TL;DR#
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it addresses the critical need for safer VLMs in real-world applications. The HySAC framework provides a new approach to content moderation that enhances safety recognition and interpretability, paving the way for more responsible and reliable AI systems. It opens avenues for further research in hyperbolic learning and safety-aware architectures, impacting the broader fields of CV and NLP.
Visual Insights#

🔼 This figure illustrates the HySAC model’s architecture and workflow. HySAC leverages the hierarchical nature of hyperbolic space to represent safe and unsafe content. Safe text and image embeddings are located near the origin, while unsafe ones are projected further away. A contrastive loss function aligns safe and unsafe image-text pairs, while an entailment loss enforces hierarchical relationships within the embedding space. The model allows for safety-aware retrieval; unsafe queries can be dynamically redirected towards safer alternatives or the original (unsafe) results can be returned.
read the caption
Figure 1: Overview of our approach. HySAC builds a hyperbolic embedding that manages content safety through an entailment hierarchy. Unsafe text and images are projected to dedicated regions of hyperbolic space, allowing for safety-aware retrieval and classification.
| Text-to-Image (-to-) | Image-to-Text (-to-) | Text-to-Image (-to-) | Image-to-Text (-to-) | |||||||||||||
| Model | R@1 | R@10 | R@20 | R@1 | R@10 | R@20 | R@1 | R@10 | R@20 | R@1 | R@10 | R@20 | ||||
| CLIP [69] | 36.8 | 71.6 | 81.5 | 39.8 | 74.2 | 83.5 | 2.0 | 24.8 | 33.2 | 4.6 | 32.9 | 40.6 | ||||
| MERU [20] | 14.9 | 43.0 | 54.2 | 14.7 | 42.3 | 53.8 | 2.2 | 15.2 | 21.5 | 4.4 | 22.6 | 29.4 | ||||
| HyCoCLIP [63] | 34.3 | 71.2 | 80.6 | 34.4 | 71.3 | 82.2 | 2.8 | 25.3 | 33.2 | 8.2 | 37.8 | 45.7 | ||||
| Safe-CLIP [66] | 45.9 | 81.8 | 89.7 | 45.3 | 82.3 | 89.8 | 8.0 | 46.9 | 58.0 | 19.1 | 62.9 | 71.1 | ||||
| MERU⋆ | 50.0 | 84.1 | 91.1 | 51.2 | 85.3 | 92.3 | 2.3 | 39.9 | 49.4 | 5.7 | 47.9 | 54.7 | ||||
| HyCoCLIP⋆ | 47.7 | 81.9 | 89.1 | 46.7 | 82.7 | 90.4 | 1.5 | 32.7 | 42.3 | 6.9 | 45.2 | 53.6 | ||||
| HySAC | 49.8 | 84.1 | 90.7 | 48.2 | 84.2 | 91.2 | 30.5 | 62.8 | 71.8 | 42.1 | 73.3 | 79.8 | ||||
🔼 Table 1 presents a comprehensive evaluation of safe content retrieval performance on the ViSU test set, comparing HySAC against several baseline models, including the original CLIP, MERU, and HyCoCLIP. It assesses performance across different retrieval tasks (text-to-image and image-to-text), along with various recall rates (R@1, R@10, R@20). The results showcase HySAC’s superior ability to retrieve safe content, particularly when dealing with unsafe inputs. The table also includes results for CLIP models fine-tuned in hyperbolic space using MERU and HyCoCLIP losses, demonstrating the benefits of HySAC’s approach over existing methods in navigating unsafe content queries towards safe and relevant outputs.
read the caption
Table 1: Safe content retrieval performance on ViSU test set. Across all tasks and recall rates, HySAC improves over existing safety unlearning CLIP and hyperbolic CLIP models, highlighting that our approach is able to navigate unsafe image or text inputs towards relevant but safe retrieval outputs. ⋆ CLIP fine-tuned in hyperbolic space on ViSU training set with MERU/HyCoCLIP losses.
In-depth insights#
HySAC: Awareness#
While the paper doesn’t have a section titled “HySAC: Awareness” verbatim, the core idea revolves around imbuing VLMs with safety awareness rather than simply unlearning unsafe content. This is a significant shift in paradigm. The goal is to enable models to distinguish between safe and unsafe content, offering users agency and control. HySAC achieves this by leveraging the hierarchical properties of hyperbolic space, organizing data into radius-based safe and unsafe regions. This approach contrasts with methods that aim to erase knowledge of NSFW content, which can inadvertently limit the model’s ability to understand and reason about the nuances of potentially harmful concepts. HySAC’s safety awareness allows for dynamic redirection of unsafe queries toward safer alternatives or, when necessary, controlled access to unsafe content, promoting both safety and responsible use.
Entailment Hierarchy#
The entailment hierarchy is a key concept for structuring relationships between different levels of safety. It allows creating an ordered structure where safe concepts are more general and unsafe concepts are more specific. In vision-language models, such a hierarchy can be modeled using techniques that ensure safe embeddings encompass unsafe representations, creating a conical structure in the embedding space. The entailment forces the model to understand the nuanced relationship between safe and unsafe content, rather than merely ‘unlearning’ unsafe concepts, allowing it to differentiate and prioritize safety while still retaining knowledge of unsafe content. This ensures a more robust and adaptable approach to content moderation, allowing controlled access or redirection when necessary.
Hyperbolic Safety#
The concept of “Hyperbolic Safety,” likely inspired by hyperbolic geometry’s hierarchical representation capabilities, suggests a novel approach to AI safety. Instead of merely unlearning unsafe concepts, models are designed to understand and categorize content safety. This involves mapping safe and unsafe content to distinct regions within a hyperbolic space, leveraging its properties to establish clear boundaries. Such safety framework enables dynamic query adjustments, prioritizing safe retrievals or, when necessary, exposing relevant unsafe content under controlled conditions. It moves towards interpretable content moderation in vision-language models.
Dynamic Traversal#
The concept of “Dynamic Traversal,” absent as a direct heading in the provided research paper, evokes compelling ideas within vision-language models’ (VLMs) safety. Such traversal suggests actively maneuvering through the embedding space to mitigate risks associated with unsafe content. One approach would be dynamically adjusting query embeddings based on content safety awareness. By redirecting unsafe queries toward safer, yet relevant alternatives or retaining the output offers a customizable safety mechanism. In hyperbolic space, entailment hierarchies would guide these dynamic adjustments, ensuring traversal adheres to established safety boundaries. A system equipped with dynamic traversal capabilities demonstrates heightened control, adaptability, and interpretability in content moderation, moving beyond mere unlearning.
Beyond Unlearning#
The concept of ‘Beyond Unlearning’ suggests a shift from simply erasing knowledge of unsafe content in AI models to a more sophisticated approach. Instead of ‘forgetting’, the focus is on awareness and nuanced understanding. This involves enabling models to discern between safe and unsafe content, allowing for controlled exposure or redirection. This paradigm prioritizes user agency, understanding, and interpretability, fostering responsible AI practices and building more adaptable and ethically sound systems. Ultimately, it is about moving towards a model that acknowledges and manages unsafe information responsibly.
More visual insights#
More on figures
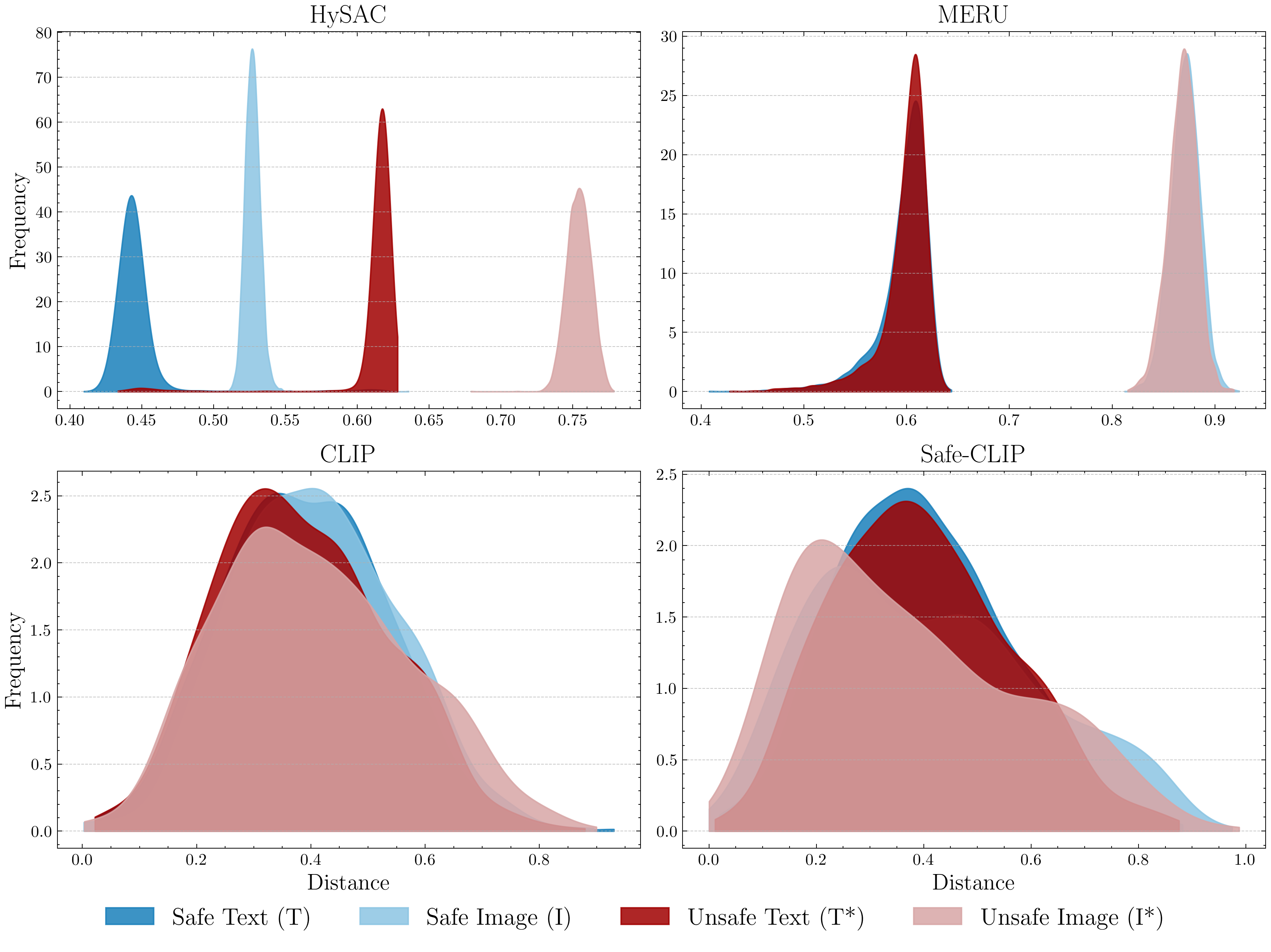
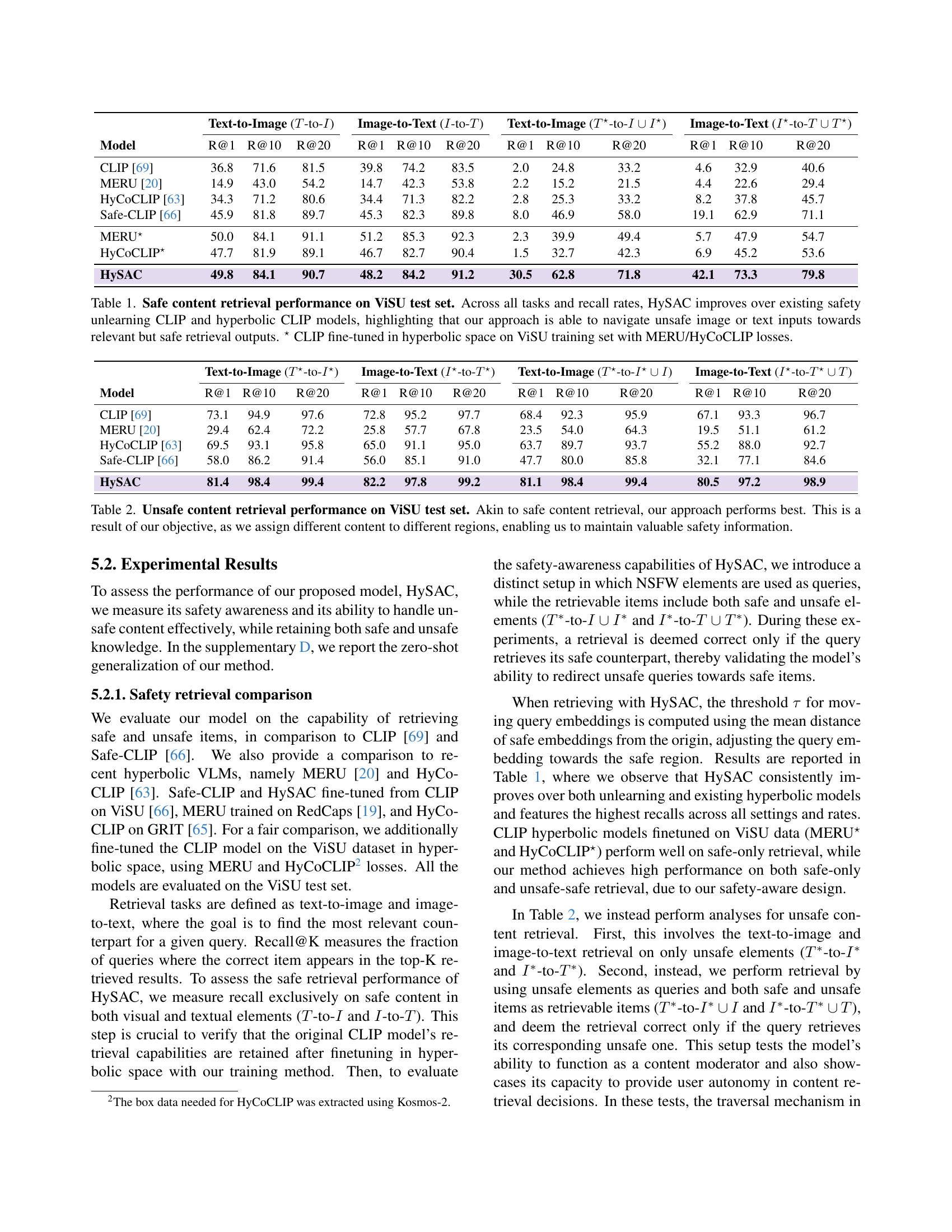
🔼 Figure 2 presents the distribution of distances of embeddings from the root in the hyperbolic space for four different models: CLIP, Safe-CLIP, MERU, and HySAC. The x-axis represents the distance from the root, and the y-axis represents the frequency of embeddings at that distance. The ViSU dataset was used to generate these distributions. The figure highlights that CLIP and Safe-CLIP fail to distinguish between text and image embeddings. MERU shows some separation between text and image embeddings, but HySAC demonstrates a clear separation not only between text and image embeddings but also between safe and unsafe content. This visual representation effectively illustrates the key difference between HySAC and previous approaches to safety-aware content management in vision-language models.
read the caption
Figure 2: Distributions of embedding distances from the root. We embed all ViSU training samples and visualize their distance distribution from the root. While CLIP and Safe-CLIP do not separate between texts and images, MERU does. HySAC, instead, also differentiates between safe and unsafe content.

🔼 Figure 3 visualizes the safety traversal mechanism in HySAC. Starting with an unsafe image query, HySAC iteratively moves the embedding towards the root node of the hyperbolic space. At each step, the closest (top-1) text caption is retrieved and displayed. The figure showcases how HySAC transitions from unsafe to safe captions as the embedding approaches the root, demonstrating its ability to prioritize safe content retrieval while maintaining semantic relevance.
read the caption
Figure 3: Qualitative traversal results. HySAC traverses towards the root feature, retrieving the top-1 text at each interpolation point. This traversal effectively transitions from unsafe to safe captions, demonstrating the model’s ability to ensure safety-aware content retrieval.

🔼 Figure 4 presents a comparison of embedding distance distributions from the root (origin) of the embedding space for both Euclidean and hyperbolic versions of the HySAC model. The distributions are shown as histograms for safe text, safe images, unsafe text, and unsafe images. The key observation is that the Euclidean version of HySAC fails to clearly separate the safe and unsafe content in its embedding space. Conversely, the hyperbolic version of HySAC shows distinct, non-overlapping distributions for safe and unsafe content, indicating a successful hierarchical organization of the data according to safety levels.
read the caption
Figure 4: Distributions of embedding distances from the root. Comparison of the distance distributions of Euclidean and hyperbolic embeddings from the root. Euclidean version of HySAC does not separate between safe and unsafe content, while HySAC does.

🔼 This figure showcases HySAC’s ability to steer image queries towards safer textual descriptions. Starting with unsafe images, the model traverses the hyperbolic embedding space towards the origin (root). Along this path, the model uses intermediate points as queries to retrieve captions from a dataset containing both safe and unsafe content. The captions change from unsafe to safe as the traversal progresses, demonstrating HySAC’s capacity to redirect unsafe inputs toward safer outputs while maintaining relevance.
read the caption
Figure 5: Traversals from unsafe image queries towards safe captions. We present qualitative results of HySAC, showing the traversals from unsafe image queries toward the root feature. Interpolation points along this path are used as new queries to retrieve captions from a pool of both safe and unsafe texts.

🔼 This figure visualizes the process of guiding unsafe image queries towards safer alternatives using HySAC. It demonstrates how intermediate steps along a traversal path in the embedding space can smoothly transition from unsafe to safe image content. Each image in the grid represents a point along this path, illustrating the gradual shift towards safer visual representations.
read the caption
Figure 6: Traversals from unsafe image queries towards safe images. We illustrate how HySAC can guide the transition from unsafe image queries to corresponding safe images, utilizing intermediate interpolation steps along the traversal path.

🔼 Figure 7 showcases the results of using HySAC with safe image queries to exclusively retrieve safe text captions. This demonstrates HySAC’s ability to maintain its performance on safe data while also incorporating its safety-awareness mechanisms. The figure visually depicts the retrieval process by showing several safe images and their corresponding safe text captions. The captions are selected from a pool that contains only safe text to further isolate the effect of using HySAC’s safety-aware mechanisms.
read the caption
Figure 7: Traversals from safe image queries to safe text. We demonstrate how HySAC effectively maintains its performance on safe data by using safe image queries to retrieve captions exclusively from a pool of safe text.
More on tables
| Text-to-Image (-to-) | Image-to-Text (-to-) | Text-to-Image (-to-) | Image-to-Text (-to-) | |||||||||||||
| Model | R@1 | R@10 | R@20 | R@1 | R@10 | R@20 | R@1 | R@10 | R@20 | R@1 | R@10 | R@20 | ||||
| CLIP [69] | 73.1 | 94.9 | 97.6 | 72.8 | 95.2 | 97.7 | 68.4 | 92.3 | 95.9 | 67.1 | 93.3 | 96.7 | ||||
| MERU [20] | 29.4 | 62.4 | 72.2 | 25.8 | 57.7 | 67.8 | 23.5 | 54.0 | 64.3 | 19.5 | 51.1 | 61.2 | ||||
| HyCoCLIP [63] | 69.5 | 93.1 | 95.8 | 65.0 | 91.1 | 95.0 | 63.7 | 89.7 | 93.7 | 55.2 | 88.0 | 92.7 | ||||
| Safe-CLIP [66] | 58.0 | 86.2 | 91.4 | 56.0 | 85.1 | 91.0 | 47.7 | 80.0 | 85.8 | 32.1 | 77.1 | 84.6 | ||||
| HySAC | 81.4 | 98.4 | 99.4 | 82.2 | 97.8 | 99.2 | 81.1 | 98.4 | 99.4 | 80.5 | 97.2 | 98.9 | ||||
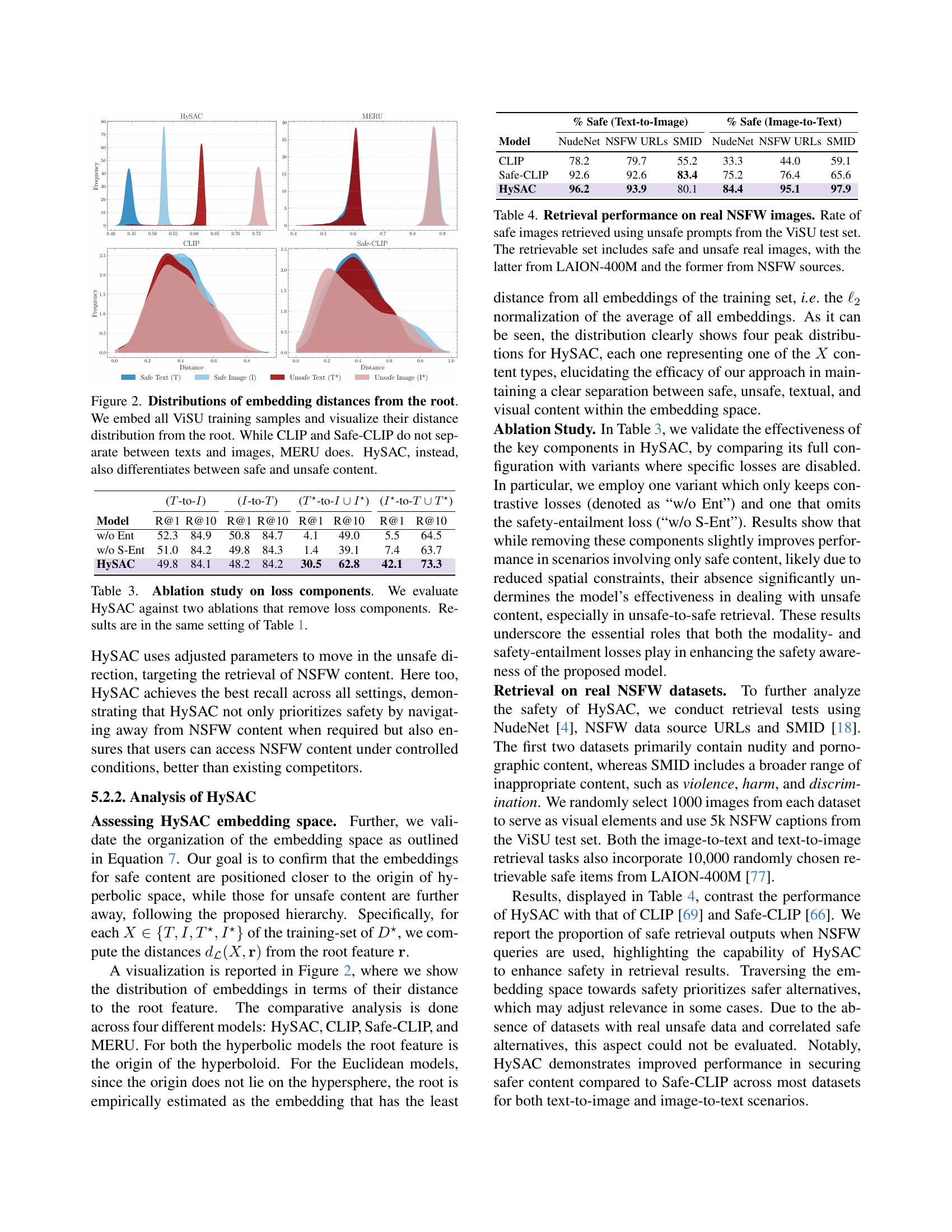
🔼 Table 2 presents the results of the unsafe content retrieval task using the ViSU test set. The table evaluates the model’s ability to retrieve unsafe content when given unsafe queries. The results demonstrate that HySAC significantly outperforms existing methods, such as CLIP and Safe-CLIP, in its ability to correctly identify and retrieve unsafe content. This superior performance stems from the core objective of HySAC—distinguishing and separating safe and unsafe content in different regions of the embedding space, thereby preserving valuable safety-related information.
read the caption
Table 2: Unsafe content retrieval performance on ViSU test set. Akin to safe content retrieval, our approach performs best. This is a result of our objective, as we assign different content to different regions, enabling us to maintain valuable safety information.
| (-to-) | (-to-) | (-to-) | (-to-) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | R@1 | R@10 | R@1 | R@10 | R@1 | R@10 | R@1 | R@10 | ||||
| w/o Ent | 52.3 | 84.9 | 50.8 | 84.7 | 4.1 | 49.0 | 5.5 | 64.5 | ||||
| w/o S-Ent | 51.0 | 84.2 | 49.8 | 84.3 | 1.4 | 39.1 | 7.4 | 63.7 | ||||
| HySAC | 49.8 | 84.1 | 48.2 | 84.2 | 30.5 | 62.8 | 42.1 | 73.3 | ||||
🔼 This ablation study analyzes the impact of different loss components in the HySAC model. Two variants of the HySAC model are created: one without the entailment loss (removing the hierarchical relationship modeling between safe and unsafe content), and one without the safety entailment loss (removing the specific relationship between safe and unsafe pairs). The results of these ablated models are compared to the full HySAC model using the same evaluation metrics and dataset (ViSU test set) as in Table 1. This allows for a quantitative assessment of the contributions of each loss component to the overall performance of the model in terms of safe and unsafe content retrieval.
read the caption
Table 3: Ablation study on loss components. We evaluate HySAC against two ablations that remove loss components. Results are in the same setting of Table 1.
| % Safe (Text-to-Image) | % Safe (Image-to-Text) | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | NudeNet | NSFW URLs | SMID | NudeNet | NSFW URLs | SMID | ||
| CLIP | 78.2 | 79.7 | 55.2 | 33.3 | 44.0 | 59.1 | ||
| Safe-CLIP | 92.6 | 92.6 | 83.4 | 75.2 | 76.4 | 65.6 | ||
| HySAC | 96.2 | 93.9 | 80.1 | 84.4 | 95.1 | 97.9 | ||
🔼 This table presents the results of a retrieval experiment using real-world NSFW images. The goal was to assess the models’ ability to retrieve safe images when given unsafe prompts (queries). Unsafe prompts were selected from the ViSU test set, while the images used for retrieval included a mix of safe images (sourced from various NSFW image datasets) and unsafe images (sourced from the LAION-400M dataset). The table shows the percentage of safe images retrieved for each model, indicating their success rate in redirecting unsafe queries to safer content.
read the caption
Table 4: Retrieval performance on real NSFW images. Rate of safe images retrieved using unsafe prompts from the ViSU test set. The retrievable set includes safe and unsafe real images, with the latter from LAION-400M and the former from NSFW sources.
| NudeNet | Mixed NSFW | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | Acc | FPR | FNR | Acc | FPR | FNR | ||
| NSFW-CNN [46] | 85.3 | 0.0 | 14.7 | 66.5 | 4.5 | 35.9 | ||
| CLIP-classifier [76] | 97.3 | 0.0 | 2.7 | 76.9 | 0.1 | 11.0 | ||
| CLIP-distance [70] | 86.4 | 0.0 | 13.6 | 77.8 | 2.0 | 22.1 | ||
| NudeNet [4] | 91.2 | 0.0 | 8.8 | 76.9 | 4.5 | 24.6 | ||
| Q16 [74] | 28.5 | 0.0 | 71.5 | 65.3 | 8.3 | 29.4 | ||
| HySAC | 99.5 | 0.0 | 0.5 | 78.9 | 16.5 | 6.8 | ||
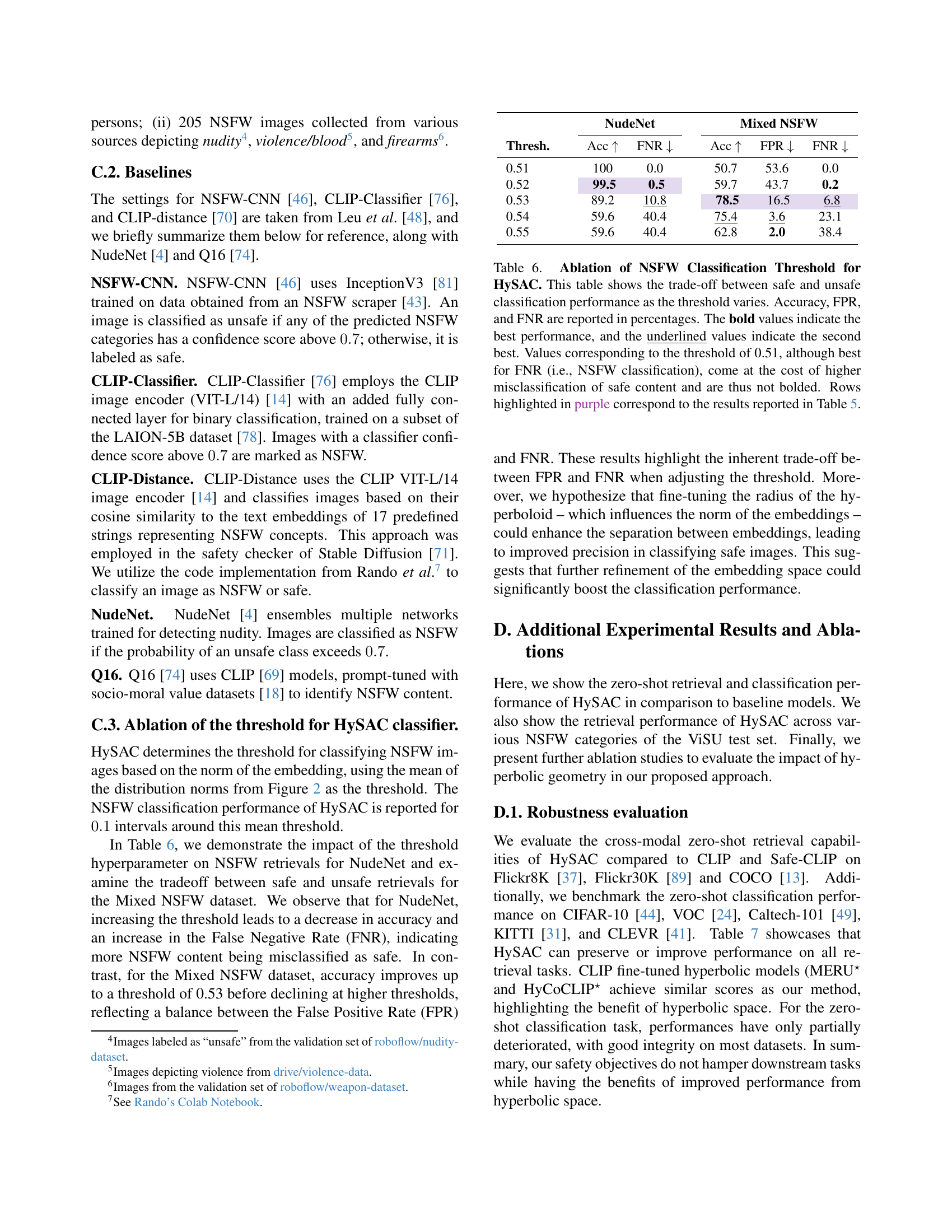
🔼 Table 5 presents a comparison of HySAC’s NSFW classification performance against several other established NSFW classifiers. It shows the accuracy, false positive rate (FPR), and false negative rate (FNR) for each model on two datasets: NudeNet (containing only nudity) and Mixed NSFW (a broader range of NSFW content). The metrics are reported as percentages, allowing for easy comparison of the models’ effectiveness in correctly identifying and classifying NSFW content.
read the caption
Table 5: NSFW classification. Comparison between HySAC and other NSFW classifiers. Metrics reported in percentages.
| NudeNet | Mixed NSFW | ||||||
|---|---|---|---|---|---|---|---|
| Thresh. | Acc | FNR | Acc | FPR | FNR | ||
| 0.51 | 100 | 0.0 | 50.7 | 53.6 | 0.0 | ||
| 0.52 | 99.5 | 0.5 | 59.7 | 43.7 | 0.2 | ||
| 0.53 | 89.2 | 10.8 | 78.5 | 16.5 | 6.8 | ||
| 0.54 | 59.6 | 40.4 | 75.4 | 3.6 | 23.1 | ||
| 0.55 | 59.6 | 40.4 | 62.8 | 2.0 | 38.4 | ||
🔼 This table presents an ablation study on the threshold parameter used in HySAC for NSFW classification. It analyzes the trade-off between correctly classifying safe and unsafe content (accuracy) and the rates of false positives (FPR, classifying safe content as unsafe) and false negatives (FNR, classifying unsafe content as safe) at different threshold values. The best overall performance across accuracy, FPR, and FNR is highlighted in bold. Threshold values that result in the best FNR (fewest unsafe images incorrectly identified as safe) but also have a high FPR (many safe images incorrectly identified as unsafe) are underlined, but not bolded, to show that these are not the best overall. Results from specific thresholds which were also reported in Table 5 are highlighted in purple for easy comparison.
read the caption
Table 6: Ablation of NSFW Classification Threshold for HySAC. This table shows the trade-off between safe and unsafe classification performance as the threshold varies. Accuracy, FPR, and FNR are reported in percentages. The bold values indicate the best performance, and the underlined values indicate the second best. Values corresponding to the threshold of 0.51, although best for FNR (i.e., NSFW classification), come at the cost of higher misclassification of safe content and are thus not bolded. Rows highlighted in purple correspond to the results reported in Table 5.
| Flickr8k | Flickr30k | MS COCO | Zero-Shot Classification | ||||||||||||
| Model | T2I | I2T | T2I | I2T | T2I | I2T | C10 | VOC | C101 | KT | CL | ||||
| CLIP | 86.4 | 94.0 | 87.3 | 97.3 | 61.1 | 79.3 | 95.6 | 78.3 | 83.3 | 21.7 | 19.4 | ||||
| MERU | 44.4 | 53.9 | 37.9 | 45.9 | 32.0 | 40.9 | 67.9 | 58.4 | 70.9 | 10.3 | 18.4 | ||||
| HyCoCLIP | 83.3 | 92.9 | 86.0 | 93.4 | 60.3 | 71.8 | 90.8 | 70.7 | 79.7 | 26.7 | 16.6 | ||||
| Safe-CLIP | 87.4 | 93.9 | 89.9 | 96.0 | 72.4 | 84.0 | 88.9 | 76.5 | 81.4 | 29.4 | 22.8 | ||||
| MERU⋆ | 93.0 | 96.8 | 94.7 | 98.7 | 75.8 | 87.5 | 93.6 | 82.0 | 85.9 | 24.3 | 27.7 | ||||
| HyCoCLIP⋆ | 92.2 | 95.9 | 93.9 | 98.7 | 73.1 | 84.8 | 92.8 | 67.9 | 83.7 | 23.1 | 21.5 | ||||
| HySAC | 92.1 | 96.2 | 93.2 | 97.9 | 75.1 | 85.4 | 93.6 | 81.7 | 82.2 | 32.6 | 23.2 | ||||
🔼 Table 7 presents the results of evaluating CLIP’s robustness across various datasets after being fine-tuned using different methods, including the proposed HySAC method and other hyperbolic vision-language models. It assesses performance on both zero-shot image retrieval (using R@5 as the metric) and zero-shot image classification (using top-1 accuracy). The goal is to show how the different approaches impact the model’s ability to generalize to unseen data while maintaining its performance on well-known datasets.
read the caption
Table 7: CLIP robustness preservation results. Metrics: R@5 for zero-shot retrieval, top-1 accuracy for zero-shot classification.
| Hate | Harassment | Violence | Self-harm | Sexual | Shocking | Illegal Act. | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | T2I | I2T | T2I | I2T | T2I | I2T | T2I | I2T | T2I | I2T | T2I | I2T | T2I | I2T | |||||||
| CLIP | 5.2 | 8.1 | 6.0 | 9.2 | 2.5 | 5.6 | 4.1 | 7.9 | 2.3 | 4.3 | 2.3 | 5.1 | 3.0 | 6.3 | |||||||
| MERU | 9.7 | 15.0 | 8.4 | 12.8 | 3.2 | 6.8 | 8.3 | 13.8 | 5.9 | 6.0 | 4.6 | 7.9 | 4.8 | 7.3 | |||||||
| HyCoCLIP | 3.3 | 15.9 | 5.2 | 16.9 | 2.7 | 8.7 | 2.1 | 12.6 | 6.1 | 4.1 | 6.3 | 7.8 | 3.7 | 12.9 | |||||||
| Safe-CLIP | 15.9 | 32.1 | 14.9 | 28.9 | 11.0 | 23.6 | 13.8 | 33.9 | 10.6 | 20.2 | 12.2 | 28.0 | 11.3 | 24.0 | |||||||
| MERU | 3.6 | 9.3 | 4.4 | 8.8 | 2.0 | 6.8 | 2.5 | 8.8 | 1.9 | 3.9 | 3.7 | 5.7 | 2.9 | 6.3 | |||||||
| HyCoCLIP | 2.0 | 11.0 | 3.6 | 8.4 | 1.3 | 7.8 | 3.8 | 7.9 | 11.7 | 6.1 | 2.4 | 7.4 | 2.3 | 8.0 | |||||||
| HySAC | 64.6 | 76.8 | 61.0 | 71.5 | 42.5 | 53.5 | 66.5 | 73.6 | 50.7 | 57.7 | 53.8 | 66.0 | 44.9 | 55.8 | |||||||
🔼 This table presents the Recall@1 (R@1) scores for seven categories of unsafe content retrieved from the ViSU test set. Recall@1 measures the percentage of times the correct item appears within the top-one retrieval result. The seven unsafe content categories are Hate, Harassment, Violence, Self-harm, Sexual, Shocking, and Illegal activities. The table shows the performance of the HySAC model and several comparison models (CLIP, MERU, HyCoCLIP, and Safe-CLIP) for each category, illustrating their ability to retrieve relevant safe content in response to potentially unsafe queries. Higher scores indicate better performance.
read the caption
Table 8: Retrieval (R@1) for seven categories of unsafe content from ViSU test.
| (-to-) | (-to-) | (-to-) | (-to-) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | R@1 | R@10 | R@1 | R@10 | R@1 | R@10 | R@1 | R@10 | ||||
| Euc EC | 32.8 | 72.0 | 35.7 | 75.4 | 2.1 | 31.5 | 0.0 | 0.2 | ||||
| Hyp Safe-CLIP | 46.9 | 82.3 | 44.7 | 82.5 | 5.1 | 42.1 | 9.8 | 51.7 | ||||
| HySAC | 49.8 | 84.1 | 48.2 | 84.2 | 30.5 | 62.8 | 42.1 | 73.3 | ||||
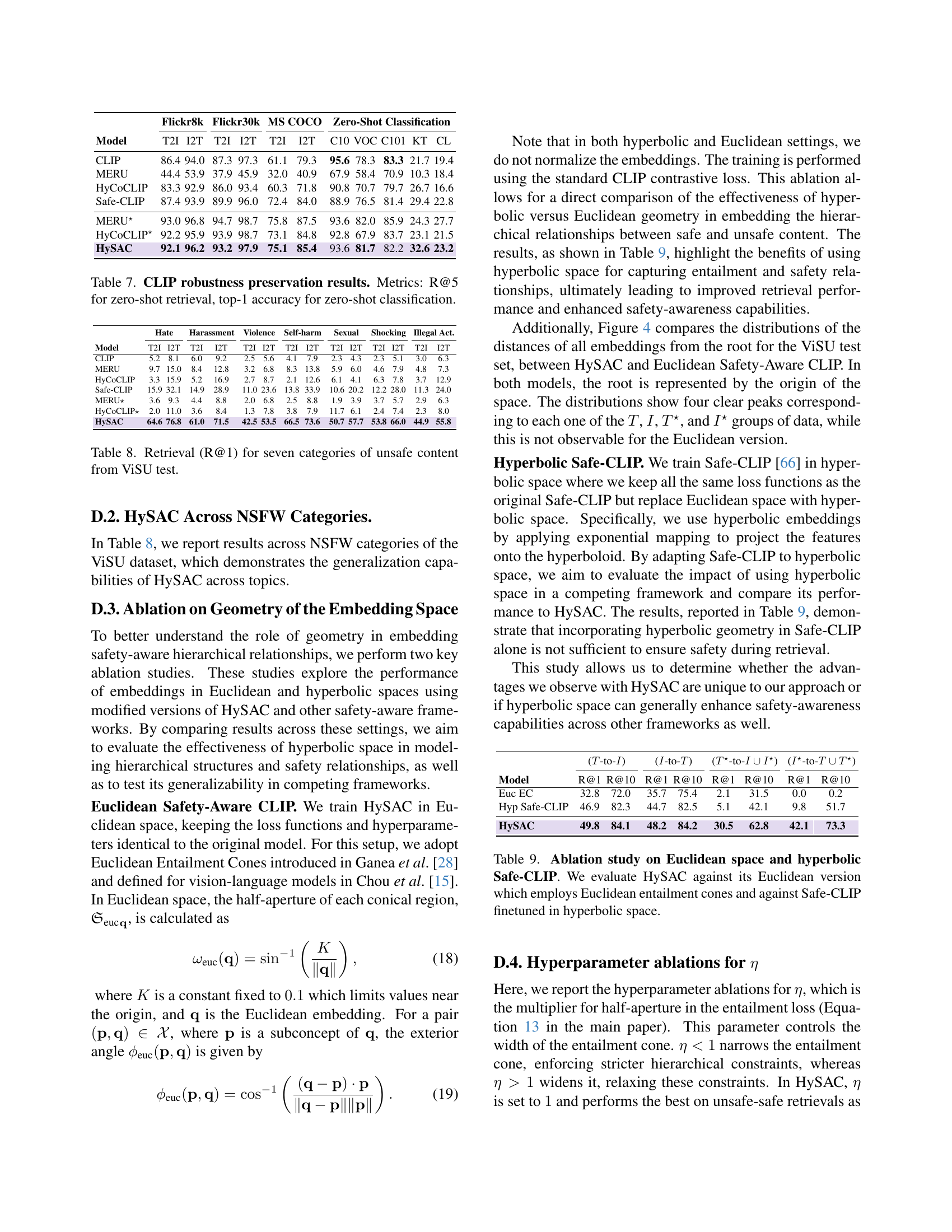
🔼 This table presents the results of an ablation study comparing different model variations to assess the impact of using hyperbolic space for safety-aware vision-language models. The study compares HySAC (the proposed model using hyperbolic space) against two variations: 1) a version of HySAC trained using Euclidean space instead of hyperbolic space, and 2) a version of Safe-CLIP (a state-of-the-art safety-focused model) fine-tuned in hyperbolic space. The comparison is made across multiple metrics, including retrieval performance (R@1 and R@10) for both safe and unsafe content. The results highlight the contribution of hyperbolic geometry for improving safety-awareness and retrieval performance.
read the caption
Table 9: Ablation study on Euclidean space and hyperbolic Safe-CLIP. We evaluate HySAC against its Euclidean version which employs Euclidean entailment cones and against Safe-CLIP finetuned in hyperbolic space.
| (-to-) | (-to-) | (-to-) | (-to-) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@10 | R@1 | R@10 | R@1 | R@10 | R@1 | R@10 | |||||
| 43.8 | 80.2 | 42.6 | 79.5 | 17.4 | 53.8 | 6.0 | 57.8 | |||||
| 37.5 | 74.9 | 35.7 | 73.1 | 7.8 | 41.9 | 4.9 | 49.3 | |||||
| 47.1 | 81.8 | 43.3 | 80.8 | 28.5 | 59.8 | 41.4 | 72.0 | |||||
| 51.7 | 85.1 | 49.3 | 84.6 | 20.1 | 62.2 | 3.6 | 63.3 | |||||
| 51.4 | 84.8 | 50.8 | 84.8 | 4.0 | 49.5 | 6.6 | 65.5 | |||||
| 51.7 | 84.7 | 50.7 | 84.8 | 2.2 | 46.2 | 5.1 | 65.2 | |||||
| HySAC | 49.8 | 84.1 | 48.2 | 84.2 | 30.5 | 62.8 | 42.1 | 73.3 | ||||
🔼 This table presents an ablation study on the hyperparameter η (eta) in the HySAC model. The hyperparameter η controls the width of the entailment cone, which influences how strictly the model enforces the hierarchical relationships between safe and unsafe content. The table shows the performance of the HySAC model trained with different values of η, evaluating both the recall of safe content (safe-to-safe retrieval) and the recall of safe content when starting with unsafe queries (unsafe-to-safe retrieval). The results demonstrate the impact of this hyperparameter on the model’s ability to effectively balance safety and retrieval performance. In the original HySAC model, η is set to 1.0.
read the caption
Table 10: Hyperparameter ablations for η𝜂\etaitalic_η. We train HySAC with different half-aperture scales, comparing only safe recalls and unsafe to safe recalls. In HySAC, η𝜂\etaitalic_η is set to 1.01.01.01.0.
Full paper#