TL;DR#
Existing zero-shot methods for goal-oriented navigation are often task-specific, limiting their ability to generalize across different types of goals. These methods typically rely on large language models (LLMs) but differ significantly in their overall pipeline, resulting in a lack of versatility. To address this, the paper introduces a general framework for universal zero-shot goal-oriented navigation.
The proposed UniGoal framework uses a uniform graph representation to unify different goals and converts agent observations into an online maintained scene graph. It leverages LLMs for explicit graph-based reasoning and employs a multi-stage scene exploration policy based on graph matching between the scene and goal graphs. Experiments demonstrate that UniGoal achieves state-of-the-art zero-shot performance on multiple navigation tasks with a single model.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it introduces a universal zero-shot goal-oriented navigation framework, addressing limitations of task-specific methods. It enables greater flexibility and generalization in robotic navigation, opening avenues for more versatile and adaptable AI agents in complex environments.
Visual Insights#

🔼 Existing zero-shot navigation methods are designed for specific goal types (object, image, text), limiting their generalizability. Universal methods exist, but they require extensive training data and lack true zero-shot capabilities. UniGoal addresses these limitations by using a unified framework for zero-shot inference across object, image, and text-based navigation goals, achieving state-of-the-art performance.
read the caption
Figure 1: State-of-the-art zero-shot goal-oriented navigation methods are typically specialized for each goal type. Although recent work presents universal goal-oriented navigation method, it requires to train policy networks on large-scale data and lacks zero-shot generalization ability. We propose UniGoal, which enables zero-shot inference on three studied navigation tasks with a unified framework and achieves leading performance on multiple benchmarks.
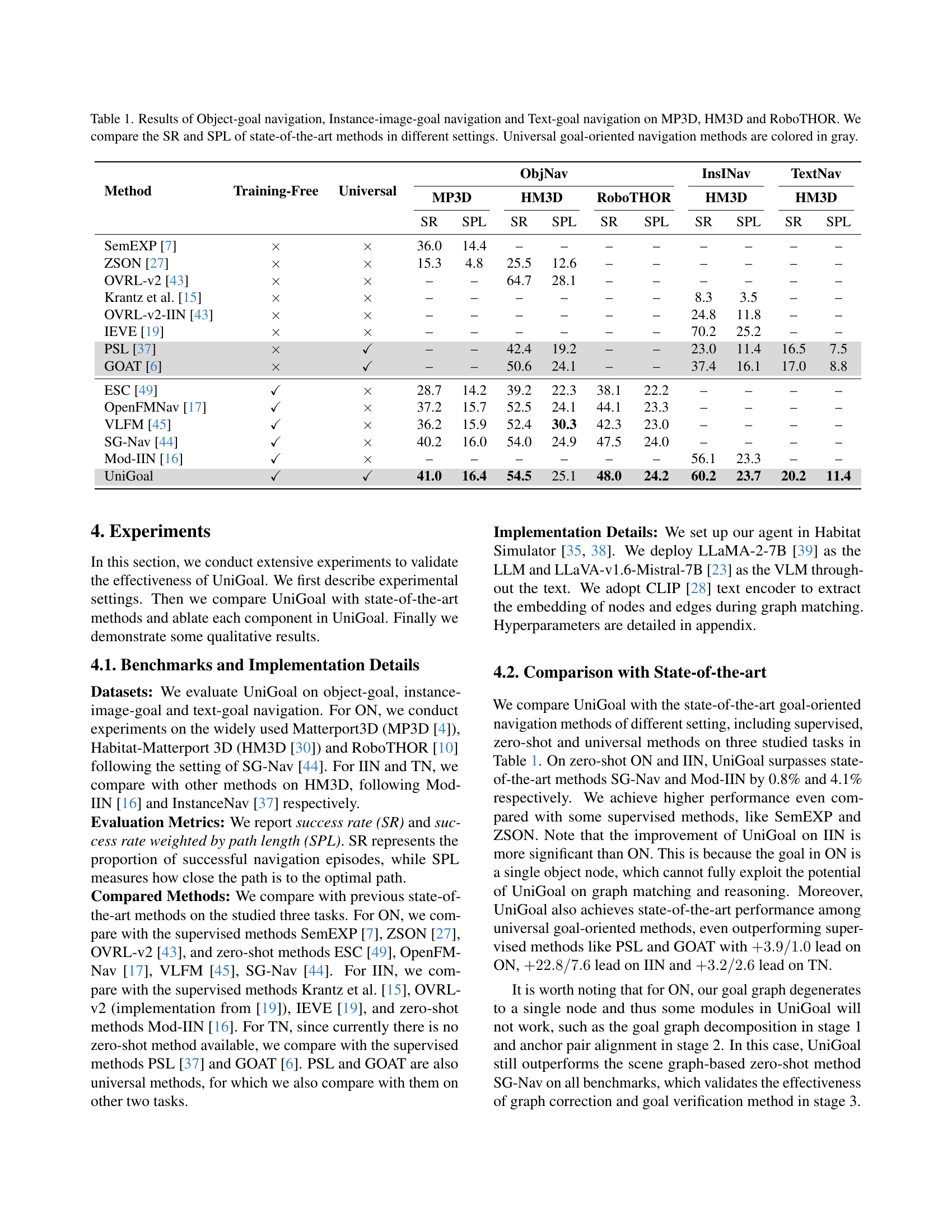
| Method | Training-Free | Universal | ObjNav | InsINav | TextNav | |||||||
| MP3D | HM3D | RoboTHOR | HM3D | HM3D | ||||||||
| SR | SPL | SR | SPL | SR | SPL | SR | SPL | SR | SPL | |||
| SemEXP [7] | 36.0 | 14.4 | – | – | – | – | – | – | – | – | ||
| ZSON [27] | 15.3 | 4.8 | 25.5 | 12.6 | – | – | – | – | – | – | ||
| OVRL-v2 [43] | – | – | 64.7 | 28.1 | – | – | – | – | – | – | ||
| Krantz et al. [15] | – | – | – | – | – | – | 8.3 | 3.5 | – | – | ||
| OVRL-v2-IIN [43] | – | – | – | – | – | – | 24.8 | 11.8 | – | – | ||
| IEVE [19] | – | – | – | – | – | – | 70.2 | 25.2 | – | – | ||
| PSL [37] | – | – | 42.4 | 19.2 | – | – | 23.0 | 11.4 | 16.5 | 7.5 | ||
| GOAT [6] | – | – | 50.6 | 24.1 | – | – | 37.4 | 16.1 | 17.0 | 8.8 | ||
| ESC [49] | 28.7 | 14.2 | 39.2 | 22.3 | 38.1 | 22.2 | – | – | – | – | ||
| OpenFMNav [17] | 37.2 | 15.7 | 52.5 | 24.1 | 44.1 | 23.3 | – | – | – | – | ||
| VLFM [45] | 36.2 | 15.9 | 52.4 | 30.3 | 42.3 | 23.0 | – | – | – | – | ||
| SG-Nav [44] | 40.2 | 16.0 | 54.0 | 24.9 | 47.5 | 24.0 | – | – | – | – | ||
| Mod-IIN [16] | – | – | – | – | – | – | 56.1 | 23.3 | – | – | ||
| UniGoal | 41.0 | 16.4 | 54.5 | 25.1 | 48.0 | 24.2 | 60.2 | 23.7 | 20.2 | 11.4 | ||
🔼 Table 1 presents a comprehensive comparison of state-of-the-art methods for three distinct goal-oriented navigation tasks: object-goal navigation (ON), instance-image goal navigation (IIN), and text-goal navigation (TN). The comparison is performed across three benchmark datasets: MP3D, HM3D, and RoboTHOR. For each method and dataset, the table reports the success rate (SR) and success rate weighted by path length (SPL). Methods designed for universal goal-oriented navigation are highlighted in gray to emphasize their broader applicability.
read the caption
Table 1: Results of Object-goal navigation, Instance-image-goal navigation and Text-goal navigation on MP3D, HM3D and RoboTHOR. We compare the SR and SPL of state-of-the-art methods in different settings. Universal goal-oriented navigation methods are colored in gray.
In-depth insights#
UniGoal Design#
While “UniGoal Design” isn’t explicitly present, the paper details a unified framework for zero-shot goal-oriented navigation. A key aspect is the uniform graph representation for diverse goals (object category, instance image, text), facilitating explicit graph-based reasoning via LLMs. This contrasts with task-specific pipelines, offering greater generalization. Another vital design element involves the online scene graph construction, capturing the agent’s evolving environment. Graph matching guides exploration, with a multi-stage policy adapting to different matching states, ranging from expanding the observed area, inferring goal location, to verifying the goal. A blacklist mechanism avoids repetitive exploration. This design aims to leverage LLMs for reasoning while maintaining structural information.
Graph Navigation#
Graph Navigation techniques leverage structured representations to enable more informed and efficient exploration. Instead of relying solely on raw sensor data, these methods construct graphs that capture spatial relationships, object categories, and semantic information. This allows the agent to reason about potential paths, identify relevant landmarks, and plan actions based on high-level understanding of the environment. By combining graph-based representations with LLMs, agents can perform complex reasoning tasks such as navigating to a specific object, following natural language instructions, or searching for a scene matching a given description.
Multi-stage Policy#
A multi-stage policy in goal-oriented navigation allows for a nuanced approach to exploration and decision-making. By breaking down the navigation task into stages, the agent can adapt its strategy based on the current state of knowledge and the degree of matching between the observed environment and the goal. Early stages might focus on broad exploration to gather information, while later stages could involve precise maneuvering towards the target once it’s been identified. The transition between stages is crucial and should be based on well-defined criteria, like matching scores or confidence levels. This staged approach enables efficient use of computational resources and can lead to more robust performance compared to a single, monolithic policy.
Robust Blacklist#
The ‘Robust Blacklist’ is a mechanism to prevent the agent from repeatedly attempting unsuccessful actions or matching to irrelevant scene elements. Blacklisting nodes/edges that consistently fail to lead to the goal prevents the agent from getting stuck in unproductive loops. This improves efficiency by focusing exploration on potentially fruitful areas. It stores world coordinates to align and infer location. By freezing unmatched parts, it encourages the agent to explore new regions. All anchor pairs will be appended to blacklist if they fail to enter into stage 3. Goal verification failure in stage 3 will move all matched pairs to blacklist, promoting more robust navigation.
Unified Model#
A ‘Unified Model’ in the context of goal-oriented navigation suggests a single framework capable of handling diverse goal types (object, image, text) without task-specific modifications. This contrasts with specialized models, offering generalization benefits. Key aspects would involve a shared representation for scenes and goals, enabling consistent reasoning. The model might leverage graph-based representations to capture structural relationships and use LLMs for high-level reasoning and decision-making. A crucial element is a multi-stage exploration strategy adapting to the level of goal matching and enabling efficient navigation in unknown environments. The model would handle visual and language-based inputs and incorporate mechanisms for error correction and robust performance across different scenarios.
More visual insights#
More on figures

🔼 UniGoal uses a graph-based approach for universal zero-shot goal-oriented navigation. Different goal types (object, image, text) are converted into a unified graph representation. The system maintains an online scene graph, and at each step, performs graph matching between the scene graph and the goal graph. The matching score determines the exploration strategy. If there’s no match, the system expands the explored area. With a partial match, it infers the goal location using graph overlap. A perfect match triggers goal verification. A blacklist prevents revisiting unsuccessfully explored areas.
read the caption
Figure 2: Framework of UniGoal. We convert different types of goals into a uniform graph representation and maintain an online scene graph. At each step, we perform graph matching between the scene graph and goal graph, where the matching score will be utilized to guide a multi-stage scene exploration policy. For different degree of matching, our exploration policy leverages LLM to exploit the graphs with different aims: first expand observed area, then infer goal location based on the overlap of graphs, and finally verify the goal. We also propose a blacklist that records unsuccessful matching to avoid repeated exploration.

🔼 Figure 3 illustrates the two main stages of the UniGoal approach. Part (a) shows Stage 2, where coordinate projection and anchor pair alignment are used to estimate the goal’s location after partial matching between scene and goal graphs. The scene graph is aligned with the goal graph using anchor pairs (matched nodes) to project the relative positions of other goal graph nodes into the scene graph’s coordinate system. Part (b) depicts Stage 3, the scene graph correction stage, activated when the scene graph is almost perfectly matched to the goal graph. The agent has almost reached the goal, but there may be small discrepancies. This stage refines the scene graph by using visual observation and graph relationship propagation, and confirms the goal location.
read the caption
Figure 3: Illustration of approach. (a) Stage 2: coordinate projection and anchor pair alignment. (b) Stage 3: scene graph correction.

🔼 This figure visualizes the multi-stage decision-making process within the UniGoal framework for goal-oriented navigation. Each row represents a different stage of the navigation process: Stage 1 (Zero Matching), Stage 2 (Partial Matching), and Stage 3 (Perfect Matching). The ‘Switch’ points indicate transitions between stages based on the graph matching score. The ‘S-Goal’ represents the long-term exploration goal dynamically generated by UniGoal at each stage using a deterministic local policy. The figure shows how the agent progresses from exploring unknown regions (Stage 1) to identifying potential goal locations via coordinate projection and anchor pair alignment (Stage 2), and finally, verifying and reaching the goal (Stage 3). The example clearly illustrates how the matching score evolves throughout the process and how the long-term goals adjust to reflect the changing understanding of the scene.
read the caption
Figure 4: Demonstration of the decision process of UniGoal. Here ‘Switch’ means the point when stage is changing. ‘S-Goal’ means the long-term goal predicted in each stage.

🔼 Figure 5 presents a visualization of UniGoal’s navigation paths across diverse environments and goal types. Green lines represent Object-goal Navigation (ON) paths, orange lines depict Instance-Image Navigation (IIN) paths, and blue lines show Text Navigation (TN) paths. The figure demonstrates UniGoal’s ability to successfully navigate to target locations using a variety of goal specifications (object category, instance image, or text description) in complex and varied scenes.
read the caption
Figure 5: Visualization of the navigation path. We visualize ON (Green), IIN (Orange) and TN (Blue) path for several scenes. UniGoal successfully navigates to the target given different types of goal and diverse environments.
More on tables
| Method | SR | SPL |
|---|---|---|
| Simplify graph matching | 54.9 | 20.7 |
| Remove blacklist mechanism | 50.6 | 17.3 |
| Simplify multi-stage exploration policy | 59.0 | 23.2 |
| Full Approach | 60.2 | 23.7 |
🔼 This table presents an ablation study evaluating the impact of different design choices within the UniGoal framework on the performance of Instance-Image goal Navigation (IIN) using the HM3D benchmark. It shows the success rate (SR) and success rate weighted by path length (SPL) achieved by UniGoal under various experimental conditions. Specifically, it examines the effects of simplifying graph matching, removing the blacklist mechanism, and simplifying the multi-stage exploration policy on the overall performance, comparing each simplified version to the complete, fully implemented UniGoal.
read the caption
Table 2: Effect of pipeline design in UniGoal on HM3D (IIN) benchmark.
| Method | Stage | SR | SPL |
|---|---|---|---|
| Replace stage 1 with FBE | 1 | 55.1 | 20.8 |
| Remove decomposition | 1 | 59.2 | 22.6 |
| Remove frontier selection | 1 | 57.4 | 22.0 |
| Simplify coordinate projection | 2 | 59.1 | 22.7 |
| Remove anchor pair alignment | 2 | 58.9 | 22.6 |
| Remove correction | 3 | 59.5 | 23.5 |
| Remove goal verification | 3 | 58.2 | 22.4 |
| Full Approach | – | 60.2 | 23.7 |
🔼 This table presents the ablation study results on the impact of different submodules within each stage of the multi-stage scene exploration process used in the UniGoal model. The experiment was conducted on the HM3D benchmark using the Instance-Image-goal Navigation (IIN) task. The table shows how the success rate (SR) and success rate weighted by path length (SPL) are affected when specific components of each stage (zero matching, partial matching, perfect matching) are removed.
read the caption
Table 3: Effect of the submodules in each stage during multi-stage scene exploration on HM3D (IIN) benchmark.
| ON | Plant | Chair | Toilet |
|---|---|---|---|
| IIN | ![[Uncaptioned image]](extracted/6278137/figures/chair.png) | ![[Uncaptioned image]](extracted/6278137/figures/sofa.png) | ![[Uncaptioned image]](extracted/6278137/figures/bed.png) |
| Chair | Sofa | Bed | |
| TN | The toilet in this image is white, surrounded by a white door, beige tiles on the walls and floor. | The bed has white bedsheets. The bedroom has a double bed, two pillows and blankets, a chair and a table. | The chair is yellow and covered with red floral patterns. There is a wooden dining table in the upper left corner. |
🔼 This table illustrates the different types of goals used in three goal-oriented navigation tasks: Object-goal Navigation (ON), Instance-Image-goal Navigation (IIN), and Text-goal Navigation (TN). For each task, an example goal is shown, with the central object highlighted in red. This visualization helps clarify the variations in goal representation across tasks, from simple object categories (ON) to more complex instance images (IIN) and detailed text descriptions (TN).
read the caption
Table 4: Illustration of goal in each task, with central objects colored in red.
Full paper#