TL;DR#
Current image generation methods often lack explicit reasoning, struggling with complex scenes. The paper addresses this by introducing Generation Chain-of-Thought (GoT), a novel paradigm that enables generation and editing through an explicit language reasoning process. This approach transforms conventional text-to-image methods into a reasoning-guided framework that analyzes semantic relationships and spatial arrangements to enhance outputs.
The authors define the formulation of GoT and construct large-scale GoT datasets with detailed reasoning chains capturing semantic-spatial relationships. To leverage GoT, they implement a unified framework that integrates a reasoning chain generation with an end-to-end diffusion model enhanced by a novel Semantic-Spatial Guidance Module. Experiments show the framework achieves excellent performance on both generation and editing tasks.
Key Takeaways#
Why does it matter?#
This paper is important as it pioneers reasoning-driven visual generation and editing, paving the way for more intuitive and controllable image creation. It offers a novel framework and a large-scale dataset that can significantly impact future research in multimodal AI and visual content generation.
Visual Insights#

🔼 Figure 1 illustrates the Generation Chain-of-Thought (GoT) process, a novel approach for image generation and editing. The figure showcases how input prompts are transformed into detailed reasoning chains, incorporating spatial coordinates. This structured reasoning guides both the generation of vivid images and precise, localized editing. The top panel demonstrates semantically-grounded visual generation; the middle shows controllable interactive generation; and the bottom demonstrates localized image editing. The central role of the reasoning chain in unifying spatial understanding across different visual tasks is highlighted.
read the caption
Figure 1: Generation Chain-of-Thought (GoT) with Semantic-Spatial Reasoning. Our approach transforms input prompts into explicit reasoning chains with coordinates (middle), which guides vivid image generation and precise editing (right). This reasoning-based generation paradigm unifies spatial understanding across visual tasks: semantically-grounded visual generation (top), controllable interactive generation (middle), and localized image editing (bottom).
| Method | Architecture | Overall | Single Obj. | Two Obj. | Counting | Colors | Position | Attr. Binding |
| Frozen Text Encoder Mapping Methods | ||||||||
| SDv1.5 [37] | Unet+CLIP | 0.43 | 0.97 | 0.38 | 0.35 | 0.76 | 0.04 | 0.06 |
| SDv2.1 [37] | Unet+CLIP | 0.50 | 0.98 | 0.51 | 0.44 | 0.85 | 0.07 | 0.17 |
| SD-XL [32] | Unet+CLIP | 0.55 | 0.98 | 0.74 | 0.39 | 0.85 | 0.15 | 0.23 |
| DALLE-2 [36] | Unet+CLIP | 0.52 | 0.94 | 0.66 | 0.49 | 0.77 | 0.10 | 0.19 |
| SD3 (d=24) [6] | MMDIT+CLIP+T5 | 0.62 | 0.98 | 0.74 | 0.63 | 0.67 | 0.34 | 0.36 |
| LLMs/MLLMs Enhanced Methods | ||||||||
| LlamaGen [42] | Autoregressive | 0.32 | 0.71 | 0.34 | 0.21 | 0.58 | 0.07 | 0.04 |
| Chameleon [44] | Autoregressive | 0.39 | - | - | - | - | - | - |
| LWM [26] | Autoregressive | 0.47 | 0.93 | 0.41 | 0.46 | 0.79 | 0.09 | 0.15 |
| SEED-X [13] | Unet+Llama | 0.49 | 0.97 | 0.58 | 0.26 | 0.80 | 0.19 | 0.14 |
| Emu3-Gen [47] | Autoregressive | 0.54 | 0.98 | 0.71 | 0.34 | 0.81 | 0.17 | 0.21 |
| Janus [50] | Autoregressive | 0.61 | 0.97 | 0.68 | 0.30 | 0.84 | 0.46 | 0.42 |
| JanusFlow [27] | Autoregressive | 0.63 | 0.97 | 0.59 | 0.45 | 0.83 | 0.53 | 0.42 |
| GoT Framework | Unet+Qwen2.5-VL | 0.64 | 0.99 | 0.69 | 0.67 | 0.85 | 0.34 | 0.27 |
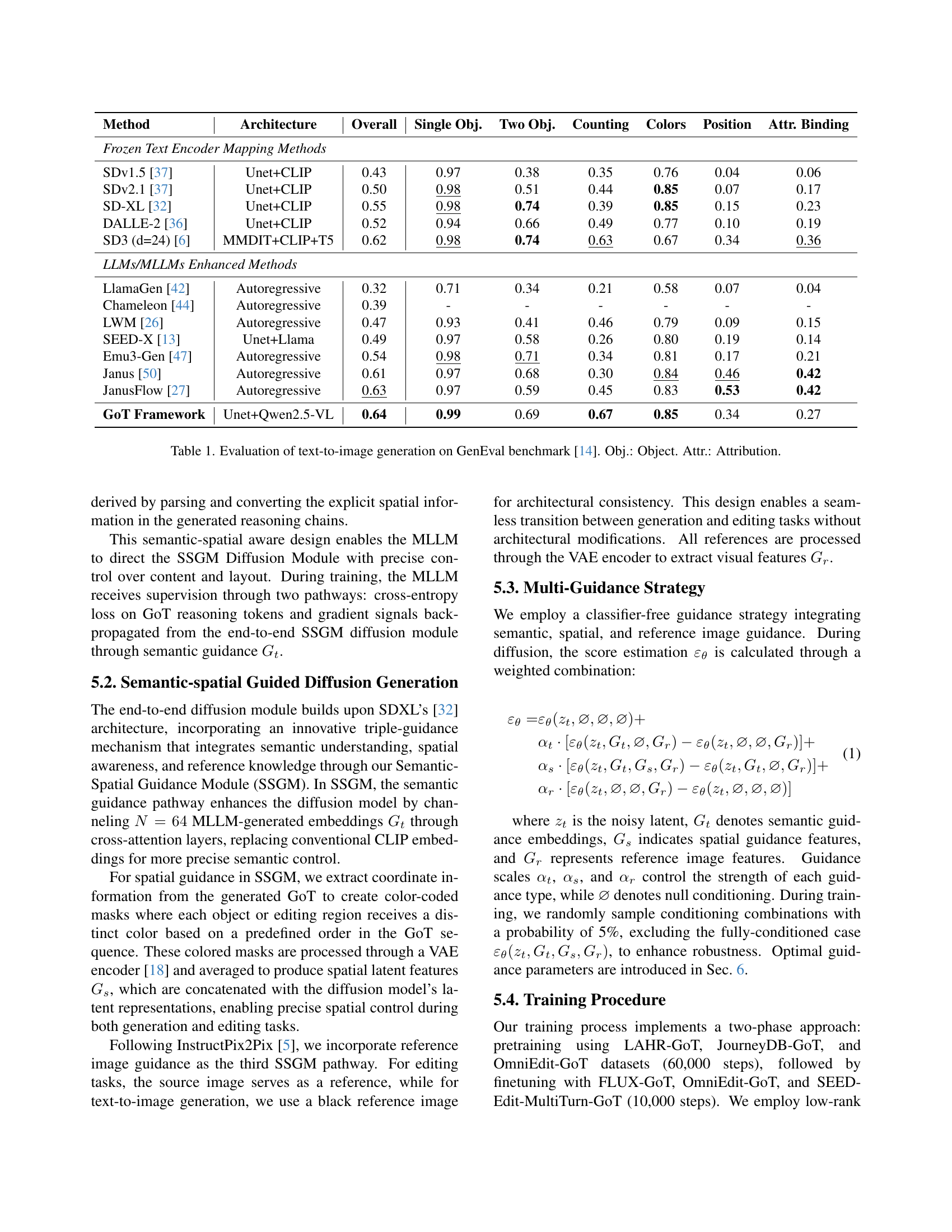
🔼 This table presents a quantitative evaluation of various text-to-image generation models on the GenEval benchmark. It compares the performance of different models across several aspects of image generation, including overall image quality, the accuracy of generating single and multiple objects, the ability to correctly count objects in the scene, and the accuracy in depicting colors and object positions. The models are evaluated based on how well they accurately represent object attributes and the relationships between objects. The results highlight the strengths and weaknesses of different methods in producing high-quality and accurate images from textual descriptions.
read the caption
Table 1: Evaluation of text-to-image generation on GenEval benchmark [14]. Obj.: Object. Attr.: Attribution.
In-depth insights#
GoT Formulation#
While “GoT Formulation” wasn’t explicitly a section, the research inherently formulates a novel approach to visual generation and editing. This involves translating textual prompts into structured, explicit reasoning chains that guide the generation or editing process. The key insight lies in decomposing complex visual tasks into a sequence of simpler, spatially-aware operations. This involves analyzing the semantic relationships between objects in a scene, determining their spatial arrangements using coordinate information, and then using this structured information to guide the image generation or editing process. Traditional methods often lack this explicit reasoning, leading to difficulties in controlling object placement, attributes, and inter-object relationships. GoT’s formulation also necessitates a new type of dataset: one that includes detailed reasoning chains alongside images, capturing both semantic and spatial information. This formulation highlights the importance of integrating reasoning capabilities into visual generation, moving beyond simple text-to-image translation.
Semantic-Spatial GoT#
The concept of “Semantic-Spatial GoT” likely refers to a Generation Chain-of-Thought approach that integrates both semantic understanding and spatial reasoning for visual generation/editing. Traditional GoT focuses on step-by-step reasoning, while the Semantic-Spatial GoT extends this by incorporating spatial information (object locations/relationships). This fusion enables more precise control over the generated image’s content and layout. The semantic aspect ensures objects are logically related, and the spatial aspect grounds these relationships in specific locations. By encoding both semantic and spatial information into the reasoning chain, the model gains a deeper understanding of the desired scene composition. That is, instead of relying solely on textual prompts, the model explicitly reasons about where objects should be placed/how they relate to each other. This approach is particularly useful in complex scenes with multiple objects or when precise spatial arrangements are needed. It could involve techniques for parsing spatial descriptions, encoding locations, and ensuring consistency between spatial and semantic representations.
MLLM+Diffusion#
MLLMs combined with diffusion models represent a burgeoning area in multimodal AI research. This synergy seeks to leverage the strengths of both architectures. MLLMs excel at reasoning and contextual understanding, providing high-level semantic guidance. Diffusion models offer unparalleled fidelity in image generation, producing photorealistic outputs. Challenges involve effectively channeling MLLM’s reasoning into the diffusion process, ensuring generated visuals align with complex, reasoned prompts. Techniques like cross-attention manipulation and spatial guidance modules are crucial for seamless integration, achieving reasoning-driven, high-quality image synthesis.
Interactive GoT#
Interactive visual generation through the Generation Chain-of-Thought (GoT) framework represents a significant advancement in AI-driven image creation. It allows users to modify text and bounding box positions, enabling iterative refinement of generated content. This interactive approach bridges the gap between human intention and AI execution, providing a more intuitive and controllable creative process. This paradigm shift offers unprecedented flexibility and precision, enabling users to steer the generation process according to their specific preferences, leading to highly customized and aligned visual outputs. This innovation marks a move towards more collaborative human-AI creation workflows, enhancing creative expression and problem-solving capabilities within image synthesis.
Reasoning Limits#
While large language models exhibit impressive reasoning, inherent limits remain. Over-reliance on superficial patterns hinders true understanding, leading to errors when faced with novel situations or adversarial inputs. Context window limitations restrict the amount of information considered, impacting performance on tasks requiring long-range dependencies. Furthermore, models struggle with common-sense reasoning and physical laws, often generating outputs inconsistent with real-world knowledge. Addressing these limits requires developing architectures that promote deeper semantic understanding, improving context handling, and incorporating external knowledge sources. Overcoming these limitations are crucial for reliable and robust reasoning.
More visual insights#
More on figures

🔼 This figure details the process of constructing the GoT (Generation Chain-of-Thought) dataset, which is crucial for training the model. The left side illustrates the pipeline for text-to-image generation. Starting from a prompt, the pipeline uses Qwen2-VL [46] and Qwen2.5 [51] to generate detailed GoT annotations. These annotations include semantic content describing the scene and spatial coordinates precisely locating objects within the image. The right side shows the pipeline for image editing. This pipeline takes a source image, a target image, and an editing instruction as input. Again, using Qwen2-VL [46] and Qwen2.5 [51], entity-aware reasoning GoTs are generated with precise spatial grounding to guide the editing process. Both pipelines ensure the generated GoTs capture comprehensive semantic-spatial relationships.
read the caption
Figure 2: GoT Dataset Construction Process. Left: Text-to-image GoT annotation pipeline that labels detailed GoT with semantic content and spatial coordinates. Right: Editing GoT annotation pipeline that processes source image, target image, and instruction to generate entity-aware reasoning GoT with precise spatial grounding. Both pipelines leverage Qwen2-VL [46] and Qwen2.5 [51] models for various stages of the annotation process.

🔼 Figure 3 illustrates the GoT framework, a unified model for both text-to-image generation and image editing. The left panel shows the overall framework architecture, highlighting the integration of a multimodal large language model (MLLM) for reasoning and a diffusion model for image generation, guided by semantic and spatial information. The MLLM generates reasoning chains, which are then used by the SSGM (Semantic-Spatial Guidance Module) to condition the diffusion model. The right panel details the SSGM, which incorporates three types of guidance: spatial layout guidance (Gs), reference image guidance (Gr), and semantic guidance (Gt), to produce an image with precise content and spatial arrangement.
read the caption
Figure 3: GoT Framework with Semantic-Spatial Guidance. Left: Our dual-task framework handling both text-to-image generation (T2I) and image editing. Right: The SSGM Diffusion Module, which combines spatial layouts guidance Gssubscript𝐺𝑠G_{s}italic_G start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPT, reference image guidance Grsubscript𝐺𝑟G_{r}italic_G start_POSTSUBSCRIPT italic_r end_POSTSUBSCRIPT, and semantic guidance Gtsubscript𝐺𝑡G_{t}italic_G start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT to generate the final image with precise content and spatial control.

🔼 This figure showcases example images generated by the GoT model. The images demonstrate the model’s ability to accurately interpret and translate textual descriptions into realistic and aesthetically pleasing visuals. The GoT framework’s capacity to reason about spatial relationships and object placement is evident in the precise positioning and arrangement of elements within each scene. The high degree of alignment between the generated images and the input captions highlights the model’s effectiveness in generating visually coherent and faithful representations of the intended concepts.
read the caption
Figure 4: Text-to-Image samples generated by our model. The GoT framework can plan object placement based on the input caption and generate highly aligned and aesthetic images accordingly.

🔼 This figure showcases the interactive capabilities of the GoT framework. Users can modify the generated image by adjusting the GoT’s description and bounding box coordinates. Three specific interactive editing operations are demonstrated: 1) replacing one object with another; 2) repositioning objects within the scene; and 3) altering an object’s attributes (e.g., color). The examples highlight the framework’s ability to maintain scene coherence while precisely implementing user-specified changes.
read the caption
Figure 5: Samples on interactive generation with GoT framework. By modifying GoT content (description and bounding box position), user can customize their text-to-image process with: 1. Object replacement 2. Object position adjustment 3. Object attribute modification.

🔼 Figure 6 showcases example results from image editing tasks, highlighting the GoT framework’s ability to handle complex edits requiring both semantic understanding and precise spatial reasoning. The examples demonstrate successful modifications of image content based on user instructions, such as removing objects, adding objects, or changing object attributes. Red bounding boxes overlaid on the images indicate the spatial regions identified by the multimodal large language model (MLLM) as relevant to the editing instructions. This visualization serves to illustrate the framework’s capacity for precise control over visual elements and its superior performance compared to methods lacking explicit reasoning and spatial awareness.
read the caption
Figure 6: Qualitative results of image editing. Our GoT framework demonstrates superior performance in settings that require semantic-spatial reasoning. Red bounding boxes indicate the coordinates predicted by MLLM within the GoT framework.

🔼 Figure 7 presents additional examples showcasing the capabilities of the GoT framework in image editing. Each example shows an original image, the GoT reasoning chain generated by the model, the editing instructions and the final edited image. The GoT reasoning chain details the specific changes to be made, including coordinates for precise control of the editing process.
read the caption
Figure 7: More samples on image editing with the GoT content generated by our model.

🔼 Figure 8 presents additional examples showcasing the interactive image generation capabilities of the GoT framework. It demonstrates how users can modify various aspects of the generated image, such as object attributes, positions, and even the addition or removal of objects, by interactively adjusting the GoT reasoning chain. The examples highlight the framework’s flexibility and precision in allowing users to precisely control the final image output through explicit reasoning modifications.
read the caption
Figure 8: More examples on interactive generation.

🔼 This figure visualizes the impact of different hyperparameter settings within the GoT framework’s multi-guidance strategy on the quality of text-to-image generation. It shows examples of images generated using various combinations of α and αs parameters, demonstrating how these settings affect the balance between semantic, spatial, and reference image guidance in the final output. The results illustrate the framework’s ability to produce visually diverse outputs depending on the chosen hyperparameters.
read the caption
Figure 9: Visualization on Multi-Guidance Strategy Hyper-parameter Selection. The above are text-to-image samples generated by GoT framework under different hyper-parameters.

🔼 Figure 10 shows examples from three datasets used in the paper: FLUX-GoT, JourneyDB-GoT, and Laion-Aesthetics-High-Resolution-GoT. Each example displays the image prompt, the generated image, and the corresponding GoT (Generation Chain-of-Thought). The GoT is a detailed, structured description of the image’s content and layout that is automatically created by the model. It includes semantic information (what objects are present) as well as spatial information (where they are located). These examples illustrate the structure of the dataset and how the GoT reasoning chains guide the image generation process.
read the caption
Figure 10: Examples of GoT dataset for text-to-image generation, including FLUX-GoT, JourneyDB-GoT, and Laion-Aesthetics-High-Resolution-GoT.
More on tables
| Method | Params. | Emu-Edit | ImagenHub | Reason-Edit | |
|---|---|---|---|---|---|
| CLIP-I | CLIP-T | GPT-4o Eval. | GPT-4o Eval. | ||
| IP2P [5] | 0.9B+0.1B | 0.834 | 0.219 | 0.308 | 0.286 |
| MagicBrush [53] | 0.9B+0.1B | 0.838 | 0.222 | 0.513 | 0.334 |
| MGIE [10] | 0.9B+7B | 0.783 | 0.253 | 0.392 | 0.264 |
| Emu-Edit [40] | - | 0.859 | 0.231 | - | - |
| SEED-X [13] | 2.8B+14B | 0.825 | 0.272 | 0.166 | 0.239 |
| SmartEdit† [17] | 0.9B+7B | - | - | - | 0.572 |
| CosXL-Edit [4] | - | 0.860 | 0.274 | 0.464 | 0.325 |
| GoT Framework | 2.8B+3B | 0.864 | 0.276 | 0.533 | 0.561 |
🔼 This table presents a quantitative comparison of various image editing models across multiple benchmark datasets. The metrics evaluate the models’ performance on different editing tasks, highlighting strengths and weaknesses. One model, SmartEdit, is noted as primarily focusing on removing and replacing objects, and its scores are not fully comparable to models with broader editing capabilities.
read the caption
Table 2: Quantitative comparison on image editing benchmarks. † denotes that SmartEdit mainly supports removing and replacing operation and is not designed for general editing operations.
| Method | GoT | SSGM | Pretrain | GenEval | ImagenHub |
|---|---|---|---|---|---|
| Baseline | 0.38 | 0.176 | |||
| + GoT | ✓ | 0.40 | 0.181 | ||
| + SSGM | ✓ | ✓ | 0.42 | 0.370 | |
| GoT Framework | ✓ | ✓ | ✓ | 0.64 | 0.533 |
🔼 This ablation study analyzes the impact of different components of the GoT framework on the performance of text-to-image generation and image editing. It compares the baseline model (without GoT and SSGM) against models incorporating GoT reasoning chains and the Semantic-Spatial Guidance Module (SSGM). The results are evaluated using two benchmarks: GenEval (overall performance) and ImagenHub (GPT-40 evaluation). The table shows how each component contributes to the overall performance improvements.
read the caption
Table 3: Ablation study of our GoT framework on GenEval overall and ImagenHub GPT-4o eval.
Full paper#