TL;DR#
Grounded video caption generation, which involves generating natural language descriptions for videos while simultaneously localizing key objects within the video using bounding boxes, is crucial for advancing areas like human-robot interaction. However, the lack of large-scale video datasets with dense spatio-temporal grounding has been a major bottleneck. Existing datasets either focus on localizing single objects or provide sparse annotations, limiting the potential for training robust models.
This work introduces a novel approach to tackle this challenge by presenting a large-scale automatic annotation method that aggregates captions and bounding boxes across individual frames into temporally dense and consistent annotations. They create HowToGround1M dataset and propose a Grounded Video Caption Generation model, dubbed GROVE, which is pre-trained on HowToGround1M and fine-tuned on the new iGround dataset. Experimental results demonstrate state-of-the-art performance on multiple datasets.
Key Takeaways#
Why does it matter?#
This paper is important for researchers as it addresses the gap in large-scale, densely annotated video datasets, enabling more effective training of video understanding models. The introduced GROVE model and iGround dataset set a new benchmark for grounded video captioning, offering a valuable resource and a strong foundation for future work in embodied perception and human-robot interaction.
Visual Insights#

🔼 This figure showcases the GROVE model’s output for an instructional video. The model generates a video-level caption (at the bottom) and highlights key objects mentioned in the caption with color-coded bounding boxes (at the top). These boxes track the objects consistently across different frames, even as the objects change size and position. Importantly, the model correctly identifies when a person is occluded, represented by the absence of a bounding box in frames where the person or their hand is not visible.
read the caption
Figure 1: Output of our GROunded Video caption gEneration (GROVE) model on an instructional video. The model outputs a video-level caption (bottom) with key noun phrases in the caption coloured and localised (grounded) in the video by temporally consistent bounding boxes (top). Note how the objects are consistently annotated (with the same color) despite changes in scale and viewpoint and how the person is marked as occluded (orange box not present) in frames 1 and 4 when the person (or their hand) is not visible.
| Dataset | Annot. | ||||
|---|---|---|---|---|---|
| Multiple | |||||
| Multi-object | |||||
| Num. | |||||
| Num. | |||||
| instances | |||||
| VidSTG [43] | Manual | ✓ | ✗ | 36.2K | 9.9M |
| HC-STVG [34] | Manual | ✓ | ✗ | 10.1K | 1.5M |
| ActivityNet-Entities [45] | Manual | ✗ | ✓ | 37.4K | 93.6K |
| HowToGround1M (Ours) | Automatic | ✓ | ✓ | 1M | 80.1M |
| iGround (Ours) | Manual | ✓ | ✓ | 2K | 236.9K |
🔼 This table compares the key characteristics of various video grounding datasets, including two newly introduced datasets: iGround and HowToGround1M. For each dataset, it shows the type of annotation (manual or automatic), whether multiple objects are annotated, whether multi-object grounding is performed, the number of frames, the number of videos, and the number of annotated instances. The table highlights the relative scale and annotation density of these datasets, demonstrating the size and quality of the datasets developed by the authors versus existing datasets.
read the caption
Table 1: Comparison of our two datasets iGround and HowToGround1M with state-of-the-art video grounding datasets.
In-depth insights#
Video GROVE Model#
The paper introduces GROVE, a novel model for grounded video caption generation. GROVE innovates by extending state-of-the-art image-based methods to the video domain. A key aspect is generating not just captions, but also temporally dense bounding boxes localizing noun phrases, along with an objectness score to handle occlusions and frame exits. GROVE employs spatio-temporal adapters with pooling for efficient video representation, leveraging pre-trained decoder weights and a dedicated temporal objectness head. This design enables the model to produce both informative captions and reliable spatio-temporal grounding in videos. This is critical for advancing areas such as human-robot interaction and embodied perception. The architecture builds upon GLaMM, adapting it for video with crucial modifications.
HowToGround1M#
HowToGround1M is a large-scale dataset derived from HowTo100M, automatically annotated for grounded video captioning. This addresses the limited training data issue by providing over 1M videos with captions and dense spatio-temporal bounding boxes. The dataset uses a pipeline of frame-wise captioning, video-level caption aggregation using LLMs, and temporal bounding box annotation. It’s designed for pre-training models like GROVE, to improve performance on video understanding tasks. By leveraging HowTo100M’s diverse content, it offers a wealth of annotated data for spatio-temporal reasoning in videos.
Spatio-Temporal#
Spatio-temporal considerations are crucial in video analysis, adding complexity compared to static images. Object tracking through time requires managing occlusions and viewpoint changes, ensuring consistent labeling. Models must capture both spatial relationships within each frame and temporal dynamics across frames. Datasets need dense annotations, going beyond sparse keyframes to capture continuous object presence. Methods that effectively integrate spatial and temporal information are key to achieving robust video understanding, but it is hard to evaluate the overall quality of annotations. Temporal coherence is essential for tasks like grounded captioning, where descriptions must align with the visual content across the video duration. Challenges lie in designing models that efficiently process sequential data and maintain consistency, especially when dealing with objects that temporarily disappear or undergo significant transformations.
Objectness Head#
The paper introduces a temporal objectness head to explicitly model objects that might temporarily leave the frame or become occluded in video, a crucial challenge for video-based grounded captioning. Unlike image-based object detection, where objectness aims to identify objects present, this temporal head predicts the visibility of an object at a given frame. This is achieved by predicting scores indicating presence or absence. During inference, a threshold is applied to these scores, selecting bounding boxes only when the objectness score exceeds the threshold. This mechanism is distinct from prior work and is tailored towards videos by handling partial visibility and occlusions, leading to more robust and temporally consistent grounding.
iGround Dataset#
The iGround dataset introduces manually annotated captions and densely grounded spatio-temporal bounding boxes for 3500 videos. With train/val/test splits, it enables progress measurement and fine-tuning, addressing the need for high-quality data in grounded video captioning. The dataset focuses on active objects humans interact with, rather than densely describing every scene object. Each bounding box is also annotated with a short phrase, linking vision and language. Manual annotation ensures greater precision, although it’s more time-consuming than automatic methods. iGround offers an avenue to improve existing models like GROVE and benchmark progress, offering a counterpoint to larger, automatically labeled datasets.
More visual insights#
More on figures

🔼 This figure illustrates a three-stage automatic annotation method for generating spatio-temporally grounded video captions. Stage 1 shows frame-wise grounded caption generation using a still-image model, resulting in temporally inconsistent outputs. Stage 2 aggregates these frame-level captions into a single, consistent video-level caption, focusing on the most important actions and objects. Finally, Stage 3 associates frame-level phrases and bounding boxes across time to create temporally consistent, dense bounding box annotations for the entire video.
read the caption
Figure 2: A method for automatic annotation of spatio-temporally grounded captions. In the first stage (left), we apply a still-image grounded caption generation model on individual video frames producing temporally inconsistent outputs. In the second stage (middle), the captions from individual frames are aggregated into a single video-level caption describing the most salient actions/objects in the video. Third (right), individual frame-level phrases and bounding boxes are associated over time into a temporally consistent and dense labelling of object bounding boxes over the video.

🔼 This figure illustrates the architecture of the GROVE model, which is designed for generating grounded video captions. Key components highlighted are spatio-temporal adapters that efficiently model temporal information in video, a bounding box decoder for generating spatially accurate bounding boxes, and a temporal objectness head to handle occluded or temporarily absent objects. The model takes a video clip as input and outputs a natural language caption along with spatio-temporal bounding boxes that ground the objects mentioned in the caption.
read the caption
Figure 3: An overview of our GROVE model for grounded video caption generation. Dashed red rectangles outline the key technical contributions enabling grounded caption generation in video and include: (i) spatio-temporal adapters; (ii) the bounding box decoder and (iii) the temporal objectness head.

🔼 This table presents a comparison of the performance of the GROVE model on the ActivityNet-Entities dataset [45], a benchmark dataset for spatio-temporal grounding. The comparison is done between three training scenarios: only fine-tuning (FT), only pre-training (PT), and both pre-training and fine-tuning (PT+FT). The results show that the model achieves improved performance (indicated by the metrics in the table, which are not included in this JSON since their detail is not provided in the question) when both pre-training and fine-tuning are employed, highlighting the benefit of large-scale pre-training using the automatically generated HowToGround1M dataset.
read the caption
Table 4: Results on the validation set of ActivityNet-Entities [45]. Large-scale pretraining (PT+FT) results in an improvement over fine-tuning only (FT) for our model GROVE.

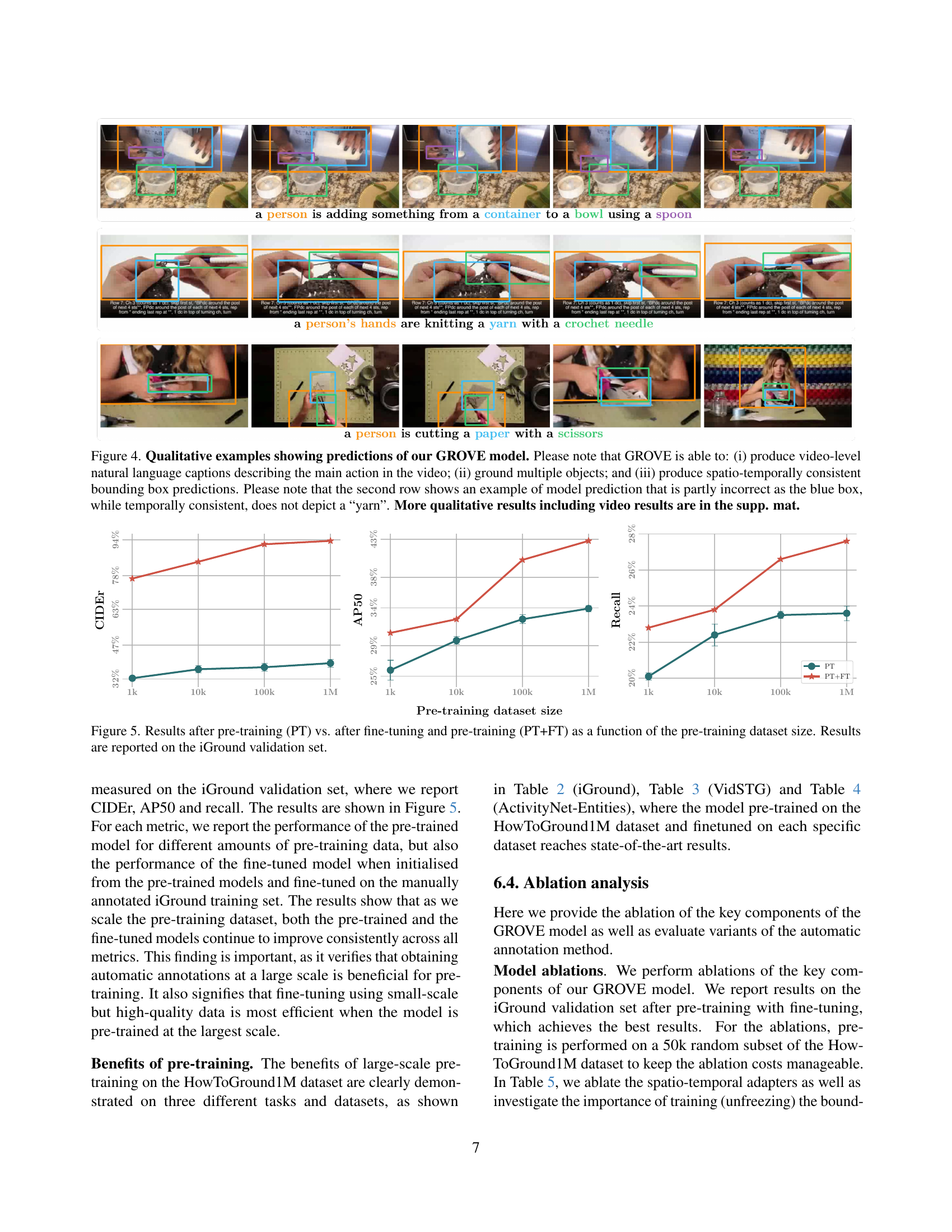
🔼 Figure 4 presents example outputs from the GROVE model, highlighting its ability to generate video-level captions that accurately describe the main action, ground multiple objects within the video by associating them with phrases in the caption, and maintain temporal consistency in the bounding box annotations across the video frames. The model successfully localizes objects even when there are changes in viewpoint or scale. However, the figure also points out a limitation where, in one instance, the temporal consistency of bounding boxes doesn’t perfectly align with the semantic meaning of the caption.
read the caption
Figure 4: Qualitative examples showing predictions of our GROVE model. Please note that GROVE is able to: (i) produce video-level natural language captions describing the main action in the video; (ii) ground multiple objects; and (iii) produce spatio-temporally consistent bounding box predictions. Please note that the second row shows an example of model prediction that is partly incorrect as the blue box, while temporally consistent, does not depict a “yarn”. More qualitative results including video results are in the supp. mat.

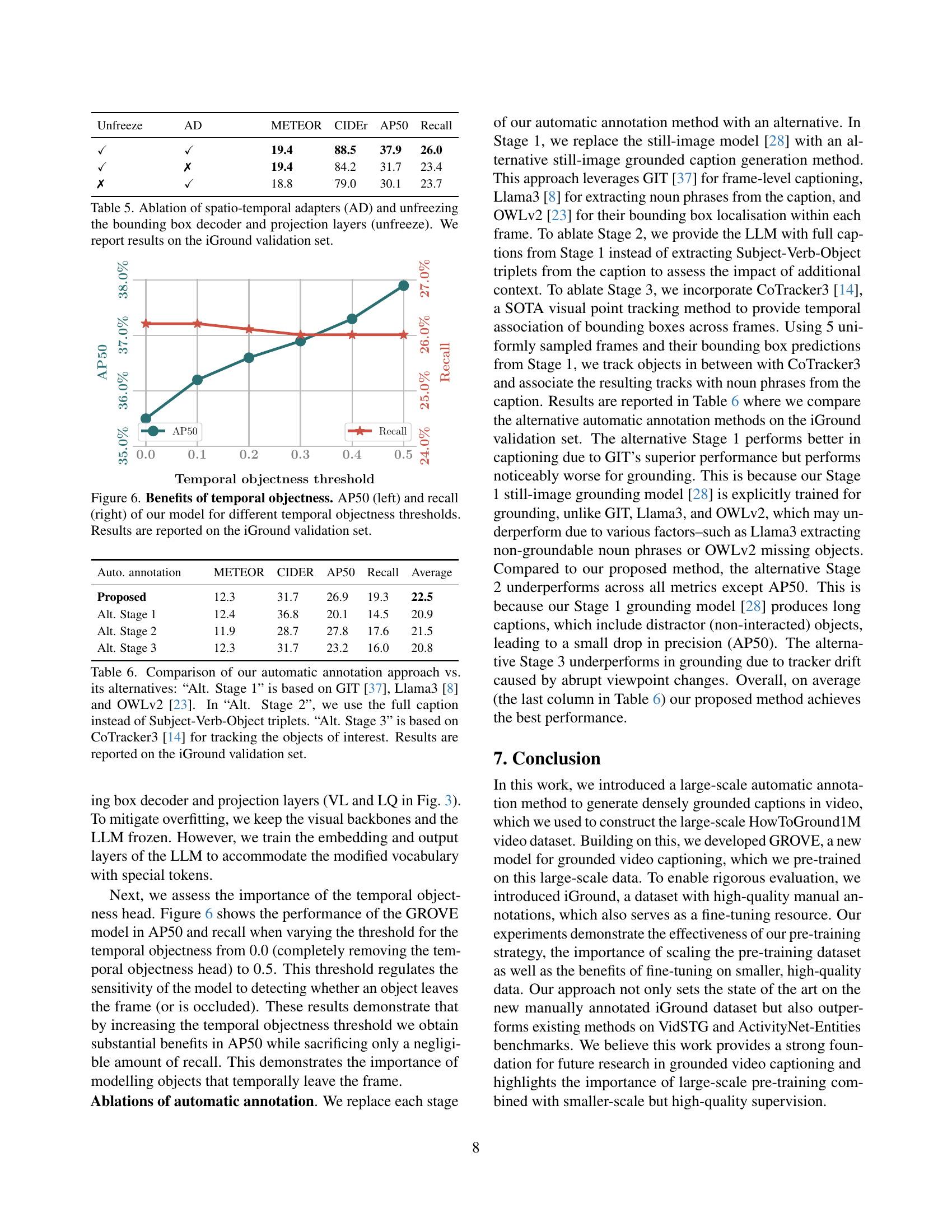
🔼 This figure shows the performance of the GROVE model on the iGround validation set as a function of the size of the pre-training dataset. Two scenarios are presented: one where the model is only pre-trained (PT) and another where it’s both pre-trained and fine-tuned (PT+FT) on the iGround dataset. The metrics used are CIDEr, AP50, and recall, all commonly used in image captioning and object detection tasks. The graph visually demonstrates how increasing the size of the pre-training data improves the model’s performance across all three metrics, highlighting the benefit of larger pre-training datasets for this task.
read the caption
Figure 5: Results after pre-training (PT) vs. after fine-tuning and pre-training (PT+FT) as a function of the pre-training dataset size. Results are reported on the iGround validation set.

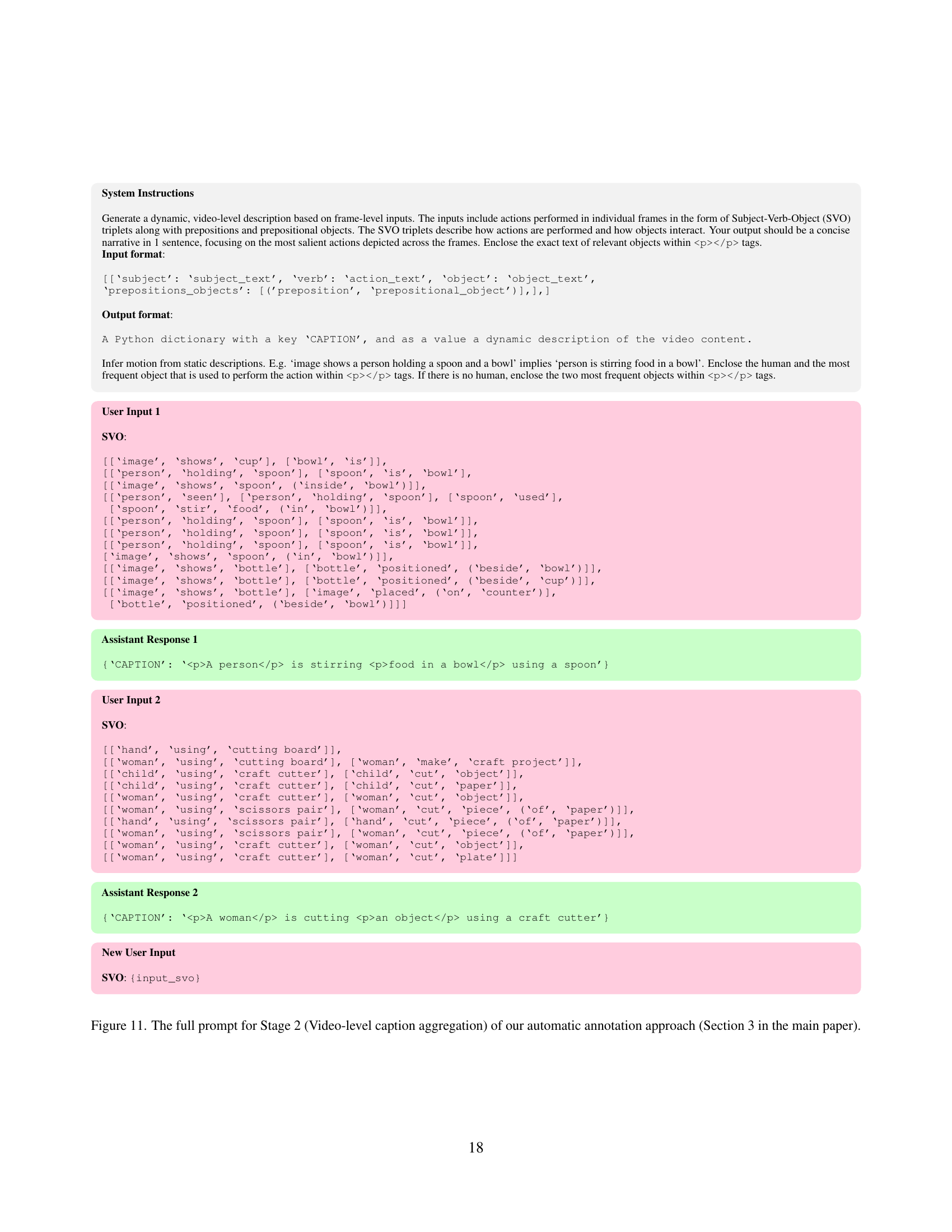
🔼 This ablation study investigates the impact of two key components of the GROVE model on the iGround validation set performance. The first component evaluated is the spatio-temporal adapters (AD), which help the model efficiently process spatio-temporal video information. The second component is the bounding box decoder and its associated projection layers. The table shows the model’s performance (measured by METEOR, CIDEr, AP50, and Recall) under different configurations: with both AD and unfreezing enabled, with only one of them enabled, and with neither enabled. This analysis reveals the contribution of each component to the overall accuracy and efficiency of the model.
read the caption
Table 5: Ablation of spatio-temporal adapters (AD) and unfreezing the bounding box decoder and projection layers (unfreeze). We report results on the iGround validation set.

🔼 This figure displays the impact of using a temporal objectness threshold on the performance of the GROVE model. The left panel shows the Average Precision at 50% Intersection over Union (AP50), while the right panel shows the recall, both evaluated on the iGround validation dataset. Different lines represent different thresholds applied to the temporal objectness scores, demonstrating how the model’s performance changes with varying thresholds for determining object presence/absence in a frame.
read the caption
Table 6: Benefits of temporal objectness. AP50 (left) and recall (right) of our model for different temporal objectness thresholds. Results are reported on the iGround validation set.

🔼 This table compares the performance of the proposed automatic annotation method with three alternative approaches. The alternatives modify different stages of the annotation pipeline. ‘Alt. Stage 1’ replaces the initial grounded caption generation stage with a combination of GIT [37] for generating captions, Llama3 [8] for extracting noun phrases and OWLv2 [23] for object localization. ‘Alt. Stage 2’ uses full frame-level captions in the caption aggregation step, instead of using just subject-verb-object triplets. Finally, ‘Alt. Stage 3’ substitutes the temporal bounding box association with CoTracker3 [14], a visual tracker. The evaluation metric used is the iGround validation set.
read the caption
Table 7: Comparison of our automatic annotation approach vs. its alternatives: “Alt. Stage 1” is based on GIT [37], Llama3 [8] and OWLv2 [23]. In “Alt. Stage 2”, we use the full caption instead of Subject-Verb-Object triplets. “Alt. Stage 3” is based on CoTracker3 [14] for tracking the objects of interest. Results are reported on the iGround validation set.
More on tables
| Method | METEOR | CIDER | AP50 | Recall | |
| Center | a. GLaMM [28] | 11.9 | 29.9 | 20.8 | 19.3 |
| b. GROVE - PT (Ours) | 14.5 | 49.9 | 26.7 | 23.0 | |
| c. GROVE - PT+FT (Ours) | 21.7 | 85.4 | 31.9 | 25.4 | |
| All | d. Automatic annotation | 13.8 | 40.0 | 27.1 | 20.4 |
| e. GROVE - PT (Ours) | 14.5 | 49.9 | 34.2 | 25.4 | |
| f. GROVE - FT (Ours) | 21.0 | 81.7 | 15.7 | 17.4 | |
| g. GROVE - PT+FT (Ours) | 21.7 | 85.4 | 40.8 | 28.6 |
🔼 This table presents the results of grounded video caption generation on the manually-annotated iGround test set. It compares the performance of the GROVE model with different training strategies: pre-training only (PT), fine-tuning only (FT), and pre-training followed by fine-tuning (PT+FT). The results are also compared against a baseline using the GLaMM model [28] and a method that directly applies automatic annotation. The evaluation metrics include METEOR, CIDEr, AP50, and Recall, and are shown separately for evaluations using only the center frame of videos and all frames. The results clearly show that the PT+FT strategy significantly outperforms other methods.
read the caption
Table 2: Grounded video caption generation on manually-annotated iGround test set. Pre-training on our new large-scale HowToGround1M dataset followed by finetuning on manually-annotated iGround training data (PT+FT) clearly outperforms pre-training only (PT) and finetuning only (FT) as well as the GLaMM baseline [28] (a.) and directly applying automatic annotation (d.). We show center frame (“Center”) and all frame (“All”) evaluation.
| Method | msIoU |
|---|---|
| STVGBert [32] | 47.3 |
| TubeDETR [39] | 59.0 |
| STCAT [13] | 61.7 |
| DenseVOC [46] | 61.9 |
| GROVE FT (Ours) | 61.3 |
| GROVE PT+FT (Ours) | 62.9 |
🔼 Table 3 presents a comparison of the GROVE model’s performance on the VidSTG [43] test set against other state-of-the-art spatial grounding models. All models utilize ground truth temporal localization. The table highlights that the GROVE model, when pre-trained at a large scale and then fine-tuned (PT+FT), significantly outperforms the same model trained only through fine-tuning (FT), demonstrating the benefits of large-scale pre-training.
read the caption
Table 3: State-of-the-art comparison of spatial grounding on the VidSTG [43] test set. All models use ground truth temporal localization. Large-scale pretraining (PT+FT) results in an improvement over fine-tuning only (FT) for our model GROVE.
| Method | F1all | F1all_per_sent | F1loc | F1loc_per_sent |
|---|---|---|---|---|
| GVD [45] | 07.10 | 17.30 | 23.80 | 59.20 |
| GROVE FT (Ours) | 09.51 | 21.15 | 30.96 | 68.79 |
| GROVE PT+FT (Ours) | 13.57 | 24.23 | 43.07 | 76.99 |
🔼 This table presents a comparison of the statistics for two datasets: HowToGround1M and iGround. HowToGround1M is a large-scale dataset automatically generated for pre-training a grounded video captioning model, while iGround is a smaller, manually annotated dataset used for fine-tuning and evaluation. The statistics shown include the average number of frames per video, average video duration, average number of instances (objects) per video, total number of instances, average bounding box dimensions (width x height), average length of object tracks (in frames), and the average length of captions (in words). These statistics highlight the differences in scale and annotation quality between the two datasets.
read the caption
Table 8: Statistics of HowToGround1M and iGround datasets.
Full paper#