TL;DR#
Collecting data for robots to learn tasks is expensive and time-consuming, particularly in real-world scenarios. Traditional methods passively record robot demonstrations, leading to redundant data and limited diversity. Recent methods attempt to address the issue by generating diversity through simulated environments or low-cost Universal Manipulation Interface grippers, but these methods face two fundamental limitations: the domain gap due to idealized physics and the impracticality of extending diversity to tele-operated systems.
To address these challenges, the paper introduces Adversarial Data Collection (ADC), a framework that uses real-time human-environment interactions to strategically inject controlled perturbations during data acquisition. This collaborative approach compresses diverse failure-recovery behaviors, task variations, and environmental changes into minimal demonstrations. Experiments show that models trained with just 20% of ADC data outperform traditional methods using full datasets, enhancing generalization, robustness, and error recovery.
Key Takeaways#
Why does it matter?#
This paper is crucial for robotics by introducing ADC, a method that slashes data needs while boosting robot skills. It addresses the pressing need for data efficiency in real-world robot learning, offering a practical solution to improve existing VLA models and opening doors for broader research into active data acquisition strategies.
Visual Insights#

🔼 Figure 1 illustrates three approaches to collecting real-world data for robotic imitation learning. (a) shows the traditional method, where a single human teleoperates the robot to perform a task based on a fixed instruction in a static environment. (b) introduces the Adversarial Data Collection (ADC) framework which utilizes two humans: one teleoperates the robot, while the other introduces dynamic perturbations during task execution. (c) details the ADC loop, highlighting how the adversarial operator introduces visual and linguistic changes to the environment and instructions, forcing the teleoperator to adapt and creating a much more information-dense demonstration.
read the caption
Figure 1: Comparative Analysis of the Real-Data Collection Loop in Robotic Manipulation. (a) Traditional Approach: A tele-operator executes tasks via fixed linguistic instructions in static visual environments. (b) Adversarial Data Collection (ADC) Framework: Employs a Two-Humans-in-the-Loop approach, where a secondary operator intervenes to perturb the primary’s execution dynamically when the tele-operator is executing a task. (c) ADC Loop: The adversarial operator introduces visual (backgrounds, object positions/poses) and linguistic (task goals) perturbations, shifting environmental context and target objects within a single episode.
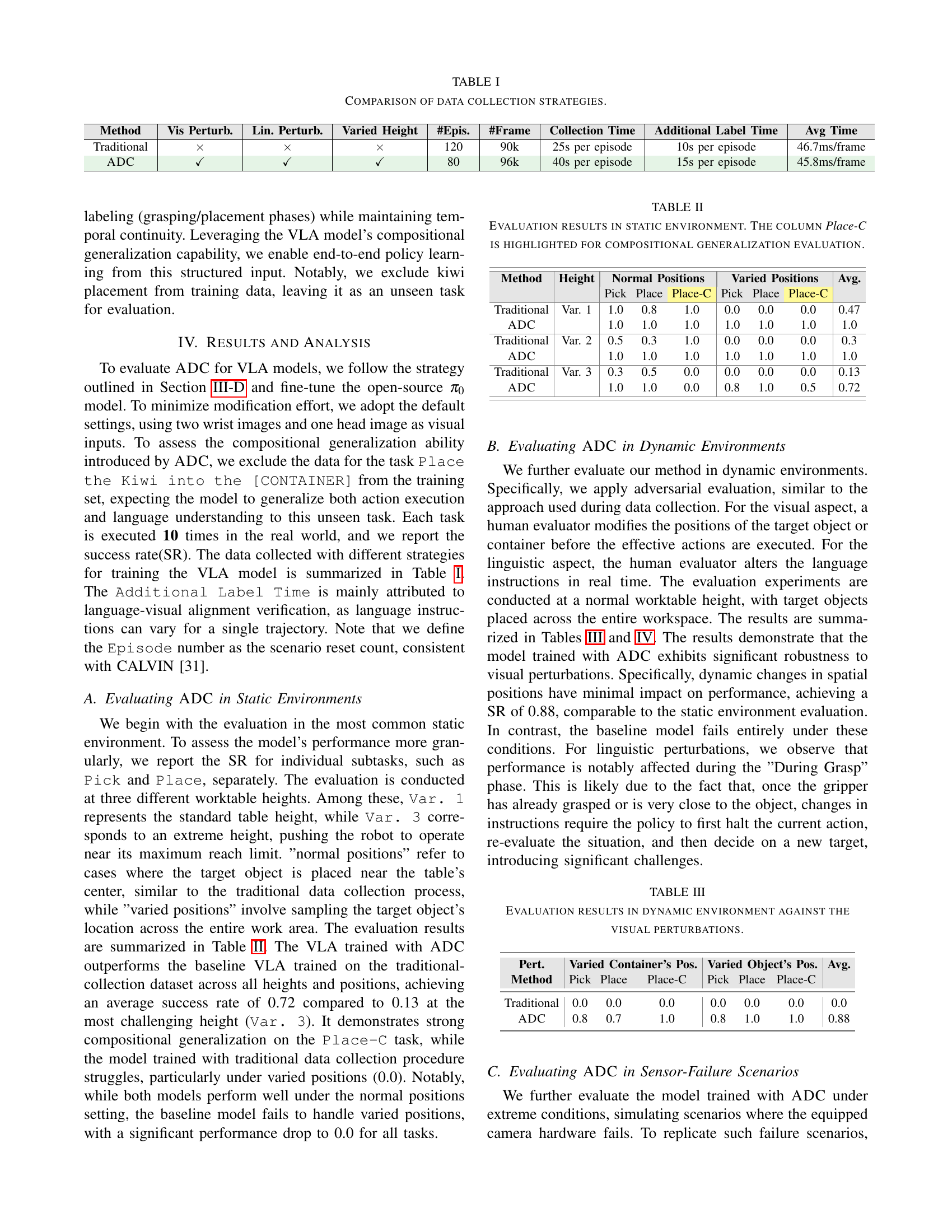
| Method | Vis Perturb. | Lin. Perturb. | Varied Height | #Epis. | #Frame | Collection Time | Additional Label Time | Avg Time |
|---|---|---|---|---|---|---|---|---|
| Traditional | 120 | 90k | 25s per episode | 10s per episode | 46.7ms/frame | |||
| ADC | ✓ | ✓ | ✓ | 80 | 96k | 40s per episode | 15s per episode | 45.8ms/frame |
🔼 This table compares two data collection strategies: the traditional approach and the proposed Adversarial Data Collection (ADC) method. It details the use of visual perturbations and linguistic perturbations in the ADC method, indicating whether they were used (X) or not. The table also shows the number of episodes, frames, and the average time spent per frame for data collection, as well as the additional time required for labeling with the ADC method.
read the caption
TABLE I: Comparison of data collection strategies.
In-depth insights#
Adversarial HiL#
The ‘Adversarial HiL’ framework introduces a novel approach to data collection by transforming conventional teleoperation into an adversarial Human-in-the-Loop process. This involves two key roles: a tele-operator and an adversarial operator, who collaboratively interact during data collection. The adversarial operator introduces controlled perturbations across visual and linguistic dimensions to maximize per-demonstration diversity, while preserving physical plausibility. This dynamic interaction forces the tele-operator to adapt in real-time, generating rich and diverse data units that include recovery behaviors, compositional task variations, and environmental perturbations. This approach aims to create more robust and generalizable models by exposing them to a wider range of scenarios during training, ultimately leading to more efficient and effective robotic learning.
Data Efficiency#
Data efficiency is critical in robot learning because collecting real-world data is expensive and time-consuming. The pursuit of efficient learning paradigms has led to the development of various techniques aimed at maximizing the information gained from each demonstration. The main idea is that high-quality data allows models to achieve better generalization and robustness with smaller datasets, thus reducing the overall cost and effort. The paper advocates for a shift in focus from simply scaling up the amount of training data to improving the informational density and diversity of the training data. This involves carefully designing data collection procedures to capture a wide range of task variations, failure recovery behaviors, and environmental perturbations. Maximizing the information density of individual demonstrations dramatically reduces the reliance on large-scale datasets while improving task performance.
VLA Robustness#
Vision-Language-Action (VLA) model robustness is a critical area in robotics, focusing on ensuring that robots can reliably perform tasks in the face of various challenges. The paper likely explores techniques to enhance VLA model robustness to perceptual ambiguities, linguistic variability, and physical uncertainties. Adversarial training with carefully designed perturbations in both the visual and linguistic domains is a key strategy. The results presented highlight the superior performance of ADC-trained models in handling ambiguous instructions, environmental perturbations, and unseen object configurations, showcasing the effectiveness of strategic data acquisition in improving VLA model robustness. The research demonstrates that VLA systems require more than just broad exposure to data, but an intentional, targeted curriculum emphasizing failure modes and recovery.
Dynamic HRI#
Dynamic Human-Robot Interaction (HRI) represents a critical frontier in robotics, shifting from static environments to collaborative spaces. Current VLA models face challenges in adapting to real-time human interventions. Robustness is crucial for seamless collaboration, requiring robots to provide dynamic and adaptive responses during task execution. Scenarios include humans moving target objects, necessitating continuous action adjustments. ADC demonstrates the ability for dynamic adaptation, enabling future HRI. This approach focuses on seamless integration with humans, where robots provide dynamic and adaptive responses during task execution, even under human intervention, requiring robots to provide dynamic and adaptive responses during task execution.
ADC: Key to HRI#
Adversarial Data Collection (ADC) holds significant promise for advancing Human-Robot Interaction (HRI). By introducing dynamic, human-driven perturbations, ADC cultivates robot robustness to environmental uncertainties and unexpected human actions. This contrasts with traditional methods focusing solely on static environments. Robots trained with ADC are better equipped to adapt in real-time to changing task goals, spatial redefinitions, and even physical disruptions, all vital for seamless human collaboration. This adaptation capability is a key prerequisite for effective HRI, allowing robots to provide dynamic, adaptive responses during task execution, even under human intervention. ADC equips robots with the ability to autonomously recover from failures which enhances their reliability and trustworthiness in collaborative settings.
More visual insights#
More on figures

🔼 Figure 2 illustrates the Adversarial Data Collection (ADC) process. It contrasts traditional data collection methods with ADC’s human-in-the-loop approach. Traditional methods passively record robot actions while ADC actively introduces dynamic visual (e.g., changing object positions, backgrounds) and linguistic (e.g., changing task instructions mid-episode) perturbations to increase data diversity. This process results in a dataset with higher information density, allowing for models trained on fewer samples to achieve better robustness and generalization on unseen tasks compared to models trained using traditional methods. The figure also visually represents how information density, coverage and completeness of observations are improved via ADC.
read the caption
Figure 2: The overview of ADC. During training data collection, we introduce several adversarial perturbations, including dynamic visual perturbations and adaptive linguistic challenges. These perturbations increase information density, expand state space coverage, and provide more complete observations of target objects. The resulting high-quality dataset enables the trained policy model to achieve strong robustness and generalization, outperforming models trained with conventional data collection strategies.

🔼 This figure shows the hardware setups used in the Adversarial Data Collection (ADC) experiments. Two robots are shown: the Aloha robot, used for conventional robotic policy experiments with various visual distractors to test robustness, and the AgiBot G1 robot, used for Vision-Language-Action (VLA) policy experiments which involved more complex and dynamic perturbations. This illustrates the different experimental conditions used to compare ADC with traditional methods.
read the caption
Figure 3: Hardware setup used in ADC for both data collection and evaluation experiments. The Aloha robot is employed for conventional robotic policy experiments, which include various visual distractors. The AgiBot G1 robot is utilized for the VLA policy experiments, where different dynamic perturbations are applied.

🔼 This figure compares attention maps of models trained on data collected using the Adversarial Data Collection (ADC) method versus a traditional method. Both models have one of their cameras masked. The attention maps show where the model focuses its attention when processing visual input. The ADC-trained model demonstrates a stronger ability to focus on the functional cameras (those that still provide useful information) even with a camera masked, highlighting its superior robustness and attention mechanism. In contrast, the traditionally-trained model shows less precise attention, paying attention to irrelevant features like table edges rather than the target object.
read the caption
Figure 4: Comparison of attention maps when one camera is masked. Models trained with ADC focus more precisely on functional cameras, demonstrating superior attention concentration compared to models trained with traditional data collection pipelines.

🔼 Figure 5 compares the visual observation coverage of the ‘Grasp the orange’ task between traditional data collection and the proposed Adversarial Data Collection (ADC) method. Traditional methods yield images of the orange from very similar viewpoints, limiting the diversity of visual data. In contrast, ADC uses dynamic perturbations to change the orange’s position and orientation during the task. This results in a much wider variety of viewpoints being captured in the dataset. This increased visual diversity from ADC is crucial for building more robust and generalizable robotic models. The improved generalization is because the models trained on the varied viewpoints from ADC can better adapt to new or unseen scenarios.
read the caption
Figure 5: Comparison of observation coverage for the task ”Grasp the orange.” In the traditional data collection process, the target object (orange) is observed from similar viewpoints, resulting in limited visual diversity. In contrast, ADC introduces dynamic perturbations, allowing the orange to be observed from a wider range of viewpoints. This leads to greater visual variation in the ADC dataset, improving model robustness and generalization.

🔼 Figure 6 showcases the dynamic human-robot interaction (HRI) scenarios used to test the robot’s ability to grasp a moving object. A human hand holds the fruit (the target object), and the human moves their hand during the grasping process, making the task significantly more challenging. The experiment was repeated across various scenes to further test the model’s robustness.
read the caption
Figure 6: Dynamic Human-Robot Interaction (HRI) scenarios. The robot is tasked with grasping the target fruit from the human hand, where the human’s hand may move during the manipulation tasks. Evaluation experiments are conducted across different scenes.

🔼 This figure shows a real-time demonstration of an autonomous failure recovery mechanism in a robot performing a grasping task. The robot initially attempts to grasp a peach but loses contact. It then automatically adjusts its grip parameters, performs a precise regrasp, and successfully completes the task. This demonstrates the robustness and adaptability of the robot’s control system, which has been trained using the Adversarial Data Collection (ADC) method.
read the caption
Figure 7: Autonomous Failure Recovery in ADC-Trained Robotic Grasping: Real-time demonstration of failure recovery after empty grasp. Following initial contact loss during peach acquisition, the system autonomously recalibrates grip pose parameters and executes a precision-aligned regrasp to complete the task.
More on tables
| Method | Height | Normal Positions | Varied Positions | Avg. | ||||
|---|---|---|---|---|---|---|---|---|
| Pick | Place | Place-C | Pick | Place | Place-C | |||
| Traditional | Var. 1 | 1.0 | 0.8 | 1.0 | 0.0 | 0.0 | 0.0 | 0.47 |
| ADC | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | |
| Traditional | Var. 2 | 0.5 | 0.3 | 1.0 | 0.0 | 0.0 | 0.0 | 0.3 |
| ADC | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | |
| Traditional | Var. 3 | 0.3 | 0.5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.13 |
| ADC | 1.0 | 1.0 | 0.0 | 0.8 | 1.0 | 0.5 | 0.72 | |
🔼 This table presents the results of evaluating different methods for robotic manipulation in static environments. It compares the success rates of a traditional approach and the proposed Adversarial Data Collection (ADC) method across various conditions. These conditions include different table heights (Var. 1, Var. 2, Var. 3 representing standard height, medium height and extreme height) and object placement positions (normal vs. varied positions). The ‘Place-C’ column is particularly important as it assesses compositional generalization – the ability of the model to perform a task (placing an object into a container) it has not explicitly been trained on, demonstrating the learned generalization capability.
read the caption
TABLE II: Evaluation results in static environment. The column Place-C is highlighted for compositional generalization evaluation.
| Pert. | Varied Container’s Pos. | Varied Object’s Pos. | Avg. | ||||
|---|---|---|---|---|---|---|---|
| Method | Pick | Place | Place-C | Pick | Place | Place-C | |
| Traditional | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ADC | 0.8 | 0.7 | 1.0 | 0.8 | 1.0 | 1.0 | 0.88 |
🔼 This table presents the results of evaluating the performance of robotic policies trained with and without adversarial data collection (ADC) in dynamic environments where visual perturbations are introduced. The visual perturbations include changes to the position of the target objects and the containers. The table shows the success rates for different tasks (Pick, Place, Place-C which indicates compositional generalization) under varied conditions. The goal is to demonstrate the robustness of ADC-trained policies to these visual disruptions.
read the caption
TABLE III: Evaluation results in dynamic environment against the visual perturbations.
| Pert. Time | Before Grasp. | During Grasp. | After Grasp. | ||||
|---|---|---|---|---|---|---|---|
| Methods | Pick | Place | Pick | Place | Pick | Place | |
| Traditional | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | |
| ADC | 1.0 | 1.0 | 0.6 | 0.7 | 1.0 | 1.0 | |
🔼 This table presents the results of evaluating the performance of robotic policies trained with and without adversarial data collection (ADC) in dynamic environments where linguistic perturbations are introduced. It shows the success rate (SR) for different subtasks (Pick, Place, Place-C, which refers to a composite task) under various conditions: before, during, and after the grasp. This allows for analysis of how well each policy handles changes in instructions mid-task execution.
read the caption
TABLE IV: Evaluation results in dynamic environment against the linguistic perturbations.
| Masked Cam. | Right Wrist | Head | Avg. | |||
|---|---|---|---|---|---|---|
| Methods | Pick | Place-AB | Pick | Place-AB | ||
| Traditional | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | |
| ADC | 0.6 | 0.5 | 0.7 | 0.4 | 0.55 | |
🔼 Table V presents the performance of models trained with traditional data collection methods and the proposed Adversarial Data Collection (ADC) method when one or more cameras are masked during evaluation. It assesses the models’ robustness to sensor failures in a static environment by measuring their success rate on the ‘Pick’ and ‘Place’ subtasks. The table evaluates performance under three different masked camera scenarios: masking only the head camera, masking only the right wrist camera, and masking all cameras. The results demonstrate the impact of ADC on the resilience of the robotic manipulation model in the face of sensor limitations.
read the caption
TABLE V: Evaluation results with masked cameras in static environment.
| Static Env. | Dynamic Env. | ||||
|---|---|---|---|---|---|
| Dataset Receipt | Pick | Place | Pick | Place | Avg. |
| 100% Traditional | 0.5 | 0.45 | 0.0 | 0.0 | 0.24 |
| 20% Ours | 0.5 | 0.75 | 0.58 | 0.75 | 0.65 |
| 50% Ours | 0.83 | 0.75 | 0.63 | 0.75 | 0.74 |
| 100% Ours | 0.9 | 0.875 | 0.83 | 0.94 | 0.89 |
🔼 This table presents a comparison of model performance using different datasets in both static and dynamic robotic manipulation environments. It shows the success rate (SR) of picking and placing objects in various conditions. These conditions include variations in object positions and heights (static), and the introduction of dynamic visual and linguistic perturbations (dynamic). The table compares the performance of models trained on 100%, 50%, and 20% of the Adversarial Data Collection (ADC) dataset, as well as a model trained on the traditional dataset (100% Traditional). This allows for an analysis of the data efficiency of the ADC method.
read the caption
TABLE VI: Performance comparison of different datasets in static and dynamic environments.
Full paper#