TL;DR#
Traditional 3D reconstruction uses visual geometry methods that require iterative optimization, increasing complexity. Also machine learning assists tasks that cannot be solved by geometry alone, such as feature matching and monocular depth prediction. State-of-the-art SfM methods combine ML and visual geometry end-to-end. But visual geometry still plays a major role which increases computational cost.
This paper introduces VGGT, a feed-forward neural network for 3D reconstruction from multiple views. VGGT directly predicts 3D attributes like camera parameters, depth maps, and point tracks in a single pass, outperforming optimization-based alternatives. It is based on a standard transformer trained on 3D-annotated datasets. Furthermore, VGGT features enhance downstream tasks like point tracking and view synthesis.
Key Takeaways#
Why does it matter?#
VGGT offers a novel approach to 3D scene understanding, reducing reliance on complex optimization. Its potential for fast and versatile 3D reconstruction can impact robotics, AR/VR, and more, spurring new research into end-to-end trainable 3D vision systems.
Visual Insights#

🔼 VGGT, a large feed-forward transformer, processes up to hundreds of images simultaneously to predict 3D scene properties such as camera poses, point clouds, depth maps, and point tracks. Its design minimizes reliance on explicit 3D inductive biases, relying instead on a large dataset of 3D-annotated data for training. The model’s speed is a key feature, performing the complete 3D reconstruction in under one second, often exceeding the accuracy of optimization-based methods without requiring additional processing.
read the caption
Figure 1: VGGT is a large feed-forward transformer with minimal 3D-inductive biases trained on a trove of 3D-annotated data. It accepts up to hundreds of images and predicts cameras, point maps, depth maps, and point tracks for all images at once in less than a second, which often outperforms optimization-based alternatives without further processing.
| Methods | Re10K (unseen) | CO3Dv2 | Time |
| AUC@30 | AUC@30 | ||
| Colmap+SPSG [92] | 45.2 | 25.3 | 15s |
| PixSfM [66] | 49.4 | 30.1 | 20s |
| PoseDiff [124] | 48.0 | 66.5 | 7s |
| DUSt3R [129] | 67.7 | 76.7 | 7s |
| MASt3R [62] | 76.4 | 81.8 | 9s |
| VGGSfM v2 [125] | 78.9 | 83.4 | 10s |
| MV-DUSt3R [111] ‡ | 71.3 | 69.5 | 0.6s |
| CUT3R [127] ‡ | 75.3 | 82.8 | 0.6s |
| FLARE [156] ‡ | 78.8 | 83.3 | 0.5s |
| Fast3R [141] ‡ | 72.7 | 82.5 | 0.2s |
| Ours (Feed-Forward) | 85.3 | 88.2 | 0.2s |
| Ours (with BA) | 93.5 | 91.8 | 1.8s |
🔼 Table 1 presents a comparison of various methods for camera pose estimation, evaluated using the RealEstate10K and CO3Dv2 datasets. Ten random frames from each dataset were used for evaluation. The metrics reported (AUC@30, RRA, RTA, Time) are higher is better, meaning higher values are more accurate. Importantly, none of the methods were trained on the RealEstate10K dataset, making this a true test of generalization performance. Runtimes were measured using a single NVIDIA H100 GPU. A ‘+’ symbol next to the method name indicates that it represents concurrent work, meaning it was published around the same time as the paper this table comes from.
read the caption
Table 1: Camera Pose Estimation on RealEstate10K [161] and CO3Dv2 [88] with 10 random frames. All metrics the higher the better. None of the methods were trained on the Re10K dataset. Runtime were measured using one H100 GPU. Methods marked with ‡ represent concurrent work.
In-depth insights#
3D Neural Nets#
3D neural networks represent a significant advancement in computer vision, enabling machines to directly process and understand three-dimensional data. Unlike traditional methods that rely on 2D image projections, these networks operate on volumetric data such as point clouds or voxels, offering a more complete geometric representation. This approach is particularly beneficial for tasks like object recognition, scene understanding, and robotic navigation, where spatial relationships and 3D structures are crucial. Recent progress has focused on developing efficient architectures and training strategies to handle the computational demands of processing 3D data, leading to improved accuracy and scalability. The ability to learn directly from 3D data reduces the need for complex preprocessing steps and hand-engineered features, paving the way for more robust and versatile 3D vision systems.
Multi-view Power#
Multi-view approaches in computer vision leverage information from multiple images of the same scene to enhance understanding and reconstruction. The power of multi-view stems from its ability to resolve ambiguities inherent in single-view analysis, enabling more robust and accurate estimations of 3D geometry, camera parameters, and object relationships. By fusing data from different perspectives, algorithms can overcome occlusions, improve depth perception, and refine feature matching. This leads to superior performance in tasks like 3D reconstruction, simultaneous localization and mapping (SLAM), and object recognition. The key challenge lies in effectively integrating information from multiple views, addressing issues such as viewpoint variations, illumination changes, and computational complexity. Advanced techniques like bundle adjustment and deep learning-based multi-view stereo have significantly advanced the field, pushing the boundaries of what’s achievable in 3D scene understanding.
VGGT’s Versatility#
VGGT’s versatility stems from its feed-forward design, enabling rapid processing of multiple images. Unlike methods requiring iterative optimization or pairwise fusion, VGGT directly infers 3D scene attributes in a single pass. Its architecture, based on a standard transformer with alternating attention, minimizes specialized 3D inductive biases, allowing it to learn from diverse 3D-annotated datasets. This adaptability allows VGGT to achieve state-of-the-art results across various 3D tasks, including camera pose estimation, multi-view depth estimation, and point tracking. Furthermore, VGGT features can be fine-tuned for downstream tasks like novel view synthesis, demonstrating its potential as a versatile feature extractor. The ability to process hundreds of images simultaneously and its competitive performance compared to optimization-based methods, highlight VGGT’s broad applicability and potential impact.
AA Transformer#
The AA Transformer, likely short for Alternating Attention Transformer, suggests an architecture employing alternating attention mechanisms. This could involve alternating between different forms of attention, such as self-attention and cross-attention, or between different granularities of attention, like local and global attention. The motivation likely stems from capturing both fine-grained details and long-range dependencies effectively. By alternating, the model might prevent over-reliance on one type of attention, promoting a more balanced representation. The architecture’s effectiveness is shown to improve performance gains while also demonstrating that it is permutation equivariant for all but the first frame.
BA Refinement#
Bundle Adjustment (BA) refinement enhances the accuracy of 3D reconstruction by iteratively optimizing camera parameters and 3D point positions. It minimizes the reprojection error, the difference between the projected 3D points and their corresponding image locations. VGGT’s initial estimates provide a solid foundation, making BA more efficient and less prone to local minima. Unlike traditional methods needing triangulation and refinement, VGGT directly predicts accurate maps, streamlining the BA process. While VGGT alone outperforms alternatives, combining it with BA yields state-of-the-art results. BA can serve as supervision signal.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of the Visual Geometry Grounded Transformer (VGGT) model. The process begins with input images that are initially divided into patches using the DINO (DETR with Improved DeNoising) method. These image patches are then converted into tokens, which are numerical representations used by the transformer network. To predict camera parameters, the model adds special ‘camera tokens’ to the image tokens. The core of VGGT is a transformer network that uses alternating layers of frame-wise and global self-attention. Frame-wise attention processes information within each individual image, while global self-attention integrates information across all input images. Finally, a dedicated ‘camera head’ in the network produces the final estimates for camera extrinsics (position and orientation) and intrinsics (focal length and sensor dimensions). A separate DPT (Depth Prediction Transformer) head generates the dense outputs such as depth maps and point clouds.
read the caption
Figure 2: Architecture Overview. Our model first patchifies the input images into tokens by DINO, and appends camera tokens for camera prediction. It then alternates between frame-wise and global self attention layers. A camera head makes the final prediction for camera extrinsics and intrinsics, and a DPT [87] head for any dense output.

🔼 This figure qualitatively compares the 3D point cloud predictions of the proposed VGGT method and the DUSt3R method on real-world images. It showcases VGGT’s superior performance in three scenarios: reconstructing the geometry of an oil painting (where DUSt3R produces a distorted plane), recovering a 3D scene from only two images with no overlap (a task DUSt3R fails), and handling an image with repetitive textures (where VGGT maintains high quality). The figure highlights VGGT’s ability to produce accurate 3D reconstructions even in challenging situations, unlike DUSt3R, which is limited by memory constraints for scenes with more than 32 images.
read the caption
Figure 3: Qualitative comparison of our predicted 3D points to DUSt3R on in-the-wild images. As shown in the top row, our method successfully predicts the geometric structure of an oil painting, while DUSt3R predicts a slightly distorted plane. In the second row, our method correctly recovers a 3D scene from two images with no overlap, while DUSt3R fails. The third row provides a challenging example with repeated textures, while our prediction is still high-quality. We do not include examples with more than 32 frames, as DUSt3R runs out of memory beyond this limit.

🔼 Figure 4 presents supplementary visualizations enhancing the understanding of point map estimation from the paper. It showcases multiple examples of 3D point cloud reconstructions, with camera frustums overlaid to clearly illustrate the estimated camera poses and orientations for each scene. The caption encourages users to explore an interactive demo for an improved and more detailed visualization experience, suggesting that the static figure is a limited representation of the full capabilities of the model.
read the caption
Figure 4: Additional Visualizations of Point Map Estimation. Camera frustums illustrate the estimated camera poses. Explore our interactive demo for better visualization quality.

🔼 Figure 5 demonstrates the application of VGGT’s tracking module for both static and dynamic scenes. The top row showcases the tracking module’s ability to generate keypoint tracks from an unordered set of images depicting a static scene. The bottom row illustrates how finetuning VGGT’s backbone improves the performance of a dynamic point tracker (CoTracker), which typically processes sequential inputs. This highlights VGGT’s versatility and adaptability to various tracking scenarios.
read the caption
Figure 5: Visualization of Rigid and Dynamic Point Tracking. Top: VGGT’s tracking module 𝒯𝒯\mathcal{T}caligraphic_T outputs keypoint tracks for an unordered set of input images depicting a static scene. Bottom: We finetune the backbone of VGGT to enhance a dynamic point tracker CoTracker [56], which processes sequential inputs.

🔼 This figure showcases qualitative examples of novel view synthesis. The top row displays the input images used for synthesis. The middle row shows the corresponding ground truth images from the target viewpoints, providing a reference for comparison. The bottom row presents the novel views synthesized by the VGGT model, illustrating its ability to generate realistic and visually consistent images from unseen perspectives.
read the caption
Figure 6: Qualitative Examples of Novel View Synthesis. The top row shows the input images, the middle row displays the ground truth images from target viewpoints, and the bottom row presents our synthesized images.
More on tables
| Known GT | Method | Acc. | Comp. | Overall |
| camera | ||||
| ✓ | Gipuma [40] | 0.283 | 0.873 | 0.578 |
| ✓ | MVSNet [144] | 0.396 | 0.527 | 0.462 |
| ✓ | CIDER [139] | 0.417 | 0.437 | 0.427 |
| ✓ | PatchmatchNet [121] | 0.427 | 0.377 | 0.417 |
| ✓ | MASt3R [62] | 0.403 | 0.344 | 0.374 |
| ✓ | GeoMVSNet [157] | 0.331 | 0.259 | 0.295 |
| ✗ | DUSt3R [129] | 2.677 | 0.805 | 1.741 |
| ✗ | Ours | 0.389 | 0.374 | 0.382 |
🔼 This table presents a comparison of different methods for dense multi-view stereo (MVS) estimation on the DTU dataset. The methods are categorized into two groups: those that utilize ground-truth camera poses (top section) and those that do not (bottom section). The performance is evaluated using Accuracy, Completeness, and Overall metrics (average of Accuracy and Completeness). This demonstrates the capabilities of methods operating under ideal conditions versus those working with real-world constraints where ground truth camera information might not be available.
read the caption
Table 2: Dense MVS Estimation on the DTU [51] Dataset. Methods operating with known ground-truth camera are in the top part of the table, while the bottom part contains the methods that do not know the ground-truth camera.
| Methods | Acc. | Comp. | Overall | Time |
|---|---|---|---|---|
| DUSt3R | 1.167 | 0.842 | 1.005 | 7s |
| MASt3R | 0.968 | 0.684 | 0.826 | 9s |
| Ours (Point) | 0.901 | 0.518 | 0.709 | 0.2s |
| Ours (Depth + Cam) | 0.873 | 0.482 | 0.677 | 0.2s |
🔼 This table presents a comparison of point map estimation results on the ETH3D dataset among different methods. It highlights the speed advantage of the proposed feed-forward approach (VGGT) compared to optimization-based methods (DUSt3R and MASt3R) which rely on global alignment. The table also shows that combining depth and camera predictions to construct the point cloud (Ours (Depth + Cam)) results in better accuracy than directly using the point map head output (Ours (Point)). Metrics used include Accuracy, Completeness, and Overall (Chamfer distance).
read the caption
Table 3: Point Map Estimation on ETH3D [97]. DUSt3R and MASt3R use global alignment while ours is feed-forward and, hence, much faster. The row Ours (Point) indicates the results using the point map head directly, while Ours (Depth + Cam) denotes constructing point clouds from the depth map head combined with the camera head.
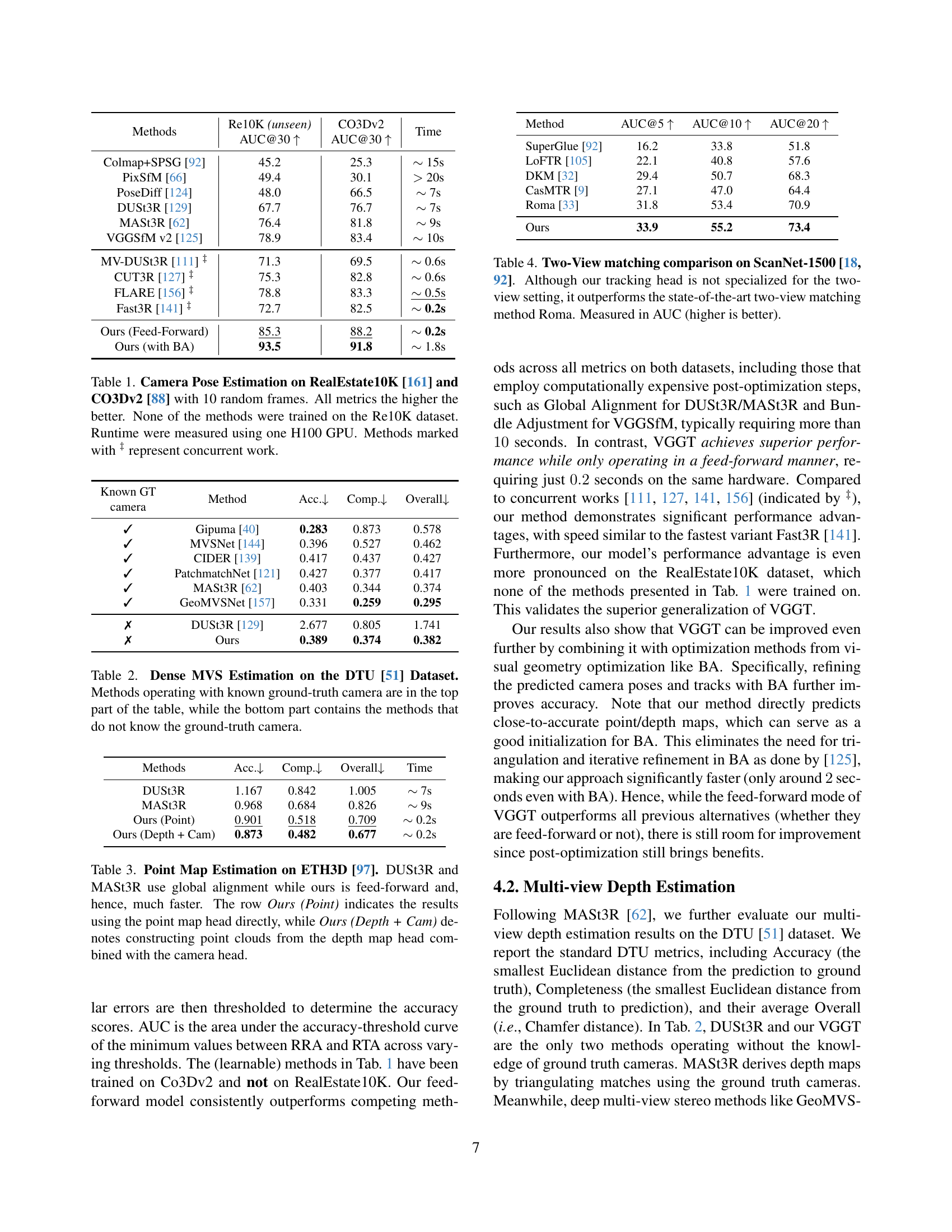
| Method | AUC@5 | AUC@10 | AUC@20 |
|---|---|---|---|
| SuperGlue [92] | 16.2 | 33.8 | 51.8 |
| LoFTR [105] | 22.1 | 40.8 | 57.6 |
| DKM [32] | 29.4 | 50.7 | 68.3 |
| CasMTR [9] | 27.1 | 47.0 | 64.4 |
| Roma [33] | 31.8 | 53.4 | 70.9 |
| Ours | 33.9 | 55.2 | 73.4 |
🔼 Table 4 presents a comparison of different methods for two-view image matching on the ScanNet-1500 dataset. The table shows the performance of various techniques, including the proposed VGGT method and state-of-the-art approaches, in terms of AUC (Area Under the Curve) scores, a common metric for evaluating matching performance. The results demonstrate that despite not being specifically designed for two-view matching, VGGT outperforms the existing best-performing method, Roma, indicating its strong generalizability across different 3D vision tasks.
read the caption
Table 4: Two-View matching comparison on ScanNet-1500 [18, 92]. Although our tracking head is not specialized for the two-view setting, it outperforms the state-of-the-art two-view matching method Roma. Measured in AUC (higher is better).
| ETH3D Dataset | Acc. | Comp. | Overall |
|---|---|---|---|
| Cross-Attention | 1.287 | 0.835 | 1.061 |
| Global Self-Attention Only | 1.032 | 0.621 | 0.827 |
| Alternating-Attention | 0.901 | 0.518 | 0.709 |
🔼 This ablation study investigates the impact of different attention mechanisms on the performance of the VGGT model for point map estimation using the ETH3D dataset. Three transformer backbone architectures are compared: one with only global self-attention, one with cross-attention, and the proposed alternating-attention mechanism. The results show the effectiveness of the alternating-attention approach in improving accuracy compared to the other two methods.
read the caption
Table 5: Ablation Study for Transformer Backbone on ETH3D. We compare our alternating-attention architecture against two variants: one using only global self-attention and another employing cross-attention.
| w. | w. | w. | Acc. | Comp. | Overall |
|---|---|---|---|---|---|
| ✗ | ✓ | ✓ | 1.042 | 0.627 | 0.834 |
| ✓ | ✗ | ✓ | 0.920 | 0.534 | 0.727 |
| ✓ | ✓ | ✗ | 0.976 | 0.603 | 0.790 |
| ✓ | ✓ | ✓ | 0.901 | 0.518 | 0.709 |
🔼 This table presents an ablation study evaluating the impact of multi-task learning on point map estimation accuracy within the ETH3D dataset. By selectively including or excluding the training of camera, depth, and track estimation components, the study demonstrates that a multi-task learning approach, encompassing all three elements, results in superior point map estimation accuracy compared to single-task learning.
read the caption
Table 6: Ablation Study for Multi-task Learning, which shows that simultaneous training with camera, depth and track estimation yields the highest accuracy in point map estimation on ETH3D.
| Method | Known Input Cam | Size | PSNR | SSIM | LPIPS |
|---|---|---|---|---|---|
| LGM [110] | ✓ | 256 | 21.44 | 0.832 | 0.122 |
| GS-LRM [154] | ✓ | 256 | 29.59 | 0.944 | 0.051 |
| LVSM [53] | ✓ | 256 | 31.71 | 0.957 | 0.027 |
| Ours-NVS∗ | ✗ | 224 | 30.41 | 0.949 | 0.033 |
🔼 This table presents a quantitative comparison of different methods for novel view synthesis using the GSO dataset. The key metric is the performance of each method in generating new views of a scene, measured using PSNR, SSIM, and LPIPS scores. The table highlights the competitive performance of VGGT even when trained on a limited dataset (only 20% of the available data) and without requiring explicit knowledge of camera parameters.
read the caption
Table 7: Quantitative comparisons for view synthesis on GSO [28] dataset. Finetuning VGGT for feed-forward novel view synthesis, it demonstrates competitive performance even without knowing camera extrinsic and intrinsic parameters for the input images. Note that ∗ indicates using a small training set (only 20%).
| Method | Kinetics | RGB-S | DAVIS | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AJ | OA | AJ | OA | AJ | OA | ||||
| TAPTR [63] | 49.0 | 64.4 | 85.2 | 60.8 | 76.2 | 87.0 | 63.0 | 76.1 | 91.1 |
| LocoTrack [13] | 52.9 | 66.8 | 85.3 | 69.7 | 83.2 | 89.5 | 62.9 | 75.3 | 87.2 |
| BootsTAPIR [26] | 54.6 | 68.4 | 86.5 | 70.8 | 83.0 | 89.9 | 61.4 | 73.6 | 88.7 |
| CoTracker [56] | 49.6 | 64.3 | 83.3 | 67.4 | 78.9 | 85.2 | 61.8 | 76.1 | 88.3 |
| CoTracker + Ours | 57.2 | 69.0 | 88.9 | 72.1 | 84.0 | 91.6 | 64.7 | 77.5 | 91.4 |
🔼 This table presents the results of dynamic point tracking experiments using the TAP-Vid benchmark. The authors compared their method (CoTracker fine-tuned with weights from their pre-trained Visual Geometry Grounded Transformer (VGGT) model) against other state-of-the-art tracking methods. The results demonstrate that even though the VGGT model wasn’t specifically trained for dynamic scenes, integrating its learned features significantly improves the performance of CoTracker, highlighting the robustness and generalizability of VGGT’s feature extraction capabilities. Metrics such as Occlusion Accuracy (OA), Average Jaccard (AJ), and others are used to evaluate the tracker’s performance across various datasets. The findings strongly support the effectiveness of VGGT’s learned representations when applied to downstream tasks.
read the caption
Table 8: Dynamic Point Tracking Results on the TAP-Vid benchmarks. Although our model was not designed for dynamic scenes, simply fine-tuning CoTracker with our pretrained weights significantly enhances performance, demonstrating the robustness and effectiveness of our learned features.
| Input Frames | 1 | 2 | 4 | 8 | 10 | 20 | 50 | 100 | 200 |
|---|---|---|---|---|---|---|---|---|---|
| Time (s) | 0.04 | 0.05 | 0.07 | 0.11 | 0.14 | 0.31 | 1.04 | 3.12 | 8.75 |
| Mem. (GB) | 1.88 | 2.07 | 2.45 | 3.23 | 3.63 | 5.58 | 11.41 | 21.15 | 40.63 |
🔼 This table presents the runtime and GPU memory usage of the VGGT model’s feature backbone when processing varying numbers of input images. The runtime is measured in seconds, and the peak GPU memory usage is reported in gigabytes. This data allows readers to assess the computational efficiency and resource requirements of the model as the number of input frames increases.
read the caption
Table 9: Runtime and peak GPU memory usage across different numbers of input frames. Runtime is measured in seconds, and GPU memory usage is reported in gigabytes.
| Method | Test-time Opt. | AUC@3 | AUC@5 | AUC@10 | Runtime |
| COLMAP (SIFT+NN) [94] | ✓ | 23.58 | 32.66 | 44.79 | 10s |
| PixSfM (SIFT + NN) [66] | ✓ | 25.54 | 34.80 | 46.73 | 20s |
| PixSfM (LoFTR) [66] | ✓ | 44.06 | 56.16 | 69.61 | 20s |
| PixSfM (SP + SG) [66] | ✓ | 45.19 | 57.22 | 70.47 | 20s |
| DFSfM (LoFTR) [47] | ✓ | 46.55 | 58.74 | 72.19 | 10s |
| DUSt3R [129] | ✓ | 13.46 | 21.24 | 35.62 | 7s |
| MASt3R [62] | ✓ | 30.25 | 46.79 | 57.42 | 9s |
| VGGSfM [125] | ✓ | 45.23 | 58.89 | 73.92 | 6s |
| VGGSfMv2 [125] | ✓ | 59.32 | 67.78 | 76.82 | 10s |
| VGGT (ours) | ✗ | 39.23 | 52.74 | 71.26 | 0.2s |
| VGGT + BA (ours) | ✓ | 66.37 | 75.16 | 84.91 | 1.8s |
🔼 Table 10 presents a comparison of camera pose estimation methods on the Image Matching Challenge (IMC) dataset [54], focusing on phototourism data. The results show that the proposed method achieves state-of-the-art performance, surpassing even VGGSfMv2 [125], the top performer in the recent CVPR 2024 IMC challenge. The table evaluates the accuracy of camera pose estimation (both rotation and translation) using various metrics and compares the performance of different algorithms, highlighting the speed and accuracy advantages of the proposed approach.
read the caption
Table 10: Camera Pose Estimation on IMC [54]. Our method achieves state-of-the-art performance on the challenging phototropism data, outperforming VGGSfMv2 [125] which ranked first on the latest CVPR’24 IMC Challenge in camera pose (rotation and translation) estimation.
Full paper#