] | 16.681 | 0.917 | 0.093 | 0.060 | |
| PSHuman [29] | 17.556 | 0.921 | 0.076 | 0.037 | |
| DreamGaussian [41] | 18.544 | 0.917 | 0.075 | 0.056 | |
| LHM-0.5B* | 25.183 | 0.951 | 0.029 | 0.035 |
🔼 This table presents a quantitative comparison of different methods for static 3D human reconstruction using synthetic data. The metrics used to evaluate the performance are PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), LPIPS (Learned Perceptual Image Patch Similarity), and FC (Face Consistency). Higher PSNR and SSIM values and lower LPIPS and FC values indicate better performance. The asterisk (*) indicates models trained exclusively on synthetic data, highlighting their potential limitations in generalizing to real-world scenarios.
read the caption
Table 1: Evaluation of static 3D reconstruction on synthtic data. * indicates this model only trains on synthetic data.
In-depth insights#
3D Avatar LHM#
While “3D Avatar LHM” isn’t explicitly a section title, we can infer its meaning from the paper’s content. LHM (Large Animatable Human Reconstruction Model) aims to create high-quality, animatable 3D avatars from single images. It tackles the challenge of decoupling geometry, appearance, and deformation, which are often ambiguous in single-image 3D reconstruction. The method stands out by using 3D Gaussian splatting for avatar representation, enabling real-time rendering and pose control. A key aspect is the multimodal transformer architecture, effectively encoding both 3D human body positional features and 2D image features, paying special attention to clothing geometry and texture, plus preserving face identity. The innovation lies in its feed-forward nature, achieving reconstruction in seconds, and its ability to generalize well to real-world images thanks to training on large-scale video data without relying on scarce 3D scans. LHM represents a leap towards efficient and generalizable 3D avatar creation.
Animatable Models#
Animatable models represent a crucial step beyond static 3D reconstruction, offering the capability to manipulate and pose reconstructed humans. This field addresses the challenge of decoupling geometry, appearance, and deformation, enabling realistic dynamic simulations. Early approaches relied on parametric models like SMPL, providing strong body priors but struggling with clothing details and facial expressions. Recent advancements combine implicit surfaces with human priors to model clothed bodies more effectively. Video-based techniques leverage temporal cues to improve reconstruction consistency from monocular or multi-view sequences. Text-to-3D methods enable avatar generation from text prompts, though often requiring extensive optimization. Current research explores diffusion models and transformer-based architectures to achieve high-quality, animatable human avatars with improved generalization and real-time performance. A key challenge lies in creating models that are both expressive and efficient, capable of capturing fine-grained details while supporting realistic animation.
MM Transformer#
The MM Transformer seems to play a pivotal role, acting as the central processing unit for fusing different modalities of data, specifically 3D geometric information with 2D image features. It’s architecture likely leverages attention mechanisms to allow the model to selectively focus on the most relevant features from each modality, facilitating a more nuanced understanding of the human form. This fusion enables the model to reason jointly across geometric and visual domains, capturing intricate details of clothing and body shape that might be missed by processing each modality separately. By incorporating a global context feature, the MM Transformer can contextualize local features, improving its ability to resolve ambiguities and generate more coherent and realistic human reconstructions. Overall, the MM Transformer architecture appears to be a key innovation for achieving high-fidelity and animatable 3D human models.
Geometric encode#
Geometric encoding is crucial for 3D human reconstruction, addressing ambiguities in appearance and deformation. Early methods relied on parametric models like SMPL, but these struggle with diverse clothing. Recent advancements use implicit functions for finer details. The Large Animatable Human Reconstruction Model (LHM) leverages SMPL-X surface points, encoding structural priors. Positional encoding and MLPs transform these points into geometric tokens. LHM’s geometric encoding effectively attends to image tokens, allowing for local and global refinement, which ultimately leading to more detailed and accurate 3D representations.
Canonical Space#
The concept of “Canonical Space” in 3D human reconstruction, particularly when dealing with single images, is pivotal for disentangling pose and shape. It provides a pose-invariant representation, enabling the model to learn shape priors independently of articulation. This addresses the inherent ambiguity in monocular 3D reconstruction, where pose variations can be misinterpreted as shape changes. Regularization in this space, as observed in the paper, is crucial because photometric losses alone, while effective in target view space, often leave the canonical representation under-constrained. This can lead to implausible deformations when the avatar is posed. Therefore, techniques like Gaussian shape regularization and positional anchoring are employed to ensure geometric coherence in canonical space, preventing excessive anisotropy and maintaining body surface plausibility. Canonical space constraints enhance the model’s generalization ability, enabling robust reconstruction and animation even for novel poses not seen during training.
More visual insights#
More on figures

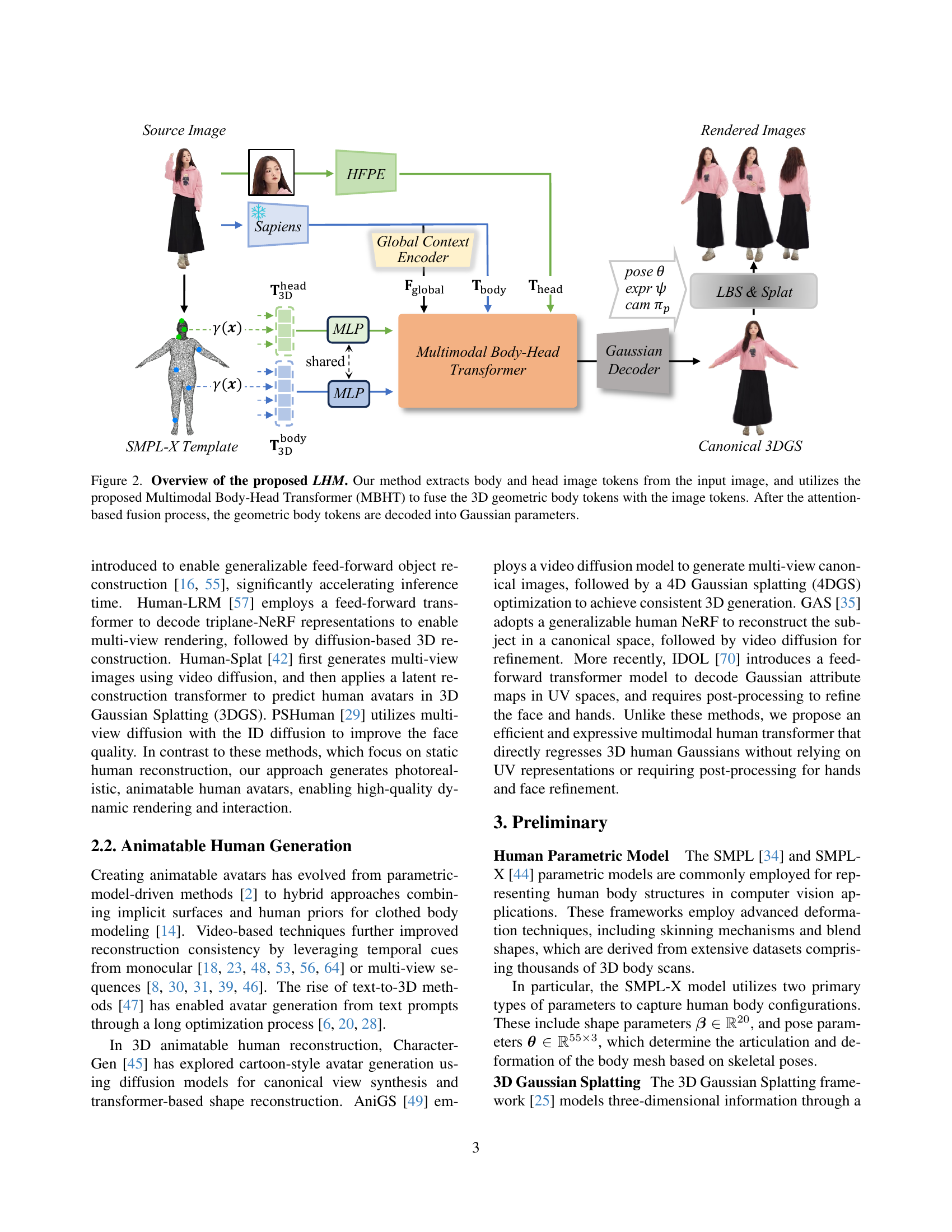
🔼 The figure illustrates the architecture of the Large Animatable Human Model (LHM). The LHM takes a single image as input and processes it through several steps. First, it extracts image tokens representing both the body and the head from the input image. Simultaneously, 3D geometric body tokens are generated from a SMPL-X template mesh. These two types of tokens (image and geometric) are fed into a Multimodal Body-Head Transformer (MBHT) module. Inside the MBHT, the tokens are fused using an attention mechanism, combining visual information with geometric priors. Finally, the resulting fused geometric tokens are decoded into parameters defining a 3D Gaussian splatting representation of the human body, allowing for realistic and animatable 3D rendering.
read the caption
Figure 2: Overview of the proposed LHM. Our method extracts body and head image tokens from the input image, and utilizes the proposed Multimodal Body-Head Transformer (MBHT) to fuse the 3D geometric body tokens with the image tokens. After the attention-based fusion process, the geometric body tokens are decoded into Gaussian parameters.

🔼 The Multimodal Body-Head Transformer (MBHT) block fuses 3D geometric tokens with body and head image features. Global context features, image tokens, and query point tokens are fed into the MBHT block. 3D head point tokens first fuse with head image features, and then concatenate with 3D body point tokens to interact with body image tokens. This architecture facilitates balanced attention across different body regions, improving the overall accuracy and detail preservation in the resulting 3D human model.
read the caption
Figure 3: Architecture of the proposed Multimodal Body-Head Transformer Block (MBHT-block).

🔼 Figure 4 presents a comparison of single-image 3D human reconstruction results from different methods, including the proposed LHM model. The comparison uses images from the DeepFashion dataset and also real-world, in-the-wild images. The results visually demonstrate that LHM achieves significantly higher levels of visual fidelity and detail, particularly noticeable in the sharpness of facial features and the accurate rendering of wrinkles and folds in clothing compared to other existing methods.
read the caption
Figure 4: Single-view reconstruction comparisons on DeepFashion [33] and in-the-wild images. LHM achieves superior appearance fidelity and texture sharpness, particularly evident in facial details and garment wrinkles.
🔼 Figure 5 presents a comparison of single-image animatable human reconstruction results between LHM and three other methods (AniGS, Ours). The results demonstrate LHM’s superior ability to produce more accurate and photorealistic animation sequences compared to existing approaches. The figure highlights that while other techniques can generate animations, they often fail to accurately capture the details and appearance of the input image, particularly evident in the results from the AniGS method, which deviates significantly from the input.
read the caption
Figure 5: Single-view animatable human reconstruction comparisons on in-the-wild sequences. LHM produces more accurate and photorealistic animation results than the baseline methods. Note that the results of AniGS are not faithful to the input images.

🔼 This ablation study analyzes the effects of different model parameters and architectural choices on the overall performance of the LHM model. Specifically, it compares results using the multimodal body-head transformer against a simpler alternative. It also demonstrates the influence of the head token shrinkage regularization technique and the impact of varying the model’s size (parameter count) on the quality of the generated 3D avatars. Visual comparisons of the generated avatars highlight the differences in reconstruction quality and detail across these various model configurations.
read the caption
Figure 6: Ablation study on model design and parameters.

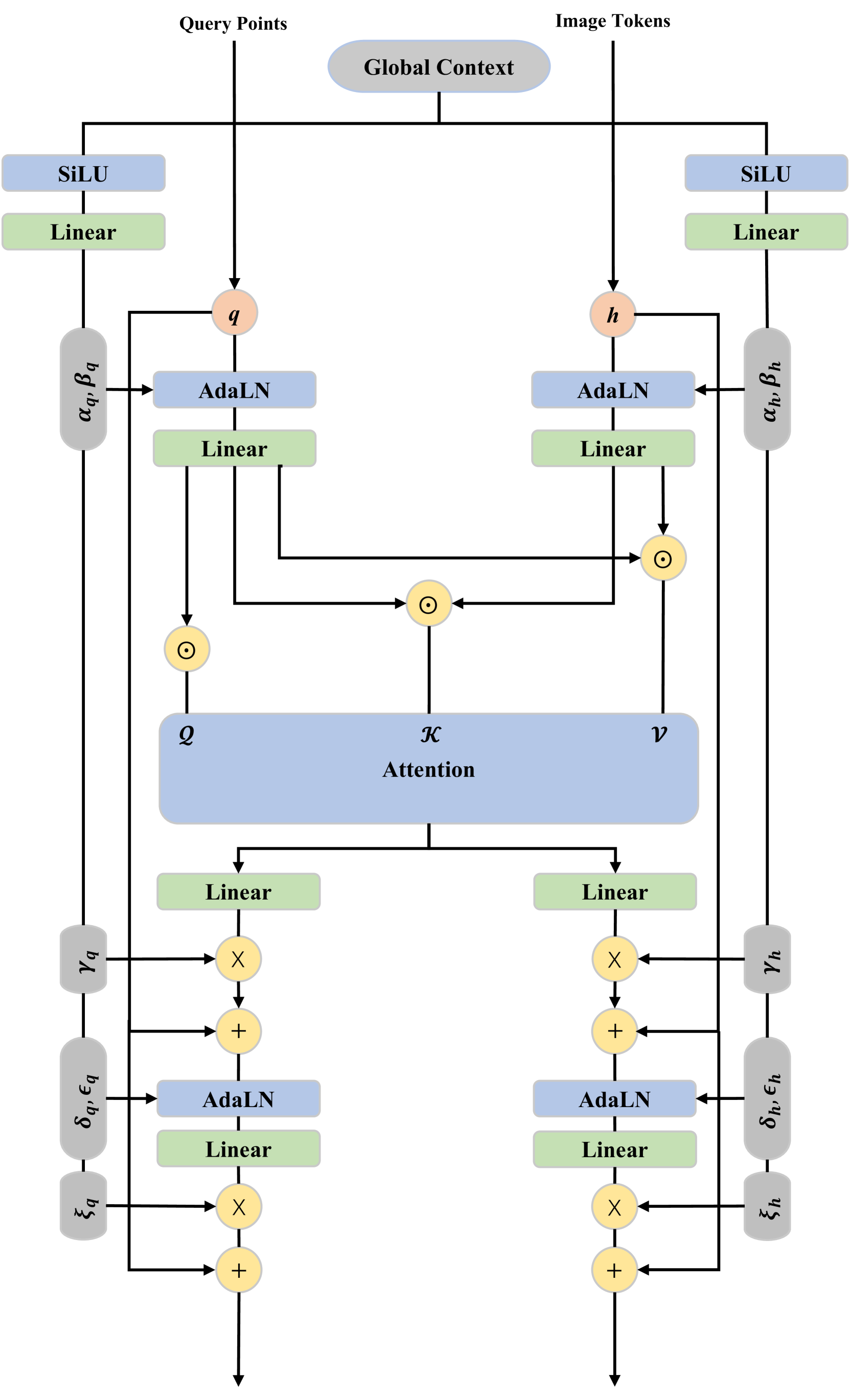
🔼 This figure presents a detailed breakdown of the Multi-Modal Transformer architecture, a key component of the LHM model. It shows the flow of information, including query points, image tokens, and global context features, through the various layers including attention mechanisms and adaptive layer normalization. The diagram illustrates how these different input modalities are integrated using multi-head attention to produce a refined output.
read the caption
Figure 7: Detailed architecture of Multi-Modal Transformer [11].

🔼 Figure 8 illustrates the architecture of the Head Feature Pyramid Encoding (HFPE) module. The HFPE module is designed to address the challenge of capturing high-frequency details in facial features, particularly given the small size of the face region within the input image and potential spatial downsampling during processing. The figure shows multiple stages: the input image, various feature extractors (ViT blocks), and the final concatenation and projection to output multi-scale facial features.
read the caption
Figure 8: Architecture of our HFPE for multi-scale facial feature extraction

🔼 This ablation study visualizes the impact of the canonical space shape regularization loss on the quality of 3D human reconstruction. The images show that using both the ‘as spherical as possible’ loss (LASAP) and the ‘as close as possible’ loss (LACAP) results in more accurate and realistic human models, compared to models trained without these losses. The lack of LASAP leads to artifacts such as semi-transparent boundaries, while the lack of LACAP causes floating points around the human body, indicating the importance of both regularization techniques for robust and accurate reconstruction.
read the caption
Figure 9: Ablation for canonical space shape regularization.
More on tables
| Methods | PSNR | SSIM | LPIPS | FC | Time | Memory | |
| En3D [36] | 15.231 | 0.734 | 0.172 | 0.058 | 5 minutes | 32 GB | |
| AniGS [49] | 18.681 | 0.871 | 0.103 | 0.053 | 15 minutes | 24 GB | |
| LHM-0.5B | 21.648 | 0.924 | 0.044 | 0.042 | 2.01 seconds | 18 GB | |
| LHM-0.7B | 21.879 | 0.930 | 0.039 | 0.039 | 4.13 seconds | 21 GB | |
| LHM-1B | 22.003 | 0.930 | 0.040 | 0.035 | 6.57 seconds | 24 GB |
🔼 This table presents a quantitative comparison of human animation results from different methods on real-world video datasets. It evaluates the performance of the proposed LHM model (Large Animatable Human Reconstruction Model) against two established baseline methods (En3D and AniGS) using metrics such as Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), Face Consistency (FC), processing time, and memory usage. The results showcase the superior performance of LHM in generating high-quality, photorealistic, and consistent human animations, significantly outperforming baseline methods in terms of accuracy and efficiency.
read the caption
Table 2: Human animation results on in-the-wild video dataset.
| Methods | PSNR | SSIM | LPIPS | FC | |
| LHM-0.5B + Synthetic Data | 19.753 | 0.904 | 0.060 | 0.057 | |
| LHM-0.5B + 10K Videos | 20.692 | 0.911 | 0.052 | 0.048 | |
| LHM-0.5B + 50K Videos | 21.108 | 0.915 | 0.050 | 0.043 | |
| LHM-0.5B + 100K Videos | 21.429 | 0.920 | 0.049 | 0.045 | |
| LHM-0.5B + All | 21.648 | 0.924 | 0.044 | 0.042 |
🔼 This table presents a quantitative comparison of different methods for human animation on real-world video data. It shows the performance of several models, including LHM variants with different model sizes and training data amounts, as well as two baseline methods (En3D and AniGS). The evaluation metrics used are PSNR, SSIM, LPIPS, and Face Consistency (FC), providing a comprehensive assessment of reconstruction quality. Inference time and memory usage are also reported to highlight the efficiency of the different approaches.
read the caption
Table 3: Quantitative results on in-the-wild video dataset.
| Methods | PSNR | SSIM | LPIPS | FC | |
| LHM-0.5B w/ MM-Transformer | 20.072 | 0.907 | 0.100 | 0.053 | |
| LHM-0.5B w/o Shrinkage Regularization | 21.037 | 0.915 | 0.049 | 0.041 | |
| LHM-0.5B | 21.648 | 0.924 | 0.044 | 0.042 |
🔼 This table presents an ablation study on the effectiveness of different components within the model’s transformer architecture. It compares the performance of the full model against variations where specific parts of the transformer are removed or modified, allowing for an analysis of their individual contributions to the overall model’s accuracy and performance.
read the caption
Table 4: Ablation study for the transformer architecture.
Full paper#