TL;DR#
Cross-modality generation is key, but current methods treat text as conditional and require complex mechanisms. Can we unify understanding and generation by enabling direct transitions in a shared space? This work revisits flow matching, learning a direct path enabling faster multimodal generation. Unlike diffusions, it requires source and target sharing the same shape.
This paper introduces FlowTok, flowing tokens for text and images. It encodes images into compact 1D tokens, reducing latent space by 3.3x at 256 resolution, removing complex conditioning. It extends to image-to-text under the same formulation. It is memory-efficient, needs fewer resources, faster sampling, and comparable SOTA performance. The code will be released!
Key Takeaways#
Why does it matter?#
This paper introduces a streamlined architecture, FlowTok, centered on compact 1D tokens, enhancing memory efficiency and faster sampling speeds for cross-modality generation. It serves as a strong foundation for future research in generalized cross-modality generation.
Visual Insights#

🔼 FlowTok, a novel model, processes both text and images within a shared, compact one-dimensional (1D) latent space. This unified representation allows for direct flow matching between 1D tokens corresponding to text and images. The result is the efficient generation of diverse and high-fidelity images directly from text prompts. The figure displays a selection of images generated by the FlowTok model, showcasing its ability to generate varied and realistic image content from textual descriptions.
read the caption
Figure 1: Text-to-Image Generation Results by FlowTok. FlowTok projects both text and images into a unified, compact 1D latent space, enabling direct flow matching between 1D tokens and facilitating the efficient generation of diverse, high-fidelity images.
| model | depth | width | mlp | heads | #params |
|---|---|---|---|---|---|
| FlowTok-B | 12 | 768 | 3072 | 12 | 153M |
| FlowTok-XL | 28 | 1152 | 4608 | 16 | 698M |
| FlowTok-H | 36 | 1280 | 5120 | 20 | 1.1B |
🔼 This table details the architectural configurations for three different variants of the FlowTok model: FlowTok-B, FlowTok-XL, and FlowTok-H. It shows how the number of DiT (Diffusion Transformer) blocks, depth, width, and the number of attention heads scale across these variants, directly impacting the model’s overall size and parameter count. The scaling strategy follows established practices in deep learning model scaling. This information provides insights into the resource requirements for training and inference for each model variant.
read the caption
Table 1: Architecture Configuration of FlowTok. Following prior work, we scale up DiT blocks across three configurations.
In-depth insights#
Direct Flow Gen#
Direct Flow Generation represents a significant shift in generative modeling, moving away from conditional approaches to directly transforming source data into the target modality. Instead of guiding the generation process through conditioning signals, direct flow methods learn a direct mapping, potentially leading to more efficient and controlled generation. This approach is particularly interesting in cross-modal tasks like text-to-image generation, where aligning the source and target representations is critical. The success hinges on finding a shared latent space and effective mechanisms for direct transformation, while retaining fidelity. Direct flow approaches provide faster inference than iterative methods because they only require a single pass through a transformation network. However, the training is more complex and needs a well-defined loss function for the transformation network.
1D Tokenization#
1D tokenization represents a departure from traditional 2D grid-based approaches in image representation, aiming for a more compact and efficient latent space. The core idea revolves around eliminating the need to preserve the spatial structure inherent in images, which is crucial for generative tasks. By encoding images into a 1D sequence of tokens, computational costs can be reduced, as there is no need to process the spatial information using operations. The challenge lies in effectively capturing the image’s content and semantic information within the reduced dimensionality of the 1D token sequence. Successfully implementing 1D tokenization is essential for enabling efficient flow matching, where different modalities (text and image) are projected into a shared latent space, thereby facilitating seamless cross-modal generation. Furthermore, this approach aligns well with the sequential nature of text, which is also encoded as a 1D sequence of tokens, enabling direct and efficient interactions between text and image representations.
FlowTok Design#
While “FlowTok Design” isn’t explicitly a heading, the paper centers around direct flow matching between text and images by projecting them into a shared 1D latent space. This involves carefully engineering both text and image encoders. The text encoder, often a pre-trained model like CLIP, is paired with a text projector to map embeddings to a lower-dimensional space matching the image tokens. On the image side, the paper enhances the TA-TiTok tokenizer with techniques like RoPE and SwiGLU FFN to create compact 1D image tokens. The design emphasizes streamlining the architecture, eliminating complex conditioning mechanisms found in diffusion models. A critical aspect is aligning the number of text and image tokens. The compact 1D token representation, smaller than typical 2D latent spaces, is key to the model’s efficiency, leading to faster training and inference. By directly flowing between these representations, FlowTok simplifies cross-modal generation.
Fast Convergence#
While the paper doesn’t explicitly use the heading “Fast Convergence”, the concept is central to its claims. FlowTok achieves comparable performance to state-of-the-art text-to-image models, but with significantly reduced training time. This “fast convergence” is a direct result of FlowTok’s architectural choices: the unified, compact 1D latent space simplifies the learning task, reducing the complexity of the mapping function the model needs to learn. By directly evolving text and image modalities within this shared space, FlowTok eliminates the need for intricate conditioning mechanisms and noise scheduling that typically slow down diffusion-based models. The efficient training allows FlowTok to be trained with fewer computational resources, making the research more accessible. Also, due to 1D architecture it achieves much faster sampling speed.
Beyond Text->Img#
The exploration ‘Beyond Text->Img’ suggests a move past traditional text-to-image generation, hinting at a more holistic approach to cross-modal understanding. This could involve scenarios where images influence text generation (‘Img->Text’), or even a synergistic, iterative process. The authors might explore the challenges of establishing a bi-directional flow between modalities, moving beyond text as a mere conditioning signal. Novel architectures and training strategies could be introduced to effectively capture and translate the underlying information in each modality. A potential focus could be on achieving more contextually aware and nuanced image generation, where the output reflects a deeper comprehension of the input text, or vice-versa. Furthermore, the investigation could extend to multi-modal editing, manipulation, and creative exploration, enabling users to seamlessly blend text and imagery for artistic expression. Ultimately, the exploration aims to foster a more unified and interactive relationship between textual and visual information, broadening the possibilities of creative content creation and data understanding.
More visual insights#
More on figures

🔼 This figure compares two approaches to text-to-image generation. The top panel illustrates the conventional method using a diffusion process, where text acts as a conditioning signal to guide the generation from noise to a final image. The bottom panel shows the FlowTok approach. Instead of using diffusion, FlowTok projects both text and images into a shared, low-dimensional (1D) latent space. This allows for direct transformation between the text and image representations, resulting in more efficient and seamless generation of images from text or vice versa.
read the caption
Figure 2: Text as Conditions vs. Direct Flow between Modalities. Top: Conventional text-to-image generation relies on the diffusion process, where text serves as a conditioning signal to guide the denoising process. Bottom: The proposed FlowTok enables direct flow between text and image modalities by projecting both into a shared, compact 1D latent space, facilitating seamless generation of both.

🔼 The figure shows a comparison of the Fréchet Inception Distance (FID) score, a metric for evaluating image quality, against the training cost (measured in 8-A100 GPU days) for various models. It illustrates that FlowTok achieves comparable or better FID scores with significantly reduced training costs compared to other models, highlighting its efficiency.
read the caption
(a) FID vs. Training Costs.

🔼 This figure shows a comparison of different models’ performance on the COCO dataset, specifically focusing on the trade-off between image quality (measured by FID score) and inference speed (images per second). The graph visualizes how various models balance these two factors. Lower FID indicates better image quality, while higher inference speed implies faster image generation.
read the caption
(b) FID vs. Inference Speed.

🔼 Figure 3 displays a comparison of FlowTok’s performance against other state-of-the-art models on the COCO dataset. Subfigure (a) shows that FlowTok achieves comparable FID scores (a measure of image quality) to other models, but requires significantly less training time (measured in 8-A100 GPU days). Subfigure (b) demonstrates that FlowTok’s inference speed (images per second) is considerably faster than competing methods. The superior efficiency of FlowTok results from its novel design using compact 1D tokens for representing both text and images, enabling direct transformation between the two modalities and improving computational efficiency. Note that a competitor model, CrossFlow, utilized high-quality proprietary data, which may influence the results.
read the caption
Figure 3: COCO Results. FlowTok presents comparable performance to previous methods on COCO while significantly reducing training resource requirements (Fig. 3(a)) and achieving much faster sampling speed (Fig. 3(b)). This efficiency stems from its minimalist design centered around 1D tokens, which facilitates direct transformation between text and image modalities, leading to superior performance with enhanced computational efficiency. We note that the compared CrossFlow [53] uses high-quality proprietary data.

🔼 Figure 4 provides a detailed overview of the FlowTok framework. The top half illustrates the text-to-image generation process. Input text is first encoded into a high-dimensional vector representation (Tinit) using a CLIP text encoder. This vector is then projected into a lower-dimensional latent space, creating text tokens (ZT). These text tokens are transformed into image tokens (ZI) of the same dimensions via a flow matching process. Finally, a 1D Image VAE Decoder uses the image tokens to generate the final image. The bottom half demonstrates image-to-text generation. An input image is encoded into image tokens (ZI) by a 1D Image VAE Encoder. Through flow matching, these tokens are mapped to text tokens (ZT) which are then decoded by a text decoder to produce the final text. The figure highlights FlowTok’s efficiency compared to traditional methods, achieving a 3.3x compression rate by using a direct 1D transformation of both text and images, leading to reduced memory usage, faster training, and quicker inference.
read the caption
Figure 4: Overview of FlowTok. FlowTok is a minimal framework that facilitates seamless flow between 1D text tokens and image tokens for both text-to-image and image-to-text generation. Top: For text-to-image generation, the input text is encoded by the CLIP text encoder into 𝐓init∈ℝN×Csubscript𝐓initsuperscriptℝ𝑁𝐶\mathbf{T}_{\text{init}}\in\mathbb{R}^{N\times C}bold_T start_POSTSUBSCRIPT init end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_N × italic_C end_POSTSUPERSCRIPT, projected into a low-dimensional latent space as text tokens 𝐙T∈ℝN×Dsubscript𝐙Tsuperscriptℝ𝑁𝐷\mathbf{Z}_{\text{T}}\in\mathbb{R}^{N\times D}bold_Z start_POSTSUBSCRIPT T end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_N × italic_D end_POSTSUPERSCRIPT, then transformed into image tokens 𝐙I∈ℝN×Dsubscript𝐙Isuperscriptℝ𝑁𝐷\mathbf{Z}_{\text{I}}\in\mathbb{R}^{N\times D}bold_Z start_POSTSUBSCRIPT I end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_N × italic_D end_POSTSUPERSCRIPT of the same shape through flow matching and decoded by a 1D Image VAE Decoder to generate the final image. Bottom: For image-to-text generation, an input image is encoded by a 1D Image VAE Encoder into 𝐙Isubscript𝐙I\mathbf{Z}_{\text{I}}bold_Z start_POSTSUBSCRIPT I end_POSTSUBSCRIPT, mapped to 𝐙Tsubscript𝐙T\mathbf{Z}_{\text{T}}bold_Z start_POSTSUBSCRIPT T end_POSTSUBSCRIPT through flow matching and decoded into text via a text decoder. Unlike conventional approaches that rely on 2D noise and image latents (e.g., 32×32×43232432\times 32\times 432 × 32 × 4 for 256-resolution images) with text as conditions, our direct 1D transformation (i.e., 77×16771677\times 1677 × 16) achieves a 3.3×\times× compression rate, significantly reducing memory costs, accelerating training, and enabling faster inference.

🔼 This figure shows the FID (Fréchet Inception Distance) scores and inference speeds of different models on the COCO dataset. Panel (a) compares the FID scores against the training costs (measured in 8-A100 GPU days), illustrating the efficiency of FlowTok which achieves comparable FID scores with significantly reduced training costs compared to other models like SD-2.1 and CrossFlow. Panel (b) presents the FID scores against the inference speed (images per second), highlighting FlowTok’s superior inference efficiency with throughputs exceeding those of Show-o and CrossFlow.
read the caption
(a)

🔼 This figure shows the comparison of FID scores versus inference speed for various models. FlowTok’s superior efficiency is highlighted by its placement at the top-left. Compared to other methods, FlowTok achieves comparable FID scores while showing significantly faster inference speeds, demonstrating a major improvement in efficiency.
read the caption
(b)
More on tables
| method | params | open-data | T | I | COCO FID-30K | MJHQ-30K FID |
|---|---|---|---|---|---|---|
| text as conditions | ||||||
| GLIDE [58] | 5.0B | ✗ | - | - | 12.24 | - |
| Dalle2 [66] | 6.5B | ✗ | - | - | 10.39 | - |
| LlamaGen [78] | 775M | ✗ | - | - | - | 25.59 |
| PixArt- [17] | 630M | ✗ | 94.1 | 7.9 | 7.32 | 9.85 |
| SDXL [62] | 2.6B | ✗ | - | - | - | 8.76 |
| LDM [69] | 1.4B | ✓ | - | - | 12.63 | - |
| Stable-Diffusion-1.5 [69] | 860M | ✓ | 781.2 | - | 9.62 | - |
| Stable-Diffusion-2.1 [69] | 860M | ✓ | 1041.6 | - | 13.45 | 26.96 |
| Show-o [85] | 1.3B | ✓ | - | 1.0 | 9.24 | 14.99 |
| text as source distributions | ||||||
| CrossFlow [53] | 950M | ✗ | 78.8 | 1.1 | 9.63 | - |
| FlowTok-XL | 698M | ✓ | 20.4 | 22.7 | 10.06 | 7.68 |
| FlowTok-H | 1.1B | ✓ | 26.1 | 18.2 | 9.67 | 7.15 |
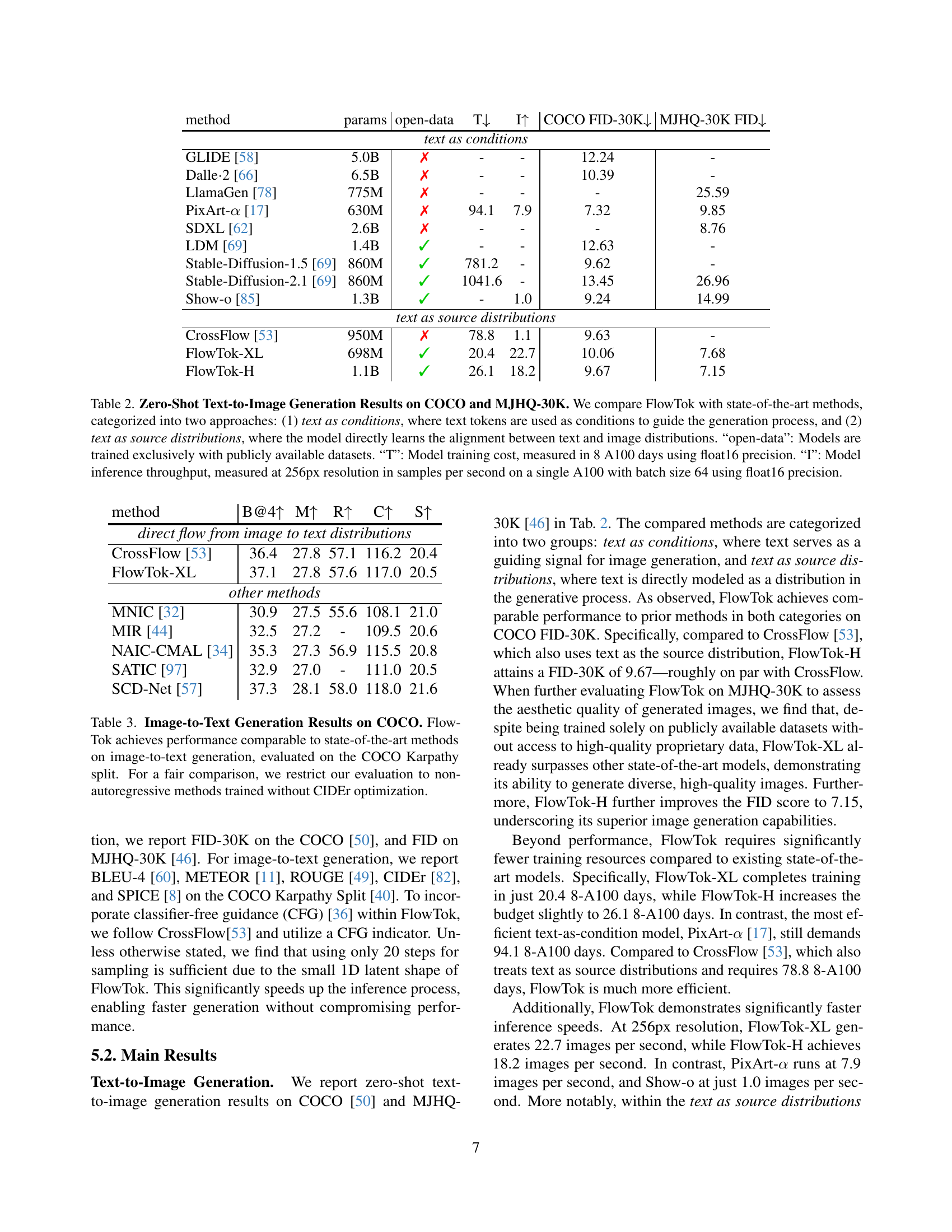
🔼 Table 2 presents a comparison of FlowTok’s performance in zero-shot text-to-image generation against other state-of-the-art models on two benchmark datasets: COCO and MJHQ-30K. The models are grouped into two categories based on their approach: those using text as conditions to guide image generation, and those directly learning the alignment between text and image distributions. The table also indicates whether models were trained solely on publicly available data (‘open-data’), the training cost in terms of 8 A100 GPU-days (‘T’), and inference speed (images per second) at 256px resolution using a single A100 GPU (‘I’). These metrics offer a comprehensive evaluation of both performance and efficiency.
read the caption
Table 2: Zero-Shot Text-to-Image Generation Results on COCO and MJHQ-30K. We compare FlowTok with state-of-the-art methods, categorized into two approaches: (1) text as conditions, where text tokens are used as conditions to guide the generation process, and (2) text as source distributions, where the model directly learns the alignment between text and image distributions. “open-data”: Models are trained exclusively with publicly available datasets. “T”: Model training cost, measured in 8 A100 days using float16 precision. “I”: Model inference throughput, measured at 256px resolution in samples per second on a single A100 with batch size 64 using float16 precision.
| method | B@4 | M | R | C | S |
|---|---|---|---|---|---|
| direct flow from image to text distributions | |||||
| CrossFlow [53] | 36.4 | 27.8 | 57.1 | 116.2 | 20.4 |
| FlowTok-XL | 37.1 | 27.8 | 57.6 | 117.0 | 20.5 |
| other methods | |||||
| MNIC [32] | 30.9 | 27.5 | 55.6 | 108.1 | 21.0 |
| MIR [44] | 32.5 | 27.2 | - | 109.5 | 20.6 |
| NAIC-CMAL [34] | 35.3 | 27.3 | 56.9 | 115.5 | 20.8 |
| SATIC [97] | 32.9 | 27.0 | - | 111.0 | 20.5 |
| SCD-Net [57] | 37.3 | 28.1 | 58.0 | 118.0 | 21.6 |
🔼 Table 3 presents a comparison of various image-to-text generation models, focusing on their performance on the COCO Karpathy split dataset. To ensure a fair comparison, only non-autoregressive models trained without CIDEr optimization are included in the results. The table shows that FlowTok’s performance is on par with state-of-the-art methods, demonstrating its effectiveness in this task.
read the caption
Table 3: Image-to-Text Generation Results on COCO. FlowTok achieves performance comparable to state-of-the-art methods on image-to-text generation, evaluated on the COCO Karpathy split. For a fair comparison, we restrict our evaluation to non-autoregressive methods trained without CIDEr optimization.
| target | COCO FID-30K |
|---|---|
| Ave Pool | 36.02 |
| MLP | 29.14 |
🔼 This table presents ablation studies on the text alignment loss function used in FlowTok, a text-to-image generation model. Three key aspects of the loss function are investigated: the alignment target, the choice of loss function (cosine similarity vs. contrastive loss), and the loss weight. The goal is to determine the optimal configuration for preserving semantic information and improving generation quality. The results are evaluated using the FID-30K metric on the COCO dataset with the FlowTok-B model, without classifier-free guidance (CFG).
read the caption
Table 4: Ablation Studies on Text Alignment Loss. We conduct comprehensive ablation studies on three key aspects of the text alignment loss ℒalignsubscriptℒalign\mathcal{L}_{\text{align}}caligraphic_L start_POSTSUBSCRIPT align end_POSTSUBSCRIPT: the alignment target (Tab. LABEL:tab:ablation_loss_target), the choice of loss function (Tab. LABEL:tab:ablation_loss_function), and the loss weight γ2subscript𝛾2\gamma_{2}italic_γ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT (Tab. LABEL:tab:ablation_loss_weight), aiming to identify the most effective strategy for preserving semantic information within FlowTok during text-to-image generation. For efficient verification, we report FID-30K on COCO using FlowTok-B, without applying the CFG indicator.
| loss type | COCO FID-30K |
|---|---|
| Cosine | 31.80 |
| Contrastive | 29.14 |
🔼 Table 5 details the datasets used to train the FlowTok model, specifically focusing on the filtering criteria applied to each dataset. These criteria include image resolution (aspect ratio less than 2 and the longer side of the image at least 256 pixels), aesthetic quality (images with predicted aesthetic scores above a certain threshold, specified in parentheses for each dataset), and the presence of watermarks (images with a predicted watermark probability above 0.5 were removed). The table notes that a re-captioned version of LAION-pop, provided by MaskGen [41], was used, incorporating improved captions.
read the caption
Table 5: Training Data Details. The filtering criteria applied include resolution (aspect ratio < 2 and longer side ≥\geq≥ 256), aesthetic score (predicted score exceeding the specified value in parentheses), and watermark detection (removal of images predicted to contain watermarks). ††\dagger†: We use the re-captioned version released by MaskGen [41], which contains improved captions.
| COCO FID-30K | |
|---|---|
| 1.0 | 29.14 |
| 2.0 | 30.59 |
🔼 This table details the hyperparameters used during the training process of the FlowTok model, providing specific values for both pre-training and fine-tuning phases. It includes settings for the optimizer (AdamW), optimizer parameters (beta1, beta2, weight decay), learning rate, learning rate scheduling, warmup steps, and batch size. The parameters are separated for pre-training and fine-tuning stages, reflecting potential differences in training strategies.
read the caption
Table 6: Training Hyper-parameters for FlowTok.
Full paper#