TL;DR#
The paper addresses challenges in building autonomous agents for humanoid robots, where directly combining Foundation Models (FMs) for high-level cognition with low-level skills often results in poor robustness and efficiency. This is due to compounding errors in long-horizon tasks and varied module latencies. To resolve this, the authors introduce Being-0, a hierarchical agent framework that integrates an FM with a modular skill library.
Being-0 utilizes a novel Connector module, powered by a lightweight vision-language model (VLM), to bridge the gap between the FM’s language-based plans and the execution of low-level skills. This enhances embodied decision-making and effectively coordinates locomotion and manipulation. With most components deployable on low-cost onboard devices, Being-0 achieves efficient, real-time performance on a full-sized humanoid robot.
Key Takeaways#
Why does it matter?#
Being-0 offers a practical framework for humanoid robots in real-world tasks, balancing cloud-based planning with on-robot skill execution. It is relevant for researchers by demonstrating efficient, real-time performance, and opens up avenues for advancing humanoid dexterity, navigation, and human-robot collaboration.
Visual Insights#

🔼 Being-0 is a hierarchical framework for humanoid robots. It consists of three main components: a Foundation Model (FM) for high-level planning and reasoning; a Connector, a vision-language model (VLM), which translates high-level plans into low-level actions; and a Modular Skill Library for locomotion and manipulation. These components work together to enable the robot to perform complex, long-horizon tasks in real-world environments.
read the caption
Figure 1: Overview of the Being-0 framework. The humanoid agent framework, Being-0, comprises three key components: (1) the Foundation Model (FM) for high-level task planning and reasoning, (2) the Connector, a vision-language model (VLM) that bridges the FM and low-level skills, and (3) the Modular Skill Library for robust locomotion and dexterous manipulation. Together, these components enable Being-0 to effectively control a full-sized humanoid robot equipped with multi-fingered hands and active vision, solving complex, long-horizon embodied tasks in real-world environments.
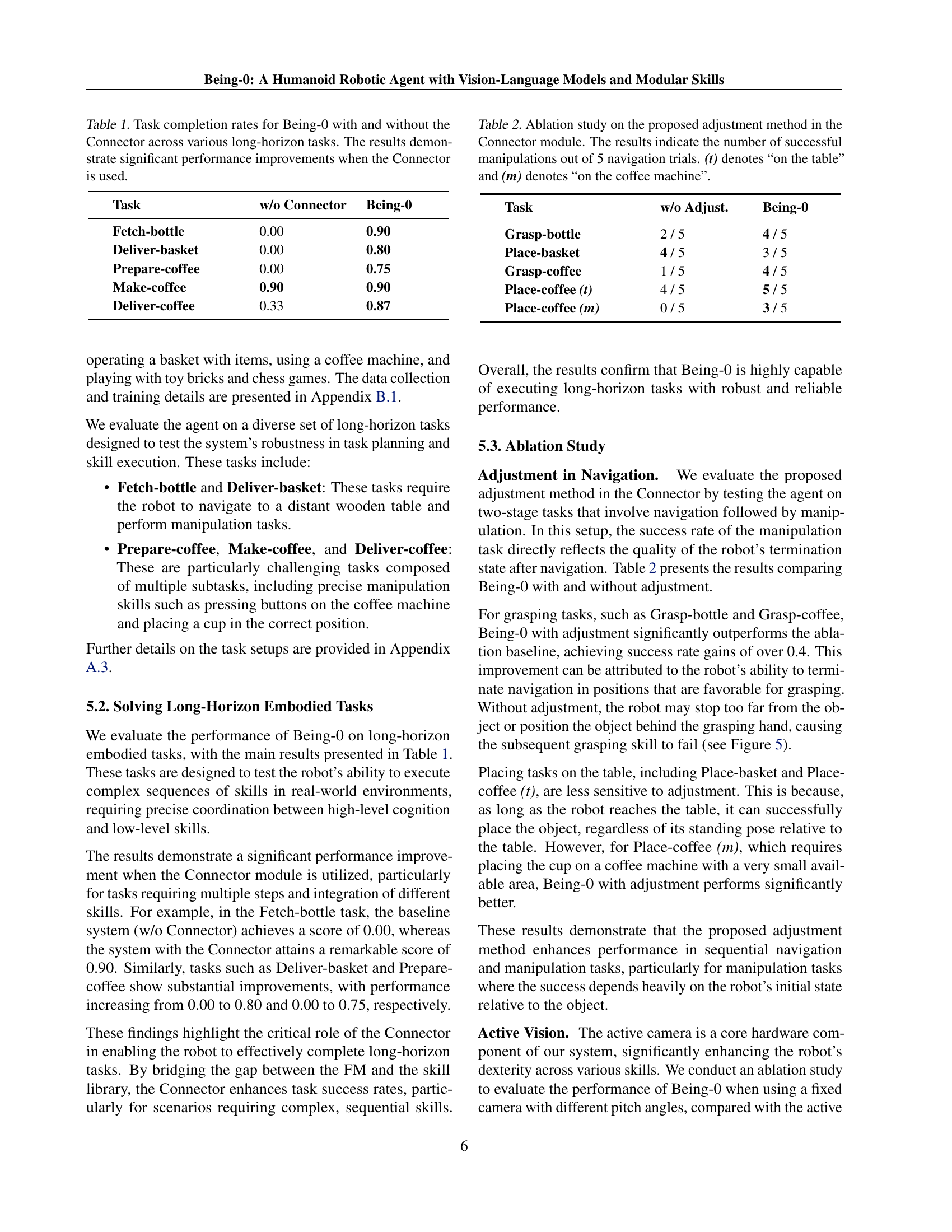
| Task | w/o Connector | Being-0 |
| Fetch-bottle | 0.00 | 0.90 |
| Deliver-basket | 0.00 | 0.80 |
| Prepare-coffee | 0.00 | 0.75 |
| Make-coffee | 0.90 | 0.90 |
| Deliver-coffee | 0.33 | 0.87 |
🔼 This table presents a comparison of the task completion success rates for the Being-0 robotic agent, both with and without the Connector module, across a range of complex, long-horizon tasks. The results clearly show a substantial increase in successful task completion when the Connector module is utilized, highlighting its significant contribution to the overall performance of the agent.
read the caption
Table 1: Task completion rates for Being-0 with and without the Connector across various long-horizon tasks. The results demonstrate significant performance improvements when the Connector is used.
In-depth insights#
Skill Stitching#
Skill stitching is crucial for humanoid robots to perform complex tasks. The paper highlights the challenges in smoothly transitioning between skills like navigation and manipulation, requiring precise pose adjustments to avoid failures. A vision-language model, or a similar connector, is proposed to bridge the gap between high-level plans and low-level skill execution. The connector enhances decision-making and coordination to improve task success and efficiency. This integration facilitates real-time adaptation, better task sequencing, and improved robustness in dynamic environments. Skill coordination leads to successful completion of complicated tasks in real-world scenarios.
VLM Connector#
The VLM Connector serves as a crucial bridge, translating FM plans into actionable skills. By grounding abstract language plans in real-time visual input, it enhances the robot’s adaptability and robustness. Key functions include grounding FM plans, closed-loop navigation, and improving transitions between navigation and manipulation. It leverages visual understanding and object detection to inform skill selection. The VLM’s rapid inference capabilities and pose adjustment improve the initialization states for subsequent manipulations, reducing compounding errors and enhancing overall task success with greater navigation efficiency. This approach allows the robot to perceive surroundings, adapt to unexpected obstacles, and coordinate locomotion and manipulation to tackle complex, long-horizon tasks in dynamic environments.
Active Vision#
The research paper highlights the significant role of active vision in enhancing a humanoid robot’s capabilities. Traditional fixed camera setups impose limitations on both navigation and manipulation tasks. By contrast, Being-0, equips the humanoid with an actuated neck and binocular RGB cameras, enabling it to dynamically adapt its field of view. This dynamic adjustment is crucial for tasks requiring both broad environmental awareness during navigation and precise object localization for manipulation. The system leverages VLM to estimate the relative position and trigger locomotion skills, allowing robot can search the target in 3D space. The integration of an active camera consistently achieves high success rates, showcasing superior performance in tasks where visual adaptability is essential. This approach, therefore, significantly contributes to the robot’s dexterity and robustness in complex, real-world environments.
FM + Skills#
Combining Foundation Models (FMs) with robotic skills holds immense potential but faces challenges. FMs excel at high-level planning but can lack real-time responsiveness needed for complex robotic tasks. The efficiency and precision of FMs directly control robots are often compromised. Directly connecting FMs with skills often leads to issues, particularly for humanoid robots due to their unstable locomotion. Humanoid robots’ unpredictable movements necessitate continuous adjustments, exceeding the processing capabilities of existing FMs and compounding errors. The inherent instability of humanoid robots requires FM to continuously react and adjust, adding an additional layer of complexity.
Limited FM#
Limited FMs in Robotics: The paper highlights challenges when directly using large, general-purpose Foundation Models (FMs) like GPT-40 for humanoid robots. Instability and poor 3D understanding lead to inefficiency. High inference times make real-time adaptation difficult. This motivates exploring smaller, specialized models, like the VLM-based Connector, which can perform grounded planning. It also calls for finding a lightweight design in model architecture to optimize resource allocation.
More visual insights#
More on figures

🔼 Figure 2 illustrates the step-by-step workflow of the Being-0 system in accomplishing the task of ‘making a cup of coffee’. The process is divided into two rows of images, progressing from left to right. Yellow borders highlight the decision points where the Foundation Model (FM) plans the next step, presented in yellow dialog boxes. The Connector module’s decisions are shown in green boxes, while the blue boxes represent the low-level skills from the modular skill library that are executed. This visualization helps to understand the hierarchical interaction between the high-level planning (FM), mid-level coordination (Connector), and low-level skill execution.
read the caption
Figure 2: Workflow of Being-0 for the task “make a cup of coffee”. The figure illustrates the step-by-step execution of the task, with images arranged in two rows. The execution order proceeds left to right in the first row, then continues left to right in the second row. Images with yellow borders indicate decision-making points for the Foundation Model (FM). The yellow dialog boxes display the FM’s plans, the green boxes show decisions made by the Connector, and the blue boxes represent the skills called from the modular skill library.

🔼 This figure compares the performance of two versions of the Being-0 robotic agent on the ‘Prepare-coffee’ task. The top row shows the agent without the Connector module, highlighting frequent queries to the Foundation Model (FM) due to poor embodied scene understanding, ultimately failing to complete the task. The bottom row demonstrates the improved performance of the agent with the Connector module, which successfully bridges the high-level planning of the FM and low-level robot control, resulting in task completion with far fewer queries to the FM.
read the caption
Figure 3: A comparison of Being-0 w/o Connector and Being-0 in the long-horizon task “Prepare-coffee.” The first row shows recordings of Being-0 without the Connector, while the second row shows recordings of Being-0 with the Connector. Being-0 w/o Connector frequently queries the FM, which often fails to provide correct plans due to its limited embodied scene understanding. In contrast, Being-0 with the Connector completes the task, requiring only a few queries to the FM.

🔼 This figure presents an ablation study comparing the performance of Being-0 with different camera configurations on navigation and manipulation tasks. The left three images in each row show the navigation phase, where the robot moves toward a target object (coffee machine). The right three images display the subsequent manipulation phase (grasping coffee). The rows represent different setups: fixed cameras with varying pitch angles (0.3, 0.6, and 0.9 radians) and Being-0 with its active camera. The results clearly show that only Being-0, using its active camera, successfully completes both tasks reliably. Fixed camera setups, regardless of angle, fail to achieve consistent success in either navigation or manipulation.
read the caption
Figure 4: Recordings from the ablation study on the active camera. Each row represents a different camera configuration, with the left three images depicting the navigation task and the right three images depicting the manipulation task. Only Being-0 with an active camera achieves robust performance in both navigation and manipulation.

🔼 This figure compares the performance of the Being-0 agent with and without the proposed adjustment method for navigation. Two-stage tasks were used, each consisting of navigation followed by manipulation. The left three images in each row show the results of Being-0 without the adjustment, demonstrating that improper navigation poses often led to failed manipulation attempts. The right three images show Being-0 with the adjustment, highlighting its success in producing appropriate poses for successful manipulation.
read the caption
Figure 5: A comparison of Being-0 with and without the adjustment method in two-stage tasks involving navigation and manipulation. Each row corresponds to a specific task, with the left three images showing results for Being-0 w/o Adjustment and the right three images showing results for Being-0. Without adjustment, the agent may terminate navigation in improper poses, leading to failed manipulations.

🔼 This figure presents a series of first-person viewpoints demonstrating the humanoid robot’s learned manipulation skills. Each row showcases a different skill, with images progressing from left to right to illustrate the sequential steps involved in successfully completing each task. The skills shown highlight the robot’s dexterity and precision in manipulating various objects.
read the caption
Figure 6: First-person view recordings of the learned manipulation skills. Each row corresponds to a specific skill, with images from left to right depicting the progression of the manipulation process.

🔼 This figure shows the detailed reasoning process of the Foundation Model (FM) in Being-0 while executing the ‘Prepare-coffee’ task. It breaks down the task into subtasks and illustrates how the FM uses image observation and reasoning to decide on the next action. The process is depicted in three stages: 1. Information gathering, including image description, target identification, and self-reflection. 2. Task Inference, involving subtask identification and reasoning. 3. Action planning, outlining the next action to be taken and the reasoning behind it. Each step demonstrates how the FM reasons about the task, identifies the next step, and plans accordingly, showcasing its hierarchical decision-making process in tackling complex tasks.
read the caption
Figure 7: Planning traces of the Foundation Model in Being-0 for the task “Prepare-coffee.”

🔼 This figure shows a continuation of the planning traces from Figure 7, illustrating how the Foundation Model (FM) in the Being-0 framework plans and reasons to complete the ‘Prepare-coffee’ task. It details the FM’s image observations, reasoning, task inference, action planning, and self-reflection steps as it guides the robot through various subtasks, like grabbing the cup and interacting with the coffee machine. The traces provide a detailed, step-by-step view of the FM’s decision-making process and highlight its ability to break down a complex task into smaller, manageable actions.
read the caption
Figure 8: (Continued) Planning traces of the Foundation Model in Being-0 for the task “Prepare-coffee.”

🔼 Figure 9 shows a continuation of the detailed planning process of the Foundation Model in the Being-0 framework for the ‘Prepare-coffee’ task. It illustrates the step-by-step reasoning, decision-making, and action planning of the Foundation Model as it processes visual information and updates its understanding of the task’s progress. The figure details the model’s internal state, including its understanding of the current situation, the selection of subsequent actions, and its self-reflection on past actions. This detailed trace provides insights into the internal workings of the Foundation Model and its ability to decompose complex tasks into smaller, manageable subtasks.
read the caption
Figure 9: (Continued) Planning traces of the Foundation Model in Being-0 for the task “Prepare-coffee.”

🔼 This figure shows a continuation of the detailed planning steps taken by the Foundation Model (FM) in the Being-0 system while attempting to complete the ‘Prepare-coffee’ task. It provides a detailed, step-by-step view of how the FM processes visual information from the robot’s cameras, reasons about the task’s progress, and plans subsequent actions. The detailed text shows the FM’s internal reasoning steps, including image descriptions, subtask inferences, self-reflection analysis, and the selection of actions. This illustrates the complex decision-making process involved in executing even a seemingly simple task like making coffee with a humanoid robot.
read the caption
Figure 10: (Continued) Planning traces of the Foundation Model in Being-0 for the task “Prepare-coffee.”

🔼 This figure displays the planning traces of the Foundation Model used in the Being-0 system (without the Connector module) while executing the ‘Prepare-coffee’ task. It shows a step-by-step breakdown of how the model reasons, makes decisions, and selects actions based solely on its high-level understanding and without the benefit of real-time visual feedback from the Connector. Each step includes the model’s interpretation of the image data, its reasoning process, the selected action, and a self-reflection evaluating the success of the previous action. The detailed traces highlight the challenges faced by a purely high-level approach in executing complex, real-world tasks, particularly involving navigation and manipulation in dynamic environments.
read the caption
Figure 11: Planning traces of the Foundation Model in Being-0 w/o Connector for the task “Prepare-coffee.”

🔼 This figure shows the detailed planning traces of the Foundation Model in the Being-0 framework, specifically when the Embodied Connector module is NOT used, for the task of preparing coffee. It provides a step-by-step breakdown of the Foundation Model’s reasoning, including image descriptions, self-reflection on previous actions, inference of subtasks, and ultimately, the planned actions for the robot. This detailed view highlights the challenges faced by the Foundation Model when operating without the intermediary assistance of the Connector, revealing its difficulties in consistently achieving successful task completion due to limitations in real-time visual understanding and precise skill execution.
read the caption
Figure 12: (Continued) Planning traces of the Foundation Model in Being-0 w/o Connector for the task “Prepare-coffee.”

🔼 This figure shows the detailed planning traces of the Foundation Model in the Being-0 system without the Connector module for the ‘Prepare coffee’ task. It provides a step-by-step breakdown of the model’s reasoning, including image descriptions, self-reflection, task inference, and action planning. It illustrates the challenges of using the Foundation Model alone, such as failure to detect the cup on the table and inefficient search strategies, due to a lack of direct perception and embodiment.
read the caption
Figure 13: (Continued) Planning traces of the Foundation Model in Being-0 w/o Connector for the task “Prepare-coffee.”
More on tables
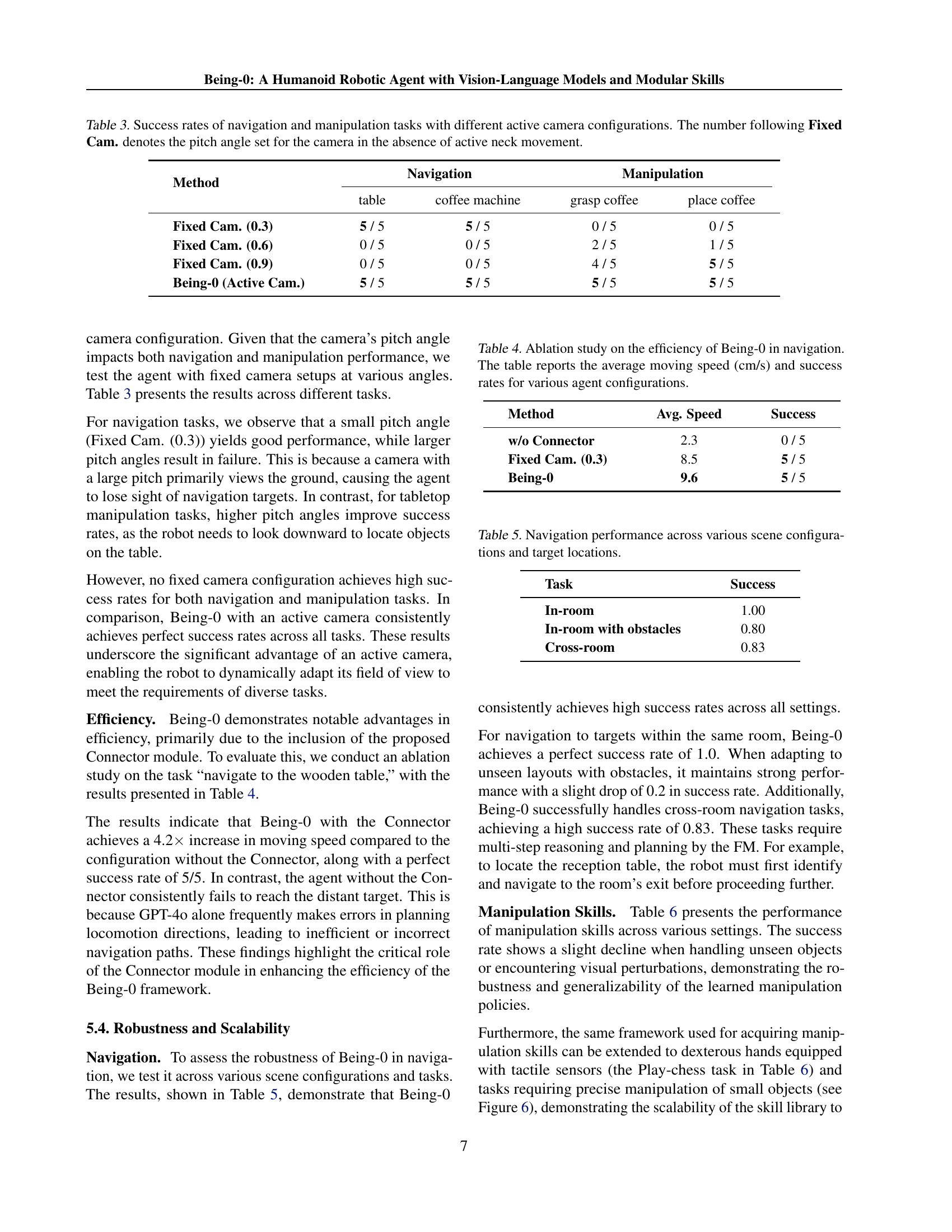
| Task | w/o Adjust. | Being-0 |
| Grasp-bottle | 2 / 5 | 4 / 5 |
| Place-basket | 4 / 5 | 3 / 5 |
| Grasp-coffee | 1 / 5 | 4 / 5 |
| Place-coffee (t) | 4 / 5 | 5 / 5 |
| Place-coffee (m) | 0 / 5 | 3 / 5 |
🔼 This ablation study analyzes the impact of the proposed adjustment method within the Connector module on the success rate of manipulation tasks. Five navigation trials were conducted for each task, and the table shows how many of those trials resulted in successful manipulation. The tasks involve grasping and placing objects either on a table (denoted by ’t’) or on a coffee machine (denoted by ’m’). The results highlight the effectiveness of the adjustment method in improving manipulation success rates, particularly in scenarios where precise positioning is crucial.
read the caption
Table 2: Ablation study on the proposed adjustment method in the Connector module. The results indicate the number of successful manipulations out of 5 navigation trials. (t) denotes “on the table” and (m) denotes “on the coffee machine”.
| Method | Navigation | Manipulation | |||
| table | coffee machine | grasp coffee | place coffee | ||
| 5 / 5 | 5 / 5 | 0 / 5 | 0 / 5 | |
| 0 / 5 | 0 / 5 | 2 / 5 | 1 / 5 | |
| 0 / 5 | 0 / 5 | 4 / 5 | 5 / 5 | |
| Being-0 (Active Cam.) | 5 / 5 | 5 / 5 | 5 / 5 | 5 / 5 | |
🔼 This table presents the success rates of navigation and manipulation tasks performed by the robot with various camera configurations. Specifically, it compares the performance of the robot using an active camera (that can adjust its pitch angle dynamically) against several configurations using a fixed camera at different pre-set pitch angles (0.3, 0.6, and 0.9). The results demonstrate the impact of active vision on task completion success rates.
read the caption
Table 3: Success rates of navigation and manipulation tasks with different active camera configurations. The number following Fixed Cam. denotes the pitch angle set for the camera in the absence of active neck movement.
| Fixed Cam. (0.3) |
🔼 This table presents the results of an ablation study evaluating the efficiency of the Being-0 navigation system. It compares three configurations: Being-0 (the complete system), a version without the Connector module, and a version with a fixed camera at a specific pitch angle. For each configuration, the average moving speed (in cm/s) and the success rate (number of successful navigation trials out of 5) are reported. This allows for an assessment of the impact of the Connector module and the use of active vision on navigation performance.
read the caption
Table 4: Ablation study on the efficiency of Being-0 in navigation. The table reports the average moving speed (cm/s) and success rates for various agent configurations.
| Fixed Cam. (0.6) |
🔼 This table presents the success rates of the Being-0 navigation system across various experimental conditions. It shows how well the robot navigated to different target locations within various indoor environments. The environments tested included simple rooms, rooms with obstacles, and rooms that required crossing between areas. This data demonstrates the robustness and generalizability of the navigation system in complex scenarios.
read the caption
Table 5: Navigation performance across various scene configurations and target locations.
| Fixed Cam. (0.9) |
🔼 This table presents the success rates of various manipulation skills performed by the humanoid robot in different scenarios. These scenarios include using seen and unseen objects and situations with visual disturbances. The results demonstrate the robustness and generalizability of the learned manipulation skills. The asterisk (*) indicates that tactile sensors were added to the dexterous hands for those specific trials.
read the caption
Table 6: Performance of manipulation skills across different scene configurations, including seen objects, unseen objects, and scenarios with visual perturbations. * denotes the use of dexterous hands equipped with tactile sensors.
| Method | Avg. Speed | Success | |
| 2.3 | 0 / 5 | |
| 8.5 | 5 / 5 | |
| 9.6 | 5 / 5 |
🔼 This table presents a breakdown of the sub-processes involved in completing several long-horizon tasks. For each task, it lists the individual steps required, and shows the success rates achieved by the Being-0 system (with the Connector module) and a baseline system (without the Connector). The results highlight the improvement in task completion rates resulting from the addition of the Connector module.
read the caption
Table 7: Detailed sub-processes required to complete each long-horizon task, along with the success rates of Being-0 and the baseline.
| w/o Connector |
🔼 This table shows the number of successful trajectory demonstrations collected for each manipulation skill during the teleoperation phase of skill acquisition. The data was used to train the manipulation skill policies via imitation learning. The number of trajectories varies based on the complexity of the task and the ease of demonstration.
read the caption
Table 8: Number of trajectories collected for each manipulation skill.
| Fixed Cam. (0.3) |
🔼 This table lists the hyperparameters used during the training of the Actor-Critic (ACT) policy for acquiring manipulation skills. The ACT policy is a behavior cloning method that uses a Transformer architecture and is trained using teleoperation data. The hyperparameters shown control aspects of the training process, such as the number of training steps, batch size, learning rate, and gradient clipping.
read the caption
Table 9: Hyperparameters used for training the ACT policy.
| Being-0 |
🔼 This table presents examples of training data used to teach the vision-language model to perform visual understanding tasks. It illustrates how different question types (bounding box detection, item identification, image description, and ground identification) are phrased and what types of answers are expected. This data helps the model learn to connect visual input with various language-based queries.
read the caption
Table 10: Examples of the training data for training the vision-language model to acquire the visual understanding ability.
| Task | Success |
| In-room | 1.00 |
| In-room with obstacles | 0.80 |
| Cross-room | 0.83 |
🔼 This table presents a summary of the dataset used to train the vision-language model (VLM) within the embodied connector module. It breaks down the number of samples collected for each type of visual understanding (VLU) task and action planning (AP) task. The VLU tasks include bounding box detection, yes/no questions, and image description, while the AP tasks involve the planning of actions by the robot.
read the caption
Table 11: Task Categories and Sample Numbers
| Task | Seen Obj. | Unseen Obj. | Perturb. |
| Grasp-bottle | 0.86 | 0.63 | 0.77 |
| Handout-snack | 0.90 | 1.00 | 0.80 |
| Place-pole | 0.90 | – | 0.80 |
| Play-chess* | 0.90 | – | 0.90 |
🔼 This table presents a detailed breakdown of the data used for training the bounding box prediction model. Each row represents a category of objects or areas within the dataset, indicating how many images are associated with each category. The categories cover various locations (e.g., Kitchen Area, Robot Laboratory Room) and specific objects within these locations (e.g., coffee machine, espresso coffee button). The ‘Value’ column shows the frequency of appearance of each category in the dataset, crucial for understanding the class distribution and potential biases in the model’s training data. This information is important for assessing the model’s performance and identifying areas for potential improvement.
read the caption
Table 12: Category data overview for the bounding box task.
| Task | Sub-Process |
|
| ||
| Fetch-bottle | Navigate to table. | 0 / 5 | 5 / 5 | ||
| Grasp cup. | 0 / 5 | 4 / 5 | |||
| Deliver-basket | Navigate to table. | 0 / 5 | 5 / 5 | ||
| Place basket. | 0 / 5 | 3 / 5 | |||
| Prepare-coffee | Navigate to table. | 0 / 5 | 5 / 5 | ||
| Grasp cup. | 0 / 5 | 4 / 5 | |||
| Navigate to coffee machine. | 0 / 5 | 3 / 5 | |||
| Place cup. | 0 / 5 | 3 / 5 | |||
| Make-coffee | Place cup. | 5 / 5 | 5 / 5 | ||
| Select coffee. | 5 / 5 | 5 / 5 | |||
| Select confirmation. | 4 / 5 | 4 / 5 | |||
| Grasp cup. | 4 / 5 | 4 / 5 | |||
| Deliver-coffee | Grasp-cup. | 5 / 5 | 5 / 5 | ||
| Navigate to table. | 0 / 5 | 4 / 5 | |||
| Place cup. | 0 / 5 | 4 / 5 |
🔼 This table presents a breakdown of the data used for training the vision-language model’s ‘yes/no’ question answering ability. It lists the different categories of objects or scenarios (e.g., ‘Coffee Machine’, ‘Reception Desk’, ‘Hallway’) and the number of training samples associated with each category. This helps to understand the distribution of data across various aspects of the environment, ensuring a balanced model.
read the caption
Table 13: Category data overview for the yes/no task.
| w/o Connector |
🔼 This table details the prompt used in the information gathering process. The prompt instructs the foundation model (a large language model) on how to process visual and textual inputs to understand the robot’s environment and task. Specific instructions are given for image description, identifying the robot’s current location, determining the cup-holding status, and determining which objects need to be targeted next.
read the caption
Table 14: The prompt we used for information gathering process.
| Being-0 |
🔼 This table presents the prompt used by the foundation model in the Being-0 framework to summarize the progress of a task and to propose a new subtask. The prompt guides the model through a structured process, incorporating information from previous subtasks, the current image, and a semantic map. It includes sections for summarizing past actions, self-reflection, error analysis, and ultimately proposing a well-reasoned next step for the robot to take toward task completion. The prompt design emphasizes a systematic and logical approach to decision making in complex, real-world scenarios.
read the caption
Table 15: The prompt for summarizing task progress and proposing a new subtask.
| Skill | Num. Trajectories |
| Carry Basket | 25 |
| Handout Snack | 50 |
| Grasp Bottle | 150 |
| Grasp Cup | 200 |
| Open Beer | 50 |
| Place Basket | 25 |
| Place Cup | 200 |
| Place Pole | 50 |
| Play Chess | 70 |
| Play Toy Bricks | 50 |
🔼 This table presents the prompt used for the self-reflection step in the Being-0 framework. The prompt guides the foundation model to analyze the results of the last action, evaluate its success in achieving the overall goal, and provide a reasoned analysis of why it succeeded or failed. It also includes fields for providing visual information (images) and contextual data (semantic map, robot location). The prompt aims to make the foundation model’s reasoning process more transparent and robust, leading to better decision-making and task completion.
read the caption
Table 16: The prompt for reflecting on the task and evaluating success.
| Hyperparameter | Value |
| Training steps | 500,000 |
| Batch size | 90 |
| Learning rate | 1e-5 |
| Gradient clip norm | 10 |
| Chunk size (train) | 30 |
| Chunk size (test) | 10 |
🔼 This table displays the prompt used for the Foundation Model (FM) in the Being-0 framework. The prompt instructs the FM on how to select the next action for the humanoid robot. It provides the FM with relevant context, including the current task, subtask, visual input (image description), robot’s status (location, whether it holds an object), past actions and their outcomes, a list of available actions (skill library), and a semantic map. The prompt guides the FM in making decisions by asking it to consider success conditions, relevant spatial relationships, and the need to search for targets that might not be immediately visible. The prompt is designed to promote both successful task execution and efficient decision-making by the FM.
read the caption
Table 17: The prompt for decision-making and action execution in humanoid robot tasks.
| Task Name | Samples |
| Bounding Boxes | Text Prompt: Detect the bounding box of target object: Reception desk. |
| Answer: [0.471, 0.082, 0.765, 0.951] | |
| Identify items | Text Prompt: Is there an exit in the image? Do not generate anything else except ’Yes’ or ’No’. |
| Answer: No. | |
| Describe image | Text Prompt: Describe the current image. List all the items you could see. |
| Answer: The image shows a corridor or office area with the following items visible: | |
| 1. A person wearing a light-colored outfit. | |
| 2. A green-framed glass door. | |
| 3. A yellow sofa with cushions. | |
| 4. A wall-mounted tablet or screen. | |
| Describe the ground and identify the transition | Text Prompt: Describe the ground and identify the transition between different grounds if there are any. |
| Answer: grey pattern carpet |
🔼 This table shows a concise prompt used for guiding a humanoid robot’s decision-making process and action execution. It provides essential information like the overall task, subtask details, a map of the environment, available actions, and prompts the model to respond using Python code for action execution.
read the caption
Table 18: The shorter version of the prompt we used for decision making and action execution of humanoid robot
Full paper#