TL;DR#
Diffusion models are great for image generation, but they’re slow🐌. Distillation speeds them up🚀, but reduces diversity📉. This paper dives into why diversity collapses in distilled models. Surprisingly, they found distilled models still understand concepts like their slower counterparts. It is confirmed after control mechanisms can be easily transferred. This raises the question: if the model understands, why is it not as diverse?
To combat diversity loss, they introduce “Diversity Distillation.” By visualizing how models evolve images through denoising, they learned that diversity hinges on the first few steps. They then suggest using the slower, more diverse model for the initial steps, then switching to the faster distilled model for the rest. This restores diversity🌈 without sacrificing speed! This work enables distillation that doesn’t sacrifice output quality.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers tackling diffusion model efficiency without sacrificing diversity. By understanding and mitigating diversity collapse during distillation, and introducing a novel approach for enhancing diversity in distilled models, it paves the way for more practical and creative applications.
Visual Insights#

🔼 Figure 1 demonstrates the core concepts of the paper: diversity and control distillation. (a) showcases a base diffusion model known for its slower speed but higher sample diversity. (b) shows a distilled model, which is faster but suffers from reduced sample diversity (mode collapse). (c) illustrates the authors’ proposed diversity distillation technique, where the first timestamp from the base model is used in conjunction with the rest of the faster distilled model’s steps to recover and even surpass the diversity of the original base model. Finally, (d) visually represents control distillation, showing how control methods (such as concept sliders) trained on the base model can be directly applied to the distilled model without requiring any retraining, demonstrating the preservation of control mechanisms during the distillation process.
read the caption
Figure 1: Diversity Distillation: (a) a base diffusion model is very slow and has good diversity (b) a distilled model is fast but sacrifices diversity (c) we show how the diversity of the base model can be distilled into the fast model by substituting the first timestamp. Control Distillation: (d) Control methods like Concept sliders can be transferred from a base model to distilled models, effectively distilling control
| Method | Concept | BaseBase | BaseDMD | BaseLCM | BaseTurbo | BaseLightning |
|---|---|---|---|---|---|---|
| Concept Sliders [8] | Age | 20.4 | 17.8 | 27.1 | 19.0 | 24.8 |
| Smile | 19.7 | 21.4 | 19.5 | 33.5 | 14.0 | |
| Muscular | 34.6 | 26.7 | 33.8 | 39.0 | 33.2 | |
| \hdashlineCustomization [26, 16] | Lego | 32.2 | 26.8 | 26.0 | 30.3 | 29.7 |
| Watercolor style | 34.3 | 31.4 | 29.6 | 27.5 | 39.2 | |
| Crayon style | 32.7 | 27.8 | 24.7 | 29.5 | 32.5 |
🔼 This table presents a quantitative analysis of the control transfer experiments. It evaluates the effectiveness of three distinct control mechanisms (Concept Sliders, Custom Diffusion, and DreamBooth) when transferred between base and distilled diffusion models. For each control mechanism, CLIP scores are calculated for various attributes before and after applying the control. The percentage change in CLIP score reflects the strength of the style transfer or attribute change achieved by the control mechanism. The table demonstrates that control mechanisms trained on base models generally maintain their effectiveness when applied to distilled models, showcasing the preservation of concept representations despite the model weight modifications that occur during distillation. Minor variations in effectiveness across different distillation techniques are observed.
read the caption
Table 1: We show the percentage change in CLIP score from the original image and the LoRA edited image. Higher values indicate stronger attribute change or style transfer. Control effectiveness is largely preserved when transferring from base to different distilled models, with only minor variations across distillation techniques.
In-depth insights#
Distill+Control#
The notion of ‘Distill+Control’ suggests a combined strategy in diffusion models, aiming for both efficient generation and precise manipulation. Distillation focuses on accelerating the image creation process, potentially by reducing the number of required denoising steps, model size, or computational complexity. However, distillation often leads to a reduction in diversity and control. Therefore, Control mechanisms are crucial to preserve or even enhance the ability to guide the generation process towards specific attributes, styles, or semantic content. Techniques like Concept Sliders, LoRA, or attention modulation can be incorporated to regain fine-grained control over the distilled model. The challenge lies in effectively transferring these control mechanisms from larger, more complex base models to smaller, distilled counterparts without significant retraining or performance degradation. A successful ‘Distill+Control’ approach would achieve a balance between efficiency and expressiveness, enabling fast and controllable image synthesis.
DT-Viz: Why?#
DT-Viz, or Diffusion Target Visualization, likely serves as a crucial analytical tool within the research paper to understand and debug the inner workings of diffusion models. It allows researchers to peek inside the ‘black box’ of these models, particularly focusing on the diversity reduction observed in distilled diffusion models. Without DT-Viz, it would be difficult to pinpoint the exact mechanisms causing mode collapse, as it enables visualizing intermediate stages, revealing what the model ’thinks’ the final image will be at each step. This aids in identifying generation artifacts and inconsistencies, such as the model initially conceptualizing a cat but later retracting it, resulting in outputs lacking elements present in the prompt. By comparing visualizations from base and distilled models, DT-Viz provides a direct comparison of image structure development, highlighting how distilled models often commit to a final image almost immediately, while base models gradually refine across multiple steps. This insight informs diversity-preserving distillation strategies, demonstrating the significant role of early timesteps in establishing output diversity. Essentially, DT-Viz acts as a microscope, providing researchers with the necessary detail to address the complex relationship between efficiency and diversity in diffusion models.
Hybrid Inference#
Hybrid inference as a conceptual framework presents an intriguing approach to balancing computational efficiency and generative diversity in diffusion models. The core idea revolves around strategically combining the strengths of different model architectures, leveraging the base model for initial, diversity-critical timesteps and transitioning to a distilled model for efficient refinement. This method directly addresses the mode collapse issue often observed in distilled models, where diversity is sacrificed for speed. By employing the base model in the initial stages, the hybrid approach aims to capture a broader range of structural compositions, which are then refined by the computationally lighter distilled model. The success of hybrid inference hinges on the compatibility of concept representations between the base and distilled models, ensuring a seamless transition without introducing artifacts or inconsistencies. Further research into adaptive inference strategies, dynamically adjusting the transition point based on prompt characteristics, could further optimize the quality-efficiency trade-off.
Early Steps Matter#
Early timesteps in diffusion models exert a disproportionate influence on the final output’s diversity. This suggests that the initial stages of the denoising process are critical for establishing the overall structure and composition of the generated image. Distilled models compress this behavior, leading to mode collapse. The initial steps act as a blueprint, determining the overall style, structure, and conceptual elements. If this early blueprint lacks variability (as is the case in distilled models), the final output will inevitably be less diverse. Focusing on enhancing the diversity and variability of these initial steps becomes paramount to overcome limitations of distilled diffusion models.
Beyond Diversity#
Moving “beyond diversity” in research necessitates a shift from simply generating diverse outputs to understanding and controlling the underlying mechanisms that enable diversity. This involves delving into the latent space of generative models to identify and manipulate factors influencing variety. It also calls for developing better metrics that quantify not just visual differences but also semantic diversity – the range of concepts and compositions a model can produce. Furthermore, research should explore how to tailor diversity to specific applications, perhaps through adaptive inference strategies or by fine-tuning models to prioritize particular types of variation. Ultimately, going beyond diversity means harnessing diversity as a tool for creativity, exploration, and robustness, rather than merely treating it as an end in itself. It is about making diffusion models more trustworthy, transparent, and robust.
More visual insights#
More on figures

🔼 Figure 2 visually demonstrates the concept transferability between base and distilled diffusion models. It shows that customization adapters (like Custom Diffusion and DreamBooth, which alter specific visual aspects of generated images) and concept control adapters (like Concept Sliders, which provide granular control over features) trained on a base SDXL model can be directly applied to various distilled models (SDXL-Turbo, SDXL-Lightning, SDXL-LCM, SDXL-DMD) without any additional training. The successful transfer across different distilled models highlights that the underlying concept representations remain intact during the distillation process, despite changes in model weights.
read the caption
Figure 2: Customization adapters (custom diffusion [16] and dreambooth [26]) and concept control adapters (concept sliders [8]) trained on SDXL-base model can be transferred to all the distilled modeled without any additional finetuning. This demonstrates that concept representations are preserved through the diffusion distillation process

🔼 This figure showcases the capabilities of Diffusion Target (DT) Visualization, a novel technique introduced in the paper to analyze diffusion model’s decision-making process during image generation. It uses the prompt “Image of dog and cat sitting on sofa”. While the final generated image shows only a dog, DT-Visualization at an intermediate timestep (T=10) reveals that the model initially considered generating a cat face, indicated by a red box around the cat face in the visualization. This cat face element is, however, absent in the final generated image. This demonstrates the dynamic nature of diffusion models’ generation process where initially considered elements can be discarded in later steps.
read the caption
Figure 3: DT-Visualization reveals generation inconsistencies. When prompted with “Image of dog and cat sitting on sofa,” the SDXL model produces an image with only a dog. However, DT-Visualization at T=10𝑇10T=10italic_T = 10 shows the model initially conceptualizing a cat face (red box) before abandoning this element in the final generation. This demonstrates how diffusion models can discard semantic elements during the denoising process.

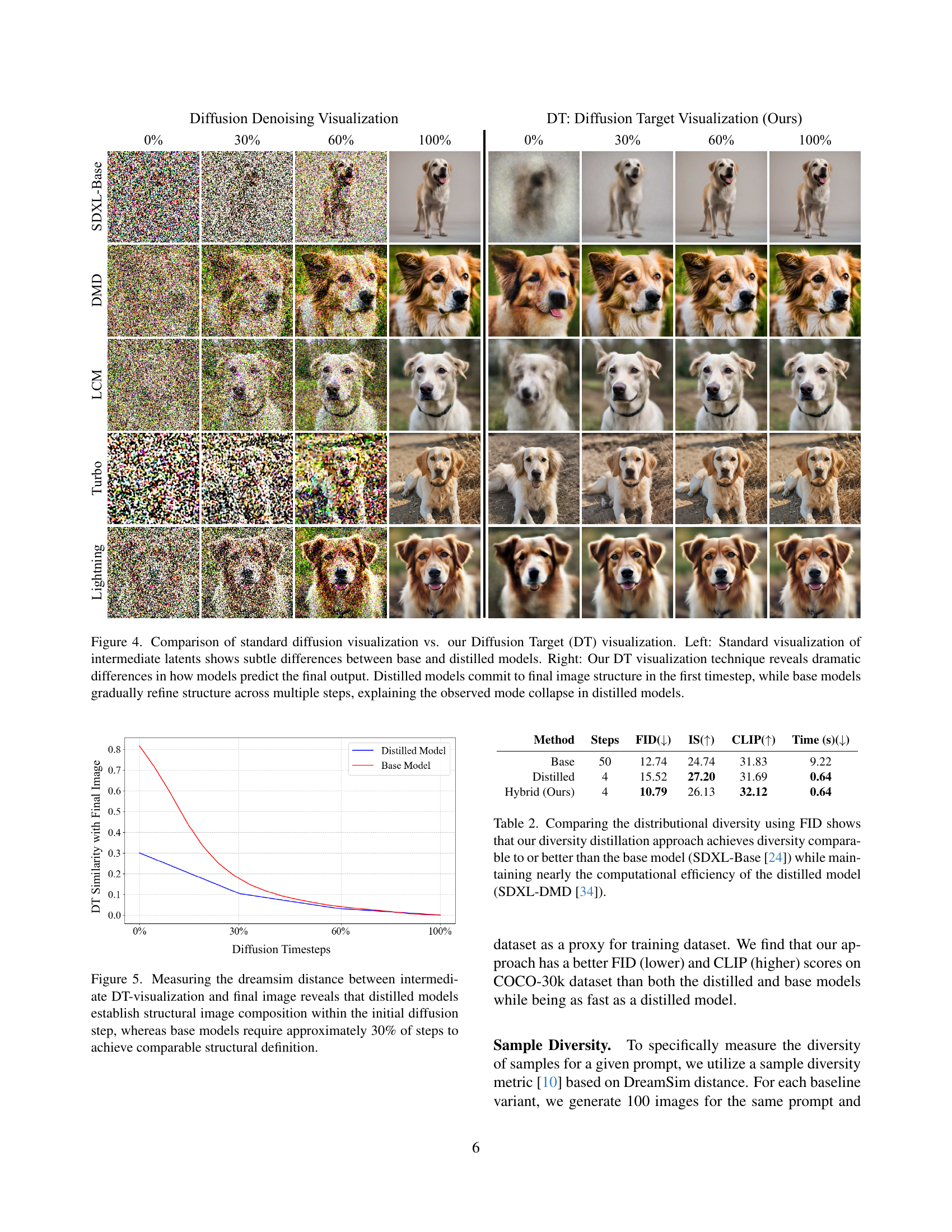
🔼 This figure compares standard diffusion visualization with the novel Diffusion Target (DT) visualization technique. The left side shows standard visualizations of intermediate latent representations during the diffusion process for both base and distilled models. These standard visualizations reveal only subtle differences between the base and distilled models. The right side shows the DT visualization, which predicts the final image at each timestep without completing the full denoising process. This reveals a dramatic difference in how the models predict the final output. Distilled models commit to the final image structure very early in the process, after just the first timestep. In contrast, base models gradually refine the structure across many timesteps. This difference in generation behavior explains why distilled models exhibit mode collapse (reduced diversity) compared to base models.
read the caption
Figure 4: Comparison of standard diffusion visualization vs. our Diffusion Target (DT) visualization. Left: Standard visualization of intermediate latents shows subtle differences between base and distilled models. Right: Our DT visualization technique reveals dramatic differences in how models predict the final output. Distilled models commit to final image structure in the first timestep, while base models gradually refine structure across multiple steps, explaining the observed mode collapse in distilled models.

🔼 The figure shows a graph plotting the DreamSim distance between intermediate DT-visualizations and final images for both base and distilled diffusion models. The x-axis represents the percentage of diffusion timesteps completed, while the y-axis represents the DreamSim distance. The graph reveals that distilled models establish significant structural composition very early in the process, usually within the first 10%, while base models require approximately 30% of total timesteps for similar structural definition. This supports the study’s hypothesis that early timesteps play a disproportionate role in determining output diversity.
read the caption
Figure 5: Measuring the dreamsim distance between intermediate DT-visualization and final image reveals that distilled models establish structural image composition within the initial diffusion step, whereas base models require approximately 30% of steps to achieve comparable structural definition.

🔼 This figure visually compares the diversity of image generation results from three different models: a base diffusion model, a distilled model, and a hybrid model using diversity distillation. Each row represents a different prompt, and within each row, three images are shown—each generated from the same prompt but with different random seeds. The base model produces diverse outputs, showing substantial variation between the three images. The distilled model, in contrast, shows very similar outputs across different random seeds, demonstrating a loss in diversity. The diversity distillation approach generates images with diversity comparable to the base model, yet maintaining the speed advantages of the distilled model. This illustrates how the proposed method effectively addresses the mode collapse issue often observed in distilled diffusion models, preserving both computational efficiency and sample diversity.
read the caption
Figure 6: Visual comparison of generation diversity. Each row shows three different generations (different random seeds) for the same prompt using: (left) base model, (middle) distilled model, and (right) our diversity distillation approach. Note how the distilled model produces visually similar outputs across seeds, while our approach restores diversity comparable to the base model while maintaining similar inference speed as distilled model.

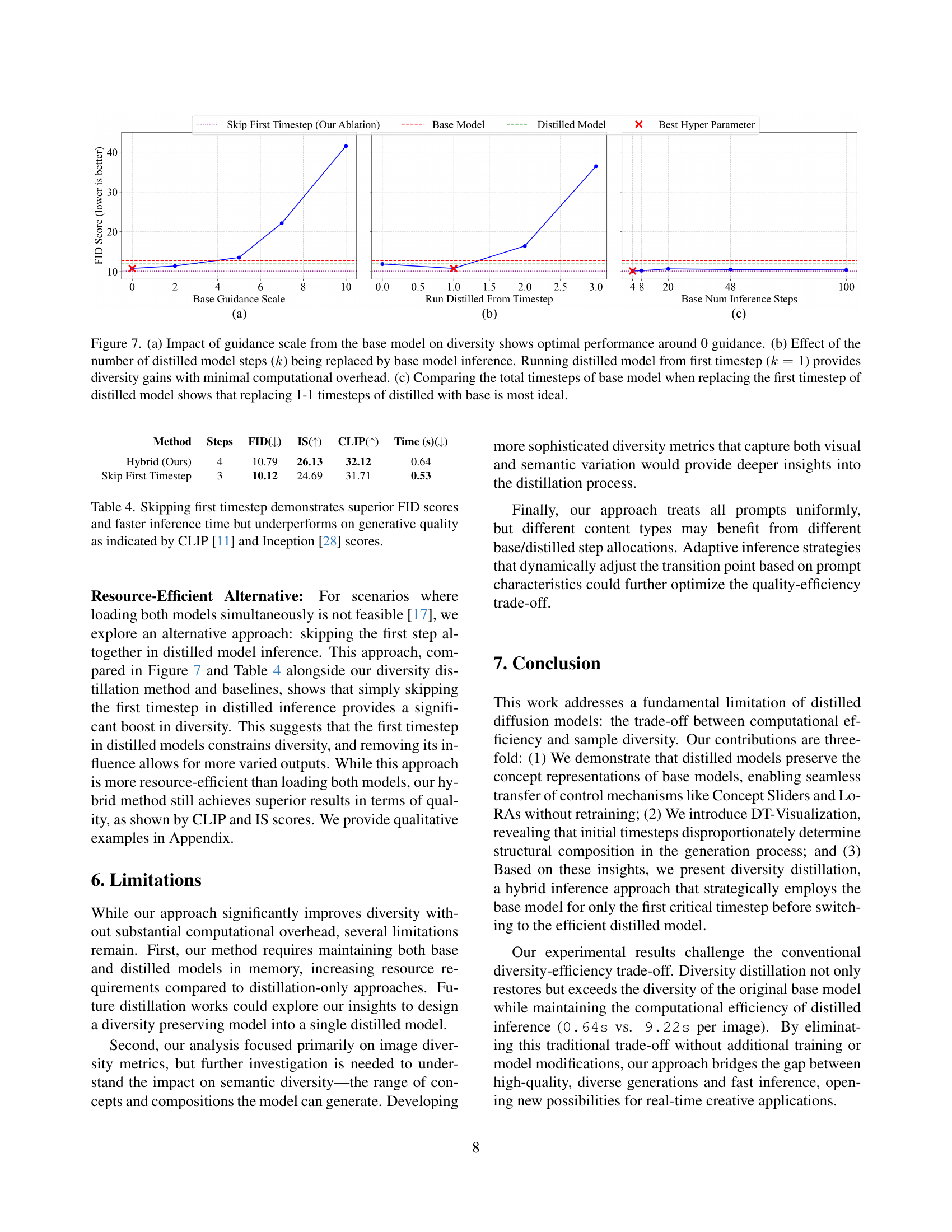
🔼 This figure analyzes the impact of different hyperparameters on the diversity and efficiency of a hybrid inference approach for diffusion models. Panel (a) demonstrates that using minimal guidance from the base model is optimal for maintaining diversity. Panel (b) shows that using the base model for even just the first timestep significantly improves diversity with minimal computational overhead. Panel (c) reveals the optimal balance between diversity enhancement and computational efficiency occurs when replacing one timestep from the distilled model with one timestep from the base model.
read the caption
Figure 7: (a) Impact of guidance scale from the base model on diversity shows optimal performance around 0 guidance. (b) Effect of the number of distilled model steps (k𝑘kitalic_k) being replaced by base model inference. Running distilled model from first timestep (k=1𝑘1k=1italic_k = 1) provides diversity gains with minimal computational overhead. (c) Comparing the total timesteps of base model when replacing the first timestep of distilled model shows that replacing 1-1 timesteps of distilled with base is most ideal.

🔼 This figure demonstrates that control mechanisms, such as Custom Diffusion and Concept Sliders, trained on distilled diffusion models can be successfully applied to base diffusion models without any further training. This experiment verifies that the fundamental conceptual representations within the models remain consistent even after the distillation process, highlighting the preservation of these representations regardless of the model’s modifications. It also notes that LoRA transfer experiments were not conducted for the LCM architecture due to difficulties in training.
read the caption
Figure A.1: Reverse Control Transfer: Control mechanisms (Custom Diffusion [16] and Concept Sliders [8]) trained on distilled models can be effectively transferred to base models without retraining. This bidirectional transferability confirms that concept representations are preserved during diffusion distillation. Note: LCM LoRA transfers were excluded due to training difficulties with the LCM architecture.

🔼 This figure compares the image generation diversity of three different models using the same prompt: ‘image of a toy.’ The leftmost column displays images generated by the base diffusion model, demonstrating a wide variety of toy types and styles. The middle column shows images from the distilled model, revealing significantly less diversity in both the type of toys and their overall appearance. The images are structurally similar, demonstrating mode collapse. The rightmost column showcases the results of the proposed diversity distillation technique. The diversity of the generated images is substantially improved compared to the distilled model, showing similar variety to the base model, indicating the effectiveness of this method in mitigating mode collapse while maintaining computational efficiency.
read the caption
Figure B.1: Comparison of generation diversity across different models for the prompt ”image of a toy.” Each image shows different seeds for the same model. Note the structural similarity in distilled model outputs compared to the greater variation in base model and our hybrid approach.

🔼 This figure compares the image generation diversity of three different models when generating images of flowers. The left column shows the output of the base diffusion model; the middle column shows the output of a distilled model; and the right column shows the output of the proposed diversity distillation method. Each column displays multiple images generated using different random seeds, making it possible to compare the diversity of outputs across different random seeds. The comparison demonstrates that the distilled model shows less diversity compared to the base model, while the proposed method is able to recover the diversity of the base model while still retaining the speed advantage of the distilled model.
read the caption
Figure B.2: Comparison of generation diversity for ”image of a flower” Distilled models (middle column) produce structurally similar outputs across different seeds, while our approach (right column) restores diversity comparable to the base model (left column) while maintaining the speed advantage of distilled models.

🔼 This figure compares the image generation diversity of three different approaches: a base diffusion model, a distilled model, and a hybrid approach combining both. The ‘city street’ prompt was used to generate multiple images using each method with varying random seeds. The base model (left column) shows a wide range of diverse city street scenes. The distilled model (middle column) demonstrates significantly reduced diversity, generating very similar-looking images across different seeds, which indicates mode collapse. The hybrid approach (right column), proposed by the authors, combines both models strategically, effectively restoring a level of diversity comparable to the base model while retaining the speed benefits of the distilled model.
read the caption
Figure B.3: Additional diversity comparison for ”city street”Distilled models (middle column) produce structurally similar outputs across different seeds, while our approach (right column) restores diversity comparable to the base model (left column) while maintaining the speed advantage of distilled models.

🔼 Figure B.4 visually compares the diversity of images generated from a base diffusion model, a distilled diffusion model, and the proposed diversity distillation approach. The prompt used was ‘picture of a monster’. The left column displays the base model’s output across multiple generation runs (different random seeds). Noticeable variation in monster designs is present. The middle column shows the distilled model’s output. Here, the diversity is significantly reduced; the generated monsters are very similar across the multiple runs, indicating mode collapse. The right column presents the results from the proposed diversity distillation method, demonstrating a significant improvement in diversity. The generated monsters are much more varied, comparable to the base model, but with the computational efficiency of the distilled model. This figure highlights the effectiveness of the proposed hybrid method in overcoming mode collapse and improving the diversity of generated images in distilled diffusion models.
read the caption
Figure B.4: Diversity comparison for abstract prompt: ”picture of a monster” Distilled models (middle column) produce structurally similar outputs across different seeds, while our approach (right column) restores diversity comparable to the base model (left column) while maintaining the speed advantage of distilled models.

🔼 This figure shows a comparison of the Diffusion Target (DT) Visualization between the SDXL-Base and SDXL-DMD models. DT-Visualization is a technique to visualize what a diffusion model predicts at any intermediate timestep without actually completing the generation process. The visualization reveals that the SDXL-DMD model, which is a distilled model, commits to the final structural composition very early in the generation process, typically within the first timestep. In contrast, the SDXL-Base model, which is a more complex model, gradually develops the image structure over multiple steps. This difference in behavior is consistent across various types of images and prompts, demonstrating a key difference between base and distilled diffusion models. The key takeaway is that the fast generation of the distilled model comes at the cost of the diversity and variability which is achieved by the gradual refinement of the base model.
read the caption
Figure C.1: Extended DT-Visualization comparison between SDXL-Base and SDXL-DMD for the prompt. The visualization reveals that DMD commits to final structural composition within the first timestep, while Base gradually develops structure across multiple steps. This pattern is consistent across different content types and prompts.

🔼 This figure shows a comparison of Diffusion Target (DT) visualizations for SDXL-Base and SDXL-DMD models. DT-Visualization is a technique that reveals what a model predicts the final image will look like at any given timestep during the generation process, without actually completing the entire generation. The comparison highlights a key difference: the SDXL-DMD (distilled) model establishes the fundamental structure of the image almost immediately in the first timestep. In contrast, the SDXL-Base (base) model develops its structure gradually over multiple timesteps. This difference is consistent regardless of the prompt’s content, demonstrating how the distillation process leads to a loss of diversity in the resulting generated images.
read the caption
Figure C.2: Extended DT-Visualization comparison between SDXL-Base and SDXL-DMD for the prompt. The visualization reveals that DMD commits to final structural composition within the first timestep, while Base gradually develops structure across multiple steps. This pattern is consistent across different content types and prompts
More on tables
| Method | Steps | FID() | IS() | CLIP() | Time (s)() |
|---|---|---|---|---|---|
| Base | 50 | 12.74 | 24.74 | 31.83 | 9.22 |
| Distilled | 4 | 15.52 | 27.20 | 31.69 | 0.64 |
| Hybrid (Ours) | 4 | 10.79 | 26.13 | 32.12 | 0.64 |
🔼 This table presents a quantitative comparison of distributional diversity, measured using the Fréchet Inception Distance (FID), across different models: a base model (SDXL-Base), a distilled model (SDXL-DMD), and the proposed diversity distillation approach. It compares the FID scores, which indicate how well the generated image distribution matches the real-world image distribution (lower is better), along with other metrics such as Inception Score (IS, higher is better) and CLIP score (higher is better). The results demonstrate that the diversity distillation approach achieves comparable or superior diversity to the base model while maintaining the significant speed advantage of the distilled model.
read the caption
Table 2: Comparing the distributional diversity using FID shows that our diversity distillation approach achieves diversity comparable to or better than the base model (SDXL-Base [24]) while maintaining nearly the computational efficiency of the distilled model (SDXL-DMD [34]).
| Prompt | Base | Distilled | Hybrid (Ours) |
|---|---|---|---|
| Sunset beach | 0.396 | 0.271 | 0.373 |
| Cute puppy | 0.233 | 0.199 | 0.265 |
| Futuristic city | 0.237 | 0.198 | 0.283 |
| Person | 0.484 | 0.347 | 0.461 |
| Van Gogh art | 0.337 | 0.305 | 0.366 |
| \hdashlineAverage | 0.337 | 0.264 | 0.350 |
🔼 This table presents a quantitative analysis of sample diversity. Sample diversity is calculated using the average pairwise DreamSim distance, a metric where higher values indicate greater diversity. The table compares the sample diversity achieved by three different methods: the base diffusion model, a distilled diffusion model, and a hybrid approach proposed in the paper (Diversity Distillation). The results show that the distilled model suffers from significantly reduced diversity compared to the base model. Notably, the hybrid approach not only recovers the lost diversity but even surpasses the base model’s diversity.
read the caption
Table 3: Sample diversity measured by average pairwise DreamSim distance (higher is more diverse). Our hybrid approach not only restores diversity lost during distillation but exceeds the diversity of the base model.
| Method | Steps | FID() | IS() | CLIP() | Time (s)() |
|---|---|---|---|---|---|
| Hybrid (Ours) | 4 | 10.79 | 26.13 | 32.12 | 0.64 |
| Skip First Timestep | 3 | 10.12 | 24.69 | 31.71 | 0.53 |
🔼 Table 4 presents a quantitative comparison of different methods for generating images using diffusion models. It compares a standard approach, a method where the first timestep is skipped, and the authors’ proposed hybrid method. The metrics used are FID (Frechet Inception Distance), which measures the similarity between generated images and real images (lower is better), IS (Inception Score), and CLIP score, which assesses the quality and diversity of generated images (higher is better). The table also shows the inference time for each method. The results show that skipping the first timestep improves FID score and inference speed, but both CLIP and Inception scores indicate a reduction in the overall quality of the generated images. The authors’ hybrid method achieves a balance between speed and image quality, offering a superior performance compared to the other methods.
read the caption
Table 4: Skipping first timestep demonstrates superior FID scores and faster inference time but underperforms on generative quality as indicated by CLIP [11] and Inception [28] scores.
Full paper#