TL;DR#
In open-world environments, agents need to combine basic skills to handle different tasks. However, online videos are long and unsegmented, making it difficult to identify and label skills. Existing methods rely on sequence sampling or human labeling. To address this, the paper introduces Skill Boundary Detection (SBD), an annotation-free temporal video segmentation algorithm. SBD is inspired by human cognitive event segmentation theory. It leverages prediction errors from a pretrained action-prediction model to detect skill boundaries. The assumption is that a prediction error shows a shift in the skill.
This approach improves the performance of conditioned policies and their hierarchical agents. The method was evaluated in Minecraft, a rich open-world simulator with extensive gameplay videos. The SBD-generated segments improved the average performance of conditioned policies by 63.7% and 52.1% on short-term atomic skill tasks. The corresponding hierarchical agents improved by 11.3% and 20.8% on long-horizon tasks. Overall, the method leverages the diverse YouTube videos to train instruction-following agents.
Key Takeaways#
Why does it matter?#
This paper introduces a novel self-supervised method for skill discovery in open-world environments, overcoming limitations of existing segmentation techniques and offering new possibilities for training instruction-following agents from unsegmented videos.
Visual Insights#
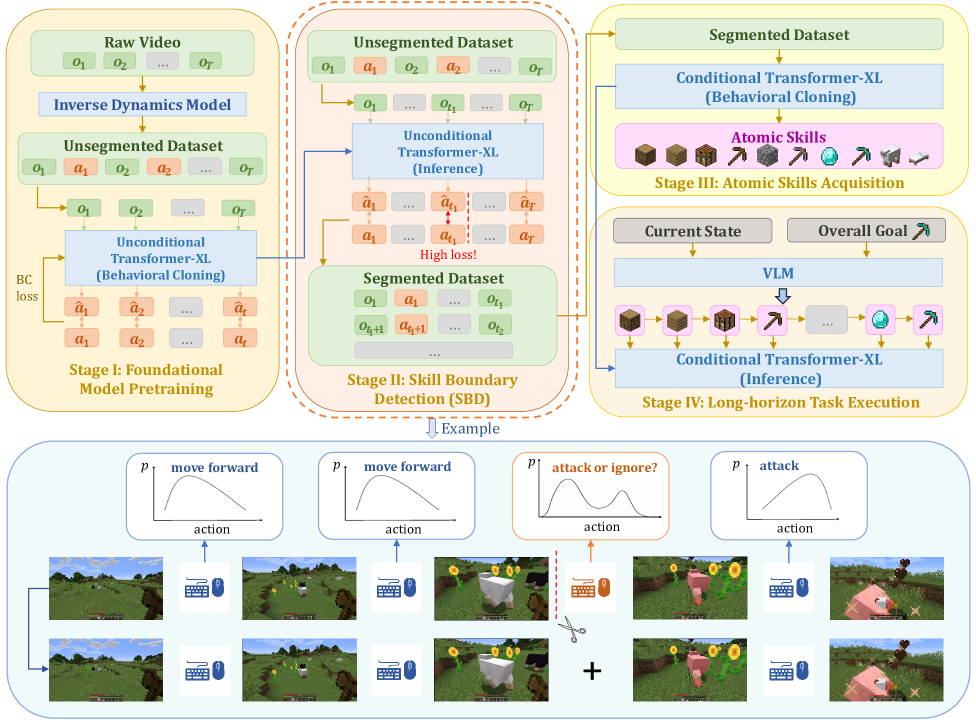
🔼 This figure illustrates the four-stage pipeline of the Skill Boundary Detection (SBD) method for skill discovery from unsegmented demonstration videos. Stage I involves pretraining an unconditional Transformer-XL model on unsegmented data to predict future actions. Stage II uses the pretrained model to detect skill boundaries by identifying significant increases in prediction error, which indicate shifts in the skill being executed. These boundaries segment the long videos into shorter, atomic skill demonstrations. Stage III trains a conditional Transformer-XL model on these segmented demonstrations to learn various atomic skills. Finally, Stage IV employs hierarchical methods, combining vision-language models with the conditional policy, to handle long-horizon instructions and model longer demonstrations.
read the caption
Figure 1: Pipeline of our method SBD for discovering skills from unsegmented demonstration videos. Stage I: An unconditional Transformer-XL based policy model (Dai et al., 2019; Baker et al., 2022) is pretrained on an unsegmented dataset to predict future actions (labeled by an inverse dynamics model) based on past observations. Stage II: The pretrained unconditional policy will produce a high predicted action loss when encountering uncertain observations (e.g., deciding whether to kill a new sheep) in open worlds. These timesteps should be marked as skill boundaries, indicating the need for additional instructions to control behaviors. We segment the long unsegmented videos into a series of short atomic skill demonstrations. Stage III: We train a conditional Transformer-XL based policy model on the segmented dataset to master a variety of atomic skills. Stage IV: Finally, we use hierarchical methods (a combination of vision-language models and the conditional policy) to model the long demonstration and follow long-horizon instructions.
| Method | Illustration | Type |
| Sequential sampling | ![[Uncaptioned image]](x1.png) | rule-based |
| Reward-driven | ![[Uncaptioned image]](x2.png) | rule-based |
| Top-down | ![[Uncaptioned image]](x3.png) | rule-based |
| Bottom-up | ![[Uncaptioned image]](x4.png) | rule-based |
| Ours (SBD) | ![[Uncaptioned image]](x5.png) | learning-based |
🔼 This table compares different video segmentation methods for skill discovery, highlighting the strengths and weaknesses of each approach. It contrasts rule-based methods (sequential sampling, reward-driven, top-down, bottom-up) with the proposed learning-based Skill Boundary Detection (SBD) method. The rule-based methods are criticized for their reliance on human-defined rules, limitations in handling various skill lengths and partial observability, high computational costs, and limited skill diversity. In contrast, SBD is presented as a more robust, flexible, and data-driven solution.
read the caption
Table 1: Comparisons between existing segmentation methods and our method SBD. Existing methods usually rely on human-designed rules, while our method is learning-based. Sequential sampling can result in a single skill spanning different segments or multiple skills located within one segment. Reward-driven methods require additional reward information, which is challenging for human annotators to label. Top-down methods often result in limited skill diversity and high computation costs. Bottom-up methods are limited in fully observable environments and hard in visually partially observable environments. are visual observations and are actions.
In-depth insights#
SBD: EST-Inspired#
SBD, inspired by EST (Event Segmentation Theory), likely segments videos based on prediction errors. EST posits humans divide experiences into discrete events when perceptual expectation is violated. SBD probably uses a pre-trained model to predict future actions; high prediction error signals a skill boundary, mirroring EST’s event boundary detection. This approach offers an unsupervised way to segment videos, unlike methods needing manual labels. SBD’s reliance on prediction error makes it suitable for identifying meaningful skill transitions in open-world environments, where skills are diverse and unlabeled.
Minecraft Tested#
While the paper doesn’t explicitly have a section titled “Minecraft Tested,” Minecraft serves as a crucial testbed. The authors utilize Minecraft due to its open-world nature and the availability of extensive gameplay videos. Minecraft’s rich environment allows for the evaluation of skill discovery and transfer learning in complex, partially observable settings. The evaluation leverages a diverse set of Minecraft skills, testing the ability of the proposed method to segment and learn from unsegmented demonstrations. This includes short-term atomic skills as well as long-horizon programmatic tasks, which highlight the hierarchical agent’s capabilities. The Minecraft environment is used to generate datasets for pre-training, segmentation, and skill acquisition, providing a holistic evaluation of the proposed Skill Boundary Detection (SBD) method. Ultimately, the choice of Minecraft as a testing ground underscores the paper’s focus on real-world applicability and the challenges associated with learning in open-ended environments.
No Human Labels#
The research emphasizes a shift away from traditional methods that rely on manual annotation or human-designed rules. By removing the need for human labels, the proposed techniques aim to reduce costs and time associated with data preparation. The self-supervised approach capitalizes on the availability of unlabeled demonstration videos, making it easier to leverage vast amounts of data. The models instead learn directly from the video content using techniques like skill boundary detection (SBD) and the predictive loss of pre-trained models. This strategy also makes the model more readily applicable in dynamic, real-world scenarios where the cost of labeling grows and labels might be impossible.
Improvement ++#
The concept of “Improvement ++” implies a significant leap beyond incremental advancements. It suggests transformative changes, perhaps driven by novel methodologies or a synergistic combination of existing techniques. This could involve breaking through performance bottlenecks, achieving previously unattainable levels of efficiency, or fundamentally altering the problem-solving approach. Such improvements often stem from rethinking core assumptions, embracing interdisciplinary perspectives, or leveraging emergent technologies. The “++” signifies not just quantitative gains, but also qualitative enhancements, leading to new functionalities, greater robustness, or enhanced user experience. Ultimately, it represents a paradigm shift, pushing the boundaries of what’s considered possible within the given domain, and opening up new avenues for research and innovation.
Action Deviance#
Action deviance plays a crucial role in identifying skill transitions. It assumes that when an agent switches skills, the actions performed are less probable under the previous skill. This ‘surprising’ action provides a signal to detect the transition. Even if policy changes occur without surprising actions, it suggests an ambiguous phase, which is inherently difficult to pinpoint. The analysis focuses on recognizing clear skill boundaries characterized by such deviating actions, emphasizing their importance in skill segmentation.
More visual insights#
More on figures

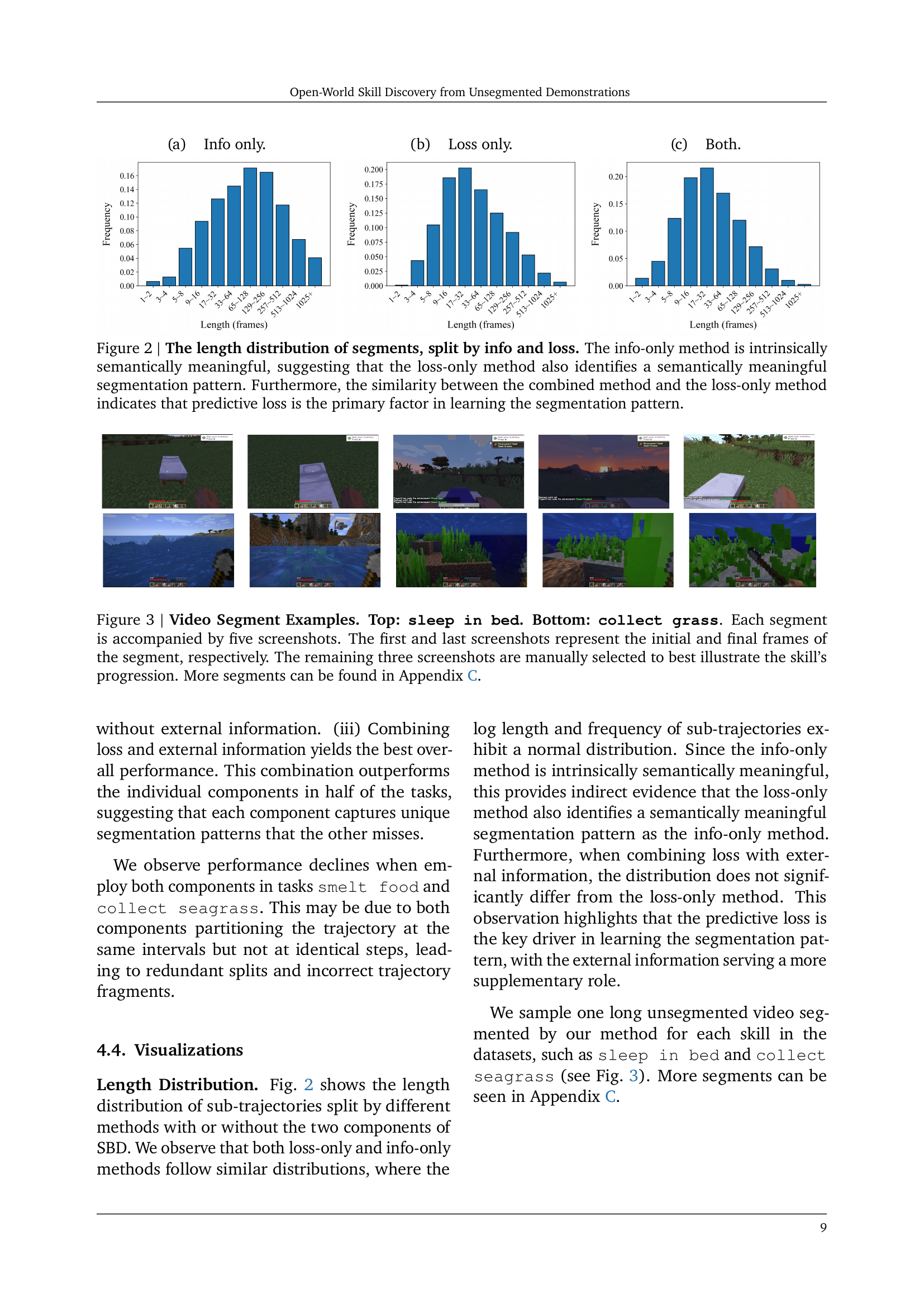
🔼 The figure shows the length distribution of video segments generated using three different methods: using only external information, using only the predictive loss, and using both. The loss-only method produces a distribution similar to the info-only method, suggesting that the loss-only method also identifies semantically meaningful segments. The combined method’s distribution closely resembles that of the loss-only method, indicating that predictive loss is the primary factor in determining the segmentation pattern.
read the caption
(a) Info only.

🔼 The figure shows the distribution of segment lengths when only the prediction loss is used to identify skill boundaries. The x-axis represents segment length in frames and the y-axis shows the frequency of segments with that length. The distribution illustrates the frequency of different segment lengths produced by the loss-only method, providing insights into the typical duration of skills detected using this approach.
read the caption
(b) Loss only.

🔼 This figure shows the length distribution of video segments generated using different methods: using only external information, using only predictive loss, and using both. The x-axis represents the length of the segments (in frames), and the y-axis shows the frequency of segments of that length. The distributions are compared to show the effect of combining external information and predictive loss on the length and semantic meaningfulness of the identified segments.
read the caption
(c) Both.

🔼 Figure 2 presents a comparative analysis of segment length distributions obtained using different methods for video segmentation. The ‘info-only’ method, which utilizes external information, produces segments with lengths that are inherently semantically meaningful. The similar distribution achieved by the ’loss-only’ method—which only uses predictive loss—strongly suggests that the predictive loss effectively captures meaningful boundaries in the video, mirroring the results of the information-rich method. The combined method, which utilizes both information and loss, shows a distribution most similar to the loss-only method. This similarity highlights the dominance of predictive loss as the crucial element in learning the segmentation pattern.
read the caption
Figure 2: The length distribution of segments, split by info and loss. The info-only method is intrinsically semantically meaningful, suggesting that the loss-only method also identifies a semantically meaningful segmentation pattern. Furthermore, the similarity between the combined method and the loss-only method indicates that predictive loss is the primary factor in learning the segmentation pattern.

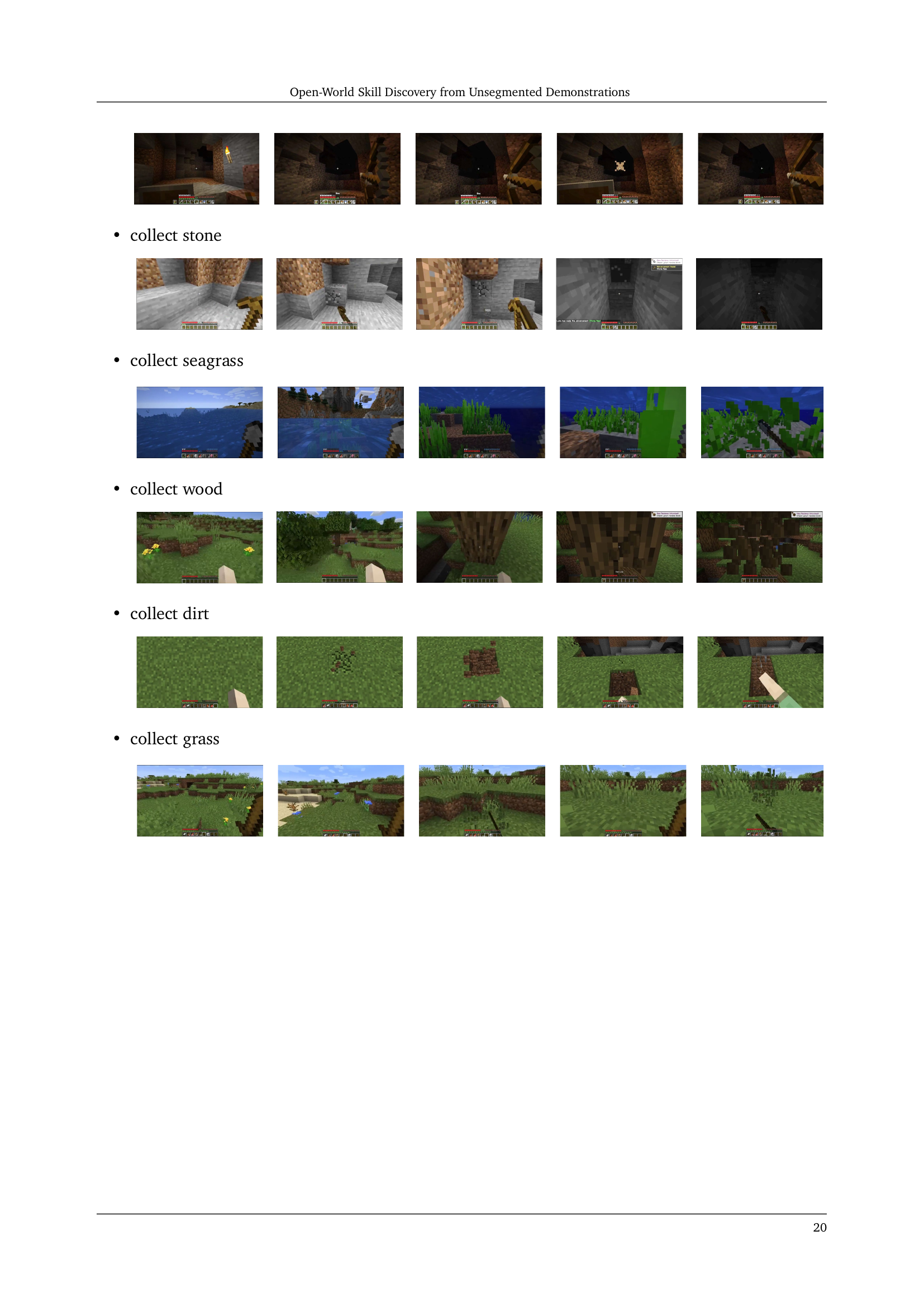
🔼 Figure 3 presents example video segments from the Skill Boundary Detection (SBD) method. Each example shows a short video clip representing a single skill, accompanied by five screenshots. The first and last screenshots capture the start and end of the skill, while the middle three screenshots highlight key steps in the skill’s progression. The top row shows the ‘sleep in bed’ skill, while the bottom row illustrates the ‘collect grass’ skill. More examples can be found in Appendix C.
read the caption
Figure 3: Video Segment Examples. Top: sleep in bed. Bottom: collect grass. Each segment is accompanied by five screenshots. The first and last screenshots represent the initial and final frames of the segment, respectively. The remaining three screenshots are manually selected to best illustrate the skill’s progression. More segments can be found in Appendix C.
More on tables
| Method | Average | |||||||||||||
| VPT | original | 11.0% | 29.0% | 0.0% | 22.0% | 7.0% | 23.0% | 77.0% | 14.0% | 73.0% | 33.0% | 30.0% | 38.0% | - |
| GROOT | original | 21.0% | 26.0% | 100.0% | 97.0% | 71.0% | 30.0% | 21.7 | 34.0% | 76.0% | 19.0% | 14.5 | 9.5 | - |
| ours | 30.0% | 54.0% | 100.0% | 88.0% | 93.0% | 80.0% | 26.8 | 51.0% | 90.0% | 44.0% | 19.7 | 25.4 | - | |
| +42.9% | +107.7% | 0 | -9.3% | +30.1% | +166.7% | +23.3% | +50.0% | +18.4% | +131.6% | +36.1% | +166.3% | +63.7% | ||
| STEVE-1 | original | 0.0% | 1.0% | 33.3% | 33.3% | 18.8% | 65.6% | 96.9% | 18.8% | 80.2% | 57.3% | 44.8% | 46.9% | - |
| ours | 0.0% | 3.1% | 40.6% | 77.1% | 42.7% | 71.9% | 96.9% | 47.9% | 84.4% | 67.7% | 43.8% | 71.9% | - | |
| 0 | +21.9% | +131.3% | +127.8% | +9.5% | 0 | +155.6% | +5.2% | +18.2% | -2.3% | +53.3% | +52.1% |
🔼 Table 2 presents a comparison of the performance of different policies (VPT, GROOT, and STEVE-1) on various Minecraft skill benchmarks. For each policy, results are shown both for the original model and for a version retrained using the Skill Boundary Detection (SBD) method developed in this paper. Performance is measured by both average success rate (percentage) and average reward (numeric score). The Minecraft environment’s random seed is held constant for each task to ensure fair comparisons between models. More details about the specific tasks are provided in Section B.1 of the paper.
read the caption
Table 2: Success rate of different policies on Minecraft skill benchmarks. For VPT (Baker et al., 2022), we report the results of the behavioral cloning version. For GROOT (Cai et al., 2023b) and STEVE-1 (Lifshitz et al., 2023), we report the results of original and our re-trained with SBD, respectively. A value with % indicates the average success rate, while a value without % indicates the average rewards. The seeds for the Minecraft environment are fixed for the corresponding task to make a fair comparison between different models. Details of the tasks are provided in Section B.1.
| Method | Wood | Food | Stone | Iron | Average |
| original | 95% | 44% | 82% | 32% | - |
| ours | 96% | 55% | 90% | 35% | - |
| +1.1% | +25.0% | +9.8% | +9.4% | +11.3% |
🔼 This table presents the success rates of the OmniJARVIS agent, trained using behavior cloning, on a set of long-horizon programmatic tasks in Minecraft. The agent’s performance is compared between using the original sequential sampling method for skill segmentation and the proposed Skill Boundary Detection (SBD) method. The tasks involve collecting various resources, such as wood, stone, iron, and diamonds, starting from an empty inventory, and the success rate indicates the percentage of successful task completions.
read the caption
(a) OmniJARVIS (behavior cloning)
| Method | Wood | Oak | Birch | Stone | Iron | Diamond | Armor | Food | Average |
| original | 92% | 89% | 90% | 90% | 33% | 8% | 12% | 39% | - |
| ours | 97% | 95% | 94% | 91% | 35% | 10% | 19% | 62% | - |
| +5.4% | +6.7% | +4.4% | +1.1% | +6.1% | +25.0% | +58.3% | +59.0% | +20.8% |
🔼 This table presents the success rates of the JARVIS-1 hierarchical agent, using in-context learning, on various long-horizon programmatic tasks in Minecraft. The results are shown for both the original method and our improved method using the SBD algorithm for segmented video data. It shows the success rates for each task, broken down by resource type (Wood, Oak, Birch, Stone, Iron, Diamond, Armor, Food), and then an overall average. This allows a comparison of the performance improvement gained by utilizing the SBD method for improved skill segmentation in training.
read the caption
(b) JARVIS-1 (in-context learning)
| Task | Average | ||||||||||||
| - | 21.0% | 26.0% | 100.0% | 97.0% | 71.0% | 30.0% | 21.7 | 34.0% | 76.0% | 19.0% | 14.5 | 9.5 | 64.2 |
| Info | 33.0% | 52.0% | 100.0% | 88.0% | 97.0% | 32.0% | 23.7 | 65.0% | 92.0% | 47.0% | 15.5 | 21.6 | 87.4 |
| Loss | 44.0% | 54.0% | 100.0% | 94.0% | 72.0% | 46.0% | 25.8 | 63.0% | 95.0% | 48.0% | 17.9 | 22.7 | 91.8 |
| Both | 30.0% | 54.0% | 100.0% | 88.0% | 93.0% | 80.0% | 26.8 | 51.0% | 90.0% | 44.0% | 19.7 | 25.4 | 93.3 |
🔼 This table presents the success rates of two hierarchical agents (OmniJARVIS using behavior cloning and JARVIS-1 using in-context learning) performing long-horizon programmatic tasks in Minecraft. The agents’ controllers were trained on datasets segmented using two different methods: the proposed Skill Boundary Detection (SBD) method and the original sequential sampling (SS) method. The tasks are grouped by the type of item the agent needs to obtain (e.g., wood, stone, iron, diamond). Each group contains multiple tasks requiring a chain of atomic skills to achieve the goal, starting either from scratch or with an iron pickaxe. All tasks were tested 30 times to ensure reliability of the results. The table compares the performance of agents trained with SBD-segmented data against those trained with sequentially sampled data, highlighting the impact of the SBD method on the ability of these agents to successfully complete complex tasks.
read the caption
Table 3: Success rate of two agents with their corresponding controllers trained on dataset segmented by our SBD method and the original sequential sampling (SS) method on groups of long programmatic tasks. All tasks are tested 30 times. In each group, the agent is required to obtain a certain type of items from scratch or given an iron pickaxe. For example, the diamond group includes diamond pickaxe, diamond sword, jukebox, etc.
| Task | Metric | Description | Text Prompt for STEVE-1 |
| Craft item cooked mutton | Given a furnace and some mutton and coal, craft a cooked mutton. | - | |
| Kill entity sheep | Summon some sheep before the agent, hunt the sheep. | - | |
| STEVE-1: Use item white bed. GROOT: Sleep in bed properly. | Given a white bed, sleep on it. | Sleep in bed. | |
| Use item torch | Give some torches, use them to light up an area. Time is set at night. | Use a torch to light up an area. | |
| Use item birch boat | Given a birch boat, use it to travel on water. Biome is ocean. | - | |
| STEVE-1: Use item bow. GROOT: Use item bow 20%, Shoot in distance 40%, take aim 40% | Given a bow and some arrows, shoot the sheep summoned before the agent. | - | |
| Mine block stone (cobblestone, iron, coal, diamond) | Given an iron pickaxe, collect stone starting from cave. Night vision is enabled. | Collect stone. | |
| Mine block seagrass (tall seagrass, kelp) | Given an iron pickaxe, collect seagrass starting from ocean. | - | |
| Mine block oak (spruce, birch, jungle, acacia) log | Given an iron pickaxe, collect wood starting from forest. | Chop a tree. | |
| Mine block oak (spruce, birch, jungle, acacia) log | Given an iron pickaxe, find and collect wood starting from plains. | Chop a tree. | |
| Mine block dirt (grass block) | Given an iron pickaxe, collect dirt starting from plains. | Collect dirt. | |
| Mine block grass (tall grass) | Given an iron pickaxe, collect grass starting from plains. | Collect grass. |
🔼 This table presents an ablation study on the Skill Boundary Detection (SBD) method. It compares the performance of different versions of SBD on Minecraft atomic skill tasks. The variations include using only the loss function for boundary detection, using only external information, combining both, and using sequential sampling as a baseline (represented by ‘-’). The results demonstrate the contribution of each component to the overall performance of the SBD algorithm.
read the caption
Table 4: Ablation on the components within SBD. We report the evaluation results on Minecraft atomic skills from the sequential sampling (- in the table) and SBD with different components.
| Hyperparameter | Value |
| Learning Rate | 0.00004 |
| Parallel GPUs | 4 |
| Accumulate Gradient Batches | 1 |
| Batch Size | 8 |
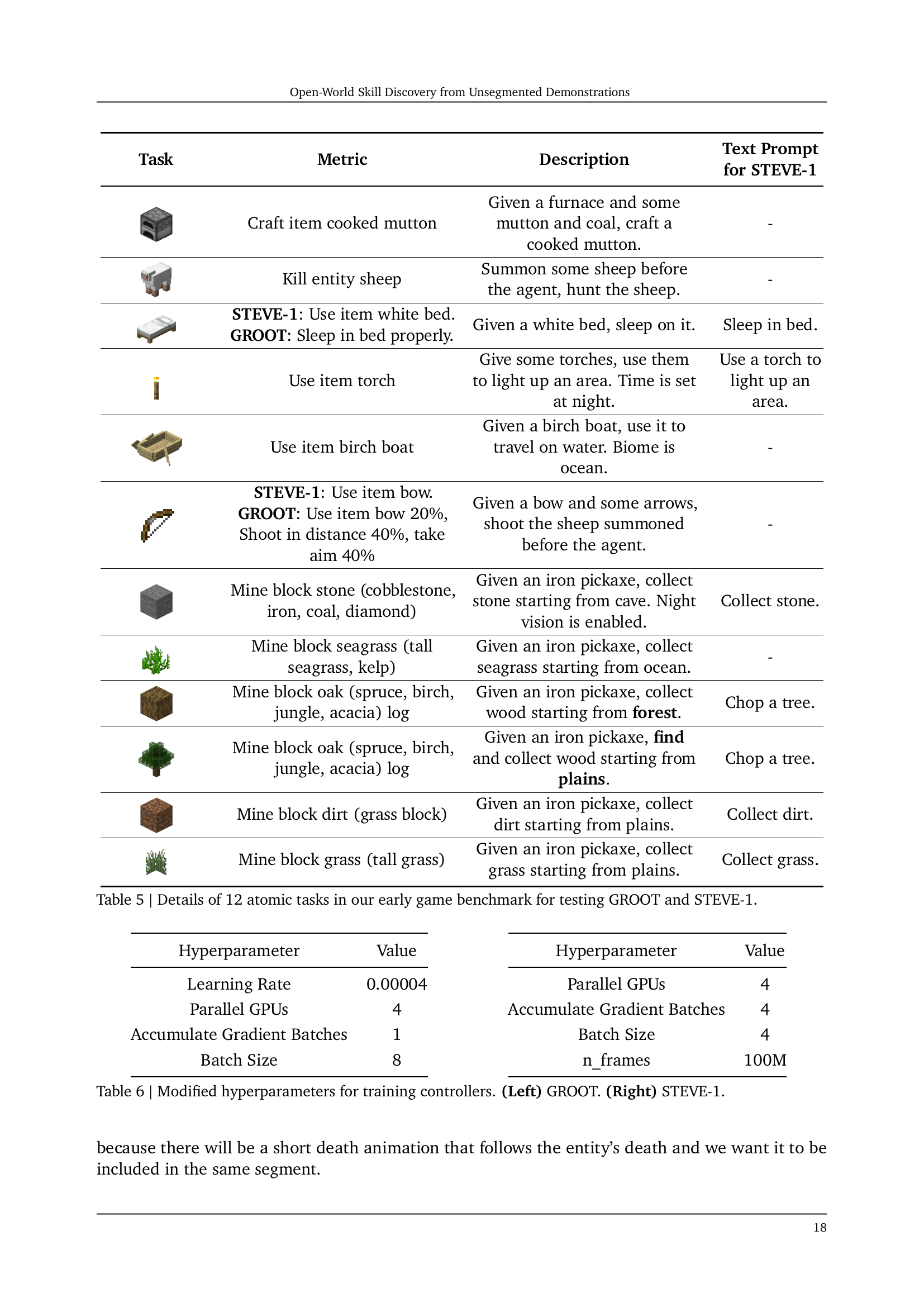
🔼 This table details twelve atomic tasks used to evaluate the GROOT and STEVE-1 models in the ‘Early Game Benchmark.’ For each task, it lists the specific metric used for evaluation, a description explaining the task’s objective and the required actions, and the text prompt used for the STEVE-1 model (when applicable). The tasks encompass a range of actions, from basic resource gathering (e.g., collecting wood, stone) to more complex actions requiring tool use (e.g., crafting cooked mutton, using a bow to shoot a sheep). This provides a comprehensive assessment of the models’ ability to perform a variety of short, discrete actions within the Minecraft game environment.
read the caption
Table 5: Details of 12 atomic tasks in our early game benchmark for testing GROOT and STEVE-1.
| Hyperparameter | Value |
| Parallel GPUs | 4 |
| Accumulate Gradient Batches | 4 |
| Batch Size | 4 |
| n_frames | 100M |
🔼 This table details the modified hyperparameters used for training the GROOT and STEVE-1 controllers. It shows the specific values adjusted for parameters such as learning rate, batch size, and gradient accumulation, distinguishing between the settings for the GROOT and STEVE-1 models. This information is crucial for replicating the experimental setup and understanding the differences in training approaches for these two types of controllers.
read the caption
Table 6: Modified hyperparameters for training controllers. (Left) GROOT. (Right) STEVE-1.
Full paper#