TL;DR#
Text-to-image generation usually relies on training larger models with more data, which is computationally expensive. There’s growing interest in improving performance during inference, mainly through best-of-N sampling. This approach generates multiple images and selects the best, but it’s not very efficient. The paper addresses the computation issues.
The paper introduces Reflect-DiT, which allows diffusion transformers to refine images using previous generations and feedback. Reflect-DiT improves performance by tailoring generations to address specific issues. Experiments show Reflect-DiT improves the GenEval benchmark and achieves a new state-of-the-art score with fewer samples compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper introduces a novel inference-time scaling method that significantly improves the efficiency and performance of text-to-image diffusion models. It is highly relevant to current trends in AI research, particularly in reducing the computational costs. This approach opens new avenues for further research into more efficient AI models.
Visual Insights#

🔼 Reflect-DiT refines image generation iteratively. A vision-language model (VLM) critiques each generated image, providing feedback. A Diffusion Transformer (DiT) uses this feedback, along with previous generations, to improve subsequent generations. This contrasts with standard best-of-N sampling, which passively selects from multiple independent generations. Reflect-DiT actively corrects errors (object count, position, attributes), leading to higher quality images with fewer samples.
read the caption
Figure 1: \ours iteratively refines image generation by using a vision-language model (VLM) to critique generations and a Diffusion Transformer (DiT) to self-improve using past generations and feedback. Specifically, at each generation step N, feedback from previous iterations (N-3, N-2, N-1, …) are incorporated to progressively improve future generations. Unlike traditional best-of-N sampling, \ours actively corrects errors in object count, position, and attributes, enabling more precise generations with fewer samples.
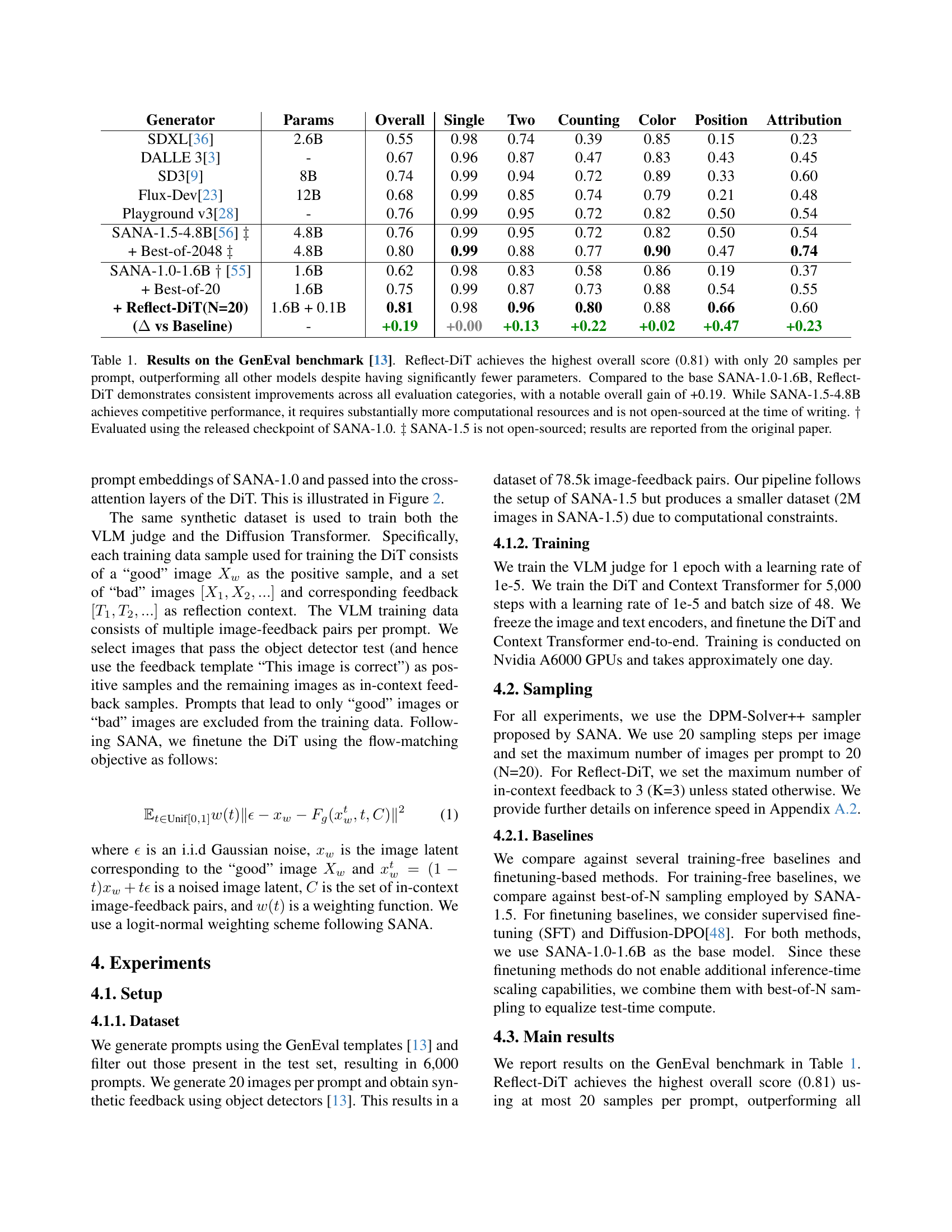
| Generator | Params | Overall | Single | Two | Counting | Color | Position | Attribution | |
| SDXL[36] | 2.6B | 0.55 | 0.98 | 0.74 | 0.39 | 0.85 | 0.15 | 0.23 | |
| DALLE 3[3] | - | 0.67 | 0.96 | 0.87 | 0.47 | 0.83 | 0.43 | 0.45 | |
| SD3[9] | 8B | 0.74 | 0.99 | 0.94 | 0.72 | 0.89 | 0.33 | 0.60 | |
| Flux-Dev[23] | 12B | 0.68 | 0.99 | 0.85 | 0.74 | 0.79 | 0.21 | 0.48 | |
| Playground v3[28] | - | 0.76 | 0.99 | 0.95 | 0.72 | 0.82 | 0.50 | 0.54 | |
| SANA-1.5-4.8B[56] | 4.8B | 0.76 | 0.99 | 0.95 | 0.72 | 0.82 | 0.50 | 0.54 | |
| + Best-of-2048 | 4.8B | 0.80 | 0.99 | 0.88 | 0.77 | 0.90 | 0.47 | 0.74 | |
| SANA-1.0-1.6B [55] | 1.6B | 0.62 | 0.98 | 0.83 | 0.58 | 0.86 | 0.19 | 0.37 | |
| + Best-of-20 | 1.6B | 0.75 | 0.99 | 0.87 | 0.73 | 0.88 | 0.54 | 0.55 | |
| + \ours(N=20) | 1.6B + 0.1B | 0.81 | 0.98 | 0.96 | 0.80 | 0.88 | 0.66 | 0.60 | |
| ( vs Baseline) | - | +0.19 | +0.00 | +0.13 | +0.22 | +0.02 | +0.47 | +0.23 |
🔼 This table presents the results of different text-to-image generation models on the GenEval benchmark. The key finding is that Reflect-DiT achieves state-of-the-art performance (0.81) using only 20 samples per prompt, significantly outperforming other models, even those with substantially more parameters. Reflect-DiT shows consistent improvements across all evaluation metrics compared to its base model (SANA-1.0-1.6B), achieving a +0.19 overall gain. The table highlights the efficiency of Reflect-DiT in contrast to SANA-1.5-4.8B, which, although achieving comparable performance, needs far greater computational resources and is not publicly available.
read the caption
Table 1: Results on the GenEval benchmark [13]. \ours achieves the highest overall score (0.81) with only 20 samples per prompt, outperforming all other models despite having significantly fewer parameters. Compared to the base SANA-1.0-1.6B, \ours demonstrates consistent improvements across all evaluation categories, with a notable overall gain of +0.19. While SANA-1.5-4.8B achieves competitive performance, it requires substantially more computational resources and is not open-sourced at the time of writing. ††{\dagger}† Evaluated using the released checkpoint of SANA-1.0. ‡‡{\ddagger}‡ SANA-1.5 is not open-sourced; results are reported from the original paper.
In-depth insights#
In-Context Refine#
In-context refinement is a compelling paradigm shift in how we approach generative models, moving beyond static, one-shot generation towards iterative refinement driven by contextual information. Instead of solely relying on initial prompts, the model leverages past generations and feedback to improve future outputs. This approach mirrors human creative processes, where we often refine our work based on critiques and self-reflection. The key benefit is the potential for higher quality outputs with fewer samples, as the model actively learns from its mistakes. By explicitly addressing shortcomings identified in previous generations, the model can tailor its subsequent outputs to meet specific requirements, leading to more precise and intentional results. This is particularly valuable for complex tasks with multiple constraints.
DiT Reflection#
The paper introduces “Reflect-DiT,” a novel approach to enhance text-to-image diffusion models by incorporating an in-context reflection mechanism. This allows the Diffusion Transformer (DiT) to iteratively refine its generations by leveraging past generations and textual feedback. Unlike standard methods that rely on best-of-N sampling, Reflect-DiT enables models to explicitly learn from their mistakes and tailor future outputs, leading to more accurate and coherent images. This method shows improvements on benchmark datasets, highlighting its potential as a more efficient alternative to simple best-of-N sampling, making better use of scarce inference resources.
VLM as Feedback#
The concept of using a Vision-Language Model (VLM) as feedback is intriguing. VLMs can assess generated images and provide natural language descriptions of errors or areas for improvement. This feedback guides iterative refinement, enhancing image quality beyond naive sampling. The VLM’s ability to understand both visual and textual data enables targeted corrections, focusing on object attributes, spatial relationships, and overall scene coherence. This approach could significantly improve text-to-image generation by providing explicit direction to the diffusion model, steering it toward more accurate and visually appealing outputs. However, biases and limitations inherited from the VLM could affect feedback quality. Therefore, creating robust and unbiased VLMs is paramount for realizing the full potential of this feedback mechanism.
Iterative Scaling#
Iterative scaling offers a compelling avenue for enhancing text-to-image diffusion models. Traditionally, improvements rely on computationally expensive training-time scaling. Iterative scaling provides a strategic alternative by refining generations during inference. Unlike naive best-of-N sampling, which passively selects from random outputs, this method actively improves images. It uses in-context learning, where models learn from past generations and textual feedback, enabling targeted enhancements. This approach explicitly addresses shortcomings, improving object count, position, and attributes. This approach could lead to significant gains in generation quality and efficiency, with fewer samples required to achieve state-of-the-art results. It potentially reduces the reliance on massive datasets and computational resources for training.
Aligning Objects#
Object alignment in images is a fascinating challenge. The task demands robust understanding of spatial relationships and scene context. Models must accurately position objects relative to each other, adhering to constraints specified in the text. Achieving this requires sophisticated reasoning capabilities and precise control over the generation process. Furthermore, the ability to correct initial misalignments through iterative refinement demonstrates a powerful form of self-correction, mimicking human cognitive processes. The iterative aspect of the object alignment, as seen in this work, contributes significantly to enhancing the quality and coherence of generated images, making them more realistic and aligned with textual descriptions.
More visual insights#
More on figures

🔼 Figure 2 illustrates the architecture of Reflect-DiT, a model that refines image generation iteratively using past generations and feedback. The process begins with a prompt. Past images are encoded into vision embeddings (V1, V2, etc.) using a vision encoder, while textual feedback is encoded into text embeddings (E1, E2, etc.). These embeddings are concatenated into a sequence (M) and passed through a Context Transformer to generate a refined context (M’). This refined context (M’) is added to the standard prompt embeddings and fed into the cross-attention layers of a Diffusion Transformer (DiT). The DiT then produces a refined image, and the cycle repeats until the desired image quality is achieved.
read the caption
Figure 2: Architecture of \ours. Given a prompt, past images and feedback, we first encode the images into a set of vision embeddings [V1,V2,…]subscript𝑉1subscript𝑉2…[V_{1},V_{2},\dots][ italic_V start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_V start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT , … ] using a vision encoder, and encode text feedback to a set of text embeddings [E1,E2…]subscript𝐸1subscript𝐸2…[E_{1},E_{2}...][ italic_E start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_E start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT … ]. We then concatenate these embeddings into a single sequence M𝑀Mitalic_M, and pass it through the Context Transformer to obtain M′superscript𝑀′M^{\prime}italic_M start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT. The extra context M′superscript𝑀′M^{\prime}italic_M start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT is concatenated directly after the standard prompt embeddings and passed into the cross-attention layers of the Diffusion Transformer (DiT).

🔼 This figure presents a qualitative comparison between Reflect-DiT and the traditional best-of-N sampling method for text-to-image generation. It showcases three examples where Reflect-DiT’s iterative refinement process, guided by feedback, leads to more accurate and visually coherent results than best-of-N. The first example illustrates Reflect-DiT’s ability to correct object positioning, the second demonstrates its capacity to resolve multiple counting constraints, and the third highlights its potential for refining object shapes. These examples demonstrate how Reflect-DiT actively addresses specific issues, converging towards more precise and aligned image generations compared to the passive selection approach of best-of-N.
read the caption
Figure 3: Side-by-side qualitative comparison of \ours and best-of-N sampling. \ours leverages feedback to iteratively refine image generations, resulting in more accurate and visually coherent outputs. In the first example, \ours progressively adjusts object positions to better satisfy the prompt “a cup left of an umbrella,” achieving significantly better image-text alignment than best-of-N sampling. The second example demonstrates how \ours corrects multiple counting constraints (“five monarch butterflies” and “a single dandelion”) over successive iterations, gradually converging to the correct solution. Lastly, in the rightmost example, \ours uses in-context feedback to refine object shapes, producing a more precise and intentional design compared to best-of-N.

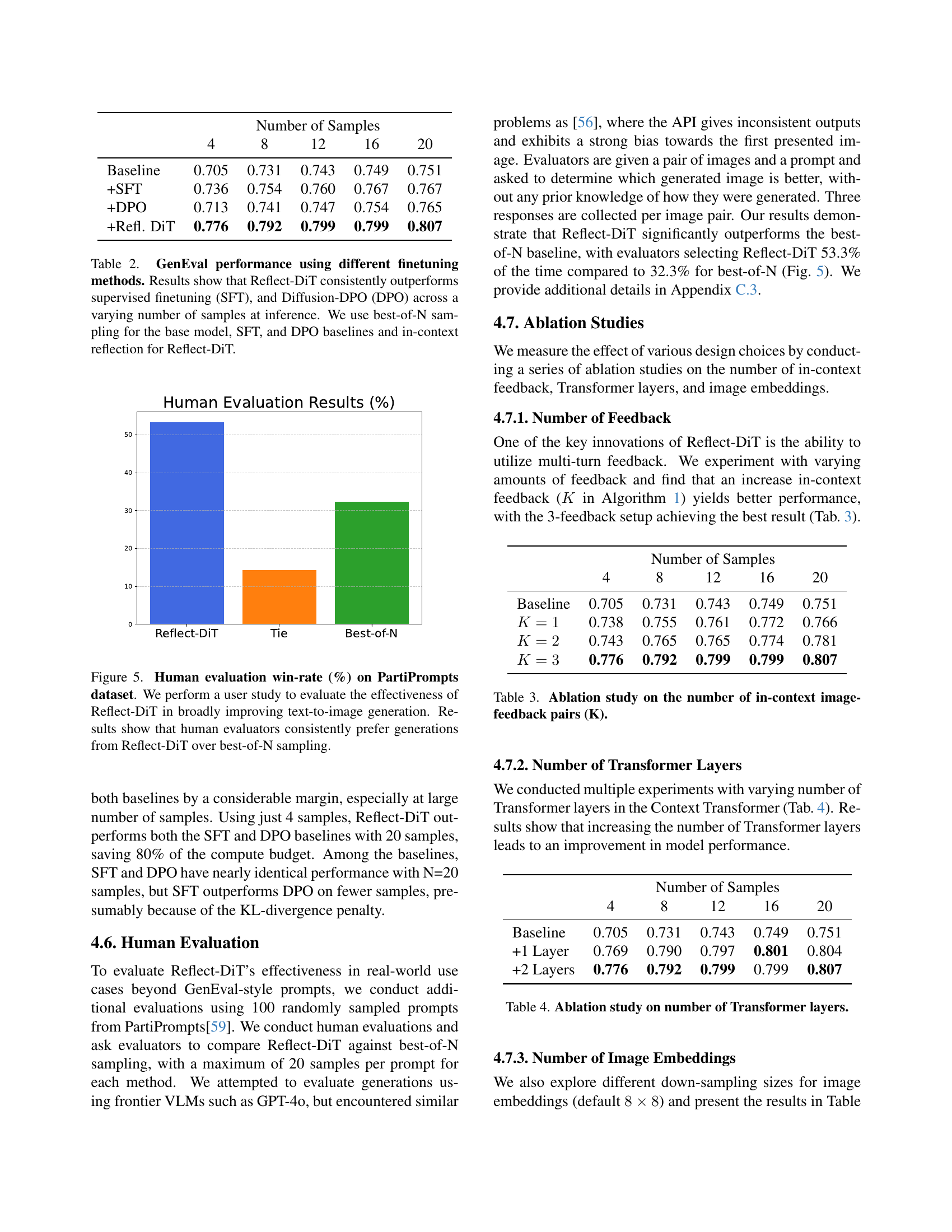
🔼 This figure compares Reflect-DiT’s performance against other fine-tuning methods like Supervised Fine-Tuning (SFT) and Diffusion-DPO (DPO) on the GenEval benchmark. The x-axis represents the number of samples used for image generation, and the y-axis shows the GenEval score. The graph demonstrates that Reflect-DiT consistently achieves higher GenEval scores than SFT and DPO, even when using significantly fewer samples. Notably, with only 4 samples, Reflect-DiT surpasses the performance of SFT and DPO using 20 samples each.
read the caption
Figure 4: Comparison of \ours with other finetuning methods. We find that \ours is able to consistently outperform finetuning methods, like supervised finetuning (SFT) and Diffusion-DPO (DPO). Using only 4 samples, \ours can outperform related finetuning baselines using best-of-20 sampling.

🔼 This figure displays the results of a human evaluation study comparing Reflect-DiT’s image generation capabilities to a traditional best-of-N sampling method. The study used the PartiPrompts dataset, which focuses on more complex image generation tasks than the GenEval benchmark used in other parts of the paper. The win-rate represents the percentage of times human evaluators preferred images generated by Reflect-DiT over the best-of-N approach. The results demonstrate a clear preference for Reflect-DiT, suggesting it produces images of higher quality and better alignment with the prompts.
read the caption
Figure 5: Human evaluation win-rate (%) on PartiPrompts dataset. We perform a user study to evaluate the effectiveness of \ours in broadly improving text-to-image generation. Results show that human evaluators consistently prefer generations from \ours over best-of-N sampling.

🔼 Figure 6 showcases Reflect-DiT’s iterative refinement process through three examples. The first demonstrates correction of object positions and classifications within a complex scene (woman, tree, cat, dog). The second example shows iterative adjustment of object counts (seeds on a dandelion head). The third example highlights the model’s ability to overcome initial misinterpretations of unusual spatial relationships (dog positioned relative to a tie). Each example demonstrates Reflect-DiT’s ability to refine generations based on feedback, ultimately achieving alignment with the prompt’s specifications.
read the caption
Figure 6: Illustration of the iterative refinement process in \ours. \ours starts with an initial image generated from the prompt and progressively refines it based on textual feedback until the final output meets the desired criteria, demonstrating the effectiveness of our reflection-based approach. In the first sequence, \ours handles a complex scene by gradually repositioning multiple objects—“woman,” “tree,” “cat,” and “dog”—to achieve correct spatial alignment. Additionally, it recognizes subtle object misclassifications, such as changing the second “dog” to a “cat” based on feedback. The second example demonstrates a counting problem, where the model iteratively adjusts the number of detached seeds until it converges to the correct count. The final example presents a particularly challenging scenario: the prompt requires the “dog” to be positioned to the “right of a tie”, an unusual object to appear independently. Initially, the model misinterprets the instruction, generating a dog wearing a tie. However, through multiple refinement steps, \ours learns to separate the objects and ultimately produces the correct spatial arrangement.

🔼 Reflect-DiT, while generally effective, occasionally produces errors due to limitations in the feedback from its Vision-Language Model (VLM). The first two examples show cases where the VLM misinterprets subtle details (lighting signifying sunset, color reflection ambiguity). The final two showcase more common failures where small or unusually shaped objects are overlooked, leading to inaccurate feedback and refinement.
read the caption
Figure 7: Failure cases of \ours. Failure cases of \ours. While \ours demonstrates strong refinement capabilities, the generated feedback can occasionally introduce errors between iterations. In the first example, the model fails to recognize that the specific lighting conditions signify a “sunset”, leading to an incorrect adjustment. Similarly, in the second example, the model struggles to distinguish the color of the “dining table” because the purple hue from the “dog” reflects off the table, creating ambiguity. These cases highlight subjectivity in the VLM evaluation, where the model’s interpretation may still be reasonable. However, the final two examples illustrate more typical failure cases. In both images, objects (“boat” and “butterfly”) are completely overlooked by the feedback model. This issue likely arises because the objects are too small or unusually shaped, which makes them difficult to detect, resulting in incorrect evaluations.

🔼 This figure shows the user interface used in a human evaluation study to compare the quality of image generations from Reflect-DiT and a best-of-N baseline. Users were presented with a prompt and two images, one from each method, and asked to select the image that best matched the prompt. Additional space was provided for comments in cases of ambiguity or bugs.
read the caption
Figure 8: User interface for human annotators.
More on tables
| Number of Samples | |||||
|---|---|---|---|---|---|
| 4 | 8 | 12 | 16 | 20 | |
| Baseline | 0.705 | 0.731 | 0.743 | 0.749 | 0.751 |
| +SFT | 0.736 | 0.754 | 0.760 | 0.767 | 0.767 |
| +DPO | 0.713 | 0.741 | 0.747 | 0.754 | 0.765 |
| +Refl. DiT | 0.776 | 0.792 | 0.799 | 0.799 | 0.807 |
🔼 This table compares the performance of Reflect-DiT against several baseline methods on the GenEval benchmark. It demonstrates Reflect-DiT’s superior performance across different numbers of inference samples. The baselines include best-of-N sampling (a common inference-time scaling technique), supervised fine-tuning (SFT), and Diffusion-DPO. Reflect-DiT uses in-context reflection, while the baselines utilize best-of-N sampling.
read the caption
Table 2: GenEval performance using different finetuning methods. Results show that \ours consistently outperforms supervised finetuning (SFT), and Diffusion-DPO (DPO) across a varying number of samples at inference. We use best-of-N sampling for the base model, SFT, and DPO baselines and in-context reflection for \ours.
| Number of Samples | |||||
|---|---|---|---|---|---|
| 4 | 8 | 12 | 16 | 20 | |
| Baseline | 0.705 | 0.731 | 0.743 | 0.749 | 0.751 |
| 0.738 | 0.755 | 0.761 | 0.772 | 0.766 | |
| 0.743 | 0.765 | 0.765 | 0.774 | 0.781 | |
| 0.776 | 0.792 | 0.799 | 0.799 | 0.807 | |
🔼 This table presents the results of an ablation study investigating the impact of varying the number of in-context image-feedback pairs (K) on the performance of the Reflect-DiT model. The study examines how changing the amount of past image generations and feedback used to refine subsequent generations affects the overall quality of the generated images. The results are likely shown across different numbers of samples used in inference to understand the effect of different compute budgets.
read the caption
Table 3: Ablation study on the number of in-context image-feedback pairs (K).
| Number of Samples | |||||
|---|---|---|---|---|---|
| 4 | 8 | 12 | 16 | 20 | |
| Baseline | 0.705 | 0.731 | 0.743 | 0.749 | 0.751 |
| +1 Layer | 0.769 | 0.790 | 0.797 | 0.801 | 0.804 |
| +2 Layers | 0.776 | 0.792 | 0.799 | 0.799 | 0.807 |
🔼 This table presents the results of an ablation study investigating the impact of varying the number of transformer layers within the context transformer of the Reflect-DiT model. It shows how the GenEval benchmark scores change as the number of transformer layers increases, for different sample sizes (4, 8, 12, 16, and 20). The goal is to determine the optimal number of layers for balancing model performance and computational cost.
read the caption
Table 4: Ablation study on number of Transformer layers.
| Number of Samples | |||||
|---|---|---|---|---|---|
| 4 | 8 | 12 | 16 | 20 | |
| Baseline | 0.705 | 0.731 | 0.743 | 0.749 | 0.751 |
| 0.770 | 0.779 | 0.783 | 0.786 | 0.786 | |
| 0.752 | 0.781 | 0.795 | 0.795 | 0.801 | |
| 0.776 | 0.792 | 0.799 | 0.799 | 0.807 | |
🔼 This ablation study investigates the impact of varying the dimensionality of image embeddings on the performance of Reflect-DiT. It shows how changing the spatial resolution of the image features used for context (4x4, 6x6, 8x8 pixels) affects the GenEval scores achieved by the model with different numbers of samples.
read the caption
Table 5: Ablation study on the size of image embeddings.
| Parm. | All | Hard-246 | Hard-56 | |
|---|---|---|---|---|
| SD3-Medium | 2B | 84.1 | - | - |
| DALLE 3 | - | 83.5 | - | - |
| FLUX-dev | 12B | 84.0 | - | - |
| SANA-1.5 | 4.8B | 85.0 | - | - |
| SANA-1.0 | 1.6B | 84.1 | 56.1 | 24.2 |
| +Best-of-20 | 1.6B | 85.6 | 63.4 | 41.0 |
| +\ours | 1.7B | 86.1 | 69.5 | 51.8 |
| ( vs Base.) | - | +2.0 | +13.4 | +27.6 |
🔼 Table 6 presents a comparison of different text-to-image generation models’ performance on the DPG-Bench benchmark. It focuses on the performance of Reflect-DiT compared to other models, including SANA baselines and best-of-N sampling approaches, showcasing its robustness and generalizability. The table includes scores on the overall DPG-Bench and also on two challenging subsets of prompts (Hard-246 and Hard-56) where the baseline models underperform. This highlights Reflect-DiT’s improvement, especially on difficult prompts. The footnote clarifies that results for SANA-1.5 are from the original paper because that model’s inference-time scaling results are not publicly available, and the single-sample results are used instead for comparison.
read the caption
Table 6: Additional quantitative results on DPG-Bench [18] ††{\dagger}† SANA-1.5 only reported inference-time scaling (best-of-2048) on GenEval benchmark and has not been open sourced. We cite their single-sample result here.
| VLM Training Data Template | |
| { "from": "human", "value": "<image>\n Please evaluate this generated image based on the following prompt: [[prompt]]. Focus on text alignment and compositionality." }, { "from": "gpt", "value": "[[feedback_text]]" } |
🔼 This table shows the template used for training the Vision-Language Model (VLM) in the Reflect-DiT framework. The VLM acts as a judge, providing feedback on generated images. The training data consists of image-feedback pairs formatted as JSON, structured with ‘from’ and ‘value’ fields. The ‘from’ field specifies the source (human or the language model), and the ‘value’ field contains the image data or feedback text, respectively.
read the caption
Table 7: VLM Training Data Template
| Hyperparameters | VLM Judge | \ours | SFT | Diffusion-DPO |
|---|---|---|---|---|
| Learning Rate | 1e-5 | 1e-5 | 1e-5 | 1e-5 |
| Batch Size | 48 | 48 | 48 | (24, 24)* |
| Weight Decay | 0.1 | 0 | 0 | 0 |
| Optimizer | AdamW | CAME | CAME | CAME |
| Schedule | 1 epoch | 5k step | 5k step | 5k step |
| Warmup steps | 0.03 epoch | 500 step | 500 step | 500 step |
🔼 This table details the hyperparameters used in the training process for different components of the Reflect-DiT model and its baselines. It shows the learning rate, batch size, weight decay, optimizer used (AdamW or CAME), and the number of warmup steps for the VLM judge, Reflect-DiT model itself, the supervised finetuning (SFT) baseline, and the Diffusion-DPO baseline. Note that for the Diffusion-DPO baseline, the batch size is a tuple indicating the number of positive and negative samples used per batch (24 positive and 24 negative samples).
read the caption
Table 8: Hyperparameters used for each experiment. * We use 24 positive samples and 24 negative samples per batch.
Full paper#