TL;DR#
Recent studies have focused on quantifying LLM uncertainty with theoretically grounded and average-behavior metrics, but none addressed human behavior alignment. To fill this gap, the study investigates various uncertainty measures. The goal is to discover which ones align with human group-level uncertainty. The research found that Bayesian measures and a modification of entropy measures, known as top-k entropy, tend to agree with human responses in proportion to the model size.
This paper directly compares human uncertainty against diverse LLM measures. The study introduces new measures for LLMs, such as nucleus size, top-k entropy, choice entropy, and derivative uncertainty metrics. Crucially, the research demonstrates that mixtures of uncertainty measures can achieve human alignment without size dependency. The data used are manually collected from the Pew Research Center’s American Trends Panel (ATP) Datasets.
Key Takeaways#
Why does it matter?#
This paper pioneers direct comparison of LLM & human uncertainty, crucial for safe AI integration. It identifies key uncertainty measures for human alignment, fostering trust & collaboration, and paves the way for further research into nuanced human-AI interaction.
Visual Insights#

🔼 This figure shows the prompt used in the study to assess human-like uncertainty in large language models (LLMs). The prompt presents a question followed by a selection of answer choices. The LLM is instructed to provide the label corresponding to the answer choice it most agrees with. This setup is designed to gather the LLM’s probability distribution over the given vocabulary, specifically focusing on the model’s confidence in its response rather than correctness since the answers do not have a definitively correct answer. This allows direct comparison of model uncertainty with human uncertainty in similar scenarios.
read the caption
Figure 1: Prompt to measure presence/absence belief.
In-depth insights#
Human vs. LLM UQ#
The comparative analysis of human and LLM uncertainty quantification (UQ) is a nascent yet critical area. Humans often express uncertainty influenced by contextual factors, biases, and nuanced understanding, whereas LLMs quantify it based on statistical probabilities derived from training data. Bridging this gap is vital for trustworthy AI. LLMs, despite their advanced capabilities, can exhibit overconfidence or miscalibration, failing to align with human intuition. Further research should focus on developing UQ methods that incorporate aspects of human cognition, enabling LLMs to express uncertainty in a more human-aligned manner. This involves improving model transparency, incorporating common-sense reasoning, and accounting for contextual nuances that influence human judgment. The ultimate goal is to enhance human-AI collaboration by ensuring that LLMs not only provide accurate predictions but also communicate their uncertainty in a way that fosters appropriate trust and reliance.
Novel UQ Measures#
In the realm of uncertainty quantification (UQ) for large language models (LLMs), novel measures represent a critical frontier for enhancing model reliability and user trust. Such measures could explore new statistical methods beyond traditional entropy or variance, possibly incorporating Bayesian approaches more deeply to capture epistemic uncertainty. Furthermore, innovations might focus on contextualizing uncertainty, tailoring measures to specific tasks or domains, acknowledging that uncertainty’s relevance varies. Also, research could investigate hybrid measures, combining existing techniques in unique ways to capture multifaceted aspects of uncertainty. A promising direction is the development of human-aligned UQ measures, calibrated to reflect human perceptions of uncertainty, thereby fostering more intuitive human-AI interaction and decision-making, ultimately leading to safer and more trustworthy deployment of LLMs.
Mixtures improve UQ#
The idea that mixtures improve Uncertainty Quantification (UQ) hints at the potential benefits of combining multiple uncertainty measures. Individually, each UQ measure may capture only certain aspects of model uncertainty, possibly leading to skewed or incomplete assessments. By combining various measures, the strengths of one can compensate for the weaknesses of another, leading to a more robust and accurate overall UQ. This is particularly relevant since different measures rely on diverse underlying principles, such as entropy, variance, or Bayesian approaches. A mixture could, for instance, use an entropy-based measure to capture aleatoric uncertainty and a Bayesian measure to capture epistemic uncertainty. A well-designed mixture might also be less susceptible to biases or sensitivities that individual measures exhibit. Furthermore, mixtures can leverage machine learning techniques to learn the optimal weighting or combination of different measures, potentially adapting to various tasks or data distributions. In essence, a mixture approach provides a more nuanced and comprehensive assessment of uncertainty, surpassing the limitations of relying on any single measure. The effectiveness of mixtures in UQ relies on careful selection of the component measures and the appropriate strategy for combining them.
Exp Design & UQ#
The paper’s experimental design employs a consistent, shared base query format across all LLM experiments, facilitating a standardized evaluation. The inclusion of cloze testing, especially over answer choice label tokens, to discern the model’s chosen answer is insightful, allowing for the determination of the most probable choice. Uncertainty Quantification (UQ) focuses on eight measures: self-reported, response frequency, nucleus size, vocabulary entropy, choice entropy, top-k entropy, population variance and population self-reported. This comprehensive set covers multiple UQ categories: self-report, consistency, logit, entropy, and ensemble-based. The use of Monte Carlo dropout to create ensembles for uncertainty estimation is a computationally efficient approach. The paper innovatively uses Nucleus Size (NS) as a novel UQ indicator, which is equivalent to credible interval. It also considers top-k entropy as a measure of the confidence on the top-k probable tokens. CE and KE are novel uncertainty measures, the former restricting vocabulary to answer choices and the latter restricting it to the top-k probable tokens.
Future UQ avenues#
Future research in Uncertainty Quantification (UQ) should prioritize developing methods applicable to black-box LLMs, as white-box models are less representative of real-world applications. Addressing the limitations of current UQ metrics, such as dependence on specific model families (e.g., LLaMA, Mistral), is crucial for broader applicability. Additionally, exploring uncertainty in scenarios beyond cloze-testing and constrained generation, such as unconstrained text generation, could yield valuable insights into model reliability. The design of experiments needs to include methods capable of capturing uncertainty behavior in more diverse scenarios. Moreover, comparing individual LLM uncertainty with individual human uncertainty could refine our understanding of human-AI alignment. Future efforts should refine metrics for dynamic k-selection in Top-K Entropy or adapt Relevance Frequency for improved human-similarity. Lastly, investigating the scalability of ensemble methods and exploring alternative measures to counteract limitations imposed by increased model size is paramount. Balancing human-like strategic behavior with a strong measure of overall agreement should be the key area of focus for future works.
More visual insights#
More on figures

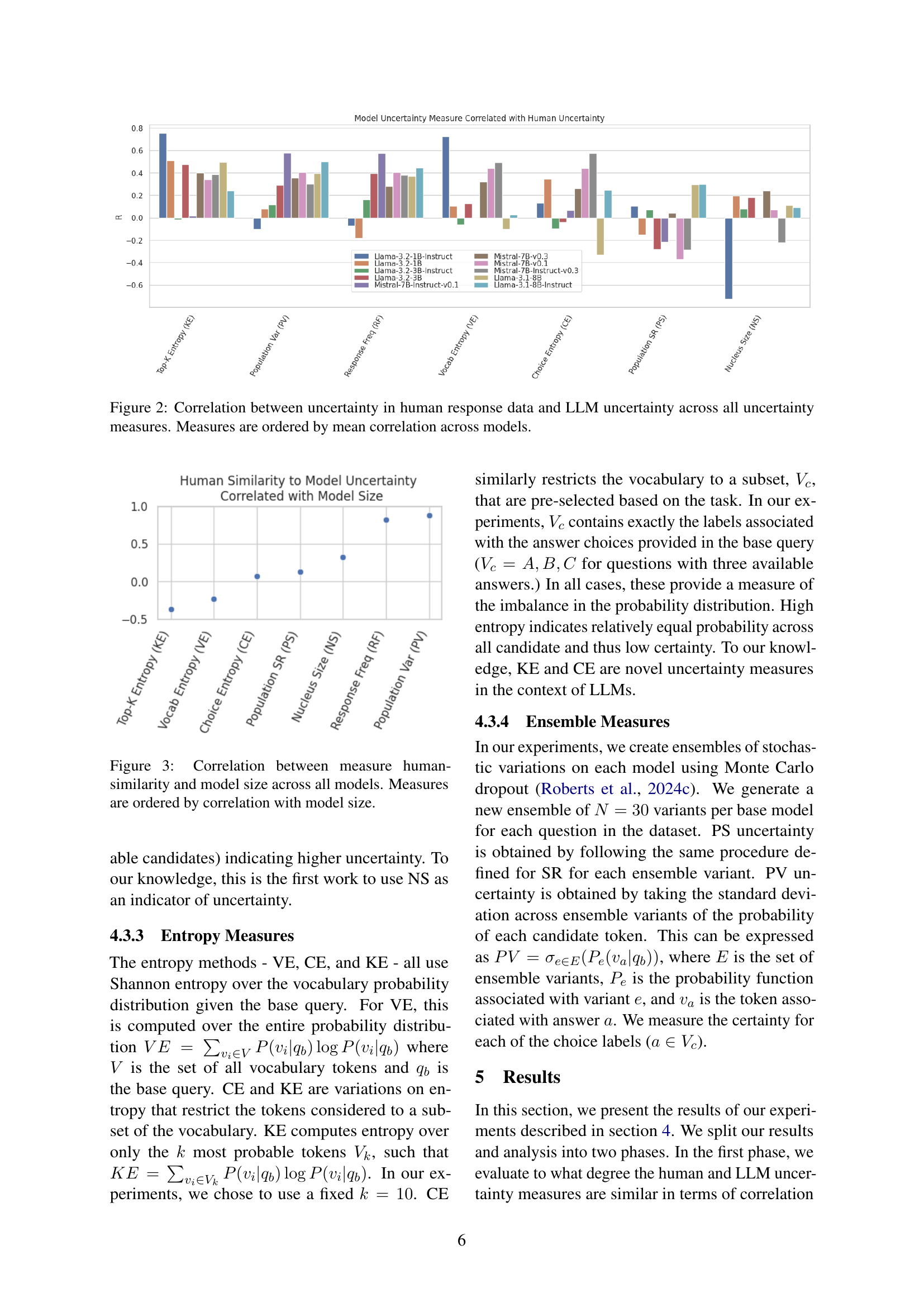
🔼 This figure displays the correlation between human-perceived uncertainty and various LLM uncertainty measures across different models. Human uncertainty was calculated as the entropy of response distributions for questions with no single correct answer. Each bar represents a specific uncertainty measure (e.g., Top-K Entropy, Vocabulary Entropy) for a particular LLM model. The bars are ordered from highest average correlation with human uncertainty to lowest, providing a visual comparison of which LLM uncertainty measures best align with human judgment of uncertainty.
read the caption
Figure 2: Correlation between uncertainty in human response data and LLM uncertainty across all uncertainty measures. Measures are ordered by mean correlation across models.

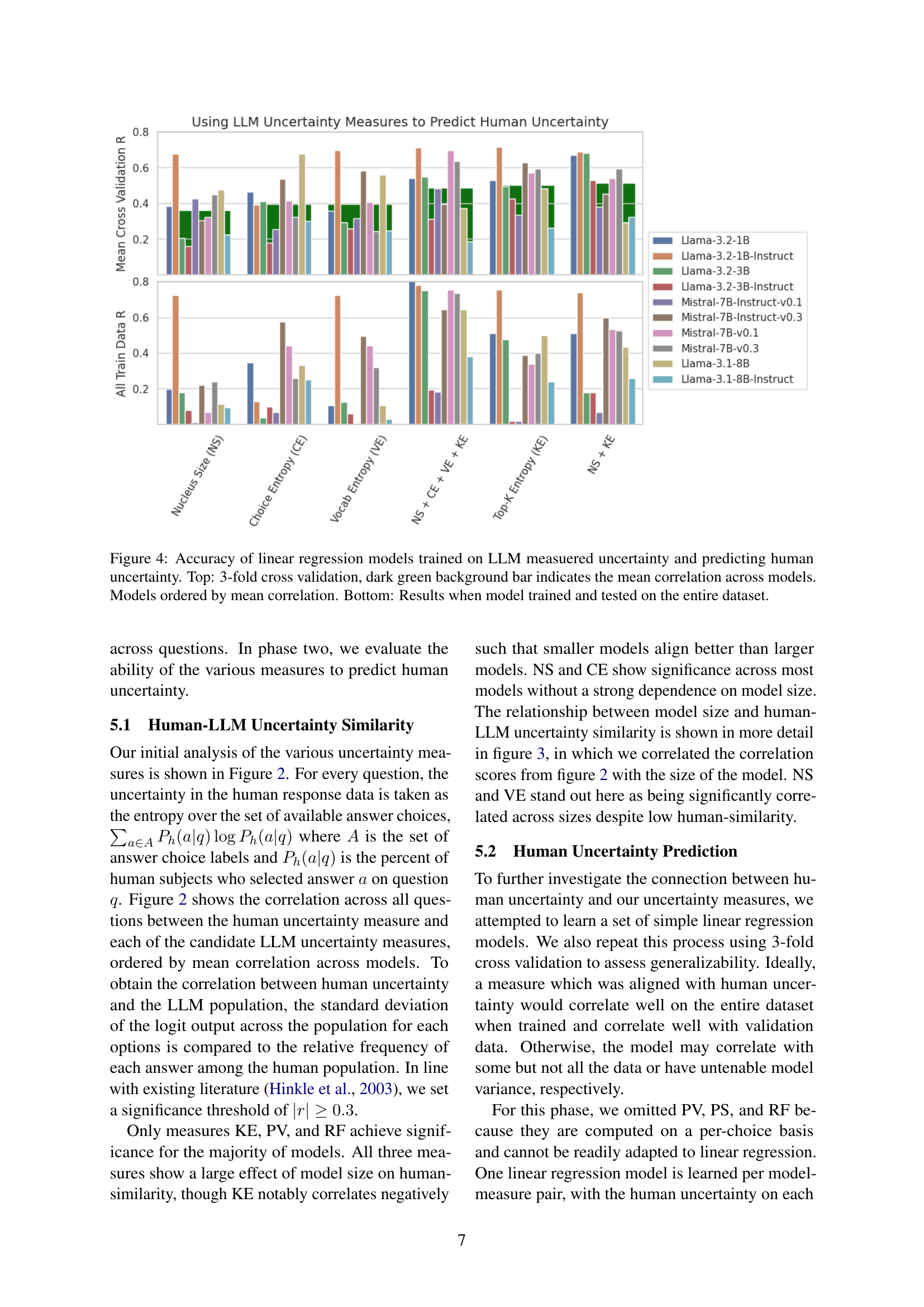
🔼 This figure displays the correlation between the degree of alignment between model-generated uncertainty and human-perceived uncertainty, and the size of the language model. Each data point represents a specific uncertainty measure applied to various language models of different sizes. The measures are ranked based on their correlation with model size; measures with stronger correlations are placed higher in the figure. This visualization helps to understand how different measures of uncertainty behave differently across models of various sizes.
read the caption
Figure 3: Correlation between measure human-similarity and model size across all models. Measures are ordered by correlation with model size.
Full paper#