TL;DR#
Multimodal chain-of-thought (MCoT) reasoning enhances AI by extending chain-of-thought reasoning to multimodal contexts, integrating modalities like image, video, and audio. This approach has gained traction in applications like robotics, healthcare and autonomous driving. Current MCOT studies design innovative reasoning paradigms to address the unique challenges of each modality, and Multimodal Large Language Models (MLLMs) are playing an increasingly significant role.
To address the lack of a unified resource, this survey offers a systematic overview of MCOT reasoning, defining key concepts and providing a taxonomy of methodologies from various perspectives, such as rationale construction, structural reasoning and objective granularity. It highlights applications, datasets, and benchmarks, also exploring the future directions and existing challenges in the field of MCOT. A key resource, it aims to foster innovation toward achieving multimodal AGI.
Key Takeaways#
Why does it matter?#
This survey on MCOT is essential for researchers, consolidating knowledge and spurring innovation by pinpointing existing challenges and future research directions. The provided resources support further advancements in multimodal AGI.
Visual Insights#

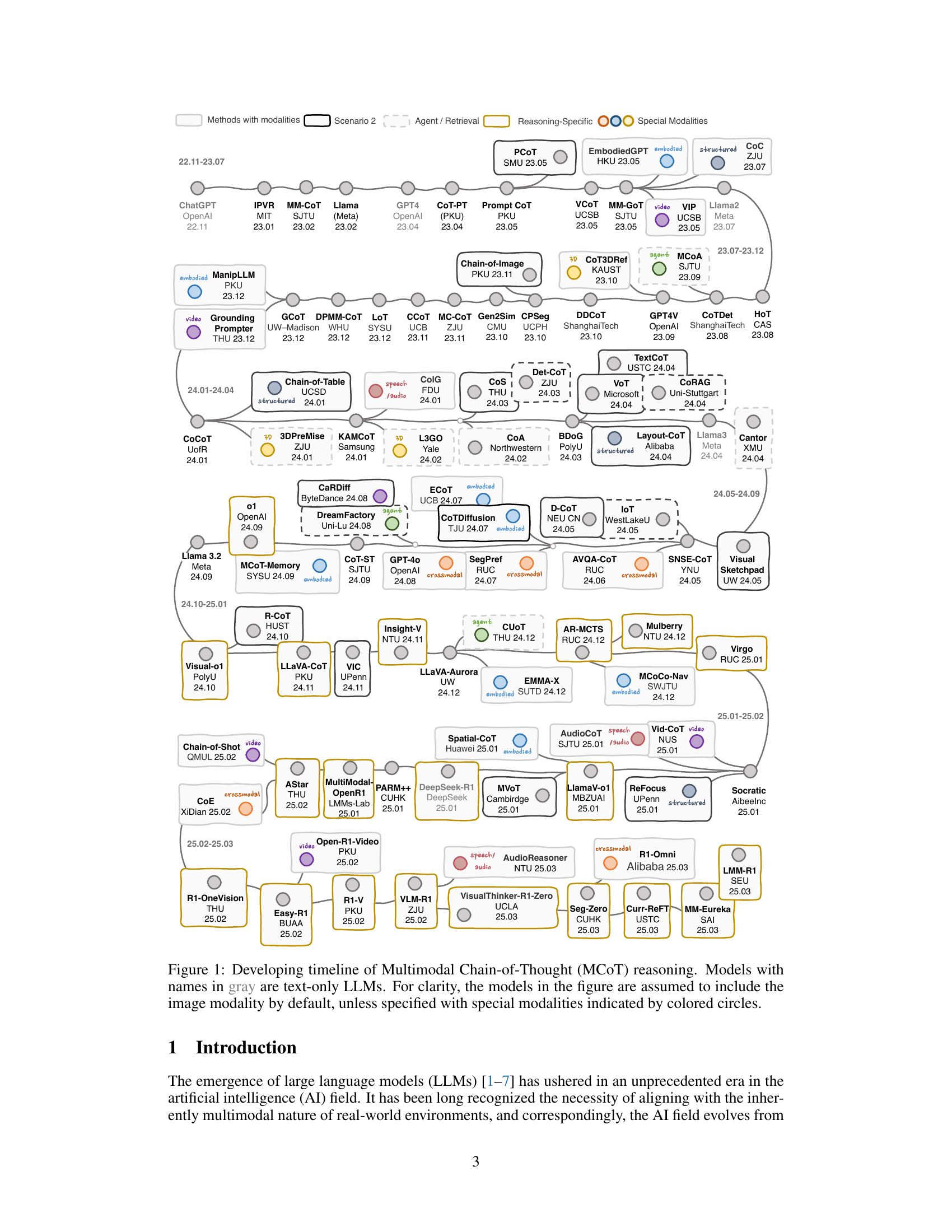
🔼 This figure is a timeline showcasing the development of Multimodal Chain-of-Thought (MCoT) reasoning models. It visually represents the chronological order of significant model releases, highlighting the integration of various modalities beyond text. Models shown in gray represent text-only Large Language Models (LLMs), while colored circles added to model names indicate the inclusion of specific additional modalities (e.g., audio, video, 3D). This visualization helps to understand the evolution of MCoT reasoning across various modalities and the increasing complexity of the models over time.
read the caption
Figure 1: Developing timeline of Multimodal Chain-of-Thought (MCoT) reasoning. Models with names in gray are text-only LLMs. For clarity, the models in the figure are assumed to include the image modality by default, unless specified with special modalities indicated by colored circles.
| Terms | Abbrev. | Description |
| In-context Learning | ICL | Prompting LLMs with task-specific examples without additional explicit training. |
| Chain-of-Thought | CoT | Prompting LLMs to reason step-by-step or breaks complex problems into logical steps. |
| Multimodal CoT | MCoT | Extends CoT to reason with multimodalities, e.g., audio, image. |
| Cross-modal CoT | Reasoning with two or more multimodalities, e.g., audio-visual. | |
| Thought | A single reasoning step in CoT. | |
| Rationale | Built upon multiple thoughts to support the final answer. |
🔼 This table defines key terms frequently used in the context of Multimodal Chain-of-Thought (MCoT) reasoning, clarifying their meaning and usage within the paper. It includes terms like In-context Learning (ICL), Chain-of-Thought (CoT), Multimodal CoT (MCOT), Cross-modal CoT, Thought, and Rationale, providing concise descriptions of each to ensure a shared understanding of terminology.
read the caption
Table 1: Interpretation of MCoT-related terms.
In-depth insights#
MCOT’s Timeline#
Based on the provided research paper, an MCOT’s timeline is presented to observe the key milestones in this emerging field. The developing timeline of MCOT reasoning and the models in the figure are assumed to include the image modality by default, unless specified with special modalities indicated by colored circles. This shows the progression of MCOT from basic COT methods to more complex structured approaches. It shows how the field has advanced, incorporating different modalities and reasoning structures to tackle complex problems in different modalities, such as audio, video, structured datasets and images. The survey identifies key research directions, challenges, and offers resources to support and accelerate progress within the research community.
Beyond Text: MCOT#
Considering ‘Beyond Text: MCOT’ as a conceptual heading, it encapsulates the essence of Multimodal Chain-of-Thought reasoning’s departure from traditional, text-centric AI. It signifies the integration of diverse data modalities like images, audio, and video to emulate human-like cognition more accurately. MCOT’s multimodal approach enables richer contextual understanding and more nuanced reasoning processes. This heading implies the development of AI systems capable of processing and reasoning across various sensory inputs, leading to more comprehensive and insightful outputs. It also highlights the challenges involved, such as aligning different modalities, managing data complexity, and ensuring seamless integration, yet it envisions a future where AI systems can perceive and interact with the world in a more holistic and human-aligned manner. MCOT broadens applicability in fields like robotics, healthcare, and autonomous driving, where understanding the environment through multiple senses is critical.
Modality Spectrum#
When considering a ‘Modality Spectrum’ in multimodal research, the focus shifts to the range and diversity of input types a system can effectively process and integrate. This spectrum encompasses everything from traditional data like text and images, to more complex modalities such as audio, video, 3D data, sensor readings, and even physiological signals. A crucial aspect is the interoperability and synergy between different modalities. The spectrum isn’t just about the number of modalities handled, but also the system’s ability to fuse information across modalities, addressing potential challenges like modality imbalance, noise, and asynchronous data. Research in this area aims to create systems that can dynamically adapt to different modal combinations, understand intricate relationships between modalities, and ultimately achieve more robust and comprehensive representations of the world, thus enabling advanced AI applications.
Rationale Focus#
Rationale focus centers on the methodologies employed in building reasoning chains, a departure from direct input-output methods. While the final answer is important, the emphasis is on how that answer was derived and justified. Methodologies are broadly prompt, plan and learning-based. Prompt based methods use instructions or demonstrations to guide rationales during inference, while plan based methods enable the model to dynamically explore various paths and improving insights. Finally, Learning based methods enable rationale construction during the training or fine-tuning, where models explicitly learn reasoning skills. Each serves to enhance the fidelity and explainability of the reasoning process, an essential aspect of trustworthy AI system.
Theor. Support?#
It appears we’re pondering the theoretical underpinnings, potentially for a novel system or technique. Strong theoretical support is crucial for long-term viability and widespread acceptance. This might involve elements of information theory (bounds on performance), computational complexity (scalability), statistical learning theory (generalization guarantees), or even formal logic (soundness/completeness). It would be vital to address potential limitations, acknowledge assumptions, and contrast this theory against existing frameworks. The more robustly the system can be justified theoretically, the better the chances of it being trusted and adopted by the broader research community. Also, it would be helpful to see whether it can be expressed using formal models.
More visual insights#
More on figures

🔼 This figure presents a comprehensive taxonomy of Multimodal Chain-of-Thought (MCoT) reasoning methods. It organizes various MCoT techniques across several dimensions, including the modality of data involved (image, video, audio, 3D, table/chart, cross-modal), the methodology employed (rationale construction, structural reasoning, information enhancing, objective granularity, multimodal rationale, test-time scaling), and the applications in which these methods are used (embodied AI, agentic systems, autonomous driving, healthcare, social and human interaction, and multimodal generation). Each category contains specific examples of relevant models and papers.
read the caption
Figure 2: Taxonomy of MCoT reasoning.
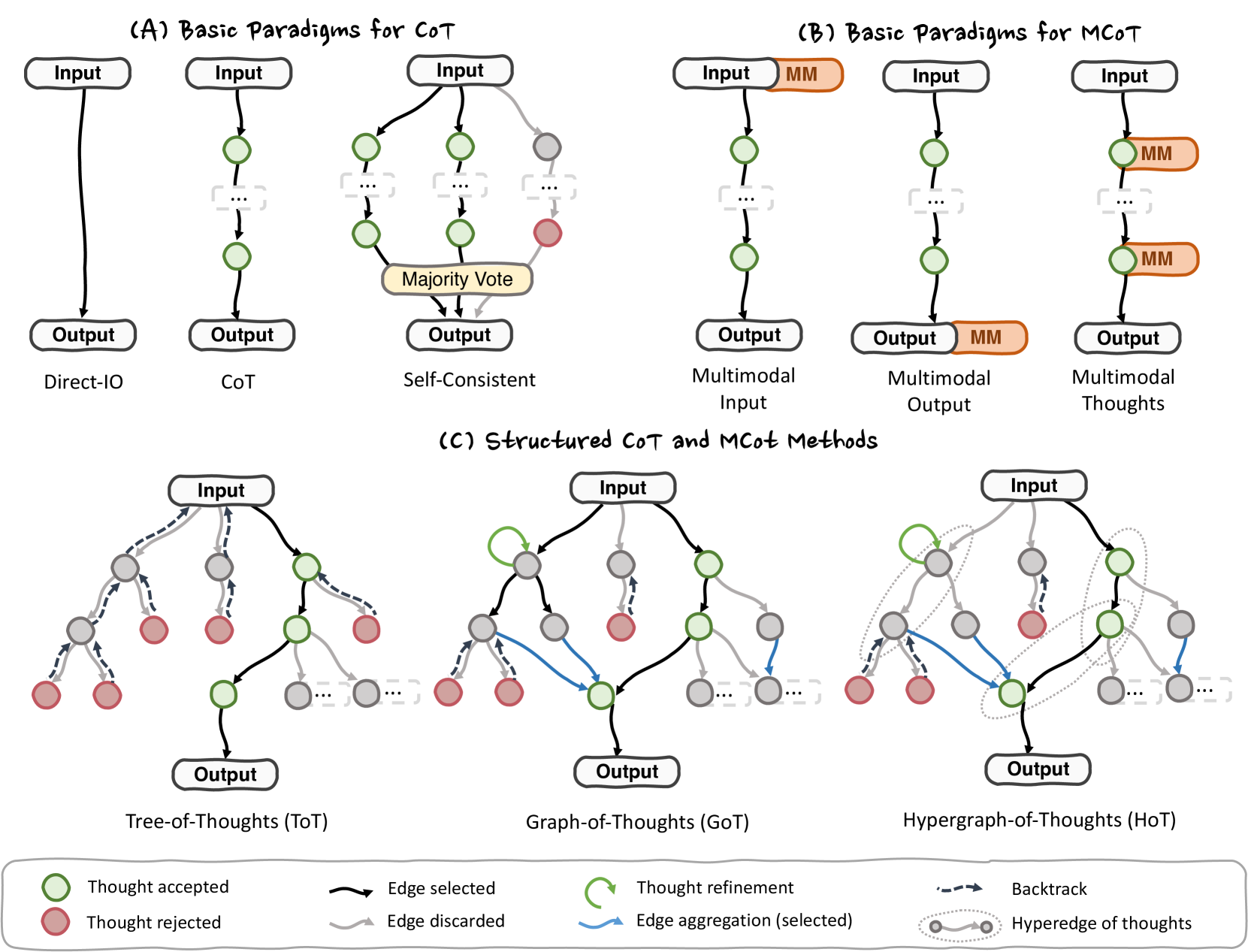
🔼 This figure illustrates the evolution of reasoning structures or topologies used in Chain-of-Thought (CoT) and Multimodal Chain-of-Thought (MCoT) reasoning. It starts by showing basic paradigms for CoT and MCoT, highlighting the differences between direct input-output methods and methods that employ majority voting or self-consistency checks. Then, it moves to structured CoT and MCoT methods, which employ more sophisticated reasoning structures. Specifically, the figure displays three main types of topologies: chain, tree, and graph. Chain topologies represent linear, sequential reasoning; tree topologies allow for exploration and backtracking; and graph and hypergraph topologies facilitate aggregation among multiple nodes, enabling reasoning over more complex multimodal inputs. The figure showcases how the evolution of these topologies directly reflects a progression from linear reasoning to parallel and branching exploration with higher-order associations.
read the caption
Figure 3: Different thought paradigms of CoT and MCoT.

🔼 Figure 4 illustrates the typical architectures of multimodal large language models (MLLMs). It contrasts comprehension-only MLLMs with those capable of both comprehension and generation. Comprehension-only models process multimodal embeddings or tokens into a decoder structure that produces an output. Comprehension and generation models utilize a similar process but also include a generation component allowing them to produce both multimodal outputs (text, image, video, audio, 3D data) and textual outputs.
read the caption
Figure 4: Common architectures for comprehension-only and comprehension-generation MLLMs.

🔼 Figure 5 presents several example applications of Multimodal Chain-of-Thought (MCoT) reasoning across various modalities. Each example showcases a task, the input modalities (e.g., audio, image, video), the reasoning process as a chain of thoughts, and the final answer. Modalities involved include audio, images, video, 3D data, and tables; task types include question answering, grounding, and generation. This highlights MCoT’s adaptability and wide applicability.
read the caption
Figure 5: Examples of MCoT applications in various modalities and tasks.

🔼 This figure illustrates three main methodologies used in Multimodal Chain-of-Thought (MCoT) reasoning, categorized by how the rationale (the step-by-step reasoning process) is constructed. Prompt-based methods use carefully crafted prompts to guide the model’s reasoning. Plan-based methods allow models to dynamically explore and refine thoughts using tree, graph, or hypergraph structures. Learning-based methods incorporate rationale construction directly into the training or fine-tuning process, teaching the model to generate rationales alongside the final answers. The figure also highlights how each method integrates multimodal inputs from various modalities (Image, Video, Audio, etc.) into the LLM.
read the caption
Figure 6: MCoT reasoning methods under different rationale construction perspectives.

🔼 This figure illustrates different methodologies employed in MCoT reasoning, categorized by their structural reasoning approach. It shows how various methods handle the organization and flow of information during the reasoning process, contrasting asynchronous modality processing, defined procedures, and autonomous procedure learning. Asynchronous approaches process modalities independently, defined procedures follow predefined steps, and autonomous methods let the model decide the sequence of reasoning steps.
read the caption
Figure 7: MCoT methods under different structural reasoning perspectives.

🔼 Figure 8 illustrates different methodologies employed in MCOT reasoning, focusing on how enhancing the input information improves the reasoning process. It shows three main approaches: using expert tools to integrate external knowledge or perform specialized operations (e.g., geometric manipulation), retrieving world knowledge from external sources (e.g., knowledge graphs, databases) to enhance the reasoning process, and leveraging in-context knowledge retrieval from the existing information in the input or already generated rationales. Each approach is represented visually, highlighting how these techniques improve multimodal reasoning in MCOT.
read the caption
Figure 8: MCoT reasoning under perspectives with information enhancing.

🔼 Figure 9 illustrates different methodologies within Multimodal Chain-of-Thought (MCoT) reasoning, categorized by the granularity of their objectives. It shows how approaches vary depending on whether the goal is a high-level overview (coarse understanding), precise identification of specific elements (semantic grounding), or detailed analysis of individual components (fine-grained understanding). The figure visually represents the different levels of detail and information processing involved in each approach.
read the caption
Figure 9: MCoT reasoning under the perspectives of various objective granularities.

🔼 This figure illustrates the concept of Multimodal Chain-of-Thought (MCoT) reasoning using multimodal rationales. It shows that, unlike traditional text-only CoT reasoning, MCoT reasoning integrates multiple modalities (represented by ‘M’) into the rationale generation process. This means that the reasoning steps are not limited to text but can also incorporate information from images, audio, video, or other modalities, leading to a more comprehensive and nuanced understanding of the problem and ultimately, a more accurate answer.
read the caption
Figure 10: MCoT reasoning with multimodal rationale.

🔼 This figure illustrates different test-time scaling strategies used in Multimodal Chain-of-Thought (MCoT) reasoning. It shows how reinforcement learning (RL) can enhance the quality of reasoning and enable active long-CoT reasoning capabilities even without extensive annotated training data for long chains of thought. The figure depicts various approaches, emphasizing that supervised fine-tuning (SFT) is an optional component in this process. The options shown highlight different ways to scale the reasoning process at test time, thus allowing for more efficient and effective reasoning in resource-constrained settings.
read the caption
Figure 11: MCoT reasoning with test-time scaling strategies. RL can help improve reasoning quality, or active long-CoT reasoning ability without annotated long-CoT training data. SFT is optional.
More on tables
| Model | Foundational LLMs | Modality | Learning | Cold Start | Algorithm | Aha-moment |
| Deepseek-R1-Zero [137] | Deepseek-V3 | T | RL | ✗ | GRPO | ✔ |
| Deepseek-R1 [137] | Deepseek-V3 | T | SFT+RL | ✔ | GRPO | - |
| LLaVA-Reasoner [138] | LLaMA3-LLaVA-NEXT-8B | T,I | SFT+RL | ✔ | DPO | - |
| Insight-V [91] | LLaMA3-LLaVA-NEXT-8B | T,I | SFT+RL | ✔ | DPO | - |
| Multimodal-Open-R1 [99] | Qwen2-VL-7B-Instruct | T,I | RL | ✗ | GRPO | ✗ |
| R1-OneVision [101] | Qwen2.5-VL-7B-Instruct | T,I | SFT | - | - | - |
| R1-V [236] | Qwen2.5-VL | T,I | RL | ✗ | GPRO | ✗ |
| VLM-R1 [237] | Qwen2.5-VL | T,I | RL | ✗ | GPRO | ✗ |
| LMM-R1 [238] | Qwen2.5-VL-Instruct-3B | T,I | RL | ✗ | PPO | ✗ |
| Curr-ReFT [243] | Qwen2.5-VL-3B | T,I | RL+SFT | ✗ | GPRO | - |
| Seg-Zero [244] | Qwen2.5-VL-3B + SAM2 | T,I | RL | ✗ | GPRO | ✗ |
| MM-Eureka [245] | InternVL2.5-Instruct-8B | T,I | SFT+RL | ✔ | RLOO | - |
| MM-Eureka-Zero [245] | InternVL2.5-Pretrained-38B | T,I | RL | ✗ | RLOO | ✔ |
| VisualThinker-R1-Zero [246] | Qwen2-VL-2B | T,I | RL | ✗ | GPRO | ✔ |
| Easy-R1 [239] | Qwen2.5-VL | T,I | RL | ✗ | GRPO | - |
| Open-R1-Video [242] | Qwen2-VL-7B | T,I,V | RL | ✗ | GRPO | ✗ |
| R1-Omni [130] | HumanOmni-0.5B | T,I,V,A | SFT+RL | ✔ | GRPO | - |
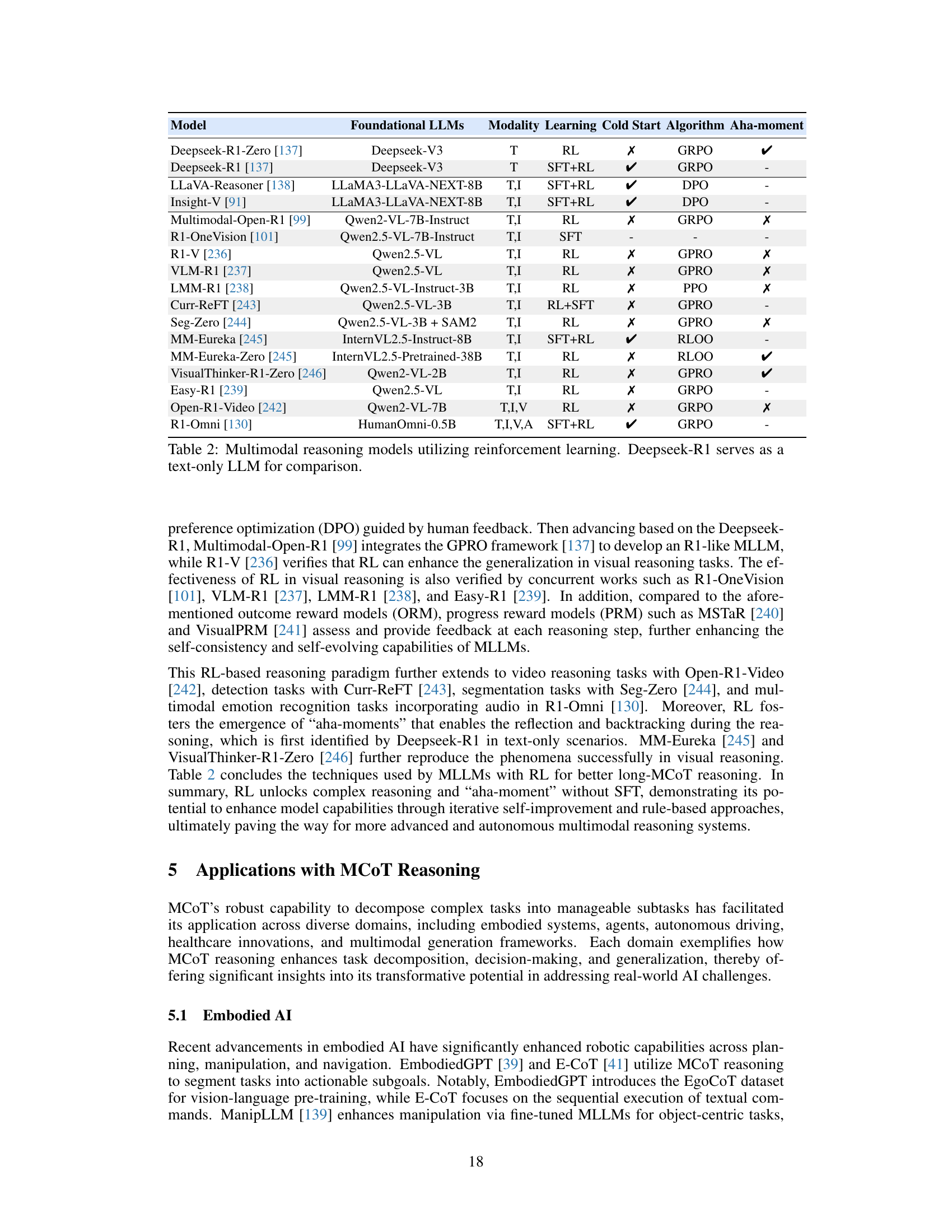
🔼 This table compares various multimodal large language models (MLLMs) that utilize reinforcement learning for reasoning tasks. It highlights key characteristics such as the foundational LLM used, the modalities supported (text, image, video, audio), whether supervised fine-tuning (SFT) was employed, the reinforcement learning algorithm used, whether cold start capabilities were present and whether the model demonstrated an ‘aha moment’, an indication of insightful reasoning. Deepseek-R1, a text-only model, is included for comparative analysis.
read the caption
Table 2: Multimodal reasoning models utilizing reinforcement learning. Deepseek-R1 serves as a text-only LLM for comparison.
| Datasets | Year | Task | Domain | Modality | Format | Samples |
| Training with rationale | ||||||
| ScienceQA [157] | 2022 | VQA | Science | T, I | MC | 21K |
| A-OKVQA [158] | 2022 | VQA | Common | T, I | MC | 25K |
| EgoCoT [39] | 2023 | VideoQA | Common | T, V | Open | 200M |
| VideoCoT [159] | 2024 | VideoQA | Human Action | T, V | Open | 22K |
| VideoEspresso [160] | 2024 | VideoQA | Common | T, V | Open | 202,164 |
| EMMA-X [140] | 2024 | Robot Manipulation | Indoor | T, V | Robot Actions | 60K |
| M3CoT [161] | 2024 | VQA | Science, Math, Common | T, I | MC | 11.4K |
| MAVIS [162] | 2024 | ScienceQA | Math | T, I | MC and Open | 834K |
| LLaVA-CoT-100k [225] | 2024 | VQA | Common, Science | T, I | MC and Open | 834K |
| MAmmoTH-VL [252] | 2024 | Diverse | Diverse | T, I | MC and Open | 12M |
| Mulberry-260k [94] | 2024 | Diverse | Diverse | T, I | MC and Open | 260K |
| MM-Verify [253] | 2025 | MathQA | Math | T, I | MC and Open | 59,772 |
| VisualPRM400K [241] | 2025 | ScienceQA | Math, Science | T, I | MC and Open | 400K |
| R1-OneVision [101] | 2025 | Diverse | Diverse | T, I | MC and Open | 155K |
| Evaluation without rationale | ||||||
| MMMU [163] | 2023 | VQA | Arts, Science | T, I | MC and Open | 11.5K |
| SEED [164] | 2023 | VQA | Common | T, I | MC | 19K |
| MathVista [165] | 2023 | ScienceQA | Math | T, I | MC and Open | 6,141 |
| MathVerse [166] | 2024 | ScienceQA | Math | T, I | MC and Open | 15K |
| Math-Vision [167] | 2024 | ScienceQA | Math | T, I | MC and Open | 3040 |
| MeViS [171] | 2023 | Referring VOS | Common | T, V | Dense Mask | 2K |
| VSIBench [170] | 2024 | VideoQA | Indoor | T, V | MC and Open | 5K |
| HallusionBench [172] | 2024 | VQA | Common | T, I | Yes-No | 1,129 |
| AV-Odyssey [254] | 2024 | AVQA | Common | T, V, A | MC | 4,555 |
| AVHBench [174] | 2024 | AVQA | Common | T, V, A | Open | 5,816 |
| RefAVS-Bench [169] | 2024 | Referring AVS | Common | T, V, A | Dense Mask | 4,770 |
| MMAU [255] | 2024 | AQA | Common | T, A | MC | 10K |
| AVTrustBench [173] | 2025 | AVQA | Common | T, V, A | MC and Open | 600K |
| MIG-Bench [135] | 2025 | Multi-image Grounding | Common | T, I | BBox | 5.89K |
| MedAgentsBench [256] | 2025 | MedicalQA | Medical | T, I | MC and Open | 862 |
| Evaluation with rationale | ||||||
| CoMT [175] | 2024 | VQA | Common | T, I | MC | 3,853 |
| OmniBench [180] | 2024 | VideoQA | Common | T, I, A | MC | 1,142 |
| WorldQA [176] | 2024 | VideoQA | Common | T, V, A | Open | 1,007 |
| MiCEval [177] | 2024 | VQA | Common | T, I | Open | 643 |
| OlympiadBench [178] | 2024 | ScienceQA | Maths, Physics | T, I | Open | 8,476 |
| MME-CoT [179] | 2025 | VQA | Science, Math, Common | T, I | MC and Open | 1,130 |
| EMMA [168] | 2025 | VQA | Science | T, I | MC and Open | 2,788 |
| VisualProcessBench [241] | 2025 | ScienceQA | Math, Science | T, I | MC and Open | 2,866 |
🔼 This table lists datasets and benchmarks used for training and evaluating Multimodal Chain-of-Thought (MCoT) reasoning models. It categorizes datasets based on whether they provide rationales (step-by-step explanations) during training. It also specifies the task (e.g., Visual Question Answering, Video Question Answering), domain (e.g., Science, Common Sense), modalities involved (Text, Image, Video, Audio), and the format of the answers (multiple-choice or open-ended). The table also indicates the number of samples in each dataset.
read the caption
Table 3: Datasets and Benchmarks for MCoT Training and Evaluation. “MC” and “Open” refer to multiple-choice and open-ended answer formats, while “T”, “I”, “V”, and “A” represent Text, Image, Video, and Audio, respectively.
| Model | Params (B) | MMMU (Val) | MathVista (mini) | Math-Vision | EMMA (mini) |
| Human | - | 88.6 | 60.3 | 68.82 | 77.75 |
| Random Choice | - | 22.1 | 17.9 | 7.17 | 22.75 |
| OpenAI | |||||
| o1 [216] | - | 78.2 | 73.9 | - | 45.75 |
| GPT-4.5 [257] | - | 74.4 | - | - | - |
| GPT-4o [212] | - | 69.1 | 63.8 | 30.39 | 36.00 |
| GPT-4o mini [212] | - | 59.4 | 56.7 | - | - |
| GPT-4V [258] | - | 56.8 | 49.9 | 23.98 | - |
| Google & DeepMind | |||||
| Gemini 2.0 Pro [259] | - | 72.7 | - | - | - |
| Gemini 2.0 Flash [259] | - | 71.7 | - | 41.3 | 48.00 |
| Gemini 1.5 Pro [260] | - | 65.8 | 63.9 | 19.24 | - |
| Anthropic | |||||
| Claude 3.7 Sonnet [194] | - | 75 | - | - | 56.50 |
| Claude 3.5 Sonnet [194] | - | 70.4 | 67.7 | 37.99 | 37.00 |
| Claude 3 Opus [194] | - | 59.4 | 50.5 | 27.13 | - |
| Claude 3 Sonnet [194] | - | 53.1 | 47.9 | - | - |
| xAI | |||||
| Grok-3 [261] | - | 78.0 | - | - | - |
| Grok-2 [262] | - | 66.1 | 69.0 | - | - |
| Grok-2 mini [262] | - | 63.2 | 68.1 | - | - |
| Moonshot | |||||
| Kimi-k1.5 [263] | - | 70 | 74.9 (test) | 38.6 | 33.75 |
| Alibaba | |||||
| QVQ-72B-Preview [264] | 72 | 70.3 | 71.4 | 35.9 | 32.00 |
| Qwen2.5-VL-72B [265] | 72 | 70.2 | 74.8 | 38.1 | - |
| Qwen2-VL-72B [11] | 72 | 64.5 | 70.5 | 25.9 | 37.25 |
| Qwen2.5-VL-7B [265] | 7 | 58.6 | 68.2 | 25.1 | - |
| Qwen2-VL-7B [11] | 7 | - | - | 16.3 | - |
| OpenGVLab | |||||
| InternVL2.5 [266] | 78 | 70.1 | - | - | 35.25 |
| InternVL2 [267] | 76 | 58.2 | 65.5 | - | - |
| LLaMA | |||||
| Llama-3.2-90B [268] | 90 | 60.3 | 57.3 | - | - |
| Llama-3.2-11B [268] | 11 | - | 48.6 | - | - |
| LLaVA | |||||
| LLaVA-OneVision [269] | 72 | 56.8 | 67.5 | - | 27.25 |
| LlaVA-NEXT-72B [270] | 72 | 49.9 | 46.6 | - | - |
| LLaVA-NEXT-34B [270] | 34 | 48.1 | 46.5 | - | - |
| LLaVA-NEXT-8B [270] | 8 | 41.7 | 37.5 | - | - |
| LLaVA-Reasoner [138] | 8 | 40.0 | 50.6 | - | - |
| LLaVA-1.5 [271] | 13 | 36.4 | 27.6 | 11.12 | - |
| Community | |||||
| Mulberry [94] | 7 | 55.0 | 63.1 | - | - |
| MAmmoTH-VL [252] | 8 | 50.8 | 67.6 | 24.4 | - |
| MM-Eureka [245] | 8 | - | 67.1 | 22.2 | - |
| MM-Eureka-Zero [245] | 38 | - | 64.2 | 26.6 | - |
| Curr-ReFT [243] | 7 | - | 64.5 | - | - |
| Curr-ReFT [243] | 3 | - | 58.6 | - | - |
| LMM-R1 [238] | 3 | - | 63.2 | 26.35 | - |
| LlamaV-o1 [97] | 11 | - | 54.4 | - | - |
| R1-Onevision [101] | 7 | - | - | 26.16 | - |
| Virgo [95] | 7 | 46.7 | - | 24.0 | - |
| Insight-V [91] | 8 | 42.0 | 49.8 | - | - |
🔼 This table presents a performance comparison of various multimodal large language models (MLLMs) from different institutions. The comparison is based on four benchmarks: MMMU (Validation set), MathVista (Mini version), Math-Vision, and EMMA (Mini version). Each benchmark likely tests different aspects of MLLM capabilities, such as mathematical reasoning, problem-solving, and understanding of visual and textual information. The table allows readers to quickly assess the relative performance of different MLLMs in these benchmark tasks, highlighting the strengths and weaknesses of various models.
read the caption
Table 4: Performance comparison of MLLMs from various institutions across four benchmarks: MMMU (Val), MathVista (Mini), Math-Vision, and EMMA (Mini).
Full paper#