TL;DR#
Existing camera control studies primarily focus on text or image-conditioned video generation. Altering camera trajectories in existing videos remains underexplored due to the challenge of maintaining frame appearance and dynamic synchronization. Current methods are limited by domain-specific training data or require per-video optimization, hindering their applicability to real-world scenarios.
To address the issues, the study introduces a framework that reproduces dynamic scenes with novel camera trajectories. It harnesses generative capabilities through a video conditioning mechanism, often overlooked in current research. The scarcity of qualified training data is addressed by constructing a multi-camera synchronized video dataset. The study improves robustness through a training strategy, outperforming existing approaches.
Key Takeaways#
Why does it matter?#
This work introduces a novel approach to camera-controlled video generation, expanding creative possibilities and enabling applications like video stabilization and super-resolution. The release of their dataset and method is poised to impact video manipulation research.
Visual Insights#

🔼 This figure showcases example videos generated by ReCamMaster, demonstrating its ability to re-render source videos from novel camera perspectives. For each example, the figure presents both the original source video frame and the corresponding video frame generated by ReCamMaster using a new camera trajectory. The novel camera paths are also visualized next to the frames, providing a clear illustration of the camera movement employed during the video re-rendering process. Additional video results can be found on the project website.
read the caption
Figure 1: Examples synthesized by ReCamMaster. ReCamMaster re-shoots the source video with novel camera trajectories. We visualized the novel camera trajectories alongside the video frames. Video results are on our project page.
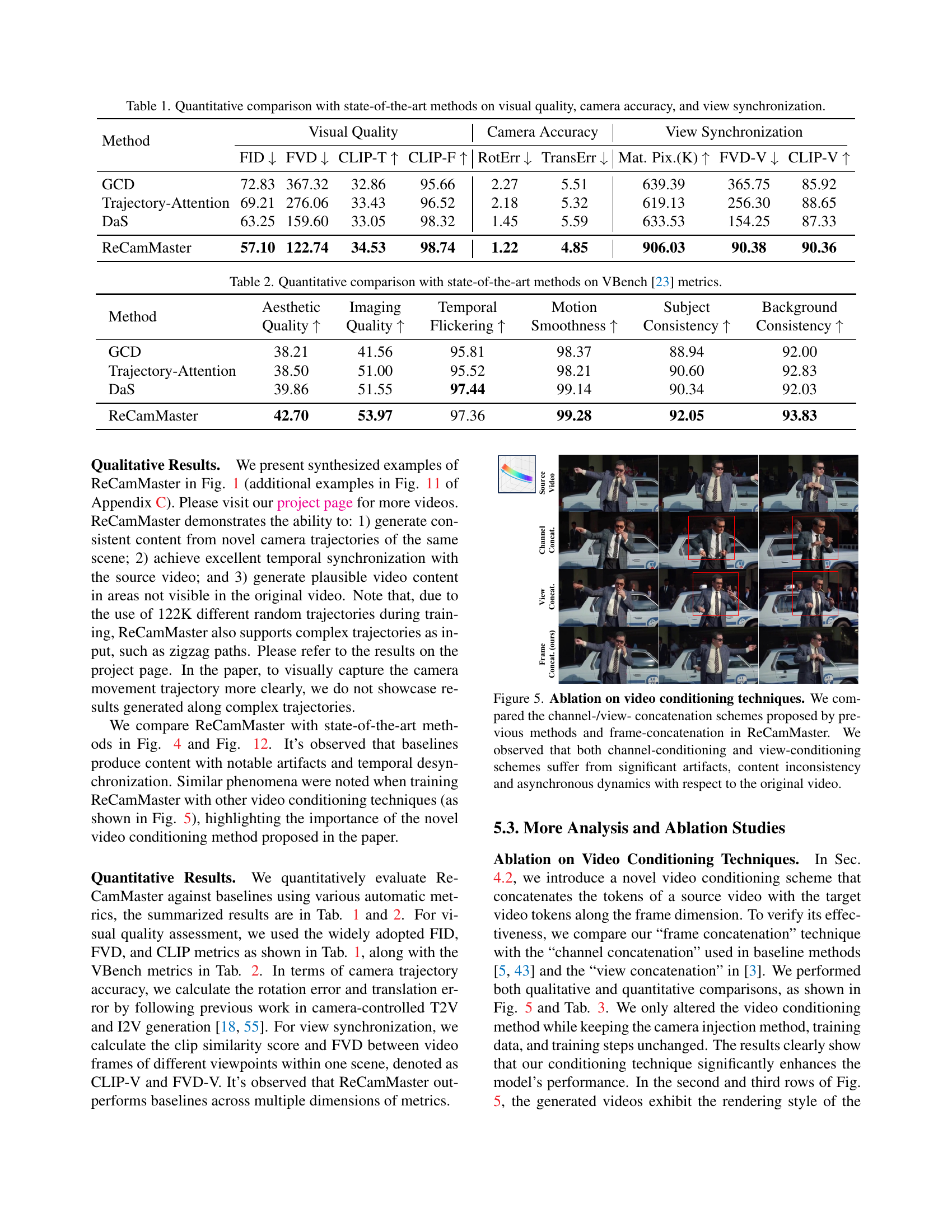
| Method | Visual Quality | Camera Accuracy | View Synchronization | ||||||
| FID | FVD | CLIP-T | CLIP-F | RotErr | TransErr | Mat. Pix.(K) | FVD-V | CLIP-V | |
| GCD | 72.83 | 367.32 | 32.86 | 95.66 | 2.27 | 5.51 | 639.39 | 365.75 | 85.92 |
| Trajectory-Attention | 69.21 | 276.06 | 33.43 | 96.52 | 2.18 | 5.32 | 619.13 | 256.30 | 88.65 |
| DaS | 63.25 | 159.60 | 33.05 | 98.32 | 1.45 | 5.59 | 633.53 | 154.25 | 87.33 |
| ReCamMaster | 57.10 | 122.74 | 34.53 | 98.74 | 1.22 | 4.85 | 906.03 | 90.38 | 90.36 |
🔼 This table presents a quantitative comparison of ReCamMaster against three state-of-the-art methods (GCD, Trajectory-Attention, and DaS) across various metrics. These metrics assess three key aspects: visual quality (FID, FVD, CLIP-T, CLIP-F), camera accuracy (RotErr, TransErr), and view synchronization (Mat.Pix, FVD-V, CLIP-V). Lower FID and FVD scores indicate better visual quality, while higher CLIP-T and CLIP-F scores represent better text-image and temporal consistency. Lower rotation error (RotErr) and translation error (TransErr) denote higher camera accuracy. Higher values for Mat. Pix, CLIP-V and lower FVD-V indicate better view synchronization. The table allows for a detailed comparison of the performance of ReCamMaster relative to existing approaches on these important aspects of camera-controlled video generation.
read the caption
Table 1: Quantitative comparison with state-of-the-art methods on visual quality, camera accuracy, and view synchronization.
In-depth insights#
Novel Camera Trajectory#
Novel camera trajectories represent a significant frontier in video manipulation. Traditional video focuses on content generation or style transfer, this explores modifying the very viewpoint. The goal is to re-shoot a video without physically doing so. This involves challenges such as maintaining consistency across frames, and dynamic elements. This requires sophisticated algorithms that consider the temporal coherence of the video and how lighting/occlusion changes with view. Datasets with multi-view videos of the same dynamic scene can boost model training and generalization on in-the-wild videos. Novel trajectories offer creative potential, enabling users to reframe existing videos in new ways.
Sync’ed Dataset#
Creating a synchronized dataset is crucial for video-related tasks, particularly when dealing with camera control and novel view synthesis. The core idea revolves around capturing or generating multiple views of the same dynamic scene simultaneously. This allows models to learn consistent 4D representations, ensuring that generated videos maintain visual fidelity and temporal coherence across different viewpoints. The synthetic data generation offers precise control over camera parameters, perfect synchronization, and scalability, albeit potentially introducing a domain gap. High-quality datasets, which involves curating diverse scenes and realistic camera movements is essential to bridge such gap and boost the model’s ability to generalize to the real world. A large-scale, multi-camera setup enables the training of robust models capable of handling varied camera trajectories and in-the-wild scenarios.
Video Conditioning#
Video conditioning is crucial for adapting pre-trained text-to-video models for tasks like camera-controlled video generation. The success hinges on how effectively the source video’s information is injected into the generation process. Approaches vary, from channel-wise concatenation of latent features to more sophisticated attention mechanisms. Effective video conditioning should maintain the source video’s content while allowing for modifications specified by the new camera trajectory. Finding the right balance between preserving information and allowing for flexibility is key for high-quality results. Frame-level concatenation is a potential solution for robust spatio-temporal awareness.
Robustness Training#
Robustness training is a critical aspect of ensuring the reliability of machine learning models. Techniques like adversarial training are employed to fortify models against input perturbations. Augmenting training data with variations enhances the model’s ability to generalize across diverse conditions. Regularization methods, such as dropout or weight decay, prevent overfitting and promote stable representations. Moreover, robust training often involves careful optimization strategies and architectural choices to mitigate vulnerabilities. The goal is to develop models that exhibit consistent performance even when faced with noisy or unconventional data, ensuring trustworthy deployment in real-world scenarios.
T2V Limitations#
Considering the current progress in text-to-video (T2V) generation, several limitations are apparent. One major challenge lies in achieving high visual fidelity and temporal coherence simultaneously. Models often struggle to maintain consistent object appearance and scene dynamics across multiple frames, resulting in flickering or unrealistic transitions. Another key constraint is the limited control over camera movements and viewpoints. While some methods allow basic camera adjustments, generating complex or user-specified trajectories remains difficult. Furthermore, T2V models typically struggle with generating fine-grained details and realistic human actions, particularly hand movements and facial expressions. Overcoming these limitations is crucial for creating more immersive and controllable video content.
More visual insights#
More on figures

🔼 Figure 2 illustrates the creation of a high-quality, multi-camera synchronized video dataset using Unreal Engine 5. The process involves four key steps: (a) selecting diverse 3D environments; (b) choosing a variety of characters; (c) utilizing numerous animations; and (d) generating massive camera trajectories. These elements are combined to create a dataset that closely mimics real-world filming conditions, offering a rich variety of scenes and camera movements.
read the caption
Figure 2: Illustration of the dataset construction process. We build the multi-camera synchronized training dataset by rendering in Unreal Engine 5. This is achieved using 3D environments, characters, animations collected from the internet, and our designed massive camera trajectories.

🔼 Figure 3 provides a comprehensive overview of the ReCamMaster model. The left panel illustrates the training process, where a latent diffusion model learns to reconstruct a target video (Vt) based on three inputs: the source video (Vs), the target camera trajectory (camt), and a text prompt (pt). The right panel presents a comparison of three distinct video conditioning techniques: (a) Frame-dimension conditioning (used in this paper), which concatenates source and target video tokens along the frame dimension; (b) Channel-dimension conditioning (used in baseline methods), which concatenates source and target latent videos along the channel dimension; and (c) View-dimension conditioning (from another study), which introduces a specialized attention module for feature aggregation across multiple views.
read the caption
Figure 3: Overview of ReCamMaster. Left: The training pipeline of ReCamMaster. A latent diffusion model is optimized to reconstruct the target video Vtsubscript𝑉𝑡V_{t}italic_V start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT, conditioned on the source video Vssubscript𝑉𝑠V_{s}italic_V start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPT, target camera pose camt𝑐𝑎subscript𝑚𝑡cam_{t}italic_c italic_a italic_m start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT, and target prompt ptsubscript𝑝𝑡p_{t}italic_p start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT. Right: Comparison of different video condition techniques. (a) Frame-dimension conditioning used in our paper; (b) Channel-dimension conditioning used in baseline methods [43, 5]; (c) View-dimension conditioning in [3]. We omit the text prompt ptsubscript𝑝𝑡p_{t}italic_p start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT in (a)-(c) for simplicity.

🔼 Figure 4 presents a comparison of video generation results between ReCamMaster and three state-of-the-art methods (GCD, Trajectory Attention, and DaS). For each method, the figure shows a source video frame and the corresponding frames generated using that method for the same camera trajectory. The purpose of the figure is to visually demonstrate that ReCamMaster better preserves the appearance consistency and temporal synchronization with the original video compared to other methods.
read the caption
Figure 4: Comparison with state-of-the-art methods. It shows that ReCamMaster generates videos that maintain appearance consistency and temporal synchronization with the source video.

🔼 This figure presents an ablation study comparing different video conditioning techniques used in video generation models. Three methods are compared: channel-dimension conditioning, view-dimension conditioning, and the frame-dimension conditioning proposed by the authors (ReCamMaster). The results show that channel and view conditioning lead to significant artifacts in the generated videos, including inconsistencies in content and timing (asynchronous dynamics) compared to the original source video. In contrast, frame-dimension conditioning produces superior results.
read the caption
Figure 5: Ablation on video conditioning techniques. We compared the channel-/view- concatenation schemes proposed by previous methods and frame-concatenation in ReCamMaster. We observed that both channel-conditioning and view-conditioning schemes suffer from significant artifacts, content inconsistency and asynchronous dynamics with respect to the original video.

🔼 This figure showcases three applications of the ReCamMaster model: video stabilization, video super-resolution, and video outpainting. The top row demonstrates video stabilization, showing how ReCamMaster smooths out shaky camera movements in a video clip. The middle row shows video super-resolution, where ReCamMaster enhances the resolution of a video clip, revealing finer details. Finally, the bottom row displays video outpainting, illustrating ReCamMaster’s ability to expand the boundaries of a video frame, creating new content beyond the original scene.
read the caption
Figure 6: Applications of ReCamMaster. From top to bottom: video stabilization, video super-resolution, and video outpainting.

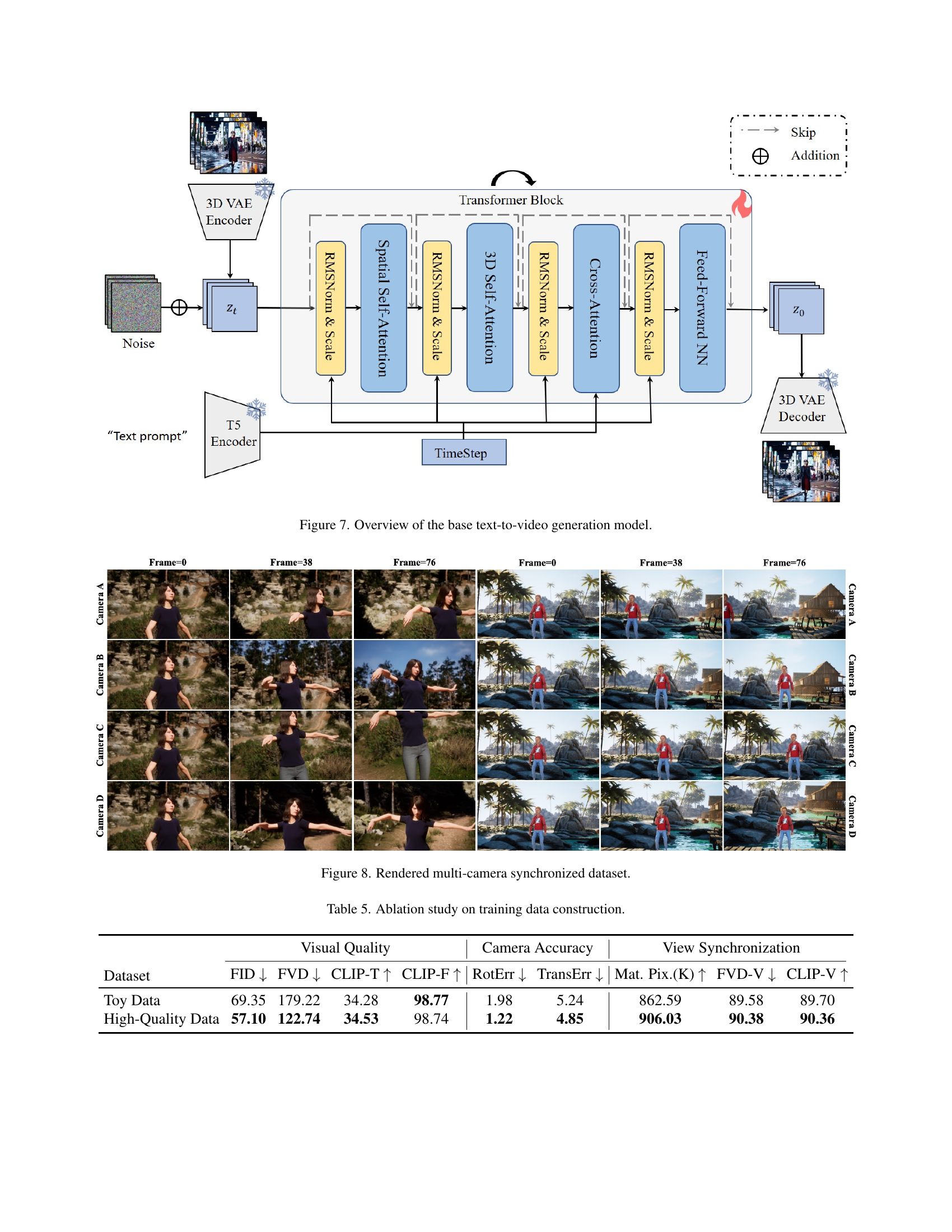
🔼 This figure provides a detailed illustration of the base text-to-video generation model used in the ReCamMaster framework. The model’s architecture is shown as a pipeline, beginning with a 3D Variational Autoencoder (VAE) that encodes the input video into a latent space. This latent representation then passes through several Transformer blocks which incorporate spatial, temporal, and cross-attention mechanisms. These attention mechanisms allow the model to effectively capture the spatiotemporal relationships within the video data. Finally, the model uses a 3D VAE decoder to reconstruct the video in the original pixel space. Time step information is also incorporated, demonstrating a diffusion process. The inclusion of a ’text prompt’ input indicates that text-based conditioning is also part of this model architecture.
read the caption
Figure 7: Overview of the base text-to-video generation model.

🔼 This figure shows a sample of videos from the dataset created using Unreal Engine 5. The dataset consists of synchronized multi-camera videos with diverse camera trajectories, featuring various scenes and actions. This dataset is crucial for training ReCamMaster, the proposed model which enables camera-controlled video generation.
read the caption
Figure 8: Rendered multi-camera synchronized dataset.

🔼 This figure demonstrates the versatility of the ReCamMaster model. It showcases successful camera-controlled video generation across three distinct tasks: Text-to-Video (T2V), Image-to-Video (I2V), and Video-to-Video (V2V). Each row displays a source video (left) and its corresponding ReCamMaster-generated video (right), illustrating the model’s ability to produce realistic and temporally coherent results regardless of the input type or task.
read the caption
Figure 9: Unify camera-controlled tasks with ReCamMaster. ReCamMaster supports T2V, I2V, and V2V camera-controlled generation.

🔼 Figure 10 presents examples where the ReCamMaster model’s generation process fails. These failures highlight limitations inherited from the underlying text-to-video model, particularly in generating small objects or intricate hand movements with high fidelity. The image showcases specific instances where these limitations are evident.
read the caption
Figure 10: Visualization of failure cases.

🔼 This figure shows more examples of videos synthesized by the ReCamMaster model. Each row displays a source video and its corresponding videos generated with novel camera trajectories. The camera trajectories are visualized alongside the video frames, illustrating the model’s ability to re-render the input video from new perspectives and angles while maintaining consistency with the original video’s content and temporal dynamics.
read the caption
Figure 11: More synthesized results of ReCamMaster.
More on tables
| Method | Aesthetic Quality | Imaging Quality | Temporal Flickering | Motion Smoothness | Subject Consistency | Background Consistency |
| GCD | 38.21 | 41.56 | 95.81 | 98.37 | 88.94 | 92.00 |
| Trajectory-Attention | 38.50 | 51.00 | 95.52 | 98.21 | 90.60 | 92.83 |
| DaS | 39.86 | 51.55 | 97.44 | 99.14 | 90.34 | 92.03 |
| ReCamMaster | 42.70 | 53.97 | 97.36 | 99.28 | 92.05 | 93.83 |
🔼 This table presents a quantitative comparison of ReCamMaster against state-of-the-art methods using the VBench metrics. VBench provides a comprehensive evaluation of video generation models across various aspects, including aesthetic quality, image quality, temporal consistency, motion smoothness, subject consistency, and background consistency. The comparison allows for a detailed assessment of ReCamMaster’s performance relative to other leading approaches in terms of the overall quality and visual fidelity of generated videos.
read the caption
Table 2: Quantitative comparison with state-of-the-art methods on VBench [23] metrics.
| Method | Visual Quality | Camera Accuracy | View Synchronization | ||||||
| FID | FVD | CLIP-T | CLIP-F | RotErr | TransErr | Mat. Pix.(K) | FVD-V | CLIP-V | |
| Channel dim. | 74.09 | 187.94 | 33.70 | 98.67 | 1.28 | 4.98 | 521.10 | 148.51 | 84.62 |
| View dim. | 80.51 | 194.47 | 34.66 | 98.71 | 1.42 | 5.77 | 573.92 | 177.68 | 83.40 |
| Frame dim. (ours) | 57.10 | 122.74 | 34.53 | 98.74 | 1.22 | 4.85 | 906.03 | 90.38 | 90.36 |
🔼 This table presents a quantitative comparison of three different video conditioning strategies used in the ReCamMaster model. The strategies compared are: Channel dimension conditioning, View dimension conditioning, and Frame dimension conditioning (the proposed method). The metrics used for comparison include visual quality (FID, FVD, CLIP-T, CLIP-F), camera accuracy (Rotation Error, Translation Error), and view synchronization (Matching Pixels, FVD-V, CLIP-V). Lower FID and FVD scores indicate better visual quality, while higher CLIP-T and CLIP-F scores, Matching Pixels, and CLIP-V scores suggest better synchronization and higher quality. Lower Rotation Error and Translation Error values indicate better camera accuracy.
read the caption
Table 3: Quantitative comparison on the video conditioning strategy.
| Method | FID | FVD | Aesthetic Quality | Imaging Quality |
| Baseline | 66.67 | 171.80 | 40.02 | 51.93 |
| + 3D-Attn. tuning | 59.47 | 132.58 | 43.08 | 52.80 |
| + Drop latent | 62.39 | 149.52 | 41.47 | 52.65 |
| + Both | 57.10 | 122.74 | 42.70 | 53.97 |
🔼 This table presents an ablation study on the training strategies used in the ReCamMaster model. It shows the impact of different training techniques on the model’s performance, as measured by FID, FVD, aesthetic quality, and imaging quality. The strategies compared include a baseline approach, adding 3D-attention tuning, dropping source latent, and combining both 3D-attention tuning and dropping source latent.
read the caption
Table 4: Ablation on our training strategies.
| Dataset | Visual Quality | Camera Accuracy | View Synchronization | ||||||
| FID | FVD | CLIP-T | CLIP-F | RotErr | TransErr | Mat. Pix.(K) | FVD-V | CLIP-V | |
| Toy Data | 69.35 | 179.22 | 34.28 | 98.77 | 1.98 | 5.24 | 862.59 | 89.58 | 89.70 |
| High-Quality Data | 57.10 | 122.74 | 34.53 | 98.74 | 1.22 | 4.85 | 906.03 | 90.38 | 90.36 |
🔼 This table presents the results of an ablation study investigating the impact of training data quality on the performance of the ReCamMaster model. It compares the model’s performance using a ’toy dataset’ (smaller, less diverse dataset) to a ‘high-quality dataset’ (larger, more diverse dataset that better reflects real-world videos). The comparison focuses on key metrics evaluating visual quality (FID, FVD, CLIP-T, CLIP-F), camera accuracy (RotErr, TransErr), and view synchronization (Mat.Pix, FVD-V, CLIP-V). This allows assessment of how data diversity and scale affect the model’s ability to generate videos with accurate camera trajectories and consistent visual quality.
read the caption
Table 5: Ablation study on training data construction.
Full paper#