TL;DR#
Current video-to-audio methods falter in long scenarios due to fragmented synthesis and inadequate cross-scene consistency. To address this, the paper introduces LVAS-Agent, a novel multi-agent framework that emulates professional dubbing workflows through collaborative role specialization. This decomposes long-video synthesis into scene segmentation, script generation, sound design, and audio synthesis, using discussion-correction and generation-retrieval loop.
LVAS-Agent mimics dubbing with agents: Storyboarder segments videos, Scriptwriter generates scripts fusing CLIP with dialogue, Designer uses spectral analysis for sound design, and Synthesizer blends neural text-to-speech with diffusion. It introduces LVAS-Bench for evaluation. Experiments show the system improves audio-visual alignment, offering a better approach to long-video audio synthesis.
Key Takeaways#
Why does it matter?#
This paper introduces a novel framework and a dedicated benchmark for long-video audio synthesis, addressing key challenges and opening new avenues for research in multi-agent collaborative systems and VLM-based content creation. It holds importance for researchers in audio processing, video understanding, and AI-driven content generation.
Visual Insights#
🔼 Figure 1 illustrates the LVAS-Agent framework, a multi-agent system designed for end-to-end long-video audio synthesis. The framework consists of four key agents: Storyboarder, Scriptwriter, Designer, and Generator. Each agent plays a distinct role in the process, mimicking a real-world dubbing workflow. The Storyboarder segments the video into scenes and identifies keyframes. The Scriptwriter generates a script based on visual analysis and dialogue extraction. The Designer refines the audio design with specifications and metadata, and the Generator synthesizes the final audio using a combination of video-to-audio and text-to-audio models. The agents collaborate through several mechanisms, including Discussion-Correction and Generation-Retrieval-Optimization, ensuring high-quality and coherent audio that aligns with the video content.
read the caption
Figure 1: We introduce LVAS-Agent, a multi-agent collaborative framework for end-to-end long video audio synthesis. Built on VLM and LLM-based agents, it simulates real-world dubbing workflows, enabling automatic video script generation, audio design, and high-quality audio synthesis for long videos.
| Methods | Distribution Matching | Audio Quality | Semantic Align | Temporal Align | |||||
|---|---|---|---|---|---|---|---|---|---|
| IB-Score | DeSync | ||||||||
| Baseline (FoleyCrafter) | 6.61 | 60.66 | 637.82 | 2.68 | 2.65 | 4.79 | 4.34 | 0.28 | 1.24 |
| Baseline (MMAudio) | 9.48 | 51.73 | 588.24 | 2.02 | 1.80 | 3.91 | 3.05 | 0.32 | 0.61 |
| LVAS-Agent (Ours) | 5.76 | 46.16 | 573.67 | 1.86 | 1.77 | 4.28 | 3.50 | 0.33 | 0.53 |
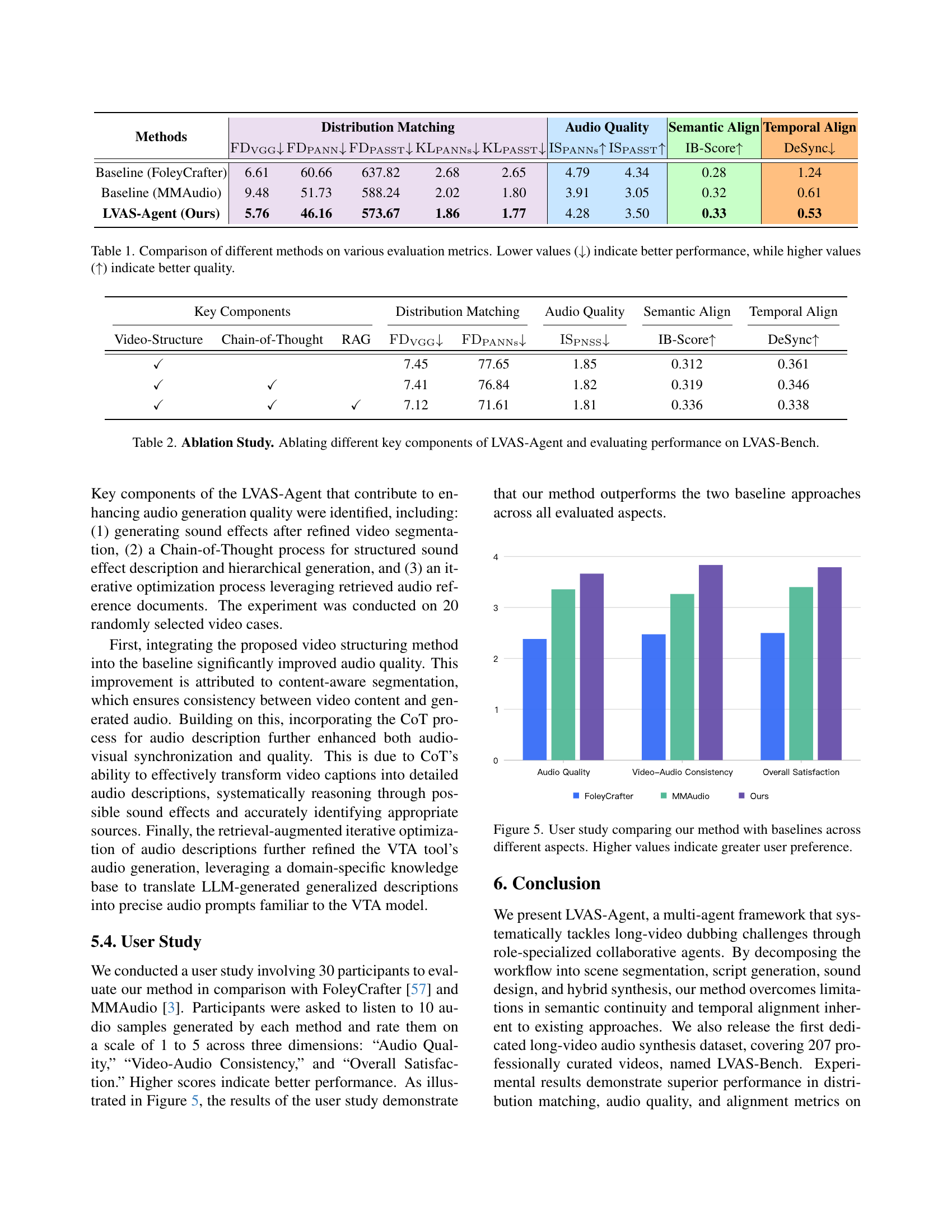
🔼 This table presents a quantitative comparison of different audio synthesis methods, namely FoleyCrafter, MMAudio, and the proposed LVAS-Agent, across four key evaluation metrics. These metrics assess the quality and alignment of the generated audio against ground truth data. Specifically, distribution matching evaluates the similarity between the generated audio’s feature distributions and those of real audio using metrics like Fréchet Distance and Kullback-Leibler divergence. Audio quality is measured using Inception Score, which quantifies how realistic and natural the generated audio sounds. Semantic alignment measures the degree of correspondence between the generated audio’s meaning and that of the visual context in the video, computed through average cosine similarity using ImageBind features. Finally, temporal alignment assesses the synchronization between audio and video by measuring the misalignment in seconds between the two modalities using Synchformer.
read the caption
Table 1: Comparison of different methods on various evaluation metrics. Lower values (↓↓\downarrow↓) indicate better performance, while higher values (↑↑\uparrow↑) indicate better quality.
In-depth insights#
LVAS-Agent’s Core#
The paper introduces LVAS-Agent, a novel multi-agent framework designed to tackle the challenges of long-video audio synthesis. It is meant to emulate professional dubbing workflows through structured role specialization. Central to the agent are key elements such as semantic scene segmentation, script generation, and audio synthesis. The core likely comprises the mechanisms for communication, data sharing, and task coordination between the agents. This allows them to decompose the complex audio dubbing process into smaller, more manageable tasks, improving overall performance and ensuring semantic coherence and temporal alignment in the final audio output. It is structured to systematically address long-video dubbing by specializing the synthesis process through role-specialized collaborative agents.
LVAS-Benchmarks#
I imagine LVAS-Bench, a hypothetical benchmark, would be crucial for evaluating long-video audio synthesis models. It would need diverse video content, going beyond typical short clips. Detailed annotations are essential, including timestamps for specific sounds and overall scene descriptions. The benchmark should assess various aspects, such as audio quality, synchronization with video, and semantic relevance. Also, metrics that capture the continuity of audio across longer videos would be vital, especially how well the model handles scene transitions. The benchmark’s statistical analysis would be based on diverse audio categories and sub-categories. Finally, a standardized evaluation protocol would enable fair comparisons between different LVAS models, accelerating progress in this challenging field.
Agent roles#
Agent roles in collaborative AI systems, particularly for tasks like long-video audio synthesis, involve a structured division of labor. Each agent specializes in a specific sub-task, such as scene segmentation, scriptwriting, sound design, or audio synthesis. This specialization allows each agent to develop expertise in its area, leading to higher quality outputs. Collaboration is key, with mechanisms for discussion, correction, and iterative refinement ensuring a coherent and consistent final product. By mimicking real-world dubbing workflows, these multi-agent systems can effectively address the challenges of complex, long-form content.
Audio Coherence#
Considering the concept of ‘Audio Coherence’ in the context of video-to-audio synthesis, especially for long-form content, it’s crucial to address how well the generated audio maintains a consistent and logical relationship with the visual narrative and its temporal progression. Achieving audio coherence involves ensuring that the sounds accurately reflect the on-screen actions, the environment, and the emotional tone of each scene. This is particularly challenging in long videos where scenes shift dynamically, and maintaining consistency becomes difficult. A coherent audio track would avoid abrupt transitions, unnatural sound placements, and mismatches between the visual and auditory experiences. The absence of dedicated datasets further complicates the issue because current models struggle to manage long-range dependencies and to create a seamless auditory experience over extended durations. Future works should focus on developing methods that can generate more realistic soundscapes to increase audio coherence.
LLM Refinement#
LLM refinement constitutes a critical area of research, addressing the inherent limitations of foundation models in specialized tasks. It encompasses techniques like fine-tuning, prompt engineering, and knowledge injection, all aimed at enhancing performance, controllability, and safety. Effective refinement requires careful consideration of task-specific data, appropriate training objectives, and robust evaluation metrics. The process can benefit from reinforcement learning to align with human preferences and mitigate biases. Ultimately, LLM refinement enables the adaptation of general-purpose models to meet the nuanced demands of real-world applications.
More visual insights#
More on figures

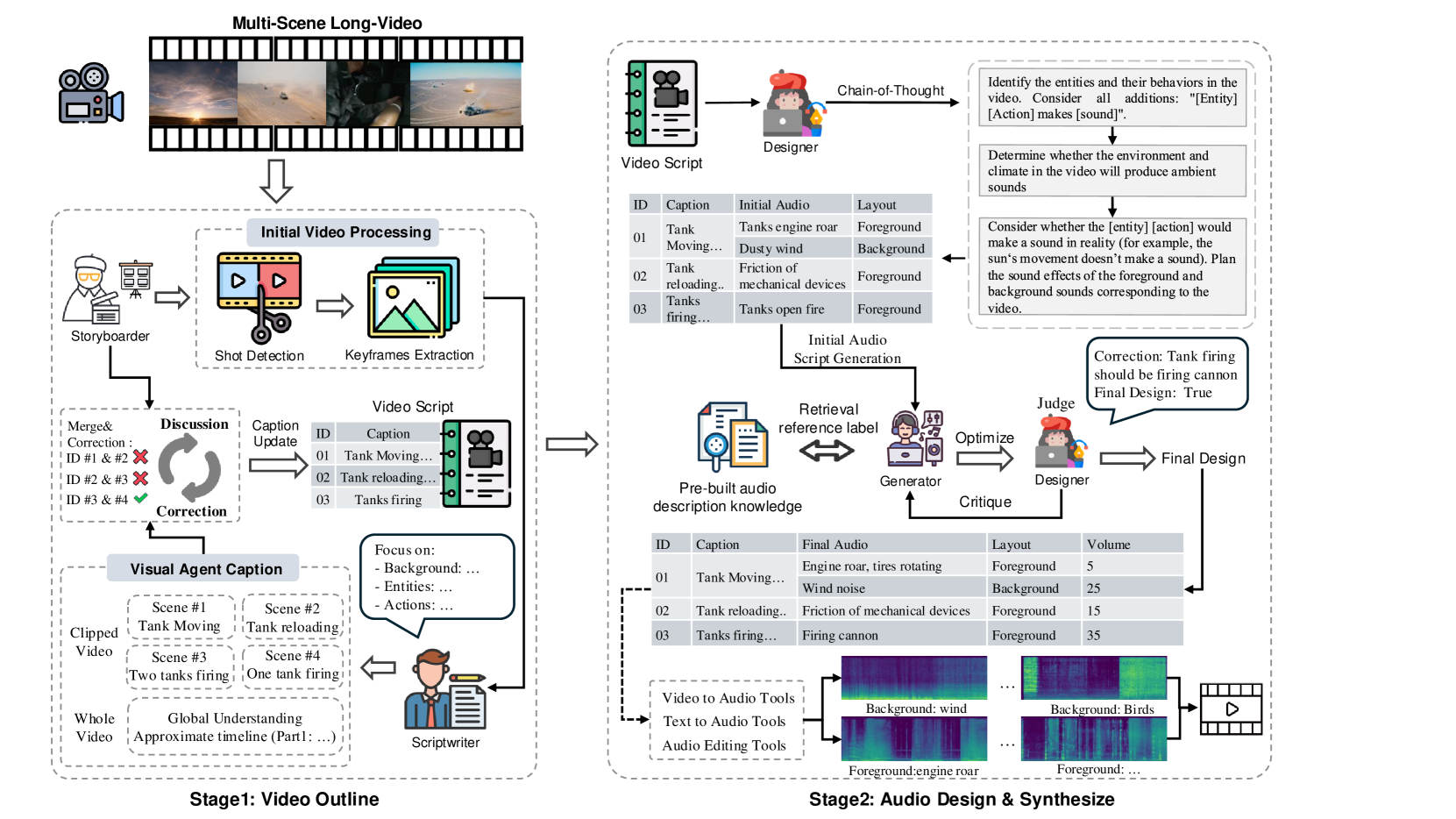
🔼 This figure illustrates the LVAS-Agent’s workflow, a multi-agent system designed for long-video audio synthesis. The process begins with the Storyboarder segmenting the input video into scenes and extracting keyframes, which are then used by the Scriptwriter to generate a video script. The Storyboarder and Scriptwriter collaborate iteratively through a discussion and correction mechanism to refine the script. This refined video script is then used by the Designer to create a detailed sound design, including both foreground and background audio elements. The sound design is further refined via a generation-retrieval-optimization loop between the Designer and Synthesizer agents. Finally, the Synthesizer, utilizing various audio tools, generates a high-quality multi-layered audio track synchronized with the video.
read the caption
Figure 2: Workflow of LVAS-Agent. Given the original video, Storyboarder and Scriptwriter collaborate through Discussion and Correction to create a structured video script. The Designer and Generator complete multi-layered, high-quality sound synthesis through the Generate-Retrieve-Optimize mechanism.

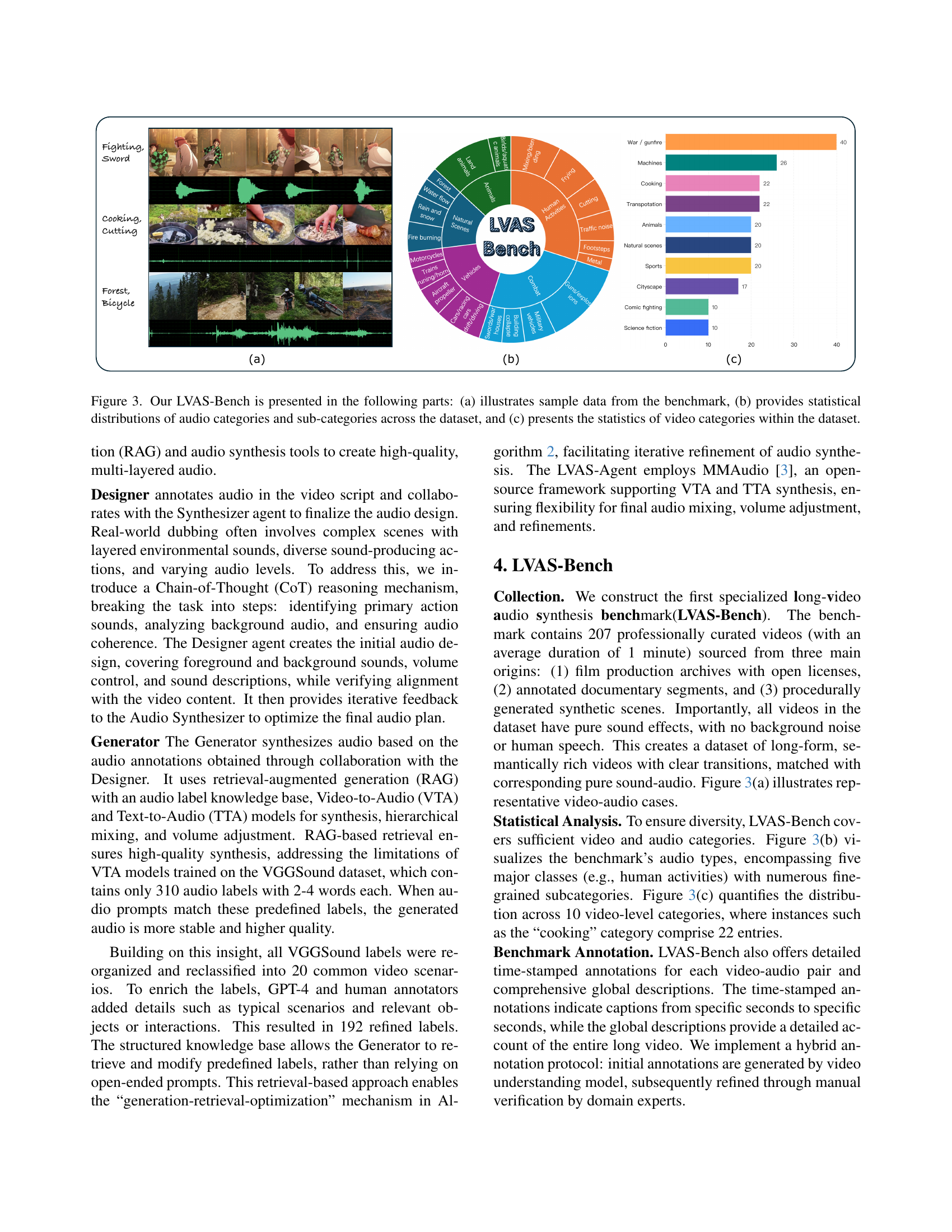
🔼 Figure 3 showcases the LVAS-Bench dataset. Part (a) displays example data points from the benchmark, offering a visual representation of the dataset’s content diversity. Part (b) presents a statistical analysis of audio categories and their sub-categories, providing insights into the distribution and prevalence of various audio types within the dataset. This visualization allows for a comprehensive understanding of the audio diversity and balance in the benchmark. Part (c) focuses on the video categories, displaying the statistical distribution of videos based on their content or theme. This detailed categorization aids in evaluating the representation of diverse video scenes within LVAS-Bench and ensures its suitability for comprehensive model evaluation across a range of contexts.
read the caption
Figure 3: Our LVAS-Bench is presented in the following parts: (a) illustrates sample data from the benchmark, (b) provides statistical distributions of audio categories and sub-categories across the dataset, and (c) presents the statistics of video categories within the dataset.

🔼 Figure 4 presents a visual comparison of spectrograms generated using existing methods and the proposed LVAS-Agent. The spectrograms showcase the audio generated for two different video scenes: a train passing a station, and fireworks exploding. This comparison highlights LVAS-Agent’s superior performance in synthesizing long-form video audio by demonstrating smoother transitions between scenes and complete audio output without missing key sounds or errors, unlike existing methods which produce incomplete or inaccurate audio.
read the caption
Figure 4: We visualize the spectrograms of generated audio (by prior works and our method). LVAS-Agent demonstrates superior performance in synthesizing long video audio, ensuring seamless scene transitions without errors or missing sounds.

🔼 This figure presents the results of a user study comparing the performance of the proposed LVAS-Agent method against two baseline methods (FoleyCrafter and MMAudio) across three key aspects of audio generation for long videos: audio quality, video-audio consistency, and overall user satisfaction. Each aspect is rated on a scale of 1 to 5, with higher scores indicating better performance. The bar chart visually represents the average scores obtained for each method across all three aspects, allowing for a direct comparison and illustrating the superior performance of the LVAS-Agent method.
read the caption
Figure 5: User study comparing our method with baselines across different aspects. Higher values indicate greater user preference.

🔼 This figure shows the prompt used for the Storyboarder agent in the LVAS-Agent framework. The Storyboarder agent is responsible for segmenting the video into scenes and creating a storyboard, so this prompt guides the agent on how to do this. The prompt provides instructions on how to identify scenes, segment the video, analyze the content of each segment, and decide whether to merge or correct the segments. It also specifies the input and output formats, including a JSON format for the final storyboard output. The figure shows example inputs and outputs to further clarify the expectations of the agent.
read the caption
Figure 1: Storyboarder Prompt

🔼 This figure displays the prompt given to the Scriptwriter agent within the LVAS-Agent framework. The Scriptwriter’s role is to analyze a full video and provide a structured summary of its content. The prompt instructs the agent to identify the main scenes and their sequence, focusing on key events and actions. It also requires the agent to generate an approximate timeline of the video, highlighting transitions between key moments. Finally, the agent must summarize the video’s content concisely and coherently.
read the caption
Figure 2: Scriptwriter Prompt: full video understanding

🔼 This figure displays the prompt given to the ‘Scriptwriter’ agent within the LVAS-Agent framework. The prompt instructs the agent on how to analyze a video segment and provide a concise textual description. It emphasizes the importance of focusing on the video content alone, avoiding speculative additions or background information. The required output format is specified, which includes descriptions of the background, entities, actions, and a final video caption. This is a crucial step in the multi-agent collaboration process, bridging visual understanding with textual representation for audio synthesis.
read the caption
Figure 3: Scriptwriter Prompt: video segment understanding

🔼 Figure 4 shows the prompt given to the ‘Designer’ agent within the LVAS-Agent framework. The Designer agent is responsible for creating detailed and realistic sound effect annotations for a video clip, based on its textual description. The prompt provides guidelines on identifying sound-producing entities and actions, determining background ambience, prioritizing sounds, ensuring realism, and avoiding redundancy. The input to the agent is a video’s textual description, and the output is a JSON containing the identified background and main sounds.
read the caption
Figure 4: Designer Prompt

🔼 This figure shows the prompt given to the Synthesizer agent in the LVAS-Agent framework. The Synthesizer’s role is to select appropriate audio labels from a predefined knowledge base, matching the input video and initial audio descriptions. The prompt guides the agent to prioritize semantic similarity when selecting labels, handling cases where an exact match isn’t found by focusing on the sound type. The agent is instructed to avoid suggesting labels with human voices unless clearly specified in the video description and to adhere strictly to the available labels within the reference document. The prompt also specifies handling of ‘None’ labels.
read the caption
Figure 5: Synthesizer Prompt
Full paper#